1. Introduction
Please let someone know on the Fulcro slack channel if this document is out of date with the live implementation in the RAD Demo, or even better: send a PR to fix it.
This book covers Rapid Application Development (RAD) tools for Fulcro. The RAD system is intended to be augmented with any number of plugins that can handle anything from back-end database management to front-end UI automation.
When reading the source code of this book we will use a number of namespace aliases. We list the aliases we most commonly use here for easy reference:
(ns some-ns
(:require
#?(:clj [com.fulcrologic.fulcro.dom-server :as dom :refer [div label input]]
:cljs [com.fulcrologic.fulcro.dom :as dom :refer [div label input]])
[clojure.string :as str]
[com.fulcrologic.fulcro.algorithms.form-state :as fs]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.routing.dynamic-routing :as dr :refer [defrouter]]
[com.fulcrologic.rad.attributes :as attr :refer [defattr]]
[com.fulcrologic.rad.attributes-options :as ao]
[com.fulcrologic.rad.authorization :as auth]
[com.fulcrologic.rad.form :as form :refer [defsc-form]]
[com.fulcrologic.rad.form-options :as fo]
[com.fulcrologic.rad.ids :refer [new-uuid]]
[com.fulcrologic.rad.picker-options :as picker-options]
[com.fulcrologic.rad.report :as report :refer [defsc-report]]
[com.fulcrologic.rad.report-options :as ro]
[com.fulcrologic.rad.routing :as rr]
[com.fulcrologic.rad.routing.history :as history]
[com.fulcrologic.rad.type-support.date-time :as datetime]
[com.fulcrologic.rad.type-support.decimal :as math]
[edn-query-language.core :as eql]))The core system has the following general ideals:
-
The world of information has many sources, and those sources can all be unified under a single model.
-
Accessing and managing data from a mix of sources (both local and remote) should be as transparent as possible to the application code.
-
EQL is more ideally suited to this task than GraphQL, as the latter’s stricter schema (which limits dynamically shaping the query to better fit client needs), paltry primitive data types (EQL uses EDN, which is trivially extensible to keep binary types in tact across platforms), and class-based model make GraphQL much less flexible as needs emerge in a data model over time.
-
-
Everything is optional. Applications written using RAD should be able to choose which aspects are useful, and easily escape from aspects if they don’t fit their needs.
-
Reasonable defaults and utilities for common needs.
-
UI Platform independent: RAD is intended to be usable for development in web and native environments. The core namespaces are not tied to a rendering/UI technology (though React-based is the practical choice).
The common features that are intended to be well-supported in early versions of the library include:
-
Declarative and extensible data model.
-
Reasonable defaults for CRUD interfaces (form generation) to arbitrary graphs of that data model, including to-one and to-many relations.
-
Reasonable defaults for common reporting needs, especially when tabular.
1.1. Core Elements
RAD defines a few central component types, with the following generalized meaning:
-
Forms: A form is a (potentially recursive) UI element that loads data from any number of sources, keeps track of changes to that data over time (including validating it), and allows the user to save/undo their work as a unit. Note that a form need not use traditional inputs. The main purpose of a form is to load/manage a cluster of persistent data fields over a fixed time period (typically while on screen).
-
Forms:
-
Obtain (or create) data from source(s) for the primary purpose of editing that data.
-
The primary actions in a form are to save/discard changes as a unit.
-
Forms can also be used in read-only mode as a way to allow viewing of that data when editing is not allowed.
-
-
Reports
-
Obtain data from source(s) which is often derived or read-only (may include aggregations, inferences, etc.)
-
Display that data in a manner that is convenient to the viewer for some particular use-case.
-
Interactions commonly include specifying input parameters, filters, and possibly the ability to manage large result sets via subselection (e.g. pagination)
-
Reports may allow interactions that change the persisted data, but those actions are targeted to subsets of items in the report, and therefore prefer to be modelled as targeted units of work (e.g. mutations) instead of "saves" of the entire data set.
-
-
Containers
-
Manage groupings of UI elements.
-
Allow for shared controls. For example a report’s links on the left might trigger a form to update on the right.
-
-
Routing (and optionally History)
-
Allows for direct navigation to a place in the application.
-
(optionally) Keeps track of where the user has been.
-
(optionally) Exposes the application location (e.g. Browser URL)
-
(optionally) Allows UI platforms to support common navigation needs (back/forward/bookmark). For example, an HTML5 implementation of history keeps the current location in the browser bar, and allows the user to use the fwd/back buttons to navigate in the application and bookmark pages.
-
-
BLOBs (Binary Large Objects)
-
Data that is typically stored in disk files (images, PDFs, spreadsheets)
-
Can be saved into the data model via forms (or report mutations)
-
Can be previewed or downloaded
-
As you can see there is some overlap in forms and reports. A read-only form is very much like a report, and a report with sufficient "row actions" (i.e. each cell can be clicked to edit) can behave very much like a form.
1.2. Required Dependencies
See the README files on the various libraries and plugins you use for the correct set of dependencies. The current version of the demo project will have an up-to-date list. The most complex dependency is on js-joda for date/time consistency. The latest versions of RAD do not require a js-joda locale, but versions prior to 1.0.28 did.
If you use the isomorphic math support you will also need big.js.
If you do not use big decimals, then you can safely ignore that ns and dependency.
Of course if you target the web then you’ll also need things like react, react-dom and any other UI libraries it might use, etc.
1.3. Attribute-Centric
Fulcro encourages the use of a graph-based data model that is agnostic to the underlying representation of your data. This turns out to be a quite powerful abstraction, as it frees you from the general limitations and restrictions of a rigid class/table-based schema while still giving you adequate structure for your data model.
The central artifact that you write when building with RAD is an attribute, which is an RDF-style concept where you define everything of interest about a particular fact in the world in a simple map. The only two required things that you must say about an attribute are its distinct name and type. The name must be a fully-qualified keyword.
The namespace should be distinct enough to co-exist in the data realm of your application (i.e. if you are working on the internet level you should consider using domain-style naming). The type is meant to be an open concept, but usually you will want to make sure that it is supported by your database back-end and possibly your rendering plugin. The type system of RAD is extensible, and you must refer to the documentation of your selected database adapter and rendering layer to find out if the data type is already supported. It is generally easy to extend the data type support of RAD at extension points in these plugins.
A minimal attribute will look something like this:
(ns com.example.model.item (:require
[com.fulcrologic.rad.attributes :as attr :refer [defattr]]))
(defattr id :item/id :uuid
{::attr/identity? true
::attr/schema :production})The defattr macro really just assigns a plain map to the provided symbol (id in this case), but it also ensures that you’ve provided a name for the attribute (:item/id in this case), and a type.
It is exactly equivalent to:
(def id {::attr/qualified-key :item/id
::attr/type :uuid
::attr/identity? true
::attr/schema :production})The various plugins and facilities of RAD define keys that allow you to describe how your new data attribute should behave in the system.
In the example above the identity? marker indicates that the attribute identifies groups of other facts (is a primary key for data), and the datomic-namespaced schema is used by the Datomic database plugin to indicate the schema that the attribute should be associated with.
1.3.1. Attribute Options – Documentation and Autocomplete
The standard in RAD is for libraries to define an *-options namespace that defines vars for each configurable key that they support.
This allows these vars to be used instead of raw keywords, leading to much easier development.
For example, the attributes namespace defines
attributes-options.
This namespace includes all of the legal keys that RAD itself defines that can be placed in an attribute’s map.
The form namespace defines form-options, etc.
This allows you to write an attribute like so:
(ns com.example.model.item (:require
[com.fulcrologic.rad.attributes-options :as ao]
[com.fulcrologic.rad.attributes :refer [defattr]]))
(defattr id :item/id :uuid
{ao/identity? true
ao/schema :production})which helps you ensure that you’re using a key that has not been mis-typed, and also gives you docstring access in your IDE.
The documentation on these options is intended to be an important source of information when using RAD.
1.3.2. Extensibility
Attributes are represented as open maps (you can add your own namespaced key/value pairs). There are a core set of keys that the library defines for generalized use, but most plugins will use keywords namespaced to their library to extend the configuration stored on attributes. These keys can define anything, and form the central feature of RAD’s extensibility.
1.4. Data Modelling, Storage, and API
The attribute definitions are intended to be usable by server storage layers to auto-generate artifacts like schema, network APIs, documentation, etc. Of course these things are all optional, but can serve as a great time-saver when standing up new applications.
1.4.1. Schema Generation
Attributes are intended to be capable of completely describing the data model. Database plugins will often be capable of using the attributes to generate server schema. Typical plugins will require library-specific keys that will tell you how to get exactly the schema you want. If you’re working with a pre-existing database you will probably not bother with this aspect of RAD.
1.4.2. Resolvers
Resolvers are part of the Pathom library. Resolvers figure out how to get from a context to data that is needed by the client. Attributes describe the data model, so storage plugins can usually generate resolvers (if your schema conforms to something it can understand) and provide a base EQL API for your data model. All you have to do is hook it into your server’s middleware.
1.4.3. Security
Statements about security can also be co-located on attributes, which means that RAD can generate protections around your data model. RAD does not pre-supply a security model at this time, since something that is fully generalized would have the scope of something like AWS IAM, and is simply more open source work than we can afford to provide.
That said, most application can implement something quite a bit more narrow in scope: is the user authenticated, and do they "own" the thing they are trying to read/write. Most systems write these rules around the network operations. In RAD the vast majority of your saves will go through the save middleware, meaning you can concentrate your rules and logic there.
For reads: Resolvers are the unit of readable data in RAD, and you can often place security in the Pathom parser as a plugin.
If you want some guidance on implementing security in RAD, please contact Fulcrologic, LLC for paid help crafting a solution that meets you needs.
1.5. Forms
Many features of web applications can be classified as some kind of form. For our purposes a form is any screen where a tree of data is loaded and saved "together", and where validation and free-form inputs are common. A form could be anything from a simple set of input fields to a kanban board (which could also be considered a report with actions). Most applications have the need to generate quite a few simple forms around the base data model in order to do customer support and general data administration. Simple forms are also a common feature in user-facing content.
RAD has a pluggable system for generating simple forms, but it can also let you take complete control of the UI while RAD still manages the reads, writes, and overall security of the data.
Forms in RAD are a mechanism around reading and writing specific sub-graphs of your data model.
1.6. Reports
A Report is any screen where the data contains a mix of read-only, derived, and aggregate data. This data may be organized in many ways (graphically, in columns, in rows, as a kanban board). Interactions with the data commonly include linking (navigation), filtering, groupings, pagination, and abstract actions that can affect arbitrary things (e.g. delete this item, move that card, zoom that chart).
Reports are about pulling data from your data model so that the user can view or interact with it in some way.
The primary difference between a form and a report is that: on a form, the majority of the data has an existence in a persistent store that is (roughly) a one-to-one correlation with a control on screen and a fact in a database. Reports, on the other hand, may include derived data, aggregations, etc. Interactions with a report that result in changes on the server must be encoded as more abstract operations.
The most common report we think of a simple list or table of values that has:
-
Input Parameters
-
A query for the results
-
A UI, often tabular.
In RAD reports are generated by adding additional "virtual attributes" to your model that have hand-written Pathom resolvers.
Report plugins should be able to provide just about anything you can imagine in the context of a report, such as:
-
Parameter Inputs
-
Linkage to forms for editing
-
Graphs/charts
-
Tabular reports
The RAD system generally makes it easy for you to pull the raw data for a report, and at any moment you can also choose to do the specific rendering for the report when no plugin exists that works for your needs.
1.7. Platform Targets
Fulcro works quite well on the web, in React Native, and in Electron. Notice that the core of RAD is built around auto-generation of UI, meaning that many features of RAD will work equally well in any of these settings.
It is our hope that the community will build libraries of UI controls for these various platforms so that the same core RAD source could be used to generate applications on any of these targets with no need to manually write UI code. That said, RAD will already work on any of these targets with no modification: you’ll just have to write the UI bodies of the forms/reports yourself. This still gives you a lot of pre-written support for:
-
Your database model
-
Loading/saving/controlling form data
-
Loading/manipulating report data.
In fact, as your application grows it is our expectation and design that you take over much of detailed code in your application. It is not the intention of RAD to do everything in your final production application. The point of RAD is to make it possible to rapidly stand up your application, and then gradually take over the parts that make sense while not having to worry over a bunch of boilerplate.
2. Attributes
The recommended setup of attributes is as follows:
-
Create a
modelpackage, such ascom.example.model. -
Use CLJC! A major point is to reuse this information in the full stack.
-
Organize your attributes around the concepts and entities that use them.
-
Try not to think of attributes as strictly belonging to an entity or table so much as describing a particular fact. For example the attribute
:password/hashed-valuemight live on aFileorAccountentity. Entity-centric attributes certainly exist, but you should not constrain your thinking about them.
-
-
Place attributes in the namespace whose name that matches that attribute’s namespace. E.g.
:account/*should be in something likecom.example.model.account. This ensures you don’t accidentally model the same attribute twice, which would confuse many of the facilities of RAD. -
At the end of each file include a
defforattributesandresolvers. Each should be a vector containing all of the attributes and Pathom resolvers defined in that file. -
Create a central model namespace that has all attributes. I.e.
com/example/model.cljccontaining adefforall-attributes.
Thus your overall source tree could look like this:
$ cd src/main/com/example
$ tree .
.
├── model
│ ├── account.cljc
│ ├── address.cljc
│ ├── invoice.cljc
│ ├── item.cljc
│ └── line_item.cljc
├── model.cljc2.1. Model Namespaces
The first thing you’ll typically create will be namespaces like this:
(ns com.example.model.account
(:require
[com.fulcrologic.rad.attributes-options :as ao]
[com.fulcrologic.rad.attributes :refer [defattr]]))
(defattr id :account/id :uuid
{ao/identity? true})
(defattr name :account/name :string
{ao/required? true
ao/identities #{:account/id}})
(def attributes [id name])
(def resolvers [])The namespace makes it easy for you to find the attributes when you want to read all of the details about them, and the final def make it easy to combine the declared attributes into a single collection for use in APIs that need to know them all.
You can also make your own defattr macro that side-effects these into a global registry.
We prefer the explicit combination of attributes because it forces you to require the proper namespaces to make the compiler happy, whereas a registry needs you to require the namespaces, but the compiler won’t complain if you clean up requires and accidentally remove a model from your program.
It’ll just fail at runtime.
2.2. Identity Attributes
Each type of entity/table/document in your database will need a primary key. Each attribute that you define that acts as a primary key will serve as a way to contextually find attributes that indicate they can be found via that key. This is very similar to what you’re used to in typical databases where a primary key gives you, say, a row. RAD’s data model does not constrain an attribute to live in just one place, as you’ll see in a moment.
The ao/identity? boolean marker on an attribute marks it as a "primary key" (really that it is a key by which a distinct entity/row/document can be found).
(ns com.example.model.account
(:require
[com.fulcrologic.rad.attributes-options :as ao]
[com.fulcrologic.rad.attributes :refer [defattr]))
(defattr id :account/id :uuid
{ao/identity? true})2.3. Data Types
The data types in RAD are not constrained by RAD itself, though only a limited number of them are supplied by database adapter and UI libraries. Extending the type system simply requires that you make a name for your type, and then supply logic to handle that type at various layers.
TODO: A chapter on adding a data type.
2.4. Scalar Attributes
Many attributes are simple containers for scalar values (strings, numbers, etc.). RAD itself does not constrain where an attribute can live in any way, but specific database adapters will have rules that match the underlying storage technology.
A RAD attribute to store a string might look like this:
(defattr name :account/name :string
{})but such an attribute will only be usable if you hand-generate resolvers on your server that can obtain the value, and can store it based on the ID you give a form. So, such an attribute isn’t useless, but it is made much more powerful when you add information for other plugins.
2.5. Attribute Clusters (Entities/Tables/Documents)
RAD recognizes that different storage technologies group facts together in different ways. (in tables/documents/entities). The common theme that RAD tries to unify is the idea that a particular fact is reachable through either itself (i.e. it is itself a primary key of things), or via some identifying information.
Now, since we recognize something like a :password/hashed-value might live on multiple kinds of things in your database, the generalization is to simply tell RAD which identities can be used to reach that kind of fact:
(defattr id :account/id :uuid
{ao/identity? true})
(defattr name :account/name :string
{ao/required? true
ao/identities #{:account/id}})
(defattr email :account/email :string
{ao/required? true
ao/identities #{:account/id}})
;; Account, files, and SFTP endpoints have passwords
(defattr password-hash :password/hash :string
{ao/required? true
ao/identities #{:account/id :file/id :sftp-endpoint/id}})This simple generalization leads to a lot of potential in libraries.
An SQL database could use this to know it should add :password/hash to the ACCOUNT, FILE, and SFTP_ENDPOINT tables, while any database driver can know to generate resolvers that can find :password/hash if supplied with an :account/id, :file/id, or :sftp-endpoint/id; and that :account/email is easily reachable if an :account/id
is known.
Remember that our graph resolver (Pathom) is also intelligent about "connecting the dots".
Thus, if there is some bit of information known (i.e. an SFTP hostname) that can be used to resolve an :sftp-endpoint/id, then the network API
will automatically be able to derive that :sftp-endpoint/hostname can be used to find a :password/hash.
2.6. Referential Attributes
Data models are typically normalized, and normalization requires that you be able to store a distinct thing once and refer to it from other places. RAD’s attribute-centric nature actually gives you quite a bit of ability to "flex" the shape of your data model at runtime through custom resolvers (i.e. you can create virtualized views of your data that have alternate shapes from the way the data is stored). Therefore the reference declarations in RAD can define a concrete (i.e. represented in storage) or virtual link.
When an attribute is declared with type :ref and it represents a concrete link in storage then it will include database adapter-specific entries that define the reification of that linkage (e.g. does it hold an ID of a foreign table/document/entity, does it use a join table, is it a back reference from a foreign table, or is it simply a nested map in a document?).
If an attribute represents a virtual link it will typically include a lambda (resolver) that runs the appropriate logic to "invent" that linkage.
For example, your customers might have multiple addresses, and you might want a virtual reference to the address you’ve most often shipped items to.
You can easily assign that a name like :customer/most-likely-address, but you’ll most likely need to run a query of order history to actually figure out what that is.
References have a cardinality (one/many), and when they are concrete they also typically have some kind of optional statement about "ownership".
In SQL this is typically modelled with CASCADE rules, in document databases it is often implied by co-location in the same document, and in Datomic it is handled with the isComponent flag.
Again, RAD attributes allow the database adapter to define namespaced keys that can be placed on an attribute to indicate how that attribute should behave.
When using references in Forms you’ll typically also have to include a bit of extra information for the form itself to know which kind of behavior should be modelled for the user, since it will not be aware of the ins-and-outs of your low-level database.
For example an invoice’s line item needs to point to something defined in your inventory. An invoice form might show that as a dropdown that lets you autocomplete a selection from the inventory items.
2.7. Attribute Types and Details
There are a number of predefined attribute types defined by the central RAD system. Add-on libraries can define more. There is nothing in RAD core itself that either implements these types or supports them. They are opaque to core, and we predefine common primitive ones as a starting point. Database adapters can define more, and these custom types will sometimes require that you write an input control or field to support such a type.
The core predefined attribute types include (this list is not complete yet, but most of these are present):
:string-
A variable-length string.
:enum-
An enumerated list of values. Support varies by db adapter.
:boolean-
true/false
:int-
A (typically 32-bit) integer
:long-
A (typically 64-bit) integer
:decimal-
An arbitrary-precision decimal number. Stored precision is up to the db adapter.
:instant-
A binary UTC timestamp.
:keyword-
An EDN keyword
:symbol:: An EDN symbol:ref:: A reference to another entity/table/document. Indicates traversal of the attribute graph. :uuid-
A UUID.
See the various docstrings in the *-options.cljc namespaces for predefined things that can be put into an attribute’s map.
Here are some examples for attributes-options:
ao/identity?-
A boolean. When true it indicates that this attribute is to be used as the PK to find an entity/document/table row.
ao/required?-
A boolean. Indicates that the system should constrain interactions such that entities/rows/documents that contain this attribute are considered invalid if they do not have it. Affects things like schema generation, form interactions, etc.
ao/target-
A keyword. Required when the type of the attribute is
:ref(unless you use ao/targets). It must be the qualified keyword name of anidentity? trueattribute. For example:account/addressesmight have a target of:address/id. ao/targets-
(NEW in 1.3.10) A SET of keywords. Required when the type of the attribute is
:refunless you useao/target. The keywords must be the qualified keywords ofidentity? trueattributes. This allows for polymorphic types to be the target of edges. ao/cardinality-
Defines the expected cardinality of the attribute. Supported when the type of the attribute is
:ref, and some database adapters may support it on other types. Defaults to:one, but can also be:many. ao/enumerated-values-
Only when type is
:enum. A set of keywords that represent the legal possible values when the type is:enum. Constraints on this may vary based on the db adapter chosen. Typically you will use narrowed keywords for this (e.g.:account/typemight have values:account.type/user, etc.). ao/enumerated-labels-
Only when type is
:enum. A map from enumerated keywords (inenumerated-values) to the user string that should be shown for that enumerated value. Used in Form UI generation.
2.8. All Attributes
RAD often needs to know what attributes are in your model. Early versions tried using a registry, but the side-effect nature of such a thing is simply quite annoying (order-dependent, you can forget requires, etc.).
When building a RAD application you should manually build up a list of all of the attributes in your model.
The recommended pattern is to include a def of attributes at the bottom of each model namespace, then you can easily define a list of all attributes like this:
(ns com.example.model
(:require
[com.example.model.account :as account]
[com.example.model.item :as item]
[com.example.model.invoice :as invoice]
[com.example.model.line-item :as line-item]
[com.example.model.address :as address]
[com.fulcrologic.rad.attributes :as attr]))
(def all-attributes (vec (concat
account/attributes
address/attributes
item/attributes
invoice/attributes
line-item/attributes)))The list of all attributes is required in a number of places in RAD: automatic resolver generation, schema support, save-middleware, etc.
It is also quite useful to have a way to quickly look up an attribute by its keyword:
(def key->attribute (attr/attribute-map all-attributes))and to have a Form Validator that is based on the attribute definitions that can be used in derived validators and directly on forms:
(def default-validator (attr/make-attribute-validator all-attributes))2.9. Attribute Hot Code Reload
Attributes are really just maps, which in Clojure are immutable. Unfortunately, as you build your model you’ll often want to edit some attribute and be able to have that change take effect quickly in the server REPL (CLJS already hot reloads a dependency list, so it already works well). This usually involves loading the attribute’s namespace, the model combination namespace, etc.
RAD attributes come with a development-time feature that can make it much faster to evolve your model during development:
RAD can replace the attribute maps with mutatble versions behind the scenes, so that re-evaluating a defattr in the REPL will fix all closures over that value!
You will still have to reload multiple namespaces if you add or remove attributes, but changes to existing attributes in this mode is much faster.
To enable it, just set the system property rad.dev to true before loading your code.
This can be done with a JVM argument: -Drad.dev=true.
|
Note
|
This is not meant to be a production feature, and without that JVM property defined the attribute maps are normal Clojure immutable data. |
3. Server Setup
A RAD server must have an EQL API endpoint, typically at /api.
This is standard Fulcro stuff, and you should refer to the Fulcro Developer’s Guide for full details, with most of the elements that RAD needs described below.
3.1. Configuration Files
Fulcro comes with an EDN-based config file system, and it has options that work well for both development and production purposes. Please see the Fulcro Developer’s Guide for complete details.
The component that loads config usually ends up being the first thing started in your program, which makes it an ideal place to put other code that does stateful initialization which has no dependencies other than the config data (such as logging and the RAD attribute registry).
Here is the recommended config component using mount:
(ns com.example.components.config
(:require
[com.fulcrologic.fulcro.server.config :as fulcro-config]
[com.example.lib.logging :as logging]
[mount.core :refer [defstate args]]
[taoensso.timbre :as log]
[com.example.model :as model]
[com.fulcrologic.rad.attributes :as attr]))
(defstate config
"The overrides option in args is for overriding configuration in tests."
:start (let [{:keys [config overrides]
:or {config "config/dev.edn"}} (args)
loaded-config (merge (fulcro-config/load-config {:config-path config}) overrides)]
(log/info "Loading config" config)
;; set up Timbre to proper levels, etc...
(logging/configure-logging! loaded-config)
loaded-config))The config files themselves, like config/defaults.edn and config/dev.edn, will contain a single map.
See the documentation of Fulcro for more information on how these configurations are merged, using values from the environment, etc.
{:my-config-value 42}3.2. Form Middleware
Forms support middleware that allows plugins to hook into the I/O subsystem of forms. This allows RAD form support plugins to be inserted into the chain to do things like save form data to a particular database. They use a pattern similar to Ring middleware.
There are currently two middlewares that must be created: save and delete.
3.2.1. Save Middleware
The save middleware is simply a function that will receive the Pathom mutation env, which is augmented with ::form/params.
Usually you will at least compose a set of pre-supplied middleware like so:
(ns com.example.components.save-middleware
(:require
[com.fulcrologic.rad.middleware.save-middleware :as r.s.middleware]
[com.fulcrologic.rad.database-adapters.datomic :as datomic]
[com.example.components.datomic :refer [datomic-connections]]
[com.fulcrologic.rad.blob :as blob]
[com.example.model :as model]))
(def middleware
(->
(datomic/wrap-datomic-save)
(r.s.middleware/wrap-rewrite-values)))This is also the best place to put things like security and schema validation enforcement for save.
3.2.2. Delete Middleware
Very similar to save middleware, but is invoked during a request to delete an entity.
(ns com.example.components.delete-middleware
(:require
[com.fulcrologic.rad.database-adapters.datomic :as datomic]))
(def middleware (datomic/wrap-datomic-delete))Of course you’ll also want to add things to this middleware to check security and such.
3.3. Pathom Parser
You will normally use Pathom to provide the processing for the network API on your server (Pathom supports CLJ and CLJS, so you can use the JVM or node). RAD has some logic to convert virtual attributes to resolvers, and many more resolvers can be auto-generated by a RAD storage plugins like Fulcro RAD Datomic.
So first, you’ll generate a stateful list of all of the attributes that convert to resolvers (these will include
::path-connect/resolve keys):
(ns com.example.components.auto-resolvers
(:require
[com.example.model :refer [all-attributes]]
[mount.core :refer [defstate]]
[com.fulcrologic.rad.resolvers :as res]
[taoensso.timbre :as log]))
(defstate automatic-resolvers
:start
(vec (res/generate-resolvers all-attributes))then you’ll set up a stateful parser that installs various plugins and resolvers along with a few standard ones and any you’ve created elsewhere. The result will look something like this:
(ns com.example.components.parser
(:require
[com.example.components.auto-resolvers :refer [automatic-resolvers]]
[com.example.components.config :refer [config]]
[com.example.components.datomic :refer [datomic-connections]]
[com.example.components.delete-middleware :as delete]
[com.example.components.save-middleware :as save]
[com.example.model :refer [all-attributes]]
[com.example.model.account :as account]
[com.fulcrologic.rad.attributes :as attr]
[com.fulcrologic.rad.blob :as blob]
[com.fulcrologic.rad.database-adapters.datomic :as datomic]
[com.fulcrologic.rad.form :as form]
[com.fulcrologic.rad.pathom :as pathom]
[mount.core :refer [defstate]]))
(defstate parser
:start
(pathom/new-parser config
[(attr/pathom-plugin all-attributes) ; required to populate standard things in the parsing env
(form/pathom-plugin save/middleware delete/middleware) ; installs form save/delete middleware
(datomic/pathom-plugin (fn [env] {:production (:main datomic-connections)})) ; db-specific adapter
[automatic-resolvers ; the resolvers generated from attributes
form/resolvers ; predefined resolvers for form support (save/delete)
account/resolvers ; custom resolvers you wrote, etc.
...]))The supplied constructor for pathom parsers is not required, you can use the source to see what it includes by default. The RAD parser construction function takes a Fulcro-style server config map, a vector of plugins, and a vector of resolvers (the resolvers can be nested sequences).
You will always want the form plugin, along with any storage adapter plugin that works with a database on your server.
3.4. The Server (Ring) Middleware
Once you have a parser you just need to wrap it in a Fulcro API handler. The resulting minimal server will be a Ring-based system with middleware like this:
(ns com.example.components.ring-middleware
(:require
[com.fulcrologic.fulcro.server.api-middleware :as server]
[mount.core :refer [defstate]]
[ring.middleware.defaults :refer [wrap-defaults]]
[com.example.components.config :as config]
[com.example.components.parser :as parser]
[taoensso.timbre :as log]
[ring.util.response :as resp]
[clojure.string :as str]))
(defn wrap-api [handler uri]
(fn [request]
(if (= uri (:uri request))
(server/handle-api-request (:transit-params request)
(fn [query]
(parser/parser {:ring/request request}
query)))
(handler request))))
(def not-found-handler
(fn [req]
{:status 404
:body {}}))
(defstate middleware
:start
(let [defaults-config (:ring.middleware/defaults-config config/config)]
(-> not-found-handler
(wrap-api "/api")
(server/wrap-transit-params {})
(server/wrap-transit-response {})
(wrap-defaults defaults-config))))See the RAD Demo project for the various extra bits you might want to define around your middleware. You will need to add middleware to support things like file upload, CSRF protection, etc.
3.5. The Server
At this point the server is just a standard Ring server like this (here using Immutant):
(ns com.example.components.server
(:require
[immutant.web :as web]
[mount.core :refer [defstate]]
[taoensso.timbre :as log]
[com.example.components.config :refer [config]]
[com.example.components.ring-middleware :refer [middleware]]))
(defstate http-server
:start
(let [cfg (get config :org.immutant.web/config)
running-server (web/run middleware cfg)]
(log/info "Starting webserver with config " cfg)
{:server running-server})
:stop
(let [{:keys [server]} http-server]
(web/stop server)))4. Client Setup
Fulcro RAD can be used with any Fulcro application. The only global configuration that is required is to initialize the attribute registry, but the more features you use, the more you’ll want to configure. RAD applications that use HTML5 routing and UI generation, for example, will also need to configure those.
Here is what a client might look like that also includes some logging output improvements and supports hot code reload at development time:
(ns com.example.client
(:require
[com.example.ui :refer [Root]]
[com.fulcrologic.fulcro.application :as app]
[com.fulcrologic.rad.application :as rad-app]
[com.fulcrologic.rad.rendering.semantic-ui.semantic-ui-controls :as sui]
[com.fulcrologic.fulcro.algorithms.timbre-support :refer [console-appender prefix-output-fn]]
[taoensso.timbre :as log]
[com.fulcrologic.rad.type-support.date-time :as datetime]
[com.fulcrologic.rad.routing.html5-history :refer [html5-history]]
[com.fulcrologic.rad.routing.history :as history]))
(defonce app (rad-app/fulcro-rad-app
{:client-did-mount (fn [app]
;; Adds improved logging support to js console
(log/merge-config! {:output-fn prefix-output-fn
:appenders {:console (console-appender)}}))}))
(defn refresh []
;; hot code reload of installed controls
(log/info "Reinstalling controls")
(rad-app/install-ui-controls! app sui/all-controls)
(app/mount! app Root "app"))
(defn init []
(log/info "Starting App")
;; a default tz, for date/time support
(datetime/set-timezone! "America/Los_Angeles")
;; Optional HTML5 history support
(history/install-route-history! app (html5-history))
;; Install UI plugin that can auto-render forms/reports
(rad-app/install-ui-controls! app sui/all-controls)
(app/mount! app Root "app"))Additional RAD plugins and templates will include additional features, and you should see the Fulcro and Ring documentation for setting up customizations to things like sessions, cookies, security, CSRF, etc.
5. Database Adapters
Database adapters are an optional part of the RAD system. There are really three main features that a given database adapter MAY provide for you (none are required). The may provide the ability to:
-
Auto-generate schema for the real database.
-
Generate a network API to read the database for the UI client.
-
Process form saves (which come in a standard diff format).
Additional features, of course, could be supplied such as the ability to:
-
Validate the attribute definitions against an existing (i.e. legacy) schema.
-
Shard across multiple database servers.
-
Pool database network connections.
-
Isolate development changes from the real database (i.e. database interaction mocking)
|
Note
|
The documentation for the database adapters will contain the most recent details, and should be preferred over this book. |
5.1. Database Adapters
The RAD Datomic database adapter has the following features:
-
Datomic Schema generation (or just validation) from attributes.
-
Support for multiple database schemas.
-
Form save automation.
-
Automatic generation of a full network API that can pull from the database(s) by ID.
-
Database sharding.
See the README of the adapter for information on dependencies and project setup. You will need to add dependencies for the version of Datomic you’re using and any storage drivers (e.g. PostgreSQL JDBC driver) for the back-end you choose.
|
Note
|
Other database adapters are in progress. There is a mostly-working SQL adapter, and a REDIS adapter is also on the way. Adapters are not terribly difficult to write, as the data format of RAD and Fulcro is normalized and straightforward. |
5.2. The Server-side Resolvers
The EQL network API of RAD is supplied by Pathom Resolvers that can pull the data of interest from your database. Typically you’ll need to have at least one resolver for each top-level entity that can be pulled by ID, and custom resolvers that can satisfy various other queries (e.g. all accounts, current user, etc.). Forms need to be able to at least resolve entities by their ID, and reports need to be able to uniquely identify rows (either through real or generated values).
DB adapters can often automatically generate many of these resolvers, but legacy applications can simply ensure all of the attributes a form might need can be resolved via an ident-based Fulcro query against that form (e.g. [{[:account/id id] [:account/name]}]).
Fulcro and EQL defines the read/write model, and RAD just leverages it. You can use as much or as little RAD automation as you want. It is just doing what you would do for Fulcro applications.
5.3. Form Middleware
Forms support middleware that allows plugins to hook into the I/O subsystem of forms. This allows RAD plugins to be inserted into the processing chain to do things like save form data to a particular database. They use a pattern similar to Ring middleware.
There are currently two middlewares that must be created: save and delete. The documentation of your plugin will indicate if it supplies such middleware, and how to install it.
5.3.1. The Parser env
Form save/delete is run in the context of Pathom, meaning that the env that is available to any plugin is whatever is configured for Pathom itself. All middleware should leverage this in order to provide runtime information.
Database plugins should require that you add some kind of plugin to your parser.
Mostly what these plugs are doing is adding content to the env under namespaced keys: database connections, URLs, etc.
Whatever is necessary to accomplish the real task at runtime will be in env.
The save and delete middlware that you install in the parser is the logic for accomplishing a save or delete.
The env in pathom is the state necessary for it to do so.
5.3.2. Save Middleware
The save middleware is simply a function that will receive the Pathom mutation env.
The env will include:
-
::form/paramsThe minimal diff of the form being saved -
::attr/key→attributeA map from qualified keyword to attribute definition -
All other pathom env entries.
Creating a middleware chain is done as in Ring: create a wrap function that optionally receives a handler and returns middleware.
The Datomic wrapper looks like this:
(defn wrap-datomic-save
"Form save middleware to accomplish Datomic saves."
([]
(fn [{::form/keys [params] :as pathom-env}]
(let [save-result (save-form! pathom-env params)]
save-result)))
([handler]
(fn [{::form/keys [params] :as pathom-env}]
(let [save-result (save-form! pathom-env params)
handler-result (handler pathom-env)]
(deep-merge save-result handler-result)))))Form Params
Forms are saved in a normalized diff format that looks like this:
{[:account/id 1] {:account/name {:before "Joe" :after "Sally"} :account/address {:after [:address/id 2]}}
[:address/id 2] {:address/street ...}}The keys of the map are Fulcro idents (like Datomic lookup refs): The id keyword and an ID.
The values of the map are the diff on the attributes that "group under" that entity/ID.
Your middleware can modify the env (so that handlers further up the chain see the effects), side effect (save long strings to an alternate store), check security (possibly throwing exceptions or removing things from the params), etc.
This simple construct allows an infinite variety of complexity to be added to your saves.
5.3.3. Delete Middleware
This is very similar to save middleware, but is invoked during a request to delete an entity.
6. Leveraging Rendering Plugins
RAD macros generate Fulcro components.
RAD will always include code in these components that helps automate the management of state.
Forms will manage the client-side load, save, dirty checking, validation, etc.
You can simply use the helper functions like form/save! to ask the form system to do such operations for you, and write the actual rendering of the form by hand.
BUT, eliminating the need to write all of this boilerplate UI code can be a huge win early in your project. So, if you do not include a render body, then RAD will attempt to generate one for you, but only if you install a render plugin.
RAD depends on React, but does not directly use any DOM or native code.
Thus, UI plugins can target both a
look and platform for UI generation.
At the time of this writing only a web plugin exists, and it uses Semantic UI CSS to provide the general look-and-feel (though semantic UI is easy to theme, so that is easy to style without having to resort to code). Perhaps by the time you read this there will also be plugins for React native.
6.1. Attribute and Context-Specific Style
Once you’ve selected the UI plugin for generating UI, you still have a lot of control over the site-specific style of a given control or format via "style". This is nothing more than the ability to give a hint as to the kind of information an attribute represents so that the UI plugin (or your own control) can change to suit a particular need.
For example, an :instant in the database might be a epoch-based timestamp, but perhaps you just care to use it with a constant time (say midnight in the user’s time zone).
You might then hint that the attribute should have the style of a "date at midnight", which you could just invent a keyword name for: :date-at-midnight.
RAD supports the ability to set and override a control style at many levels. The attribute itself can be given a style:
(defattr :account/created-on :instant
{ao/style :long-timestamp
...})and forms and reports will allow you to override that style via things like formatters and field style overrides.
See the form-options and report-options namespaces for particular details.
6.2. Installing Controls
RAD places the definition of controls inside of the Fulcro application itself (which has a location for just such extensible data). The map for UI element lookup looks something like this (subject to change and customization in UI plugins):
(def all-controls
{;; Form-related UI
;; completely configurable map...element types are malleable as are the styles. Plugins will need to doc where
;; they vary from the "standard" set.
:com.fulcrologic.rad.form/element->style->layout
{:form-container {:default sui-form/standard-form-container
:file-as-icon sui-form/file-icon-renderer}
:form-body-container {:default sui-form/standard-form-layout-renderer}
:ref-container {:default sui-form/standard-ref-container
:file sui-form/file-ref-container}}
:com.fulcrologic.rad.form/type->style->control
{:text {:default text-field/render-field}
:enum {:default enumerated-field/render-field
:autocomplete autocomplete/render-autocomplete-field}
:string {:default text-field/render-field
:autocomplete autocomplete/render-autocomplete-field
:viewable-password text-field/render-viewable-password
:password text-field/render-password
:sorted-set text-field/render-dropdown
:com.fulcrologic.rad.blob/file-upload blob-field/render-file-upload}
:int {:default int-field/render-field}
:long {:default int-field/render-field}
:decimal {:default decimal-field/render-field}
:boolean {:default boolean-field/render-field}
:instant {:default instant/render-field
:date-at-noon instant/render-date-at-noon-field}
:ref {:pick-one entity-picker/to-one-picker
:pick-many entity-picker/to-many-picker}}
;; Report-related controls
:com.fulcrologic.rad.report/style->layout
{:default sui-report/render-table-report-layout
:list sui-report/render-list-report-layout}
:com.fulcrologic.rad.report/control-style->control
{:default sui-report/render-standard-controls}
:com.fulcrologic.rad.report/row-style->row-layout
{:default sui-report/render-table-row
:list sui-report/render-list-row}
:com.fulcrologic.rad.control/type->style->control
{:boolean {:toggle boolean-input/render-control
:default boolean-input/render-control}
:string {:default text-input/render-control
:search text-input/render-control}
:picker {:default picker-controls/render-control}
:button {:default action-button/render-control}}})The idea is that layouts and controls should be pluggable and extensible simply by inventing new ones and adding them to the map installed in your application.
The map also allows you to minimize your CLJS build size by only configuring the controls you use. Thus a library of controls might include a very large number of styles and type support, but because you can centralize the inclusion and requires for those items into one minimized map you can much more easily control the UI generation and overhead from one location. These are the primary reasons we do not use some other mechanism for this like multi-methods, which cannot be dead-code eliminated and are hard to navigate in source.
UI Plugin libraries should come with a function that can install all of their controls at once.
The report namespace allows you to define (or override) field formatters via report/install-formatter!.
6.3. Forms
A form is really just a Fulcro component.
RAD includes the macro defsc-form that can auto-generate the various component options (query, ident, route target parameters, etc.) from your already-declared attributes.
The fo namespace is an alias for the com.fulcrologic.rad.form-options namespace.
A form should have a minimum of 2 attributes:
fo/id-
An attribute (not keyword) that represents the primary key of the entity/document/table being edited.
fo/attributes-
A vector of attributes (not keywords) that represent the attributes to be edited in the form. These can be scalar or reference attributes, but must have a resolver that can resolve them from the
::form/idattribute, and must also be capable of being saved using that ID.
Most forms that are used directly (and not just as sub-forms) must also include a route prefix to make them capable of direct use:
fo/route-prefix-
A single string. Every form ends up with two routes:
[prefix "create" :id]and[prefix "edit" :id]. Theformnamespace includes helpersedit!andcreate!to trigger these routes, but simply routing to them will invoke the action (edit/create).
If you have configured UI generation then that is all you need. Thus a minimal form that is using the maximal amount of RAD plugins and automation is quite small:
(form/defsc-form AccountForm [this props]
{fo/id account/id
fo/attributes [account/name account/email account/enabled?]
fo/route-prefix "account"})There are pre-written functions in the form ns for the common actions:
(form/create! app-ish FormClass)-
Create a new instance of an entity using the given form class.
(form/edit! app-ish FormClass id)-
Edit the given entity with
idusingFormClass (form/delete! app-ish qualified-id-keyword id)-
Delete an entity. Should not be done while in the form unless combined with some other routing instruction.
6.4. A Complete Client
We are now to the point of seeing what a complete Fulcro RAD client looks like. The bare minimal client will have:
-
A Root UI component
-
(optional) Some kind of "landing" page (default route)
-
One or more forms/reports.
-
The client initialization (shown earlier).
(ns com.example.ui
(:require
[com.example.model.account :as acct]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
#?(:clj [com.fulcrologic.fulcro.dom-server :as dom :refer [div]]
:cljs [com.fulcrologic.fulcro.dom :as dom :refer [div]])
[com.fulcrologic.fulcro.routing.dynamic-routing :refer [defrouter]]
[com.fulcrologic.rad.authorization :as auth]
[com.fulcrologic.rad.form-options :as fo]
[com.fulcrologic.rad.form :as form]))
(form/defsc-form AccountForm [this props]
{fo/id acct/id
fo/attributes [acct/name]
fo/route-prefix "account"})
(defsc LandingPage [this props]
{:query ['*]
:ident (fn [] [:component/id ::LandingPage])
:initial-state {}
:route-segment ["landing-page"]}
(div
(dom/button {:onClick (fn [] (form/create! this AccountForm))}
"Create a New Account"))
(defrouter MainRouter [this props]
{:router-targets [LandingPage AccountForm]})
(def ui-main-router (comp/factory MainRouter))
(defsc Root [this {::auth/keys [authorization]
:keys [authenticator router]}]
{:query [{:router (comp/get-query MainRouter)}]
:initial-state {:router {}}}
(div :.ui.container.segment
(ui-main-router router)))The landing page in this example includes a sample button to create a new account, but of course you’ll also need to add some seed data to your database, wrap things with some authorization, etc.
6.5. UI Validation
The data type and rendering style of an attribute (along with extended parameters possibly defined by input styles in their respective documentation) are the first line of data enforcement: Saying that something is a decimal number with a US currency style will already ensure that the user cannot input "abc" into the field.
Further constraining the value might be something you can say at the general attribute level (age must be between 0 and 130), or may be contextual within a specific form (from-date must be before to-date).
Validators are functions as described in Fulcro’s Form State support:
They are functions that return :valid, :invalid, or :unknown (the field isn’t ready to be checked yet).
They are easily constructed using the form-state/make-validator helper, which takes into account the current completion marker on the field itself (which prevents validation messages from showing too early).
Attribute-level validation checks can be specified with a predicate:
(defattr name :account/name :string
{ao/valid? (fn [nm] (boolean (seq nm)))})Custom validations are defined at the form level with the ::form/validator key.
If there are validators at both layers then the form one completely overrides all attribute validators.
If you want to compose validators from the attributes then use attr/make-attribute-validator on your complete model, and use the result in the form validator:
(ns model ...)
(def all-attributes (concat account/attributes ...)
(def all-attribute-validator (attr/make-attribute-validator all-attributes))
...
(ns account)
(def account-validator (fs/make-validator (fn [form field]
(case field
:account/email (str/ends-with? (get form field) "example.com")
(= :valid (model/all-attribute-validator form field))))))The message shown to the user for an invalid field is also configurable at the form or attribute level. The existence of a message on the form overrides the message declared on the attribute.
(attr/defattr age :thing/age :int
::attr/validation-message (fn [age]
(str "Age must be between 0 and 130.")))
...
(form/defsc-form ThingForm [this props]
{fo/validation-messages
{:thing/age (fn [form-props k]
(str (get form-props k) " is an invalid age."))}
...})The form-based overrides are useful when you have dependencies between fields, since they can consider all of the data in the form at once and incorporate it into the check and validation message. For example you might want to require a new email user use their lower-case first name as a prefix for an email address you’re going to generate in your system. You might use something like this:
(def account-validator (fs/make-validator (fn [form field]
(case field
:account/email (let [prefix (or
(some-> form
(get :account/name)
(str/split #"\s")
(first)
(str/lower-case))
"")]
(str/starts-with? (get form :account/email) prefix))
(= :valid (model/all-attribute-validator form field))))))6.6. Composing Forms
It is quite common for a form to cover more than one entity (row or document) in a database. An account might have one or more addresses. An invoice has a customer, line items, and references to inventory. In RAD, combining related data requires a form definition for each uniquely identifiable entity/row/document. These can have to-one or to-many relationships.
A given entity and its related data can be joined together into a single form interaction by making one of the forms the master. This must be a form that resolves to a single entity, and whose subforms are reachable by resolvers through the attributes of that master (or descendants).
Any form can automatically serve as a master. The master is simply selected by routing to it, since that will start that form’s state machine which in turn will end up controlling the entire interaction. The subforms themselves can act as standalone forms, but will not be running their own state machine unless you route directly to them. Interestingly this means that forms can have both a sibling and parent-child relationship in your application’s UI graph.
All forms are typically added to a top-level router so that each kind of entity can be worked with in isolation.
However, some forms may also make sense to use as subforms within the context of others.
An example might be an AddressForm.
While it might make sense to allow someone to edit an address in isolation, the address itself probably belongs to some other entity that may wish to allow editing of that sub-entity in its context.
A simple example of this would look as follows:
(form/defsc-form AddressForm [this props]
{fo/id address/id
fo/attributes [address/street address/city address/state address/zip]
fo/cancel-route ["landing-page"]
fo/route-prefix "address"
fo/title "Edit Address"})
(form/defsc-form AccountForm [this props]
{fo/id acct/id
fo/attributes [acct/name acct/email acct/active? acct/addresses]
fo/cancel-route ["landing-page"]
fo/route-prefix "account"
fo/title "Edit Account"
fo/subforms {:account/addresses {fo/ui AddressForm}}})
(defrouter MainRouter [this props]
{:router-targets [AccountForm AddressForm]})In the above example the AddressForm is completely usable to edit an address (if you have an ID) or create one (if it makes sense to your application to create one in isolation).
But it is also used as a subform through the
:account/addresses attribute where the fo/subforms map is used to configure which form should be used for the items of the to-many relationship.
Additional keys in the subforms map entries allow for specific behavioral support.
6.7. Default Values During Creation
This section assumes you know a bit about Fulcro’s Form State support. The validation system used in RAD is just that, with some automation stacked on top. It is important to understand that validation does not start taking effect on a field until it is "marked complete", and a form is never considered "valid" until everything it is considered "complete". RAD will automatically mark things complete as users interact with form fields (often on blur), but creation needs you to indicate what (pre-filled) fields should be considered "already complete".
The rules the built-in RAD form state machine uses:
-
Any existing (loaded) form is automatically fully-marked as complete.
-
New top-level forms pre-mark fields complete if:
-
The field is optional.
-
The field has a default value.
-
The field is passed in (via route parameters :initial-state)
-
These rules are applied recursively by the top-level form.
-
The attributes options for setting defaults when things are created are:
fo/default-value-
Can be placed on an attribute to indicate a default value for this attribute.
fo/default-values-
A map from attribute name (as a keyword) to a default value. Subform data can be placed in this tree.
6.7.1. Relationship Lifecycle
One of the core questions in any relation is: does the referring entity/table/document "own" the target?
In other words does it create and destroy it?
When there is a graph of such relations this question is also recursive (and is handled by things like CASCADE in SQL and isComponent markers in Datomic).
When there is not an ownership relation one still needs to know if the referring entity is allowed to create new ones (destroying them is usually ruled out, since others could be using it).
In the cases where there is not an ownership relation we usually model it as some kind of "picker" in a form, allowing the user to simply select (or search for) "which" of the existing targets are desired. When there is an ownership relation the form will usually model the items as editable sub-forms, with optional controls that allow the addition and removal of the elements in the relation.
The form management system uses the concept of "subforms" to model all of the possible relationships, relies on database adapters to manage things like cascading deletes, and needs some additional configuration (on a per-form basis) from you as to how relations should be rendered and interacted with in the UI.
The following sections cover various relational use-cases that RAD forms support.
6.7.2. To-One Relation, Owned by Reference
In this case the referenced item springs into existence when the parent creates it, and drops from existence when it is no longer referenced. Database adapters model this in various ways, but the concept at the form layer is simple: If you’re creating it then you’ll be creating a new thing, an edit will edit the current thing, and if you drop the reference you’ll depend on the database adapter’s save logic to delete it (which may or may not be implemented, you may need to add save middleware).
The form rendering system can derive that it is a to-one relation from the cardinality declared on the reference attribute. The ownership nature is more of a rendering concern than anything: If the new thing is exclusively owned then we know we have to generate a subform that can fill out the details.
|
Note
|
This kind of relation can also be modelled by folding the referred items attributes into the owner.
For example if you have an edge called :account/primary-address that is a to-one relation to an address, but you don’t plan to do real normalization of addresses (which is difficult), then you could also just make :account/primary-street and such on the account itself and skip the relational nature altogether.
|
6.7.3. To-One Relation to Pre-existing
|
Note
|
This use-case is partially implemented. It will work well when selecting from a relatively small set of targets, but will not currently perform well if the list of potential targets is many thousands or greater. |
In this case setting up the relation is nothing more that picking some pre-existing thing in the database. There are several sub-aspects to this problem:
-
Should you be able to create a new one?
-
When selecting an existing one, how do you manage large lists of potential candidates (search, caching, etc.)?
-
How do you label the items so the user can select them?
At the time of this writing the answers are:
-
Not yet generically implemented. Setting a to-one relation is a selection process unless you hand-write the UI yourself; However, it is relatively easy to implement a UI control that can do both.
-
This is an option of the UI control used to do the selection. At present all of the potential matches are pre-loaded. This is also something you can easily customize by simply writing your own control.
-
This is something you can configure.
A demonstration of this case is as follows: Assume we want to generate a form for an invoice. The invoice will have line items (to many, owned by the invoice), and each line item will point to an item from our inventory (owned by inventory, not the line item).
We can start from the bottom. The inventory item itself might have this model in a Datomic database:
(ns com.example.model.item
(:require
[com.fulcrologic.rad.attributes-options :as ao]
[com.fulcrologic.rad.attributes :refer [defattr]]))
(defattr id :item/id :uuid
{ao/identity? true
ao/schema :production})
(defattr item-name :item/name :string
{ao/identities #{:item/id}
ao/schema :production})
...followed by the line item model:
(ns com.example.model.line-item
(:require
[com.fulcrologic.rad.form-options :as fo]
[com.fulcrologic.rad.attributes :refer [defattr]]
[com.fulcrologic.rad.attributes-options :as ao]))
(defattr id :line-item/id :uuid
{ao/identity? true
ao/schema :production})
(defattr item :line-item/item :ref
{ao/target :item/id
ao/required? true
ao/cardinality :one
ao/identities #{:line-item/id}
ao/schema :production})
(defattr quantity :line-item/quantity :int
{ao/required? true
ao/identities #{:line-item/id}
ao/schema :production})
...note the :line-item/item reference.
It is a to-one that targets entities that have an :item/id.
There is no Datomic marker indicating that it is a component, so we’ve already inferred that the line item doesn’t own it.
But it might also be possible that the line item could be allowed to create new ones.
We just don’t know for sure unless we provide more context.
In RAD we do that at the form layer:
(form/defsc-form LineItemForm [this props]
{fo/id line-item/id
fo/attributes [line-item/item line-item/quantity]
;; Picker-related rendering
fo/field-styles {:line-item/item :pick-one}
fo/field-options {:line-item/item {::picker-options/query-key :item/all-items
::picker-options/query-component item-forms/ItemForm
::picker-options/options-xform (fn [normalized-result raw-response]
(mapv
(fn [{:item/keys [id name price]}]
{:text (str name " - " (math/numeric->currency-str price)) :value [:item/id id]})
(sort-by :item/name raw-response)))
::picker-options/cache-time-ms 60000}}})Here we’ve generated a normal form.
We’ve included the line-item/item attribute, and since that is a ref we must normally include subform configuration; however, we do not intend to render a subform.
We can use fo/field-styles
to indicate to RAD that a reference attribute will be rendered as a field.
In this case the :pick-one field type will look in field-options for additional information.
This field type, of course, could also just be set as
fo/field-style on the attribute itself.
The fo/field-options map should contain an entry for each :pick-one field style.
The options are:
::picker-options/query-key-
A top-level EDN query key that can return the entities you want to choose from.
::picker-options/cache-key-
(optional) A key under which to cache the options. If not supplied this assumes query key.
::picker-options/query-component-
(optional) A UI component that can be used for the subquery. This allows the picker options to be normalized into your normal database. If not supplied then the options will stored purely in the options cache.
::picker-options/options-xform-
a
(fn [normalized-result raw-result] picker-options). This function, if supplied, is given both the raw and normalized result. It must return a vector of{:text "" :value v}that will be used as the picker’s options. ::picker-options/cache-time-ms-
How long, in ms, should the options be cached at the cache key? Defaults to 100ms.
At this point you can use the LineItemForm and it will allow you to pick from the existing items in your database as long as you have a resolver.
Something like this on the server (assuming you installed the attribute to resolver generator in your parser) would fit the bill:
(defattr all-items :item/all-items :ref
{::attr/target :item/id
::pc/output [{:item/all-items [:item/id]}]
::pc/resolve (fn [{:keys [query-params] :as env} _]
#?(:clj
{:item/all-items (queries/get-all-items env query-params)}))})6.7.4. To-Many Relationships, Owned by Parent
The next case we’ll consider is the case where a form has a to-many relationship, and the items referred to are created (and owned) by that parent form. This case uses a normal form for the to-many items, and is pretty simple to configure. Say you have accounts, and each account can have multiple addresses (the addresses are not globally normalized but instead just owned by the account, since they are hard to globally normalize).
The addresses attribute looks like you’d expect:
(ns com.example.model.account ...)
(defattr addresses :account/addresses :ref
{::attr/target :address/id
::attr/cardinality :many
:com.fulcrologic.rad.database-adapters.datomic/schema :production
:com.fulcrologic.rad.database-adapters.datomic/entity-ids #{:account/id}})and the UI for an AddressForm might look like this:
(form/defsc-form AddressForm [this props]
{fo/id address/id
fo/attributes [address/street address/city address/state address/zip]
fo/cancel-route ["landing-page"]
fo/route-prefix "address"})The AccountForm would then simply use that AddressForm in a subform definition like so:
(form/defsc-form AccountForm [this props]
{fo/id acct/id
fo/attributes [acct/name acct/addresses]
fo/cancel-route ["landing-page"]
fo/route-prefix "account"
fo/subforms {:account/addresses {fo/ui AddressForm
fo/can-delete-row? (fn [parent item] (< 1 (count (:account/addresses parent))))
fo/can-add-row? (fn [parent] (< (count (:account/addresses parent)) 2))}}})Here the subform information for the :account/addresses field indicates:
-
fo/ui- The UI component to use for editing the target(s). -
fo/can-delete-row?- A lambda that receives the current parent (account) props and the a referred item. If it returns true then that item should show a delete button. -
fo/can-add-row?- A lambda that receives the current parent (account). If it returns true then the UI should include some kind of add control for adding a new row (address). You can also return:append(default) or:prependif you’d like the newly added item to appear first or last.
So our form shown above does not allow the user to delete the address if it is the only one, and prevents them from adding more than 2.
6.7.5. To-Many, Selected From Pre-existing
|
Note
|
This use-case is not yet implemented. |
6.8. Dynamic Forms
There are currently 3 kinds of dynamism supported by RAD:
-
The ability for a field to be a completely computed bit of UI based on the current form, with no stored state.
-
The ability to derive one or more stored fields, spreadsheet-style, where the values are computed from user-input fields, where the results of the computation are stored in the model.
-
The ability to hook into the UI state machine of the form in order to drive dependent field changes and also drive I/O for things like cascading dropdowns and dynamically loading information of interest to the user about the form in progress (username already in use, current list price of an item, etc.).
6.8.1. Purely Computed UI Fields
A purely computational (display-only) attribute is simple enough to declare:
(defattr subtotal :line-item/subtotal :decimal
{::attr/computed-value (fn [{::form/keys [props] :as form-env} attr]
(let [{:line-item/keys [quantity quoted-price]} props]
(math/round (math/* quantity quoted-price) 2)))})Such a field will show as a read-only field (formatted according to the field style you select). The function is supplied with the form rendering env (which includes the current form props) and the attribute definition of the field that is changing. The return value will be the displayed value, and must match the declared type of the field.
These attributes will never appear in Fulcro state. They are pure UI artifacts, and recompute their value when the form renders.
You actually have access to the entire set of props in the form, but you should note that other computed fields are not in the data model. So if you have data dependencies across computed fields you’ll end up re-computing intermediate results.
6.8.2. Derived, Stored Fields
Derived fields are attributes that are meant to actually appear in Fulcro state, and can also (optionally) participate in Form I/O (i.e. be saved to your server database). Derived fields are meant to be very easy to reason over in a full-form sense, and are meant to be an easy way to manage interdependencies of calculated data.
Each form can set up a derived field calculation by adding a :derive-fields trigger to the form:
(defn add-subtotal* [{:line-item/keys [quantity quoted-price] :as item}]
(assoc item :line-item/subtotal (math/* quantity quoted-price)))
(form/defsc-form LineItemForm [this props]
{fo/id line-item/id
fo/attributes [line-item/item line-item/quantity line-item/quoted-price line-item/subtotal]
fo/triggers {:derive-fields (fn [new-form-tree] (add-subtotal* new-form-tree))}A derive-fields trigger is a referentially-transparent function that will receive the tree of denormalized form props for the form, and must return an optionally-updated version of that same tree.
Since it is a tree it is very easy to reason over, even when there is nested data that is to be changed.
If a master form and child form both have derive-fields triggers, then the behavior is well-defined:
-
An attribute change will always trigger the
:derive-fieldson the form where the attribute lives, if defined.-
The master form’s
:derive-fieldswill be triggered on each attribute change, and is guaranteed to run after the nested one.
-
-
A row add/delete will always trigger the master form’s
:derive-fields, if defined.
Note: Deeply nested forms do not run :derive-fields for forms between the master and the form on which the attribute changed.
Assume you have an invoice that contains line item’s that use the above form.
The :invoice/total is clearly a sum of the line item’s subtotals.
Therefore the invoice (which in this example is the master form) would look like this:
(defn sum-subtotals* [{:invoice/keys [line-items] :as invoice}]
(assoc invoice :invoice/total
(reduce
(fn [t {:line-item/keys [subtotal]}]
(math/+ t subtotal))
(math/zero)
line-items)))
(form/defsc-form InvoiceForm [this props]
{fo/id invoice/id
fo/attributes [invoice/customer invoice/date invoice/line-items invoice/total]
...
fo/subforms {:invoice/line-items {fo/ui LineItemForm}}
fo/triggers {:derive-fields (fn [new-form-tree] (sum-subtotals* new-form-tree))}
...})Now an attribute change of the item on a line item will first trigger the derived field update of subtotal on the LineItemForm, and then the master form’s derived field update will fix the total.
|
Warning
|
It may be tempting to use this mechanism to invent values that are unrelated to the form and put them into the state.
This is legal, but placing data in Fulcro’s state database does not guarantee they will show up in rendered props.
Fulcro pulls props from the database according to the component’s query, and forms only place the listed attributes in that query.
This means if you put an arbitrary key into the state of your form it will not show up unless you also add it to the fo/query-inclusion of that form.
Of course, auto-rendering will also know nothing about it unless it is listed as some kind of attribute.
You can define a no-op attribute (at attribute with nothing more than a type) as a way to render such on-the-fly values, but you should also be careful about how such props might interact with form loads and saves.
|
6.8.3. Form Change and I/O
The next dynamic support feature is the :on-change trigger.
This trigger happens due to a user-driven change of an attribute on the form.
Such triggers do not cascade.
This trigger is ultimately driven by the form/input-changed! function (which is used by all pre-built form fields to indicate changes).
The :on-change trigger is implemented as a hook into the Fulcro UI State Machine that is controlling the form, and must be coded using that API.
The Fulcro Developer’s Guide covers the full API in detail.
The most important aspect of this API is that it is side-effect free.
You are passed an immutable UISM environment, and thread any number of uism functions together against that env to evolve it into a new desired env, which you return.
This is then processed by the state machine system to cause the desired effects.
Code for UISM handlers generally looks something like this:
(fn [env]
(-> env
(uism/apply-action ...)
(some-helper-you-wrote)
(cond->
condition? (optional-thing))))|
Important
|
Handlers must either return an updated env or nil (which means "do nothing").
Returning anything else is an error.
There are checks in the internals that try to detect if you make a mistake and will show an error in the console.
|
In RAD Forms, the on-change handler is passed the UI State machine environment, along with some other convenient values: the ident of the form being modified, the keyword name of the attribute that changed, along with that attribute’s old and new value.
In our Line Item example we allow a user to pick an item from inventory, which has a pre-defined price.
Users of the invoice form might need to override this price to give a discount or correct an error in pricing.
Therefore, each line item will have a :line-item/quoted-price.
Every time the user selects an item to sell on a line item we want push the inventory price of the item into the item’s quoted-price.
We cannot do this with the derived-fields trigger because that trigger does not know what changed, and we only want to push the item price into quoted price on item change (not every time the form changes).
This is a prime use-case for an :on-change, and can be coded like this:
(form/defsc-form LineItemForm [this props]
{fo/id line-item/id
fo/attributes [line-item/item line-item/quantity line-item/quoted-price line-item/subtotal]
fo/triggers {:on-change (fn [{::uism/keys [state-map] :as uism-env} form-ident k old-value new-value]
(case k
;; In this example items are normalized, so `new-value` will be the ident
;; of an item in the database, which in turn has an :item/price field.
:line-item/item
(let [item-price (get-in state-map (conj new-value :item/price))
target-path (conj form-ident :line-item/quoted-price)]
;; apply-action allows you to update the Fulcro state database. It works
;; as-if you were doing an `update` on `state-map`.
(uism/apply-action uism-env assoc-in target-path item-price))The :on-change triggers always precede :derive-fields triggers, so that the global derivation can depend upon values pushed from one field to another.
6.9. Extended Data Type Support
|
Note
|
The goals of RAD are stated in this section, but only some of the type support is fully-implemented and stable. |
Fulcro uses EDN for its data representation, and supports all of the data types that transit supports out of the box, at least at the storage/transmission layer. Some of these type, however, have further complications. The two most pressing are time and precise representation of numbers, but others certainly exist.
RAD includes support for helping deal with these problems.
6.9.1. Dates and Time
The standard way to represent time is as an offset from the epoch in milliseconds.
This is the de-facto representation in the JVM, JS VM, transit, and many storage systems.
As such, it is the standard for the instant type in RAD.
User interfaces also need to localize the date and time to either the user or context of the form/report in question.
There are standard implementations of localization for js and the JVM, but since we’re using CLJC already it makes the most sense to us to just use cljc.java-time, which is a library that unifies the API of the standard JVM Time API.
This makes it much simpler to write localized support for dates and times in CLJC files.
To date we are avoiding the
tick library because it is not yet as mature, and is overkill for RAD itself (though you can certainly use it in your applications).
At the time of this writing RAD supports only the storage of instants (Java/js Date objects), and requires that you select a time-zone for the context of your processing.
The concept of LocalDate and LocalTime can easily be added, but for now the style of the UI control determines what the user interaction looks like.
This means that when you ask the user for a date, it will be stored as a specific time on a specific date in a specific time zone.
For example, an Invoice might require a date (which could be in the context of the receiver or the shipper). The "ideal" solution is to do time zone offset calculations, but a reasonable approximation might be to just store the date relative to noon (or midnight, etc.) in the time zone of the user. This can be supported with a simple UI control style:
(defattr date :invoice/date :instant
{fo/field-style :date-at-noon
...})Of course you can provide your own style definitions for controls, and you can also choose to store things like "Local Dates" as simple strings (or a LocalDate type if your storage engine has one) in your database if you wish to completely avoid the time zone complication. At that point you could also add Transit support for local dates to your network layer, and keep those items in the correct type in a full-stack manner.
Setting the Time Zone
|
Note
|
At the time of this writing the date-time namespace requires the 10-year time zone range from Joda Timezone. This will most likely be removed from RAD and changed to a requirement for your application, since you can then select the time zone file that best meets your application’s size and functionality requirements. |
In order to use date/time support in RAD you must set the time zone so that RAD knows how to adjust local date and times into proper UTC offsets. Setting the time zone can be done in a couple of ways, depending on the desired usage context.
It is important to note that the server (CLJ) side will typically only deal with already-adjusted UTC offsets. Thus, the code on the server mostly just read/saves the values without having to do anything else. A UTC offset is unambiguous, just not human friendly. The user interface is where RAD does this human interfacing.
In CLJS you are commonly dealing with a lot of (potentially behind-the-scenes) asynchronous logic. Fulcro makes most of the model appear synchronous, but the reality is quite different in implementation. Fortunately, most UI contexts are aimed at the user, and that user usually has a particular time zone that is of interest to them. Thus, the time zone on the client side can usually be set to some reasonable default on client startup (perhaps based on the browser’s known locale) and further refined when a user logs in (via a preference that you allow them to set).
Thus, CLJS code will typically call (datetime/set-timezone! "America/Los_Angeles"), where the string argument is one of the standard time zone names.
The are available from (cljc.java-time.zone-id/get-available-zone-ids).
;; Typical client initialization
(defn init []
(log/info "Starting App")
;; set some kind of default tz until they log in
(datetime/set-timezone! "America/Los_Angeles")
(form/install-ui-controls! app sui/all-controls)
(attr/register-attributes! model/all-attributes)
(app/mount! app Root "app"))|
Note
|
The above action is all that is needed to get most of RAD working. The remainder of the date/time support is used internally, and can also be convenient for your own logic as your requirements grow. |
It is also possible that you may wish to temporarily override the currently-selected time zone for some context. This is true for CLJS (though you will have to be careful to manage async behavior there), and is central to CLJ operation.
In CLJ your normal reads and mutations will be dealing with UTC offsets that have already been properly adjusted in the client. There are times when you’ll want to deal with timezone-centric data (in reports and calculations, for example, you might need to choose a range from the user’s perspective).
Most of the functions in the date-time namespace allow you to pass the zone name (string version of zone id) as an optional parameter, but the default value comes from the dynamic var datetime/current-timezone as a ZoneID instance, not a string.
So, you can get a thread-local binding for this with the standard Clojure:
(binding [datetime/*current-timezone* (zone-id/of "America/New_York")]
...)The macro with-timezone makes this a less noisy:
(with-timezone "America/New_York"
...)See the doc strings on the functions in com.fulcrologic.rad.type-support.date-time namespace for more details on what support currently exists.
This namespace will grow as needs arise, but many of the things you might need are easily doable using cljc.java-time (already included) and tick (an easy add-on dependency) as long as you center your logic around the *current-timezone when appropriate.
6.9.2. Arbitrary Precision Math and Storage
EDN and Transit already support the concept of representing and transmitting arbitrary precision numbers.
CLJ uses the built-in BigDecimal and BigInteger JVM support for runtime implementation and seamless math operation.
Unfortunately, CLJS accepts the notation for these, but uses only JS numbers as the actual runtime representation.
This means that logic written in CLJC cannot be trusted to do math.
In RAD we desire the representation on the client to be closer to what you’d have on the server. Most applications have large amounts of their logic on the client these days, so it makes no sense, in our opinion, to simply pass numbers around as unmarked strings and expect things to work well.
Therefore RAD has full-stack support for BigDecimal (BigInteger may be added, as needed).
Not just in type, but in
operation.
The com.fulcrologic.rad.type-support.decimal namespace includes constructors that work the same in CLJ and CLJS (you would avoid using suffixes like M, since the CLJS code would map that to Number), and many of the common mathematical operations you’d need to implement your calculations in CLJS (PRs encouraged for adding ones you find missing).
Working with these looks like the following:
(ns example
(:require
[com.fulcrologic.rad.type-support.decimal :as math]))
;; Works the same in CLJ and CLJS.
(-> (math/numeric 41)
(math/div 3) ; division defaults to 20 digits of precision, can be set
(math/+ 35))TODO: Need math/with-precision instead of just an arg to div.
Of course you can use clojure exclusions and refer to get rid of the math prefix, but since it is common to need normal math for other UI operations we do not recommend it.
Fields that are declared to be arbitrary precision numerics will automatically live in your Fulcro database as this math/numeric type (which is CLJ is BigDecimal, and in CLJS is a transit-tagged BigDecimal (a wrapped string)).
The JS implementation is currently provided by big.js (which you must add to your package.json).
Most of the functions will auto-coerce values, and you can also ask for a particular calculation to be done with primitive math (which will run much faster but incur inaccuracies).
You can ask for imprecise (but fast) math operation (only really affects CLJS) with:
(time (reduce math/+ 0 (range 0 10000)))
"Elapsed time: 251.240947 msecs"
=> 49995000M
(time (math/with-primitive-ops (reduce math/+ 0 (range 0 10000))))
"Elapsed time: 1.9688 msecs"
=> 49995000which will run much faster, but you are responsible for knowing when that is safe. This allows you to compose functions that were written for accuracy into new routines where the accuracy isn’t necessary.
|
Note
|
with-primitive-ops coerces the value down to a js/Number (or JVM double), and then calls Clojure’s pre-defined +, etc.
This primarily exists for cases where you’re doing something in a UI that must render quickly, but that uses data in this numeric format.
For example a dynamically-adjusting report where you know the standard math to be accurate enough for transient purposes.
|
|
Warning
|
with-primitive-ops returns the value of the last statement in the body.
If that is a numeric value then it will be a primitive numeric value (since you’re using primitives).
You must coerce it back using math/numeric
if you need the arbitrary precision data type for storage.
|
6.10. File Upload/Download
RAD Forms can support file uploads, along with download/preview of previously-uploaded files.
-
Attribute(s) that represent the details you want to store in a database to track the file.
-
An attribute that represents the file itself and can be used to generate a URL of the file. EQL resolvers send transit, so it is not possible to query for the file content via a Pathom resolver. Instead you must supply a resolver that can, given the current parsing context, resolve the URL of the file’s content for download by the UI.
File transfer support leverages Fulcro’s normal file upload mechanisms for upload and the normal HTTP GET mechanisms for download. The file is sent as a separate upload mutation during form interaction, and upload progress blocks exiting the form until the upload is complete (the form field itself for the upload relies on correctly-installed validation for this to function).
The file itself is stored on the server as a temporary file until such time as you save the form itself (though you can also configure the form to auto-save when upload is complete). When you save the form you must use the save middleware to move the temporary file to a permanent store of your choice and then augment the incoming form data to include the details about the file that will allow your file detail resolver to emit a proper URL for getting the file.
6.10.1. General Operation
RAD’s built-in support for BLOBs requires that you define a place in one of your database stores to keep a fingerprint for the file.
RAD uses SHA256 to generate such a fingerprint for files (much like git).
The fingerprint is treated as the key to the binary data in the store where you place the bytes of the file.
This allows you to do things like duplicate detection, and can help in situations where many users might upload the same content (your regular database would track who has access to what files, but they’d be deduped).
Forms need to know where to upload the file content. Fulcro requires an HTTP remote for file upload, since it sends the file through a normal HTTP POST. If your primary remote is HTTP, then your client needs nothing more than the standard file upload middleware added to the request middleware on the client, and file upload middleware on the server that can receive the files.
The general operation of file support in RAD is shown in the diagram below. As the user edits a form with a file upload control they can choose local files. RAD generates a SHA for each file, and begins uploading it immediately (tracking progress and disabling save/navigation until the upload is complete). The SHA is stored in the form field (and is what you’ll have in your database as a key to find the binary data later).
The file is saved in a temporary store (usually a temporary disk file).
Once the file(s) is/are uploaded then the form can be saved. When the user does this the SHA comes across in the save delta and middleware on the server detects it. This triggers the content (named as the SHA) to be moved from the temporary store to a permanent store. Of course the SHA is saved in the entity/document/row of your database (along with other facets of the file you’ve set up, such as user-specified filename).
The permanent store is configured to understand how to provide a URL (properly protected) to serve the file content, allowing the form, reports, and other features of your application to provide the file content on demand.
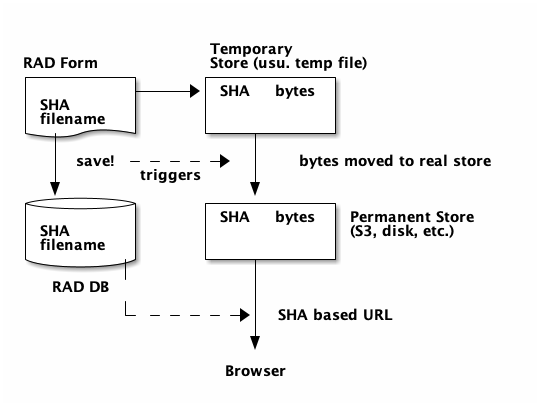
Since RAD controls the rendering of the file in forms it needs to know how to group together attributes of a file so that it knows which is the filename, which is the URL, etc.
RAD does this by keyword "narrowing", our term for the process of using the current attribute’s full name as a namespace (by replacing / with .) and adding a new name.
Thus, if you define a blob attribute :file/sha then the filename attribute will be assumed to be :file.sha/filename
by the auto-generated UI in RAD.
You can use rewrite middleware and custom resolvers if you want to save it under a different name in your real database, but it is easiest in greenfield projects just to adopt the convention.
6.10.2. Defining Binary Large Object (BLOB) attributes
There is a special macro in the blob namespace defblobattr that should be used to declare a BLOB-tracking attribute in your database.
It ensures that you supply sufficient information about the attribute for uploads to work correctly.
A sample file entity (backed by Datomic) might be defined like this:
(ns com.example.model-rad.file
(:require
[com.fulcrologic.rad.attributes :refer [defattr]]
[com.fulcrologic.rad.attributes-options :as ao]
[com.fulcrologic.rad.blob :as blob]))
(defattr id :file/id :uuid
{ao/identity? true
ao/schema :production})
;; :files is the name of the BLOB store, and :remote is the Fulcro remote that uploads go to.
(blob/defblobattr sha :file/sha :files :remote
{ao/identities #{:file/id}
ao/schema :production})
(defattr filename :file.sha/filename :string
{ao/schema :production
ao/identities #{:file/id}})
(defattr uploaded-on :file/uploaded-on :instant
{ao/schema :production
ao/identities #{:file/id}})
(def attributes [id sha filename uploaded-on])The defblobattr requires you supply a keyword for the attribute, the name of the permanent store for the content (:files in this example), and the name of the Fulcro client remote (:remote in this example) that can transmit the file bytes.
6.10.3. Setting up the Client
You must configure an HTTP remote on the client that includes the Fulcro file upload middleware. This is covered in the Fulcro Developer’s guide, but looks like this:
(def request-middleware
(->
(net/wrap-fulcro-request)
(file-upload/wrap-file-upload)))
(defonce app (app/fulcro-app {:remotes {:remote (http/fulcro-http-remote {:url "/api"
:request-middleware request-middleware})}6.10.4. Setting up the Server
The server setup needs several things.
First, you need to define a temporary and permanent store.
RAD requires a store to implement the
com.fulcrologic.rad.blob-storage/Storage protocol.
The temporary store can just use the pre-supplied transient store, which uses (and tries to garbage collect) temporary disk files on your server’s disk.
RAD’s transient store requires connection stickiness so that the eventual form save will go to the save server as the temporary store.
If that is not possible in your deployment then you may wish to use your permanent store as the temporary store and just plan on cleaning up stray files at some future time.
Once you’ve defined you two stores you can add the blob support to your Ring middleware and as a plugin to your Pathom parser.
There are two parts to the Ring middleware, and one is optional and is only necessary if you plan to serve the BLOB URLs from your server.
(ns com.example.components.blob-store
(:require
[com.fulcrologic.rad.blob-storage :as storage]
[mount.core :refer [defstate]]))
(defstate temporary-blob-store
:start
(storage/transient-blob-store "" 1))
(defstate file-blob-store
:start
(storage/transient-blob-store "/files" 10000))
;; -------------------------------------------
(ns com.example.components.ring-middleware
(:require
[com.example.components.blob-store :as bs]
[com.example.components.config :as config]
[com.fulcrologic.fulcro.networking.file-upload :as file-upload]
[com.fulcrologic.fulcro.server.api-middleware :as server]
[com.fulcrologic.rad.blob :as blob]
[mount.core :refer [defstate]]
[ring.middleware.defaults :refer [wrap-defaults]]
[ring.util.response :as resp]
[taoensso.timbre :as log]))
(defstate middleware
:start
(let [defaults-config (:ring.middleware/defaults-config config/config)]
(-> not-found-handler
(wrap-api "/api")
;; Fulcro support for integrated file uploads
(file-upload/wrap-mutation-file-uploads {})
;; RAD integration for *serving* files FROM RAD blob store (at /files URI)
(blob/wrap-blob-service "/files" bs/file-blob-store)
(server/wrap-transit-params {})
(server/wrap-transit-response {})
(wrap-html-routes)
(wrap-defaults defaults-config))))You must also install plugins and resolvers to your parser:
(ns com.example.components.parser
(:require
[com.example.components.blob-store :as bs]
[com.example.components.database :refer [datomic-connections]]
[com.example.model-rad.attributes :refer [all-attributes]]
[com.fulcrologic.rad.blob :as blob]
[com.fulcrologic.rad.pathom :as pathom]
[mount.core :refer [defstate]]))
...
(defstate parser
:start
(pathom/new-parser config
[...
;; Enables binary object upload integration with RAD
(blob/pathom-plugin bs/temporary-blob-store {:files bs/file-blob-store})
...]
[resolvers
...
(blob/resolvers all-attributes)]))The blob plugin mainly puts the temporary store and permanent store(s) into the parsing env so that they are available when built-in blob-related reads/mutations are called.
The BLOB resolvers use the keyword narrowing of your SHA attribute and the env to provide values that can be derived from the SHA and the store (i.e. :file.sha/url).
6.10.5. File Arity
A file is tracked by a SHA.
Therefore you can support a fixed number of files simply be defining more than one SHA-based attribute on an entity/document/row of your database.
You can also support general to-many support for files simply by creating a ref attribute that refers to a entity/row/document that has a file SHA on it.
6.10.6. Rendering File Upload Controls
Each set of UI rendering controls will have one or more ways of rendering and dealing with file uploads. See the documentation of the rendering system you’ve chosen to see what comes with it. Of course, you can always render exactly what you want simply by following Fulcro and RAD documentation.
You can use the blob/upload-file! function to submit a file for upload processing.
The system will automatically add a status and progress attribute to the in-memory entity in your Fulcro client db.
Assuming this represents the UI instance that has the file upload field, the call to start an upload is:
(blob/upload-file! this blob-attribute js-file {:file-ident (comp/get-ident this)})If your blob-attribute had the keyword :file/sha then you’d see a :file.sha/progress and :file.sha/status appear on that entity and update as the file upload progresses.
Saving the form should then automatically move the file content (named by SHA) from temporary to permanent storage.
6.10.7. Downloading Files
The Storage protocol defines a blob-url method.
This method is under the control of the implementation, of course, and may do nothing more than return the SHA you hand it.
You are really responsible for hooking RAD up to a binary store that works for your deployment.
The built-in support assumes that you’ll serve the file content through your server for access control.
The provided middleware simply asks the Storage protocol for a stream of the file’s bytes, and serves them at a URI on your server.
Thus, you might configure your permanent blob store to return the URL /files/<SHA>, and then configure your Ring middleware to provide the correct file when asked for /files/<SHA>.
This is what the middleware configuration shown earlier will do.
7. Advancing Your Forms: Taking Control of Form Implementation
RAD has a core design principle that you must be able to take control of any aspect of system with minimal trouble. The default features are meant to be useful for rapidly developing your idea, but it is inevitable that any system that does this much work for you will fail to meet your needs in any number of ways.
This chapter covers details of how to augment and modify the RAD Form system.
7.1. Form System Architecture
The UI plugin is probably the first and most obvious element that you’ll want control over. RAD is built to give you escape hatches for every element of rendering.
The first thing to realize is that a defsc-form is just a Fulcro component that has a bunch of data in the component options that the various plugins use to do their work.
However, forms can be nested, and that creates a bit of additional complexity.
The overall architecture of a RAD form is roughly like this:
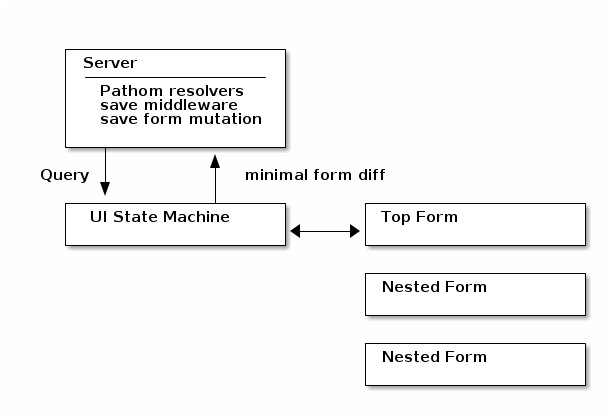
7.2. Server
The server is the easy part.
A single form/save-form mutation is the source of all writes (except delete) and resolvers are the source of form data for reads.
The form data is sent via Fulcro’s form-state minimal diff, which makes implementing generic save logic very easy (the Datomic one is just a couple hundred lines of code).
Security and such can be added to the form and Pathom middleware.
7.2.1. Save Operation
The core code element on the server for controlling saves is the save middleware. All saves flow through this middleware as a minimal diff, which looks like this:
{ident {attr-key {:before val :after val}
...}
...}It is very similar to the Fulcro database format, with the only difference being that every value has a before/after version. This can be used to implement optimistic concurrent transactions, and is also necessary for determining the correct database operation when the attribute is to-many.
Note that many adapters don’t use the :before for anything except resolving to-many operations.
For example:
{[:person/id 1] {:person/addresses {:before [[:address/id 3]] :after []}}}means "remove address 3 from person 1’s addresses."
{[:person/id 1] {:person/addresses {:before [[:address/id 3]] :after [[:address/id 4]]}}}means "replace address 3 with address 4 in person 1’s addresses." The Datomic adapter, for example, can use this for a to-many diff where the existing full set of addresses does not have to be in the before/after. Only the diff itself is used for the operation.
This makes it very easy to implement custom mutations in terms of form’s save mutation!
In fact, there is a form/save-form* public function that is meant to be used exactly this way.
This means you can write all of your server mutations in a database agnostic fashion, with centralized middleware that manages the custom aspects of your write architecture:
(pc/defmutation disable-account [env {:account/keys [id]}]
{::pc/output [:account/id]}
(form/save-form* env {::form/id id
::form/master-key :account/id
::form/delta {[:account/id id] {:account/enabled? {:after false}}}}))Note that since the database plugin uses Pathom plugins to augment the env there’s no need to couple the mutation to any database logic (assuming your parameters contain enough info and no query is needed). Also note that attributes can span schema, meaning that such a save could cross more than one database, and the middleware can just "handle" it!
7.2.2. Save Middleware
Now that you know what data is flowing to the server for a save, it is pretty easy to understand how save middleware works: It’s a middleware pattern where the pathom-env (containing the form info) is threaded through.
Here’s sample middleware that let’s you add in a function to arbitrarily rewrite an incoming diff (this one in supplied in RAD’s save-middleware ns):
(defn wrap-rewrite-delta
"Save middleware that adds a step in the middleware that can rewrite the incoming delta of a save.
The rewrite is allowed to do anything at all to the delta: add extra entities, create relations, augment
entities, or even clear the delta to an empty map so nothing will be saved.
The `rewrite-fn` should be a `(fn [pathom-env delta] updated-delta)`. You *can* return nil to indicate no
rewrite is needed, but any other return will be used as the new thing to save (instead of what was sent).
The `delta` has the format of a normalized Fulcro form save:
```
{[:account/id 19] {:account/age {:before 42 :after 43}
:account/items {:before [] :after [[:item/id 1]]}}
[:item/id 1] {:item/value {:before 22M :after 19.53M}}}
```
"
[handler rewrite-fn]
(fn [env]
(let [old-delta (get-in env [::form/params ::form/delta])
new-delta (or (rewrite-fn env old-delta) old-delta)]
(handler (assoc-in env [::form/params ::form/delta] new-delta)))))As long as the RAD model understands the attributes you’re placing in the diff, then a database plugin should be able to write them. So, it is perfectly valid to expand what is in the diff.
Here are some ideas for middleware that we’ve found useful:
-
Pull each entity of the diff from the database, apply the diff to them, then run Clojure specs on them to ensure the save won’t violate data specs.
-
Add entity ownership to new entities (which will have a Fulcro tempid in their ident).
-
Augment the diff with session-relation information (e.g. for auditing)
-
Check the ownership on every entity (by ident) in the database as a security measure for writing to them.
-
Make sure the diff doesn’t contain other security violations (such as changing the ownership of an entity).
Autojoin Middleware
In RAD 1.6.5 another middleware was introduced: autojoin. This middleware is used in the case where you want to create or edit an entity that MUST have a parent, but you simply want to specify the parent on form start instead of having to make the parent form with subforms in order to work with the children.
See the com.fulcrologic.rad.middleware.autojoin namespace docstring for details and an example.
7.2.3. Delete Middleware
Delete middleware is similar to save middleware, but quite a bit simpler. See, for example, the Datomic RAD plugin for the basic implementation of implementing delete middleware.
7.3. UI
The UI is a bit more complex in structure.
There is a single UISM that is started with the top-level form. Subforms are controlled by this same top-level machine. The real communication layer is the standard Fulcro state database (query) and mutations (UISM trigger), but for simplicity we show the communcation going through the UISM.
Each form has a query and ident that follows the exact rules of Fulcro, and the props in any form are exactly the content of that component’s query; however, every nested form (no matter the depth) must know its immediate parent, and also the master form (because the UISM is identified by that top-level form’s ident).
7.3.1. Rendering Environment
To facilitate this the top-level form and all nested forms leverage computed Fulcro props to pass additional information about the form set.
This information is referred to as the rendering-env, and can include:
{::form/master-form react-instance
::form/form-instance this
::form/parent parent-react-instance
::form/parent-relation keyword-navigated-to-child-form}Many of the helper functions in the RAD form namespace will accept this as a potential argument, and some of them may require you to construct one (there’s a rendering-env helper for this).
7.3.2. Form Rendering via Multimethods (RAD V1.6+, 1.6.0-SNAPSHOT)
The rendering system in RAD prefers to use maps to define plugins in order to avoid the use of multimethods. This choice was made for several reasons:
-
Multimethods have to be
requiredto work, and once required cannot be dead code eliminated. If you’re not using some subset of controls when using plain maps, you can remove them from the maps and they will dead code eliminate. -
Multimethods in stack traces are harder to follow, so debugging them can be a hassle.
-
Hard to figure out which
defmethodis being called for a particular bit of output, or even which file it is in. This can be problematic in large projects.
However, after experiencing the map-based mechanism, it suffers from similar issues:
-
Still hard to trace the rendering to figure out what is generating output, though having a single map you can look at does make it a little easier to discover things, and navigate to them via IDE jump.
-
Dead code elimination tuning is probably not going to save you much, given that these renderers are few in number, and you can avoid requiring things you don’t want in the first place.
So, in 1.6.0 it was decided that adding multimethods to the system would give extra flexibility and utility, and if the defaults just called the existing plugins, would neither break anything or really even add overhead if you don’t want to use them.
The result seems pretty positive: It is much easier to use the multimethods to customize how things render, and the use of a predefined hierarchy (for multimethods) means you can add additional multimethods to customize how rendering should work in general. The new support defines a number of multimethods, but you can actually choose not to use some of them at all.
This section of the manual will refer to the new namespaces:
[com.fulcrologic.rad.form-render :as fr]
[com.fulcrologic.rad.form-render-options :as fro]The RAD form namespace has the following primary entry points:
-
(form/render-layout this props)- This is the function that the defsc-form macro automatically places in the body of a form if you don’t supply one. As of V1.6 this callscom.fulcrologic.rad.form-render/render-form, whose:defaultdispatch does legacy work to be bw compatible. You can redefine this dispatch to an alternative of your choosing. -
(form/render-field renv attr)- This function can be called to render a field forattr(complete with labels, etc.). The default implementation of this will do a legacy search of the control map installed on the app, but as of V1.6 it calls the multimethodcom.fulcrologic.rad.form-render/render-field, whose:defaultdispatch does the old behavior. You can redefine that dispatch to change the default.
Technically, redefining the default dispatch (via defmethod) for those two will let you completely override how forms are rendered (just make sure you do that after you require the form ns).
Dispatch Hierarchy
The multimethods in form-render all use the form-render/render-hierarchy (See Clojure Multimethods) and most of them dispatch on a vector (e.g. [type style] or [attribute-keyword style]).
You can use the hierarchy to set up fall-through.
Unfortunately hierarchies differ slightly in CLJ vs CLJS.
In CLJ the render-hierarchy is a plain var, but in CLJS it is an atom so that the hierarchy can be modified at runtime.
This makes the usage of derive
and isa? a little confusing so the form-render ns includes a CLJC version called derive! and and isa? that will work without having to think about it.
For example, say you want to use the same rendering code to render all kinds of numeric fields.
The supplied fr/render-field dispatches on [data-type style] (where style is from form field-styles, attribute field-style, or attribute style).
Let’s say you sometimes want to have a normal input field, and sometimes you want a slider. You could indicate the relation of the numeric data types, and define two styles of field renderers:
(fr/derive! :int :number)
(fr/derive! :long :number)
(fr/derive! :double :number)
(fr/derive! :decimal :number)
(defmethod fr/render-field [:number :default] [renv attr]
(dom/div ...))
(defmethod fr/render-field [:number :slider] [renv attr]
(dom/div ...))Another example is for relating types.
Perhaps you have two different kinds of entities (let’s say entities identified by :car/id and :vehicle/id) in your database that are very closely related and you can see how one render function could be used for rendering both kinds of forms.
The fr/render-form method dispatches on id-keyword and style.
So, you could use derive to indicate this fall-through:
(fr/derive! :car/id :vehicle/id)
(fr/derive! :truck/id :vehicle/id)
(fr/derive! :plane/id :vehicle/id)
(defmethod fr/render-form [:vehicle/id :default] [env id-attr]
(dom/div ...))If you’d like the system to start out considering :default to be the parent of all attribute keywords (so that the vector dispatch supports :default within the vector), then you can call the helper:
(fr/isa? :vehicle/id :default) ; => false
(fr/allow-defaults! model/all-attributes)
(fr/isa? :vehicle/id :default) ; => true
(defmethod fr/render-form [:default :inline] [env id-attr]
(dom/div ...))Predefined Methods
The multimethod rendering pre-defines:
-
(render-form renv id-attribute)- Intended to encapsulate the rendering of the entire form. Usually the definition of this would call the other multimethods likerender-headerandrender-fields, but that is completely up to you. The global default calls the map-based default for the UI plugin. -
(render-header renv attr)- Intended to render headers for things. This exists for your (optional) convenience, and your composition of this into your other calls will determine how it is used. -
(render-footer renv attr)- Intended to render footers for things. Comments about this are the same as for header. -
(render-fields renv id-attr)- Intended to act as the field layout. Optional and for your convenience. -
(render-field renv attr)- Renders a usable form field. Dispatches on[type style]. The default falls back to the UI plugin map.
but the mere existence of the multimethods does not mean they get called, since you have to write the
defmethod for each dispatch value you plan to use, and you choose what to call from where (do you want a header for the given element style?).
For example, when rendering a to-many ref as a table clearly the header is the top of the table that lists things like column names, and that must be rendered in the context of the form that has the to-many ref, not in the context of each row (which are themselves forms that could have headers/footers, but in this case probably won’t).
|
Important
|
ONLY render-form and render-field are used by default in order to maintain backward compatibility with the map-based rendering plugin.
The other methods are defined to establish possible useful patterns and are not used by base RAD.
|
|
Tip
|
If you enable dev-time source line attribution in the compiler options you can at least see where a DOM element came from in the source. See the Fulcro Developer’s Guide. |
Render Multimethod Dispatch
The dispatch rules for the predefined rendering multimethods looks a bit complex at first, but in general they are meant to allow the least typing for the common case in options.
The fro/style option is the fallback for pretty much everything.
There are other style keys (e.g.
fro/header-style) which are meant to override the general style of a form.
For example, if you chose to render a subform with a :table style, you probably also need the header, fields, and footer to know that as well.
So, it makes sense to use fro/style the fall-through.
For fields there are already existing options for styles (ao/style, fo/field-style, and fo/field-styles), so it makes sense to honor those in the new method dispatch.
The complete rules of dispatch are:
render-form-
The dispatch uses a vector of
[qualified-keyword style], where thestyleis derived as follows:-
The dispatch function will first look to see if it is rendering as a subform
-
if so will find the subform options on the
parentforparent-relationand look for the fro/style there.
-
-
If that fails, it will look for the
fro/styleon the form instance being rendered -
finally will look on the attribute.
-
Otherwise it will use a style of
:defaultNote that the attribute in question will be the entity ID attribute. In the case of render-header/footer/fields you write the calling code and can choose the attribute to pass in.
-
render-fields-
The
render-fieldsmethod dispatch is identical torender-form([id-key style]), and this method is always intended to be called in the context of the currently-rendering form-instance with an id-attribute. The only difference is that it will first try to findfro/fields-style, and then fall back tofro/style. render-header-
Dispatch on [attr-key style].
The style is derived as follows:
-
If
attris anao/identity?attribute-
dispatch identically to render-form, but looking for
fro/header-style(preferred) andfro/stylefallback.
-
-
If it is NOT an id attribute, then:
-
Look for
fro/header-styleon the current form’s subform options at the qualified key of attr -
Look for
fro/header-styleon the attr -
Look for
fro/styleon the current form’s subform options at the qualified key of attr -
Look for
fro/styleon the attrOtherwise style will be
:default
-
-
render-footer-
Same as render-header, but replace
fro/header-stylewithfro/footer-style. render-field-
Dispatches on
[field-data-type style]where style is derived as follows:-
Look for
fro/styleon the subform options. This is for the case of ref attributes where the field render (which might need to wrap a to-many collection) must know the context that the subform will be rendered in, and that should be preferred. -
Then look in form
fo/field-styles(map from k → field style) -
Then look for
fro/styleon the attribute -
Then look for
fo/field-styleon the attribute -
Then look for
ao/styleon the attribute -
Otherwise
:default.
-
Example Setup
Let’s say you want to use the semantic UI rendering plugin to get the table support and predefined field renderers, but you want to also better leverage the new multimethods. The forms will already have set up a default render-field that uses the SUI controls, so there is nothing to do there; however, the render-form defaults to calling into the old plugin.
Let’s also assume you have Tailwind CSS (e.g. class "mt-12").
The first thing is to make a function that can install the support under a well-known style key so we can opt into the new rendering (and let the SUI plugin take care of pre-existing code):
(ns com.example.ui.form-rendering
(:require
#?(:cljs [com.fulcrologic.fulcro.dom :as dom :refer [div]]
:clj [com.fulcrologic.fulcro.dom-server :as dom :refer [div]])
[com.fulcrologic.fulcro-i18n.i18n :refer [tr]]
[com.fulcrologic.fulcro.components :as comp]
[com.fulcrologic.fulcro.dom.html-entities :as ent]
[com.fulcrologic.rad.attributes :as attr]
[com.fulcrologic.rad.attributes-options :as ao]
[com.fulcrologic.rad.control :as control]
[com.fulcrologic.rad.form :as form]
[com.fulcrologic.rad.form-options :as fo]
[com.fulcrologic.rad.form-render :as fr]
[com.fulcrologic.rad.options-util :refer [?!]]
[com.fulcrologic.rad.rendering.semantic-ui.form :as rsf]
[com.fulcrologic.rad.semantic-ui-options :as suo]
[taoensso.timbre :as log]))
(defn install!
"Install multimethod rendering such that:
* All keywords in the RAD model will derive from :default.
"
[app attrs]
(fr/allow-defaults! attrs))Calling install! on startup will make it so that any RAD registered keywords will derive from :default.
The RAD rendering uses the multimethods for all rendering already, but installs :default handlers that call the
old code by default, so that fall-through will hit any plugin.
For our demo we will choose to use a style named :multimethod. I.e. forms that set fro/style :multimethod will use the new rendering.
Next, we should set up some defaults so that selecting multimethod as the style does something. We’ll leverage the plugin to provide those defaults, but split them out so we can customize them. Note that we have to supply a default for rendering :ref fields because once we’re using the multimethods there is no special handling of refs like there is in the standard SUI plugin, but we can dispatch to the code that is in the plugin.
;; Default to render forms that choose fro/style :multimethod
(defmethod fr/render-form [:default :multimethod] [{::form/keys [form-instance parent parent-relation master-form] :as renv} id-attr]
(dom/div :.ui.container.form {:key (str (comp/get-ident form-instance))}
(fr/render-header renv id-attr)
(fr/render-fields renv id-attr)
(fr/render-footer renv id-attr)))
;; Need this so that the plugin's default way of rendering refs is used when rendering with multimethods
(defmethod fr/render-field [:ref :default] [{::form/keys [form-instance] :as renv} field-attr]
(rsf/standard-ref-container renv field-attr (comp/component-options form-instance)))
;; Use SUI's layout code for rendering fields by default
(defmethod fr/render-fields :default [{::form/keys [form-instance] :as renv} attr]
(rsf/standard-form-layout-renderer renv))
;; This gives us the standard headings for forms and to-many. Renders controls on top-level forms,
;; and renders optional delete button on deleteable nested forms.
;; This is copied from Semantic UI StandardFormContainer. It's everything but the calls to `render-fields`.
(defmethod fr/render-header :default [{::form/keys [master-form form-instance] :as env} attr]
(let [nested? (not= master-form form-instance)
props (comp/props form-instance)
computed-props (comp/get-computed props)
{::form/keys [title action-buttons controls show-header?]} (comp/component-options form-instance)
title (?! title form-instance props)
action-buttons (if action-buttons action-buttons form/standard-action-buttons)
show-header? (cond
(some? show-header?) (?! show-header? master-form)
(some? (fo/show-header? computed-props)) (?! (fo/show-header? computed-props) master-form)
:else true)
{::form/keys [can-delete?]} computed-props
read-only-form? (or
(?! (comp/component-options form-instance ::form/read-only?) form-instance)
(?! (comp/component-options master-form ::form/read-only?) master-form))
{:ui/keys [new?]
::form/keys [errors]} props
invalid? (if read-only-form? false (form/invalid? env))
errors? (or invalid? (seq errors))]
(if nested?
(div {:className (or (?! (comp/component-options form-instance ::ref-element-class) env) "ui segment")}
(div :.ui.form {:classes [(when errors? "error")]
:key (str (comp/get-ident form-instance))}
(when can-delete?
(dom/button :.ui.icon.primary.right.floated.button {:disabled (not can-delete?)
:onClick (fn [] (form/delete-child! env))}
(dom/i :.times.icon)))))
(div {:key (str (comp/get-ident form-instance))
:className (or
(?! (suo/get-rendering-options form-instance suo/layout-class) env)
(?! (comp/component-options form-instance suo/layout-class) env)
(?! (comp/component-options form-instance ::top-level-class) env)
"ui container")}
(when show-header?
(div {:className (or
(?! (suo/get-rendering-options form-instance suo/controls-class) env)
(?! (comp/component-options form-instance ::controls-class) env)
"ui top attached segment")}
(div {:style {:display "flex"
:justifyContent "space-between"
:flexWrap "wrap"}}
(dom/h3 :.ui.header {:style {:wordWrap "break-word" :maxWidth "100%"}}
title)
(div :.ui.buttons {:style {:textAlign "right" :display "inline" :flexGrow "1"}}
(keep #(control/render-control master-form %) action-buttons)))))
(div {:classes [(or (?! (comp/component-options form-instance ::form-class) env) "ui attached form")
(when errors? "error")]}
(when invalid?
(div :.ui.red.message (tr "The form has errors and cannot be saved.")))
(when (seq errors)
(div :.ui.red.message
(div :.content
(dom/div :.ui.list
(map-indexed
(fn [idx {:keys [message]}]
(dom/div :.item {:key (str idx)}
(dom/i :.triangle.exclamation.icon)
(div :.content (str message))))
errors))
(when-not new?
(dom/a {:onClick (fn []
(form/undo-via-load! env))} (tr "Reload from server")))))))))))
;; No footer by default
(defmethod fr/render-footer :default [renv attr])The plugin already has rendering for fields defined for a lot of types, and the multimethod for render-field has a default that uses the installed UI plugin’s map.
So there is nothing to do to get fields to render with multimethods, but if you do a defmethod on fr/render-field then that will take precedence:
;; Override how to render the default string field
(defmethod fr/render-field [:string :default] ...)Finally, let’s do something new! Let’s say we want to-many subforms to render as a table, where the header of the table has the field labels, and the rows just show the inputs.
First, we define how to render a :ref field that uses a :table style.
This will let us add fro/style to the subform options and get a table:
;; Rendering the to-many field must wrap things in the table, and wrap the subforms (which will render as rows) in a tbody.
(defmethod fr/render-field [:ref :table] [{::form/keys [form-instance] :as renv} field-attr]
(let [relation-key (ao/qualified-key field-attr)
item (-> form-instance comp/props relation-key)
ItemForm (form/subform-ui (comp/component-options form-instance) field-attr)
to-many? (= :many (ao/cardinality field-attr))]
(if ItemForm
(dom/table :.ui.table {:key (str relation-key)}
(fr/render-header renv field-attr)
(dom/tbody nil
(if to-many?
(mapv (fn [i] (form/render-subform form-instance relation-key ItemForm i)) item)
(form/render-subform form-instance relation-key ItemForm item)))
(fr/render-footer renv field-attr))
(log/error "There is no Subform UI declared for" relation-key "on" (comp/component-name form-instance)))))We need to use render-subform for each of the items, which in turn will hit render-form for each of them.
We’re also calling render-header and render-footer, so we should write those.
Basically the header is going to be the field lables, and the footer is going to be the (optional) add button.
;; We aren't supporting using this on top-level forms, so we output a warning div if it gets used that way
(defmethod fr/render-header [:default :table] [{::form/keys [form-instance] :as env} field-attr]
(if (ao/identity? field-attr)
(dom/div "Table header only supports rendering as a subform")
(let [{ItemForm ::form/ui
::form/keys [can-add?]} (fo/subform-options (comp/component-options form-instance) field-attr)
attrs (comp/component-options ItemForm fo/attributes)]
(dom/thead nil
(dom/tr nil
(mapv
(fn [a] (dom/th {:key (str (ao/qualified-key a))} (form/field-label env a)))
attrs)
(when can-add?
(dom/th nil ent/nbsp)))))))
(defmethod fr/render-footer [:default :table] [{::form/keys [form-instance] :as env} {::attr/keys [qualified-key] :as field-attr}]
(if (ao/identity? field-attr)
(dom/div "Table footer only supports rendering as a subform")
(let [{ItemForm ::form/ui
::form/keys [can-add?]} (fo/subform-options (comp/component-options form-instance) qualified-key)
can-add? (?! can-add? form-instance field-attr)]
(when can-add?
(dom/tfoot nil
(dom/tr nil
(dom/td nil
(dom/button :.ui.icon.button
{:onClick (fn []
(form/add-child! form-instance qualified-key ItemForm {:order :append}))}
(dom/i :.plus.icon)))))))))The only thing left to do is add render-form for laying out the subform as a row:
;; Rendering the an actual form as a table row is supported. If table is used on a top-level form we just emit a warning div.
(defmethod fr/render-form [:default :table] [{::form/keys [parent parent-relation form-instance] :as renv} idattr]
(if parent
(let [{::form/keys [attributes]} (comp/component-options form-instance)
{::form/keys [can-delete?]} (fo/subform-options (comp/component-options parent) parent-relation)
can-delete? (?! can-delete? parent (comp/props form-instance))]
(dom/tr {:key (str (comp/get-ident form-instance))}
(mapv (fn [attr]
(dom/td {:key (str (ao/qualified-key attr))}
(form/render-input renv attr))) attributes)
(when can-delete?
(dom/td {:style {:verticalAlign "middle"}}
(dom/button :.ui.icon.button {:onClick (fn [] (form/delete-child! parent parent-relation (comp/get-ident form-instance)))}
(dom/i :.times.icon))))))
(dom/div nil "Rendering top-level forms as a table is not supported.")))Note that we use render-input, which is render-field that hints to the plugin that it doesn’t want the label.
See the new-rendering branch of the Fulcro Rad Demo to play with this exact code.
Remember To Derive!
For the vector-based entry of :default to act like you expect, all keywords that should fall through to that default must be "derived" using the fr/derive! function.
So, for example if you want [:ref :table] to fall through to
[:ref :default] (instead of the top level :default), then you must run (fr/derive! :table :default) before you render with that style.
This allows you to relate your styles:
(derive! :alternating-row-color-table :celled-table)
(derive! :celled-table :plain-table)
(derive! :plain-table :table)
(derive! :table :default)Demo
The Fulcro RAD Demo repository has a new-rendering
branch that defines and uses these multimethods for rendering.
7.3.3. Custom Field Rendering
The most common and easy customization is simply to provide a new form field renderer.
These can be installed (even via hot code reload) and then selected with fo/field-style.
You should consider the fulcro-rad-semantic-ui source code a good resource for examples.
Version 1.6+ also has a mulitmethod implementation for field rendering.
Be sure to read Form Rendering via Multimethods (RAD V1.6+, 1.6.0-SNAPSHOT).
The most important things to be aware of when creating a new field renderer are:
-
com.fulcrologic.fulcro.dom.inputs: This namespace includesStringBufferedInputand some sample of making low-level input controls that use DOM inputs, but support non-string data types. -
com.fulcrologic.rad.form/with-field-context: Alet-like macro that can efficiently pre-extract important details about a given field. There is alsofield-contextas a function. -
com.fulcrologic.rad.rendering.semantic-ui.field/render-field-factory: An example of how you could create your own field factory. If you’re using the SUI library, it is already the factory you might want. -
Any of the namespaces ending in
-fieldin the SUI plugin, as examples.
Installing a new form field style can be done with a simple assoc-in on the controls you install in your client (which can be called on a hot reload hook):
;; Install some plugin
(rad-app/install-ui-controls! app sui/all-controls)
;; Install a custom control for a given style
(form/install-field-renderer! app :string :email email-field-render)Then you can select your custom control by setting the fo/field-style on an attribute or override it on a given form via fo/field-styles.
There are also plugin points for the wrappers around the form body, subforms, and such. See the RAD Semantic UI plugin for example implementations of these.
7.3.4. Form Abandonment
When the user tries to route away from a form with unsaved changes the default is to show a js/confirm dialog and
ask if the user intends to throw away changes. If they answer yes, then routing continues, otherwise they stay on the form.
In the latest versions of RAD and the SUI plugin, you can choose an alternative that can be customized. To do so you
specify the fo/confirm option. This option can be a synchronous function (e.g. js/confirm) that takes a message
and returns a boolean. The reason for this is to make it compatible with native (non-web) environments.
You can now also set it to the special keyword :async, which causes the form state machine to assume you have
a rendering plugin that can support rendering some kind of modal for the user to interact with. The SUI plugin
includes a default modal. So, the only thing you have to do is:
(defsc-form MyForm [this props]
{...
fo/confirm :async
...})If you want to customize the modal, then look at the all-controls map in the
com.fulcrologic.rad.rendering.semantic-ui.semantic-ui-controls namespace, and copy the implementation from the
:default entry, and then assoc yours into the map in the location shown when you install all controls:
(def all-controls
{:com.fulcrologic.rad.form/element->style->layout
{
...
:async-abandon-modal {:default sui-form/standard-abandon-modal
:new-style your-custom-renderer-here}}With the SUI plugin you can select the abandon modal style via the form fo/layout-styles option:
(defsc-form MyForm [this props]
{fo/confirm :async
fo/layout-styles {:async-abandon-modal :new-style}
...7.3.5. Augmenting Form Behavior
There are times when your form will need more than just the content of the form itself. This is commonly the case for things like autocomplete fields. RAD comes with a prewritten version of this (pickers), but they have the limitation of having to be able to pre-load all of the options in advance. This is insufficient when the number of options might be very large.
One way to do things like autocompletes is to use React hooks and Fulcro’s hooks/use-component combined with things like hooks/use-generated-id, df/load!, and such inside of a custom control.
At other times, though, you may just need to augment how the I/O or other logic of a form operates.
Forms are completely controlled by their UI State Machine, and you can augment or even replace that machine via the fo/machine option.
A very common pattern is to grab an existing handler from the state machine and add a step to it. You can create simple helpers like this to make that easy:
(defn augment-event
"Add `additional-action` to the end of the actions performed by the `base-machine` in `state` for `event`. `event` can
be nil if there is just a global handler for that state. Returns the modified machine, so more than one of these
can be threaded together to modify a machine in multiple places."
[base-machine state event additional-action]
(let [handler-path (if event
[::uism/states state ::uism/events event ::uism/handler]
[::uism/states state ::uism/handler])
original-handler (get-in base-machine handler-path)]
(assoc-in base-machine handler-path (fn [env]
(-> env
(original-handler)
(additional-action))))))Note that the above function would add your additional action at the end of the chain of operations. A similar pattern can be used to add new event types, etc. See Fulcro’s UISM documentation for more information on how to program UI state machines.
7.3.6. Taking Over Rendering
Many forms can be customized to look and behave exactly like you want by using the techniques of the prior sections; however, at some point you will run into a situation where customizing the plugin elements themselves isn’t worth it. Sometimes there’s just a single form that has some strange custom look and feel that isn’t worth generalizing.
At that point you can take control of the rendering but still leverage all of the form’s state machine, loading, saving, undo, and even individual field rendering! This lets you take over exactly what you need to take over without doing an inordinate amount of extra work.
Remember, this is just a Fulcro component! The props are pretty much exactly what you’d expect.
The first step is very easy: just supply the form with a body! If you do that, then RAD no longer uses the rendering plugin for that form (each subform will have the same rule: add a body to take over the render).
If you’re doing the rendering, then some options (like fo/layout) are ignored, but you still need to specify things like the fo/id, fo/attributes, fo/subforms and such, since those are part of how RAD generates the query for the form, and how it understands how to do things like initialize it.
Within the render body, the basic functions to know about are:
-
form/rendering-env: Used to create theenvthat a lot of other helper functions want. -
form/render-layout: This is exactly what the form normally calls to render itself. You can use it if you want to embed the content of the form in additional elements. -
form/render-form-fields: Renders everything that would normally be in the form, but does NOT render the container/controls. -
form/render-field: Renders the specified field using the rendering plugin. -
form/save!: Save the form to the server. -
form/undo-all!: Undo all changes. -
form/cancel!: Cancel the edits. Also used as "done". Undoes the changed and possibly triggers routing. -
form/add-child!: Used to add a child form (to-one or many). -
form/delete-child!: Used (usually within the sub-form) to delete that element from the form set.
Subforms
The primary thing to understand about rendering subforms is that you must create a proper rendering-env for the subform and pass it along as the computed props of that subform.
It is useful to create `comp/computed-factory`s for your subforms so you can do this as a simple third argument.
(defsc-form Address [this props env]
{ ... }
...)
(defn ui-address (comp/computed-factory Address))
...
;; in parent Person form, rendering subform through :person/address
(let [env (render-env this props)]
...
(ui-address address
(merge
env
{::form/parent this
::form/parent-relation :person/address}))7.4. Subforms with Multiple Target types
In RAD 1.3.10 we added the ao/targets option to reference attributes to support the idea that an edge in the graph may point to more than one kind of thing.
The setup and usage is identical to everything you’ve read so far in this guide, except for one thing: Your
fo/subform option must be a proper Fulcro union component that properly composes together the possible forms that would be used at that edge.
The new helper form/defunion can be used to generate such a component.
(ns com.example.ui.notes
(:require
#?(:clj [com.fulcrologic.fulcro.dom-server :as dom]
:cljs [com.fulcrologic.fulcro.dom :as dom])
[taoensso.timbre :as log]
[com.example.model :as model]
[com.example.model.company :as company]
[com.example.model.entity :as entity]
[com.example.model.person :as person]
[com.example.model.note :as note]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.rad.form :as form]
[com.fulcrologic.rad.control :as control]
[com.fulcrologic.rad.form-options :as fo]
[com.fulcrologic.rad.report :as report]
[com.fulcrologic.rad.report-options :as ro]))
;; IN this example the Note entity has a creator and interested parties. Those can be Person or Company entities.
;; 1. Declare a form for Person (as normal)
(form/defsc-form PersonForm [this props]
{fo/id person/id
fo/attributes [person/first-name
person/last-name
entity/email]
fo/add-label (fn [_ add!] (dom/button :.ui.basic.icon.button {:onClick add!}
(dom/i :.plus.icon)
"Add Person"))
fo/route-prefix "person"
fo/title "Person"})
;; 2. Declare a form for Company (as normal)
(form/defsc-form CompanyForm [this props]
{fo/id company/id
fo/attributes [company/classification
entity/email
entity/name]
fo/add-label (fn [_ add!] (dom/button :.ui.basic.icon.button {:onClick add!}
(dom/i :.plus.icon)
"Add Company"))
fo/route-prefix "company"
fo/title "Company"})
;; 3. Make a union component using the helper:
(form/defunion PartyUnion PersonForm CompanyForm)
(form/defsc-form NoteForm [this props]
{fo/id note/id
fo/validator model/all-attribute-validator
fo/attributes [note/author
note/content
note/parties]
fo/default-values {:account/active? true
:account/primary-address {}
:account/addresses [{}]}
fo/route-prefix "note"
fo/title "Edit Note"
;; 4. Use the union for the UI of the subform
fo/subforms {:note/author {fo/ui PartyUnion
fo/title "Author"}
:note/parties {fo/ui PartyUnion
fo/can-delete? true
fo/default-values [(fn [id] {:person/id id})
(fn [id] {:company/id id})]
fo/title "Interested Parties"}}})7.5. Choosing Where to go After an Edit
When a user finishes editing something, you often want them to route back to where they came from. Early RAD versions defaulted to just this. Unfortunately, if they just loaded the form via a bookmark, "where you came from" is "nowhere".
The form option fo/cancel-route was added as a way to supports a number of options for how a form should behave when the user decides to finish editing.
The default is to "go back" to where you came from.
There are other things you can place on this option:
-
:back(the default) -
A route as a vector of strings
-
A component that you want to route to
-
A map with :route, :target, and :params keys
-
A
(fn [app form-props] …)that can return any of the above
8. Reports
RAD Reports are based on the generalization that many reports are a query across data that is list-based, and most reports have parameters. RAD’s graph API is the source of the things that you’ll show in reports, and the report system of RAD associates logic with the report for managing the general operation.
A sample report might look like this:
(defsc EmployeeListItem [this {:employee/keys [id first-name last-name enabled?] :as props}]
{:query [:employee/id :employee/first-name :employee/last-name :employee/enabled?]
:ident :employee/id}
(div :.item {:onClick #(form/edit! this EmployeeForm id)
:classes [clickable-item]}
(div :.content
(dom/span (str first-name " " last-name (when-not enabled? " (disabled)"))))))
(report/defsc-report EmployeeList [this props]
{ro/BodyItem EmployeeListItem
ro/create-form EmployeeForm
ro/layout-style :default
ro/source-attribute :employee/all-employees
ro/parameters {:include-disabled? {:type :boolean
:label "Show Past Employees?"}}
ro/initial-parameters (fn [report-env] {:include-disabled? false})
ro/run-on-mount? true
:route-segment ["employee-list"]})The report component has the following options, and of course this list is extensible:
:route-segment-
Dynamic-router parameter. A report is a normal component, and has hooks for route enter and exit. Use this option to set the route’s target segment.
ro/BodyItem-
The UI component that renders the row of a report.
- You can use
ro/create-form -
A Form that should be used to create new instances of items in the report. Optional. If supplied then the toolbar of the report will have an add button.
ro/layout-style-
An alternate style (plugged into the app) for rendering the report.
ro/source-attribute-
The EQL top-level key to query for the report. Combined with the
BodyItemquery to generate the full report query. ro/parameters-
A map from report parameter name to a map of configuration. The type/label options are used to generate a query toolbar.
ro/initial-parameters-
A map from report parameter data key to an initial value. May also be a lambda to generate the map.
ro/run-on-mount?-
Boolean. If true it causes the report to auto-run when mounted.
8.1. Handling Report Queries
A report query is nothing more than your normal EQL query, so it can be resolved by a Pathom client or server parser. The query parameters that come from the report will only normally appear in the AST at the top-level resolver (for the source-attribute).
There is a com.fulcrologic.rad.pathom/query-params-to-env-plugin that can be added to a pathom parser which moves the top-level params into the general parsing env at key :query-params.
This is where the report parameters will show up.
So, your parser will look something like this:
(def parser
(pathom/parser
{::p/mutate pc/mutate
::p/env {::p/reader [p/map-reader pc/reader2 pc/index-reader
pc/open-ident-reader p/env-placeholder-reader]
::p/placeholder-prefixes #{">"}}
::p/plugins [...
query-params-to-env-plugin
...]}))and from there it’s simply a matter of writing resolvers. Assuming you have a function that can get all employees:
(defresolver all-employees [{:keys [db query-params] :as env} input]
{::pc/output [{::all-employees [:employee/id]}]}
(let [employees (get-all-employees db)
employees (if (:include-disabled? query-params)
employees
(filterv :employee/enabled? employees))]
{::all-employees employees}))Remember that Pathom resolvers auto-connect based on inputs and outputs, so any given report attribute can be connected from there. For example, perhaps your report generates the number of hours an employee has worked this pay period, you’d simply add that attribute to the report and a resolver like this:
(defresolver pay-period-hours-resolver [env {:employee/keys [id]}]
{::pc/input #{:employee/id}
::pc/output [:employee/hours-this-period]}]}
{:employee/hours-this-period (calculate-hours id)})8.2. Customizing Report Rendering
There are two choices as of version 1.6 of RAD. One method uses maps of styles that can be selected as options (which are implements in the plugin like the Semantic UI plugin), and the other is to leverage multimethods (v1.6+). This section of the book covers the older map-based way. See the section on Report Rendering with Multimethods for the other.
You will have to install UI renderers for reports to render at all. Your rendering plugin will come with a default layout and perhaps others. You can define your own and the component options can easily be used to get what you need to render the data.
(defn custom-report-layout [this]
(let [props (comp/props this)
{::report/keys [source-attribute BodyItem parameters create-form]} (comp/component-options this)
id-key (some-> BodyItem (comp/get-ident {}) first)
row-factory (comp/factory BodyItem {:keyfn id-key})
rows (get props source-attribute [])
loading? (df/loading? (get-in props [df/marker-table (comp/get-ident this)]))]
...))Setting up your layout is just done on app config:
(form/install-ui-controls! app
(-> base-controls
(assoc-in [ro/style->layout :custom-layout] custom-report-layout)and then set the ro/layout-style :custom-layout option on the report.
8.3. Report Row Rendering
|
Note
|
At present you must write the row rendering yourself. The design of the recursive pluggable report rendering is still in progress. You can, of course, place renderers in the global controls map to generalize things. |
8.4. Report Performance
Just some notes…
Normalization can be expensive for large reports. Denormalize reports that don’t share info with forms. This can save many seconds of processing if you have thousands of data points, will also affect rendering speed if you are doing something like a chart.
Reports filter, sort, and paginate in phases.
For large reports, disabling the filter or sort stages can be quite helpful when they are not needed.
Use ro/skip-filtering? to programatically force the report to skip the processing of filters (normally if you provide a row-visible? it is called once per row no matter what).
Sorting can be disabled by calling report/clear-sort!, which does not re-render or re-sort the table.
It just sets a flag so that future operations won’t call the sort stage.
This dissoc’s the :sort-by sort paramter, so NOT including a :sort-by in your
ro/initial-sort-params is how to disable sorting on initial load.
Pagination is cheap, so it should never be the source of problems.
Note also that filtering happens first, then sorting, then pagination. If you re-sort, then filtering will never be re-applied, but if you change the filters sorting will also happen (unless disabled).
8.5. Report Rendering with Multimethods
This technique for working with report rendering was added in version 1.6. The initial implementation didn’t use multimethods because they do not dead-code eliminate, and they are a bit hard to trace, but with the addition in Fulcro DOM of source code attribution in the DOM. Selecting things into a map at runtime ensures you only get what you intend, and the "extras" will dead-code eliminate. But just requiring multimethods gets you something that cannot be optimized away. However, you can manage which namespaces you want to require, so the benefits multimethods can bring were just to great to ignore.
Report multimethod use is centered around these two namespaces:
[com.fulcrologic.rad.report-render :as rr]
[com.fulcrologic.rad.report-render-options :as rro]The former defines some stock multimethods (you can, of course add your own), only one of which is called by RAD itself.
8.5.1. The Rendering Multimethods
RAD predefines a number of multimethods for rendering:
render-report-
Entry point called from RAD.
render-controls-
Meant to contain the code for rendering the controls that appear above a report.
render-body-
Meant for rendering the report itself, and probably composes together the remaining three.
render-header-
Meant to render the headings (i.e. table headers) of the report
render-row-
Meant to be called once per row of the report.
render-footer-
Meant to render the footer (duplicate controls?)
and it defines defaults for three of them to do what the older versions of RAD already did (so you can fall back on those if desired):
(defmethod rr/render-row :default [report-instance options row-props]
(let [row-class (ro/BodyItem options)]
(default-render-row report-instance row-class row-props)))
(defmethod rr/render-report :default [report-instance options]
(default-render-layout report-instance))
(defmethod rr/render-controls :default [this options]
((control-renderer this) this))other methods are defined because they seem like the generally useful set of methods you’d want, and if you had to define them yourself then library authors would not have much common ground to rely on.
The multimethods use the same dispatch hierarchy as forms.
So fr/derive! and fr/isa? are what you would use to manage ad-hoc polymorphism.
The multimethods dispatach on vectors.
The data that will appear in the vector for each is the row’s primary key keyword (e.g. the qualified keyword of the ro/row-pk option) and a style.
Each of the different multimethods has a custom style option in the report-render-options namespace, but the style will always fall back to trying the value of rro/style if no specialized style is defined.
All of these styles are meant to appear as top-level options on the report component itself:
(defsc-report People [this props]
{ro/row-pk person/id
rro/style :compact/table
rro/header-style :foo
...
})would try to invoke the render-report with a dispatch of [:person/id :compact/table].
This would resolve according to multimethod rules (isa? on each element of the vector) and fall
back to the special value :default (not a vector) if none are found. All the multimethods would
expect style :compact/table (dispatch uses rr/style as a fallback) except for headers,
which stated an explicit header style of rro/header-style :foo.
8.5.2. Example Setup
The Fulcro RAD Demo new-rendering branch includes a running sample.
The step to follow are:
-
Set up you hierarchy fall-through using the form rendering hierarchy (since it is shared). This involves calling things like
fr/allow-defaults!andfr/derive!. -
Define multimethods for your style(s)
-
Set the style option on one or more reports.
Setting up the Hierarchy
The first step is to decide where fall-through is desired. Say you want to specialize how reports render people and employees, but there are some similarities.
(fr/allow-defaults! r.model/all-sttributes) ; indicate that ANY RAD attribute will fall through to :default
(fr/derive! :employee/id :person/id) ; indicate that an employee IS a kind of person
(fr/derive! :compact/table :table) ; indicate that a compact table is a kind of tableNow if a report for employee’s is rendering as a compact table the dispatch [:employee/id :compact/table] can look for multimethods that accept [:employee/id :compact/table], [:person/id :compact/table], [:employee/id :table], etc.
This means that you can define, say, a custom render-body for [:default :compact/table] that adds css classes to
compress the table, but you can then let the other elements (header/footer/rows) fall all the way through to default,
or be specialized on the data type.
Define the Multimethods
The com.example.ui.report-rendering of the
new-rendering branch
of the Fulcro RAD Demo is a runnable demo that sets things up as follows.
First, it invents style name (:multimethod) for render-report, and provides
a default for rendering controls and the report body. In those it calls some of
the other multimethods:
(defmethod rr/render-report [:default :multimethod] [this options]
(dom/div :.ui.container nil
(rr/render-controls this options)
(rr/render-body this options)))
(defmethod rr/render-controls [:default :multimethod] [report-instance options]
(let [controls (control/component-controls report-instance)
{:keys [::report/paginate?]} options
{::suo/keys [report-action-button-grouping]} (suo/get-rendering-options report-instance)
{:keys [input-layout action-layout]} (control/standard-control-layout report-instance)
{:com.fulcrologic.rad.container/keys [controlled?]} (comp/get-computed report-instance)]
(comp/fragment
(div {:className (or
(?! (suo/get-rendering-options report-instance suo/controls-class))
"ui basic segment")}
;; CODE copied From Semantic UI Plugin to render controls
))))
(defmethod rr/render-body :default [this options]
(let [rows (report/current-rows this)
selected-row (report/currently-selected-row this)]
(dom/table :.ui.compact.table {}
(rr/render-header this options)
(dom/tbody nil
(map-indexed
(fn [idx row] (rr/render-row this options
(assoc row ::report/idx idx ::report/highlighted? (= idx selected-row))))
rows))
(rr/render-footer this options))))Next, it sets up a global fall-through default for table headers and footers (since there are none). Headers are somewhat complex because you often want to let the user click on a header to sort the table. The code for the headers was largely lifted from the SUI plugin:
(defmethod rr/render-header :default [this options]
(let [column-headings (report/column-heading-descriptors this options)
props (comp/props this)
sort-params (-> props :ui/parameters ::report/sort)
{::report/keys [compare-rows]} options
sortable? (if-not (boolean compare-rows)
(constantly false)
(if-let [sortable-columns (some-> sort-params :sortable-columns set)]
(fn [{::attr/keys [qualified-key]}] (contains? sortable-columns qualified-key))
(constantly true)))
sui-header-class (suo/get-rendering-options this suo/report-table-header-class)
ascending? (and sortable? (:ascending? sort-params))
sorting-by (and sortable? (:sort-by sort-params))]
(dom/thead nil
(dom/tr nil
(map-indexed (fn [idx {:keys [label help column]}]
(let [alignment-class (sur/column-alignment-class this column)]
(dom/th {:key idx
:classes [alignment-class (?! sui-header-class this idx)]}
(if (sortable? column)
(dom/a {:onClick (fn [evt]
(evt/stop-propagation! evt)
(report/sort-rows! this column))}
label
(when (= sorting-by (::attr/qualified-key column))
(if ascending?
(dom/i :.angle.down.icon)
(dom/i :.angle.up.icon))))
label)
#?(:cljs
(when help
(ui-popup {:trigger (dom/i :.ui.circle.info.icon)}
(ui-popup-content {}
help)))))))
column-headings)))))
(defmethod rr/render-footer :default [_ _]
(dom/tfoot nil
(dom/tr nil
(dom/td {:colSpan 3
:style {:color "lightgrey"
:fontSize "8pt"}}
"Table by multimethods"))))Next we define a query-less component to wrap how we will render a row. We do this because defsc generates a pure
component, which will avoid rendering if the props have not changed. This is important for a table, which might
be trying to display a lot of DOM. Then a factory is generated and called from the multimethod.
(comp/defsc TableRowLayout [_ {:keys [report-instance props] :as rp}]
{}
(let [{::report/keys [columns link links on-select-row]} (comp/component-options report-instance)
links (or links link)
action-buttons (sur/row-action-buttons report-instance props)
{::report/keys [idx highlighted?]} props
sui-cell-class (suo/get-rendering-options report-instance suo/report-table-cell-class)]
(dom/tr {:classes [(when highlighted? "active")]
:onClick (fn [evt]
(evt/stop-propagation! evt)
(when-not (false? (suo/get-rendering-options report-instance suo/selectable-table-rows?))
(?! on-select-row report-instance props)
(report/select-row! report-instance idx)))}
(map-indexed
(fn [idx {::attr/keys [qualified-key] :as column}]
(let [alignment-class (sur/column-alignment-class report-instance column)
column-classes (str alignment-class " " (report/column-classes report-instance column))]
(dom/td {:key (str "col-" qualified-key)
:classes [(?! sui-cell-class report-instance idx) column-classes]}
(let [{:keys [edit-form entity-id]} (report/form-link report-instance props qualified-key)
link-fn (get links qualified-key)
label (report/formatted-column-value report-instance props column)]
(cond
edit-form (dom/a {:onClick (fn [evt]
(evt/stop-propagation! evt)
(form/edit! report-instance edit-form entity-id))} label)
(fn? link-fn) (dom/a {:onClick (fn [evt]
(evt/stop-propagation! evt)
(link-fn report-instance props))} label)
:else label)))))
columns)
(when action-buttons
(dom/td {:key "actions"
:className (or
(?! sui-cell-class report-instance (count columns))
"collapsing")}
action-buttons)))))
(let [ui-table-row-layout (comp/factory TableRowLayout)]
(defn render-table-row [report-instance row-class row-props]
(ui-table-row-layout {:report-instance report-instance
:row-class row-class
:props row-props})))
(defmethod rr/render-row [:default :multimethod] [this options row]
(render-table-row this (ro/BodyItem options) row))The render-row multimethod is called with the report instance, row class, and row props. Usually you won’t need the row class (it established the query and normalization), but it is there just in case. The bulk of the logic in row rendering centers around the fact that a row can be "selected" and/or have form links. So, if you want to support those RAD options, you’ll have to include logic to handle them.
That’s it! A full set of multimethods for rendering reports. All you have to do is add a style option and your report will switch to using the multimethods:
(defsc-report Report [this props]
{rro/style :multimethod
...
})9. Arbitrary Form and Report UI Composition
The default setup of forms and reports is for them to be proper routes in your application in the dynamic routing system. This is an option (the default). Reports and forms are just components, and as such they can be composed in any of the ways other Fulcro components can be composed into an application. The primary thing to know is that the routing system hooks that are preconfigured on the forms and reports trigger a UI state machine to start when that form or report is routed to. In order for you to take control of rendering you need only:
-
Make sure the component in question is in app state, and is either composed with the parent’s query, or is being used through hooks like
use-component. -
Start the state machine on the report or form.
-
(Optional) Clear the state machine from app state when you remove it from the screen (so it will restart from scratch the next time you show it). Skipping this step would let you show/hide a form/report without having to restart it.
9.1. Composing a Component in Dynamically
If you don’t know the report or form that is to be started in advance, then it is rather difficult to pre-compose it into app state and the query.
It is recommended that you use use-form or use-report in a hooks component in this case; however, you can also leverage dynamic queries to place a form or report into anyplace in your tree, and a mutation to pre-populate things using merge-component!.
Forms will auto-load themselves into state, so simply putting the correct form ident into app state at the proper location is sufficient.
Reports have initial state (use comp/get-initial-state), so you can simply merge the report into app state and put it’s ident (which is a constant) in the proper location.
9.2. Starting Forms
-
A UISM can be started with
uism/begin!, but it is easier to useform/start-form!.-
The machine to use is on the form itself (comp/component-options Form fo/machine), which defaults to
form/form-machine. -
The ASM ID for forms is simply the form’s ident.
-
The only actor is :actor/form
-
The event-data can contain various options related to form startup.
-
(defsc-form Form [this props] ...)
...
;; in some mutation or something
(form/start-form! app (tempid/tempid) Form options)The options include (see docstring for latest):
-
:on-saved fulcro-txnA transaction to run when the form is successfully saved. Exactly what you’d pass totransact!. The form will add{:ident final-ident}to the mutation’s parameters (so you can see the remapped ID if it was new) -
:on-cancel fulcro-txnA transaction to run when the edit is cancelled. -
:on-save-failed fulcro-txnA transaction to run when the server refuses to save the data. -
:embedded? booleanDisable history and routing for embedded forms. Default false.
9.3. Starting Reports
Starting reports is similar.
Use the report/start-report!.
9.4. Better Dynamic Composition: Hooks-based Forms and Reports
React hooks give us a great way to compose all sorts of things in the UI.
The com.fulcrologic.rad.rad-hooks namespace includes hooks-based form and report helpers:
form/use-form-
A hook that takes a Form, and id, and options, and returns a factory and props for rendering the form in any context. The form state machine stays active while the containing component is mounted, and is automatically cleaned up afterwards.
report/use-report-
A hook that takes a Report and options, and returns a factory and props for rendering the report in any context.
The Semantic UI RAD plugin also has
com.fulcrologic.rad.rendering.semantic-ui.modals/ui-form-modal, which leverages useForm.
When you render it, it automatically pops the form in a modal.
When the user saves/cancels the modal, a mutation is called of your choosing with the ident of the form.
When you stop rendering the modal it disappears and removes the form state machine.