1. About This Book
This is a stand-alone developer’s guide for version 3 of Fulcro. It is intended to be used by beginners and experienced developers and covers most of the library in detail. Fulcro has a pretty extensive set of resources on the web tailored to fit your learning style.
There is this book, the docstrings/clojure docs, and even a series of YouTube videos. Even more resources can be reached via the Fulcro Community site.
A lot of time and energy went into creating these libraries and materials and providing them free of charge. If you find them useful please consider contributing to the project.
Of course fixes to this guide are also appreciated as pull requests against the github repository.
This book includes quite a bit of live code. Live code demos with their source look like this:
(ns book.example-1
(:require
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.mutations :refer [defmutation]]
[com.fulcrologic.fulcro.dom :as dom]))
(defmutation bump-number [ignored]
(action [{:keys [state]}]
(swap! state update :ui/number inc)))
(defsc Root [this {:ui/keys [number]}]
{:query [:ui/number]
:initial-state {:ui/number 0}}
(dom/div
(dom/h4 "This is an example.")
(dom/button {:onClick #(comp/transact! this [(bump-number {})])}
"You've clicked this button " number " times.")))Each example includes a "Focus Inspector" button that will cause the Fulcro Inspect development tools to focus on that example. See Install Fulcro Inspect for details on how to set that up and use it.
All of the full stack examples use a mock server embedded in the browser to simulate any network interaction, but the source that you’ll read for the application is identical to what you’d write for a real server.
|
Warning
|
If you’re viewing this directly from the GitHub repository then you won’t see the live code! Use http://book.fulcrologic.com/fulcro3 instead. |
The mock server has a built-in latency to simulate a moderately slow network so you can observe behaviors over time. You can control the length of this latency in milliseconds using the "Server Controls" in the upper-right corner of this document (if you’re reading the HTML version with live examples).
1.1. Common Prefixes and Namespaces
Many of the code examples assume you’ve required the proper namespaces in your code. This book adopts the following general set of requires and aliases:
(ns your-ns
(:require [com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.application :as app]
[com.fulcrologic.fulcro.data-fetch :as df]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.algorithms.lookup :as ah]
[com.fulcrologic.fulcro.algorithms.merge :as merge]
[com.fulcrologic.fulcro.algorithms.data-targeting :as targeting]
[com.fulcrologic.fulcro.algorithms.denormalize :as fdn]
[com.fulcrologic.fulcro.algorithms.normalize :as fnorm]
[com.fulcrologic.fulcro.algorithms.react-interop :as interop]
[com.fulcrologic.fulcro.algorithms.tempid :as tempid]
[com.fulcrologic.fulcro.algorithms.form-state :as fs]
[com.fulcrologic.fulcro.algorithms.tx-processing.synchronous-tx-processing :as stx]
[com.fulcrologic.fulcro.networking.http-remote :refer [fulcro-http-remote]]
[com.fulcrologic.fulcro.ui-state-machines :as uism]
[com.fulcrologic.fulcro.react.hooks :as hooks]
[com.fulcrologic.fulcro.routing.dynamic-routing :as dr]
[com.fulcrologic.fulcro.routing.legacy-ui-routers :as r]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[edn-query-language.core :as eql]))others will be identified as they are used.
1.2. Best Practices
Fulcro and our understanding of best practices with it have evolved over time. Unfortunately we don’t have time to update this book every time a new insight or technique proves to be more useful than older ones. Everything in this book functions in the latest versions of Fulcro (to the best of our knowledge); however, this small section of the book is where we’ll try to list notes about current evolutions of the library and which features might be best to focus on.
As of September 2020 you should concentrate your efforts on understanding:
-
How Fulcro normalizes data. Pay particular attention to query, ident, and initial state. These are the core of Fulcro’s operation.
-
The core internals of I/O operation are still mutations (which in turn are used to implement the internals of loads); however, application authors would do well to pay attention to UI State Machines, which are generally a better way to organize groups of operations around components in order to reason over them.
-
UI Routing takes on a different flavor in Fulcro, because both the UI and queries need to be managed.
-
You should consider Fulcro RAD early in your application development. The attribute-centric focus brings a lot of extensibility/flexibility to your application, and the overall design and internals might help you understand more advanced usage of Fulcro itself.
-
Keep your query light! You can do this by adopting either the legacy union router (fast, low-feature, bit harder to understand) or the dynamic router (preferred, composable, more moving internal parts). When used at the top level of your app these will lead to better performance by making sure only the data needed for the active view is pulled from the database.
2. React Versions
Fulcro works with React for browsers, embedded in Electron, and React Native. Version 15+ should work with Fulcro through version 3.5.x, though React 17 is recommended for versions of Fulcro through 3.5.x.
Fulcro 3.6.0+ are compatible with React 17 and above (the final few versions of 16 that have Context should also work).
If you want to use React 18 in non-legacy mode, then you need to enable it. This is a manual process because React changed the namespaces where the entry point code lives.
When creating your Fulcro app, do the following:
(ns com.example.client
(:require
[com.fulcrologic.fulcro.application :as app]
[com.fulcrologic.fulcro.react.version18 :refer [with-react18]]
["react-dom/client" :as dom-client]
...))
(def my-app (-> (app/fulcro-app {... normal options ...})
(with-react18)))At the time of this writing Fulcro 3.6.0 is in progress, and is available as 3.6.0-SNAPSHOT.
Report any issues to the #fulcro Clojurians Slack channel.
3. Fulcro From 10,000 Feet
You may be reading this guide hoping for a "quick feel" for why Fulcro might be a good fit for a project. The Getting Started chapter walks you through the evolution of the model in a way that is intended to lead to the best understanding, but it is a lot of minutiae to absorb just to get the "big picture" and there is some chance you’ll misunderstand where that is going and stop before you get to the good stuff. This book is also a rather large work intended to serve as a complete reference guide, so reading it cover to cover may not be all that desirable for your purposes.
If you really want to learn to use Fulcro, feel free to skip this chapter and read Core Concepts; however, if you’d rather learn the central ideas and approach of Fulcro this is a good place to start.
At its core Fulcro and its companion library pathom are a full-stack application programming system centered around graph-based UI and data management.
The core ideas are as follows:
-
Graphs and Graph Queries are a great way to generalize data models.
-
UI trees are directed graphs that can easily be "fed" from graph queries.
-
User-driven operations are modeled as transactions whose values are simply data (that look like calls).
-
Arbitrary graphs of data from the server need to be normalized (as in database normalization):
-
UI trees often repeat parts of the graph.
-
Local Manipulation of data obtained from a graph needs to be de-duped.
-
-
Composition is King. Seamless composition is a key component of software sustainability.
3.1. But Does it Have X?
People have a number of initial "comparative" questions when looking at Fulcro when they’ve used other libraries. If you are familiar with other CLJS or JS UI libraries then you may have one of these questions. The most common ones are:
- Can I use "hiccup" notation for the DOM?
-
Yes, you can use Sablono. It should work fine, but it is cljs-only. If you want support, isomorphic server-side rendering of components, etc.: then use what Fulcro provides.
- Why don’t you use Hiccup by default?
-
The honest answer is "because". As in: because that’s the way it was written in Om Next, the predecessor of Fulcro. I assume David Nolen had his reasons for preferring functions/macros over hiccup and I respected his choice (even though I did not personally know why it was). Why is Fulcro still using functions? Well, several reasons: Certainly the fact that I already have the code and there are apps based on it is sufficient, it is no more verbose (if you leverage
:referin:require), it tests to be as fast as raw React when used optimally, and works with the same API on the client and server for supporting isomorphic rendering (Hiccup is CLJ only, you have to use Sablono for cljs with React). Finally, I will note that this question ranks near the top of my list of "Questions that Don’t Matter". If you came to Fulcro looking for DOM notation: move along. - Where are the "reducers"?
-
Re-frame and Redux are very popular choices for front-end work, and for good reason. Fulcro is basically a graph-centric full-stack CQRS-style library. Mutations are the "commands" that are queued (like events in a reducer system), but Fulcro adds some very important things: graph data support, auto-normalization of central database, and a centralized transaction processing system.
Fulcro 3’s UI State Machines are usable in exactly the same way as reducer/event systems, but have some distinct differences (dare I say improvements?): They support an actor model where instances of UI components are assigned at runtime to play "roles" in the logical flow; they are true state machines (not just switch/case statements); they make use of Fulcro’s database auto-normalization, graph query abilities, and abstract mutation system; and their current "state" is stored and normalized into the same central application database where Fulcro’s Chrome extension makes them easy to debug.
- Can I Subscribe to XYZ?
-
Subscriptions are not a central concern of Fulcro itself, but Fulcro’s architecture mixed with the websocket remote make building something that has a "Meteor JS" experience pretty easy to do. Almost all of the real difficulty in making a subscription system has to do with server-side management. You could use a "custom" websocket remote to adapt to any existing GraphQL infrastructure that supplies such automatic updates.
- What about Server-Side Rendering?
-
Fulcro is written in CLJC. The intention is to be able to set up and "run" an application in a headless JS OR Java VM environment and either actively control a DOM or just render "frames" as strings. The server-side implementation of the DOM methods let you render Fulcro UI in a Java VM without needing to resort to a JS engine at all.
3.2. Server Schema vs. UI Graph
Fulcro makes no assumptions nor does it have any requirements about back-end databases. You don’t even have to have a back-end: You can easily simulate one with the browser (like this book does), wrap browser local storage, or simply not use one at all.
If you are using a server database, then normalization and schema on the server is done according to whatever you’ve designed. Pathom makes it easy to "reshape" any particular schema or storage technology into a graph that fits your external API and UI needs.
This is an important point: it does not matter how your back-end database structures the data, as long as you know how to get the data you need when given a "context" that makes sense.
3.3. Queries (EQL)
Fulcro uses EQL (EDN Query Language), a graph query language similar to Datomic’s pull query notation.
A query is a vector (with nesting) that lists the things you want:
[:person/name {:person/address [:address/street]}]The above query (when run against a person) asks for that person’s name, and then indicates a "join" by using a map whose key is the join property on person, and whose value is a subquery of things to pull from there.
Such a query returns a map that mirrors the query structure:
{:person/name "Joe"
:person/address {:address/street "111 Main St."}}and could potentially return to-many results (if the address field were to-many in the database of the server):
{:person/name "Joe"
:person/address [{:address/street "111 Main St."} {:address/street "345 Center Ave."}]}For those coming from SQL this roughly equates to a LEFT JOIN from person to address (where the behind-the-scenes join key might be converted from :person/address to something like address.person_id).
You could implement this with something crude like:
SELECT person.id, person.name, address.id, address.street FROM person, address WHERE address.id = person.address_idand walk the table result with a reduce to convert the rows into the graph, but fortunately, the Pathom library does most of that "lifting" for you and also includes features that can be used to tune for optimal performance (e.g. fixing n+1 query problems, branch caching, parallel operation, etc.).
3.4. Fulcro Client Database
Fulcro uses a single, central, normalized graph database. Any time data is created or read into a Fulcro application it can be auto-normalized into this database, and queries from the UI components can easily be fulfilled from it.
The format of this database is trivial (and very fast as a result):
-
Nodes of the graph have some distinct ID (for their type, at least)
-
Nodes are stored in "tables".
-
Edges are represented as vectors:
[TABLE ID]
We use the term *ident* to mean "A tuple of table and ID that uniquely identify a graph node in the database."
The graph of data like this:
{:person/id 1 :person/name "Joe" :person/address {:address/id 42 :address/street "111 Main St."}}can be turned into this:
;; TABLE ID ENTITY POINTER TO ADDRESS TABLE
{ :PERSON { 1 {:person/id 1 :person/name "Joe" :person/address [:ADDRESS 42]}}
:ADDRESS { 42 {:address/id 42 :address/street "111 Main St."}}}This format supports any arbitrary graph, to-many (a vector of idents) and to-one (single ident) relations, any possible property value type (though you should generally make sure they’re serializable for network transfer), and is simple to manipulate (i.e. an assoc-in with a path length of 2 or 3 gets you to anything).
This leads to the following useful results:
-
Everything is de-duped for you. No need to worry that composing in some "alternate view" of pre-existing data will cause two out of sync copies to exist.
-
Caching is a centralized concern. Your normalized client database is the only possible place for the data, and each node of the graph has exactly one place to live (even if a query has two views of the same thing on different branches of some complex graph query result, which is common when composing related components onto a UI).
-
Subgraph reasoning is trivial: You can (re)load any portion of the graph at any time.
-
A UI query, server load, or transfer of some portion of the graph can be started from any node.
-
Manipulation of some node affects all paths through that node.
-
-
Meteor-style subscription models need not be an internal part of the library. If you have a database that can tell you when data changes then you can either re-run your graph query to pull those changes or merge in new graph of data that arrives from some arbitrary websocket push.
You may be asking "by what magic can Fulcro do this?". The answer is simple: by co-locating the node/edge descriptions with the components of your UI!
3.5. The Glue: UI Components
We also are writing SPAs where what we care about is the UI we end up with. Pathom can shape our server graph to match whatever we need on the client, and this frees us to design our UI as we see fit.
Components can therefore represent the desired UI nodes of a graph, and the EQL joins can represent the edges. Auto-normalization just requires one more detail: a way to manufacture the correct ident for a given node in order to make the edge.
This is functional programming, so of course the answer is a function:
(defn person-ident [props] [:person/id (:person/id props)])The convention for our table names (for ease of use with Pathom) is to use the name of the ID field of the entity (e.g. :person/id) as the table name for those types of entities.
Thus, the "ident" of this person:
(person-ident {:person/id 22 ...})
; => [:person/id 22]Of course, this function needs to be associated with the Person component for Fulcro to know how to use it.
That looks like this:
(defsc Person [this props]
{:query [:person/id :person/name] ; (1)
:ident (fn [] [:person/id (:person/id props)])} ; (2)
(dom/div ; (3)
(:person/name props)))-
The co-located query: What should we ask the server for when we’re asking for person data?
-
The ident: Given the props for some particular person, what is the 2-tuple that describes the table and ID for it?
-
What does this component look like when rendered?
3.5.1. Putting Things in the Database
Of course, the most interesting aspect of the operation now is "how do I get data into the system?".
Well, the query and normalization constructs are on the component, so you simply use the component with various APIs.
For example, to put some arbitrary graph of data you generated by hand into the database you could use:
(merge/merge-component! app Person {:person/id 11 ...})which inserts this:
{:person/id {11 {:person/id 11 ...}}}To put that same data into the database and add an "edge" somewhere else in the graph you could do:
(merge/merge-component! app Person {:person/id 11 ...} :append [:list/id :friends :list/people])which would add this to the graph:
;; append implies to-many. i.e. a vector of idents
{:list/id {:friends {:list/people [... [:person/id 11]] :list/id :friends ...}}
:person/id {11 {:person/id 11 ...}}}Loading
Loading is just as trivial and uses the same mechanisms. Loading a particular person from the server might look like this:
(df/load! app [:person/id 22] Person)Nested Things
Of course components are typically nested, and all of this composes with elegance. Say your person had some addresses that you modeled on a sub-component. If you compose those together everything else just falls into place:
(defsc Address [this props]
{:query [:address/id :address/street]
:ident :address/id} ; shorthand notation for the most common case: the table name and id key are the same keyword
...)
(defsc Person [this props]
{:query [:person/id :person/name {:person/address (comp/get-query Address)}]
:ident :person/id}
...)Then using load or merge against such a component
(merge-component! app Person {:person/id 1 :person/address {:address/id 42 ...}})will merge and normalize the entire (sub)graph.
3.6. The Operational Model
During operation you will need to make things happen.
3.6.1. Mutations
Mutations are a first-class higher-order citizen of Fulcro, and encode all of the possible interactions that your UI might need to have with the local graph database and any remote servers. Mutations are similar to specific "handler cases" of reducers in Redux, but are more akin to the "request" of a CQRS system in that they are serialized into a network-compatible form so that a single operation can be abstractly communicated to both the local logic and remote server(s) without having to deal with the low-level details.
The UI-layer need know nothing about these details because it submits transactions that look like data (notice the syntax quote and unquote (~)):
(comp/transact! this `[(add-person {:name ~name})])add-person in this case is not a function, but instead a mutation (which at the UI layer is just data).
The defmutation macro that is used to create mutations emits a binding for the symbol, that when
called returns the expression as namespace-resolved CLJ(S) data
(a list containing a fully-qualified symbol and the (evaluated) parameters):
;; Assume in ns.of.mutation you have:
(defmutation add-person ...)
;; Then:
user=> (require '[ns.of.mutation :refer [add-person]])
user=> (def name "Tony")
user=> (add-person {:name name})
;;=> (ns.of.mutation/add-person {:name "Tony"})This is an important point. Thus you can write transactions without the need to quote:
(comp/transact! this [(add-person {:name name})])The core point is that the UI submits an abstract bit of data to Fulcro’s transaction system. The UI doesn’t usually directly manipulate anything to do with the database, networking, or any other async APIs.
Mutations are written as separate code units using defmutation, which has a notation somewhere between defn and
defrecord with a protocol:
(defmutation add-person [params]
(action [env] ...)
(remote [env] ...)
(rest [env] ...)
(ok-action [env] ...)
(error-action [env] ...))where each "section" represents how that particular mutation interacts with the world around it.
The action section describes what happens locally and optimistically to the client database before any networking.
This is the main place where you manipulate the graph database (via swap!/merge/etc. on it).
The remote sections (which is any section not ending in -action) describe how that mutation should interact with some particular server (you name them, and remote is the default name).
Remotes are defined at a top-level of the application so that networking code is not mixed into the mutations at all.
Remotes usually just return true
to indicate that the mutation should be forwarded on to the server it represents (unchanged), but they can also make decisions based on state and even "rewrite" the transaction that will flow over the network.
Other *-action sections have to do with handling network results as they occur.
Thus a simple UI call can turn into a combination of optimistic actions, remote interactions, etc.
Mutations are allowed to submit new transactions themselves, so sections like ok-action can check results of remote interactions and then decide what to do, if anything, next.
Mutations, as in GraphQL, can return graph results. Fulcro, of course, can auto-merge those into the client database.
3.7. Additional Items of Interest
The prior sections describe the core points of Fulcro’s architecture. Data flows in and out via graph queries and mutations that can easily manipulate a local normalized graph database in a unified way. Remote interactions are managed by mutation declarations and all side-effecting and asynchrony is isolated from the UI layer by a CQRS-style transactional semantic. Fulcro leverages the idents, immutable data structures, co-located queries, and other tricks to optimize refresh.
Here are some additional interesting things that fall out of this model "for free":
-
Initial application state can also be co-located as a superb optimization for "getting things going".
-
The queries can be used to "traverse" the declarative UI graph. Some places where this has been used to good effect:
-
Error checking: The
defscmacro leverages the co-located query to check things like your props destructuring and initial state to warn you when you’ve got a typo or have forgotten something. -
Nested forms can "discover" children using the query and leverage that to calculate diffs for server interactions.
-
UI screen routers can discover nested routers allowing UI sub-module composition for things like HTML 5 routing without explicit declaration.
-
-
Debugging is a relatively simple matter of looking at a component’s current state, which is always in a well-defined location (and easily visible in Fulcro Inspect, a Chrome extension).
-
History traversal is trivial. All application state is just a single immutable map. Saving snapshots over time is all it takes to be able to "view" the app as it existed at some prior point in time.
-
Snapshotting an application state for re-use during development. Fulcro Inspect can take a picture of app state and save it in browser local storage for later restoration. This allows you to "jump to" some application state that you use a lot during development (e.g. jump to screen 2, with a partially filled form ready to submit).
Finally, a more recent addition to the library has proven to be extremely useful: UI State Machines.
Most UIs end up with a mess of logic spread out in ways that are hard to reason about. Look no further than any "login" module of an application. Are you logged in? Are we checking the server to see if our session is valid? Should I show a "wait" indicator?
We’ve known for years that state machines are a great way to manage this kind of complexity, but they are traditionally a bit of work to integrate into any given "UI library".
Fulcro’s central normalized database and mutation model made an internal version of state machines a very good match. Not only is it easy to define them, the model makes them reusable: that is to say you can indicate which UI components serve roles within the machine, leading to things like CRUD state machines that can manage the interactions (edit, list, save, reset, cancel, etc.) for most of the entities in a form system.
4. Core Concepts
This chapter covers some detail about the core library features and theory that are important in the Fulcro ecosystem. You need not read this chapter to use Fulcro, but it will aid in your understanding of it quite a bit, especially if you’re relatively new to Clojurescript.
4.1. Immutable Data Structures
Many of the most interesting and compelling features of Fulcro are directly or indirectly enabled (or made simpler) by the use of persistent data structures that are a first-class citizen of the language.
In imperative programming languages like Java and Javascript you have no idea what a function or method might do to your program state:
Person p = new Person();
doSomethingOnAnotherThread(p);
p.fumble();
// did p just change??? Did I just cause a race condition???This leads to all sorts of subtle bugs and is arguably the source of many of
the hardest problems in keeping software sustainable today. What if Person couldn’t
change and you instead had to copy instead if you wanted to modify?
Person p = new Person();
doSomethingOnAnotherThread(p);
Person q = p.fumble();
// p is definitely unchanged, but q could be differentNow you can reason about what will happen. The other thread will see p exactly as
it was when you (locally) reasoned about it. Furthermore, q cannot be affected
because if p is truly "read-only" then I still know what it is when I use it to
derive q (the other thread can’t modify it either).
In order to derive these benefits you need to either write objects that enforce this behavior (which is highly inconvenient and hard to make efficient in imperative languages), or use a programming language that supplies the ability to do so as a first-class feature.
Another benefit is that persistent data structures can do structural sharing. Basically the new version of a map, vector, list, or set can use references to point to any parts of the old version that are still the same in the new version. This means, for example, that adding an element to the head of a list that had 1,000,000 entries (where only one is being changed) is still a constant time operation!
Here are some of the features in Fulcro that trivially result from using persistent data structures:
-
A Time-travel UI history viewer that consumes little space.
-
Extremely efficient detection of data changes that affect the UI (can be ref compare instead of data compare)
-
"Pure Rendering" is possible and convenient without having to resort to hidden variables in the UI.
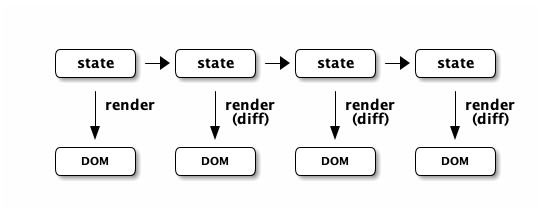
4.2. Pure Rendering
Fulcro’s default rendering system uses Facebook’s React to accomplish updates to the browser DOM. React, in concept, is really simple:
Render is a function you make that generates a data structure known as the VDOM (a lightweight virtual DOM)
-
On the first "frame", the real DOM is made to match this data structure.
-
On every subsequent frame, render is used to make a new VDOM. React compares the prior VDOM (which is cached) to the new one, and then applies the changes to the DOM.
The cool realization the creators of React had was that the DOM operations are slow and heavy, but there are efficient ways to figure out what needs to be changed via the VDOM without you having to write a bunch of controller logic.
Now, because React lives in a mutable space (JavaScript), it allows all sorts of things that can embed "rendering logic" within a component. This sounds like a good idea to our OOP brains, but consider this:
What if you could have a complete snapshot of the state of your application, pass that to a function, and have the screen just "look right". Like writing a 2D game: you just redraw the screen based on the new "state of the world". All of the sudden your mind shifts away from "bit twiddling" to thinking more about the representation of your model with minimal data!
That is what we mean by "pure rendering".
Here’s an example to whet your appetite: Nested check-boxes. In imperative programming each checkbox has its own state, and when we want a "check all" we end up writing nightmares of logic to make sure the thing works right because we’re having to store a mutable value into an object that then does the rendering. Then we play with it and find out we forgot to handle that event where some sub-box gets unchecked to fire an event to ensure to uncheck the "check all"…oh wait, but when I do that it accidentally fires the event from "check all" which unchecks everything and then goes into an infinite loop!
What a mess! Maybe you eventually figure out something that’s tractable, but that extra bit of state in the "check all" is definitely the source of bugs.
Here’s what you do in pure rendering with immutable data:
Each sub-item checkbox is a simple data structure with a :checked? key that has a boolean
value. You use that to directly tell the checkbox what its state should be
(and React enforces that…making it impossible for the UI to draw it any
differently)
(def state {:items [{:id :a :checked? true} {:id :b :checked? false} ...]})For a "state of the world", these are read-only. (you have to make a "new
state of the world" to change one). When you render, the state of the
check-all is just the conjunction of its children’s :checked?:
(let [all-checked (every? :checked? (get state :items)]
(dom/input {:checked all-checked}))The check-all button would have no application state at all, and React will force it to the correct state based on the calculated value. When the sub-items change, a new "state of the world" is generated with the altered item:
(def next-state (assoc-in state [:items 0 :checked?] false))and the entire UI is re-rendered (React makes this fast using the VDOM diff), the "check all" checkbox will just be right!
If the "check all" button is pressed, then the logic is similarly very simple: change the state for the subitems to checked if any were unchecked, or set them all to unchecked if they were all checked:
(def next-state-2
(let [all-checked? (every? :checked? (get state :items))
c (not all-checked?)
old-items (get state :items)
new-items (mapv #(assoc % :checked? c) old-items)]
(assoc state :items new-items)))and again you get to pretend you’re rendering an entire new frame on the screen!
You’ll be continually surprised at how simple your logic gets in the UI once you adjust to this way of thinking about the problem.
4.3. Data-Driven
Data-driven concepts were pioneered in web development by Facebook’s GraphQL and Netflix’s Falcor. The idea is quite powerful, and eliminates huge amounts of complexity in your network communication and application development.
The basic idea is this: Your UI, which might have various versions (mobile, web, tablet) all have different, but related, data needs. The prevalent way of talking to our servers is to use REST, but REST itself isn’t a very good query 'or' update language. It creates a lot of complexity that we have to deal with in order to do the simplest things. In the small, it is "easy". In the large, it isn’t the best fit.
Data-driven applications basically use a more detailed protocol that allows the client UIs to specify what they need, and also typically includes a "mutation on the wire" notation that allows the client to abstractly say what it needs the server to do.
So, instead of /person/3 you can instead say "I need person 3, but only their
name, age, and billing info. But in the billing info, I only need to know their
billing zip code".
Notice that this abstract expression (which of course has a syntax we’re not showing you yet) is "walking a graph". This is why Facebook calls their language "GraphQL".
You can imagine that the person and billing info might be stored in two tables of a database, with a to-one relationship, and our query is basically asking to query this little sub-graph:

Modifications are done in a similar, abstract way. We model them as if they were "function calls on the wire". Like RPC/RMI:
'(change-person {:id 3 :age 44})but instead of actually 'calling' the function, we encode this list as a data structure (it is a list containing a symbol and a map: the power of Clojure!) and then process that data locally (in the back-end of the UI) and optionally also transmit it 'as data' over the wire for server processing!
4.4. Graph Database
The client-side of Fulcro keeps all relevant data in a simple graph database, which is referenced by a single top-level atom. The database itself is a persistent map.
The database should be thought of as a root-level node (the top-level map itself), and tables that can hold data relevant to any particular component or entity in your program (component or entity nodes).
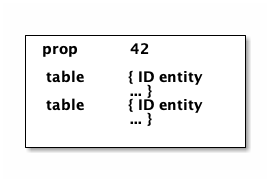
The tables are also simple maps, with a naming convention and well-defined structure. The name of the table is typically namespaced with the "kind" of thing you’re storing, and has a name that indicates the way it is indexed:
{ :person/id { 4 { :person/id 4 :person/name "Joe" }}}
; ^ ^ ^ ^
; kind table id entity value itself4.4.1. Idents
Items are joined together into a graph using a tuple of the table name and the key of
an entity. For example, the item above is known as [:person/id 4]. Notice that this
tuple is also exactly the vector you’d need in an operation that would pull data from that
entity or modify it:
(update-in state-db [:person/id 4] assoc :person/age 33)
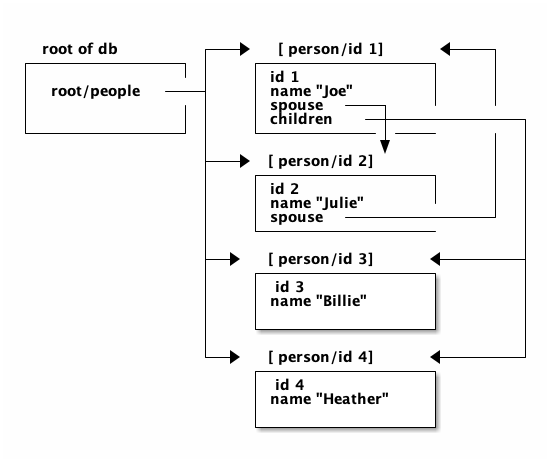
(get-in state-db [:person/id 4])These tuples are known as 'idents'. Idents can be used anywhere one node in the graph needs to point to another. If the idents (which are vectors) 'appear' in a vector, then you are creating a 'to-many' relation:
{ :person/id
{ 1 {:person/id 1 :person/name "Joe"
:person/spouse [:person/id 2] ; (1)
:person/children [ [:person/id 3]
[:person/id 4] ] } ; (2)
2 { :person/id 2
:person/name "Julie"
:person/spouse [:person/id 1]} ; (3)
3 { :person/id 3
:person/name "Billy" }
4 { :person/id 4
:person/name "Heather"}}-
A to-one relation to Joe’s spouse (Julie)
-
A to-many relation to Joe’s kids
-
A to-one relation back to Joe from Julie
Notice in the example above that Joe and Julie point at each other. This creates a 'loop' in the graph. This is perfectly legal. Graphs can contain loops. The table in the example contains 4 nodes.
The client database treats the 'root' node as a special set of non-table properties in the top of the database map. Thus, an entire state database with 'root node' properties might look like this:
This makes for a very compact representation of a graph with an arbitrary number of nodes and edges. All nodes but the special "root node" live in tables. The root node itself is special because it is the storage location for both root properties and for the tables themselves.
|
Important
|
Since the root node and the tables containing other nodes are merged together into the same overall map it is important that you use care when storing things so as not to accidentally collide on a name. Larger programs should namespace all keywords. |
4.4.2. A Special Note about The Client-Side Database
The graph database on the client is the most central and key concept to understand in Fulcro. Remember that we are doing pure rendering. This means that the UI is simply a function transforming this graph database into the UI.
There are two primary things to write in Fulcro: the UI and the mutations. The UI pulls data from this database and displays it. The mutations evolve this database to a new version. Every interaction that changes the UI should be thought of as a data manipulation. You’re making a new state of the world that your pure renderer turns into DOM.
The graph format of the database means that your data manipulation, the main dynamic thing in the entire application, is simplified down to updating properties/nodes, which themselves live at the top of the state atom or are only 2-3 levels deep:
; change the root list of people, and modify the name and age of person 2
(swap! state (fn [s]
(-> s
(assoc :root/people [[:person/id 1] [:person/id 2]])
(assoc-in [:person/id 2 :person/name] "George")
(assoc-in [:person/id 2 :person/age] 33))))For the most part the UI takes care of itself. Clojure has very good functions for manipulating maps and vectors, so even when your data structures get more complex the task is still about as simple as it can be.
4.4.3. Client Database Naming Conventions
We recommend the following naming conventions to avoid accidental data collisions in your database and to better understand your data:
| UI-only Properties |
|
| Tables |
|
| Root properties |
|
| Node properties |
|
| Singleton Components |
Use a constant ident for components that are singleton UI elements. I prefer |
5. Getting Started
This chapter takes you through a step-by-step guide of how to go from nothing to a full-stack basic application. Concepts are introduced as we go, and given a very cursory definition in the interest of concision. Once you’ve got the general idea you can use other materials to refine your understanding.
|
Important
|
This document assumes you’re working with Fulcro 3.x and above. Please see older version of the Developer’s Guide if you’re working with an older version. |
5.1. Install Fulcro Inspect
You should use Chrome for development because we have a developer tool called Fulcro Inspect that is available from the Chrome store for free.
There are also devtools that are installed via preloads which will autoformat EDN that is sent via console.log.
When properly configured, these tools will let you view the internal state of your Fulcro application, the local and remote transaction history, save "snapshots" of state so you can quickly retry a UI flow by hitting a "reset" button, "scroll" over state history and watch the UI change, run queries (with autocomplete if you’re using Pathom) against your EQL server, and even (via binaryage devtools) source-level debug your Fulcro application in CLJS with stack frame analysis and proper clojure names for things!
These tools will save you countless hours of frustration.
Fulcro Inspect is a free extension for Chrome, and Binaryage devtools is a library that can be injected via a preload (which shadow-cljs does for you if it is in your dependencies).
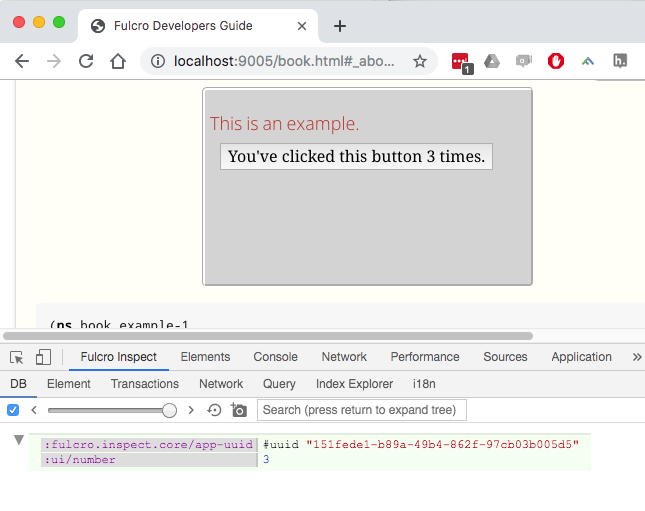
All of the examples in the book have a "Focus Inspector" button. If you open Chrome devtools, choose the Fulcro Inspect tab, and then press that button you will focus the inspector on that example so you can see its database. The first example in this book looks like this when you do that:
5.2. Configure Chrome Development Settings
You should open the Chrome developer tools (e.g. console and such). Edit the developer tool settings and change:
-
Under "Console": "Enable Custom Formatters"
-
Under "Network": "Disable Cache (while devtools is open)"
and always keep devtools open when you’re working on your apps. This ensures you’ll not be confused by caching issues and will be able to see clojure data structures as Clojure, and not low-level JS objects.
5.3. Install Supporting Tools
You’ll normally want to build a real application based on the Fulcro template. It contains a lot of boilerplate on things like server configuration, CSRF, testing, better error message formatting, and so on. This can save you quite a bit of setup and development time.
For this chapter we’re going to start from literally nothing. These instructions should work with any UNIX-like (e.g. OSX or Linux) system. I do not use Windows, so your mileage may vary if you’re on that platform.
-
Install a Java SE Development Kit (JDK). You’ll have an easier time if you use an older version: 8. OpenJDK or the official one is fine.
-
Install Clojure CLI Tools
-
Install Node and npm: The shadow-cljs compiler uses node for all js dependencies.
-
Optional, but recommended: Install IntelliJ CE and the Cursive plugin. There are free versions of both for non-commercial use. Any programming editor will do, but if you’re doing anything large I recommend this (or Emacs/Spacemacs if (and only if) you already use it).
The following commands should work from your command line (the $ is the command prompt):
$ clj
Clojure 1.10.0
user=>(hit CTRL-D or CTRL-C to exit)
$ java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)your version may be different. In general you should use the latest version of the JDK that is compatible with Clojure, but later versions should probably work fine as well.
$ npm list
/your/directory
└── (empty)If any of these fail, diagnose your installation of those tools before continuing.
5.4. Create Your Project
Create a directory and set up a basic node project:
$ mkdir app
$ cd app
$ mkdir -p src/main src/dev resources/public
$ npm init
... answer the questions or just take defaults ...
$ npm install shadow-cljs react react-dom --save|
Warning
|
Note the version of shadow-cljs that gets installed. It is possible that it differs from what is shown in the next section. Make sure both versions match, and that you are using the latest version of Clojurescript. Using an older version of Clojuresript and a brand-new version of shadow-cljs can lead to confusing build errors. |
5.4.1. Clojure Dependencies
Create a deps.edn file with this content:
{:paths ["src/main" "resources"]
:deps {org.clojure/clojure {:mvn/version "1.10.3"}
com.fulcrologic/fulcro {:mvn/version "3.5.9"}}
:aliases {:dev {:extra-paths ["src/dev"]
:extra-deps {org.clojure/clojurescript {:mvn/version "1.10.914"}
thheller/shadow-cljs {:mvn/version "2.16.9"}
binaryage/devtools {:mvn/version "1.0.4"}
cider/cider-nrepl {:mvn/version "0.27.4"}}}}}|
Tip
|
clj-kondo support: Fulcro exports configs for the clj-kondo linter (Calva uses Clojure LSP which will import these automatically). If you are using clj-kondo with another tool you may need to import these manually. To import them, create |
5.4.2. Shadow-cljs Build Tool Configuration
And a shadow-cljs.edn file that looks like this:
{:deps {:aliases [:dev]}
:dev-http {8000 "classpath:public"}
:builds {:main {:target :browser
:output-dir "resources/public/js/main"
:asset-path "/js/main"
:dev {:compiler-options {:external-config {:fulcro {:html-source-annotations? true}}}}
:modules {:main {:init-fn app.client/init
:entries [app.client]}}
:devtools {:after-load app.client/refresh
:preloads [com.fulcrologic.fulcro.inspect.preload
com.fulcrologic.fulcro.inspect.dom-picker-preload]}}}}The init-fn and after-load options give you a place to put code that will set up an application on load, and trigger UI refreshes on hot code reload.
We’ll put those functions in the source in a moment.
The top-level dev-http server will cause shadow to start a dev web server on port 8000 that serves the files from our resources/public directory (resources is on our classpath via :paths in deps.edn). This port is used for Workspaces and test UI, which you can configure separately in shadow-cljs.edn. To access your application after Running the Server, make sure to use port 3000.
The :modules section configures what code gets pulled into a given build.
Every build has at least one module, and shadow will follow requires in the code so you typically only need your entry-point namespace in :entries.
The dev-time compiler option for source-annotations is very handy for back-tracing UI from the DOM to the code. It adds a data-fulcro-source attribute to every DOM node generate by a DOM macro (CLJS can have function and macros bound to the same symbol). The macro will be used IF you provide any props, even as an empty map or nil). For example:
(mapv dom/div ["a" "b"]) ; uses DOM function. Will NOT have the source attribute
(dom/div nil "a") ; uses the DOM macro. WILL have source annotation if compiler option is on
(dom/div {} "a") ; uses the DOM macro. WILL have source annotation if compiler option is onso in Chrome dev tools, when the option is on and the macro is used, you’ll see the source code namespace and line like this:
<div data-fulcro-source="com.example.myns:34">a</div>|
Note
|
using the macro versions of dom factories not only gives you good debugging info, it emits vanilla js (and pre-converts clj prop maps to js objects at COMPILE time). This means it emits code that is identical to what JSX with babel would do, so there is no performance hit for interop! |
See the Shadow-cljs User’s Guide for more information.
5.4.3. HTML File
In resources/public/index.html add this content:
<html>
<meta charset="utf-8">
<body>
<div id="app"></div>
<script src="/js/main/main.js"></script>
</body>
</html>We really only need to load our one (generated) JS file and supply a div with an ID. Our React application will be rendered on that div.
You may, of course, include other content around that:
CSS, other divs, etc.
5.4.4. Application Source
Our base source path is src/main for production code, and we want a namespace within the app package.
Our directory structure must match this in CLJ(S), so we create src/main/app/client.cljs:
(ns app.client
(:require
[com.fulcrologic.fulcro.application :as app]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]))
(defonce app (app/fulcro-app))
(defsc Root [this props]
(dom/div "TODO"))
(defn ^:export init
"Shadow-cljs sets this up to be our entry-point function. See shadow-cljs.edn `:init-fn` in the modules of the main build."
[]
(app/mount! app Root "app")
(js/console.log "Loaded"))
(defn ^:export refresh
"During development, shadow-cljs will call this on every hot reload of source. See shadow-cljs.edn"
[]
;; re-mounting will cause forced UI refresh, update internals, etc.
(app/mount! app Root "app")
;; As of Fulcro 3.3.0, this addition will help with stale queries when using dynamic routing:
(comp/refresh-dynamic-queries! app)
(js/console.log "Hot reload"))5.4.5. Summary
Your project source tree should now look like this:
$ tree -I node_modules .
.
├── deps.edn
├── package.json
├── resources
│ └── public
│ ├── index.html
├── shadow-cljs.edn
└── src
└── main
└── app
└── client.cljsThat’s it! You have a complete Fulcro application!
5.4.6. Build It!
You can start shadow-cljs' server mode with:
$ npx shadow-cljs serverand then navigate to the URL it prints out for the server UI (usually http://localhost:9630). You can then use the "Builds" menu to turn on/off different client builds and see the progress live as it happens!
|
Warning
|
Pay attention to that last sentence. The server mode of shadow-cljs does NOT start any particular
build. It starts a Web UI that can be used to control the builds. There is also a watch mode, but this mode
is not as flexible in real circumstances, and I highly recommend you use server mode instead. See the User’s Guide
of Shadow-cljs for more information.
|
It also has hot-code (and CSS) reload built in, so there is no need for any additional tools!
Build your app now by selecting "main" under the "Builds" menu and clicking "start watch".
We configured the shadow-cljs server to also start a development mode HTTP server to serve our HTML file and javascript.
So, if you didn’t make any typos then your new app should display "TODO" at
http://localhost:8000.
5.4.7. Using the REPL
Shadow-cljs creates a network REPL for your clojurescript program.
You can actually use a limited REPL via the shadow-cljs control web page (the one at port 9630).
If you look at the command-line startup output you’ll also see it report a port number on which you can connect a more advanced REPL (you can nail that port to a constant using the setting :nrepl {:port 9000} at the top-level of shadow-cljs.edn).
If you’re using IntelliJ, edit your run configurations and add a "Clojure → Remote REPL".
Give it localhost
for the host, and the port reported by shadow’s startup message.
Once you connect to the network REPL you’ll have to select the build you want to work against (and you must already have that application running in a browser). Just run:
user=> (shadow/repl :main)to cause it to change over to a CLJS REPL connected to your running application.
Now running (js/alert "Hi") should cause the browser to throw up an alert on your application’s tab.
5.5. Basic UI Components
Fulcro supplies a defsc macro to build React components.
This macro emits class-based React components (or, with :use-hooks? true, a pure functions with hooks support).
These components are augmented with Fulcro’s data management and render refresh.
There are also factory functions for generating all standard HTML5 DOM elements in React in the
com.fulcrologic.fulcro.dom namespace.
The basic code to build a simple component has the following form:
(defsc ComponentName
[this props] ; parameters. Available in body, and in *some* of the options
; optional: { ...options... }
(dom/div {:className "a" :id "id" :style {:color "red"}}
(dom/p "Hello")))This macro emits the equivalent of a React component with a render method.
You can tighten your DOM code up even more if you also :refer the common tags in your namespace declaration:
(ns app.client
(:require
[com.fulcrologic.fulcro.dom :as dom :refer [div p]]))
(defsc ComponentName [this props]
{ ...options... }
(div {:className "a" :id "id" :style {:color "red"}}
(p "Hello")))React lifecycle methods are all supported, but we’ll talk about those later.
5.5.1. The render method.
The body of defsc is the render for the component and can do whatever work you need, but it should be a "pure" function of the parameters and return a react element (see React Components, Elements, and Instances).
As of React 16 you can return a fragment or sequence of elements as well (though each must have a unique :key).
The DOM element functions allow class names and IDs to be written in various forms for convenience. The following are all equivalent:
(dom/div {:id "id" :className "x y z" :style {:color "red"}} ...)
(dom/div :.x#id {:className "y z" :style {:color "red"}} ...)
(dom/div :.x.y.z#id {:style {:color "red"}} ...)
(dom/div :.x#id {:classes ["y" "z"] :style {:color "red"}} ...)|
Note
|
The keyword notation requires each class to be preceded by a ., and will give a compile error if you forget to do that.
|
Children simply placed after the props as nested children.
|
Important
|
If you’re writing your UI in CLJC files then you need to make sure you use a conditional reader to pull in the proper server DOM functions for Clojure: |
(ns app.client
(:require #?(:clj [com.fulcrologic.fulcro.dom-server :as dom]
:cljs [com.fulcrologic.fulcro.dom :as dom]))
... the actual code is the same as beforeThe reason this is necessary is that CLJS requires macros to be in CLJ files, but in order to get higher-order functions to operate in CLJ the DOM elements must be functions. In CLJS, you can have both a macro and function with the same name, but this is not true in CLJ. Therefore, two namespaces are required in order to get the optimal (inlined) client performance.
|
Note
|
Regarding performance:
The dom macros/functions in Fulcro can be nearly as fast as calling raw React createElement
directly (the macros, in fact, directly turn into low-level js/createElement calls with compile-time conversion of the cljs props to js in the optimal case), even when using the convenience features; however, the macros cannot make them that fast if there is ambiguity about the props vs. children.
For example, (div :.a (f)) is ambiguous at compile time (the expression after :.a could be a function call returning a props map or a nested React element), so it will be forced to add code that checks for a cljs map, and if it finds one, code to convert it to a js object.
Technically you can force the highest level of runtime performance by always including a props map, even if you don’t need one: (div :.a {} (f)).
This latter example has no ambiguity and the macro can at compile time convert the props to a javascript object for passing directly to React createElement.
The speed difference can be about 3-fold, but even then it is usually so small that it won’t matter, so you may want to use tighter notation unless you measure a real performance problem.
|
5.5.2. Props
React components receive their data through props and state (which is local mutable state on the component).
In Fulcro you will usually use props for most things.
The data passed to a component can be accessed (as a CLJS map) by calling comp/props on this, or by destructuring in the second argument of defsc.
So, let’s define a Person component in src/main/app/client.cljs to display details about a person.
We’ll assume that we’re going to pass in name and age as properties:
(defsc Person [this {:person/keys [name age]}]
(dom/div
(dom/p "Name: " name)
(dom/p "Age: " age)))Now, in order to use this component we need an element factory.
An element factory lets us use the component within our React UI tree.
Name confusion can become an issue (Person the component vs. person the factory?) we recommend prefixing the factory with ui-:
(def ui-person (comp/factory Person))Now we can compose people into our root:
(defsc Root [this props]
(dom/div
(ui-person {:person/name "Joe" :person/age 22})))5.5.3. Hot Code Reload
Part of our quick development story is getting hot code reload to update the UI whenever we change the source.
Try editing the UI of Person and save.
You should see the UI update even though the person’s data didn’t change.
5.5.4. Organizing Source
At this point it is a good idea to adopt some code organization. The application itself might be needed from any number of namespaces, so having it mixed in with things can easily lead to circular requires, which are not allowed in Clojure(script).
To avoid this, we’ll create src/main/app/application.cljs and put this content there:
(ns app.application
(:require
[com.fulcrologic.fulcro.application :as app]))
(defonce app (app/fulcro-app))You probably want to move your actual UI tree to a new namespace for similar reasons.
Create a new file src/main/app/ui.cljs with this content:
(ns app.ui
(:require
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]))
(defsc Person [this {:person/keys [name age]}]
(dom/div
(dom/p "Name: " name)
(dom/p "Age: " age)))
(def ui-person (comp/factory Person))
(defsc Root [this props]
(dom/div
(ui-person {:person/name "Joe" :person/age 22})))and now you can trim your client.cljs down to just the initialization code:
(ns app.client
(:require
[app.application :refer [app]]
[app.ui :as ui]
[com.fulcrologic.fulcro.components :as comp]
[com.fulcrologic.fulcro.application :as app]))
(defn ^:export init []
(app/mount! app ui/Root "app")
(js/console.log "Loaded"))
(defn ^:export refresh []
;; re-mounting will cause forced UI refresh
(app/mount! app ui/Root "app")
;; 3.3.0+ Make sure dynamic queries are refreshed
(comp/refresh-dynamic-queries! app)
(js/console.log "Hot reload"))Splitting up your source will also typically help with overall incremental compilation speed.
5.5.5. Composing
You should already be getting the picture that your UI is going to be a tree composed from a root element. The method of data passing (via props) should also be giving you the picture that supplying data to your UI (through root) means you need to supply an equivalently structured tree of data. This is true of basic React. However, just to drive the point home let’s make a slightly more complex UI and see it in detail:
Replace your UI content with this:
(defsc Person [this {:person/keys [name age]}]
(dom/li
(dom/h5 (str name " (age: " age ")"))))
;; The keyfn generates a react key for each element based on props. See React documentation on keys.
(def ui-person (comp/factory Person {:keyfn :person/name}))
(defsc PersonList [this {:list/keys [label people]}]
(dom/div
(dom/h4 label)
(dom/ul
(map ui-person people))))
(def ui-person-list (comp/factory PersonList))
(defsc Root [this {:keys [ui/react-key]}]
(let [ui-data {:friends {:list/label "Friends" :list/people
[{:person/name "Sally" :person/age 32}
{:person/name "Joe" :person/age 22}]}
:enemies {:list/label "Enemies" :list/people
[{:person/name "Fred" :person/age 11}
{:person/name "Bobby" :person/age 55}]}}]
(dom/div
(ui-person-list (:friends ui-data))
(ui-person-list (:enemies ui-data)))))So that the UI graph looks like this:
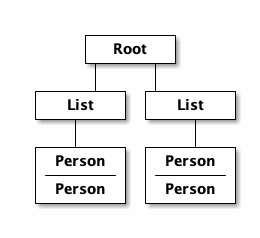
and the data graph matches the same structure, with map keys acting as the graph "edges":
{ :friends { :list/people [PERSON ...]
; ==to-one list=> ==to-many people==>
:enemies { :list/people [PERSON ...] }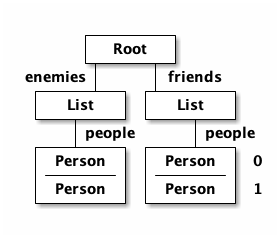
5.6. Feeding the Data Tree
Obviously it isn’t going to be desirable to hand-manage this very well for anything but the most trivial application (which is the crux of the problems with most UI libraries).
At best it does give us a persistent data structure that represents the current "view" of the application (which has many benefits), but at worst it requires us to "think globally" about our application. We want local reasoning. We also want to be able to easily re-compose our UI as needed, and a static data graph like this would have to be updated every time we made a change! Almost equally as bad: if two different parts of our UI want to show the same data then we’d have to find and update a bunch of copies spread all over the data tree.
So, how do we solve this?
5.6.1. Why not have components just "grab" their data (sideband)?
This is certainly a possibility; however, it leads to other complications. What is the data model? How do you interact with remotes to fill your data needs? Fulcro has a very nice cohesive story for these questions, while other systems end up with complications like event handler middleware, data management instances or modules peppered through the code, etc.
Fulcro has a model for all of this, and it is surprising how simple it makes your application once you put it all together. Let’s look at the steps and parts:
5.6.2. Step 1 — The Initial State
All applications have some starting initial state. Since our UI is a tree, our starting state needs to somehow establish what goes into the initial nodes and edges of the local client database.
In Fulcro there is a way to construct the initial tree of data in a way that allows for local reasoning and easy refactoring: co-locate the initial desired part of the tree with the component that uses it. This allows you to compose the state tree in exactly the same way as the UI tree.
The defsc macro makes short work of this with the initial-state option.
Simply give it a lambda that gets parameters (optionally from the parent) and returns a map representing the state of the component.
You can retrieve this data using (comp/get-initial-state Component).
It looks like this:
(ns app.ui
(:require
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]))
(defsc Person [this {:person/keys [name age]}]
{:initial-state (fn [{:keys [name age] :as params}] {:person/name name :person/age age}) }
(dom/li
(dom/h5 (str name "(age: " age ")"))))
(def ui-person (comp/factory Person {:keyfn :person/name}))
(defsc PersonList [this {:list/keys [label people]}]
{:initial-state
(fn [{:keys [label]}]
{:list/label label
:list/people (if (= label "Friends")
[(comp/get-initial-state Person {:name "Sally" :age 32})
(comp/get-initial-state Person {:name "Joe" :age 22})]
[(comp/get-initial-state Person {:name "Fred" :age 11})
(comp/get-initial-state Person {:name "Bobby" :age 55})])})}
(dom/div
(dom/h4 label)
(dom/ul
(map ui-person people))))
(def ui-person-list (comp/factory PersonList))
; Root's initial state becomes the entire app's initial state!
(defsc Root [this {:keys [friends enemies]}]
{:initial-state (fn [params] {:friends (comp/get-initial-state PersonList {:label "Friends"})
:enemies (comp/get-initial-state PersonList {:label "Enemies"})}) }
(dom/div
(ui-person-list friends)
(ui-person-list enemies)))|
Note
|
You must reload your browser for this to show up. Fulcro pulls this data into the database when the application first mounts, not on hot code reload (because that would change your app state, and hot code reload is more useful without state changes). |
Now a lot of the specific data here is just for demonstration purposes.
Data like this (people) would almost certainly come from a server, but it serves to illustrate that we can localize the initial data needs of a component to the component, and then compose that into the parent in an abstract way (by calling get-initial-state against that child).
There are several benefits of this so far:
-
It generates the exact tree of data needed to feed the initial UI.
-
That initial state becomes your initial application database.
-
It restores local reasoning (and easy refactoring). Moving a component just means local reasoning about the component being moved and the component it is being moved from/to: You remove the
get-initial-statefrom one parent and add it to a different one.
You can see that there is no magic if you just pull the initial tree at the REPL:
dev:cljs.user=> (com.fulcrologic.fulcro.components/get-initial-state app.ui/Root {})
{:friends {:list/label "Friends",
:list/people [{:person/name "Sally", :person/age 32} {:person/name "Joe", :person/age 22}]},
:enemies {:list/label "Enemies",
:list/people [{:person/name "Fred", :person/age 11} {:person/name "Bobby", :person/age 55}]}}|
Note
|
The REPL shown here is a CLJS REPL. Shadow-cljs makes a REPL port available when it starts.
If you connect to it (as a Remote REPL in IntelliJ) you can interact with a live browser session by first typing (shadow/repl :main) (where :main is the name of the build).
This requires a browser be actively running the build output.
|
It’s nothing more than function composition.
The initial state option on defsc encodes your initial state into a function that can be accessed via get-initial-state on a class.
So behind the scenes Fulcro detects the initial state on the first mount and automatically uses it to initialize your application state.
By default, the entire initial state database is passed into your root node on render, so it is available for destructuring in Root’s props.
If you want to see your current application state, you can do so through the app itself:
dev:cljs.user=> (com.fulcrologic.fulcro.application/current-state app.application/app)but you’ll usually look at this state via the Fulcro Inspect Chrome development tool.
Let’s move on and see how we program our UI to access the data in the application state!
5.6.3. Step 2 — Establishing a Query
Fulcro unifies the data access story using a co-located query on each component. This sets up data access for both the client and server, and also continues our story of local reasoning and composition.
Queries go on a component in the same way as initial state: in the options map.
The query notation is relatively light, and we’ll just concentrate on two bits of query syntax: props and joins.
Queries form a tree just like the UI and data. Obtaining a value at the current node in the tree traversal is done using the keyword for that value. Walking down the graph (a join) is represented as a map with a single entry whose key is the name (keyword) for that nested bit of state.
So, a data tree like this:
{:friends
{:list/label "Friends",
:list/people
[{:person/name "Sally", :person/age 32}
{:person/name "Joe", :person/age 22}]},
:enemies
{:list/label "Enemies",
:list/people
[{:person/name "Fred", :person/age 11}
{:person/name "Bobby", :person/age 55}]}}would have a query that looks like this:
[{:friends ; JOIN
[ :list/label
{:list/people ; JOIN
[:person/name :person/age]}]}
{:enemies ; JOIN
[ :list/label
{:list/people ; JOIN
[:person/name :person/age]}]}]This query reads "At the root you’ll find :friends, which joins to a nested entity that has a label and people.
People, in turn, is a join that has nested properties name and age.
-
A vector always means "get this stuff at the current node". Note that this is a relative (to the current node) statement.
-
:friendsis a key in a map, so at the root of the application state the query engine would expect to find that key, and would expect the value to be nested state (because maps mean joins on the tree) -
The value in the
:friendsjoin is a subquery, and therefore must be a vector because we have to indicate what we want out of the nested data.
Joins are automatically to-one if the data found in the state is a singular, and to-many if the data found is a vector.
In the example above the :friends field from root pointed to a single PersonList, whereas the PersonList
field :list/people pointed to a vector of Person data.
Beware that you don’t confuse yourself with naming (e.g. friends is plural, but points to a single UI element that represents a single list, which in turn owns the items of that list).
The namespacing of keywords in your data (and therefore your query) is highly encouraged, as it makes it clear to the reader what kind of entity you’re working against (it also ensures that over-rendering doesn’t happen on refreshes later). Furthermore, it enables the full potential of Pathom when you get to the server interactions.
You can try this query stuff out in your REPL. Let’s say you just want the friends list label.
The function
fdn/db→tree can take an application database (which we can generate from initial state) and run a query against it:
dev:cljs.user=> (fdn/db->tree [{:friends [:list/label]}] (comp/get-initial-state app.ui/Root {}) {})
{:friends {:list/label "Friends"}}HINT:
The mirror of initial state with query is a great way to error-check your work (and defsc does some of that for you):
For each scalar property in initial state, there should be an identical simple property in your query.
For each join of initial state to a child via get-initial-state there should be a query join via get-query to that same child.
Adding Queries to Our Example
We want our queries to have the same nice local-reasoning as our initial data tree.
The get-query function works just like the get-initial-state function, and can pull the query from a component.
The get-query function actually augments the subqueries with metadata that is important at a later stage.
So, the Person component queries for just the properties it needs:
(defsc Person [this {:person/keys [name age]}]
{:query [:person/name :person/age]
:initial-state (fn [{:keys [name age] :as params}] {:person/name name :person/age age})}
(dom/li
(dom/h5 (str name "(age: " age ")"))))Notice that the entire rest of the component did not change.
Next up the chain, we compose the Person query into PersonList (notice how the composition of state and query are mirrored):
(defsc PersonList [this {:keys [list/label list/people]}]
{:query [:list/label {:list/people (comp/get-query Person)}]
:initial-state
(fn [{:keys [label]}]
{:list/label label
:list/people (if (= label "Friends")
[(comp/get-initial-state Person {:name "Sally" :age 32})
(comp/get-initial-state Person {:name "Joe" :age 22})]
[(comp/get-initial-state Person {:name "Fred" :age 11})
(comp/get-initial-state Person {:name "Bobby" :age 55})])})}
(dom/div
(dom/h4 label)
(dom/ul
(map ui-person people))))again, nothing else changes.
5.6.4. Step 3 — Receive the Data Feed as Props in Root
Finally, we compose to Root:
(defsc Root [this {:keys [friends enemies]}]
{:query [{:friends (comp/get-query PersonList)}
{:enemies (comp/get-query PersonList)}]
:initial-state (fn [params] {:friends (comp/get-initial-state PersonList {:label "Friends"})
:enemies (comp/get-initial-state PersonList {:label "Enemies"})})}
(dom/div
(ui-person-list friends)
(ui-person-list enemies)))This all looks like a minor (and somewhat wordy) addition; However, we’re getting close to the magic, so stick with us. The major difference in this code is that even though the database starts out with the initial state, there is nothing to say we have to query for everything that is in there, or that the state has to start out with everything we might query for in the future. We’re getting close to having a dynamic data-driven application.
Notice that everything we’ve done so far has global client database implications, but that each component codes only the local portion it is concerned with. Local reasoning is maintained. All software evolution in this model preserves this critical aspect.
Also, you now have application state that can evolve (the query is running against the active application database stored in an atom).
|
Important
|
You should always think of the query as "running from root".
You’ll notice that Root still expects to receive the entire data tree for the UI (even though it doesn’t have to know much about what is in it, other than the names of direct children), and it still picks out those sub-trees of data and passes them on.
In this way an arbitrary component in the UI tree is not querying for its data directly in a side-band sort of way, but is instead being composed in from parent to parent all the way to the root.
Later, we’ll learn how Fulcro can optimize this and pull the data from the database for a specific component, but the reasoning will remain the same.
|
5.7. Passing Callbacks and Other Parent-computed Data
The queries on components describe what data the component wants from the database; however, you’re not allowed to put code in the database, and sometimes a parent might compute something it needs to pass to a child like a callback function.
It turns out that we can optimize away the refresh of components (if their data has not changed). This means that we can use a component’s query to directly re-supply data for refresh; however, since doing so skips the rendering of the parent. If we are not careful this can lead to "losing" these extra bits of computationally generated data passed from the parent, like callbacks.
Let’s say we want to render a delete button on our individual people in our UI. This button will mean "remove the person from this list"…but the person itself has no idea which list it is in. Thus, the parent will need to pass in a function that the child can call to affect the delete properly:
5.7.1. The Incorrect Way:
(defsc Person [this {:keys [person/name person/age onDelete]}] ; (3)
{:query (fn [] [:person/name :person/age])
:initial-state (fn [{:keys [name age] :as params}] {:person/name name :person/age age})}
(dom/li
(dom/h5 (str name " (age: " age ")") (dom/button {:onClick #(onDelete name)} "X")))) ; (4)
(def ui-person (comp/factory Person {:keyfn :person/name}))
(defsc PersonList [this {:list/keys [label people]}]
{:query [:list/label {:list/people (comp/get-query Person)}]
:initial-state
(fn [{:keys [label]}]
{:list/label label
:list/people (if (= label "Friends")
[(comp/get-initial-state Person {:name "Sally" :age 32})
(comp/get-initial-state Person {:name "Joe" :age 22})]
[(comp/get-initial-state Person {:name "Fred" :age 11})
(comp/get-initial-state Person {:name "Bobby" :age 55})])})}
(let [delete-person (fn [name] (println label "asked to delete" name))] ; (1)
(dom/div
(dom/h4 label)
(dom/ul
(map (fn [p] (ui-person (assoc p :onDelete delete-person))) people))))) ; (2)-
A function acting in as a stand-in for our real delete
-
Adding the callback into the props (WRONG)
-
Pulling the onDelete from the passed props (WRONG). The query has to be changed to a lambda to turn off error checking to even try this method.
-
Invoking the callback when delete is pressed.
This method of passing a callback will work initially, but not consistently. The problem is that we can optimize away a re-render of a parent when it can figure out how to pull just the data of the child on a refresh, and in that case the callback will get lost because only the database data will get supplied to the child! Your delete button will work on the initial render (from root), but may stop working at a later time after a UI refresh.
5.7.2. The Correct Way:
There is a special helper function that can record the computed data like callbacks onto the child that receives them such that an optimized refresh will still know them.
There is also an additional (optional) component parameter to defsc
that you can use to deconstruct them:
(defsc Person [this {:person/keys [name age]} {:keys [onDelete]}] ; (2)
{:query [:person/name :person/age]
:initial-state (fn [{:keys [name age] :as params}] {:person/name name :person/age age})}
(dom/li
(dom/h5 (str name " (age: " age ")") (dom/button {:onClick #(onDelete name)} "X")))) ; (2)
(def ui-person (comp/factory Person {:keyfn :person/name}))
(defsc PersonList [this {:list/keys [label people]}] ;
{:query [:list/label {:list/people (comp/get-query Person)}]
:initial-state
(fn [{:keys [label]}]
{:list/label label
:list/people (if (= label "Friends")
[(comp/get-initial-state Person {:name "Sally" :age 32})
(comp/get-initial-state Person {:name "Joe" :age 22})]
[(comp/get-initial-state Person {:name "Fred" :age 11})
(comp/get-initial-state Person {:name "Bobby" :age 55})])})}
(let [delete-person (fn [name] (println label "asked to delete" name))] ; (1)
(dom/div
(dom/h4 label)
(dom/ul
(map (fn [p] (ui-person (comp/computed p {:onDelete delete-person}))) people))))) ; (1)-
The
comp/computedfunction is used to add the computed data to the props being passed. -
The child adds an additional parameter, and pulls the computed data from there. You can also use
(comp/get-computed this)to pull all of the computed props in the body.
Now you can be sure that your callbacks (or other parent-computed data) won’t be lost to render optimizations.
|
Note
|
You can create a comp/computed-factory instead of a regular factory for ui-person.
The computed factory accepts props and computed as two arguments instead of having to use a nested notation.
|
5.8. Updating the Data Tree
Now the real fun begins: Making things dynamic.
Most operations that make changes to the client database should happen through the Fulcro transaction system. It is actually possible to do more advanced low-level things, but that is beyond our current scope.
5.8.1. Transactions
Every change to the application database must go through a transaction processing system. This has two goals:
-
Abstract the operation (like a function)
-
Treat the operation like data (which allows us to generalize it to remote interactions)
The operations themselves are just data and can be written as quoted data structures. Specifically as a vector of mutation invocations. The entire transaction is just data. It is not something run in the UI, but instead passed into the underlying system for processing.
You essentially just "make up" names for the operations you’d like to do to your database, just like function names. Namespacing is encouraged, and of course syntax quoting honors namespace aliases.
(comp/transact! this `[(ops/delete-person {:list-name "Friends" :person "Fred"})])is asking the underlying system to run the mutation ops/delete-person (where ops can be an alias established in the ns).
Of course, you would typically use unquote to embed data from local variables:
(comp/transact! this `[(ops/delete-person {:list-name ~name :person ~person})])|
Important
|
When you define mutations they are actually set up to return themselves as data. This allows you to avoid the need to quote in most circumstances. |
The defmutation macro returns a function-like object that just returns itself as data when called "normally":
user=> (app.mutations/delete-person {:name "Joe"})
(app.mutations/delete-person {:name "Joe"})So, here are the rules of using mutations in transact!:
-
If you can require the mutation namespace without causing circular references, then you can just "call" the mutation within the transaction as-if it were a function (avoiding quoting). The result will still just embed the mutations as raw data.
-
If you cannot require the namespace (i.e. that would cause a circular require), then you must quote it, ensure the fully-qualified namespace is correct, and unquote any data from the surrounding scope.
With the require:
(ns app.ui
(:require
[app.mutations :as api]))
...
(comp/transact! this [(api/delete-person {:list-name name ...})])Without the require:
(ns app.ui
(:require
...))
...
(comp/transact! this `[(app.mutations/delete-person {:list-name ~name ...})])Both uses generate the exact same runtime result.
5.8.2. Handling Mutations
Mutations can be defined wherever you want, but of course you need to make sure that namespace is required by files that your program already uses or they won’t end up being available at runtime.
Something like src/main/app/mutations.cljs
is fine, but you might also find it useful to place your mutations in something topical so you can write the server mutations in the CLJ version of the file, and the client ones in the cljs.
Mutations are always namespaced.
A mutation definition looks a bit like a method: It can have a docstring, and the argument list will always receive a single argument (params) that will be a map (which then allows destructuring).
The body looks a bit like a letfn, but some of the names we use for the items are pre-established.
The one we’re interested in at the moment is action, which is what to do locally.
The action method will be passed the application database’s app-state atom, and it should change the data in that atom to reflect the new "state of the world" indicated by the mutation.
For example, delete-person must find the list of people on the list in question, and filter out the one that we’re deleting:
(ns app.mutations
(:require [com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]))
(defmutation delete-person
"Mutation: Delete the person with `name` from the list with `list-name`"
[{:keys [list-name name]}] ; (1)
(action [{:keys [state]}] ; (2)
(let [path (if (= "Friends" list-name)
[:friends :list/people]
[:enemies :list/people])
old-list (get-in @state path)
new-list (vec (filter #(not= (:person/name %) name) old-list))]
(swap! state assoc-in path new-list))))-
The argument list for the mutation itself
-
The thing to do, which receives the app-state atom as an argument.
Then all that remains is to change app.ui in the following ways:
-
Add a require for app.mutations
-
Change the callback to run the correct transaction
(ns app.ui
(:require
; ADD THIS:
[app.mutations :as api])) ; (1)
...
(defsc PersonList [this {:keys [list/label list/people]}]
...
(let [delete-person (fn [name] (comp/transact! this [(api/delete-person {:list-name label :name name})]))] ; (2)
...-
The require ensures that the mutations are loaded, and also gives us an alias to the namespace of the mutation’s symbol.
-
Running the transaction in the callback.
Note that our mutation’s symbol is actually app.mutations/delete-person, but the first layer of evaluation (calling a mutation as a function just returns the call itself) will rewrite it to (app.mutations/delete-person …).
Also realize that the mutation is not running in the UI, it is instead being handled "behind the scenes".
This allows a snapshot of the state history to be kept, and also a more seamless integration to full-stack operation over a network to a server (in fact, the UI code here is already full-stack capable without any changes!).
This is where the power starts to show: all of the minutiae above is leading us to a grand unification when it comes to writing full-stack applications.
5.8.3. Hold on – Something Still Sucks!
But first, we should address a problem that many of you may have already noticed: The mutation code is tied to the shape of the UI tree!!!
This breaks our lovely model in several ways:
-
We can’t refactor our UI without also rewriting the mutations (since the data tree would change shape)
-
We can’t locally reason about any data. Our mutations have to understand things globally!
-
Our mutations could get rather large and ugly as our UI gets big
-
If a fact appears in more than one place in the UI and data tree, then we’ll have to update all of them in order for things to be correct. Data duplication is never your friend.
5.9. The Secret Sauce – Normalizing the Database
Fortunately, we have a very good solution to the mutation problem above, and it is one that has been around for decades: database normalization!
Here’s what we’re going to do:
Each UI component represents some conceptual entity with data (assuming it has state and a query). In a fully normalized database, each such concept would have its own table, and related things would refer to it through some kind of foreign key. In SQL land this looks like:
In a graph database (like Datomic) a reference can have a to-many arity, so the direction can be more natural:
Since we’re storing things in a map, we can represent "tables" as an entry in the map where the key is the table name, and the value is a map from ID to entity value. So, the last diagram could be represented as:
{:PersonList { :friends { :id :friends
:label "Friends"
:people #{1, 2} }}
:Person { 1 {:id 1 :name "Joe" }
2 {:id 2 :name "Sally"}}}This is close, but not quite good enough.
The set in :people is a problem.
There is no schema so there is no way to know which table to look in for "1" and "2"!
The solution is rather easy: code the foreign reference to include the name of the table: [:Person 1].
To-one relations are represented as a single one of these, and to-many relations as a vector of these (to preserve order).
In Fulcro [TABLE ID] is known as an ident.
So, now that we have the concept and implementation, let’s talk about conventions:
-
Properties should be namespaced:
:person/name,:account/email, etc. -
Entities are usually identified by a type-centric ID:
:person/id,:account/id, etc. -
Table names in the database are usually the same as the ID key of the entities within it (to facilitate some nice support in Pathom).
Using these conventions the prior example would have looked like this:
{:list/id { :friends { :list/id :friends
:list/label "Friends"
:list/people [[:person/id 1] [:person/id 2]] }}
:person/id { 1 {:person/id 1 :person/name "Joe" }
2 {:person/id 2 :person/name "Sally"}}}5.9.1. Automatic Normalization
Fortunately, you don’t have to hand-normalize your data. The components have everything they need to do the normalization for you, other than the actual value of the ident. So, we’ll add one more option to your components (and we’ll add IDs to the data at this point, since you can’t easily normalize things that don’t have them):
The program will now look like this:
(ns app.ui
(:require
[app.mutations :as api]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]))
(defsc Person [this {:person/keys [id name age] :as props} {:keys [onDelete]}]
{:query [:person/id :person/name :person/age] ; (2)
:ident (fn [] [:person/id (:person/id props)]) ; (1)
:initial-state (fn [{:keys [id name age] :as params}] {:person/id id :person/name name :person/age age})} ; (3)
(dom/li
(dom/h5 (str name " (age: " age ")") (dom/button {:onClick #(onDelete id)} "X")))) ; (4)
(def ui-person (comp/factory Person {:keyfn :person/id}))
(defsc PersonList [this {:list/keys [id label people] :as props}]
{:query [:list/id :list/label {:list/people (comp/get-query Person)}] ; (5)
:ident (fn [] [:list/id (:list/id props)])
:initial-state
(fn [{:keys [id label]}]
{:list/id id
:list/label label
:list/people (if (= id :friends)
[(comp/get-initial-state Person {:id 1 :name "Sally" :age 32})
(comp/get-initial-state Person {:id 2 :name "Joe" :age 22})]
[(comp/get-initial-state Person {:id 3 :name "Fred" :age 11})
(comp/get-initial-state Person {:id 4 :name "Bobby" :age 55})])})}
(let [delete-person (fn [person-id] (comp/transact! this [(api/delete-person {:list/id id :person/id person-id})]))] ; (4)
(dom/div
(dom/h4 label)
(dom/ul
(map #(ui-person (comp/computed % {:onDelete delete-person})) people)))))
(def ui-person-list (comp/factory PersonList))
(defsc Root [this {:keys [friends enemies]}]
{:query [{:friends (comp/get-query PersonList)}
{:enemies (comp/get-query PersonList)}]
:initial-state (fn [params] {:friends (comp/get-initial-state PersonList {:id :friends :label "Friends"})
:enemies (comp/get-initial-state PersonList {:id :enemies :label "Enemies"})})}
(dom/div
(ui-person-list friends)
(ui-person-list enemies)))-
Adding an ident allows Fulcro to know how to build a FK reference to a person (given its props). The
propsfrom thedefscargument list is "in scope" forident. -
We will be using IDs now, so we need to add them to the query (and props destructuring).
-
The state of the entity will also need the ID
-
The callback will now be able to delete people by their ID (see below)
-
The list will have an ID, and an Ident as well
If you reload the web page (needed to reinitialize the database state), then you can look at the newly normalized database at the REPL (NOTE: It is much easier to look at this using Fulcro Inspect in your developer tools tab):
dev:cljs.user=> (com.fulcrologic.fulcro.application/current-state app.application/app)
{:friends [:list/id :friends]
:enemies [:list/id :enemies]
:person/id {1 {:person/id 1, :person/name "Sally", :person/age 32}
2 {:person/id 2, :person/name "Joe", :person/age 22}
3 {:person/id 3, :person/name "Fred", :person/age 11}
4 {:person/id 4, :person/name "Bobby", :person/age 55}}
:list/id {:friends {:list/id :friends, :list/label "Friends", :list/people [[:person/id 1] [:person/id 2]]}
:enemies {:list/id :enemies, :list/label "Enemies", :list/people [[:person/id 3] [:person/id 4]]}}}Note that fdn/db→tree understands this normalized form, and can convert it (via a query) to the proper data tree.
So, try this at the REPL:
=> (def state (com.fulcrologic.fulcro.application/current-state app.application/app))
#'cljs.user/state
=> (def query (com.fulcrologic.fulcro.components/get-query app.ui/Root))
#'cljs.user/query
=> (com.fulcrologic.fulcro.algorithms.denormalize/db->tree query state state)
{:friends {:list/id :friends,
:list/label "Friends",
:list/people [{:person/id 1, :person/name "Sally", :person/age 32}
{:person/id 2, :person/name "Joe", :person/age 22}]},
:enemies {:list/id :enemies,
:list/label "Enemies",
:list/people [{:person/id 3, :person/name "Fred", :person/age 11}
{:person/id 4, :person/name "Bobby", :person/age 55}]}}5.9.2. Mutations on a Normalized Database
We have now made it possible to fix the problems with our mutation. Now, instead of removing a person from a tree, we can remove a FK from a TABLE entry!
This is not only much easier to code, but it is completely independent of the shape of the UI tree.
Fulcro’s
com.fulcrologic.fulcro.algorithms/merge namespace includes tools for merging and managing normalized data and includes some helpers for dealing with lists of idents.
Our mutation can now become:
(ns app.mutations
(:require
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.fulcrologic.fulcro.algorithms.merge :as merge]))
(defmutation delete-person
"Mutation: Delete the person with `:person/id` from the list with `:list/id`"
[{list-id :list/id
person-id :person/id}]
(action [{:keys [state]}]
(swap! state merge/remove-ident* [:person/id person-id] [:list/id list-id :list/people])))Mutation "helpers" in fulcro are functions that work against a plain map (normalized app database) so that they can be used easily in swap!.
By convention these functions have a * suffix, and often have mutation versions that do not have the suffix.
The remove-ident* mutation helper does just that:
It removes an ident from a list of idents.
The arguments are the ident to remove and the path to the list of idents that you want to remove it from.
Of course, you’ll have to change the mutation usage in the application to look like this now:
(defsc Person [this {:person/keys [id name age] :as props} {:keys [onDelete]}] (1)
...
(dom/h5 (str name " (age: " age ")") (dom/button {:onClick #(onDelete id)} "X")))) ; (2)
...
(defsc PersonList [this {:list/keys [id label people] :as props}] (1)
...
(let [delete-person (fn [person-id] (comp/transact! this [(api/delete-person {:list/id id :person/id person-id})]))] ; (2)-
Destructure ID from the props.
-
Use IDs in the mutation and callback.
If we were to now refactor the UI and wrap the person list in any amount of additional UI (e.g. a nav bar, sub-pane, modal dialog, etc.) this mutation will still work perfectly, since the list itself will only have one place it ever lives in the database.
5.9.3. How Automatic Normalization Works (optional)
It is good to know how an arbitrary tree of data (the one in initial app state) can be converted to the normalized form. Understanding how this is accomplished can help you avoid some mistakes later.
When you compose your query (via comp/get-query), the get-query function adds metadata to each component’s query fragment that names which component that query fragment came from.
For example, try this at the REPL:
dev:cljs.user=> (meta (com.fulcrologic.fulcro.components/get-query app.ui/PersonList))
{:component app.ui/PersonList}The get-query function adds the component itself to the metadata for that query fragment.
We already know that we can get other static information from a component (in this case we’re interested in the ident).
So, Fulcro includes a function called com.fulcrologic.fulcro.algorithms.normalize/tree→db that can simultaneously walk a data tree (in this case initial-state) and a component-annotated query.
When it reaches a data node whose query metadata names a component with an ident it places that data into the appropriate table (by calling your ident function), and replaces the data in the tree with its ident.
Once you realize that the query and the ident work together to do normalization, you can more easily figure out what mistakes you might make that could cause auto-normalization to fail (e.g. stealing a query from one component and placing it on another, writing the query of a sub-component by-hand instead of pulling it with get-query, etc.).
5.10. Review So Far
-
An initial app state sets up a tree of data for startup to match the UI tree.
-
Component query and ident are used to normalize this initial data into the database.
-
The query is used to pull data from the normalized db into the props of the active Root UI.
-
Transactions invoke abstract mutations.
-
Mutations modify the (normalized) db.
-
Fulcro and React manage the UI to do a minimal refresh.
-
5.11. Using Better Tools
So far we’ve been hacking things in place and using the REPL to watch what we’re doing. There are better ways to work on Fulcro applications, and now that we’ve got one basically working, let’s take a look at them both.
5.11.1. Fulcro Inspect
We’ve mentioned this before, but now that you know about the centralized database, we want to mention it again: Use it! The DB tab of this tool shows you your application’s database and has a time slider to see the history of states. It also has tabs for showing you transactions that have run, and network interactions. See the tool’s documentation for more information.
5.11.2. Workspaces
The Workspaces library allows you to start up a development environment where you can code components, full-stack elements, or even entire applications in a flexible environment. Remember, we can actually split off chunks of the application because they are all fed data via a normalized database and coupled only to their parent.
Setting up an alternate build for workspace in which you can create and edit portions of your application in isolation can be a real productivity boost. It enables you to focus on the selected components without having to bother with the rest of the application.
Some common useful cases:
-
Work on the layout of a component
-
Test out complex components in isolation.
-
Feed generated (spec-based) data to components and see if they break.
-
Work on a subset of screens as a mini-application. You can embed an entire app in a card!
5.12. Going Remote!
OK, back to the main story!
Believe it or not, there’s not much to add/change on the client to get it talking to a server, and there is also a relatively painless way to get a server up and running.
5.12.1. The Communication
Fulcro uses transit as the over-the-wire protocol for network requests. There is only one API endpoint, and an EQL parser on the server will process the requests and return responses. The overall network interaction story is essentially just EQL requests and responses.
We recommend using Pathom to process the EQL on the server, and we’ll set up a simple Pathom parser for our application’s server.
Add this to your deps:
com.wsscode/pathom {:mvn/version "2.2.15"}
com.taoensso/timbre {:mvn/version "4.10.0"}and create the file src/main/app/parser.clj with this content:
(ns app.parser
(:require
[com.wsscode.pathom.core :as p]
[com.wsscode.pathom.connect :as pc]
[taoensso.timbre :as log]))
(def resolvers [])
(def pathom-parser
(p/parser {::p/env {::p/reader [p/map-reader
pc/reader2
pc/ident-reader
pc/index-reader]
::pc/mutation-join-globals [:tempids]}
::p/mutate pc/mutate
::p/plugins [(pc/connect-plugin {::pc/register resolvers})
p/error-handler-plugin
;; or p/elide-special-outputs-plugin
(p/post-process-parser-plugin p/elide-not-found)]}))
(defn api-parser [query]
(log/info "Process" query)
(pathom-parser {} query))5.12.2. Setting up a Server
To run a server you’ll first need something that implements the core HTTP stuff, and some bits of glue.
The standard for this in Clojure is Ring, and a common easy-to-use HTTP server is http-kit.
Open your deps.edn file and add dependencies so it looks like this:
{:paths ["src/main" "resources"]
:deps {org.clojure/clojure {:mvn/version "1.10.3"}
com.fulcrologic/fulcro {:mvn/version "3.5.9"}
com.wsscode/pathom {:mvn/version "2.4.0"}
com.taoensso/timbre {:mvn/version "5.1.2"}
ring/ring-core {:mvn/version "1.9.4"}
http-kit/http-kit {:mvn/version "2.5.3"}}
:aliases {:dev {:extra-paths ["src/dev"]
:extra-deps {org.clojure/clojurescript {:mvn/version "1.10.914"}
thheller/shadow-cljs {:mvn/version "2.16.9"}
binaryage/devtools {:mvn/version "1.0.4"}
cider/cider-nrepl {:mvn/version "0.27.4"}}}}}and then add a src/main/app/server.clj namespace:
(ns app.server
(:require
[app.parser :refer [api-parser]]
[org.httpkit.server :as http]
[com.fulcrologic.fulcro.server.api-middleware :as server]
[ring.middleware.content-type :refer [wrap-content-type]]
[ring.middleware.resource :refer [wrap-resource]]))
(def ^:private not-found-handler
(fn [req]
{:status 404
:headers {"Content-Type" "text/plain"}
:body "Not Found"}))
(def middleware
(-> not-found-handler ; (1)
(server/wrap-api {:uri "/api"
:parser api-parser}) ; (2)
(server/wrap-transit-params)
(server/wrap-transit-response)
(wrap-resource "public") ; (3)
wrap-content-type))
(defonce stop-fn (atom nil))
(defn start []
(reset! stop-fn (http/run-server middleware {:port 3000})))
(defn stop []
(when @stop-fn
(@stop-fn)
(reset! stop-fn nil)))-
The middleware stack ends at a not found handler
-
The
wrap-apimiddleware from Fulcro, along with transit in/out encode/decode. -
Resource serving (to get our index.html file) and set the content type correctly.
5.12.3. Running the Server
The Clojure REPL will automatically start in the user namespace.
During development we can leverage that to make our lives a little easier.
One thing we’ll commonly want to do it refresh our server when we make code changes.
So, we should add a little more to our project.
First, code reloading tools in deps.edn:
{:paths ["src/main" "resources"]
:deps {org.clojure/clojure {:mvn/version "1.10.1"}
com.fulcrologic/fulcro {:mvn/version "3.0.10"}
com.wsscode/pathom {:mvn/version "2.2.15"}
ring/ring-core {:mvn/version "1.6.3"}
com.taoensso/timbre {:mvn/version "4.10.0"}
http-kit {:mvn/version "2.3.0"}}
:aliases {:dev {:extra-paths ["src/dev"]
:extra-deps {org.clojure/clojurescript {:mvn/version "1.10.520"}
thheller/shadow-cljs {:mvn/version "2.8.40"}
binaryage/devtools {:mvn/version "0.9.10"}
org.clojure/tools.namespace {:mvn/version "0.2.11"}}}}} ; (1)-
Tools for reloading namespaces at runtime.
and we only want our "development" mode to see our user.clj file, so we’ll put it in the alternate dev source path src/dev/user.clj:
|
Important
|
This file goes in src/dev, not src/main.
|
(ns user
(:require
[app.server :as server]
[clojure.tools.namespace.repl :as tools-ns :refer [set-refresh-dirs refresh]]))
;; Ensure we only refresh the source we care about. This is important
;; because `resources` is on our classpath and we don't want to
;; accidentally pull source from there when cljs builds cache files there.
(set-refresh-dirs "src/dev" "src/main")
(defn start []
(server/start))
(defn restart
"Stop the server, reload all source code, then restart the server.
See documentation of tools.namespace.repl for more information."
[]
(server/stop)
(refresh :after 'user/start))
;; These are here so we can run them from the editor with kb shortcuts. See IntelliJ's "Send Top Form To REPL" in
;; keymap settings.
(comment
(start)
(restart))|
Important
|
Make sure the dev alias is enabled for Clojure when you run your REPL. In IntelliJ this is in the "Clojure Deps" tab, under "aliases".
From the command line include -A:dev.
|
If you start the server with (start) you should be able to load http://localhost:3000/index.html. Note you must
specify the path because our server is quite literal at the moment. It has no idea what "/" means.
5.12.4. Server Refresh
When you add/change code on the server you will want to see those changes in the live server without having to restart your REPL. The additions we’ve made make this possible by just running:
user=> (restart)If there are compiler errors, then the user namespace might not reload properly.
In that case, you should be able to recover using:
user=> (tools-ns/refresh)
user=> (start)5.13. Parsing Queries
Before we can obtain data from the server we have to understand a little bit about writing resolvers for Pathom. Pathom is basically a library for building EQL parsers. The two critical things you define are called resolvers and mutations. The latter is pretty much identical to what you’ve already done in Fulcro, and at the moment we’re primarily interested in satisfying some reads. So let’s talk about resolvers.
Resolvers are defined to expect some particular inputs, and declare what they can produce.
They are always called with some context (stored in an env parameter) and some optional inputs that match the expected inputs.
The context includes the portion of the query that is currently being parsed along with a number of other things.
The idea is that "given a context and some input" you should be able to write some code that can resolve the desired outputs.
In this chapter the following requires with aliases are assumed:
...
(:require
[com.wsscode.pathom.core :as p]
[com.wsscode.pathom.connect :as pc]))Here is a sample resolver:
(pc/defresolver person-resolver [env input]
{::pc/input #{:person/id}
::pc/output [:person/name]}
(let [name (get-name-from-database (:person/id input))]
{:person/name name}))it declares "Given a :person/id as input, I can produce their name".
The inputs are written as a set, and the output is written as an EQL query.
The body of the function will find the required input in the input parameter, and must return an EQL response that matches the shape of the declared ::pc/output.
In cases where the resolver is not able to find the data promised in ::pc/output`, simply elide the promised key from
the returned map. Loosely following the examples below, such a situation might arise if the person you’re querying for
has no enemies while :person/enemies is in the declared ::pc/output. Excluding a key like this from the resolver’s
return value will cause Pathom to respond with {:person/enemies ::p/not-found …}, which gets removed from the final
query output as long as your parser config includes one of the elide plugins like p/elide-special-outputs-plugin or
(p/post-process-parser-plugin p/elide-not-found). Foregoing this step can cause Fulcro to produce malformed idents like
[:thing/id nil] when referring to the thing that could not be found. Lastly, another option is to set :person/enemies
to an empty vector in such cases instead of excluding it from the map entirely.
Furthermore, the output of a resolver augments the known context that Pathom is working with, and can be used to chain lookups across resolvers to fulfill a complete query.
For the sake of our examples we’re going to hand-generate a server-side database in simple maps so that you can concentrate on the code of interest instead of boilerplate database initialization and queries.
Add a src/main/app/resolvers.clj file with this content:
(ns app.resolvers
(:require
[com.wsscode.pathom.core :as p]
[com.wsscode.pathom.connect :as pc]))
(def people-table
{1 {:person/id 1 :person/name "Sally" :person/age 32}
2 {:person/id 2 :person/name "Joe" :person/age 22}
3 {:person/id 3 :person/name "Fred" :person/age 11}
4 {:person/id 4 :person/name "Bobby" :person/age 55}})
(def list-table
{:friends {:list/id :friends
:list/label "Friends"
:list/people [1 2]}
:enemies {:list/id :enemies
:list/label "Enemies"
:list/people [4 3]}})
;; Given :person/id, this can generate the details of a person
(pc/defresolver person-resolver [env {:person/keys [id]}]
{::pc/input #{:person/id}
::pc/output [:person/name :person/age]}
(get people-table id))
;; Given a :list/id, this can generate a list label and the people
;; in that list (but just with their IDs)
(pc/defresolver list-resolver [env {:list/keys [id]}]
{::pc/input #{:list/id}
::pc/output [:list/label {:list/people [:person/id]}]}
(when-let [list (get list-table id)]
(assoc list
:list/people (mapv (fn [id] {:person/id id}) (:list/people list)))))
(def resolvers [person-resolver list-resolver])and then add these resolvers into the parser.clj file:
(ns app.parser
(:require
[app.resolvers]
[com.wsscode.pathom.core :as p]
[com.wsscode.pathom.connect :as pc]))
(def resolvers [app.resolvers/resolvers])
... as beforeThese two resolvers already give you a lot of power. We’ve been following a convention for some time of giving idents the "table name" of the ID field. This is because Pathom can treat an ident as "context" for determining which resolver to run.
It turns out that EQL will allow an ident to be used as a join key to establish a particular graph context (i.e. pretend we’re on the node with the given ident): :
[{[:person/id 3] [:person/name]}]If you load the parser namespace you can try these out in a CLJ REPL (e.g. clj -A:dev at the command line):
(require 'app.parser)
(app.parser/api-parser [{[:list/id :friends] [:list/id]}])
=> {[:list/id :friends] {:list/id :friends}}
(app.parser/api-parser [{[:person/id 1] [:person/name]}])
=> {[:person/id 1] {:person/name "Sally"}}
(app.parser/api-parser [{[:list/id :friends] [:list/id {:list/people [:person/name]}]}])
=> {[:list/id :friends] {:list/id :friends, :list/people [{:person/name "Sally"} {:person/name "Joe"}]}}Pathom’s magic is that it can traverse the graph based on the declared inputs and outputs.
The fact that the list resolver says it outputs :person/id means that Pathom can "connect the dots" to fill in details of that person.
Those two resolvers make it possible for us to execute all of the arbitrary queries we’d need to feed data to our application at any level!
It is also possible to define resolvers that don’t require any inputs at all.
These "global resolvers" are the same as "root queries" in GraphQL. We could use one of these for our application, so add this to your resolvers.clj file:
...
(pc/defresolver friends-resolver [env input]
{::pc/output [{:friends [:list/id]}]}
{:friends {:list/id :friends}})
(pc/defresolver enemies-resolver [env input]
{::pc/output [{:enemies [:list/id]}]}
{:enemies {:list/id :enemies}})
;; Make sure you add the two resolvers into the list
(def resolvers [person-resolver list-resolver friends-resolver enemies-resolver])and now if you reload the code in your REPL you should be able to run a query like this:
(app.parser/api-parser [{:friends [:list/id {:list/people [:person/name]}]}])
=> {:friends {:list/id :friends, :list/people [{:person/name "Sally"} {:person/name "Joe"}]}}5.13.1. Loading Data
At this point we’ve actually got everything we need on the server to handle incoming load requests from the client.
In your clojure REPL, use (restart) to stop/reload/start the server.
If everything went OK you’ve got a server that can satisfy client queries.
Now we will start to see more of the payoff of our UI co-located queries and auto-normalization. Our application so far is quite unrealistic: the lists of people we’re showing should be coming from a server-side database, they should not be embedded in the code of the client. Let’s remedy that.
Fulcro provides a few mechanisms for loading data, but most important load scenarios can be done using the com.fulcrologic.fulcro.data-fetch/load! function.
It is very important to remember that our application database is completely normalized, so anything we’d want to put in that application state will be at most 3 levels deep (the table name, the ID of the thing in the table, and the field within that thing). We’ve also seen that Fulcro can also auto-normalize complete trees of data, and has graph queries that can be used to ask for those trees.
Thus, there really are not very many scenarios!
The three basic scenarios are:
-
Load something into the root of the application state (root prop).
-
Load a tree and normalize it into tables.
-
Target a loaded tree to "start" at some specific edge in the graph.
Let’s try out these different scenarios with our application.
First, get rid of the application’s initial state
(ns app.ui
(:require
[app.mutations :as api]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]))
(defsc Person [this {:person/keys [id name age] :as props} {:keys [onDelete]}]
{:query [:person/id :person/name :person/age]
:ident (fn [] [:person/id (:person/id props)])}
(dom/li
(dom/h5 (str name " (age: " age ")") (dom/button {:onClick #(onDelete id)} "X")))) ; (4)
(def ui-person (comp/factory Person {:keyfn :person/id}))
(defsc PersonList [this {:list/keys [id label people] :as props}]
{:query [:list/id :list/label {:list/people (comp/get-query Person)}]
:ident (fn [] [:list/id (:list/id props)])}
(let [delete-person (fn [person-id] (comp/transact! this [(api/delete-person {:list/id id :person/id person-id})]))] ; (2)
(dom/div
(dom/ul
(map #(ui-person (comp/computed % {:onDelete delete-person})) people)))))
(def ui-person-list (comp/factory PersonList))
(defsc Root [this {:keys [friends enemies]}]
{:query [{:friends (comp/get-query PersonList)}
{:enemies (comp/get-query PersonList)}]
:initial-state {}}
(dom/div
(dom/h3 "Friends")
(when friends
(ui-person-list friends))
(dom/h3 "Enemies")
(when enemies
(ui-person-list enemies))))We also added a little "guard code" to test if data was missing so we don’t try to render nil props.
If you now reload your page you should see two headings, but no people.
Loading something into the DB root
Our application has two root-level things that we’d like to load. Loads, of course, can be triggered at any time (startup, event, timeout). Loading is just a function call.
For this example, let’s trigger the load just after the application has started, and load our friends and enemies.
Open the app.application namespace and add remote support:
(ns app.application
(:require
[com.fulcrologic.fulcro.application :as app]
[com.fulcrologic.fulcro.networking.http-remote :as http]))
(defonce app (app/fulcro-app
{:remotes {:remote (http/fulcro-http-remote {})}}))and then go to client.cljs and add our initial load during application startup:
(ns app.client
(:require
[app.application :refer [app]]
[app.ui :as ui]
[com.fulcrologic.fulcro.application :as app]
[com.fulcrologic.fulcro.data-fetch :as df]))
(defn ^:export init []
(app/mount! app ui/Root "app")
(df/load! app :friends ui/PersonList)
(df/load! app :enemies ui/PersonList)
(js/console.log "Loaded"))
...Of course hot code reload does not restart the app (it just hot patches the code), so to see this load trigger we must reload the browser page.
|
Important
|
Make sure your application is running from your server (port 3000), and not the dev server. |
Technically, load! is just writing a query for you (in this case [{:friends (comp/get-query PersonList)}]) and sending it to the server.
The server will receive exactly that query as a CLJ data structure.
Loading a specific entity and its subgraph (by ident)
Once things are loaded from the server they are immediately growing stale (unless you’re pushing updates with websockets). It is very common to want to re-load a particular thing in your database. Of course, you can trigger a load just like we’ve been doing, but in that case we would be reloading a whole bunch of things. What if we just wanted to refresh a particular person (e.g. in preparation for editing it).
The load! function can be used for that as well.
Just replace the keyword with an ident, and you’re there!
Load can take the app or any component’s this as the first argument, so from within the UI we can trigger a load using this:
(df/load this [:person/id 3] Person)Adding Edges
There are a number of ways to "add edges" to the UI data graph when loading.
The most common is to use the :target option of load!.
This option indicates that the incoming data should be "joined" into the graph as a given edge (the default is to link it to the root node).
So, you could add an arbitrary person to the friends list like this:
(df/load! this [:person/id 3] Person {:target (targeting/append-to [:list/id :friends :list/people])})|
Note
|
Targets are just graph database paths.
The append-to modifier comes from the com.fulcrologic.fulcro.algorithms.data-targeting
namespace and will append the edge to a to-many relation if (and only if) it isn’t already there.
Remember, any edge is reachable in our database by a path that is at most three elements long (table, id, field).
|
Additional Permutations
Fulcro’s load system covers a number of additional bases that bring the story to completion. There are load markers (so you can show network activity), server query parameters, error handling, and more. Read the corresponding chapters in this guide for more details.
5.13.2. Handling Mutations on The Server
Mutations can be handled on the server using Pathom’s defmutation macro.
This has a nearly-identical syntax to the client Fulcro macro of the same name.
|
Important
|
You want to place your mutations in the same namespace on the client and server since the defmutation
macros namespace the symbol into the current namespace.
The Pathom defmutation actually lets you override what symbol it responds to, so this is not absolutely necessary.
|
So, let’s add an implementation for our server-side delete-person.
First, we need to modify our database tables so we can change them.
Modify the resolvers.clj to be this:
(ns app.resolvers
(:require
[com.wsscode.pathom.core :as p]
[com.wsscode.pathom.connect :as pc]))
(def people-table
;; changed to an atom so we can update these "databases"
(atom
{1 {:person/id 1 :person/name "Sally" :person/age 32}
2 {:person/id 2 :person/name "Joe" :person/age 22}
3 {:person/id 3 :person/name "Fred" :person/age 11}
4 {:person/id 4 :person/name "Bobby" :person/age 55}}))
(def list-table
(atom
{:friends {:list/id :friends
:list/label "Friends"
:list/people [1 2]}
:enemies {:list/id :enemies
:list/label "Enemies"
:list/people [4 3]}}))
;; Given :person/id, this can generate the details of a person
(pc/defresolver person-resolver [env {:person/keys [id]}]
{::pc/input #{:person/id}
::pc/output [:person/name :person/age]}
(get @people-table id))
;; Given a :list/id, this can generate a list label and the people
;; in that list (but just with their IDs)
(pc/defresolver list-resolver [env {:list/keys [id]}]
{::pc/input #{:list/id}
::pc/output [:list/label {:list/people [:person/id]}]}
(when-let [list (get @list-table id)]
(assoc list
:list/people (mapv (fn [id] {:person/id id}) (:list/people list)))))
(pc/defresolver friends-resolver [env input]
{::pc/output [{:friends [:list/id]}]}
{:friends {:list/id :friends}})
(pc/defresolver enemies-resolver [env input]
{::pc/output [{:enemies [:list/id]}]}
{:enemies {:list/id :enemies}})
(def resolvers [person-resolver list-resolver friends-resolver enemies-resolver])Then create src/main/app/mutations.clj and add this code to it:
(ns app.mutations
(:require
[app.resolvers :refer [list-table]]
[com.wsscode.pathom.connect :as pc]
[taoensso.timbre :as log]))
(pc/defmutation delete-person [env {list-id :list/id
person-id :person/id}]
;; Pathom registers these mutations in an index. The key that the mutation is
;; indexed by can be overridden with the `::pc/sym`
;; configuration option below. Note, however, that mutation we are sending
;; in the `comp/transact!` from the PersonList component above is
;; `[(api/delete-person ,,,)]` which will expand to the fully qualified
;; mutation of `[(app.mutations/delete-person ,,,)]`. If you
;; encounter unexpected error messages about mutations not being found,
;; ensure any overridden syms match the expanded namespaces of your mutations.
{::pc/sym `delete-person}
(log/info "Deleting person" person-id "from list" list-id)
(swap! list-table update list-id update :list/people (fn [old-list] (filterv #(not= person-id %) old-list))))
(def mutations [delete-person])and then modify parser.clj to require and include the mutations in the overall list of pathom resolvers:
(ns app.parser
(:require
[app.resolvers]
[app.mutations] ; <----- add this
[com.wsscode.pathom.core :as p]
[com.wsscode.pathom.connect :as pc]
[taoensso.timbre :as log]))
(def resolvers [app.resolvers/resolvers app.mutations/mutations]) <---- add to this
;; no other changesRefresh the code on your server with (restart) at the REPL; However, don’t expect it to work just yet.
We have to tell the client to send the remote request.
Triggering the Remote Mutation from the Client
Mutations are simply optimistic local updates by default.
To make them full-stack, you need to add a method-looking section to your defmutation handler:
(defmutation delete-person
"Mutation: Delete the person with `:person/id` from the list with `:list/id`"
[{list-id :list/id
person-id :person/id}]
(action [{:keys [state]}] ...)
(remote [env] true)) ; This one line is it!!!The syntax for the addition is:
(remote-name [env] boolean-or-ast-or-env)where remote is the name of a remote server (the default is remote).
You can have any number of network remotes.
The default one talks to the page origin at /api.
What is this AST we speak of?
It is the abstract syntax tree of the mutation itself (as data).
Using a boolean true means "send it just as the client specified".
If you wish you can pull the AST from the env, augment it (or completely change it) and return that instead.
Now that you’ve got the UI in place, try deleting a person. It should disappear from the UI as it did before; however, now if you’re watching the network you’ll see a request to the server. If you server is working right, it will handle the delete.
Try reloading your page from the server. That person should still be missing, indicating that it really was removed from the server.
5.14. Wrapping Up
At this point you’ve gotten more detailed view of what a Fulcro application looks like. The remaining chapters of this book go into considerably more detail about each important part of the API.
6. Core API
The Core API of Fulcro centers around manipulating the graph of data in your client-side database. Fulcro’s APIs are CLJC, and many of them have nothing at all to do with rendering. In fact, most of the operations of Fulcro can be used in a completely "headless" CLJ REPL.
You can safely skip this chapter, but since Fulcro uses a very simple model of operation centered around these functions it is useful to see these them in isolation so you can more easily understand how things work.
First we’ll talk about denormalization and normalization. These two are the yin and yang of Fulcro’s operation, and it is difficult to choose which to cover first. We’ll start with denormalization because it requires no extra knowledge other than a map in Fulcro’s graph database format.
6.1. Denormalization
Denormalization in Fulcro is the process of running an EQL query against a normalized Fulcro client database. The algorithm is pretty trivial in the common case, but since EQL supports recursion, wildcards, and union queries the actual implementation is somewhat difficult to read and understand.
Fortunately, using it is much simpler.
The primary algorithm for denormalization is db→tree, found in the [com.fulcrologic.fulcro.algorithms.denormalize :as fdn]
namespace.
The db→tree function is designed to be used in two different contexts:
-
Starting from the root of a Fulcro database, and running EQL from there.
-
Starting from some arbitrary node of a Fulcro database, and running EQL from there.
Notice that since the Fulcro database itself is just a special (the root) node of the database that the two cases are really identical in practice. The first case is just a "well-known" node to start at.
Let’s make it more concrete. Assume you have the following Fulcro database:
(def sample-db
{:people [[:person/id 1] [:person/id 2]]
:person/id {1 {:person/name "Bob"}
2 {:person/name "Judy"}}})I can pull a tree of data using:
(let [starting-node sample-db]
(fdn/db->tree [{:people [:person/name]}] starting-node sample-db))
=> {:people [#:person{:name "Bob"} #:person{:name "Judy"}]}I want you to note a few very important things:
-
The EQL drives a simple recursive walk of the database.
-
The main task of
db→treeis to do a(get-in db ident)any time it sees an ident (for an EQL join) to replace that ident with the corresponding map.
For clarity, let’s build this up a step at a time:
;; The query just asks for a top-level prop.
(let [starting-node sample-db]
(fdn/db->tree [:people] starting-node sample-db))
=> {:people [[:person/id 1] [:person/id 2]]}
;; The query just asks for a table
(let [starting-node sample-db]
(fdn/db->tree [:person/id] starting-node sample-db))
=> #:person{:id {1 #:person{:name "Bob"}, 2 #:person{:name "Judy"}}}Notice that both of the above queries stop where the EQL stops (even if there are unresolved idents). If you say you
want :people as a prop, then you get that value as an "opaque" literal. You are free to store whatever you like
at a prop in a Fulcro database, and the denormalization will only resolve an ident when it is told to expect a join.
Now, let’s suppose you wanted to query the details of a person, but you didn’t want to follow any joins. Well, in that
case you can essentially use db→tree much like clojure.core/select-keys:
(let [starting-entity {:person/name "Joe" :person/age 42}
empty-db {}]
(fdn/db->tree [:person/name] starting-entity empty-db))
=> #:person{:name "Joe"}In this case I can supply an empty database for the final argument because that database is only used to resolve
idents. In fact, if I have a tree of data with no normalization, I can use db→tree to simply "prune it" as if
it were a more advanced version of select-keys:
(let [starting-entity {:person/name "Joe" :person/age 42 :person/spouse {:person/name "Judy" :person/age 45}}
empty-db {}]
(fdn/db->tree [:person/name {:person/spouse [:person/age]}] starting-entity empty-db))
=> #:person{:name "Joe", :spouse #:person{:age 45}}Thus, you see that the final database argument is only about resolving idents when they are crossed by a join in the EQL.
6.1.1. Idents as a Query Element
EQL allows for the use of idents in the query itself. Basically these are just instructing db→tree to "move" the context
to some particular normalized entity in the database.
(def sample-db
{:people [[:person/id 1] [:person/id 2]]
:person/id {1 {:person/name "Bob" :person/spouse [:person/id 2]}
2 {:person/name "Judy"}}})
(let [starting-entity {}]
(fdn/db->tree [[:person/id 1]] starting-entity sample-db))
=> {[:person/id 1] #:person{:name "Bob", :spouse [:person/id 2]}}In the above case the starting entity is irrelevant, because the given EQL says "Join to a particular entity in the database". The start entity isn’t part of the query. Now, of course the two can be mixed:
(def sample-db
{:people [[:person/id 1] [:person/id 2]]
:some-number 99
:person/id {1 {:person/name "Bob" :person/spouse [:person/id 2]}
2 {:person/name "Judy"}}})
(let [starting-entity sample-db]
(fdn/db->tree [:some-number [:person/id 1]] starting-entity sample-db))
=> {:some-number 99, [:person/id 1] #:person{:name "Bob", :spouse [:person/id 2]}}Again make note of the fact that no extra idents were followed when the EQL didn’t make a join of them (in this
case the :person/spouse was treated as an EQL prop).
Of course we can also use an ident query element with EQL join syntax to then start walking the database to generate a tree:
(fdn/db->tree [{[:person/id 1] [:person/name {:person/spouse [:person/name]}]}] {} sample-db)
=> {[:person/id 1] #:person{:name "Bob", :spouse #:person{:name "Judy"}}}However, note that all the ident is doing in the above case is naming the starting entity! We can of course just give a particular table entry as the starting entity by pulling it out ourselves!
(let [starting-entity (get-in sample-db [:person/id 1])]
(fdn/db->tree [:person/name] starting-entity sample-db))
=> #:person{:name "Bob"}and this is in fact what Fulcro has to do when doing a localized refresh of some UI component. It has to ask the component
"what is your ident?", pull that entry from the db, then asks the component "OK, what is your query". It then combines
that into the above call to db→tree to get the desired props for rendering that component.
One final note: you may have noticed that db→tree doesn’t care that the entities themselves know their identity. For
simplicity I left the IDs out of all of the person maps. This was intentional for two reasons:
-
db→treedoes not need the entities to have an ID in their map, it only needs them to be in properly indexed tables. -
To highlight that there is no magic. Most of denormalization is just doing recursive evaluation of
get-inon idents according to the data requested in the supplied EQL, and the location (i.e.[:person/id 1]) in the database of those entities.
6.2. Normalization
The normalization of data is the reverse process of denormalization. Take an arbitrary tree of data and turn it into Fulcro’s normalized graph database form. Note that, except for the root of the tree, that every element in the tree is relative to another element:
{:root {:child {:children [{:x 1} {:x 2} ...]}}}our task in normalization is to recursively replace every relative child with a "lookup ref" (known to Fulcro as an ident), and to place that child at the location indicated by that lookup ref.
How do we do that?
6.2.1. Deriving Idents
The central questions of normalization are, when a map is found:
-
Should that map be normalized?
-
Where should it be normalized to?
Imagine your processing a tree of data and find the map {:x 1}. How do you decide when to replace it with an ident,
and how do you determine what the ident is?
Determining When to Normalize
If you remember back in the denormalization section we consider "props" in EQL to be opaque. If you query it as a prop you may want to get an ident, but you might also just want to get a map that was left denormalized in the database (intentionally). If you query it as a join then you’re either pruning an intentionally non-normalized map, or you want to follow an ident.
What we’re getting at is that the normalization process MUST be told which you mean to do. It must not normalize a nested map unless that is your intention.
Fortunately, there is a trivial thing we can use to make that determination: the very query you want to be able to run (and which will be in your UI).
Determining Target Location
Figuring out the ident for an arbitrary map could be done in any number of ways:
-
A registry of "ID" props to look for? This sort of works, but it has a few weaknesses: It’s a little slow to scan each map for a known ID, but the bigger problem is that a map could have more than one ID. It is rare but entirely plausible (sometimes desirable) to overlay the identities of two things (i.e. a primary address with customer data).
-
A naming convention? This is just like the prior solution, but only rids us of the need to make a registry.
-
Some find of global function you provide? This isn’t much better than a naming convention. Your global function would have to analyze the map in question and try to deduce what to use as an ident.
Fulcro’s solution combines the following observations:
-
A UI component will typically correspond to the normalization boundaries. We’re interested in each component having a deduplicated value in the database.
-
Our primary goal with data-driven EQL is to co-locate the requirements of a component’s data (a co-located query) with that component.
-
We need to know if the component wants to treat the data at some location as a prop, or as a join. This is the answer to the "when to normalize" question.
Thus, it seems like the component itself could tell us where to put the data during normalization!
Here’s how it works. Every component has an optional function associated with it called ident, stored in its
component-options. In a CLJ REPL you can see this with:
(defsc X [this props]
{:ident (fn [] [:x 1])})
(let [options (comp/component-options X)
ident-fn (get options :ident)]
(ident-fn X {}))
=> [:x 1]The convenience function comp/get-ident does the work of pulling the function out of component options, so we can
shorten usage to:
(comp/get-ident X {})
=> [:x 1]The defsc macro, for convenience, allows you to pretend to close over the two arguments of the class (the first of
which will either be passed to use as the class or the live on-screen instance). It can also auto-generate this function
from two other syntax annotations:
(defsc Person [this props]
{:ident (fn [] [:person/id (:person/id props)])})
(defsc Person [this props]
{:ident [:person/id :person/id]})
(defsc Person [this props]
{:ident :person/id})The first is explicit. Whatever you return, which can be derived from a map of data (props) is the ident. This form
is commonly used when the component has a constant (singleton) ident. The second
form generates a lambda where the first element of the supplied vector is literal, and the second is used to get
data from props. The final one recognizes that we commonly just use the ID field name as both the table name and
the method of finding the ID, and is the most compact and common notation. All three are exactly equivalent in the above.
Now, note that props is a bit of a misnomer. The component-centric ident function just needs a map of data to
generate the desired location, and that is exactly what we have when we are normalizing things.
The question is now this: How do we know which component’s ident function to use when we run across the map
{:person/id 2 :person/name "Judy"}?
Remember that we need the query of the component to know when to normalize something, so we’ve already agreed that we must use the component’s query on the map. Therefore it seems obvious that we should also just use the component’s ident. The problem is this: how do we find either of those things (the query and ident) when we’re normalizing an arbitrary map?
The answer turns out to be quite simple: shape.
The shape of the UI tree will naturally match the shape of the data tree, which in turn MUST match the shape of the query (or the query would not be able to supply the data for the UI tree to render)!
(defsc Person [this props]
{:query [:person/id :person/name]
:ident :person/id})
(defsc Root [this props]
{:query [{:root/people (comp/get-query Person)}]})
(comp/get-query Root)
=> [#:root{:people [:person/id :person/name]}]Notice that the query is nothing more than a literal tree-like composition, and the expected shape looks just like you’d expect:
(def sample-tree {:root/people [{:person/id 1 :person/name "Bob"}
{:person/id 2 :person/name "Judy"}]})and remember that you can use a query and db→tree to get the effect of an advanced select-keys:
(fdn/db->tree (comp/get-query Root) sample-tree sample-tree)
=> #:root{:people [#:person{:id 1, :name "Bob"} #:person{:id 2, :name "Judy"}]}but now we can answer how we’ll go about finding the function to generate idents! The comp/get-query function
in Fulcro adds metadata to the query!
(meta (comp/get-query Person))
=>
{:component {:com.fulcrologic.fulcro.components/component-class? true,
:fulcro$options {:query #object[user$eval16991$query_STAR___16992
0x5836a00c
"user$eval16991$query_STAR___16992@5836a00c"],
:ident #object[user$eval16991$ident_STAR___16994
0x7f934ca2
"user$eval16991$ident_STAR___16994@7f934ca2"],
:render #object[com.fulcrologic.fulcro.components$eval16408$wrap_base_render__16433$fn__16434
0x3caa065
"com.fulcrologic.fulcro.components$eval16408$wrap_base_render__16433$fn__16434@3caa065"]},
:fulcro$registryKey :user/Person,
:displayName "user/Person"},
:queryid "user/Person"}The :queryid is used for dynamic queries, but the component is the literal class (in this case Person) that
supplied that element of the query (you can tell because the :fulcro$registryKey is the fully-qualified name of the class)!
So, normalization can do this:
-
Walk the tree in parallel with the EQL
-
At a join:
-
Ask the query for the metadata, and pull the ident function from there.
-
Run the ident function on the tree’s data to get the ident.
-
Put the map of tree data into the normalized form (
(assoc-in result ident tree-value)).
-
-
Continue…
(let [{:keys [component]} (meta (comp/get-query Person))]
(comp/get-ident component {:person/id 1 :person/name "Bob"}))
=> [:person/id 1]The namespace [com.fulcrologic.fulcro.algorithms.normalize :as fnorm] has the core algorithm tree→db that does
exactly that:
(fnorm/tree->db Root {:root/people {:person/id 1 :person/name "Bob"}} true)
=> {:root/people [:person/id 1], :person/id {1 #:person{:id 1, :name "Bob"}}}Notice that you pass a component to this particular function, because normalization has to be component-centric. A query would not be enough, since the components themselves hold the key to normalization.
Also note that while many Fulcro programs might use db→tree (say to pull a subtree from the database in a mutation),
the low-level tree→db has a quirky interface for internal reasons, and there are better user-level functions for
putting things into your client-side database.
6.3. Initial State
Now that you understand how the normalization and denormalization APIs work, it is much easier to understand the
purpose and functionality of component :initial-state. It is common for people to misunderstand initial state to
be some kind of OO constructor pattern. It is not. Initial state is bourne out of the following problem:
You start a brand new Fulcro app. It has a query that wants to pull data from a client database. What is in that database?
The answer is, well, nothing!
In the very early days this was a painful problem. If you wanted a real normalized database then you had to build the darn thing by hand! You’d write some UI, then you’d hack away on a data structure to build a normalized database that you’d then initialize the app with. This was very error prone and frustrating. Worse, when you’d go to refactor your application you’d have to refactor your initial database.
After doing that about 3 times it was obvious that this needed a better solution, and it didn’t take much thinking to realize that we already had the answer: The shape of the UI! The shape of the UI already dictates the query, and that same parallel magic that led to the co-location of the ident was now an obvious similar solution for this initial application state problem!
By having you co-locate the component’s query and state, and then compose the query (through joins) and initial state (by component reference) we could have an initial application state that could be automatically extracted, normalized, and would also "follow along" through refactoring!
The defsc macro again has some convenient "magic" that can save you some typing, but the reality is this: initial state
is just a function in component options that returns the desired initial data for that component (if it has any). That
component, of course, also knows the immediate children and composes their queries and initial state into its own.
That causes the whole shape to naturally form and maintain correctness as a simple part of UI construction.
Try it out in a REPL:
(defsc Person [this props]
{:query [:person/id :person/name]
:ident :person/id
:initial-state (fn [params] {:person/id (:id params)
:person/name (:name params)})})
(let [is-fn (-> Person (comp/component-options) (:initial-state))]
(is-fn {:id 1 :name "Bob"}))
;; or more simply:
(comp/get-initial-state Person {:id 1 :name "Bob"})
=> #:person{:id 1, :name "Bob"}and then build it up a layer at a time:
(defsc Root [this props]
{:query [{:root/people (comp/get-query Person)}]
:initial-state (fn [_] {:root/people [(comp/get-initial-state Person {:id 1 :name "Bob"})
(comp/get-initial-state Person {:id 2 :name "Judy"})]})})
(comp/get-initial-state Root)
=> #:root{:people [#:person{:id 1, :name "Bob"} #:person{:id 2, :name "Judy"}]}Fulcro is doing no magic here at all. It is simply returning your own composition of data that just happens to naturally fall into the correct shape due to your composition of the UI (assuming you follow the rule, which is simply: shape of query + initial state == shape of stateful UI).
It is a natural composition technique that self-maintains through any amount of refactoring, is reasoned about locally (yes, root gets the entire application’s tree of data, but it need know nothing about anything but the direct children, which it cannot get out of knowing because it renders them!), and which leads to all of the additional cool stuff you get from Fulcro:
-
Self-maintaining, auto-normalizing, application initialization.
-
Automatic normalization of any incoming data (subgraph).
-
Localized queries that can be used to get targeted data from servers.
-
Introspection (you can use the query to understand things about an arbitrary application)
As a quick final example, the initialization of a Fulcro application is something you should now be able to write yourself! You’ve seen all of the elements that are required. It is simply:
-
Get the root initial state (which is a data tree that matches the shape of your UI)
-
Get the root query (which is EQL that matches the shape of the initial state tree, and has metadata for pulling component ident functions for normalization)
-
Run
tree→db -
Reset the Fulcro state atom to the result!
(let [data-tree (comp/get-initial-state Root)
normalized-tree (fnorm/tree->db Root data-tree true)]
normalized-tree)Fulcro does a few more things related to unions during this initialization, so this isn’t the entire picture, but it is pretty darn close.
6.4. Understanding Rendering
Fulcro has a lot of internal mechanisms dedicated to rendering, but you’ll possibly be surprised to learn that the core rendering logic is about 5 lines long. Most of the additional logic is made up of pluggable algorithms that do various (optional) optimizations.
The primary rendering of Fulcro is just this:
;; Sample current state is to illustrate that we just have a normalized database, which is normally held in an atom.
(let [current-state {:root/people [[:person/id 1] [:person/id 2]],
:person/id {1 #:person{:id 1, :name "Bob"}, 2 #:person{:id 2, :name "Judy"}}}
denormalized-tree (fdn/db->tree (comp/get-query Root) current-state current-state)
root-factory (comp/factory Root)]
(js/ReactDOM.render (root-factory denormalized-tree) dom-node))That’s it! The optimizations do things like re-render targeted components (instead of the root), but it is critical that you understand that the rendering is a literal reification of your normalized database as UI.
6.5. Evolving the Graph
So, now that you’ve been awakened to how simple Fulcro actually is internally, you can start to shift your mental model to the reality of working with Fulcro. The primary task is this:
Update your state database (and optionally your queries) such that the next reification of that data will be the desired render frame.
That’s the major shift you have to make when thinking about UI in Fulcro. It’s all about the data. Therefore, the operations you’ll be doing throughout your application’s lifetime are:
-
Mess with the graph data using
assoc-in, etc. (Done within the confines of mutations, usually). -
Add things to the graph in a structured manner.
Trivial operations like "check that box" or "hide that dialog" are done via manual manipulation, and are quite
common (and simple) to do in mutations. You can technically swap! against the actual state atom, but Fulcro
does not watch the state atom, so rendering refreshes are not automatic, and that form of direct manipulation
bypasses a lot of other useful and important features. Advanced users (or library authors) with specific needs might do
that to add some advanced feature, but most users will never want to.
Structured manipulation is where Fulcro starts to get really nice. It is very common for a Fulcro application to
want to add something to the graph dynamically. It is most easy to do that using a tree of data and the
built-in normalization features. You can, of course, do this within a mutation using tree→db, but because there
are some common use-cases there are pre-built functions to help you with this task. The primary two are df/load! and
merge/merge-component!.
Both of these functions are just fancy versions of tree→db: that is to say take a tree of data and merge it into
the database. The load! variant obtains the tree over the network, and the merge-component! one assumes you’ve
got a tree of data in hand.
In both cases they leverage the fact that a query has metadata that can be used for normalization. The load! variant,
of course, also needs the query so it can ask a remote server for the correct tree.
Again, these APIs work in a CLJ REPL (though to use either you have to have a running Fulcro app). load! also requires
a CLJ implementation for a remote, so we’ll just play with merge-component!, which does everything load! does except
obtain the tree remotely.
|
Note
|
You can still do the following code in a CLJ REPL! |
Let’s say you set up a running application. The :headless keyword is just an arbitrary placeholder in CLJ. There
is no actual UI mounted, but we have to pass something to match the function’s arity.
(defsc Person [this props]
{:query [:person/id :person/name]
:ident :person/id
:initial-state (fn [params] {:person/id (:id params)
:person/name (:name params)})})
(defsc Root [this props]
{:query [{:root/people (comp/get-query Person)}]
:initial-state (fn [_] {:root/people [(comp/get-initial-state Person {:id 1 :name "Bob"})
(comp/get-initial-state Person {:id 2 :name "Judy"})]})})
(def app (app/fulcro-app))
(app/mount! app Root :headless)
(app/current-state app)
=>
{:fulcro.inspect.core/app-id "user/Root",
:root/people [[:person/id 1] [:person/id 2]],
:person/id {1 #:person{:id 1, :name "Bob"}, 2 #:person{:id 2, :name "Judy"}}}Notice that we can start up the Fulcro app just like we could on the client, and that when we ask for the current state it is exactly what we expect (plus an app ID that Inspect adds).
Let’s say we want to add another person to this database. This usually involves 2 operations:
-
Putting the new data into a normalized table
-
Fixing the "edges" of the graph so that it will show up in the right place.
We could use a mutation and do those steps manually, but it gets really tedious if there are complete subgraphs to
normalize. Instead, we use merge/merge-component! from [com.fulcrologic.fulcro.algorithms.merge :as merge]:
(merge/merge-component! app Person {:person/id 3 :person/name "Sally"})
(app/current-state app)
=>
{:fulcro.inspect.core/app-id "user/Root",
:root/people [[:person/id 1] [:person/id 2]],
:person/id {1 #:person{:id 1, :name "Bob"}, 2 #:person{:id 2, :name "Judy"}, 3 #:person{:id 3, :name "Sally"}}}
Notice that this put the new map of data in the correct (normalized) place. If there were sub-children of a person
(e.g. :person/address) then this would have normalized (and joined) those parts as well.
For example,
(defsc Address [this props]
{:query [:address/id :address/street]
:ident :address/id})
(defsc Person [this props]
{:query [:person/id :person/name {:person/address (comp/get-query Address)}]
:ident :person/id
:initial-state (fn [params] {:person/id (:id params)
:person/name (:name params)})})
(merge/merge-component! app Person {:person/id 3 :person/name "Sally" :person/address {:address/id 33 :address/street "111 Main St"}})
(app/current-state app)
=>
{:fulcro.inspect.core/app-id "user/Root",
:root/people [[:person/id 1] [:person/id 2]],
:person/id {1 #:person{:id 1, :name "Bob"},
2 #:person{:id 2, :name "Judy"},
3 #:person{:id 3, :name "Sally", :address [:address/id 33]}},
:address/id {33 #:address{:id 33, :street "111 Main St"}}}The main problem is that the new person is not yet in the :root/people list! If the UI for Root was rendering all
of the people, then this new person isn’t going to show up! Remember that the UI is just a reification of the data graph,
and the data graph is missing an edge from :root/people to [:person/id 3].
We could, of course, manually fix that with a mutation, but merge-component! (and load!) understand that this is a very
very common need. So, the merge variant allows any number of optional targets (and load! supports a :target parameter).
The name "target" comes from the idea that the thing you’re merging often needs to be added to the graph: a desired
target location. It is specified as a vector-path (ala assoc-in), and can also be augmented with metadata to tell it
how to behave with respect to to-many edges.
For example, say you wanted to target the new person to be available from the root as a new :root/edge:
(merge/merge-component! app Person {:person/id 3 :person/name "Sally" :person/address {:address/id 33 :address/street "111 Main St"}}
:replace [:root/edge])
(app/current-state app)
=>
{:fulcro.inspect.core/app-id "user/Root",
:root/people [[:person/id 1] [:person/id 2]],
:person/id {1 #:person{:id 1, :name "Bob"},
2 #:person{:id 2, :name "Judy"},
3 #:person{:id 3, :name "Sally", :address [:address/id 33]}},
:address/id {33 #:address{:id 33, :street "111 Main St"}},
:root/edge [:person/id 3]}or this new person was the spouse of Bob:
(merge/merge-component! app Person {:person/id 3 :person/name "Sally" :person/address {:address/id 33 :address/street "111 Main St"}}
:replace [:person/id 1 :person/spouse])
(app/current-state app)
=>
{:fulcro.inspect.core/app-id "user/Root",
:root/people [[:person/id 1] [:person/id 2]],
:person/id {1 #:person{:id 1, :name "Bob", :spouse [:person/id 3]},
2 #:person{:id 2, :name "Judy"},
3 #:person{:id 3, :name "Sally", :address [:address/id 33]}},
:address/id {33 #:address{:id 33, :street "111 Main St"}}}or this new person should be shown at the beginning of the :root/people list:`
(merge/merge-component! app Person {:person/id 3 :person/name "Sally" :person/address {:address/id 33 :address/street "111 Main St"}}
:prepend [:root/people])
(app/current-state app)
=>
{:fulcro.inspect.core/app-id "user/Root",
:root/people [[:person/id 3] [:person/id 1] [:person/id 2]],
:person/id {1 #:person{:id 1, :name "Bob"},
2 #:person{:id 2, :name "Judy"},
3 #:person{:id 3, :name "Sally", :address [:address/id 33]}},
:address/id {33 #:address{:id 33, :street "111 Main St"}}}The same thing applies when you’re writing mutations. The returning helper for mutations is just a way of sending
a query on the return value of a mutation that is then merged into your database. It’s all the same stuff!
(defmutation update-person [new-name]
(remote [env]
(-> env
(m/returning Person))))is a mutation that will (only) do remote operations on person, but will also return the updated person. When it does
so the server should use the query (of Person) to return only the items the UI cares about, and Fulcro will merge the resulting
data using merge-component! via Person.
Of course, that would only update the person in-place, and would not change any graph edges. Making new edges is also possible on mutation return values. Say you use Person to represent your system users. When you application first loads you might want a mutation to run that looks something like this:
(defmutation resume-session [new-name]
(remote [env]
(-> env
(m/with-target [:current-user])
(m/returning Person))))where the server-side implementation of resume-session looks to see if there is a cookie that represents a known
user. If so, it returns the identity according to the Person query, and when the application receives the result
it joins that person to the graph at the root "edge" :current-user. The UI could then integrate that in
for display in the header to indicate who is logged in:
(defsc Root [this props]
{:query [{:current-user (comp/get-query Person)}
{:root/people (comp/get-query Person)}]
:initial-state (fn [_] {:current-user {:person/id :unknown :person/name "Unknown"}
:root/people [(comp/get-initial-state Person {:id 1 :name "Bob"})
(comp/get-initial-state Person {:id 2 :name "Judy"})]})})Now that you have the general idea of the core APIs of Fulcro, the remaining chapters should be considerably easier to digest. Every other feature of Fulcro is kind of a "side detail" or "gravy on top".
The React-centric APIs (i.e. DOM factories) have to do with writing web applications. The transaction and mutation system are central to the overall operation of a Fulcro application and provide a number of services that make writing applications more sane. The routing APIs are really just two ways of how you might go about doing UI routing in Fulcro. The state machine API is a kind of "mega mutation" system for writing coordinated bits of logic with your UI.
Ultimately there is a lot of "support" in the Fulcro ecosystem of libraries, but at the core is this simple mechanism: The shape of your UI mirrors the shape of the query which in turn mirrors the resulting shape of the data. That symmetry of shape leads to the ability to easily transform the data between normalized and denormalized forms, which in turn leads to the ability to easily evolve your graph of data, and thus your UI.
Debugging becomes largely a task of "Does my data have the right shape, and if not, why?"
7. Components and Rendering
7.1. HTML5 Element Factories
The core HTML5 elements all have simple factory functions that generate the core elements that stand-in for the real DOM. These stand-ins (commonly referred to as the virtual DOM or VDOM) are ultimately what React uses to generate, diff, and update the real DOM.
So, there are functions for every possible HTML5 element.
These are in the
com.fulcrologic.fulcro.dom namespace.
(ns app.ui
(:require [com.fulcrologic.fulcro.dom :as dom]))
...
(dom/div :.some-class
(dom/ul {:style {:color "red"}}
(dom/li ...)))|
Important
|
If you’re writing your UI in CLJC files then you need to make sure you use a conditional reader to pull in the proper server DOM functions for Clojure:
(ns app.ui (:require #?(:clj [com.fulcrologic.fulcro.dom-server :as dom] :cljs [com.fulcrologic.fulcro.dom :as dom]))
|
The notation allowed is as follows:
(dom/div "Hello") ; no props
(dom/div nil "Hello") ; nil props (may perform slightly better)
(dom/div #js {:data-x 1} ...) ; js objects are allowed
(dom/div :.cls.cls2#id ...) ; shorthand for specifying static classes and ID
(dom/div :.cls {:data-x 2} "Ho") ; shorthand + propsThere is also a :classes property that can be used to add (typically via expressions) additional classes.
It drops nil, and allows classname keywords and strings as well:
(dom/div :.a {:className "other" :classes [(when hidden "hidden") (if tall :.tall :.short)]} ...)Assuming hidden and (not tall) would yield classes "a other hidden short" on output.
Of course you probably don’t need all of these at once, but supporting them all lets you programmatically combine them when generating props.
NOTE:
This feature does not work on props sent with #js notation.
Remember that this (nested) call of functions results in a representation (React Elements) of what you’d like to end up on the screen.
The next level of abstraction is simply a function. Combining more complex bits of UI into a function is a great way to group re-usable nested DOM:
(defn my-header []
(dom/div :.some-class
(dom/ul
(dom/li ...))))but remember that a function has no component hooks, so it cannot do things like short-circuit rendering when props have not changed.
7.1.1. Fulcro and React DOM – Notes
Here are some common things you’ll want to know how to do that are different when rendering with Fulcro:
-
Attributes follow the react naming conventions for [Tags and Attributes](https://facebook.github.io/react/docs/tags-and-attributes.html)
-
As an example - CSS class names are specified with
:classNameinstead of:class.
-
-
Any time an element includes a collection of children they should each have a unique
:keyattribute. This helps the React diff figure out how that collection has changed. You will get warnings in the browser console if you fail to do so.
7.1.2. Converting HTML to Fulcro
Below is a simple little live application that can convert valid HTML into the Clojure(script) you’d use within a Fulcro component.
Note that stray whitespace will be converted to (harmless) things like " \n" that can be easily removed, and the output indentation isn’t ideal; Still, it turns the task into one of simple formatting:
(ns book.html-converter
(:require
#?(:cljs [com.fulcrologic.fulcro.dom :as dom]
:clj [com.fulcrologic.fulcro.dom-server :as dom])
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.fulcrologic.fulcro.dom.html-entities :as ent]
[taoensso.timbre :as log]
[camel-snake-kebab.core :as csk]
[hickory.core :as hc]
[clojure.set :as set]
[clojure.pprint :refer [pprint]]
[clojure.string :as str]))
(def attr-renames {:class :className
:for :htmlFor
:tabindex :tabIndex
:viewbox :viewBox
:spellcheck :spellcheck
:autocorrect :autoCorrect
:autocomplete :autoComplete})
(defn fix-style [style]
(try
(let [lines (str/split style #";")
style-map (into {} (mapv (fn [line]
(let [[k v] (str/split line #":")]
[(csk/->camelCase (keyword k)) (str/trim v)])) lines))]
style-map)
(catch #?(:cljs :default :clj Exception) e
style)))
(defn classes->keyword [className]
(when (seq (str/trim className))
(let [classes (keep (fn [e] (when (seq e) e)) (str/split className #" *"))
kw (keyword (str "." (str/join "." classes)))]
kw)))
(defn- chars->entity [ns chars]
(if (= \# (first chars))
(apply str "&" (conj chars ";")) ; skip it. needs (parse int, convert base, format to 4-digit code)
(if (seq ns)
(symbol ns (apply str chars))
(symbol (apply str chars)))))
(defn- parse-entity [stream result {:keys [entity-ns] :as options}]
(loop [s stream chars []]
(let [c (first s)]
(case c
(\; nil) [(rest s) (if (seq chars)
(conj result (chars->entity entity-ns chars))
result)]
(recur (rest s) (conj chars c))))))
(defn- html-string->react-string [html-str {:keys [ignore-entities?] :as options}]
(if ignore-entities?
html-str
(loop [s html-str result []]
(let [c (first s)
[new-stream new-result] (case c
nil [nil result]
\& (parse-entity (rest s) result options)
[(rest s) (conj result c)])]
(if new-stream
(recur new-stream new-result)
(let [segments (partition-by char? new-result)
result (mapv (fn [s]
(if (char? (first s))
(apply str s)
(first s))) segments)]
result))))))
(defn element->call
([elem]
(element->call elem {}))
([elem {:keys [ns-alias keep-empty-attrs?] :as options}]
(cond
(and (string? elem)
(let [elem (str/trim elem)]
(or
(= "" elem)
(and
(str/starts-with? elem "<!--")
(str/ends-with? elem "-->"))
(re-matches #"^[ \n]*$" elem)))) nil
(string? elem) (html-string->react-string (str/trim elem) options)
(vector? elem) (let [tag (name (first elem))
raw-props (second elem)
classkey (when (contains? raw-props :class)
(classes->keyword (:class raw-props)))
attrs (cond-> (set/rename-keys raw-props attr-renames)
(contains? raw-props :class) (dissoc :className)
(contains? raw-props :style) (update :style fix-style))
children (keep (fn [c] (element->call c options)) (drop 2 elem))
expanded-children (reduce
(fn [acc c]
(if (vector? c)
(into [] (concat acc c))
(conj acc c)))
[]
children)]
(concat (list) (keep identity
[(if (seq ns-alias)
(symbol ns-alias tag)
(symbol tag))
(when classkey classkey)
(if keep-empty-attrs?
attrs
(when (seq attrs) attrs))]) expanded-children))
:otherwise "")))
(defn html->clj-dom
"Convert an HTML fragment (containing just one tag) into a corresponding Dom cljs.
Options is a map that can contain:
- `ns-alias`: The primary DOM namespace alias to use. If not set, the calls will not be namespaced.
- `keep-empty-attrs?`: Boolean (default false). Output (dom/p {} ...) vs (dom/p ...).
- `entity-ns`: String (defaults to \"ent\"). When named HTML entities are found they are converted to the Fulcro
HTML entity ns symbols that stand for the correct unicode (e.g. \""\" -> `ent/quot`). This is the ns alias
for those.
- `ignore-entities?`: Boolean (default false). If true, entities in strings will not be touched.
"
([html-fragment options]
(let [hiccup-list (mapv hc/as-hiccup (hc/parse-fragment html-fragment))
options (cond-> options
(not (contains? options :entity-ns)) (assoc :entity-ns "ent"))]
(let [result (keep (fn [e] (element->call e options)) hiccup-list)]
(if (< 1 (count result))
(vec result)
(first result)))))
([html-fragment]
(html->clj-dom html-fragment {:ns-alias "dom"})))
(defmutation convert [p]
(action [{:keys [state]}]
(let [html (get-in @state [:top :conv :html])
cljs (html->clj-dom html)]
(swap! state assoc-in [:top :conv :cljs] {:code cljs}))))
(defsc HTMLConverter [this {:keys [html cljs]}]
{:initial-state (fn [params] {:html "<div id=\"3\" class=\"b\"><p>Paragraph</p></div>" :cljs {:code (list)}})
:query [:cljs :html]
:ident (fn [] [:top :conv])}
(dom/div {:className ""}
(dom/textarea {:cols 80 :rows 10
:onChange (fn [evt] (m/set-string! this :html :event evt))
:value html})
(dom/button :.c-button {:onClick (fn [evt]
(comp/transact! this [(convert {})]))} "Convert")
(dom/pre {} (with-out-str (pprint (:code cljs))))))
(def ui-html-convert (comp/factory HTMLConverter))
(defsc Root [this {:keys [converter]}]
{:initial-state {:converter {}}
:query [{:converter (comp/get-query HTMLConverter)}]}
(ui-html-convert converter))7.2. The defsc Macro
Fulcro’s defsc is the main macro you’ll use to create components. It is sanity-checked for the most common elements: ident (optional), query, props destructuring, and initial state (optional). The sanity checking prevents a lot of the most common errors when writing a component, and the concise syntax reduces boilerplate to the essential novelty. The name means "define stateful component" and is intended to be used with components that have queries (though that is not a requirement).
7.2.1. The Argument List
The primary argument list contains the common elements you might need to use in the body:
(defsc [this props <optional-computed> <optional-extensible-arg>]
{ ...options... }
(dom/div {:onClick (:onClick computed)} (:db/id props)))The last parameter is used by libraries to augment defsc with any additional data they might want to make convenient.
See the fulcro-garden-css library for an example.
Only the first two parameters are required, so you can even write:
(defsc [this props]
{ ...options... }
(dom/div (:db/id props)))Argument Destructuring
The parameter list fully supports Clojure destructuring on the props, computed, and "extra map" without having to write a separate let:
(defsc DestructuredExample [this
{:keys [db/id] :as props}
{:keys [onClick] :as computed :or {onClick identity}}]
{:query [:db/id]
:initial-state {:db/id 22}}
(dom/div
(str "Component: " id)))7.2.2. Options – Lambda vs. Template
The core options (:query, :ident, :initial-state) of defsc are special.
They support both a lambda and a template form.
The template form is shorter and enables some sanity checks; however, it is not expressive enough to cover all possible cases.
The lambda form is slightly more verbose, but enables full flexibility at the expense of the sanity checks.
IMPORTANT NOTE:
In lambda mode ident can use this and props from the defsc argument list.
The other two are primarily used "statically" and have no sane this or props.
7.2.3. Ident Generation
If you include :ident, it can take three possible forms: a template, lambda, or keyword.
Keyword Idents
The keyword option is a popular option if you’re following the recommended naming conventions. It means that the table name and the ID key of the entity are the same.
Template Idents
A template ident is just a vector that patterns what goes in the ident. The first element is always literal, and the second is the name of the property to pull from props to get the ID.
If you use the template mechanism you get some added sanity checks: it won’t compile if your ID key isn’t in your query, eliminating some possible frustration.
So, the following two forms are identical:
(defsc Person [_ _]
{:ident :person/id
...
;; OR
(defsc Person [_ _]
{:ident [:person/id :person/id]
...Lambda Idents
The above options are great for the common cases, but they don’t work if you have a single instance ever (i.e. you want a literal second element), and they won’t work at all for union queries. They also do not support embedded code. Therefore, if you want a more advanced ident you’ll need to spell out the code.
defsc causes an ident lambda to "close over" the defsc argument list, which at least eliminates some of the boilerplate:
(defsc UnionComponent [this {:keys [db/id component/type]}]
{:ident (fn [] (union-ident type id))} ; id and type are destructured into the method for you.
...)7.2.4. Query
defsc also allows you to specify the query as a template or lambda.
Template Query
The template form is strongly recommended for most cases, because without it many of the sanity checks won’t work.
In template mode, the following sanity checks are enabled:
-
The props destructuring can only include things that are in the query.
-
The ident’s id property is checked to make sure it is in the query (if ident is in template mode)
-
The initial app state can only contains things that are also queried for (if it is in template mode as well)
Lambda Query
This mode is necessary if you use more complex queries. The template mode currently does not support union queries or wildcards. It is also useful when you want to disable the sanity checks for any reason.
To use this mode, specify your query as (fn [] [:x]).
7.2.5. Initial State
As with :query and :ident, :initial-state supports a template and lambda form.
The template form for initial state is a bit magical, because it tries to sanity check your initial state, but also has to support relations through joins.
Finally it tries to eliminate typing for you by auto-wrapping nested relation initializations in get-initial-state for you by deriving the correct class to use from the query.
This further reduces the chances of error; however, you may find the terse result more difficult to read and instead choose to write it yourself.
Both ways are supported:
Lambda mode
This is simple to understand, and all you need to see is a simple example:
(defsc Component [this props]
{:initial-state (fn [params] ...exactly the state this component should start with...)}
...)Template Mode
In template mode :initial-state converts incoming parameters (which must use simple keywords) into :param/X keys.
So,
(defsc Person [this props]
{:initial-state {:db/id :param/id}}
...)means:
(defsc Person [this props]
{:initial-state (fn [params] {:db/id (:id params)}})}
...)It is even more powerful than that, because it analyzes your query and can deal with to-one and to-many join initialization as well:
(defsc Person [this props]
{:query [{:person/job (comp/get-query Job)}]
:initial-state {:person/job {:job/name "Welder"}}
...)means (in simplified terms):
(defsc Person [this props]
{:initial-state (fn [params] {:person/job (comp/get-initial-state Job {:job/name "Welder"})})}
...)Notice the magic there. Job was pulled from the query by looking for joins on the initialization keyword (:person/job).
To-many relations are also auto-derived:
(defsc Person [this props]
{:query [{:person/prior-jobs (comp/get-query Job)}]
:initial-state {:person/prior-jobs [{:job/name "Welder"} {:job/name "Cashier"]}
...)means (in simplified terms):
(defsc Person [this props]
{:initial-state (fn [params]
{:person/prior-jobs [(comp/get-initial-state Job {:job/name "Welder"})
(comp/get-initial-state Job {:job/name "Cashier"})]})}
...)The internal steps for processing this template are:
-
Replace all uses of :param/nm with (get params :nm)
-
The query is analyzed for joins on keywords (ident joins are not supported).
-
If a key in the initial state matches up with a join, then the value in initial state must be a map or a vector. In that case (get-initial-state JoinClass p) will be called for each map (to-one) or mapped across the vector (to-many).
-
REMEMBER: the value that you use in the initial-state for children is the parameter map to use against that child’s initial state function. To-one and to-many relations are implied by what you pass (a map is to-one, a vector is to-many).
Step (1) means that nesting of param-namespaced keywords is supported, but realize that the params come from the declaring component’s initial state parameters, they are substituted before being passed to the child.
7.2.6. Pre-Merge
The :pre-merge option offers a hook to manipulate data entering your Fulcro app at a component level.
The option looks like this:
(defsc Countdown [this props]
{:pre-merge (fn [env] ...)}
...)The :pre-merge lambda receives a single map containing the following keys:
-
:data-tree- the new data tree entering the database (e.g. from a load or explicitmerge-component!) -
:current-normalized- the current entity value (normalized form in the db) -
:state-map- the current normalized client database (as a map, not an atom) -
:query- the query being used to for this request (user may have modified the original using:focus,:withoutor:update-queryduring the load call
and returns the data that should actually be merged into app state. You will need it when for example loading domain data from the server while also requiring the presence of some ui-only props (such as a child router state or form data). This feature requires a complete understanding of normalization and full stack operation, and is covered in a later chapter.
7.2.7. Component Constructor
It is sometimes useful to be able to run some code once on component construction.
In React this is particularly useful when you want a function for saving off :ref or as other callbacks (so the function isn’t changing all the time), or copy something from props into state.
Use :initLocalState to do these operations before you return a value.
7.2.8. React Lifecycle Methods
The options of defsc allow for React Lifecycle methods to be defined (as lambdas).
The first argument of all non-static lifecycle methods is this.
The React documentation describes any further arguments.
Where props or state are expected you will be given Fulcro’s version of those (cljs data instead of raw js).
Where the current props are not an argument you can call (comp/props this) to get them, and you can obtain computed using comp/get-computed.
The signatures are:
(defsc Component [this props]
:initLocalState (fn [this props] ...)
:shouldComponentUpdate (fn [this next-props next-state] ...)
:componentWillReceiveProps (fn [this next-props] ...)
:componentWillUpdate (fn [this next-props next-state] ...)
:componentDidUpdate (fn [this prev-props prev-state] ...)
:componentWillMount (fn [this] ...)
:componentDidMount (fn [this] ...)
:componentWillUnmount (fn [this] ...)
;; Replacements for deprecated methods in React 16.3+
:UNSAFE_componentWillReceiveProps (fn [this next-props] ...)
:UNSAFE_componentWillUpdate (fn [this next-props next-state] ...)
:UNSAFE_componentWillMount (fn [this] ...)
;; ADDED for React 16:
:componentDidCatch (fn [this error info] ...)
:getSnapshotBeforeUpdate (fn [this prevProps prevState] ...)
;; NOTE: getDerivedStateFromProps must return a js map. Fulcros C.L. state is under the "fulcro$state" key.
:getDerivedStateFromProps (fn [props state] #js {"fulcro$state" {:error? true}}) ; static
;; ADDED for React 16.6:
:getDerivedStateFromError (fn [error] ...) ; static. **NOTE**: Sets low-level state, Use get-react-state.See the React documentation for more details on how these work.
Component Local State and Errors
Fulcro wraps React’s state such that you can easily store cljs data in the component (e.g. arguments to methods like
componentDidUpdate prev-state will be a cljs map, NOT the raw JS one that React uses).
The same is true for the return value of initLocalState:
You return a CLJS map, and it is safely stored in react state but otherwise behaves just like the native.
The advantage of this is twofold:
-
Convenience: You get to use immutable data for component-local state
-
Speed: Fulcro is able to very quickly compare and short-circuit React rendering because immutable state is very fast to compare (it can mostly be a single reference compare).
This is accomplished by storing the "Fulcro" version of component state under the fulcro$state key in the low-level js state.
Normally, this is of no concern to you at all, but React 16.7 added a static lifecycle method called getDerivedStateFromError
whose return value is meant to be a js map that gets merged to the low-level state, and there is no internal hook or
hack (yet found) to merge that into the correct Fulcro location.
Thus, if you provide a getDerivedStateFromError your return value (a CLJS map) will overwrite your current component local state.
If you’re not using component local state for anything else, then this is probably just fine, but if you have important information in component-local state you may want to choose an alternative.
One workaround is to set state in componentDidCatch.
This is deprecated by React because it happens in a different phase of the React processing, so you should read up on that
in the React docs to see if it is acceptable for your case.
Another (trivial but possibly annoying) workaround is to write a wrapper component that does nothing but deal with errors, so that the state is never used for anything but error handling.
7.2.9. Sanity Checking
The sanity checking mentioned in the earlier sections causes compile errors. The errors are intended to be self-explanatory. They will catch common mistakes (like forgetting to query for data that you’re pulling out of props, or mis-spelling a property).
For example, try:
-
Mismatching the name of a prop in a query with a destructured name in props.
-
Destructuring a prop that isn’t in the query
-
Including initial state for a field that is not listed as a prop or child in options.
-
Using a scalar value for the initial value of a joined child (instead of a map or vector of maps)
-
Forget to query for the ID field of a component that is used in an ident
In some cases the sanity checking is too aggressive or may mis-detect a problem. To get around it simply use the lambda style.
7.3. The Component Registry
You may find it useful to note that any Fulcro component that is loaded in your application will appear in a global component registry. You can look up such components using a symbol or keyword that matches the fully namespace-qualified name of the component:
(comp/registry-key->class `app.ui/Root)
;; OR
(comp/registry-key->class :app.ui/Root)This comes in handy for things like code splitting (where the dynamically loaded code will appear in the registry), tracking classes (by name) in app state (which cannot appear there as "code").
7.4. Factories
Factories are how you generate React elements (the virtual DOM nodes) from your React classes defined with
defsc.
You make a new factory using com.fulcrologic.fulcro.components/factory:
(def ui-component (comp/factory MyComponent {:keyfn f}))The :keyfn option is a function against props to generate a React key.
This should be supplied on any component that will appear as a to-many child to ensure React rendering can properly diff.
In Fulcro documentation we generally adopt the naming convention for UI factories to be prefixed with ui-.
This is because you often want to name joins the same thing as a component: e.g. your query might be
[{:ui/child (comp/get-query Child)}], and then when you destructure in render: (let [{:ui/keys [child]} (comp/props this) …
you have local data in the symbol child.
If your UI factory was also called child then it would cause annoying name collisions.
Prefixing the factories with ui- eliminates such collisions.
7.5. Render and Props
Properties are always passed to a component factory as the first argument and are not optional:
(ui-child child-props)The properties are available as the second argument to defsc for the render body, but can also be accessed by calling com.fulcrologic.fulcro.components/props on this.
The latter approach is useful in functions that receive the instance as an argument.
In components with queries there is a strong correlation between the query (which must join the child’s query), props (from which you must extract the child’s props), and calling of the child’s factory (to which you must pass the child’s data).
If you are using components that do not have queries, then you may pass whatever properties you deem useful.
Such components do not benefit from many other Fulcro advantages. However, you may still wish to use defsc for rendering optimization.
Details about additional aspects of rendering are in the sections that follow.
7.5.1. Derived Values
It is possible that your logic and state will be much simpler if your UI components derive some values at render time. A prime example of this is the state of a "check all" button. The state of such a button is dependent on other components in the UI, and it is not a separate value. Thus, your UI may want to compute it and not store it else it could easily become out of sync and lead to more complex logic.
(defn item-checked? [item] (:checked? item))
(defsc Checkboxes [this {:list/keys [items]}]
{:query [{:list/items (comp/get-query CheckboxItem)}]}
(let [all-checked? (every item-checked? items)]
(dom/div
"All: " (dom/input {:checked all-checked? ...})
(dom/ul ...))))There is a problem, though: the rendering refresh algorithms of Fulcro tries to avoid rendering things that don’t actually change. In this case the thing that is changing is a child (it is being toggled). Technically this changes the parent’s props (because the child flows through it) but some of Fulcro’s rendering optimizations might not see it that way (nothing the parent directly queried for changed).
If you’re using the ident-optimized render, then you’ll want to add a refresh option to the transaction that changes the child:
(comp/transact! this [(toggle-checkbox {...})] {:refresh [:list/items]})The :refresh option indicates that the property (or ident) listed changed in a way that any component querying directly for it should be refreshed even if the data that the component itself uses did not change.
|
Note
|
The ident of this is always included in the refresh list for you; therefore you can avoid having to deal with this additional parameter if you run the toggle against the parent (e.g. via a callback sent to the child).
|
General Guidelines for Derived Values
You should consider computing a derived value when:
-
The known data from the props already gives you sufficient information to calculate the value.
-
The computation is relatively light.
Some examples where UI computation are effective, light, or even necessary:
-
Rendering an internationalized value. (e.g.
tr) -
Rendering a check-all button
-
Rendering "row numbering" or other decorations like row highlighting
There are some trade-offs, but most significantly you generally do not want to compute things like the order/pagination of a list of items. The logic and overhead in sorting and pagination often needs caching, and there are clear and easy "events" (user clicking on sort-by-name) that make it clear when to call the mutation to update the database. You still have to store the selected sort order, and you have to have idents pointing to the list of items. It is possible for your "selected sort order" and list to become out of sync, but the trade-offs of sorting in the UI are typically high, particularly when pagination is involved and large amounts of data would have to be fed to the UI.
7.5.2. Computed Props and Callbacks
Many reusable components will need to tell their parent about some event. For example, a list item generally wants to tell the parent when the user has clicked on the "remove" button for that item. The item itself cannot be truly composable if it has to know details of the parent. But a parent must always know the details of a child (it rendered it, didn’t it?). As such, manipulations that affect the content of a parent should be communicated to that parent for processing. The mechanism for this is identical to what you’d do in stock React: callbacks from the child.
The one major difference is how you pass the callback to a component.
The query and data feed mechanisms that supply props to a component are capable of refreshing a child without refreshing a parent. This UI optimization can pull the props directly from the database using the query, and re-feed them to the child.
But this mechanism knows nothing about callbacks, because they are not (and should not be) stored in the client database. Parents should not pass callbacks through the props because the parent is where they are created, but the parent may not be involved in the refresh!
So, any value (function or otherwise) that is generated on-the-fly by the parent must be passed by wrapping them in
com.fulcrologic.fulcro.components/computed.
This tells the data feed system how to reconstruct the complete data should it do a targeted update.
(defsc Child [this {:keys [y]}]
{:query [:y]}
(let [onDelete (comp/get-computed this :onDelete)]
...))
(defsc Parent [this {:keys [x child]}]
{:query [:x {:child (comp/get-query Child)}]}
(let [onDelete (fn [id] (comp/transact! ...))
child-props-with-callbacks (comp/computed child {:onDelete onDelete})]
(ui-child child-props-with-callbacks)))|
Warning
|
Not understanding this can cause a lot of head scratching: The initial render will always work perfectly, because the parent is involved. All events will be processed, and you’ll think everything is fine; however, if you have passed a callback incorrectly it will mysteriously stop working after a (possibly unnoticeable) refresh. This means you’ll "test it" and say it is OK, only to discover you have a bug that shows up during subsequent use. |
For convenience there is a function that can generate a factory that accepts computed data as a second argument to the factory so you can avoid calling computed:
(defsc Child [this {:keys [y]}]
{:query [:y]}
(let [onDelete (comp/get-computed this :onDelete)]
...))
(def ui-child (comp/computed-factory Child))
(defsc Parent [this {:keys [x child]}]
{:query [:x {:child (comp/get-query Child)}]}
(let [onDelete (fn [id] (comp/transact! ...))]
(ui-child child {:onDelete onDelete})))7.5.3. Children
A very common pattern in React is to define a number of custom components that are intended to work in a nested fashion.
So, instead of just passing props to a factory, you might also want to pass other React elements.
This is fully supported in Fulcro, but can cause confusion when you first try to mix it with the data-driven aspect of the system.
Working with Children
If children are passed to your factory they will be available in (comp/children this).
Basically, the child or children can simply be dropped into the place where they should be rendered.
(defsc Parent [this props]
{:query [:x]}
(apply dom/div :.ui.grid
(comp/children this)))
(def ui-parent (comp/factory Parent))
(defsc Component [this {:keys [parent-props child-props other-child-props]}]
{:query [{:parent-props (get-query X)}
{:child-props (get-query Y)}
{:other-child-props (get-query Z)}]
...}
(ui-parent parent-props
(ui-child child-props)
(ui-child other-child-props)))The main trick is making sure you get the data feed right.
In this case the data is all obtained by the component rendering this cluster, even though the UI tree has a slightly different shape.
Technically they are all "data children" of Component.
Often, the Parent in this situation is something like a modal or layout component that may or may not even need a query.
React 16 Fragments and Returning Multiple Children
React 16 allows you to return a vector of children or a Fragment from a component (so you no longer are forced to have a single child as a return value).
Fulcro’s components namespaces include a fragment
function to wrap elements in a fragment:
(defsc X [this props]
(comp/fragment ; in the comp namespace, because it isn't DOM specific. Could be used with native.
(dom/p "a")
(dom/p "b")))or
(defsc X [this props]
[(dom/p {:key "a"} "a") (dom/p {:key "b"} "b")])
(def ui-x (comp/factory X))allows your component to return multiple elements that are spliced into the parent without any "wrapping" elements in the DOM. If you return a vector then you also need to supply React keys.
(dom/div (ui-x)) => <div><p>a</p><p>b</p></div>See React documentation for more details.
Mixing Data-Driven Children with UI-Only Concerns
At first this seems a little mind-bending, because you are in fact nesting components in the UI, but the query nesting need only mimic the stateful portion of the UI tree. This means there is ample opportunity to use React children in a way that looks incorrect from what you’ve learned so far. On deeper inspection it turns out it is in alignment with the rules, but it takes a minute on first exposure.
Take a collapse component: It needs state of its own in order to know when it is collapsed, and we’d like that to be part of the application database. However, the children of the collapse cannot be known in advance when writing the collapse reusable library component.
The solution is simple once you see it: Query for the collapse component’s state and the child state in the common parent component, then do the UI nesting in that component. Technically the component that is "laying out" the UI (the ultimate parent) is in charge of both obtaining and rendering the data. The fact that the UI child ends up nested in a query sibling is perfectly fine.
The collapse component itself is only concerned with the fact that it is open/closed, and that it has children that should be shown/hidden. The actual DOM elements of those children are immaterial, and can be assembled by the parent:
(defsc CollapseExample [this {:keys [collapse-1 child]}]
{:initial-state (fn [p] {:collapse-1 (comp/get-initial-state Collapse {:id 1 :start-open false})})
:query [{:collapse-1 (comp/get-query Collapse)}
{:child (comp/get-query SomeChild)}]}
(dom/div
(ui-collapse collapse-1
(ui-child child))))7.6. Controlled Inputs
Form inputs in React can take two possible approaches: controlled and uncontrolled.
The browser maintains the value state of inputs for you as mutable data; however, this breaks our overall model of pure rendering! If your UI gets rather large, it is possible that UI updates on keystrokes in form inputs may be too slow (this is largely not a problem in 3.2 and above).
|
Note
|
Technically the low-level browser maintains input state and changes it due to locale, input devices, etc. If you set it the value via js while the user is typing then ugly things happen…so controlled inputs are actually an illusion in React. |
This is the same sort of trade-off that we talked about when covering component local state for rendering speed with more graphical components. Fulcro is designed to be fast enough that then your application should be fast enough to do database updates on every keystroke, and you can keep all input changes in your client database. See the optimization guidelines if you have problems, and ideally just use Fulcro 3.2 or above.
In general it is recommended that you use controlled inputs and retain the benefits of pure rendering: no embedded state, your UI exactly represents your data representation, concrete devcards support for UI prototyping, and full support viewer support.
Most inputs become controlled when you set their :value property.
The table below lists the mechanism whereby a form input is completely controlled by React:
| Input type | Attribute | Notes |
|---|---|---|
input |
:value |
(not checkboxes or radio) |
checkbox |
:checked |
|
radio |
:checked |
(only one in a group should be checked) |
textarea |
:value |
|
select |
:value |
Instead of marking an option selected. Match |
|
Important
|
React will consider nil to mean you want an uncontrolled component.
This can result in a warning about converting uncontrolled to controlled components.
In order to prevent this warning you should make sure that :checked is always a boolean, and that other inputs have a valid :value (e.g. an empty string).
The
select input can be given an "extra" option that stands for "not selected yet" so that you can start its value at something valid.
|
|
Note
|
HTML inputs deal in strings (even date and numeric controls).
Be careful when using the value from change events in your database, because you may change your data to a string by mistake.
A nice way to handle this is to wrap inputs with your own components that do data transforms in-between :value and :onChange.
See StringBufferedInput
|
See React Forms for more details.
7.6.1. Advanced Details of Wrapped Inputs
React is actually designed for you to do controlled components via component-local state, and in reality it doesn’t deal well with a behind-the-scenes persistence mechanism tracking the state. Fulcro actually has a wrapper around inputs to deal with these complications for you. Other libraries do as well. They are ugly bits of code that do all sorts of magic to work around the problem.
If you use any kind of library that provides input-like controls you may experience similar kinds of issues.
You have three options to make them behave correctly. The ideal one is to use Fulcro 3.2 or better. The other
older options are to use component-local state with them, or similarly wrap them using Fulcro’s pre-built wrapper code.
There is a function in the dom namespace called wrap-form-element that can be used to create a factory for input-like controls that misbehave.
If you’re interested in the complete gory details, check out a more complete write-up that describes this historical problem and how it is solved in Fulcro 3.2 and above.
7.6.2. Fulcro 3.2 Inputs
Fulcro 3.2 released a dramatic improvement to the controlled input equation. It turns out that Fulcro had a mechanism
for quite some time that can be used to solve the asynchronous problem with inputs much more cleanly that wrapping them
with crazy ugly code and caching values. Technically, the feature is known internally as "tunneled props", but the simple explanation is
just this: Fulcro knows how to send new props to a stateful component (that has a query and ident) by using js/setState
on the component.
So the solution in Fulcro is quite simple: do the transaction’s optimistic updates synchronously and immediately tunnel
the props back to the component through React’s setState.
Now, we’d prefer not to break out of Fulcro’s abstractions,
so this is done via a new option that can be passed to transact! and an option: :synchronously? true. As a convenience
there is a simple wrapper called transact!! that sets the option for you.
So, the current best practice is for your controlled input usage to look like this:
(defmutation set-thing-label [...])
...
(defsc Thing [this {:thing/keys [label]}]
{:query [:thing/id :thing/label]
:ident :thing/id}
...
(dom/input {:onChange #(transact!! this [(set-thing-label {:value (.. % -target -value)})])]))Voila! You’re now doing forms the React way while still looking like you’re doing them the Fulcro way!
This special transact!! will work just as well with imported (vanilla js) React input components.
You can technically improve the performance of this (very slightly) by telling Fulcro that you no longer want the
dom/input to be a wrapped input by setting a compiler option, but beginners should not bother with this.
The mutations namespace now also includes set-string!!, set-integer!!, etc. These are identical to their
single ! counterparts, except they use synchronous transact!!.
One final note: Synchronous transactions will not cause a full UI refresh. It will only target refreshes to the
component passed as an argument (which must have an ident). This ensure speedy performance, but if the parent
component uses the props of children to derive values (e.g. the number of items checked), then the parent will
not refresh. The most general way to solve that is to schedule your own UI refresh via app/schedule-render!
at a point that makes sense in your application (e.g. perhaps on field blur).
See also the synchronous transaction plugin for Fulcro.
7.6.3. StringBufferedInput
Often you want to use non-string data types for attributes in your client database, but HTML inputs only deal in
strings. The com.fulcrologic.fulcro.dom.inputs namespace includes a helper function that can return a new
generated input type that can auto-transform between the low-level input and your data model. The namespace
also includes a few pre-written examples. See the docstrings for more details, but here’s an input type
that allows the user to input only symbol characters and makes sure the result is a keyword in the client db:
(defn symbol-chars
"Returns `s` with all non-digits stripped."
[s]
(str/replace s #"[\s\t:]" ""))
(def ui-keyword-input
"A keyword input. Used just like a DOM input, but requires you supply nil or a keyword for `:value`, and
will send a keyword to `onChange` and `onBlur`. Any other attributes in props are passed directly to the
underlying `dom/input`."
(comp/factory (StringBufferedInput ::KeywordInput {:model->string #(str (some-> % name))
:string-filter symbol-chars
:string->model #(when (seq %)
(some-> % keyword))})))Basically you just need to supply an optional filter, and two conversion functions.
7.7. Using defsc for Rendering Optimization
Normally you’ll define components that have both a query and ident; however, it is perfectly legal to define components that are completely controlled by their parent and have no identity of their own.
This is useful when you have a component that has a rather large UI, but for which the query does not need further breakdown.
Using defsc instead of defn to render subsections of a component means that you get shouldComponentUpdate optimizations that will short-circuit automatically when the props sent to those components have not changed.
A simple example:
(defsc TopBar [this {:keys [title]}]
{}
(dom/div
...
(dom/h3 title)))
(def ui-top-bar (comp/factory TopBar))instead of
(defn ui-top-bar [{:keys [title]}]
(dom/div
...
(dom/h3 title)))7.8. React Lifecycle Examples
There are some common use-cases that can only be solved by working directly with the React Lifecycle methods.
Some topics you should be familiar with in React to accomplish many of these things are:
-
Component references: A mechanism that allows you access to the real DOM of the component once it’s on-screen.
-
Component-local state: A stateful mechanism where mutable data is stored on the component instance.
-
General DOM manipulation. Clojurescript builds using the Google Closure compiler and therefore includes the Google Closure library, which in turn has all sorts of helpful low-level functions should you need them.
7.8.1. Focusing an input
Focus is a stateful browser mechanism, and React cannot infer the rendering of "focus" from pure data.
As such, when you need to deal with UI focus it generally involves some interpretation, and possibly component local state.
The most common way of dealing with deciding when to focus is to look at a component’s prior vs. next properties.
This can be done in componentDidUpdate.
For example, say you have an item that renders as a string, but when clicked turns into an input field.
You’d certainly want to focus that, and place the cursor at the end of the existing data (or highlight it all).
If your component had a property called editing? that you made true to indicate it should render as an input instead of just a value, then you could write your focus logic based on the transition of your component’s props from :editing? false to :editing? true.
(ns book.ui.focus-example
(:require
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.react.hooks :as hooks]
[goog.object :as gobj]))
(defsc ClickToEditField [this {:keys [value editing?]}]
{:initial-state {:value "ABC"
:db/id 1
:editing? false}
:query [:db/id :value :editing?]
:ident [:field/by-id :db/id]
:use-hooks? true}
(let [^js ref (hooks/use-ref nil)
focus! (fn [] (when-let [input-field (.-current ref)] (.focus input-field)))
select! (fn [] (when-let [input-field (.-current ref)]
(.focus input-field)
(.setSelectionRange input-field 0 (.. input-field -value -length))))]
(dom/div
(dom/a {:onClick focus!} "Click to focus (if not already editing): ")
(dom/input {:value value
:onChange #(m/set-string! this :value :event %)
:ref ref})
(dom/button {:onClick select!} "Highlight All"))))
(def ui-click-to-edit (comp/factory ClickToEditField))
(defsc Root [this {:keys [field] :as props}]
{:query [{:field (comp/get-query ClickToEditField)}]
:initial-state {:field {}}}
(ui-click-to-edit field))|
Note
|
The older string support for refs is still present, but will not be supported in future versions. Use the function-based version of refs and port old code to that to avoid future problems. |
7.8.2. Taking control of the sub-DOM (D3, etc)
Libraries like D3 are great for dynamic visualizations, but they need full control of the portion of the DOM that they create and manipulate.
In general this means that your render method should be called once (and only once) to install the base DOM onto which the other library will control.
For example, let’s say we wanted to use D3 to render things. We’d first write a function that would take the real DOM node and the incoming props:
(defn db-render [DOM-NODE props] ...)This function should do everything necessary to render the sub-dom (and update it if the props change).
Then we’d wrap that under a component that doesn’t allow React to refresh that sub-tree via shouldComponentUpdate.
Below is a demo of this:
(ns book.ui.d3-example
(:require
[com.fulcrologic.fulcro.dom :as dom]
;; REQUIRES shadow-cljs, with "d3" in package.json
["d3" :as d3]
["react" :as react]
[goog.object :as gobj]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]))
;; HACK
(set! (.-React js/window) react)
(defn render-squares [dom-node props]
(let [svg (-> d3 (.select dom-node))
data (clj->js (:squares props))
selection (-> svg
(.selectAll "rect")
(.data data (fn [d] (.-id d))))]
(-> selection
.enter
(.append "rect")
(.style "fill" (fn [d] (.-color d)))
(.attr "x" "0")
(.attr "y" "0")
.transition
(.attr "x" (fn [d] (.-x d)))
(.attr "y" (fn [d] (.-y d)))
(.attr "width" (fn [d] (.-size d)))
(.attr "height" (fn [d] (.-size d))))
(-> selection
.exit
.transition
(.style "opacity" "0")
.remove)
false))
(defsc D3Thing [this props]
{:componentDidMount (fn [this]
(when-let [dom-node (gobj/get this "svg")]
(render-squares dom-node (comp/props this))))
:shouldComponentUpdate (fn [this next-props next-state]
(when-let [dom-node (gobj/get this "svg")]
(render-squares dom-node next-props))
false)}
(dom/svg {:style {:backgroundColor "rgb(240,240,240)"}
:width 200 :height 200
:ref (fn [r] (gobj/set this "svg" r))
:viewBox "0 0 1000 1000"}))
(def d3-thing (comp/factory D3Thing))
(defn random-square []
{
:id (rand-int 10000000)
:x (rand-int 900)
:y (rand-int 900)
:size (+ 50 (rand-int 300))
:color (case (rand-int 5)
0 "yellow"
1 "green"
2 "orange"
3 "blue"
4 "black")})
(defmutation add-square [params]
(action [{:keys [state]}]
(swap! state update :squares conj (random-square))))
(defmutation clear-squares [params]
(action [{:keys [state]}]
(swap! state assoc :squares [])))
(defsc Root [this props]
{:query [:squares]
:initial-state {:squares []}}
(dom/div
(dom/button {:onClick #(comp/transact! this
[(add-square {})])} "Add Random Square")
(dom/button {:onClick #(comp/transact! this
[(clear-squares {})])} "Clear")
(dom/br)
(dom/br)
(d3-thing props)))The things to note for this example are:
-
We override the React lifecycle method
shouldComponentUpdateto return false. This tells React to never ever call render once the component is mounted. D3 is in control of the underlying stuff. -
We override
shouldComponentUpdateandcomponentDidMountto do the actual D3 render/update. The former will get incoming data changes, and the latter is called on initial mount. Our render method delegates all of the hard work to D3.
7.8.3. Dynamically rendering into a canvas
Sometimes you need to use component-local state to avoid the overhead in running a query to feed props. An example of this is when handing mouse interactions like drag. You’ll typically use React refs to grab the actual low-level canvas.
The set-state! function is a Fulcro wrapper of React’s setState, but it let’s you use cljs maps instead of js ones.
The shallow merge described by React is honored as if you used an updater function (there is no need for an updater function).
The set-state! also allows a callback to give you full React compatibility.
Note, however, that React 16’s setState schedules a state update and render.
It is not guaranteed to be immediate.
The update-state! function in Fulcro is like Clojurescripts swap! function, and uses set-state! behind the scenes.
The following code is an example using component local state to render a box that follows the hover position of the mouse.
(ns book.ui.hover-example
(:require
[com.fulcrologic.fulcro.mutations :refer [defmutation]]
[com.fulcrologic.fulcro.components :as comp :refer [defsc initial-state]]
[goog.object :as gobj]
[com.fulcrologic.fulcro.dom :as dom]))
(defn change-size*
"Change the size of the canvas by some (pos or neg) amount.."
[state-map amount]
(let [current-size (get-in state-map [:child/by-id 0 :size])
new-size (+ amount current-size)]
(assoc-in state-map [:child/by-id 0 :size] new-size)))
; Make the canvas smaller. This will cause
(defmutation ^:intern make-smaller [p]
(action [{:keys [state]}]
(swap! state change-size* -20)))
(defmutation ^:intern make-bigger [p]
(action [{:keys [state]}]
(swap! state change-size* 20)))
(defmutation ^:intern update-marker [{:keys [coords]}]
(action [{:keys [state]}]
(swap! state assoc-in [:child/by-id 0 :marker] coords)))
(defn event->dom-coords
"Translate a javascript evt to a clj [x y] within the given dom element."
[evt dom-ele]
(let [cx (.-clientX evt)
cy (.-clientY evt)
BB (.getBoundingClientRect dom-ele)
x (- cx (.-left BB))
y (- cy (.-top BB))]
[x y]))
(defn event->normalized-coords
"Translate a javascript evt to a clj [x y] within the given dom element as normalized (0 to 1) coordinates."
[evt dom-ele]
(let [cx (.-clientX evt)
cy (.-clientY evt)
BB (.getBoundingClientRect dom-ele)
w (- (.-right BB) (.-left BB))
h (- (.-bottom BB) (.-top BB))
x (/ (- cx (.-left BB))
w)
y (/ (- cy (.-top BB))
h)]
[x y]))
(defn render-hover-and-marker
"Render the graphics in the canvas. Pass the component props and state. "
[canvas props coords]
(let [marker (:marker props)
size (:size props)
real-marker-coords (mapv (partial * size) marker)
; See HTML5 canvas docs
ctx (.getContext canvas "2d")
clear (fn []
(set! (.-fillStyle ctx) "white")
(.fillRect ctx 0 0 size size))
drawHover (fn []
(set! (.-strokeStyle ctx) "gray")
(.strokeRect ctx (- (first coords) 5) (- (second coords) 5) 10 10))
drawMarker (fn []
(set! (.-strokeStyle ctx) "red")
(.strokeRect ctx (- (first real-marker-coords) 5) (- (second real-marker-coords) 5) 10 10))]
(.save ctx)
(clear)
(drawHover)
(drawMarker)
(.restore ctx)))
(defn place-marker
"Update the marker in app state. Derives normalized coordinates, and updates the marker in application state."
[child evt]
(let [canvas (gobj/get child "canvas")]
(comp/transact! child [(update-marker
{:coords (event->normalized-coords evt canvas)})])))
(defn hover-marker
"Updates the hover location of a proposed marker using canvas coordinates. Hover location
is stored in component local state (meaning that a low-level app database query will not
run to do the render that responds to this change)"
[child evt]
(let [canvas (gobj/get child "canvas")
updated-coords (event->dom-coords evt canvas)]
(comp/set-state! child {:coords updated-coords})
(render-hover-and-marker canvas (comp/props child) updated-coords)))
(defsc Child [this {:keys [id size] :as props}]
{:query [:id :size :marker]
:initial-state (fn [_] {:id 0 :size 50 :marker [0.5 0.5]})
:ident (fn [] [:child/by-id id])
:initLocalState (fn [this _] {:coords [-50 -50]})}
; Remember that this "render" just renders the DOM (e.g. the canvas DOM element). The graphical
; rendering within the canvas is done during event handling.
; size comes from props. Transactions on size will cause the canvas to resize in the DOM
(when-let [canvas (gobj/get this "canvas")]
(render-hover-and-marker canvas props (comp/get-state this :coords)))
(dom/canvas {:width (str size "px")
:height (str size "px")
:onMouseDown (fn [evt] (place-marker this evt))
:onMouseMove (fn [evt] (hover-marker this evt))
; This is a pure React mechanism for getting the underlying DOM element.
; Note: when the DOM element changes this fn gets called with nil
; (to help you manage memory leaks), then the new element
:ref (fn [r]
(when r
(gobj/set this "canvas" r)
(render-hover-and-marker r props (comp/get-state this :coords))))
:style {:border "1px solid black"}}))
(def ui-child (comp/factory Child))
(defsc Root [this {:keys [child]}]
{:query [{:child (comp/get-query Child)}]
:initial-state (fn [params] {:ui/react-key "K" :child (comp/get-initial-state Child nil)})}
(dom/div
(dom/button {:onClick #(comp/transact! this [(make-bigger {})])} "Bigger!")
(dom/button {:onClick #(comp/transact! this [(make-smaller {})])} "Smaller!")
(dom/br)
(dom/br)
(ui-child child)))The component receives mouse move events to show a hover box. In this case we really don’t care to take the overhead to track the cursor position in real app state, so we leverage component local state instead. Clicking to save the box position and resizing the container are real transactions, and will actually cause a refresh from application state to update the rendering.
7.9. React Hooks Support
React introduced a new, more functional, API for creating UI components as simple functions known as hooks in version 16.8.
React hooks are supported in Fulcro 3.1.17 and above.
The defsc macro will generate a plain function that supports hook usage if you include
the :use-hooks? true component option:
(defsc HookThing [this props]
{:query [:thing/id] ; normal Fulcro component options
:ident :thing/id
:use-hooks? true ; generate a hooks-compatible function instead of a React class.
...}
(dom/div ...)) ; as before
(def ui-hook-thing (comp/factory HookThing {:keyfn :thing/id}))Hooks-based components:
-
Currently ONLY support the
thisandpropsarguments. -
Ignore any attempts at requesting React class methods (e.g. shouldComponentUpdate, componentDidMount, etc.)
-
Have wrappers for
useStateanduseEffectashooks/use-stateandhooks/use-effect.
|
Note
|
You still use factories with hooks components, and computed-factory should work; however,
(for the time being) use (get-computed this) instead of the 3rd defsc argument to get computed props
in hooks-enabled components. This will be fixed in a future release.
|
|
Note
|
The version of React at the time of this writing was not able to batch updates to state via hooks when called
from async functions without help, which results in some over-rendering when using hooks.
Fulcro supports React’s optimization for this (which is under an unstable API), but since it requires different mechanisms
depending on what you are using (DOM, Native, etc.) and isn’t API-stable you have to manually install the optimization.
For DOM it requires you set the :batch-notifications option on your app, and set it to
(fn [n!] (js/ReactDOM.unstable_batchedUpdates n!)). See https://dev.to/raibima/batch-your-react-updates-120b for more information.
|
7.9.1. The React.memo optimization
The components namespace includes a memo function which will correctly work for Fulcro hooks components to give the
same effect as a PureComponent (shouldComponentUpdate of class-based components). Wrap the component class
with it when you’re building your factory:
(def ui-thing (comp/factory (comp/memo Thing) {:keyfn :thing/id}))|
Note
|
This is only useful on hooks-based components. |
7.10. Using Javascript React Components
One of the great parts about React is the ecosystem. There are some great libraries out there. Many libraries will work without issue as long as you’re using shadow-cljs as your compiler; However, the interop story requires a few adaptations. The goal of this section is to make that story a little clearer.
7.10.1. Factory Functions for JS React Components
You must understand React and the ecosystem. This book is not a tutorial on the fundamental js ecosystem. Some important points to understand:
-
If you are importing third party components, you should be importing the class, not a factory.
-
You need to explicitly create react elements with factories. The relevant js functions are React.createElement, and React.createFactory.
-
Children. JS does not have a built in notion of lazy sequences. Clojurescript does. This can create subtle bugs when evaluating the children of a component.
com.fulcrologic.fulcro.components/force-childrenhelps us in this regard by taking a seq and returning a vector.
The react-interop namespace includes a pre-written function for generating factories that can accept CLJS maps and children, and properly takes the normal corrective actions:
(ns app
(:require
["some-react-thing" :refer [Thing]]
[com.fulcrologic.fulcro.algorithms.react-interop :as interop]))
(def ui-thing (interop/react-factory Thing))Now that we have some background on creating React Elements it’s pretty simple to implement something.
7.10.2. The Function-As-a-Child Pattern
A common pattern in React libraries is to use a function as a single child instead of an actual element. This is an accepted and widely used pattern, but you need to do a simple extra step for it to work properly with Fulcro. You see, Fulcro components use some behind-the-scenes bindings to allow for targeted UI rendering optimizations, and when you embed them in a function that is invoked from external JS out of that context things won’t work correctly.
For example, the react-motion library gives you React tools that can animate DOM motion.
It animates variables that you apply to nested DOM, and it does this through the function-as-a-child pattern.
Here’s an example from a demo project (which uses shadow-cljs to get easy access to NPM libraries):
(ns book.react-interop.react-motion-example
(:require ["react-motion" :refer [Motion spring]]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.algorithms.react-interop :as interop]))
(def ui-motion (interop/react-factory Motion))
(defsc Block [this {:block/keys [name]} {:keys [top]}]
{:query [:block/id :block/name]
:ident :block/id
:initial-state {:block/id 1
:block/name "A Block"}}
(dom/div {:style {:position "relative"
:top top}}
(dom/div
(dom/label "Name?")
(dom/input {:value name
:onChange #(m/set-string! this :block/name :event %)}))))
(def ui-block (comp/factory Block {:keyfn :id}))
(defsc Demo [this {:keys [ui/slid? block]}]
{:query [:ui/slid? {:block (comp/get-query Block)}]
:initial-state {:ui/slid? false :block {:id 1 :name "N"}}
:ident (fn [] [:control :demo])}
(dom/div {:style {:overflow "hidden"
:height "150px"
:margin "5px"
:padding "5px"
:border "1px solid black"
:borderRadius "10px"}}
(dom/button {:onClick (fn [] (m/toggle! this :ui/slid?))} "Toggle")
(ui-motion {:style {"y" (spring (if slid? 175 0))}}
(fn [p]
(let [y (comp/isoget p "y")]
; The binding wrapper ensures that internal fulcro bindings are held within the lambda
(comp/with-parent-context this
(dom/div :.demo
(ui-block (comp/computed block {:top y})))))))))
(def ui-demo (comp/factory Demo))
(defsc Root [this {:root/keys [demo] :as props}]
{:query [{:root/demo (comp/get-query Demo)}]
:initial-state {:root/demo {}}}
(ui-demo demo))The key is the call to with-parent-context.
It causes the enclosed elements to have bindings pulled from the component passed as the first parameter (in this case this).
Rendering will work correctly without this wrapper, but interactions (particularly transact!) will not operate correctly without it.
7.11. Colocated CSS
Please see fulcro-garden-css for a library that allows you to co-locate CSS with Fulcro components.
7.12. Component Middleware
When creating a Fulcro application you have the option of setting two bits of component middleware:
(def app (fulcro-app {:props-middleware ...
:render-middleware ...}))These enable some advanced functionality for Fulcro without having to write your own macro that deals with various internals.
7.12.1. Render Middleware
The render middleware is a function (or chain of functions) with the general form:
(fn [this real-render]
...
(real-render))The intention is that you can wrap or instrument/measure rendering.
For example, using the tufte library:
(ns my.ui
(:require
...
[com.fulcrologic.fulcro.components :as comp]
[com.fulcrologic.fulcro.rendering.ident-optimized-render :refer [render!]]
[taoensso.tufte :as tufte :refer [p profile]]))
(tufte/add-basic-println-handler! {})
(defonce SPA (app/fulcro-app
{:render-middleware (fn [this real-render]
;; record how long each component, by name, takes to render
(p {:id (comp/component-name this)}
(real-render)))
:optimized-render! (fn render-performance
([app options]
;; capture the recordings and print a report at the end
(profile {}
(render! app options)))
([app] (render-performance app {})))would print statistics like this to the Chrome developer’s console:
pId nCalls Min 50% ≤ 90% ≤ 95% ≤ 99% ≤ Max Mean MAD Clock Total
app.ui.root/Root 1 3ms 3ms 3ms 3ms 3ms 3ms 3ms ±0% 3ms 17%
app.ui.root/User 1 0ns 0ns 0ns 0ns 0ns 0ns 0ns ±NaN% 0ns 0%
Accounted 3ms 17%
Clock 18ms 100%Note that you can see the component props using comp/props on the component you’re passed, but you are not allowed to manipulate it.
Limited manipulation can be done via the props middleware.
7.12.2. Extra Props Middleware
The props middleware lets you manipulate the raw props that flow through your components.
This is an advanced functionality, since misuse could cause your application to fail to work properly at all.
The primary use for this middleware is to allow libraries to extend the "extra" props argument that defsc supports.
The defsc macro actually supports up to four arguments: this, props , computed, and
extra.
This last arg is a map that can be filled by libraries that wish to more tightly integrate with Fulcro’s component system.
Typically you’ll set such middleware something like this:
(def app (app/fulcro-app
{:props-middleware (comp/wrap-update-extra-props
(fn [cls extra-props]
(assoc extra-props :x 1)))))which then allows you to write components like this:
(defsc MyComponent [this props computed {:keys [x]]
...)The "extra props" are actually encoded onto the internal raw js props of React, so the most common operation is to leverage wrap-update-extra-props so you only affect those.
7.13. Component Options
The component options map that appears after the argument list is just that: a plain map.
The
defsc macro adds a bit of magic to the three central items (initial-state, query, and
ident), but otherwise the map is open; that is to say you can add you own stuff to it, and whatever you add will be available via comp/component-options on both the component class and the instances.
This opens up all sorts of possibilities for extensions. The form-state library, component-local CSS, and new dynamic router use this fact and add their own keys that only they use and know about. You can too.
7.14. Using Fulcro Component Classes in Vanilla JS (Detached Subtrees)
Fulcro components are normally joined by query and state into a UI tree. This has a number of advantages that are used throughout the system. For example the dynamic routers use the query to automatically create the virtual "routing tree", form state uses the same mechanism to deal with nested forms automatically. The query and state reification is quite a powerful tool and should not be abandoned lightly; however, there are some vanilla React libraries that require you pass them a component class. Those libraries often make their own factories, modify props, and generally do not work well with Fulcro’s UI composition. They assume that you’re using the React norm of co-locating your data and I/O logic with specific sub-trees of your application. Obviously the two are at odds.
If you decide that it is worth giving up things like composition of the dynamic routing system across these boundaries, then you can change the renderer in Fulcro to one that supports multiple Fulcro roots. This allows a single Fulcro application to continue to control the data needs of the components while not requiring that they be composed together in the graph.
|
Note
|
As of Fulcro 3.2 you should use React Hooks and use-component for this instead of the
multi-root render. See Fulcro Hook Components from Vanilla React. The multi-root renderer is works, but it introduces a
coupling between the rendering layer and the application’s general composition, and should be
avoided for that reason.
|
Fulcro 3.1.13+ includes such a renderer, which includes generation functions for making floating root factories for use with in Fulcro itself, as well as a function to create a vanilla React class.
The basic idea is that you set an alternate renderer on your app, and then add register/deregister hooks on your
"floating" root(s). Then you can use either floating-root-factory or floating-root-react-class to generate
the artifact you need to use elsewhere in your application.
(ns example
(:require
com.fulcrologic.fulcro.rendering.multiple-roots-renderer))
;; Typically in a ns all by itself, for easy reference anywhere.
(defonce app (app/fulcro-app {:optimized-render! mroot/render!}))
(defsc OtherChild ...)
;; The floating root itself. Must register/deregister.
(defsc AltRoot [this {:keys [alt-child]}]
;; query is from ROOT of the db, just like normal root.
{:query [{:alt-child (comp/get-query OtherChild)}]
:componentDidMount (fn [this] (mroot/register-root! this {:app app}))
:componentWillUnmount (fn [this] (mroot/deregister-root! this {:app app}))
:initial-state {:alt-child [{:id 1 :n 22}
{:id 2 :n 44}]}}
(dom/div
(mapv ui-other-child alt-child)))
;; For use in the body of normal defsc components.
(def ui-alt-root (mroot/floating-root-factory AltRoot))
;; For use as plain React class
(def PlainAltRoot (mroot/floating-root-react-class AltRoot app))You can use the factory in normal Fulcro apps like normal, but you don’t compose the class/state into the query of the parent, nor do you pass it props. The floating class can simply be passed to any library that expects a normal React class.
|
Warning
|
Remember that things like the dynamic router, which leverage the query composition for introspection, will
not be able to "see" across this boundary. You’d have to use change-route-relative! against some class in the
subroot in order for it to function properly.
|
7.15. React Higher-Order Components
When using external libraries with Fulcro you’ll often run into the higher-order component pattern. React Higher Order Components (HOC) can be used with Fulcro but due to how Fulcro works internally interop/glue code is needed.
Higher Order Components is a pattern in React similar to the Decorator pattern in object-oriented programming: you wrap one component class with another component to decorate it with extra behaviour.
Some React reusable components provide HOC components to wrap cross cutting logic needed for the wrapped components to work.
For example google-maps-react provides GoogleApiWrapper HOC that handles dynamic loading and initialisation of Google Maps Javascript library so it doesn’t have to be handled manually in every place where Google Maps React component (like Map or Marker) is used.
In this particular example, GoogleApiWrapper creates a wrapper component class that behaves in the following way:
-
it will display a placeholder "Loading" component and trigger Google Maps script loading and initialisation
-
when the script loading and initialisation is complete it will replace "Loading" placeholder with the wrapped component
7.15.1. Fulcro and React HOC
There are two things that need to be "patched" in order for Fulcro components to function properly as targets of the HOC pattern:
-
Raw React libraries pass props as js objects. Fulcro normally wraps/unwraps these for you.
-
Fulcro wraps in some special items to props that carry along context for transactional operation.
Fulcro includes an interop function for your convenience that should work for many examples of this pattern "in the wild".
The com.fulcrologic.fulcro.algorithms.react-interop namespace includes a function that does the necessary props and context manipulation for you:
;; injected-props in the computed section passes in the raw js props that the HOC passed in (a js map)
(defsc TargetOfHOC [this props {:keys [injected-props]}] ...)
(def ui-target-of-hoc (interop/hoc-factory TargetOfHOC hocFunction))The following two live examples show you how to use this function in the context of the Google Maps React API (the example requires billing now, but you can see it embeds the map), and the Stripe Elements API.
(ns book.react-interop.google-maps-example
(:require
["google-maps-react" :as maps :refer [GoogleApiWrapper Map Marker]]
[com.fulcrologic.fulcro.algorithms.react-interop :as interop :refer [react-factory]]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]))
;; Fulcro wrapper factory for google-maps-react's Map component
(def ui-google-map (react-factory Map))
;; Another wrapper factory for Marker component
(def ui-map-marker (react-factory Marker))
(defsc LocationView [this {:map/keys [latitude longitude] :as props} {:keys [injected-props] :as computed}]
{:query [:map/latitude :map/longitude]
:ident (fn [] [:component/id ::location-view])
:initial-state {:map/latitude 45.5051 :map/longitude -122.6750}}
(dom/div
(dom/div {:style {:width "520px" :height "520px"}}
;; The API docs say the the HOC adds a "google" prop that should be passed to Map
(ui-google-map {:google (.-google injected-props)
:zoom 5
:initialCenter {:lat latitude :lng longitude}
:style {:width "90%" :height "90%"}}
(ui-map-marker {:position {:lat latitude :lng longitude}})))))
(def injectGoogle (GoogleApiWrapper #js {:apiKey "AIzaSyAM9PWfj-rJDnmyJvh8QNkO4pgGzy5s_Yg"}))
(def ui-location-view (interop/hoc-factory LocationView injectGoogle))
(defsc Root [this {:root/keys [location-view] :as props}]
{:query [{:root/location-view (comp/get-query LocationView)}]
:initial-state {:root/location-view {}}}
(dom/div
(dom/h3 "A Map View")
(ui-location-view this location-view)))(ns book.react-interop.stripe-example
(:require
["react-stripe-elements" :as stripe :refer [StripeProvider Elements injectStripe
CardNumberElement
CardExpiryElement
CardCvcElement]]
[com.fulcrologic.fulcro.algorithms.react-interop :as interop]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.mutations :as m]))
(def test-key "pk_test_crQ5GM8nCR8tM06YZcgunnmZ00qjGWhSNV")
;; Wrap the stripe UI components in interop factories
(def ui-stripe-provider (interop/react-factory StripeProvider))
(def ui-elements (interop/react-factory Elements))
(def ui-card-element (interop/react-factory CardNumberElement))
(def ui-exp-element (interop/react-factory CardExpiryElement))
(def ui-cvc-element (interop/react-factory CardCvcElement))
(defn handle-result [result]
(let [{{:keys [message]} :error
{:keys [id]} :token} (js->clj result :keywordize-keys true)]
(when message
(js/alert (str "Error: " message)))
(when id
(js/alert (str "Created payment token " id)))))
(defsc CCForm [this {:customer/keys [name] :as props} {:keys [injected-props] :as computed}]
{:query [:customer/name]
:initial-state {:customer/name ""}
:ident (fn [] [:component/id ::ccform])}
;; isoget is a util that gets props from js maps in cljs, or CLJ ones in clj
(let [stripe (comp/isoget injected-props "stripe")]
(dom/form :.ui.form
{:onSubmit (fn [e] (.preventDefault e))}
(dom/div :.field
(dom/label "Name")
(dom/input {:value name
:onChange #(m/set-string! this :customer/name :event %)}))
(dom/div :.field
(dom/label "Card Number")
(ui-card-element {}))
(dom/div :.two.fields
(dom/div :.field
(dom/label "Expired")
(ui-exp-element {}))
(dom/div :.field
(dom/label "CVC")
(ui-cvc-element {})))
(dom/button {:onClick (fn [e]
;; createToken is a calls to the low-level JS API
(-> (.createToken stripe #js {:type "card" :name name})
(.then (fn [result] (handle-result result)))
(.catch (fn [result] (handle-result result)))))}
"Pay"))))
;; NOTE: The js library says you should call injectStripe(FormComponent) to get your wrapped component,
;; so use interop to do that:
(def ui-cc-form (interop/hoc-factory CCForm injectStripe))
(defsc Root [this {:keys [root/cc-form] :as props}]
{:query [{:root/cc-form (comp/get-query CCForm)}]
:initial-state {:root/cc-form {}}}
(dom/div
(dom/h2 "Payment Form")
;; Stripe documentation says to wrap a stripe provider around the whole thing, and use the
;; HOC form.
(ui-stripe-provider #js {:apiKey test-key}
(ui-elements #js {}
;; NOTE: Remember to pass parent's `this` to the child when using an HOC factory.
(ui-cc-form this cc-form)))))7.15.2. How It Works
The property passing is relatively simple: pull the props apart at the correct time (and from the correct type) and pass them through as needed.
The other thing that has to happen is maintaining context from the Fulcro component parent as discussed earlier.
The components namespace includes a with-parent-context function that can do this in any scenario where some subtree of Fulcro components will be rendered by some function outside of the normal Fulcro tree:
(defsc Component [this {:keys [child-props] :as props}]
(dom/div {}
(some-js-component {:content (fn []
(comp/with-parent-context this
(ui-fulcro-child child-props)))})))If you look at the source of react-interop, you’ll see that both things are being done in order to make the target child component tolerant of being wrapped by a HOC pattern.
7.16. React Errors
React 16 adopted a new form of error handling where an exception in components "burns down" the
entire UI up to an "error boundary". If you don’t supply one, then your UI will go completely blank on errors: a
very bad experience for users and developers. See the React documentation
for manually handling this situation (all of the lifecycle methods are available from Fulcro’s defsc)
Fulcro 3.3.3+ includes a namespace with a helper macro that makes this a lot easier: com.fulcrologic.fulcro.react.error-boundaries.
The macro in this namespace emits code that will render the children within a nested pair of stateless react elements that will catch these errors and properly render something useful in the area of the UI affected.
To use it:
-
(Optionally) set the render-error to a function that renders the replacement UI.
-
Wrap bits of your UI using the macro.
;; At app initialization: (in CLJ, use alter-var-root)
(set! error-boundaries/*render-error* (fn [this error] (dom/div ...)))
;; within your UI rendering:
(error-boundary
(dom/div ...))In development mode the UI can use component-local state to allow the developer to retry rendering (after a hot code reload). The default rendering for errors looks like this, if you need help figuring out what to do when writing an override:
(def ^:dynamic *render-error*
(fn [this cause]
(dom/div
(dom/h2 :.header "Unexpected Error")
(dom/p "An error occurred while rendering the user interface.")
(dom/p (str cause))
(when #?(:clj false :cljs goog.DEBUG)
(dom/button {:onClick (fn []
(comp/set-state! this {:error false
:cause nil}))} "Dev Mode: Retry rendering")))))7.17. Integrating with Reagent
(this section and example kindly provided by Daniel Vingo)
Using the :render-middleware and :render-root! properties of a Fulcro application we can easily
render our Fulcro components using other ClojureScript libraries.
For example we can add Reagent rendering support to a Fulcro application like so:
(:require
[reagent.core]
[reagent.dom])
(app/fulcro-app
{:render-middleware (fn [_ render] (reagent.core/as-element (render))
:render-root! reagent.dom/render})The invocation to (render) returns whatever value is returned by a Fulcro component within this application.
That output is then passed to Reagent’s as-element function to return a React element.
Because Reagent will render any React element in addition to Hiccup data structures, we can mix Fulcro created React elements inside Reagent processed Hiccup - or any React elements no matter how they were created.
(defsc Page [this props]
{}
[:div.ui.container
[:div
(dom/p "A paragraph")]])Any Fulcro component that returns a React element will also be passed through by Reagent:
(defsc Page [this props]
{}
(dom/div "Another component"))Thus you can mix and match both React element creation styles in one Fulcro application.
Note that if you want to render a Reagent data structure within Fulcro created React elements you will
need to invoke reagent.core/as-element to convert that data structure to a React element.
(defsc Page [this props]
{}
(dom/div :.ui.container
(reagent.core/as-element [:h1 "A nested reagent component"])))8. EQL — The Query and Mutation Language
Before reading this chapter you should make sure you’ve read The Graph Database Section. It details the low-level format of the application state, and talks about general details that are referenced in this chapter.
In Fulcro all data is queried and manipulated from the UI using the EDN Query Language (EQL). EQL is a subset of Datomic’s pull query syntax with extensions for unions and mutations. A query is a graph walk, so it is a relative notation: it must start at some specific spot, but that spot is not always named in the query itself. On the client side the starting point is usually the root node of your database. Thus, a complete query from the Root UI component will be a graph query that can start at the root node of the database.
However, you’ll note that any query fragment is implied to be relative to where we are in the walk of the graph database.
This is important to understand: no component’s query can just be grabbed and run against the database as-is.
Then again, if you know the ident of a component, then you can start at that table entry in the database and go from there.
The mutation portion of the language is a data representation of the abstract actions you’d like to take on the data model. It is intended to be network agnostic: The UI need not be aware that a given mutation does local-only modifications and/or remote operations against any number of remote servers. As such, the mutations, like queries, are simply data. Data that can be interpreted by local logic, or data that can be sent over the wire to be interpreted by a server.
Queries can either be a vector or a map of vectors. The former is a regular component query, and the latter is known as a union query. Union queries are useful when you’re walking a graph edge and the target could be one of many different kinds of nodes, so you’re not sure which query to use until you actually are walking the graph.
8.1. Properties
The simplest thing to query are properties "right here" in the relative node of the graph. Properties are queried by a simple keyword. Their values can be any scalar data value that is serializable in EDN.
The query
[:a :b]is asking for the properties known as :a and :b at the "current node" in the graph traversal.
8.2. Joins
A join represents a traversal of an edge to another node in the graph. The notation is a map with a single key (the local key on the current node that holds the "pointer" to another node) whose single value is the query for the remainder of the graph walk:
[{:children (comp/get-query Child)}]The query itself cannot specify that this is a to-one or to-many join. The data in the database graph itself determines the arity when the query is being run. Basically, if walking the join property leads to a vector of links, it is to-many. If it leads to a single link, then it is to-one. Rendering the data is going to have the same concern so the arity of the relation more strongly affects the rendering code.
Joins should always use get-query to get the next component in the graph.
This annotates (with metadata) the sub-query so that normalization can work correctly.
|
Note
|
Auto normalization for a to-many will only occur if it is given a vector. Lists and seqs will not be normalized. |
8.3. Unions
Unions represent a map of queries, only one of which applies at a given graph edge. This is a form of dynamic query that adjusts based on the actual linkage of data. Unions cannot stand alone. They are meant to select one of many possible alternate queries when a link (to-one or to-many join) in the graph is reached. Unions are always used in tandem with a join, and can therefore not be used on root-level components. The union query itself is a map of the possible queries:
(defsc PersonPlaceOrThingUnion [this props]
; lambda form required for unions (a limitation of the error checking routines in defsc)
{:query (fn [] {:person/id (comp/get-query Person)
:place/id (comp/get-query Place)
:thing/id (comp/get-query Thing)})}
...)and such a query must be joined by a parent component. Therefore, you’ll always end up with something like this:
(defsc Parent [this props]
{:query [{:person-place-or-thing (comp/get-query PersonPlaceOrThingUnion)}]})Union queries take a little getting used to because there are a number of rules to follow when using them in order for everything to work correctly (normalization, queries, and rendering).
Here is what a graph database might look like for the above query assuming we started at Parent:
{ :person-place-or-thing [:place/id 3]
:place/id { 3 { :place/id 3 :location "New York" }}}The query would start at the root.
When it saw the join it would detect a union.
The union would be resolved by looking at the first element of the ident in the database (in this case :place from [:place 3]).
That keyword would then be used to select the query from the subcomponent union (in this example, (comp/get-query Place)).
Processing of the query then continues as normal as if the join was just on Place.
A to-many linkage works just as well:
{ :person-place-or-thing [[:person/id 1] [:place/id 3]]
:person/id { 1 { :person/id 1 :person/name "Julie" }}
:place/id { 3 { :place/id 3 :place/location "New York" }}}and now you have a mixed to-many relationship where the correct sub-query will be used for each item in turn.
Normalization of unions requires that the union component itself have an ident function that can properly generate idents for all of the possible kinds of things that could be found. Often this means that you’ll need to encode some kind of type indicator in the data itself.
Say you had this incoming tree of data:
{:person-place-or-thing [ {:person/id 1 :person/name "Joe"} {:place/id 3 :place/location "New York"} ]}In order to normalize this correctly we need to end up with the correct person and place idents.
The resulting ident function might look like this:
(defsc PersonPlaceOrThingUnion [this props]
{:ident (fn []
(cond
(contains? props :person/id) [:person/id (:person/id props)]
(contains? props :place/id) [:place/id (:place/id props)]
:else [:thing/id (:thing/id props)]))}
...)Rendering the correct thing in the UI of the union component has the same concern: you must detect what kind of data (among the options) that you actually receive, and pass that on to the correct child factory (e.g.
ui-person, ui-place, or ui-thing.
8.3.1. Demo – Using Unions as a UI Type Selector
The com.fulcrologic.fulcro.routing.legacy-ui-routers/defsc-router macro (2.6.18+) emits a union component that can be switched to point at any kind of component that it knows about.
The support for parameterized routers in the routing tree makes it possible to very easily reuse the UI router as a component that can show one of many screens in the same location.
This is particularly useful when you have a list of items that have varying types, and you’d like to, for example, show the list on one side of the screen and the detail on the other.
To write such a thing one would follow these steps:
-
Create one component for each item type that represents how it will look in the list.
-
Create one component for each item type that represents the fine detail view for that item.
-
Join (1) together into a union component and use it in a component that shows them as a list. In other words the union will represent a to-many edge in your graph. Remember that unions cannot stand alone, so there will be a union component (to switch the UI) and a list component to iterate through the items.
-
Combine the detail components from (2) into a
defsc-router(e.g. with ID :detail-router). -
Create a routing tree that includes the :detail-router, and parameterize both elements of the target ident (kind and id)
-
Hook a click event from the items to a
route-tomutation, and send route parameters for the kind and id.
The output of the macro:
(defsc-router ItemDetail [this props]
{:router-id :detail-router
:ident (fn [] (item-ident props))
:default-route PersonDetail
:router-targets {:person/id PersonDetail
:place/id PlaceDetail
:thing/id ThingDetail}}
(dom/div "Route not set"))is roughly this (cleaned up from macro output):
(defsc ItemDetail-Union [this props]
{:initial-state (fn [params] (comp/get-initial-state PersonDetail params)) ;; defaults to the first one listed
:ident (fn [] (item-ident props))
:query (fn [] {:person/id (comp/get-query PersonDetail),
:place/id (comp/get-query PlaceDetail),
:thing/id (comp/get-query ThingDetail)}}
(let [page (first (comp/get-ident this))]
(case page
:person/id ((comp/factory PersonDetail) (comp/props this))
:place/id ((comp/factory PlaceDetail) (comp/props this))
:thing/id ((comp/factory ThingDetail) (comp/props this))
(dom/div (str "Cannot route: Unknown Screen " page))))
(defsc ItemDetail [this props]
{:initial-state (fn [params] {:com.fulcrologic.fulcro.routing.legacy-ui-routers/id :detail-router
:com.fulcrologic.fulcro.routing.legacy-ui-routers/current-route (comp/get-initial-state ItemDetail-Union params)})
:ident (fn [] [:com.fulcrologic.fulcro.routing.legacy-ui-routers.routers/id :detail-router])
:query [:com.fulcrologic.fulcro.routing.legacy-ui-routers/id {:fulcro.client.routing/current-route (comp/get-query ItemDetail-Union)}]}
(let [computed (comp/get-computed this)
props (:com.fulcrologic.fulcro.routing.legacy-ui-routers/current-route (comp/props this))
props-with-computed (comp/computed props computed)]
((comp/factory ItemDetail-Union) props-with-computed)))))You can see that this just defines a union whose "selection" is controlled by the :current-route property!
Here is a complete working example that uses this to make a UI around displaying things of various types:
(ns book.queries.union-example-1
(:require
[com.fulcrologic.fulcro.dom :as dom :refer [div table td tr th tbody]]
[com.fulcrologic.fulcro.routing.legacy-ui-routers :as r :refer [defsc-router]]
[book.elements :as ele]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[taoensso.timbre :as log]))
(defn person? [props] (contains? props :person/id))
(defn place? [props] (contains? props :place/id))
(defn thing? [props] (contains? props :thing/id))
(defn item-ident
"Generate an ident from a person, place, or thing."
[props]
(cond
(person? props) [:person/id (:person/id props)]
(place? props) [:place/id (:place/id props)]
(thing? props) [:thing/id (:thing/id props)]
:else nil))
(defn item-key
"Generate a distinct react key for a person, place, or thing"
[props] (str (item-ident props)))
(defn make-person [id n] {:person/id id :person/name n})
(defn make-place [id n] {:place/id id :place/name n})
(defn make-thing [id n] {:thing/id id :thing/label n})
(defsc PersonDetail [this {:person/keys [id name] :as props}]
; defsc-router expects there to be an initial state for each possible target. We'll cause this to be a "no selection"
; state so that the detail screen that starts out will show "Nothing selected". We initialize all three in case
; we later re-order them in the defsc-router.
{:ident (fn [] (item-ident props))
:query [:person/id :person/name]
:initial-state {:person/id :no-selection}}
(dom/div
(if (= id :no-selection)
"Nothing selected"
(str "Details about person " name))))
(defsc PlaceDetail [this {:place/keys [id name] :as props}]
{:ident (fn [] (item-ident props))
:query [:place/id :place/name]
:initial-state {:place/id :no-selection}}
(dom/div
(if (= id :no-selection)
"Nothing selected"
(str "Details about place " name))))
(defsc ThingDetail [this {:thing/keys [id label] :as props}]
{:ident (fn [] (item-ident props))
:query [:thing/id :thing/label]
:initial-state {:thing/id :no-selection}}
(dom/div
(if (= id :no-selection)
"Nothing selected"
(str "Details about thing " label))))
(defsc PersonListItem [this
{:person/keys [id name] :as props}
{:keys [onSelect] :as computed}]
{:ident (fn [] (item-ident props))
:query [:person/id :person/name]}
(dom/li {:onClick #(onSelect (item-ident props))}
(dom/a {} (str "Person " id " " name))))
(def ui-person (comp/factory PersonListItem {:keyfn item-key}))
(defsc PlaceListItem [this {:place/keys [id name] :as props} {:keys [onSelect] :as computed}]
{:ident (fn [] (item-ident props))
:query [:place/id :place/name]}
(dom/li {:onClick #(onSelect (item-ident props))}
(dom/a {} (str "Place " id " : " name))))
(def ui-place (comp/factory PlaceListItem {:keyfn item-key}))
(defsc ThingListItem [this {:thing/keys [id label] :as props} {:keys [onSelect] :as computed}]
{:ident (fn [] (item-ident props))
:query [:thing/id :thing/label]}
(dom/li {:onClick #(onSelect (item-ident props))}
(dom/a {} (str "Thing " id " : " label))))
(def ui-thing (comp/factory ThingListItem item-key))
(defsc-router ItemDetail [this props]
{:router-id :detail-router
:ident (fn [] (item-ident props))
:default-route PersonDetail
:router-targets {:person/id PersonDetail
:place/id PlaceDetail
:thing/id ThingDetail}}
(dom/div "No route"))
(def ui-item-detail (comp/factory ItemDetail))
(defsc ItemUnion [this props]
{:ident (fn [] (item-ident props))
:query (fn [] {:person/id (comp/get-query PersonListItem)
:place/id (comp/get-query PlaceListItem)
:thing/id (comp/get-query ThingListItem)})}
(cond
(person? props) (ui-person props)
(place? props) (ui-place props)
(thing? props) (ui-thing props)
:else (dom/div "Invalid ident used in app state.")))
(def ui-item-union (comp/factory ItemUnion {:keyfn item-key}))
(defsc ItemList [this {:keys [items]} {:keys [onSelect]}]
{
:initial-state (fn [p]
; These would normally be loaded...but for demo purposes we just hand code a few
{:items [(make-person 1 "Tony")
(make-thing 2 "Toaster")
(make-place 3 "New York")
(make-person 4 "Sally")
(make-thing 5 "Pillow")
(make-place 6 "Canada")]})
:ident (fn [] [:lists/id :singleton])
:query [{:items (comp/get-query ItemUnion)}]}
(dom/ul :.ui.list
(mapv (fn [i] (ui-item-union (comp/computed i {:onSelect onSelect}))) items)))
(def ui-item-list (comp/factory ItemList))
(defsc Root [this {:keys [item-list item-detail]}]
{:query [{:item-list (comp/get-query ItemList)}
{:item-detail (comp/get-query ItemDetail)}]
:initial-state (fn [p] (merge
(r/routing-tree
(r/make-route :detail [(r/router-instruction :detail-router [:param/kind :param/id])]))
{:item-list (comp/get-initial-state ItemList nil)
:item-detail (comp/get-initial-state ItemDetail nil)}))}
(let [; This is the only thing to do: Route the to the detail screen with the given route params!
showDetail (fn [[kind id]]
(comp/transact! this [(r/route-to {:handler :detail :route-params {:kind kind :id id}})]))]
; devcards, embed in iframe so we can use bootstrap css easily
(div {:key "example-frame-key"}
(dom/style ".boxed {border: 1px solid black}")
(table :.ui.table {}
(tbody
(tr
(th "Items")
(th "Detail"))
(tr
(td (ui-item-list (comp/computed item-list {:onSelect showDetail})))
(td (ui-item-detail item-detail))))))))8.4. Mutations
Mutations are also just data, as we mentioned earlier. However, they are intended to look like single-argument function calls where the single argument is a map of parameters:
[(do-something)]The main concern is that this expression, in normal Clojure, will be evaluated because it contains a raw list. In order to keep it data, one can quote expressions with mutations. Of course you may use syntax quoting or literal quoting.
|
Note
|
In Fulcro 3 the mutation itself, when called, just returns itself as data. This eliminates the requirement to quote unless a circular reference prevents you from requiring the namespace. |
Usually we recommend namespacing your mutations (with defmutation) and then using syntax quoting to get reasonably short expressions:
(ns app.mutations)
(defmutation do-something [params] ...)(ns app.ui
(:require [app.mutations :as am]))
...
(comp/transact! this [(am/do-something {})])We talked about syntax quoting transactions in the Getting Started chapter. You may want to review that or just read more online about Clojure syntax quoting.
The parameter map on mutations is optional, but recommended, if you’re using IDE support since the IDE will always see mutations as if they were function calls with an arity of one.
8.5. Parameters
Most of the query elements also support a parameter map. In Fulcro these are mainly useful when sending a query to the server, and it is rare you will write such a query "by hand". However, for completeness you should know what these look like. Basically, you just surround the property or join with parentheses, and add a map as parameters. This is just like mutations, except instead of a symbol as the first element of the list it is either a keyword (prop) or a map (join).
Thus a property can be parameterized:
[(:prop {:x 1})]This would cause, for example, a server’s query processing to see {:x 1} in the params when handling the read for :prop.
A join is similarly parameterized:
[({:child (comp/get-query Child)} {:x 1})]with the same kind of effect.
Unfortunately lists have special meaning to Clojure, so if you need to use them you’ll have to use syntax quoting. For example, the join example above would actually be written in code as:
...
:query (fn [this] `[({:child ~(comp/get-query Child)} {:x 1})])
...to avoid trying to use the map as a function for execution, yet allowing the nested get-query to run and embed the proper subquery.
8.6. Queries on Idents
Idents are valid in queries as a plain prop or a join. When used alone (not in a join) this will pull a table entry from the database without normalizing it or following any subquery:
[ [:person/id 1] ]results in something like this:
(defsc Phone [this props]
{:query [:id :phone/number]
:ident [:phone/id :id]}
...)
(defsc Person [this props]
{:query [:id {:person/phone (comp/get-query Phone)}]
:ident [:person/id :id]}
...)
(defsc X [this props]
{:query [ [:person/id 1] ] } ; query just for the ident
(let [person (get props [:person/id 1]) ; NOT get-in. The key of the result is an ident
...
; person contains {:id 1 :person/phone [:phone/id 4]}This is not typically what you want because you’d typically want it to follow the graph links (resolving phone number).
Therefore these kinds of queries are normally done via a join:
(defsc X [this props]
{:query [{[:person/id 1] (comp/get-query Person)}]}
(let [person (get props [:person/id 1])
...
; person contains {:id 1 :person/phone {:phone/id 4 :phone/number "555-1212"}}This has the effect of "re-rooting" the graph walk at that ident’s table entry and continuing from there for the rest of the subtree. In fact this is how Fulcro’s ident-based rendering optimization works.
8.7. Link Queries
There are times when you want to start "back at the root" node. This is useful for pulling data that has a singleton representation in the root node itself. For example, the current UI locale or currently logged-in user. There is a special notation for this that looks like an ident without an ID:
[ [:ui/locale '_] ]This component query would result in :ui/locale in your props (not an ident) with a value that came from the overall root node of the database.
Of course, denormalization just requires you use a join:
[ {[:current-user '_] (comp/get-query Person)} ]would pull :current-user into the component’s props with a continued walk of the graph.
In other words this is just like the ident join, except the special symbol _ indicates there is only one of them and it is in the root node.
8.8. A Warning About Ident and Link Queries
Components can query for whatever they want, and sometimes it is useful to write components that only query for things "elsewhere" in the database:
(defsc LocaleSwitcher [this {:keys [ui/locale]}]
{:query [[:ui/locale '_]]}
(dom/div ...))When the database is constructed for such components they will have no state of their own.
Sadly, even if you compose it into your UI properly it may not receive any data:
(defsc Root [this {:keys [locale-switcher]}]
{:query [{:locale-switcher (comp/get-query LocaleSwitcher)}]}
(ui-locale-switcher locale-switcher)) ; data comes back nil!!!The problem is that the query engine walks the database and query in tandem.
When it sees a join (:locale-switcher in this case) it goes looking for an entry in the database at the current location (root node in this case) to process the subquery against.
If it finds an ident it follows it and processes the subquery.
If it is a map it uses that to fulfill the subquery.
If it is a vector then it processes the subquery against every entry.
But if it is missing then it stops.
The fix is simple: make sure the component has a presence in the database, even if empty:
(defsc LocaleSwitcher [this {:keys [ui/locale]}]
{:query [[:ui/locale '_]]
:initial-state {}} ; empty map
(dom/div ...))
(defsc Root [this {:keys [locale-switcher]}]
{:query [{:locale-switcher (comp/get-query LocaleSwitcher)}]
:initial-state (fn [params] {:locale-switcher (comp/get-initial-state LocaleSwitcher)})} ; empty map from child
(ui-locale-switcher locale-switcher)) ; link query data is found/passed8.8.1. Using Shared State
An alternative to ident and link queries is shared state. The first thing to note is that it is not a complete replacement for link queries. It is a low-level feature that is meant for two basic scenarios:
-
Data that needs to be visible to all components, but never changes once the app is mounted.
-
Data that is derived from the UI props (from root) or globals, but only updates on root-level renders (not component-local updates).
The first use-case might be handy if you pass some data to your mount through the HTML page itself. The latter is useful for data that affects everything in your application, such as the current user.
The primary thing to remember is that components that look at shared state will not see updates unless a root render occurs with those updates.
This typically means calling comp/force-root-render!.
Say we wanted all components to be able to see :pi (a constant) and :current-user (a value from the database).
We could declare this as follows:
(app/fulcro-app
{:shared {:pi 3.14} ; never changes
:shared-fn #(select-keys % :current-user)}) ; updates on root renderNow any component can access these as follows:
(defsc C [this props]
(let [{:keys [pi current-user]} (comp/shared this)]
; current-user will be denormalized...it comes from the root props (Root must query for it still)
...))|
Warning
|
Remember that this is not equivalent to a link query for [:current-user '_].
There are two differences.
The first is that pulling :current-user still requires that your root component query for it (or it won’t even be in the props).
Second, the shared value will not visibly change until a root render happens, where link queries can refresh locally with a component.
The final difference is that if you use data in your shared-fn that is derived from anything other than the state database then it will not work correctly in the history support viewer.
|
8.9. Recursive Queries
EQL includes support for recursive queries.
Recursion is always expressed on a join, and it always means that the recursive item has the same type as the component you’re on.
There are two notations for this: … and a number.
The former means "recurse until there are no more links (circular detection is included to prevent infinite loops)", and the other is the recursion limit:
|
Note
|
At the time of this writing you must use the lambda mode of defsc for queries that include recursion.
|
The following demo (with source) demonstrates the core basics of recursion:
(ns book.queries.recursive-demo-1
(:require [com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]))
(defn make-person
"Make a person data map with optional children."
[id name children]
(cond-> {:db/id id :person/name name}
children (assoc :person/children children)))
(declare ui-person)
; The ... in the query means there will be children of the same type, of arbitrary depth
; it is equivalent to (comp/get-query Person), but calling get query on yourself would
; lead to infinite compiler recursion.
(defsc Person [this {:keys [:person/name :person/children]}]
{:query (fn [] [:db/id :person/name {:person/children '...}])
:initial-state (fn [p]
(make-person 1 "Joe"
[(make-person 2 "Suzy" [])
(make-person 3 "Billy" [])
(make-person 4 "Rae"
[(make-person 5 "Ian"
[(make-person 6 "Zoe" [])])])]))
:ident [:person/id :db/id]}
(dom/div
(dom/h4 name)
(when (seq children)
(dom/div
(dom/ul
(mapv (fn [p]
(ui-person p))
children))))))
(def ui-person (comp/factory Person {:keyfn :db/id}))
(defsc Root [this {:keys [person-of-interest]}]
{:initial-state {:person-of-interest {}}
:query [{:person-of-interest (comp/get-query Person)}]}
(dom/div
(ui-person person-of-interest)))8.9.1. Circular Recursion
It is perfectly legal to include recursion in your graph, and it is equally fine to query for it. The query engine will automatically stop if a loop is detected.
However, this is not the whole story. You see, components can be updated in a relative fashion when all optimizations are enabled. This means that a refresh could happen anywhere in the (recursive) UI, and the query would run until it detects the loop again. This can lead to funny-looking results.
The demo below lets you modify people and their spouse (a circular relation). Try it out and you’ll see that something isn’t quite right (try making Sally older):
(ns book.queries.recursive-demo-2
(:require [com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.mutations :refer [defmutation]]
[com.fulcrologic.fulcro.dom :as dom]))
(declare ui-person)
(defmutation make-older [{:keys [id]}]
(action [{:keys [state]}]
(swap! state update-in [:person/id id :person/age] inc)))
(defsc Person [this {:keys [db/id person/name person/spouse person/age]}]
{:query (fn [] [:db/id :person/name :person/age {:person/spouse 1}]) ; force limit the depth
:initial-state (fn [p]
; this does look screwy...you can nest the same map in the recursive position,
; and it'll just merge into the one that was previously normalized during normalization.
; You need to do this or you won't get the loop in the database.
{:db/id 1
:person/name "Joe"
:person/age 20
:person/spouse {:db/id 2
:person/name "Sally"
:person/age 22
:person/spouse {:db/id 1 :person/name "Joe"}}})
:ident [:person/id :db/id]}
(dom/div
(dom/div "Name:" name)
(dom/div "Age:" age
(dom/button {:onClick
#(comp/transact! this [(make-older {:id id})])} "Make Older"))
(when spouse
(dom/ul
(dom/div "Spouse:" (ui-person spouse))))))
(def ui-person (comp/factory Person {:keyfn :db/id}))
(defsc Root [this {:keys [person-of-interest]}]
{:initial-state {:person-of-interest {}}
:query [{:person-of-interest (comp/get-query Person)}]}
(dom/div
(ui-person person-of-interest)))The problem is that when you touch Sally the UI refresh updates just that component; however, that component has a recursive query of depth 1, so it ends up returning Joe as her spouse! This is technically correct, but almost certainly isn’t what you want!
|
Note
|
The above problem will only manifest for certain Fulcro configurations. The more recent default will not show this particular issue, so the above demo has been set up with an older renderer that will have the issue known as the "ident optimized renderer". The more current default rendering renders from root with the above code, and will not have a problem; however, technically the fix below is still recommended because there are other ways for a localized refresh to cause this problem to manifest. |
The fix is equally simple: calculate depth and pass it to the child. Use the calculated depth to prevent the extra rendering when local refresh gives you data you don’t need. The demo below has this fix.
(ns book.queries.recursive-demo-3
(:require [com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.mutations :refer [defmutation]]
[com.fulcrologic.fulcro.dom :as dom]))
(declare ui-person)
(defmutation make-older [{:keys [id]}]
(action [{:keys [state]}]
(swap! state update-in [:person/id id :person/age] inc)))
; We use computed to track the depth. Targeted refreshes will retain the computed they got on
; the most recent render. This allows us to detect how deep we are.
(defsc Person [this
{:keys [db/id person/name person/spouse person/age]} ; props
{:keys [render-depth] :or {render-depth 0}}] ; computed
{:query (fn [] [:db/id :person/name :person/age {:person/spouse 1}]) ; force limit the depth
:initial-state (fn [p]
{:db/id 1 :person/name "Joe" :person/age 20
:person/spouse {:db/id 2 :person/name "Sally"
:person/age 22
:person/spouse {:db/id 1 :person/name "Joe"}}})
:ident [:person/id :db/id]}
(dom/div
(dom/div "Name:" name)
(dom/div "Age:" age
(dom/button {:onClick
#(comp/transact! this [(make-older {:id id})])} "Make Older"))
(when (and (= 0 render-depth) spouse)
(dom/ul
(dom/div "Spouse:"
; recursively render, but increase the render depth so we can know when a
; targeted UI refresh would accidentally push the UI deeper.
(ui-person (comp/computed spouse {:render-depth (inc render-depth)})))))))
(def ui-person (comp/factory Person {:keyfn :db/id}))
(defsc Root [this {:keys [person-of-interest]}]
{:initial-state {:person-of-interest {}}
:query [{:person-of-interest (comp/get-query Person)}]}
(dom/div
(ui-person person-of-interest)))8.9.2. Duplicates and Recursion
Of course it is perfectly fine for there to be multiple edges in your graph that point to the same node.
Below is a recursive bullet list example.
We’ve intentionally nested item B.1 under B and D so you can see that it all works itself out.
Normalization of initial state (which must be a tree) is perfectly happy to see duplicate entries. It simply merges the multiple copies into the same normalized entry in the table.
Since the two entries merge to the same entry, it also means the modifications will be shared among them.
Try checking item B.1 in either location.
(ns book.queries.recursive-demo-bullets
(:require [com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.fulcrologic.fulcro.dom :as dom]
[clojure.string :as str]))
(declare ui-item)
(defsc Item [this {:keys [ui/checked? item/label item/subitems]}]
{:query (fn [] [:ui/checked? :db/id :item/label {:item/subitems '...}])
:ident [:item/by-id :db/id]}
(dom/li
(dom/input {:type "checkbox"
:checked (if (boolean? checked?) checked? false)
:onChange #(m/toggle! this :ui/checked?)})
label
(when subitems
(dom/ul
(mapv ui-item subitems)))))
(def ui-item (comp/factory Item {:keyfn :db/id}))
(defsc ItemList [this {:keys [db/id list/items] :as props}]
{:query [:db/id {:list/items (comp/get-query Item)}]
:ident [:list/by-id :db/id]}
(dom/ul
(mapv ui-item items)))
(def ui-item-list (comp/factory ItemList {:keyfn :db/id}))
(defsc Root [this {:keys [list]}]
{:initial-state (fn [p]
{:list {:db/id 1
:list/items [{:db/id 2 :item/label "A"
:item/subitems
[{:db/id 7
:item/label "A.1"
:item/subitems
[{:db/id 8
:item/label "A.1.1"
:item/subitems []}]}]}
{:db/id 3
:item/label "B"
:item/subitems
[{:db/id 6 :item/label "B.1"}]}
{:db/id 4
:item/label "C"
:item/subitems []}
{:db/id 5
:item/label "D"
; just for fun..nest a dupe under D
:item/subitems [{:db/id 6 :item/label "B.1"}]}]}})
:query [{:list (comp/get-query ItemList)}]}
(dom/div
(ui-item-list list)))8.10. The AST
You can convert any expression of EQL into an AST (abstract syntax tree) and vice versa.
This lends itself to doing complex parsing of the query (typically on the server).
The functions of interest are eql/query→ast and eql/ast→query.
There are many uses for this.
One such use might be to convert the graph expression into another form.
For example, say you wanted to run a query against an SQL database.
You could write an algorithm that translates the AST into a series of SQL queries to build the desired result.
The AST is always available as one of the parameters in the mutation/query env on the client and server.
Another use for the AST is in mutations targeted at a remote: it turns out you can morph a mutation before sending it to the server.
8.10.1. Morphing Mutations
The most common use of the AST is probably adding parameters that the UI is unaware need to be sent to a remote.
When processing a mutation with defmutation (or just the raw defmethod) you will receive the AST of the mutation in the env.
It is legal to return any valid AST from the remote side of a mutation.
This has the effect of changing what will be sent to the server:
(defmutation do-thing [params]
(action [env] ...)
(remote [{:keys [ast]}] ast)) ; same effect as `true`
(defmutation do-thing [params]
(action [env] ...)
(remote [{:keys [ast]}] (eql/query->ast `[(do-other-thing)])) ; completely change what gets sent to `remote`
(defmutation do-thing [params]
(action [env] ...)
(remote [{:keys [ast]}] (assoc ast :params {:y 3}))) ; change the parametersFor more on mutations see the chapter on Handling Mutations
9. Initial Application State
When starting any application one thing has to be done before just about anything else: Establish a starting state. In Fulcro this just means generating a client-side application database (normalized). Other parts of this guide have talked about the Graph Database. You can well imagine that hand-coding one of these for a large application’s starting state could be kind of a pain. Actually, even though coding it would be a pain, it turns out that the bigger pain happens later when you want to refactor! That can become a real mess!
However, Fulcro already knows how to normalize a tree of data, and your UI is already the tree you’re interested in. So, Fulcro encourages you to co-locate initial application state with the components that need the state and compose it towards the root, just like you do for queries. This gives some nice results:
-
Your initial application state is reasoned about locally to each component, just like the queries.
-
Refactoring the UI just means modifying the local composition of queries and initial state from one place to another in the UI.
-
Fulcro understands unions (you can only initialize one branch of a to-one relation), and can scan for and initialize alternate branches.
9.1. Adding Initial State to Components
To add initial state, follow these steps:
-
For each component that should appear initially: add the
:initial-stateoption. -
Compose the components in (1) all the way to your root.
That’s it! Fulcro will automatically detect initial state on the root, and use it for the application!
(defsc Child [this props]
{:initial-state (fn [params] {:child/id 1})
:ident :child/id
:query [:child/id]}
...)
(defsc Parent [this props]
{:initial-state (fn [params] {:parent/id 1 {:parent/child (comp/get-initial-state Child)}})
:ident :parent/id
:query [:parent/id {:parent/child (comp/get-query Child)}]}
...)
...Notice the nice symmetry here.
The initial state is (usually) a map that represents (recursively) the entity and its children.
The query is a vector that lists the "scalar" props, and joins as maps.
So, in Child we have initial state and a query for its ID. In the parent we have a query for the parent’s data with a join to the child, and initial state mirrors that with an identical structure pulling the child state.
9.1.1. Initial State and Alternate Branches of Unions
The one "extra" feature that initial state support does for you is to initialize alternate branches of components that have a to-one union query. Remember that a to-one relation from a union could be to any number of alternates.
Take this union query: {:person (comp/get-query Person) :place (comp/get-query Place)}
It means "if you find an ident in the graph pointing to a :person, then query for the person.
If you find one for :place, then query for a place."
The problem is: if it is a to-one relation then only one can be in the initial state tree at startup!
{ :person-or-place [:person 2]
:person {2 {:id 2 ...}}}If you look at a proposed initial state, it will make the problem more clear:
(defsc Person [this props]
{:initial-state (fn [{:keys [id name]}] {:id id :name name :type :person})
...)
(defsc PersonPlaceUnion [this props]
{:initial-state (fn [p] (comp/get-initial-state Person {:id 1 :name "Joe"})) ; I can only put in one of them!
:query {:person (comp/get-query Person) :place (comp/get-query Place)})
...)
(defsc Parent [this props]
{:initial-state (fn [p] {:person-or-place (comp/get-initial-state PersonPlaceUnion)}))
:query [{:person-or-place (comp/get-query PersonPlaceUnion)}]))This would result in a person in the initial state, but not a place.
Fulcro solves this at startup in the following manner: It pulls the query from root and walks it. If it finds a union component, then for each branch it sees if that component (via the query metadata) has initial state. If it does, it places it in the correct table in app state. This does not, of course, join it to anything in the graph since it isn’t the "default branch" that was explicitly listed.
This behavior is critical when using unions to handle UI routing, which is in turn essential for good application performance.
9.1.2. Initial State Demo
The following demo shows all of this in action.
(ns book.demos.initial-app-state
(:require
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]))
(defmethod m/mutate 'nav/settings [{:keys [state]} sym params]
{:action (fn [] (swap! state assoc :panes [:settings :singleton]))})
(defmethod m/mutate 'nav/main [{:keys [state]} sym params]
{:action (fn [] (swap! state assoc :panes [:main :singleton]))})
(defsc ItemLabel [this {:keys [value]}]
{:initial-state (fn [{:keys [value]}] {:value value})
:query [:value]
:ident (fn [] [:labels/by-value value])}
(dom/p value))
(def ui-label (comp/factory ItemLabel {:keyfn :value}))
;; Foo and Bar are elements of a mutli-type to-many union relation (each leaf can be a Foo or a Bar). We use params to
;; allow initial state to put more than one in place and have them be unique.
(defsc Foo [this {:keys [label]}]
{:query [:type :id {:label (comp/get-query ItemLabel)}]
:initial-state (fn [{:keys [id label]}] {:id id :type :foo :label (comp/get-initial-state ItemLabel {:value label})})}
(dom/div
(dom/h2 "Foo")
(ui-label label)))
(def ui-foo (comp/factory Foo {:keyfn :id}))
(defsc Bar [this {:keys [label]}]
{:query [:type :id {:label (comp/get-query ItemLabel)}]
:initial-state (fn [{:keys [id label]}] {:id id :type :bar :label (comp/get-initial-state ItemLabel {:value label})})}
(dom/div
(dom/h2 "Bar")
(ui-label label)))
(def ui-bar (comp/factory Bar {:keyfn :id}))
;; This is the to-many union component. It is the decision maker (it has no state or rendering of it's own)
;; The initial state of this component is the to-many (vector) value of various children
;; The render just determines which thing it is, and passes on the that renderer
(defsc ListItem [this {:keys [id type] :as props}]
{:initial-state (fn [params] [(comp/get-initial-state Bar {:id 1 :label "A"}) (comp/get-initial-state Foo {:id 2 :label "B"}) (comp/get-initial-state Bar {:id 3 :label "C"})])
:query (fn [] {:foo (comp/get-query Foo) :bar (comp/get-query Bar)}) ; use lambda for unions
:ident (fn [] [type id])} ; lambda for unions
(case type
:foo (ui-foo props)
:bar (ui-bar props)
(dom/p "No Item renderer!")))
(def ui-list-item (comp/factory ListItem {:keyfn :id}))
;; Settings and Main are the target "Panes" of a to-one union (e.g. imagine tabs...we use buttons as the tab switching in
;; this example). The initial state looks very much like any other component, as does the rendering.
(defsc Settings [this {:keys [label]}]
{:initial-state (fn [params] {:type :settings :id :singleton :label (comp/get-initial-state ItemLabel {:value "Settings"})})
:query [:type :id {:label (comp/get-query ItemLabel)}]}
(ui-label label))
(def ui-settings (comp/factory Settings {:keyfn :type}))
(defsc Main [this {:keys [label]}]
{:initial-state (fn [params] {:type :main :id :singleton :label (comp/get-initial-state ItemLabel {:value "Main"})})
:query [:type :id {:label (comp/get-query ItemLabel)}]}
(ui-label label))
(def ui-main (comp/factory Main {:keyfn :type}))
;; This is a to-one union component. Again, it has no state of its own or rendering. The initial state is the single
;; child that should appear. Fulcro (during startup) will detect this component, and then use the query to figure out
;; what other children (the ones that have initial-state defined) should be placed into app state.
(defsc PaneSwitcher [this {:keys [id type] :as props}]
{:initial-state (fn [params] (comp/get-initial-state Main nil))
:query (fn [] {:settings (comp/get-query Settings) :main (comp/get-query Main)})
:ident (fn [] [type id])}
(case type
:settings (ui-settings props)
:main (ui-main props)
(dom/p "NO PANE!")))
(def ui-panes (comp/factory PaneSwitcher {:keyfn :type}))
;; The root. Everything just composes to here (state and query)
;; Note, in core (where we create the app) there is no need to say anything about initial state!
(defsc Root [this {:keys [panes items]}]
{:initial-state (fn [params] {:panes (comp/get-initial-state PaneSwitcher nil)
:items (comp/get-initial-state ListItem nil)})
:query [{:items (comp/get-query ListItem)}
{:panes (comp/get-query PaneSwitcher)}]}
(dom/div
(dom/button {:onClick (fn [evt] (comp/transact! this '[(nav/settings)]))} "Go to settings")
(dom/button {:onClick (fn [evt] (comp/transact! this '[(nav/main)]))} "Go to main")
(ui-panes panes)
(dom/h1 "Heterogenous list:")
(dom/ul
(mapv ui-list-item items))))9.2. Initial State and State Progressions
Since our rendering via React is a pure function of state you think about your application as a sequence of states that are rendered in time (like a movie), and the initial state just generates the first state for that progression.
An interesting note is that this model also results in a really useful property: You can take the initial state, run it though the implementation of one or more mutations, and end up with any other state. This means you can easily reason about initializing your application into any state, which is useful for things like testing and server-side rendering.
There are all sorts of very useful features that fall out of this. For example, it is also possible to record a series of "user interactions" (which can be recorded as a list of the mutations that ran) and replay those. This could be used to send a tester a sequence of steps to show recent development work, run automated demos/tests, teleport your development environment to a specific page, etc.
Writing tests against the state model and mutation implementations is a great way to unit test your application without needing to involve the UI itself at all.
10. Normalization
Normalization is a central mechanism in Fulcro. It is the means by which your data trees (which you receive from component queries against servers) can be placed into your normalized graph database.
10.1. Internals
The function fnorm/tree→db is the workhorse that turns an incoming tree of data into normalized data (which can then be merged into the overall database).
Imagine an incoming tree of data:
{ :people [ {:db/id 1 :person/name "Joe" ...} {:db/id 2 ...} ... ] }and the query:
[{:people (comp/get-query Person)}]which expands to:
[{:people [:db/id :person/name]}]
^ metadata {:component Person}tree→db recursively walks the data structure and query:
-
At the root, it sees
:peopleas a root key and property. It remembers it will be writing:peopleto the root. -
It examines the value of
:peopleand finds it to be a vector of maps. This indicates a to-many relationship. -
It examines the metadata on the subquery of
:peopleand discovers that the entries are represented by the componentPerson -
For each map in the vector, it calls the
identfunction ofPerson(which it found in the metadata) to get a database location. It then places the "person" values into the result viaassoc-inon the ident. -
It replaces the entries in the vector with the idents.
If the metadata was missing then it would assume the person data did not need normalization.
This is why it is critical to compose queries correctly.
The query and tree of data must have a parallel structure, as should the UI. In template mode defsc will try to check some things for you, but you must ensure that you compose the queries correctly.
10.2. Normalization: Initial State, Server Interactions, and Mutations
The process described above is how most data interactions occur.
At startup the :initial-state supplies data that exactly matches the tree of the UI. This gives your UI some initial state to render.
The normalization mechanism described above is what happens to that initial tree when it is detected by Fulcro at startup (with the addition of the alternate union merging, described earlier).
Network interactions send a UI-based query (which is annotated with the components). The query is remembered and when a response tree of data is received (which must match the tree structure of the query), the normalization process is applied and the resulting normalized data is merged with the database.
It is the same thing when using websockets:
A server push gives you a tree of data.
You could hand-normalize that data, but actually if you know the structure of the incoming data you can easily generate a client-side query (using
defsc) that can be used in conjunction with fnorm/tree→db to normalize that incoming data.
Mutations can do the same thing. If a new instance of some entity is being generated by the UI as a tree of data, then the query for that UI component can be used to turn it into normalized data that can be merged into the state within the mutation.
Some useful functions to know about:
-
merge/merge-component!andmerge/merge-component- merge new instances of a (possibly recursive) entity into the normalized database. -
merge/merge!andmerge/merge*- merge root-level out-of-band data into your application. -
fnorm/tree→db- General utility for normalizing data via a query and chunk of data. -
targeting/integrate-ident*- A utility for adding an ident into existing to-one and to-many relations in your database. Can be used within mutations.
|
Note
|
The general merge operations all support the option :remove-missing?.
This option defaults to false.
When set to true it will cause the merge algorithms to exhibit the Fulcro remote load cleanups: if something is in the query but not the data then it will be removed from the state database.
The deep merge used by the merge routines is not otherwise meant to "write over" existing versions of your entities, since they may have ui-only attributes that the incoming trees do not know about.
See the section on remote result merging.
|
11. Full Stack Operation
One of the most interesting and powerful things about Fulcro is that the model for server interaction is unified into a clean data-driven structure. At first the new concepts can be challenging, but once you’ve seen the core primitive (component-based queries/idents for normalization) we think you’ll find that it dramatically simplifies everything!
In fact, now that you’ve completed the materials of this guide on the graph database, queries, idents, and normalization, it turns out that the server interactions become nearly trivial!
Not only is the structure of server interaction well-defined, Fulcro come with pre-written middleware to handle plumbing for you.
However, there are a lot of possible pitfalls when writing distributed applications. People often underestimate just how hard it is to get web applications right because they forget that.
So, while the API and mechanics of how you write Fulcro server interactions are as simple as possible there is no getting around that there are some hairy things to navigate in distributed apps independent of your choice of tools. Fulcro tries to make these things apparent, and it also tries hard to make sure you’re able to get it right without pulling out your hair.
Here are some of the basics:
-
The Network protocol is included (and extensible))
-
The protocol is EDN on the wire (via transit), which means you just speak Clojure data on the wire, and can easily extend it to encode/decode new types.
-
-
All network requests (queries and mutations) are processed sequentially unless you specify otherwise. This allows you to reason about optimistic updates (Starting more than one at a time via async calls could lead to out-of-order execution, and impossible-to-reason-about recovery from errors).
-
You can provide error handling for remote problems at a global or mutation-local level.
-
You can interact directly with the network result or use default result processing.
-
Any
:ui/namespaced query elements are automatically elided when generating a query from the UI to a server, allowing you to easily mix UI concerns with server concerns in your component queries. You can also change the global rewrite logic to elide other local props from remote queries. -
Normalization of a remote query result is automatic when using
defmutation, but customizable.-
Query results use intelligent overwrite for properties that are already present in the client database.
-
-
Any number of remotes can be defined
-
Protocol and communication is strictly constrained to the networking layer and away from your application’s core structure, meaning you can actually speak whatever and however you want to a remote. In fact the concept of a remote is just "something you can talk to via queries and mutations". You can easily define a "remote" that reads and writes browser local storage or a Datascript database in the browser. This is an extremely powerful generalization for isolating side-effect code from your UI.
|
Note
|
To those of you with REST or GraphQL APIs: See the Pathom library for ways of converting those services into custom client remotes that isolate those APIs to the networking layers of your client. |
11.1. General Theory of Operation
There are only a few general kinds of interactions with a server:
-
Initial loads when the application starts
-
Incremental loads of sub-graphs of something that was previously loaded.
-
Event-based loads (e.g. user or timed events)
-
Integrating data from other external sources (e.g. server push)
-
Run a remote operation, which can optionally return a graph of data as a response.
In standard Fulcro networking, all of the above have the following similarities:
-
A component-based graph query needs to be involved to enable auto-normalization. This is true even for a server push (though in that case the client needs to know what implied query the server is sending data about).
-
The data from the server will be a tree that has the same shape as the query.
-
The data needs to be normalized into the client database.
-
Optionally: after integrating new data there may be some need to transform the result to a form the UI needs (e.g. perhaps you need to sort or paginate some list of items that came in).
IMPORTANT: Remember what you learned about the graph database, queries, and idents. This section cannot possibly be understood properly if you do not understand those topics!
11.1.1. Integration of ALL new external data is just a Query-Based Merge
So, here is the secret: When external data needs to go into your database it all uses the exact same mechanism: a query-based merge. So, for a simple load: you send a UI-based query to the server, the server responds with a tree of data that matches that graph query, and then the query itself (which is annotated with the components and ident functions) can be used to normalize the result. Finally, the normalized result can be merged into your existing client database.
Query --> Server --> Response + Original Query w/Idents --> Normalized Data --> Database Merge --> New DatabaseAny other kind of external data integration just starts at the "Response" step by manually providing the query:
New External Data + Query w/Idents --> Normalized Data --> Database Merge --> New DatabaseThere is a primitive function merge/merge! function that implements this, so that you can simplify the picture to:
Tree of Data + Query --> merge! --> New Database11.1.2. The Central Functions: transact! and merge!
The two core functions that allow you to trigger abstract operations or data merges externally (via your app) are:
comp/transact!-
The central function for running abstract (possibly full-stack) changes in the application. Can be run with a component or app. If run with the app, will typically cause a root re-render.
merge/merge!-
A function that can be run against the app to merge a tree of data via a UI query.
merge/merge-component!-
Like
merge!, but can be passed a component instead of a query. merge/merge*-
merge!, but in a mutation viaswap!
These (and related/derived helpers) are the primary tools used to put new data into your client’s database.
11.1.3. Query Mismatch
We have all sorts of ways we’d like to view data. Perhaps we’d like to view "all the people who’ve ever had a particular phone number". That is something we can very simply represent with a UI graph, but may not be trivial to pull from our database.
In general, there are a few approaches to resolving our graph differences:
-
Use a query parser on the server to piece together data based on the graph of the query (preferred).
-
Ask the server for exactly what you want, using an invented well-known "root" keyword, and hand-code the database code to create the UI-centric view.
-
Ask the server for the data in a format it can provide and morph it on the client.
The first two have the advantage of making the client blissfully unaware of the server schema. It just asks for what it needs, and someone on the server programming team makes it happen. Fortunately, pathom makes this approach quite tractable and good.
In some cases, though, you’d like to morph it a bit on the client-side. We’ll show you an example of this as we explore the data fetch options.
11.1.4. Server Interaction Order
Fulcro will serialize requests unless you mark queries as parallel (an option you can specify with df/load!).
Two different events that queue mutations or loads will be processed in the order of events.
For example, if the user clicks on something and you trigger two loads during that event, then both of those may be combined (if they don’t conflict) and sent as one network request.
If the user clicks on something else and that handler queues two more loads, then the latter two loads will not start over the network until the first load sequence has completed.
This ensures that you don’t get out-of-order server execution. This is a distributed system, so it is possible for a second request to hit a less congested server (or even thread) than the first and get processed out of order. That would hurt your ability to reason about your program, so the default behavior in Fulcro is to ensure that server interactions happen on the server in the same order as they do on the client.
Fulcro will also try to reorder writes that are submitted alongside reads so that the writes appear on the server first, giving you the best possible chance that the reads get the most up-to-date versions of data.
In Summary:
-
Loads/transactions queued while "holding the UI thread" may be joined together in a single network request.
-
Remote writes go before reads (for a given processing event)
-
Loads/transactions queued at a later event (new UI thread event) are guaranteed to be processed after ones queued earlier.
-
You can override this behavior with the
paralleloption ofload!orparallel?oftransact!.
11.1.5. Server Result Query Merging
There is a potential for a data-driven app to create a new class of problem related to merging data. The normalization guarantees that the data for any number of views of the same thing are normalized to the same node in the graph database.
Thus, your PersonListRow view and PersonDetail view should both normalize the same person data to a location like [:person/id id].
Let’s say you have a quick list of people on the screen that is paginated and demand-loaded, where each row is a PersonListRow with query [:db/id :person/name {:person/image (comp/get-query Image)}].
Now say that you can click on one of these rows and a side-by-side view of that person’s PersonDetail is shown, but the query for that is a whole bunch of stuff: name, age, address, phone numbers, etc.
A much larger query.
A naive merge could cause you all sorts of nightmares. For example, Refreshing the list rows would load only name and image, but if merge overwrote the entire table entry then the current detail would suddenly empty out!
Fulcro provides you with an advanced merging algorithm that ensures these kinds of cases don’t easily occur. It does an intelligent merge with the following algorithm:
-
It is a detailed deep merge. Thus, the target table entry is updated, not overwritten.
-
If the query asks for a value but the result does not contain it, then that value is removed.
-
If the query didn’t ask for a value, then the existing database value is untouched.
This reduces the problem to one of potential staleness. It is technically possible for an entity in the resulting client database to be in a state that has never existed on the server because of such a partial update. This is considered to be a better result than the arbitrary UI madness that a more naive approach would cause.
For example, in the example above a query for a list row will update the name and image. All of the other details (if already loaded) would remain the same; however, it is possible that the server has run a mutation that also updated this person’s phone number. The detail part of the UI will be showing an updated name and image, but the old phone number. Technically this "state of Person" has never existed in the server’s timeline, but from a user’s perspective it looks better than the phone number disappearing.
In practice this isn’t that big of a deal; however, if you are switching the UI to an edit mode it is generally a good practice to on-demand (re)load the entity being edited to help prevent user confusion.
11.1.6. Defining Error Conditions
Both loads and mutations have a general concept of network errors that is customizable.
The default detection of error conditions looks at the status-code of the network result.
If it is 200, then it is considered "ok", and anything else is an error.
You may want to customize this behavior to also look for other bits of content in the result, which can be specific to the remote and middleware definitions.
There is one global definition for error detection that is used for both loads and mutations.
It can be overridden with the :remote-error? option when creating the application:
(def app (app/fulcro-app {:remote-error? (fn [result] ...)}))11.2. React Lifecycle and Load
React lifecycle and load may not mix well. It is technically legal to issue transactions and loads from React Lifecycle methods, but it is recommended that you carefully check the state of the system in said mutations before actually queuing network traffic. Perhaps you wish to ensure something is loaded. To do that: trigger a mutation that checks state and optionally submits a load. This is also true for any sort of side-effecting against your application state since the React lifecycle calls can be triggered for unexpected reasons (e.g. instability in a parent’s key can cause all children to unmount/remount).
12. Mutations
Mutations are the primary mechanism by which side effects happen in Fulcro.
In fact, even the load API in the data-fetch namespace is implemented via the mutation system.
Mutations are data expressions that represent a command to execute (locally and/or remotely).
The remote operation of a mutation can optionally return a graph tree to be merged into your application’s state.
Mutations are submitted to Fulcro’s transaction processing system via comp/transact!.
Technically the algorithm for processing transactions is pluggable, but this book will only cover the built-in version.
Mutations are known by their symbol and are dispatched to the internal multi-method
com.fulcrologic.fulcro.mutations/mutate.
To handle a mutation you can do two basic things: use defmethod
to add a mutation, or use the macro defmutation to handle this for you.
The macro is highly recommended for all but the most advanced cases because:
-
Your editor/IDE can treat it like
defnfor better navigation and support. -
It is where the default remote response handling is "plugged in".
-
It prevents certain implementation errors.
-
It isolates you from any potential internal changes to Fulcro.
-
It auto-namespaces the mutation to the namespace of declaration without the need to quote.
-
It adds support to use the mutation in a transaction without syntax quoting.
You might use the internal multi-method directly for more advanced things like:
-
You’re writing your own
defmutationwrapper to change some global behavior for your application (note, though, that the built-indefmutationhas an extension point). -
You want to dynamically affect a mutation in some complex way at runtime.
|
Important
|
The internals of mutations changed drastically between version 2 and 3 of Fulcro. The low-level multimethod requires a different format for the return value in version 3, and mutations directly handle network results in 3. |
12.1. Stages of Mutation
A mutation expresses the local effects, outgoing remote request(s), and network result processing for a given abstract operation in a Fulcro application.
The local effects are applied first, the remote requests are queued, and the responses are processed as they arrive.
The default behavior of the transaction processing system is to process all of the local effects of a given transaction first, then submit all of the network requests later.
This "optimistic" processing mode can be toggled with an option to the top-level transact!:
(comp/transact! this [(f) (g) (h)] {:optimistic? false})This would run the optimistic actions of f, wait for any network results, then run the optimistic actions of g, etc.
whereas
(comp/transact! this [(f) (g) (h)])will cause the optimistic actions of f, g, and h to all run, and then submit the network actions.
In Fulcro 3 each stage of the mutation is implemented as a lambda, and each stage receives an environment that describes the state of the app (and even what the state looked like before the mutation started).
12.2. Using defmutation
Using defmutation looks like this:
(defmutation mutation-symbol
"docstring"
[params]
(action [{:keys [state] :as env}]
(swap! state ...))
(rest-api [env] true)
(remote [env] true))It intentionally looks a bit like a function definition so that IDE’s like Cursive can be told how to resolve the macro (as defn in this case) and will then let you read the docstrings and navigate to the definition from the usage sites.
This makes development a lot easier.
The symbol itself does get interned into the local namespace as a function-like thing that will return the call itself as data (i.e. running (f {:x 1}) in a REPL returns the list (the.ns/f {:x 1})).
This allows you to use the mutation unquoted in most situations (except where there are circular references and you cannot require it):
(ns app
(:require [app.mutations :as am]))
...
(comp/transact! this [(am/mutation-symbol {})])|
Note
|
You can get the "quoteless" feature using the m/declare-mutation function as well.
|
12.2.1. The env
Each stage of the mutation will receive an environment parameter the has a number of things in it that can be used to accomplish the real work of the mutation:
:app-
The application itself. Can be used to do things like call
transact!, etc. :component-
Will be the component (if any) that ran the transaction
:ref-
Will be the ident of the component (if any) that ran the transaction
:state-
The atom holding the state database. Optimistic actions
swap!on this. :state-before-action-
(in remotes) A map holding the value of the state database before the
:actionran. :ast-
The AST of the mutation node that is running.
:com.fulcrologic.fulcro.algorithms.tx-processing/options-
The map of options that was passed to
transact!(if using the default built-in transaction processing). :result-
(passed to
:result-action, which may subsequently callok-actionorerror-action). The raw remote response. This raw result’s content will depend on the actual remote and middleware you’re using for that remote, but it will typically include things like the raw response and the network result status code. :dispatch-
A map from section name to the lambdas that represent the other sections of the mutation (e.g.
:actionin this map is the lambda representing theactionsection of the mutation). This can be used to cross-call sections, usually to invent your own purpose-built sections of mutations via overriding the defaultresult-action. :mutation-return-value-
The data returned from the server-side mutation (if available). Will be in
envofok-actionanderror-actionIF you are using the built-in default result action handler. (requires Fulcro 3.6.4+). Otherwise you can derive this by looking inresult, which is the network result.
12.2.2. The Sections
The sections of a mutation include:
action-
The optimistic action. Run before any network traffic is submitted.
remote-
Instructions for the remote side of the mutation. The names of these sections are user-defined by the list of remotes you define when you create the application. The return value of a remote determines what, if anything, is sent to that remote.
result-action-
Optional. The default value of this can be overridden as an application parameter. The
result-actionsection receives network results as they arrive. The default result action handles mutation return values and cross-callsok-actionorerror-action. ok-action-
Optional. If you are using the default
result-action, theok-actionis called when the remote result received is free from errors. error-action-
Optional. If you are using the default
result-action, theerror-actionis called when the remote result was an error. See Defining Error Conditions.
12.3. Remote Mutations
Mutations are already plain data, so Fulcro can pass them over the network as-is when the client invokes them. All you need to do to indicate that a given mutation should affect a given remote is add that remote to the mutation:
(defmutation add-friend [params]
(action ...) ; optimistic update of client state
(remote [env] true)) ; send the mutation to the remote known as :remoteTake a moment to note that getting the "right" level of abstraction for these commands can give you great leverage. These are the units of optimistic and full-stack operation.
12.3.1. The remote Section(s)
You can define any number of remotes for your Fulcro application.
The default remote is an HTTP remote that talks to the server of the page at /api through HTTP POST requests.
Additional remotes are created and named by you.
The remote operation you want to run against any mutation just needs to share the name of that mutation:
(def app (app/fulcro-application {:remotes {:rest-api ...}}))
(defmutation some-thing [params]
(rest-api [env] true))A mutation is allowed to trigger itself against any number of simultaneous remotes.
The return value of a remote section must be one of:
-
true: Sends the exact expression that was sent viatransact!to that remote. -
An
envcontaining an:ast: Sends the expression of the:astkey from thatenv. Useful with built-in helpers. -
An EQL AST: Sends the expression of the AST node, which generally can be generated via
eql/query→ast1. -
false: The same as not listing the section.
The remote section is treated as a lambda, and it is call after the optimistic action has run.
The env passed to it will include the :state-before-action
which is a snapshot (i.e. normalized database map) of the state before the optimistic change occurred.
This allows you to make the logic of your remote conditional on either the state as it is now (via :state) or before.
Therefore, you can alter a mutation simply by altering and returning the ast given in env:
(defmutation do-thing [params]
(action [env] ...)
; send (do-thing {:x 1}) even if params are different than that on the client
(remote [{:keys [ast]}] (assoc ast :params {:x 1})) ; change the param list for the remote
; or using the with-params helper against `env`
(defmutation do-thing [params]
(action [env] ...)
; send (do-thing {:x 1}) even if params are different than that on the client
(remote [env] (m/with-params env {:x 1})) ; change the param list for the remoteor even change which mutation the server sees:
(defmutation some-mutation [ params]
;; Send a completely different mutation to the server
(remote [env] (eql/query->ast1 `[(some-other-thing {:x 2})])))12.3.2. Result Action
A key part of defmutation is that it emits a "default" result action that does a number of automatic operations for your mutation’s network results:
-
If there is an error, it calls your
error-actionsection. -
If there is not an error, it calls you
ok-actionsection. -
If it was configured with a global error handler, then that handler is called on errors (see the docstring of
default-result-action). -
It merges and targets the mutation’s remote return value (if you indicated there was a return value).
-
It resolves tempids.
|
Important
|
If you override the result-action section, then none of these default behaviors will happen unless you do them yourself.
If you want to augment the default behavior, then you can manually call the m/default-result-action
function as part of your own :result-action.
|
12.3.3. Plugging in a New Global Result Action
You can supply a lambda to use instead of default-result-action when you create your application:
(def app (app/fulcro-app {:default-result-action (fn [env] ...)}))|
Warning
|
This setting will affect all mutations in your system, and should be used with care.
If you choose not to call m/default-result-action within your custom function then mutation return values, tempid resolution, and ok/error action handlers will not work.
|
12.3.4. Optimistic vs. Pessimistic
The action portion of a mutation is run immediately on the client.
When there is also a server interaction then the client-side operation is known as an optimistic update because by default we assume that the server will succeed in replicating the action.
This gives the user immediate feedback and the ability to proceed quickly even in the presence of a slow network.
You may, of course, decide not to do anything in the action section (don’t provide one).
In this case you’re operating in a pessimistic mode where the user won’t see a result until the network result has arrived and you
:result-action has processed it.
12.3.5. Writing The Server Mutations
Server-side mutations in Fulcro arrive as an EQL transaction, and must be interpreted as such.
Typically you’ll use an EQL parser built by Pathom.
The pathom defmutation
looks very similar to the Fulcro one:
;; CLIENT (Fulcro)
;; src/my_app/mutations.cljs
(ns my-app.mutations
(:require [com.fulcrologic.fulcro.mutations :refer [defmutation]]))
(defmutation do-something [{:keys [p]}]
(action [{:keys [state]}]
(swap! state assoc :value p))
(remote [env] true));; SERVER (Pathom)
;; src/my_app/mutations.clj
(ns my-app.mutations
(:require
[com.wsscode.pathom.connect :as pc]))
;; `env` can be augmented in parser setup to include things like database connection, etc.
(pc/defmutation do-something [env params]
{}
...))or even a CLJC file:
(ns my-app.mutations
(:require
[com.wsscode.pathom.connect :as pc]
[com.fulcrologic.fulcro.mutations :refer [defmutation]])))
#?(:cljs
(defmutation do-something [{:keys [p]}]
(action [{:keys [state]}]
(swap! state assoc :value p))
(remote [env] true))
:clj
(pc/defmutation do-something [env params]
...))Pathom lets you override the symbol on the server (via a ::pc/sym options) but it is still a good idea to use the same actual namespace (via clj/cljs pairs or just a CLJC file) to "co-locate" the mutations for easier code navigation.
Your tools will likely readily navigate you to just one of them, so having them side-by-side in CLJC is often the easiest to maintain, even though it is a bit noisier to write.
#?(:clj (pc/defmutation do-thing ...)
:cljs (defmutation do-thing ...))|
Note
|
Fulcro’s mutations and Pathom’s mutations are both CLJC themselves.
This allows for things like using your UI code (Fulcro’s defmutation) within the server for server-side rendering and building a client-layer EQL parser (Pathom’s defmutation) to process EQL on simulated remotes in the client.
Be careful that you don’t accidentally use the wrong version of defmutation in a given context.
|
12.3.6. New item creation – Temporary IDs
Fulcro has a built in function tempid/tempid that will generate a unique temporary ID of a special type.
This allows the normalization and denormalization of the client side database to continue working while the server processes the new data and returns the permanent identifier(s).
The idea is that these temporary IDs can be safely placed in your client database (and network queues), and will be automatically rewritten to their real ID when the server has managed to create the real persistent entity. Of course, since you have optimistic updates on the client it is important that things go in the correct sequence, and that queued operations for the server don’t get confused about what ID is correct!
|
Note
|
It is generally considered a "best practice" to generate and pass tempids as parameters to a mutation from the UI. This ensures that the same tempid flows through the local and all remotes. |
Fulcro’s implementation works as follows:
-
Mutations always run in the order specified in the call to
transact! -
Transmission of separate calls to
transact!run in the order they were called. -
If remote mutations are separated in time, then they go through a sequential networking queue, and are processed in order.
-
As mutations complete on the server, they can return tempid remappings. Those are applied to the application state and network queue before the next network operation (load or mutation) is sent.
This set of rules helps ensure that you can reason about your program, even in the presence of optimistic updates that could theoretically be somewhat ahead of the server.
For example, you could create an item, edit it, then delete it. The UI responds immediately, but the initial create might still be running on the server. This means the server has not even given it a real ID before you’re queuing up a request to delete it! With the above rules, it will just work! The network queue will have two backlogged operations (the edit and the delete), each with the same tempid that you used from the start (since that’s what the ID is in app state). When the create operation finally returns it will automatically rewrite all of the tempids in state and the network queues, then send the next operation. Thus, the edit will apply to the correct server entity, as will the delete.
All the mutation has to do is return a map with the special key :tempids
whose value is a map of tempid→realid.
|
Note
|
Make sure that the remote returns the :tempids map to Fulcro. For Pathom, you can ensure that by
adding ::pc/mutation-join-globals [:tempids] into its ::p/env config map - see this
demonstrated in fulcro-template.
|
Here are the client-side and server-side implementations of the same mutation that create a new item:
;; client
;; src/my_app/mutations.cljs
(ns my-app.mutations
(:require [com.fulcrologic.fulcro.mutations :refer [defmutation]]))
(defmutation new-item [{:keys [tempid text]}]
(action [{:keys [state]}]
(swap! state assoc-in [:item/id tempid] {:db/id tempid :item/text text}))
(remote [env] true));; server
;; src/my_app/mutations.clj
(ns my-app.mutations
(:require
[com.wsscode.pathom.connect :as pc]))
(pc/defmutation new-item [env {:keys [tempid text]}]
{}
(let [database-tempid (make-database-tempid)
database-id (add-item-to-database database {:db/id database-tempid :item/text text})]
{:tempids {tempid database-id}})))Other mutation return values are covered in Mutation Return Values.
|
Warning
|
When you pass tempids as a parameter to a mutation, that value will be captured and not rewritten. Thus
your ok-action and result-action env will contain a :tempid→realid map that can be used to translate those
values.
|
Avoiding Tempids
It is also possible to avoid tempids altogether. For example, if you make a unique attribute (column) on your server-side entities (rows) that holds a UUID. This has the following trade-offs:
-
It consumes a bit more space in your database.
-
The client can generate new IDs for entities without needing a server connection.
-
If you use GUUIDs, then they are globally unique. They are all you might need in your data-store to find a given entity.
-
Transactions that use a UUID for creation are easier to make idempotent (can be applied more than once without breaking things). Tempids are remapped by the server, so two creations in a row with the same tempid will create two different new rows. This is a useful property for systems where you’d like to enable auto-retry at the network layer without worrying about correctness.
-
It is impossible to tell if an entity on the client is persisted without additional tracking. Tempids give you an easy way to instantly "see" that something isn’t yet saved.
12.3.7. Actions After a Mutation
Fulcro will automatically queue remote reads after writes when they are submitted in the same thread interaction. The following code:
(comp/transact! this [(f)])
(df/load this :thing Thing)
(comp/transact! this [(g)])will result in two network interactions.
The first will run [(f) (g)], and the second will be a load of :thing.
This is a defined and official behavior.
Thus, one way you can implement a sequence of mutations followed by a read is to simply run a mutation and a load.
However, this is not sufficient in many cases because not only do you need to know what happened on the server, you may also need to make some local changes to your application state based on that result. Common examples abound, but include:
-
You want to navigate away from a form after you know it is saved.
-
You want to close a payment modal after a charge is processed.
-
You want to route to a screen based upon a result.
-
You want to load something else based upon a prior result.
There are several ways to accomplish these tasks in Fulcro 3: pessimistic transactions, and various approaches using the ok-action and error-action of a mutation.
12.3.8. Pessimistic Transactions
A pessimistic transaction is a transaction processing semantic where each mutation in a transaction is processed to completion (full stack) before the next mutation in that same transaction does anything. Pessimistic transactions have no interaction with each other (other than guarantees of submission order).
This means that you can code a mutations whose optimistic action checks the result of the prior mutation to decide what to do. This looks like this at the UI layer:
(comp/transact! this `[(charge-card) (route-after-charge)] {:optimistic? false})and will run the full-stack operations of charge-card before the optimistic action of route-after-charge.
This mechanism has the advantage of keeping all transactions "top-level".
In other words this scheme makes the sequence of transactions apparent right at the point of call to the initial transact! and you can follow the sequence linearly right from there.
Unfortunately, you still have to analyze the nested logic in the mutations to figure out what really happens.
Fulcro 3 has some additional options for handling this.
12.3.9. Result Action for Pessimism
You are allowed to submit new transactions (via transact! or load!) in the ok-action and error-action sections of a mutation.
Thus, instead of writing a top-level transaction you can simply queue the first action:
(comp/transact! this `[(charge-card)])and then trigger the next step(s) in the mutation’s remote handling:
(defmutation charge-card [params]
...
(ok-action [{:keys [app result] :as env}]
;; you can `transact!`, `swap!`, etc.
(if (charge-ok? result)
(comp/transact! app [(show-ok-screen)])
(comp/transact! app [(show-error-screen)]))))12.3.10. Using Loads as Mutations
There is technically nothing wrong with issuing a load that has side-effects on the server (though one could argue that this is a bit sketchy from a design perspective). For example, one way to implement login is to issue a load with the user’s credentials:
(df/load :current-user User {:params {:username u :password p}})The server query response can validate the credentials, set a cookie, and return the user info all at once!
Your UI can simply base rendering on the values in :current-user.
If they’re valid, you’re logged in.
If you remember from the General Operations section, you can modify the low-level Ring response by associating a lambda with your return value. If you were using Ring Session, then this might be how the query would be implemented on the server:
(ns my-api
(:require [fulcro.server :as server :refer [defmutation defquery-root]]))
(def bad-user {:db/id 0})
(pc/defresolver
...
(if-let [{:keys [db/id] :as user} (authenticate params)] ; look up the user, return nil if bad
(server/augment-response user (fn [resp] (assoc-in resp [:session :uid] id)))
bad-user)))12.3.11. Running Mutations in the Context of an Entity
If you submit a transaction and include an ident:
(comp/transact! app `[(f)] {:ref [:person/id 3]})then the env of the mutation will include that explicit ref in the env.
If you use transact! against a component instance then ref is automatically set to the ident of that instance.
This means that you can write mutations that are "context sensitive" and can do things relative to the "invoking on-screen component instance".
This is how the mutation helper functions m/set-string! and m/toggle! work.
12.3.12. Mutations that Trigger one or more Loads
Mutations generally need not expose their full-stack nature to the UI. For example a next-page mutation might trigger a load for the next page of data or simply swap in some already cached data.
The UI need not be aware of the logic of this distinction (though typically the UI will want to include loading markers, so it is common for there to be some kind of knowledge about lazy loading).
Instead of coding complex "do I need to load that?" logic in the UI (where it most certainly does not belong) one should instead write mutations that abstract it into a nice concept.
The df/load! function simply runs a transact! on an internally-defined mutation with a special :result-action.
If you’d like to compose one or more loads into a mutation you can simply call them from any part of your mutation (even the remote sections, though technically it is probably better to use one of the action sections).
The basic pattern is:
(defmutation next-page [params]
(action [{:keys [app state] :as env}]
(swap! state ...) ; local optimistic db updates
(df/load! app :prop Component {:remote :remote}) ; same basic args as `load`, except state atom instead of `this`
(df/load! app :other Other) {:remote :other-remote})) ; as many as you need...12.4. Server Mutation Return Values
We’ve talked a lot about the client-side perspective of mutations, what they send to the server, and where you can place code to process the response of a mutation; however, we have not yet completely addressed the actual interaction with the server.
A server mutation is always allowed to return a value. The only "pre-built" behavior that happens with a server’s return values is temporary ID remappings:
; server-side
(defmutation new-thing [params]
(action [env]
...
{:tempids {old-id new-id}}))In some cases you’d like to return other details. However, remember that any arbitrary data merge on the client needs a tree of data and a query. With a mutation there is no query! As such, return values from mutations are ignored by default because there is no way to understand how to merge the result into your database.
Of course, you can override result-action or ok-action and directly access the mutation return value in :result of env, but this is Fulcro: we can do better!
If you want to make use of the returned values from the server then you need to add something to remedy the lack of a query.
12.4.1. Using Mutation Joins
The solution might be obvious to you: include the query with the mutation! This is called a mutation join. The explicit syntax in EQL for a mutation join looks like this:
`[{(f) [:x]}]but you never write them this way because a manual query doesn’t have component metadata information and cannot aid normalization. Instead, you write them just like you do when grabbing queries for anything else:
[{(f) (comp/get-query Item)}]Running a mutation with this notation allows you to return a value from the server’s mutation that exactly matches the graph of the item, and it will be automatically normalized and merged into your database.
So, if the Item query ended up being
[:item/id :item/value] then the server mutation could just return a simple map like so:
; server-side.
(pc/defmutation f [env params]
{::pc/output [:item/id]}
{:item/id 1})The reason we’re only returning :item/id in this example is that Pathom resolvers understand how to resolve the return value queries as if they were normal queries.
This means that as long as there are resolvers that can look up item details based on :item/id then the mutation need return nothing more, but the client can walk any arbitrary graph from there!
|
Note
|
At the time of this writing the query must come from a UI component that has an ident. Thus, mutations joins essentially normalize things into a specific table in your database (determined by the ID(s) of the return value and the ident on the query’s component). |
12.4.2. Mutation Joins: Simpler Notation
Writing transact! using manual mutation joins in the UI is quite visually noisy.
It turns out there is a better way.
If you remember: the remote section of client mutations can modify the remote EQL. Fulcro comes with helper functions that can rewrite the AST of the mutation to modify the parameters or convert it to a mutation join!
This can simplify how the mutations look in the UI.
Here’s the difference. With the manual syntactic technique we just described your UI and client mutation would look something like this:
; in the UI
(transact! this `[{(f) ~(comp/get-query Item)}])
; in your mutation definition (client-side)
(defmutation f [params]
(action [env] ...)
(remote [env] true))However, using the helpers you can instead write it like this:
; in the UI
(transact! this `[(f)])
; in your mutation definition (client-side)
(defmutation f [params]
(action [env] ...)
(remote [{:keys [ast state] :as env}] (returning env Item))This makes the mutation join an artifact of the network interaction, and less for you to manually code (and read) in the UI.
The server-side code is the same for both: just return a proper graph value!
12.4.3. Targeting Return Values From Mutation Joins
If you deal with return type at the mutation then Fulcro gives you some additional bonus features: m/with-params and
m/with-target.
These can be used together to fully customize the outgoing request.
Remember that m/returning just sets the return type.
By default, you’re just returning some entity tree.
The data gets normalized, but there is no further linkage into your app state.
You will sometimes need to change outgoing parameters on the mutation, and also to pepper idents around your app state to point at the return value.
These helpers all work on env and return env, and the remote sections accept env as a return value:
(defmutation f [params]
(action [env] ...)
(remote [env]
(-> env
(m/with-params (merge params {:api-token "cygnus x-1"}))
(m/returning Item)
(m/with-target (targeting/append-to [:path :to :field])))))All special targets are supported:
(defmutation f [params]
(action [env] ...)
(remote [env]
(-> env
(m/returning Item)
(m/with-target
(targeting/multiple-targets
(targeting/append-to [:table 3 :field])
(targeting/prepend-to [:table-2 4 :field]))))))Demo of Mutation Joins
The demo below cover the basics of using mutation joins. It demonstrates:
-
Targeting Raw Values
If you don’t specify a component with
returning, then your returned data can be targeted, but of course it won’t normalize:(defmutation trigger-error "This mutation causes an unstructured error on the server (just a map), but targets that value to the field `:error-message` on the component that invoked it." [_] (remote [{:keys [ref] :as env}] (m/with-target env (conj ref :error-message))))and the server simply returns a raw value (map is recommended)
(pc/defmutation trigger-error [_ _] (action [env] {:error "something bad"})) -
Targeting Graph Results
In the demo The bulk of the work is done in the
create-entitymutation. which is targeting to-many so we can demo more features.(defmutation create-entity "This mutation simply creates a new entity, but targets it to a specific location (in this case the `:child` field of the invoking component)." [{:keys [where?] :as params}] (remote [{:keys [ast ref state] :as env}] (let [path-to-target (conj ref :children) ; replacement cannot succeed if there is nothing present...turn those into appends no-items? (empty? (get-in @state path-to-target)) where? (if (and no-items? (= :replace-first where?)) :append where?)] (cond-> (-> env ; always set what kind of thing is coming back (m/returning Entity) ; strip the where?...it is for local use only (not server) (m/with-params (dissoc params :where?))) ; Add the targeting...based on where? (= :append where?) (m/with-target (targeting/append-to path-to-target)) ; where to put it (= :prepend where?) (m/with-target (targeting/prepend-to path-to-target)) (= :replace-first where?) (m/with-target (targeting/replace-at (conj path-to-target 0)))))))The server mutation just returns the entity.
(ns book.demos.server-targeting-return-values-into-app-state
(:require
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.algorithms.data-targeting :as targeting]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.fulcrologic.fulcro.data-fetch :as df]
[com.wsscode.pathom.connect :as pc]
[com.wsscode.pathom.core :as p]
[com.fulcrologic.fulcro.algorithms.tempid :as tempid]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def ids (atom 1))
(pc/defmutation server-error-mutation [env params]
{::pc/sym `trigger-error}
;; Throw a mutation error for the client to handle
(throw (ex-info "Mutation error" {:random-reason (rand-int 100)})))
(pc/defmutation server-create-entity [env {:keys [db/id]}]
{::pc/sym `create-entity}
(let [real-id (swap! ids inc)]
{:db/id real-id
:entity/label (str "Entity " real-id)
:tempids {id real-id}}))
(def resolvers [server-error-mutation server-create-entity])
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(declare Item Entity)
(defmutation trigger-error
"This mutation causes an unstructured error (just a map), but targets that value
to the field `:error-message` on the component that invokes it."
[_]
(remote [{:keys [ref] :as env}]
(m/with-target env (conj ref :error-message))))
(defmutation create-entity
"This mutation simply creates a new entity, but targets it to a specific location
(in this case the `:child` field of the invoking component)."
[{:keys [where?] :as params}]
(remote [{:keys [ast ref state] :as env}]
(let [path-to-target (conj ref :children)
; replacement cannot succeed if there is nothing present...turn those into appends
no-items? (empty? (get-in @state path-to-target))
where? (if (and no-items? (= :replace-first where?))
:append
where?)]
(cond-> (-> env
; always set what kind of thing is coming back
(m/returning Entity)
; strip the where?...it is for local use only (not server)
(m/with-params (dissoc params :where?)))
; Add the targeting...based on where?
(= :append where?) (m/with-target (targeting/append-to path-to-target)) ; where to put it
(= :prepend where?) (m/with-target (targeting/prepend-to path-to-target))
(= :replace-first where?) (m/with-target (targeting/replace-at (conj path-to-target 0)))))))
(defsc Entity [this {:keys [db/id entity/label]}]
{:ident [:entity/by-id :db/id]
:query [:db/id :entity/label]}
(dom/li {:key id} label))
(def ui-entity (comp/factory Entity {:keyfn :db/id}))
(defsc Item [this {:keys [db/id error-message children]}]
{:query [:db/id :error-message {:children (comp/get-query Entity)}]
:initial-state {:db/id :param/id :children []}
:ident [:item/by-id :db/id]}
(dom/div :.ui.container.segment #_{:style {:float "left"
:width "200px"
:margin "5px"
:border "1px solid black"}}
(dom/h4 (str "Item " id))
(dom/button {:onClick (fn [evt] (comp/transact! this [(trigger-error {})]))} "Trigger Error")
(dom/button {:onClick (fn [evt] (comp/transact! this [(create-entity {:where? :prepend :db/id (tempid/tempid)})]))} "Prepend one!")
(dom/button {:onClick (fn [evt] (comp/transact! this [(create-entity {:where? :append :db/id (tempid/tempid)})]))} "Append one!")
(dom/button {:onClick (fn [evt] (comp/transact! this [(create-entity {:where? :replace-first :db/id (tempid/tempid)})]))} "Replace first one!")
(when error-message
(dom/div
(dom/p "Error:")
(dom/pre (pr-str error-message))))
(dom/h6 "Children")
(dom/ul
(mapv ui-entity children))))
(def ui-item (comp/factory Item {:keyfn :db/id}))
(defsc Root [this {:keys [root/items]}]
{:query [{:root/items (comp/get-query Item)}]
:initial-state {:root/items [{:id 1} {:id 2} {:id 3}]}}
(dom/div
(mapv ui-item items)
(dom/br {:style {:clear "both"}})))12.4.4. Augmenting the Ring Response
The middleware that comes with Fulcro can modify the outgoing response in arbitrary ways. By default it sets the content type to transit and the body to the EDN your mutation(s) have returned (as a map keyed by mutation symbol). However, there are times when you need to modify something about the low-level response itself (such as adding a cookie).
You can ask Fulcro’s middleware to do additional changes to the Ring response by adding metadata to your mutation response.
The built-in function api-middleware/augment-response can be used to easily accomplish this.
(pc/defmutation f [env params]
{}
(api-middleware/augment-response
{:normal :response}
(fn [ring-response] modified-ring-response)))For example, if you are using the api-middleware/wrap-api and Ring Session middleware you could cause user information to be stored in a server session store simply by returning this from a query on user:
...
(let [user (find-user ...)]
(server/augment-response user (fn [resp] (update resp :session merge {:uid real-uid}))))|
Tip
|
This is not specific to fulcro, but be aware with Ring Sessions (wrap-session), updating the :session key in your augmented response will replace the session map. Your first augment-response function called will receive an empty map as input, so any parts of the session you want to retain will need to be copied from the request, or re-built. This is important as other parts of your app may use the session, for example, the anti-forgery token used by ring-anti-forgery.
|
12.4.5. Binary Return Values
Fulcro 3.0.8 and above has extended support for returning binary values from full-stack mutations. Prior versions
left this as an exercise to the reader, but it became evident that the existing support was easy enough
to extend. As such, the built-in HTTP remote has
been extended to allow you to indicate that you expect the server to return a non-EDN value, and that you’d like to
receive it in some alternate format. This is particularly useful if you have a mutation that does something like
generation of a PDF, where you want to be able to use that result immediately in the client code in your
mutation’s result-action.
Client Side Setup
Requirements:
-
You must use the
com.fulcrologic.fulcro.networking.http-remote -
You are responsible for making your server respond to a mutation in a way that will make it through the middleware as a non-EDN response.
-
Your mutation must indicate that the server’s return value is expected to be a different type.
-
You must define a
result-actionhandler in the mutation to directly deal with the result.
The Client-side Mutation
The mutation needs to define a result action and modify the remote return type, like this:
(ns app.model
(:require
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.fulcrologic.fulcro.networking.file-url :as file-url]))
(defmutation generate-pdf [params]
(result-action [{:keys [state result]}]
;; body will be a js ArrayBuffer. file-url ns has helpers to convert to data url
(swap! state assoc-in [:component :id :fileUrl]
(file-url/raw-response->file-url result "application/pdf")))
(remote [env]
(m/with-response-type env :array-buffer)))The file-url namespace includes a few utilities for creating a data URL out of such a network result, triggering
a browser save, etc. Please see the documentation in that ns for more details.
Progress
You can easily leverage the data load markers in your mutations to have the same story as load markers with these kinds of mutation (really, you can do it for any of them):
(defmutation generate-pdf [params]
(action [{:keys [app]}]
(df/set-load-marker! app ::pdf :loading))
(result-action [{:keys [app state result]}]
(df/remove-load-marker! app ::pdf)
...)
(remote [env]
(m/with-response-type env :array-buffer)))This will work identically to using the :marker option in df/load!. You can all use the progress update support
if you expect the response to be rather large.
12.4.6. Returning Binary Values from Server Mutations
The normal Fulcro middleware on the server will simply try to transit encode your response. You must insert additional middleware to circumvent this above (before) processing reaches this step. Here is an example of how you might do that:
First, invent a mutation return value that is easy to detect in the middleware:
;; SERVER side
(defmutation print [params]
(action [env]
(let [f (File. ...)]
{:file/mime-type "application/pdf"
:file/name "report.pdf"
:file/source f})))The idea is that a map with a :file/source key indicates that the mutation is trying to return a disk file to the client.
Then code up something in the middleware like this:
(defn file-response? [{:keys [body]}]
(when (map? body)
(let [values (vals body)
has-file? (some :file/source values)
multiple? (> (count values) 1)]
(when (and has-file? multiple?)
(throw (ex-info "A resolver is trying to respond with a file, but there were multiple elements in the request!" {:response body})))
has-file?)))
(defn wrap-file-response
"Middleware that converts responses that indicate the response is a file. "
{:arglists '([handler] [handler options])}
[handler]
(fn [request]
(let [response (handler request)]
(if (file-response? response)
(let [{:file/keys [source mime-type name]} (some-> response :body vals first)]
(if source
(-> (resp/response source)
(cond->
mime-type (resp/header "Content-Type" mime-type))
(resp/header "Content-Disposition" (str "attachment; filename=\"" (or name "file") "\""))
(resp/header "Last-Modified" (ring.util.time/format-date (dt/now))))
{:status 404}))
response))))and then place this new middleware between your API handler and the transit stuff:
(def middleware
(-> not-found-handler
(wrap-api "/api")
(wrap-file-response)
(server/wrap-transit-params {:opts {:handlers (:read transit-handlers)}})
(server/wrap-transit-response {:opts {:handlers (:write transit-handlers)}})
...))12.5. File Uploads (version 3.0.10+)
File uploads can, of course, be accomplished by simply submitting a POST to some server URI that you designate to handle such uploads; however, file uploads are usually related to some other server-side operation that needs to integrate that information into a database. Thus, it is desirable to be able to submit file uploads with mutations such that the files appear as parameters to the mutations, without having to resort to base64 encoding and all of the possible nightmares that can entail.
Fulcro’s com.fulcrologic.fulcro.networking.file-upload namespace includes client and server middleware that can
be used with the HTTP remote to add support for seamlessly associating file uploads with mutation parameters so
that the file upload processing can happen in the context of mutations.
It uses multipart MIME encoding in an HTTP POST, and uses low-level Javascript FormData. This means that large file uploads are only constrained by your network stack settings on the server (e.g. POST limits).
Features:
-
Each client mutation call can attach any number of binary objects (
js/File,js/ArrayBuffer, orjs/Blob). -
Any number of mutations in a single transaction can attach objects.
-
The transaction, if sent to the same remote, will be combined such that all uploads and mutation calls are encoded in a single HTTP POST.
-
The server side will receive the uploads in their parameters.
12.5.1. The Client
Setting up the client requires that you add additional middleware to an http remote. For example:
(ns app.application
(:require
[com.fulcrologic.fulcro.networking.http-remote :as net]
[com.fulcrologic.fulcro.networking.file-upload :as file-upload]
[com.fulcrologic.fulcro.application :as app]
[com.fulcrologic.fulcro.components :as comp]))
(def request-middleware
(->
(net/wrap-fulcro-request)
(file-upload/wrap-file-upload)))
(defonce SPA (app/fulcro-app
{:remotes {:remote (net/fulcro-http-remote
{:url "/api"
:request-middleware request-middleware})}}))This middleware watches for special mutation parameters that indicate file upload. You use helper
function from the file-upload namespace to create such mutations.
You can upload raw binary simply by using js/ArrayBuffer or js/Blob; however, most people will just want to submit
from a normal form input for files. Here is an example of how to do that:
;; An input to submit a tx which includes file uploads. `params` is just the normal mutation parameters.
(dom/input {:type "file"
:accept "image/jpeg,image/png"
;; Set `:multiple true` if you want to upload more than one at a time
:onChange (fn [evt]
(let [files (file-upload/evt->uploads evt)]
(comp/transact! this [(settings/save-settings (file-upload/attach-uploads params files))])))})You can, of course, give such a transaction an abort ID, since your user may want to cancel an accidental upload. See aborting a network request.
12.5.2. The Server
The server setup is similar: Add some middleware. The server must include Ring’s multipart-params middleware so
that the server can decode the multipart file submission. The middleware stack for the server will look something
like this:
(ns app.server-components.middleware
(:require
[com.fulcrologic.fulcro.networking.file-upload :as file-upload]
[com.fulcrologic.fulcro.server.api-middleware :refer [handle-api-request
wrap-transit-params
wrap-transit-response]]
...))
(def ^:private not-found-handler
(fn [req]
{:status 404
:headers {"Content-Type" "text/plain"}
:body "NOPE"}))
(defn wrap-api [handler uri]
(fn [request]
(if (= uri (:uri request))
(handle-api-request
(:transit-params request)
(fn [tx] (parser {:ring/request request} tx)))
(handler request))))
(def middleware
(-> not-found-handler
(wrap-api "/api")
(file-upload/wrap-mutation-file-uploads {})
wrap-transit-params
wrap-transit-response
(wrap-multipart-params)
...)))Notice that the file upload middleware is earlier in the execution chain than the API handler, but after the multipart decoding.
If you’ve set up everything correctly, then your mutations should automatically receive files as a namespaced parameter in the server mutation:
(ns app.model.settings
(:require
[com.wsscode.pathom.connect :as pc :refer [defresolver defmutation]]
[taoensso.timbre :as log]
[com.fulcrologic.fulcro.networking.file-upload :as file-upload]))
(defmutation save-settings [env {:account/keys [real-name]
::file-upload/keys [files]}]
{}
(log/info "Saving settings")
(log/info "New name:" real-name)
(log/info "New avatar:" (first files)))Notice that the ::file-upload/files key is plural, and will always be a sequence. This is to support multiple uploads
attached to a single mutation. If you only expect one file, then you can simply use first on it.
Each file in the sequence will be exactly what the multipart params middleware decodes. For example:
{:filename "me.jpg", :content-type "image/jpeg", :tempfile #object[java.io.File], :size 13210}|
Note
|
Both the client and server file-upload middleware allow you to give transit options so that your mutation parameters can be properly encoded/decoded if you normally extend the types allowed over transit. |
12.6. Additional Mutation Topics
12.6.1. Ownership and Mutations
A common case that causes some confusion is working with mutations that affect the ownership of some child in the UI. In these cases, the parent can be seen as a UI component in control of the children (it is responsible for telling them to render). In such cases it is usually better to reason about the management logic (i.e. deleting, reordering, etc) from the parent; however, it is commonly the case the you want the child to render some controls, such as a delete button. Thus, the control that wants to modify the state (the delete button on the item) is not local to the component that will need to refresh (the parent’s list).
The solution is simple: create a callback in the parent that can run the delete transaction and pass it through as a computed value.
(ns book.demos.parent-child-ownership-relations
(:require
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.algorithms.merge :as merge]
[taoensso.timbre :as log]))
; Not using an atom, so use a tree for app state (will auto-normalize via ident functions)
(def initial-state {:ui/react-key "abc"
:main-list {:list/id 1
:list/name "My List"
:list/items [{:item/id 1 :item/label "A"}
{:item/id 2 :item/label "B"}]}})
(m/defmutation delete-item
"Mutation: Delete an item from a list"
[{:keys [list-id id]}]
(action [{:keys [state]}]
(log/info "Deleting item" id "from list" list-id)
(swap! state
(fn [s]
(-> s
(update :items dissoc id)
(merge/remove-ident* [:items id] [:lists list-id :list/items]))))))
(defsc Item [this
{:keys [item/id item/label] :as props}
{:keys [on-delete] :as computed}] ;; (1)
{:initial-state (fn [{:keys [id label]}] {:item/id id :item/label label})
:query [:item/id :item/label]
:ident [:items :item/id]}
(dom/li label (dom/button {:onClick #(on-delete id)} "X")))
(def ui-list-item (comp/factory Item {:keyfn :item/id}))
(defsc ItemList [this {:list/keys [id name items]}]
{:initial-state (fn [p] {:list/id 1
:list/name "List 1"
:list/items [(comp/get-initial-state Item {:id 1 :label "A"})
(comp/get-initial-state Item {:id 2 :label "B"})]})
:query [:list/id :list/name {:list/items (comp/get-query Item)}]
:ident [:lists :list/id]}
(let [delete-item (fn [item-id] (comp/transact! this [(delete-item {:list-id id :id item-id})])) ;; (2)
item-props (fn [i] (comp/computed i {:on-delete delete-item}))]
(dom/div
(dom/h4 name)
(dom/ul
(mapv #(ui-list-item (item-props %)) items)))))
(def ui-list (comp/factory ItemList))
(defsc Root [this {:keys [main-list]}]
{:initial-state (fn [p] {:main-list (comp/get-initial-state ItemList {})})
:query [{:main-list (comp/get-query ItemList)}]}
(dom/div (ui-list main-list)))-
The item uses the computed callback
-
The list creates a lambda that closes over the list id
12.6.2. Mutations Without Quoting or Circular References
There are times when you need to use a component in a mutation (for a merge, for example), but the component is also using mutations. You can easily end up with circular references in your code which Clojure does not allow. Of course since mutations are just data you can just quote the fully-qualified mutation name in the UI, but that is inconvenient because the names get rather long.
(comp/transact! this '[(some.namespace.that.is.long/f params)])and it also leads to another problem:
Did you notice the error in that last expression? params wasn’t un-quoted!:
but this won’t work:
(comp/transact! this '[(some.namespace.that.is.long/f ~params)])because we’re not using syntax quoting. Changing the quote style fixes it:
(comp/transact! this `[(some.namespace.that.is.long/f ~params)])or you can build the list manually and use literal quote:
(comp/transact! this [(list 'some.namespace.that.is.long/f params)])Declare Your Mutations Elsewhere
The defmutation macro creates a version of itself that is actually a mutation declaration.
You can use that same feature to put declarations of your mutations in a namespace different from the mutation itself.
Thus, you can code up a mutation "interface" namespace that won’t generate circular references with the UI:
(ns my-mutations
(:require [com.fulcrologic.fulcro.mutations :as m :refer [declare-mutation]])
(declare-mutation boo 'real-ns.of.mutations/boo)and now you can use this new boo in place of the real one without quoting:
(ns real-ui
(:require
[my-mutations :refer [boo]]
...))
...
(comp/transact! this [(boo {:a "hello" :b 22})])There’s really not much to the magic. boo becomes a function-like thing that just returns a list with the proper symbols and data in it:
(boo {:a "hello"}) => '(real-ns.of.mutations/boo {:a "hello"})Additionally, since your real mutation is in a whole different namespace that is never required by the UI or the interface you are now free to require the UI in the mutation namespace if you need it for merges and other component-centric mutations concerns without causing circular references.
This requires an extra namespace and a little extra declaration work, but cleans up the UI and ns requires quite well.
Use the Component Registry
There is also a global component registry that can help with this problem. Any component that is (transitively) required in your application will appear in the registry. This makes it possible to track component classes in app state (since the name is serializable) and also look up a component class for merges from within mutations:
(defmutation f [params]
(action [{:keys [state]}]
(let [todo-list-class (comp/registry-key->class :com.company.app/TodoList)]
(swap! state merge/merge-component todo-list-class {:list/id ...}))))12.6.3. IDE Integration
The syntax of defmutation and declare-mutation are both intentionally "shaped" like defn and def so that you can tell your IDE how to resolve them.
In IntelliJ, you can do this by clicking on the macro name (e.g. defmutation) and waiting for the light bulb.
Then select "Resolve as" and then defn for defmutation and def for declare-mutation.
You may not need to do this for defmutation, as IntelliJ does have some predefined resolutions for Fulcro built-in.
12.6.4. Recommendations About Writing Mutations
Mutations themselves are meant to be abstractions across the entire stack; however, the optimistic side of them are really just functions on your application state. Components have nice clean abstractions, and you will often benefit from writing low-level functions that represent the general operations on a component’s data. As you move towards higher-level abstractions you’ll want to compose those lower-level functions. As such, it pays to think a little about how this will look over time.
If you write the actual logic of a mutation into a defmutation, then composition is difficult because mutations are not functions, and wont' compose as functions.
To maximize code reuse, local reasoning, and general readability it pays to think about your mutations in the following manner:
-
A mutation is a function that changes the state of the application:
state → state' -
Within a mutation, you are essentially doing operations to a graph, which means you have operations that work on some node in the graph:
node → node'. These operations may modify a scalar or an edge to another node.
Mutation "Helpers"
Fulcro adopts the general notation of suffixing functions with * when they operate on a normalized state map (not atom).
These functions are referred to as "mutation helpers" because they can easily be used with swap! against the mutation atom:
(swap! state targeting/integrate-ident* ...)and composed together as well:
(defn create-person*
"Create a person entity and add it to the normalized database in state-map."
[state-map id name]
(assoc-in state-map [:person/id id] {:person/id id :person/name name}))
(defmutation create-friend
"Mutation: create a new person and add them to the friends list"
[{:person/keys [id name]}]
(action [{:keys [state]}]
(swap! state
(fn [s]
(-> s
(create-person* id name)
(targeting/integrate-ident* [:person/id id] :append [:list/id :friends :list/people])))))))and your mutations become a thing of beauty!
Of course, this can also be overkill.
It is true that it is often handy to be able to compose many db operations together into one abstract mutation, but don’t forget that more that one mutation can be triggered by a single call to transact!:
(comp/transact! this `[(route-to {:handler :show-friend :route-params {:person-id ~target-id}})
(add-friend {:source-person-id ~my-id :target-id ~target-id})])You’ll want to balance your mutations just like you do any other library of code: so that reuse and clarity are maximized. In the case of mutations the deciding factor is often how you want to deal with remote mutations.
12.7. Advanced Mutation Topics
This section covers a number of additional mutation techniques that arise in more advanced situations.
A lot of these things are handled for you with normal full-stack operations, so you might want to skip this section until you’re comfortable with that material.
12.7.1. Using the Multimethod Directly
The multi-method approach just requires you to return a map containing all of the things that should be done.
This looks somewhat similar to defmutation in structure:
(defmethod com.fulcrologic.fulcro.mutations/mutate `mutation-symbol [params]
{:action (fn [env] ...)
:result-action (fn [env] ...)
:remote (fn [env] true)})The biggest trick to this technique is the :result-action key.
Any remote results will be passed, unprocessed, to this handler and only this handler.
The defmutation macro uses a default implementation of this action that merges results, checks for errors, calls other handlers, etc.
If you make a multimethod, then you will not get any of that built-in behavior.
If all you want to do is change the result action, then look into setting the :default-result-action option when you create your application.
If you would like your multimethod mutation to work like defmutation then you should do the following in your
:result-action:
(defmethod m/mutate `mutation-symbol [params]
{...
:result-action (fn [env]
(when-let [default-action (lookup/app-algorithm (:app env) :default-result-action)]
(default-action env)))
...
})12.7.2. Using app Directly
When you set up your application it is best to save it in a global place so that you can use it outside of the normal flow of things (e.g. a websocket push notification):
(comp/transact! app ...)12.7.3. Swapping on the State Atom?
You can technically tweak the database atom in the application directly, but that side-steps all of the internals of Fulcro including UI refresh.
It can be handy in limited cases, but generally we recommend you use
transact!.
|
Note
|
Fulcro 3 does not watch the state atom (though Inspect does). |
(let [{::app/keys [state-atom]} app]
(swap! state-atom ...))If you do such a change then you are responsible for triggering a UI refresh (if you want one).
You can schedule a render by calling (app/schedule-render! app).
12.7.4. Leveraging tree→db and db→tree
It is sometimes useful to convert a bit of the database to a tree for manipulation in a mutation, or the other way around. Remember that these utility functions exist as part of the toolbox.
12.7.5. Using integrate-ident
When in a mutation you very often need to place an ident in various spots in your graph database.
The helper function targeting/integrate-ident* can by used from within mutations to help you do this.
It accepts any number of named parameters that specify operations to do with a given ident:
(swap! state
(fn [s]
(-> s
(do-some-op)
(integrate-ident* the-ident
:append [:table id :field]
:prepend [:other id :field]))))This function checks for the existence of the given ident in the target list, and will refuse to add it if it is already there.
The :replace option can be used on a to-one or to-many relation.
When replacing on a to-many, you use an index in the target path (e.g. [:table id :field 2] would replace the third element in a to-many :field)
12.7.6. Creating Components Just For Their Queries
If your UI doesn’t have a query that is convenient for sending to the server (or for working on tree data like this), then it is considered perfectly fine to generate components just for their queries (no render). This is often quite useful, especially in the context of pre-loading data that gets placed on the UI in a completely different form (e.g. the UI queries don’t match what you’d like to ask the server).
(defsc SubQuery [t p]
{:ident [:sub/id :id]
:query [:id :data]})
(defsc TopQuery [t p]
{:ident [:top/id :id]
:query [:id {:subs (comp/get-query SubQuery)}]})(ns book.tree-to-db
(:require
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[devcards.util.edn-renderer :refer [html-edn]]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.fulcrologic.fulcro.algorithms.normalize :as fnorm]))
(defsc SubQuery [t p]
{:ident [:sub/by-id :id]
:query [:id :data]})
(defsc TopQuery [t p]
{:ident [:top/by-id :id]
:query [:id {:subs (comp/get-query SubQuery)}]})
(defmutation normalize-from-to-result [ignored-params]
(action [{:keys [state]}]
(let [result (fnorm/tree->db TopQuery (:from @state) true)]
(swap! state assoc :result result))))
(defmutation reset [ignored-params] (action [{:keys [state]}] (swap! state dissoc :result)))
(defsc Root [this {:keys [from result]}]
{:query [:from :result]
:initial-state (fn [params]
; some data we're just shoving into the database from root...***not normalized***
{:from {:id :top-1 :subs [{:id :sub-1 :data 1} {:id :sub-2 :data 2}]}})}
(dom/div
(dom/div
(dom/h4 "Pretend Incoming Tree")
(html-edn from))
(dom/div
(dom/h4 "Normalized Result (click below to normalize)")
(when result
(html-edn result)))
(dom/button {:onClick (fn [] (comp/transact! this [(normalize-from-to-result {})]))} "Normalized (Run tree->db)")
(dom/button {:onClick (fn [] (comp/transact! this [(reset {})]))} "Clear Result")))of course, you can see that you’re still going to need to merge the database table contents into your main app state and carefully integrate the other bits as well.
12.7.7. Using com.fulcrologic.fulcro.components/merge!
Fulcro includes a function that takes care of the rest of these bits for you.
It requires the app or a component.
The arguments are similar to tree→db:
(merge/merge! app ROOT-data ROOT-query)The same things apply as tree→db (idents especially), however, the result of the transform will make its way into the
app state.
IMPORTANT: The biggest challenge with using this function is that it requires the data and query to be structured from the ROOT of the database! That is sometimes perfectly fine, but our next section talks about a helper that might be easier to use.
12.7.8. Using merge/merge-component!
There is a common special case that comes up often: You want to merge something that is in the context of some particular UI component.
(merge/merge-component! app ComponentClass ComponentData)Think of this case as: I have some data for a given component (which MUST have an ident). I want to merge into that component’s entry in a table, but I want to make sure the recursive tree of data also gets normalized properly.
merge-component! also integrates the functionality of targeting/integrate-ident* to pepper the ident of the merged entity
throughout your app database, and can often serve as a total one-stop shop for merging data that is coming from some external source.
This first argument can be an application or component.
Merge-component! Demo
In the card below the button simulates some external event that has brought in data that we’d like to merge (a newly arrived counter entity):
{ :counter/id 5 :counter/n 66 }We’ll want to:
-
Add the counter to the counter’s table (which is not even present because we have none in our initial app state)
-
Add the ident of the counter to the UI panel so its UI shows up
(defsc Counter [this {:keys [counter/id counter/n] :as props} {:keys [onClick] :as computed}]
{:query [:counter/id :counter/n]
:ident [:counter/id :counter/id]}
...
(defn add-counter
"Merge the given counter data into app state and append it to our list of counters"
[app counter]
(merge/merge-component! app Counter counter
:append [:panels/by-kw :counter :counters]))
...
(defsc Root ...
(let [app (comp/any->app this)] ; another way to get to the app
(dom/button {:onClick #(add-counter app {:counter/id 4 :counter/n 22})} "Simulate Data Import")
...Here is the full running example with source:
(ns book.merge-component
(:require
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.fulcrologic.fulcro.data-fetch :as df]
[com.fulcrologic.fulcro.algorithms.merge :as merge]))
(defsc Counter [this {:keys [counter/id counter/n] :as props} {:keys [onClick] :as computed}]
{:query [:counter/id :counter/n]
:ident [:counter/by-id :counter/id]}
(dom/div :.counter
(dom/span :.counter-label
(str "Current count for counter " id ": "))
(dom/span :.counter-value n)
(dom/button {:onClick #(onClick id)} "Increment")))
(def ui-counter (comp/factory Counter {:keyfn :counter/id}))
; the * suffix is just a notation to indicate an implementation of something..in this case the guts of a mutation
(defn increment-counter*
"Increment a counter with ID counter-id in a Fulcro database."
[database counter-id]
(update-in database [:counter/by-id counter-id :counter/n] inc))
(defmutation increment-counter [{:keys [id] :as params}]
; The local thing to do
(action [{:keys [state] :as env}]
(swap! state increment-counter* id))
; The remote thing to do. True means "the same (abstract) thing". False (or omitting it) means "nothing"
(remote [env] true))
(defsc CounterPanel [this {:keys [counters]}]
{:initial-state (fn [params] {:counters []})
:query [{:counters (comp/get-query Counter)}]
:ident (fn [] [:panels/by-kw :counter])}
(let [click-callback (fn [id] (comp/transact! this
[(increment-counter {:id id}) :counter/by-id]))]
(dom/div
; embedded style: kind of silly in a real app, but doable
(dom/style ".counter { width: 400px; padding-bottom: 20px; }
button { margin-left: 10px; }")
; computed lets us pass calculated data to our component's 3rd argument. It has to be
; combined into a single argument or the factory would not be React-compatible (not would it be able to handle
; children).
(mapv #(ui-counter (comp/computed % {:onClick click-callback})) counters))))
(def ui-counter-panel (comp/factory CounterPanel))
(defonce timer-id (atom 0))
(declare sample-of-counter-app-with-merge-component-fulcro-app)
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; The code of interest...
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn add-counter
"NOTE: A function callable from anywhere as long as you have a reconciler..."
[app counter]
(merge/merge-component! app Counter counter
:append [:panels/by-kw :counter :counters]))
(defsc Root [this {:keys [panel]}]
{:query [{:panel (comp/get-query CounterPanel)}]
:initial-state {:panel {}}}
(dom/div {:style {:border "1px solid black"}}
; NOTE: A plain function...pretend this is happening outside of the UI...we're doing it here so we can embed it in the book...
(dom/button {:onClick #(add-counter (comp/any->app this) {:counter/id 4 :counter/n 22})} "Simulate Data Import")
(dom/hr)
"Counters:"
(ui-counter-panel panel)))13. Loads
Most of your server API should be written with something like Pathom Connect. There are also ways to adapt to GraphQL servers, REST APIs, etc. This chapter will be strictly using a Pathom parser to supply data from the servers according to the following database schema and data:
13.1. Load Demo Database
(ns book.database
(:require
[cljs.spec.alpha :as s]
[datascript.core :as d]
[com.wsscode.pathom.connect :as pc]
[com.wsscode.pathom.core :as p]
[cljs.core.async :as async]
clojure.pprint
[taoensso.timbre :as log]))
(def schema {:person/id {:db/unique :db.unique/identity}
:person/spouse {:db/cardinality :db.cardinality/one}
:person/children {:db/cardinality :db.cardinality/many}
:person/addresses {:db/cardinality :db.cardinality/many}
:person/phone-numbers {:db/cardinality :db.cardinality/many}})
(defonce connection (d/create-conn schema))
(defn db [connection] (deref connection))
(defn seed-database []
(d/transact! connection [{:db/id 1
:person/id 1
:person/age 45
:person/name "Sally"
:person/spouse 2
:person/addresses #{100}
:person/phone-numbers #{10 11}
:person/children #{4 3}}
{:db/id 10
:phone/id 10
:phone/number "812-555-1212"
:phone/type :work}
{:db/id 11
:phone/id 11
:phone/number "502-555-1212"
:phone/type :home}
{:db/id 12
:phone/id 12
:phone/number "503-555-1212"
:phone/type :work}
{:db/id 2
:person/id 2
:person/name "Tom"
:person/age 48
:person/phone-numbers #{11 12}
:person/addresses #{100}
:person/spouse 1
:person/children #{3 4}}
{:db/id 3
:person/id 3
:person/age 17
:person/addresses #{100}
:person/name "Amy"}
{:db/id 4
:person/id 4
:person/age 25
:person/addresses #{100}
:person/name "Billy"
:person/children #{5}}
{:db/id 5
:person/addresses #{100}
:person/id 5
:person/age 1
:person/name "Billy Jr."}
{:db/id 100
:address/id 100
:address/street "101 Main St"
:address/city "Nowhere"
:address/state "GA"
:address/postal-code "99999"}]))
(pc/defresolver person-resolver [{:keys [connection]} {:person/keys [id]}]
{::pc/input #{:person/id}
::pc/output [:person/name
:person/age
{:person/addresses [:address/id]}
{:person/phone-numbers [:phone/id]}
{:person/spouse [:person/id]}
{:person/children [:person/id]}]}
(d/pull (db connection)
[:person/name
:person/age
{:person/addresses [:address/id]}
{:person/phone-numbers [:phone/id]}
{:person/spouse [:person/id]}
{:person/children [:person/id]}]
id))
(pc/defresolver all-people-resolver [{:keys [connection]} _]
{::pc/output [{:all-people [:person/id]}]}
{:all-people (mapv
(fn [id] {:person/id id})
(d/q '[:find [?e ...]
:where
[?e :person/id]]
(db connection)))})
(pc/defresolver address-resolver [{::p/keys [parent-query]
:keys [connection] :as env} {:address/keys [id]}]
{::pc/input #{:address/id}
::pc/output [:address/street :address/state :address/city :address/postal-code]}
(d/pull (db connection) parent-query id))
(pc/defresolver phone-resolver [{::p/keys [parent-query]
:keys [connection] :as env} {:phone/keys [id]}]
{::pc/input #{:phone/id}
::pc/output [:phone/number :phone/type]}
(d/pull (db connection) parent-query id))
;; Allow a person ID to resolve to (any) one of their addresses
(pc/defresolver default-address-resolver [{:keys [connection]} {:person/keys [id]}]
{::pc/input #{:person/id}
::pc/output [:address/id]}
(let [address-id (d/q '[:find ?a .
:in $ ?pid
:where
[?pid :person/addresses ?addr]
[?addr :address/id ?a]]
(db connection) id)]
(when address-id
{:address/id address-id})))
;; Resolve :server/time-ms anywhere in a query. Allows us to timestamp a result.
(pc/defresolver time-resolver [_ _]
{::pc/output [:server/time-ms]}
{:server/time-ms (inst-ms (js/Date.))})
(def general-resolvers [phone-resolver address-resolver person-resolver
default-address-resolver
all-people-resolver time-resolver])This database and small set of resolvers can resolve quite complex queries:
(parse
[{:all-people [:person/name
:person/age
{:person/phone-numbers [:phone/number :phone/type]}
{:person/spouse [:person/name]}
{:person/children [:person/name {:person/spouse [:person/name]}]}
{:person/addresses [:address/street]}
{:person/addresses [:address/id :address/street :address/state
:address/city :address/postal-code]}]}])
;; result
{:all-people
[{:person/spouse {:person/name "Tom"},
:person/age 45,
:person/name "Sally",
:person/children [{:person/name "Amy"} {:person/name "Billy"}],
:person/addresses [{:address/street "101 Main St"}],
:person/phone-numbers
[{:phone/type :work, :phone/number "812-555-1212"}
{:phone/type :home, :phone/number "502-555-1212"}]}
{:person/spouse {:person/name "Sally"},
:person/age 48,
:person/name "Tom",
:person/children [{:person/name "Amy"} {:person/name "Billy"}],
:person/addresses [{:address/street "101 Main St"}],
:person/phone-numbers
[{:phone/type :home, :phone/number "502-555-1212"}
{:phone/type :work, :phone/number "503-555-1212"}]}
{:person/age 17,
:person/name "Amy",
:person/addresses [{:address/street "101 Main St"}]}
{:person/age 25,
:person/name "Billy",
:person/children [{:person/name "Billy Jr."}],
:person/addresses [{:address/street "101 Main St"}]}
{:person/age 1,
:person/name "Billy Jr.",
:person/addresses [{:address/street "101 Main St"}]}]}13.1.1. Playing with the Database
If you’re running the live book with Inspect installed you can leverage a really nice feature of that tool: When you use Pathom as your parser it is able to send an autocomplete index to your tools, which allows you play with the parser on your server to see what it can do!
Try the following:
-
Go to the Loading Data Basics example.
-
Open Fulcro Inspect
-
Focus the inspector on that example (Use the "Focus Inspector" button).
-
In Inspect, choose the Query sub-tab.
-
In the while bar just below the tabs there is a round grey button and a "Run query". Button. Press the grey button. This will load the indexes from the Pathom server. The button should turn green.
-
Place your cursor in the left half of the query tool. This is where you type in queries. Autocomplete should be working (try typing
:inside of the vector)!
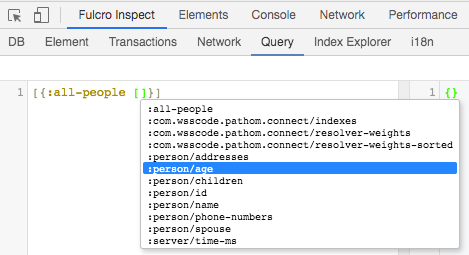
If you write a legal query and press "Run query", it will contact the server and give you the result.
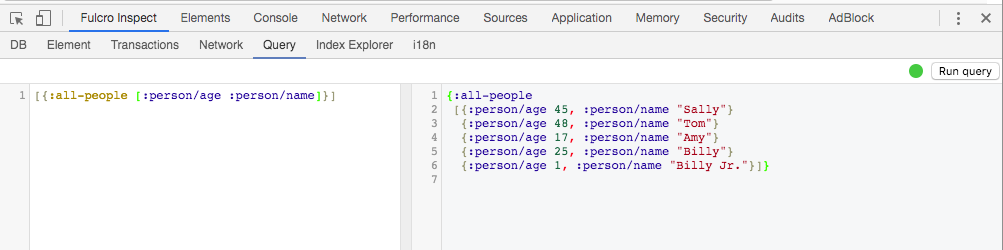
Some quick keyboard shortcuts (OSX):
-
CMD-J: Turn the keyword under the cursor into a query join (wrap it in a map with a subquery vector). -
CMD-ENTER: Run the query
13.2. The Data Fetch API: load!
Let’s say we want to load all of our friends from the server.
A query has to be rooted somewhere, so we’ve invented a root-level keyword, :all-friends that can query the database for every entity that has a :person/id.
In Fulcro component queries that would look like this:
[{:all-friends (comp/get-query Person)}]What we’d like to see then from the server is a return value with the shape of the query:
{ :all-friends [ {:person/id 1 ...} {:person/id 2 ...} ...] }If we combined that query with the tree result and were to manually call merge/merge! then we’d end up with this in our client database:
{ :all-friends [ [:person/id 1] [:person/id 2] ...]
:person/id { 1 { :person/id 1 ...}
2 { :person/id 2 ...}
...}}The data fetch API has a simple function for this that will do all of these together (query derivation, server interaction, and merge):
(ns my-thing
(:require [com.fulcrologic.fulcro.data-fetch :as df]))
...
(df/load! comp-or-app :all-friends Person)The first argument is the component (i.e. this) or the application.
The next argument is a keyword or an ident, and the next argument defines the type of thing (to-one or many) that will be the next "level" of the query.
An important thing to notice is that load! can be thought of as a function that loads normalized data into the root node of your graph (:all-friends in this scenario would appear in your root node).
This is sometimes what you want, but often you really want that data loaded at some other spot in your graph.
13.2.1. Basic Targeting
When you want the data from load to appear at some other edge in your database you can simply tell load the normalized path (which is rarely more than 3 elements) to the location you’d like to place the result. For example, if you had list components with IDs, then this:
(df/load! comp-or-app :all-friends Person {:target [:list/id :people :list/people]})might load two people (with IDs 1 and 2) and would result in your database containing:
{:person/id {1 {...} 2 {...}} ; normalized people
:list/id {:people {:list/people [[:person/id 1] [:person/id 2]]13.2.2. Ident-based Loading
You can also simply load (and normalize the sub-tree) a given entity with:
(df/load! this [:person/id 1] Person)which will simply update the entries in the tables, but won’t add any edges to the graph. You can use targeting with these loads in order to that ident in the graph at arbitrary locations:
(df/load! this [:person/id 1] Person {:target [:current-user]})which will result in something like this:
{:person/id {1 {:person/id 1 :person/name "Joe"}}
:current-user [:person/id 1]}13.2.3. A Loading Example
The two general loading techniques are shown in the following example which uses our database described in Load Demo Database. You should Focus the Inspect tool on this example’s database so you can see what is happening (via the DB, Transaction, and Network sub-tabs).
Pressing the "Load People" button will load all of the people.
Once they are loaded you can refresh any one of them.
A special resolver on the server for :server/time-ms allows us to timestamp the entities with the server’s time so we can see the refresh taking effect.
(ns book.demos.loading-data-basics
(:require
[com.fulcrologic.fulcro.data-fetch :as df]
[book.demos.util :refer [now]]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.data-fetch :as df]))
(defsc Person [this {:person/keys [id name age] :server/keys [time-ms] :as props}]
{:query [:person/id :person/name :person/age :server/time-ms]
:ident :person/id}
(dom/li
(str name " (last queried at " time-ms ")")
(dom/button {:onClick (fn []
; Load relative to an ident (of this component).
; This will refresh the entity in the db. The helper function
; (df/refresh! this) is identical to this, but shorter to write.
(df/load! this (comp/get-ident this) Person))} "Update")))
(def ui-person (comp/factory Person {:keyfn :db/id}))
(defsc People [this {:list/keys [people]}]
{:initial-state {:list/id :param/id :list/people []}
:query [:list/id {:list/people (comp/get-query Person)}]
:ident :list/id}
(dom/ul
(mapv ui-person people)))
(def ui-people (comp/factory People {:keyfn :people/kind}))
(defsc Root [this {:root/keys [list]}]
{:initial-state (fn [_] {:root/list (comp/get-initial-state People {:id :people})})
:query [{:root/list (comp/get-query People)}]}
(dom/div
(dom/button
{:onClick (fn []
(df/load! this :all-people Person {:target [:list/id :people :list/people]}))}
"Load People")
(dom/h4 "People in Database")
(ui-people list)))13.2.4. Targeting Loads
We covered a little bit about targeting in Basic Targeting. It turns out that the targeting system gives you a bit more power than what we showed there. This section covers targeting in a bit more detail.
Simple Targeting
The simplest targeting is to put a "root" result somewhere besides root, or to add an additional ident (edge) when you’ve loaded something by ident:
(df/load comp :all-people Person {:target [:list/id :people :list/people]})So, the server will still see the well-known query for :all-friends, but your local UI graph will end up seeing the results in the list on the friends screen.
This is equivalent to the full replacement of the edge. Anything that existed at the target path will be overridden by an ident (to-one) or a vector of idents (to-many). Remember that the cardinality is determined based on the actual result (not some kind of client-side schema).
Advanced Targets
You can also ask the target parameter to modify to-many edges instead of replacing them. For example, say you were loading one new person, and wanted to append it to the current list:
(df/load comp [:person/id 42] Person {:target (targeting/append-to [:list/id :people :list/people])})The append-to function augments the target to indicate that the incoming items (which will be normalized) should have their idents appended onto the to-many edge found at the given location.
|
Note
|
append-to will not create duplicates in the list of idents.
|
There is also prepend-to.
You may also ask the targeting system to place the result(s) at more than one place in your graph.
You do this with the multiple-targets wrapper:
(df/load comp :best-friend Person {:target (targeting/multiple-targets
(targeting/append-to [:screens/by-type :friends :friends/list])})
[:other-spot]
(targeting/prepend-to [:screens/by-type :summary :friends]))})Note that multiple-targets can use plain target vectors (replacement) or any of the special wrappers.
13.2.5. Other Load Options
Loads allow a number of additional arguments. Many of these are discussed in more detail in later sections:
:post-mutation and :post-mutation-params
|
A mutation to run once the load is complete, and the parameters to pass to it. |
:remote
|
The name of the remote you want to load from. |
:parallel
|
Boolean. Defaults to false. When true, bypasses the sequential network queue. Allows multiple loads to run at once, but causes you to lose any guarantees about ordering since the server might complete them out-of-order. |
:fallback
|
A mutation to run if your configured |
:focus
|
A subquery to filter from your component query. Covered in Incremental Loading. |
:without
|
A set of keywords to elide from the query. Covered in Incremental Loading. |
:update-query
|
A function that will take the component original query and should return a query that will be sent to the remote |
:params
|
A map. If supplied the params will appear as the params of the query on the server. |
See the docstring of the load! function for more.
Parallel vs. Sequential Loading
The :parallel option of load bypasses the normal network sequential queue.
Below is a simple live example that shows off the difference between regular loads and those marked parallel.
In order to see the effect increase your server latency to a large value.
Normally, Fulcro runs separate event-based loads in sequence, ensuring that your reasoning can be synchronous; however, for loads that might take some time to complete, and for which you can guarantee order of completion doesn’t matter, you can specify an option on load (:parallel true) that allows them to proceed in parallel.
Pressing the sequential buttons on all three (in any order) will take at least 3x your server latency to complete from the time you click the first one (since each will run after the other is complete). If you rapidly click the parallel buttons, then the loads will not be sequenced and you will see them all complete in roughly 1x your server latency (from the time you click the last one).
(ns book.demos.parallel-vs-sequential-loading
(:require
[com.fulcrologic.fulcro.data-fetch :as df]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.wsscode.pathom.connect :as pc]
[taoensso.timbre :as log]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(pc/defresolver long-query-resolver [_ _]
{::pc/output [:background/long-query]}
{:background/long-query 42})
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defsc Child [this {:keys [id name background/long-query] :as props}]
{:query (fn [] [:id :name :background/long-query [df/marker-table '_]])
:ident [:background.child/by-id :id]}
(let [status (get-in props [df/marker-table [:fetching id]])]
(dom/div {:style {:display "inline" :float "left" :width "200px"}}
(dom/button {:onClick #(df/load-field! this :background/long-query {:parallel true
:marker [:fetching id]})} "Load stuff parallel")
(dom/button {:onClick #(df/load-field! this :background/long-query {:marker [:fetching id]})} "Load stuff sequential")
(dom/div
name
(if (df/loading? status)
(dom/span "Loading...")
(dom/span long-query))))))
(def ui-child (comp/factory Child {:keyfn :id}))
(defsc Root [this {:keys [children] :as props}]
; cheating a little...raw props used for child, instead of embedding them there.
{:initial-state (fn [params] {:children [{:id 1 :name "A"} {:id 2 :name "B"} {:id 3 :name "C"}]})
:query [{:children (comp/get-query Child)}]}
(dom/div
(mapv ui-child children)
(dom/br {:style {:clear "both"}}) (dom/br)))13.3. Tracking Specific Loads
It is very often the case that you might have a number of loads running to populate different parts of your UI all at once. In this case it is quite useful to have some kind of load-specific marker that you can use to show that activity. Fulcro provides a pre-built facility in the load API that can put markers into a normalized table, allowing you to query for them in the components that need to show the activity of interest.
Load markers are normalized into a well-known table via an ID that you choose. You can use just about any value (except a boolean) for the id. This has the following behavior:
-
Load markers are placed the top-level table (the var
com.fulcrologic.fulcro.data-fetch/marker-tableholds the table name), using your marker value as their ID. -
You can explicitly query for them using an ident-based join.
13.3.1. Working with Normalized Load Markers
The steps are rather simple:
Include the :marker parameter with load, and add a query for the load marker on a UI component.
(defsc SomeComponent [this props]
{:query [:data :prop2 :other [df/marker-table :marker-id]]} ; an ident in queries pulls in an entire entity
;; important: `get`, NOT `get-in`.
(let [marker (get props [df/marker-table :marker-id])]
...)))
...
(df/load this :key Item {:marker :marker-id})The data fetch load marker will be missing if no loading is in progress. You can use the following functions to detect what state the load is in:
-
(df/loading? marker)- Returns true if the item is still in progress (of any kind) -
(df/failed? marker)- Returns true if the item failed, according to your definition of an error.
The marker will disappear from the table when network activity completes successfully, but will remain in place on failures.
The rendering is up to you, but that is really all there is to it.
Notes on Marker IDs
Marker IDs can be any value that supports equivalence, including data structures. You can also pull the entire load marker table into a component with a link query:
(defsc Component [_ props]
{:query [... [df/marker-table '_] ...]}
(let [table (get props df/marker-table)
marker (get table id-of-marker)]
...))Beware, though, that querying for the entire marker table will tend to "over render" the given component (every time any load marker changes).
13.4. Initializing Loaded Items
There are two main ways to augment the items you load. One is using post-mutations, and the other is Pre-merge.
13.4.1. Post Mutations – Morphing Loaded Data
The targeting system that we discussed in the prior section is great for cases where your data-driven query gets you exactly what you need for the UI. In fact, since you can process the query on the server it is entirely possible that load with targeting is all you’ll ever need; however, from a practical perspective it may turn out that you’ve got a server that can easily understand certain shapes of data-driven queries, but not others.
For example, say you were pulling a list of items from a database. It might be trivial to pull that graph of data from the server from the perspective of a list of items, but let’s say that each item had a category. Perhaps you’d like to group the items by category in the UI.
The data-driven way to handle that is to make the server understand the UI query that has them grouped by category; however, that may not be possible if you’re using something less powerful than Pathom.
Another way of handling this is to let the client morph the incoming data into a shape that makes more sense to the UI.

We all understand doing these kinds of transforms. It’s just data manipulation. So, you may find this has some distinct advantages:
-
Simple query to the server (only have to write one query handler) that is a natural fit for the database there.
-
Simple layout in resulting UI database (normalized into tables and a graph)
-
Straightforward data transform into what we want to show
Using defsc For Server Queries
If you are taking the approach we’ve described then you have a problem:
None of your UI matches the query that we need for the server!
It turns out that it is perfectly legal (and recommended) to use defsc to define a graph query (and normalization) for something like this that doesn’t exactly exist on your UI.
Simply code your (nested) queries using defsc, and skip writing the body:
(defsc ItemQuery [this props]
{:query [:db/id :item/name {:item/category (comp/get-query CategoryQuery)}]
:ident [:items/id :db/id]})and now you can load (and normalize) the data that the server knows how to provide, and then use a post-mutation to re-shape it to suit your needs:
(df/load! this :all-items ItemQuery {:post-mutation `group-items})Live Demo of Post Mutations
The example below simulates post mutations to show how a load of simple data could be morphed into something that the UI wants to display. In this case we’re pretending that the load has brought in a number of items (as a collection) and normalized it, but we’d prefer to show the items organized by category.
You should interact with it and view the database in Inspect to A/B compare the before/after state.
(ns book.server.morphing-example
(:require
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[book.macros :refer [defexample]]
[com.fulcrologic.fulcro.mutations :refer [defmutation]]
[com.fulcrologic.fulcro.algorithms.normalize :as fnorm]
[com.fulcrologic.fulcro.algorithms.merge :as merge]))
(defsc CategoryQuery [this props]
{:query [:db/id :category/name]
:ident [:categories/by-id :db/id]})
(defsc ItemQuery [this props]
{:query [:db/id :item/name {:item/category (comp/get-query CategoryQuery)}]
:ident [:items/by-id :db/id]})
(def sample-server-response
{:all-items [{:db/id 5 :item/name "item-42" :item/category {:db/id 1 :category/name "A"}}
{:db/id 6 :item/name "item-92" :item/category {:db/id 1 :category/name "A"}}
{:db/id 7 :item/name "item-32" :item/category {:db/id 1 :category/name "A"}}
{:db/id 8 :item/name "item-52" :item/category {:db/id 2 :category/name "B"}}]})
(def component-query [{:all-items (comp/get-query ItemQuery)}])
(def hand-written-query [{:all-items [:db/id :item/name
{:item/category [:db/id :category/name]}]}])
(defsc ToolbarItem [this {:keys [item/name]}]
{:query [:db/id :item/name]
:ident [:items/by-id :db/id]}
(dom/li name))
(def ui-toolbar-item (comp/factory ToolbarItem {:keyfn :db/id}))
(defsc ToolbarCategory [this {:keys [category/name category/items]}]
{:query [:db/id :category/name {:category/items (comp/get-query ToolbarItem)}]
:ident [:categories/by-id :db/id]}
(dom/li
name
(dom/ul
(mapv ui-toolbar-item items))))
(def ui-toolbar-category (comp/factory ToolbarCategory {:keyfn :db/id}))
(defmutation group-items-reset [params]
(action [{:keys [app state]}]
(swap! state (fn [s]
(-> s
(dissoc :categories/by-id :toolbar/categories)
(merge/merge* component-query sample-server-response))))))
(defn add-to-category
"Returns a new db with the given item added into that item's category."
[db item]
(let [category-ident (:item/category item)
item-location (conj category-ident :category/items)]
(update-in db item-location (fnil conj []) (comp/ident ItemQuery item))))
(defn group-items*
"Returns a new db with all of the items sorted by name and grouped into their categories."
[db]
(let [sorted-items (->> db :items/by-id vals (sort-by :item/name))
category-ids (-> db (:categories/by-id) keys)
clear-items (fn [db id] (assoc-in db [:categories/by-id id :category/items] []))
db (reduce clear-items db category-ids)
db (reduce add-to-category db sorted-items)
all-categories (->> db :categories/by-id vals (mapv #(comp/ident CategoryQuery %)))]
(assoc db :toolbar/categories all-categories)))
(defmutation ^:intern group-items [params]
(action [{:keys [state]}]
(swap! state group-items*)))
(defsc Toolbar [this {:keys [toolbar/categories]}]
{:query [{:toolbar/categories (comp/get-query ToolbarCategory)}]}
(dom/div
(dom/button {:onClick #(comp/transact! this [(group-items {})])} "Trigger Post Mutation")
(dom/button {:onClick #(comp/transact! this [(group-items-reset {})])} "Reset")
(dom/ul
(mapv ui-toolbar-category categories))))
(defexample "Morphing Data" Toolbar "morphing-example" :initial-db (fnorm/tree->db component-query sample-server-response true))13.5. Pre-Merge
Pre-merge offers a hook to manipulate data entering your Fulcro app at the component level.
During the lifetime of a Fulcro application, data will enter the system:
-
During app initialization
-
When loaded from a remote
-
By being added via mutations
In the first case the data comes from the component initial state or user-provided initial state. Such pre-supplied data usually includes both domain and UI-centric data.
In the second case the data comes from a remote and contains only domain data; however, the UI might still need to do some type of initialization to add UI-centric props for this in the local database.
Post-mutations are a little limiting in this case because they are not component-centric: they are not co-located with the components, and may have to deal with an entire sub-tree all at once. Pre-hooks decompose this logic to the component level making things a bit simpler in many cases.
To illustrate these issues we are going to write a small app that has some countdown buttons. The idea is that each counter will go down each time it is clicked until it reaches zero. The important detail will be how we can handle the initial counter value.
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]}
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))The :ui/count is a ui-only concern that must start with some value.
We will arbitrarily choose 5 as a start.
Whatever it is we need to initialize it when a new instance of a Countdown
enters the system.
First, we’ll use this post-mutation to initialize this ui property:
(m/defmutation initialize-counter [{::keys [counter-id]}]
(action [{:keys [state]}]
(swap! state update-in [::counter-id counter-id] #(merge {:ui/count 5} %))))And use it via this call to load:
(df/load this [::counter-id 1] Countdown
{:target [:counter]
:post-mutation `initialize-counter
:post-mutation-params {::counter-id 1}})Here is a running demo:
(ns book.demos.pre-merge.post-mutation-countdown
(:require
[com.fulcrologic.fulcro.data-fetch :as df]
[book.demos.util :refer [now]]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.data-fetch :as df]
[com.wsscode.pathom.connect :as pc]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}])
(pc/defresolver counter-resolver [env {::keys [counter-id]}]
{::pc/input #{::counter-id}
::pc/output [::counter-id ::counter-label]}
(let [{:keys [id]} (-> env :ast :params)]
(first (filter #(= id (::counter-id %)) all-counters))))
(def resolvers [counter-resolver])
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(m/defmutation initialize-counter [{::keys [counter-id]}]
(action [{:keys [state]}]
(swap! state update-in [::counter-id counter-id] #(merge {:ui/count 5} %))))
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]}
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))
(def ui-countdown (comp/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {:keys [counter]}]
{:initial-state (fn [_] {})
:query [{:counter (comp/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq counter)
(ui-countdown counter)
(dom/button {:onClick #(df/load! this [::counter-id 1] Countdown
{:target [:counter]
:post-mutation `initialize-counter
:post-mutation-params {::counter-id 1}})}
"Load one counter"))))
(defn initialize
"To be used in :started-callback to pre-load things."
[app])Now let’s see in case of a to-many, this is what our new mutation looks like:
(m/defmutation initialize-counters [_]
(action [{:keys [state]}]
(swap! state
(fn [state]
(reduce
(fn [state ref]
(update-in state ref #(merge {:ui/count 5} %)))
state
(get state ::all-counters))))))(ns book.demos.pre-merge.post-mutation-countdown-many
(:require
[com.fulcrologic.fulcro.data-fetch :as df]
[book.demos.util :refer [now]]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.wsscode.pathom.connect :as pc]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}
{::counter-id 2 ::counter-label "B"}
{::counter-id 3 ::counter-label "C"}
{::counter-id 4 ::counter-label "D"}])
(pc/defresolver counter-resolver [env _]
{::pc/output [{::all-counters [::counter-id ::counter-label]}]}
{::all-counters all-counters})
(def resolvers [counter-resolver])
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(m/defmutation initialize-counters [_]
(action [{:keys [state]}]
(swap! state
(fn [state]
(reduce
(fn [state ref]
(update-in state ref #(merge {:ui/count 5} %)))
state
(get state ::all-counters))))))
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]}
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))
(def ui-countdown (comp/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {})
:query [{::all-counters (comp/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq all-counters)
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))
(dom/button {:onClick #(df/load! this ::all-counters Countdown
{:post-mutation `initialize-counters})}
"Load many counters"))))As you can see, adding a single depth to the query can yield a fair amount of extra code to hook things up, and as you app grows each join depth will add more post-mutation code to compose over. Solving this composition issue is the main motivation behind pre-merge.
13.5.1. Pre-merge Basics
Pre merge addresses these issues by providing a component level hook that allows the additional merge logic to be localized to the component of interest.
This is how we would set up our Countdown component using :pre-merge:
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
; (1)
(merge
{:ui/count 5} ; (2)
current-normalized ; (3)
data-tree))} ; (4)
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))-
This merge setup works for most of the cases
-
We start the merge with a map containing defaults
-
Then we merge with the data that is already there for this component (may be
nilif component doesn’t have previous data) -
Finally merge in the incoming data tree, since it’s the last it will win over any of the previous
The :pre-merge lambda receives a single map containing the following keys:
-
:data-tree- the new data tree entering the database -
:current-normalized- the current entity value (if any), comes normalized from the db (as in(get-in state ref)) -
:state-map- the current app state map (you may use to lookup refs). -
:query- the query used to do this request (user may have modified the original using:focus,:withoutor:update-queryduring the load call
With this setup we can get rid of the post-mutation.
The cleaned up examples follow.
(ns book.demos.pre-merge.countdown
(:require
[com.fulcrologic.fulcro.data-fetch :as df]
[book.demos.util :refer [now]]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.wsscode.pathom.connect :as pc]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}])
(pc/defresolver counter-resolver [env {::keys [counter-id]}]
{::pc/input #{::counter-id}
::pc/output [::counter-id ::counter-label]}
(let [{:keys [id]} (-> env :ast :params)]
(first (filter #(= id (::counter-id %)) all-counters))))
(def resolvers [counter-resolver])
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
{:ui/count 5}
current-normalized
data-tree))}
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))
(def ui-countdown (comp/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {:keys [counter]}]
{:initial-state (fn [_] {})
:query [{:counter (comp/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq counter)
(ui-countdown counter)
(dom/button {:onClick #(df/load! this [::counter-id 1] Countdown {:target [:counter]})}
"Load one counter"))))
(defn initialize
"To be used in :started-callback to pre-load things."
[app])(ns book.demos.pre-merge.countdown-many
(:require
[book.demos.util :refer [now]]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.data-fetch :as df]
[com.wsscode.pathom.connect :as pc]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}
{::counter-id 2 ::counter-label "B"}
{::counter-id 3 ::counter-label "C"}
{::counter-id 4 ::counter-label "D"}])
(pc/defresolver counter-resolver [env _]
{::pc/output [{::all-counters [::counter-id ::counter-label]}]}
{::all-counters all-counters})
(def resolvers [counter-resolver])
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
{:ui/count 5}
current-normalized
data-tree))}
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))
(def ui-countdown (comp/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {})
:query [{::all-counters (comp/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq all-counters)
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))
(dom/button {:onClick #(df/load! this ::all-counters Countdown)}
"Load many counters"))))
(defn initialize
"To be used in :started-callback to pre-load things."
[app])13.5.2. Pre-merge with Server Data
To make this example more interesting let’s make it possible, but optional, for the server to define an initial counter value.
(ns book.demos.pre-merge.countdown-with-initial
(:require
[com.fulcrologic.fulcro.data-fetch :as df]
[book.demos.util :refer [now]]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.wsscode.pathom.connect :as pc]
[com.fulcrologic.fulcro.algorithms.merge :as merge]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}
{::counter-id 2 ::counter-label "B" ::counter-initial 10}
{::counter-id 3 ::counter-label "C" ::counter-initial 2}
{::counter-id 4 ::counter-label "D"}])
(pc/defresolver counter-resolver [env _]
{::pc/output [{::all-counters [::counter-id ::counter-label ::counter-initial]}]}
{::all-counters all-counters})
(def resolvers [counter-resolver])
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def default-count 5)
(defsc Countdown [this {::keys [counter-label counter-initial]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label ::counter-initial :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
; (1)
{:ui/count (or (merge/nilify-not-found (::counter-initial data-tree)) default-count)}
current-normalized
data-tree))}
(dom/div
(dom/h4 (str counter-label " [" (or counter-initial default-count) "]"))
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))
(def ui-countdown (comp/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {})
:query [{::all-counters (comp/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq all-counters)
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))
(dom/button {:onClick #(df/load! this ::all-counters Countdown)}
"Load many counters"))))-
During the normalization step of a load Fulcro will put
::merge/not-foundvalue on keys that were not delivered by the server, this is used to do asweep-mergelater, themerge/nilify-not-foundwill return the same input value (likeidentity) unless it’s a::merge/not-found, in which case it returnsnil, this way theorworks in both cases.
13.5.3. Pre-merge and UI Children
Next, we are going to extract the counter button into its own component to illustrate how you can augment pure UI concerns with this feature:
(defsc CountdownButton [this {:ui/keys [count]}]
{:ident [:ui/id :ui/id]
:query [:ui/id :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
; (1)
{:ui/id (random-uuid)
:ui/count default-count}
current-normalized
data-tree))}
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count)))))
(defsc Countdown [this {::keys [counter-label counter-initial]
:ui/keys [counter]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label ::counter-initial
{:ui/counter (comp/get-query CountdownButton)}]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(let [initial (comp/nilify-not-found (::counter-initial data-tree))]
(merge
; (2)
{:ui/counter (cond-> {} initial (assoc :ui/count initial))}
current-normalized
data-tree)))}
(dom/div
(dom/h4 (str counter-label " [" (or counter-initial default-count) "]"))
(ui-countdown-button counter)))-
For the UI element we can also set the initial id using pre-merge, and now we moved the default there
-
Note we pass a blank map to the
:ui/counter, this will reach the pre-merge fromCountdownButtonas thedata-treepart
Full demo:
(ns book.demos.pre-merge.countdown-extracted
(:require
[com.fulcrologic.fulcro.data-fetch :as df]
[book.demos.util :refer [now]]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.algorithms.merge :as merge]
[com.wsscode.pathom.connect :as pc]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}
{::counter-id 2 ::counter-label "B" ::counter-initial 10}
{::counter-id 3 ::counter-label "C" ::counter-initial 2}
{::counter-id 4 ::counter-label "D"}])
(pc/defresolver counter-resolver [env _]
{::pc/output [{::all-counters [::counter-id ::counter-label]}]}
{::all-counters all-counters})
(def resolvers [counter-resolver])
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def default-count 5)
(defsc CountdownButton [this {:ui/keys [count]}]
{:ident [:ui/id :ui/id]
:query [:ui/id :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
; (1)
{:ui/id (random-uuid)
:ui/count default-count}
current-normalized
data-tree))}
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count)))))
(def ui-countdown-button (comp/factory CountdownButton {:keyfn ::counter-id}))
(defsc Countdown [this {::keys [counter-label counter-initial]
:ui/keys [counter]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label ::counter-initial
{:ui/counter (comp/get-query CountdownButton)}]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(let [initial (merge/nilify-not-found (::counter-initial data-tree))]
(merge
; (2)
{:ui/counter (cond-> {} initial (assoc :ui/count initial))}
current-normalized
data-tree)))}
(dom/div
(dom/h4 (str counter-label " [" (or counter-initial default-count) "]"))
(ui-countdown-button counter)))
(def ui-countdown (comp/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {})
:query [{::all-counters (comp/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq all-counters)
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))
(dom/button {:onClick #(df/load! this ::all-counters Countdown)}
"Load many counters"))))13.5.4. Pre-merge During App Initialization
Another interesting property about pre-merge is that it also runs during normalization of app initialization, this means you can provide the minimum amount of data as the initial state and let the pre-merge fill the UI needs, to illustrate let’s add some initial state to our demo:
(defsc Root [this _]
{:initial-state (fn [_] {::all-counters
[{::counter-id (tempid/tempid)
::counter-label "X"}
{::counter-id (tempid/tempid)
::counter-label "Y"}
{::counter-id (tempid/tempid)
::counter-label "Z"
::counter-initial 9}]})
:query [{::all-counters (comp/get-query Countdown)}]}
...)Pre merge will be applied on top of that running the pre-merge on the respective data parts. Full demo:
(ns book.demos.pre-merge.countdown-initial-state
(:require
[com.fulcrologic.fulcro.data-fetch :as df]
[book.demos.util :refer [now]]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.wsscode.pathom.connect :as pc]
[com.fulcrologic.fulcro.algorithms.merge :as merge]
[com.fulcrologic.fulcro.algorithms.tempid :as tempid]
[taoensso.timbre :as log]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}
{::counter-id 2 ::counter-label "B" ::counter-initial 10}
{::counter-id 3 ::counter-label "C" ::counter-initial 2}
{::counter-id 4 ::counter-label "D"}])
(pc/defresolver counter-resolver [env _]
{::pc/output [{::all-counters [::counter-id ::counter-label]}]}
{::all-counters all-counters})
(def resolvers [counter-resolver])
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def default-count 5)
(defsc CountdownButton [this {:ui/keys [count]}]
{:ident [:ui/id :ui/id]
:query [:ui/id :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
{:ui/id (random-uuid)
:ui/count default-count}
current-normalized
data-tree))}
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count)))))
(def ui-countdown-button (comp/factory CountdownButton {:keyfn ::counter-id}))
(defsc Countdown [this {::keys [counter-label counter-initial]
:ui/keys [counter]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label ::counter-initial
{:ui/counter (comp/get-query CountdownButton)}]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(let [initial (merge/nilify-not-found (::counter-initial data-tree))]
(log/spy :info (merge
{:ui/counter (cond-> {} initial (assoc :ui/count initial))}
current-normalized
data-tree))))}
(dom/div
(dom/h4 (str counter-label " [" (or counter-initial default-count) "]"))
(ui-countdown-button counter)))
(def ui-countdown (comp/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {::all-counters
[{::counter-id (tempid/tempid)
::counter-label "X"}
{::counter-id (tempid/tempid)
::counter-label "Y"}
{::counter-id (tempid/tempid)
::counter-label "Z"
::counter-initial 9}]})
:query [{::all-counters (comp/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(when (seq all-counters)
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters)))))13.5.5. Pre-merge via Mutations
We’ve already talked about ways to integrate new data using things like merge/merge-component, and since pre-merge takes effect there as well we can rely on it in mutations:
(m/defmutation create-countdown [countdown]
(action [{:keys [state ref]}]
(swap! state merge/merge-component Countdown countdown :append [::all-counters])
(swap! state update-in ref assoc :ui/new-countdown-label "")))And add some UI to trigger this mutation:
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {::all-counters
[{::counter-id (tempid/tempid)
::counter-label "X"}
{::counter-id (tempid/tempid)
::counter-label "Y"}
{::counter-id (tempid/tempid)
::counter-label "Z"
::counter-initial 9}]})
:query [{::all-counters (comp/get-query Countdown)}
:ui/new-countdown-label]}
(dom/div
(dom/h3 "Counters")
(dom/button {:onClick #(comp/transact! this [`(create-countdown ~{::counter-id (tempid/tempid)
::counter-label "New"})])}
"Add counter")
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))))Full demo:
(ns book.demos.pre-merge.countdown-mutation
(:require
[book.demos.util :refer [now]]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.algorithms.merge :as merge]
[com.fulcrologic.fulcro.algorithms.tempid :as tempid]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def default-count 5)
(defsc CountdownButton [this {:ui/keys [count]}]
{:ident [:ui/id :ui/id]
:query [:ui/id :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
{:ui/id (random-uuid)
:ui/count default-count}
current-normalized
data-tree))}
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count)))))
(def ui-countdown-button (comp/factory CountdownButton {:keyfn ::counter-id}))
(defsc Countdown [this {::keys [counter-label counter-initial]
:ui/keys [counter]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label ::counter-initial
{:ui/counter (comp/get-query CountdownButton)}]
:pre-merge (fn [{:keys [current-normalized data-tree] :as x}]
(let [initial (merge/nilify-not-found (::counter-initial data-tree))]
(merge
{:ui/counter (cond-> {} initial (assoc :ui/count initial))}
current-normalized
data-tree)))}
(dom/div
(dom/h4 (str counter-label " [" (or counter-initial default-count) "]"))
(ui-countdown-button counter)))
(def ui-countdown (comp/factory Countdown {:keyfn ::counter-id}))
(m/defmutation create-countdown [countdown]
(action [{:keys [state ref]}]
(swap! state merge/merge-component Countdown countdown :append [::all-counters])
(swap! state update-in ref assoc :ui/new-countdown-label "")))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {::all-counters
[{::counter-id (tempid/tempid)
::counter-label "X"}
{::counter-id (tempid/tempid)
::counter-label "Y"}
{::counter-id (tempid/tempid)
::counter-label "Z"
::counter-initial 9}]})
:query [{::all-counters (comp/get-query Countdown)}
:ui/new-countdown-label]}
(dom/div
(dom/h3 "Counters")
(dom/button {:onClick #(comp/transact! this [(create-countdown {::counter-id (tempid/tempid)
::counter-label "New"})])}
"Add counter")
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))))13.6. Incremental Loading
It is very common for your UI query to have a lot more in it than you want to load at any given time. In some cases, even a specific entity asks for more than you’d like to load. A good example of this is a component that allows comments. Perhaps you’d like the initial load of the component to not include the comments at all, then later load the comments when the user, for example, opens (or scrolls to) that part of the UI.
Fulcro makes this quite easy. There are three basic steps:
-
Put the full query on the UI
-
When you use that UI query with load, prune out the parts you don’t want.
-
Later, ask for the part you do want (see warning about using this with
load-field!).
Step 2 sounds like it will be hard, but it isn’t:
13.6.1. Pruning the Query
Sometimes your UI graph asks for things that you’d like to load incrementally. Let’s say you were loading a blog post that has comments. Perhaps you’d like to load the comments later:
(df/load! app :server/blog Blog {:params {:id 1}
:without #{:blog/comments}})The :without parameter can be used to elide portions of the query (it works recursively).
The query sent to the server will not ask for :blog/comments.
Of course, your server has to parse and honor the exact details of the query for this to work (if the server decides it’s going to returns the comments, you get them…but this is why we disliked REST, right?).
Of course, Pathom makes this quite easy since it honors the query presented to it.
13.6.2. Filling in the Subgraph
Later, say when the user scrolls to the bottom of the screen or clicks on "show comments" we can load the rest from of this previously partially-loaded graph within the Blog itself.
We can do this using df/load-field!, which does the opposite of :without on the query:
(defsc Blog [this props]
{:ident :blog/id
:query [:blog/id :blog/title {:blog/content (comp/get-query BlogContent)} {:blog/comments (comp/get-query BlogComment)}]}
(dom/div
...
(dom/button {:onClick #(df/load-field! this :blog/comments {})} "Show Comments")
...)))The load-field! function finds the query on the component (via this) and prunes everything from that query except for the branch joined through the given key.
It also generates an entity rooted query based on the calling component’s ident:
[{[:table ID] subquery}]In the example above, this would end up something like this:
[{[:blog/id 1] [{:blog/comments [:comment/id :comment/author :comment/body]}]}]This kind of query can be handled automatically by Pathom as long as there is a resolver that takes :blog/id as an input, and resolvers exist to fulfill the subgraph from there!
(pc/defresolver blog-resolver [env {:blog/keys [id]}]
{::pc/input #{:blog/id}
::pc/output [... {:blog/comments [:comment/id]}]}
...)
(pc/defresolver comment-resolver [env {:comment/keys [id]}]
{::pc/input #{:comment/id}
::pc/output [:comment/body {:comment/author [:author/id]}]}
...)
;; and so on|
Warning
|
If you are using pre-merge then you will need to fetch the ID as part of the load or current-normalized will
be nil in your pre-merge handler. As of 3.1.10 Fulcro’s load-field! supports a vector of fields so that you can
load more than one field: (df/load-field! this [:thing/id :thing/field] …).
|
Load Focus
Another way to load a subgraph part is to use the :focus setting on the load, :focus
allow you to define a subquery to be loaded from the component query, to start simple here is how we can write the same previous example using :focus:
(defsc Blog [this props]
{:ident [:blog/id :db/id]
:query [:db/id :blog/title {:blog/content (comp/get-query BlogContent)} {:blog/comments (comp/get-query BlogComment)}]}
(dom/div
...
(dom/button {:onClick #(load this (comp/get-ident this) Blog {:focus [:blog/comments]})}
"Show Comments")
...)))Although the interface requires more code, it’s more flexible, let’s say for instance you only want to load the comment id and author, you can write as:
(load this (get-ident this) Blog {:focus [{:blog/comments [:db/id :comment/author]}]})As you might notice, in the first :focus example when we point to a join, the whole join sub-query will be pulled, but you can get more precise by expressing more of the sub-query.
Load focus on unions
A special case that worth mention about focus sub-query is how it handles unions.
Other than on unions, :focus will only use the attributes mentioned on the sub-query, but on unions, if you don’t express some union branch it will be pulled as is, for example, let’s say you have this given query:
[{:feed/item {:message [:message/text :message/timestamp]
:activity [:activity/source-id :activity/url]}}]If you :focus on this:
[{:feed/item {:message [:message/text]}}]Then you get out the query:
[{:feed/item {:message [:message/text]
:activity [:activity/source-id :activity/url]}}]This makes sure you will keep all union branches.
13.7. Load Errors
The load! function includes a number of options for dealing with problems during load.
The docstring load!
describes your options, and we leave that discussion to the chapter on overall error handling and user experience.
14. Client Networking with Fulcro HTTP Remote
Fulcro allows you to define any number of remote handlers for talking to any number of remote servers.
If unspecified it defaults to using an HTTP remote named :remote that talks to your js origin server through HTTP POST at the /api URI, and uses JSON-encoded transit to communicate requests and interpret responses.
You can create additional remotes of your own implementation or instances of Fulcro’s built-in HTTP remote, which is written to be customizable.
It has the following features:
-
It uses middleware for the request and response so you can customize the entire communication pipeline without having to deal with low-level networking. A remote can now manipulate everything from the request headers to the URL and even the raw data on the wire.
-
It supports Fulcro’s
app/abort!. -
It reports progress, so the
progress-actionof your mutations can update the UI as the operation runs.
14.1. Creating a Remote
A remote with these new features requires very little code:
(http-remote/fulcro-http-remote {:url "/api"})You may include a :url parameter to specify what the server endpoint is (defaults to "/api"), and you may also provide middleware.
14.2. Request Middleware
The request will, by default, be sent through pre-written middleware fulcro.client.network/wrap-fulcro-request.
This middleware will convert the body to a json-encoded transit form and add content-type headers.
If you specify request middleware you will want to compose that middleware in or normal API requests won’t work.
Additional middleware can do any number of things:
-
Re-route requests to an alternate URI
-
Change the content type and encode the body
-
Short-circuit the result of the middleware stack
Middleware is just a function (fn [handler] (fn [req] …)).
The inner function can choose to modify the request and pass it through the remaining handler, or just return a request as the final thing to process.
This is similar to Ring middleware on the server.
Fulcro will supply the middleware with a request that contains:
-
:body- The EDN transaction to send (query or mutations). -
:headers- An empty map. -
:url- The default URL this remote talks to. -
:method- The HTTP verb as a keyword. All Fulcro requests default to:post.
Middleware should return a map with the same keys that is passed on to the next layer. It may add any keys it wishes. The final result of the middleware stack will be used as follows:
-
:body- The raw data that will be given to XhrIO send -
:headers- A clj map from string to string. It will be converted to a jsobj and given as the headers to the request. -
:url- The network target. Can be relative or a complete URL, assuming you have security set to allow you to talk to the given server. -
:method- Converted to an upper-case HTTP verb as a string.
14.3. Client Response Middleware
The response will, by default, be sent through the pre-written middleware function http-remote/wrap-fulcro-response
which contains the logic to properly decode an API response (which is essentially just a transit decode).
If you specify response middleware you will want to compose that middleware in or normal API responses won’t work.
Raw responses from the remote will include:
-
:body- The data that will be given back to Fulcro as the response from the server -
:original-transaction- The original transaction that was sent from tx layer that the body is a response to. If you modify this for queries you can manipulate the final merge. -
:status-code- The HTTP status code -
:status-text- The HTTP status text -
:error- An error code. Typically one of:network-error,:http-error,:timeout, etc. -
:error-text- A string describing the error -
:outgoing-request- The request that this is a response to.
Your middleware can add a :transaction key and modify the :body key, which will then be used
at the merge layer. Note that this can confuse things like normalization and mark-and-sweep merge, so it should generally
be used with quite a bit of caution.
If you add a :transaction key be sure to use a query from components so that normalization is done properly.
|
Note
|
Fulcro versions prior to 3.1 used the :transaction key for the raw middlware input as well as output. This
caused issues with other internals since it was difficult to tell when you’d overridden it. If you have custom
middleware that needs to look at the original transaction you will need to port that to use the new key.
|
|
Important
|
Response middleware is allowed to rewrite an errant response to an OK one (by clearing the error fields and setting :status-code to 200). This would allow you, for example, to merge specific errors into state as you see fit instead of relying on Fulcro’s built-in error handling model. |
14.3.1. Merging State
TODO: REVIEW this section
As mentioned above: the final response body and transaction combo will be given to Fulcro for merge. The basic pipeline is like this:
-
You run a transact that goes remote. E.g.
(transact! this '[(f {:x 1})]).transactionis[(f {:x 1})] -
The response is received from the server. This can be anything you want to return, but typically for mutations is just
:tempids. For example{'f {:tempids {1 2}}}. This is thebody. -
Merge is a two-part affair:
-
Any mutation keys in the response are pulled off and run through migrate to get tempid migrations.
-
The remainder of the k/v pairs in the map are then run through normal merge (which requires a query, assumed to be in
transaction).
-
So, this gives you a ton of power in your response middleware to customize everything from error handling to doing post-operations on mutations.
Let’s say you want to write response middleware that does the following:
If there is an error, skip Fulcro’s error pipeline and instead put the information in :my-error key at root (which
perhaps you have set up to pop a modal in your UI code).
So, your desired merge transaction is [:my-error] (rewriting the transaction "as if" you had "asked" for the error),
and the body is {:my-error {…data for error…}}! The entire middleware component is:
(defn wrap-errors [handler]
(fn [resp]
(let [{:keys [error status-code]} resp]
(handler
(if (not= 200 status-code) ; when there are errors, rewrite them "as-if" we had asked for it
(-> resp
(assoc :body {:my-error {:error error}} :transaction [:my-error] :status-code 200)
(dissoc :error))
resp)))))installed with:
;; Resulting middleware (evaluates right to left because of nested composition)
(def middleware (-> (net/wrap-fulcro-response) (wrap-errors)))
...
(def client (fc/make-fulcro-client {:networking {:remote (net/fulcro-http-remote {:url "/api" :response-middleware middleware})}})14.4. Writing Your Own Remote Implementation
If you do not want to use the networking code provided in Fulcro then you may write your own.
You could use the code in http_remote.cljs as a starting point.
Here are the basics:
-
A remote is just a map. The map can contain anything you want, but MUST contain a
:transmit!key whose value is a(fn [remote send-node] ).
A remote is the remote map itself.
A send-node has the following spec:
(s/def :com.fulcrologic.fulcro.algorithms.tx-processing/send-node
(s/keys
:req [:com.fulcrologic.fulcro.algorithms.tx-processing/id
:com.fulcrologic.fulcro.algorithms.tx-processing/idx
:com.fulcrologic.fulcro.algorithms.tx-processing/ast
:com.fulcrologic.fulcro.algorithms.tx-processing/result-handler
:com.fulcrologic.fulcro.algorithms.tx-processing/update-handler
:com.fulcrologic.fulcro.algorithms.tx-processing/active?]
:opt [:com.fulcrologic.fulcro.algorithms.tx-processing/options]))The ast is the AST of the request that Fulcro wants to make.
The result-handler and update-handler are functions you call to report the result (once and only once) or send updates.
The options map will include things like the
abort-id.
This book implements a remote that uses a cljs pathom parser to respond (no network).
You could define a "remote" that talks to browser local storage.
There are really no limitations beside the fact that you must call result-handler once and only once.
What you pass to the result handler is also up to you. If you send a "normal" Fulcro result it should have the basic form of:
{:body some-edn
:original-transaction original-tx-or-query
:status-code n}but since you can define what happens to this data via default-result-action or directly in mutations it is really wide open to your own invention.
If you follow the standard result format, then you can expect the default load and mutation return merging to work, and error/ok processing to function as well.
If you deviate from the standard format then those functions will not work without additional intervention on your part.
14.5. Interfacing with Alternate Network Protocols
Fulcro’s pluggable remotes make it relatively easy to plug in alternate communication methods. You can interface with things like REST or GraphQL servers with relative ease, especially if you use the Pathom parser library.
14.5.1. A REST Example
TODO: This is an unported Fulcro 2 example. The pathom network support for fulcro is for version 2 at the moment, so this example would require a bit more work.
Here’s a simple example to give you an idea of how simple it can be:
(ns app.rest-remote
(:require [com.wsscode.pathom.connect :as pc]
[com.wsscode.pathom.core :as p]
[com.wsscode.pathom.fulcro.network :as pn]
[clojure.core.async :as async]
[com.fulcrologic.fulcro.components :as comp]
[fulcro.client.network :as net]))
(defmulti resolver-fn pc/resolver-dispatch)
(defonce indexes (atom {}))
(defonce defresolver (pc/resolver-factory resolver-fn indexes))
(defn rest-parser
"Create a REST parser. Make sure you've required all nses that define rest resolvers. The given app-atom will be available
to all resolvers in `env` as `:app-atom`."
[extra-env]
(p/async-parser
{::p/plugins [(p/env-plugin
(merge extra-env
{::p/reader [p/map-reader
pc/all-async-readers]
:app-atom app-atom
::pc/resolver-dispatch resolver-fn
::pc/indexes @indexes}))
p/request-cache-plugin
(p/post-process-parser-plugin p/elide-not-found)]}))
(defn rest-remote [extra-env]
(pn/pathom-remote (rest-parser extra-env)))The rest-remote function creates a remote that can resolve REST requests via Pathom resolvers.
It is written to take an atom that will hold your Fulcro app, so that resolvers for REST can interact with your database.
Simply add the remote into your networking on the client:
(app/fulcro-app
{:remotes {:remote (fulcro-http-remote ...)
:rest (rr/rest-remote app)}})and you can use the newly defined defresolver to define Pathom resolvers for satisfying REST API requests, like so:
(defresolver `ofac
{::pc/output [:rest/thing]}
(fn [env _]
(let [name (-> env :ast :params :name)
params {"name" name}]
(go
(let [{:keys [body]} (<!
(http/get "https://myrest.com/search" {:query-params params}))]
{:rest/thing body})))))which can then be used with:
(df/load this :rest/thing nil {:params {:name "Simon"}})and can be targeted, use load markers, etc.
Of course, you can also define resolvers that "compute" derived data with normal resolver tricks. See Pathom documentation.
GraphQL
The Pathom library also includes a pre-built GraphQL remote for Fulcro, along with tools that allow you to combine resolvers with GraphQL servers easily. Pathom’s connect feature can be combined in, which allows you to morph your perception of the server’s graph in ways that are more convenient for your application. This results in a remote for Fulcro that is far more powerful than standard GraphQL, even when GraphQL is what the server is providing!
15. Network Latency, Error Handling, and User Experience
Most applications have to contend with network latency. A good user experience requires that applications be able to give feedback to the user about the progress of network operations. The optimistic nature of Fulcro means that you can often give the user the impression of zero latency (the UI changes before the networking even starts); however, there are many circumstances where you would like to give the user some assurance that the full-stack operation is complete before moving on. For example, when saving a form you usually don’t want to pop up some kind of error about the submission of that form when the user has already moved on to a new screen.
You’ve certainly seen a number of different ways this can be handled. Network applications like Google Docs give the user a continuous indication of when their changes are pending vs. when they have been saved, which allows the user to work in an uninterrupted fashion where they only need to worry about the network when they are done with the entire session. More and more applications save data from things like settings screens as the changes are made, removing the need for a user "save step" as well.
Still others do more complex schemes that persist data into browser local storage as a method of preventing data loss even if the network is spotty or the browser crashes while unsaved changes are queued.
Fulcro gives you the power to express any user experience, and this chapter covers some of the techniques you can use to provide the experience you desire.
Network latency can often be improved by using Batched Reads.
15.1. Global Network Activity
Fulcro tracks the general idea that network activity is happening in the state database under the key :com.fulcrologic.fulcro.application/active-remotes. The value is a set of remote names (keywords) that have scheduled remote activity that has yet to complete. A remote will appear in this set from the time the desire for remote content enters the transaction processing system until that desire is met (or fails).
This global set can easily be queried for by a component that wants to track the status of network activity by simply querying for it with a root link element in the query: [::app/active-remotes '_].
|
Note
|
Any component querying for the network active remotes will see a lot of re-renders. It is recommended that such a component be a leaf in the UI graph so you don’t trigger refresh on entire subtrees due to network activity status updates. |
(defsc GlobalStatus [this {::app/keys [active-remotes]}]
{:query [[::app/active-remotes '_]]
:ident (fn [] [:component/id :activity])
;; important: components that query only for root data need to have at least some empty state of their own
:initial-state {}}
...
(let [loading? (boolean (seq active-remotes))]
(when loading?
(dom/div "Loading..."))))(ns book.server.network-activity
(:require
[com.fulcrologic.fulcro.application :as app]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.wsscode.pathom.connect :as pc]
[taoensso.timbre :as log]
[clojure.pprint :refer [pprint]]
[com.fulcrologic.fulcro.data-fetch :as df]))
;; Simulated server
(pc/defresolver silly-resolver [_ _]
{::pc/output [::data]}
{::data 42})
;; Client
(defsc ActivityIndicator [this props]
{:query [[::app/active-remotes '_]]
:ident (fn [] [:component/id ::activity])
:initial-state {}}
(let [active-remotes (::app/active-remotes props)]
(dom/div
(dom/h3 "Active Remotes")
(dom/pre (pr-str active-remotes)))))
(def ui-activity-indicator (comp/factory ActivityIndicator {:keyfn :id}))
(defsc Root [this {:keys [indicator]}]
{:query [{:indicator (comp/get-query ActivityIndicator)}]
:initial-state {:indicator {}}}
(dom/div {}
(dom/p {} "Use the server controls to slow down the network, so you can see the activity")
(dom/button {:onClick #(df/load! this ::data nil)} "Trigger a Load")
(ui-activity-indicator indicator)))15.2. Pessimistic Operation
Fulcro is optimistic by default, but pessimism is also a supported mode. There are a couple of clear techniques you can use to allow the network activity to complete before allowing the user to continue:
-
The Load API has a number of parameters that can allow you to plug in your own code for dealing with results.
-
For mutations: use the action/ok-action/error-action to do a sequence of optimistically blocking the UI, sending the request, and then using the ok-action/error-action as the place to unblock the UI and report the result. This is the most similar to the approach other libraries use.
-
Use pessimistic transactions. This is a mode of transaction processing that allows each mutation in a single top-level transaction (call to
transact!) to complete (full-stack) before anything from the next one begins. This mode has the advantage of making the sequence visible at the transaction layer, but requires you share progressive data through the app state itself. Some people prefer this because the "happy path" can be expressed clearly in the UI, even though the details are still within the mutation. Something like(comp/transact! this [(submit-form) (process-result)] {:optimistic? false})is more directly informative to the reader than(comp/transact! this [(submit-form)])(implied post-processing hidden in the mutationok-action).
There are also some more advanced techniques that allow you to leverage more global control:
-
Change the
default-result-actionfor mutations and provide application-specific defaults for error handling. -
Change the
internal-loadmutation for loads to add in whatever global changes you desire.
The above two techniques typically would leverage the default implementations so that the pre-defined behaviors still work, but might include mechanisms you define to handle common cases without having to code them repeatedly.
If you want to explore these advanced techniques expect to use the source.
See mutations.cljc and data_fetch.cljc for the default implementations, and the docstring of app/fulcro-app for the options you can use to override the defaults.
15.3. Full-Stack Error Handling
The first thing I want to challenge you to think about is this: why do errors happen, and what can we do about them?
In the early days of web apps, our UI was completely dumb: the server did all of the logic. The answer to these questions were clear, because it wasn’t even a distributed app: it was a remote display of an app running on a remote machine. In other words, the context of the error handling was available at the same time as our request to do the operation.
In more modern apps we often block the UI so that the user cannot get ahead of things (like submit a form and move on before the server has confirmed the submission). Over the years we’ve gotten a little more clever with our error handling, but largely our users (and our ability to reason about our programs) has kept us firmly rooted to the block-until-we-know method of error handling because that behavior is simple: it is much less like an actual distributed system. Unfortunately, such UI interactions are doomed to feel sluggish in congested or bandwidth-limited environments.
More and more code is moving to the client machine. In the world of single-page apps we want things to "make sense" and we also want them to be snappy. Unfortunately, we still also have security concerns at the server, so we get confused by the following fact: the server has to be able to validate a request for security reasons. There is no getting around this. You cannot trust a client.
However, I think many of us take this too far: security concerns are often a lot easier to enforce than the full client-level interaction with these concerns. For example, we can say on a server that a field must be a number. This is one line of code that can be done with an assertion.
The UI logic for this is much larger: we have to tell the user what we expected, why we expected it, constrain the UI to keep them from typing letters, etc. In other words, almost all of the real logic is already on the client, and unless there is a bug, our UI won’t cause a server error because it is pre-checking everything before sending it out.
So, in a modern UI, here are the scenarios for errors from the server:
-
You have a bug. Is there anything you can really do? No, because it is a bug. If you could predict it going wrong, you would have already fixed it. Testing and user bug reports are your only recourse.
-
There is a security violation. There is nothing for your UI to do, because your UI didn’t do it! This is an attack. Throw an exception on the server, and never expect it in the UI. If you get it, it is a bug. See (1).
-
There is a user perspective outage (LAN/WiFi/phone). These are possibly recoverable. You can block the UI, and allow the user to continue once networking is re-established.
-
There is an infrastructure outage. You’re screwed. Things are just down. If you’re lucky, it is networking and your user is seeing it as (3) and is just blocked. If you’re not lucky, your database crashed and you have no idea if your data is even consistent.
So, I would assert that the only full-stack error handling worth doing in any detail is for case (3). If communications are down, the client can retry. But in a distributed system this can be a little nuanced. Did that mutation partially complete?
If your application can assume reasonably reliable networking and you write your server operations to be atomic then your error handling can be a relatively small amount of code. Unrecoverable problems will be rare and at worst you throw up a dialog that says you’ve had an error and the user hits reload on their browser. If this happens to users once or twice a year, it isn’t going to hurt you.
But of course there is more to the story, and the devil is in the details.
15.3.1. Programming with Pure Optimism
The general philosophy of a Fulcro application is that optimistic updates are not even triggered on the client unless they expect to succeed on the server. In other words, you write the application in such a way that operations cannot be triggered from the UI unless you’re certain that a functioning server will execute them. A server should not throw an exception and trigger a need for error handling unless there is a real, non-recoverable situation.
If this is true then a functioning server does need to do sanity checking for security reasons, but in general you don’t need to give friendly errors when those checks fail: you should assume they are attempted hacks. Other serious problems are similar: there is usually nothing you can do but throw an exception and let the user contact support. Exceptions to this rule certainly exist, but they are not the central concern.
There are some cases where the server has to be involved in a validation interaction non-optimistically. Login is a great example of this. However, invalid credentials on login need not be treated as an error. Instead they can be treated as a response to a question. "Can I log in with these credentials?". Yes or no. This allows the UI to show the correct result without treating anything as a distributed-systems/data-consistency kind of error.
This philosophy eases the overhead in general application programming. You need not write a bunch of code in the UI that gives a nice friendly message for every kind of error that can possibly occur (nor does anyone really do that anywhere anyhow, since it is quite expensive). If an error occurs, you can pretty much assume it is either a bug or a real outage. In both cases, there isn’t a lot you can do that will work "well" for the user. If it is a bug, then you really have no chance of predicting what will fix it, otherwise you would have already fixed the bug. If it’s an outage you might be able to do retries, but in many cases you have no way of knowing what has gone wrong.
So, one approach is to treat most error conditions as a rare problem that needs fairly radical recovery. One such method is to use a global error handler that is configured during the setup of your client application. This function could update application state to show some kind of top-level modal dialog that describes the problem, possibly allows the user to submit application history (for support viewer) to your servers, and then re-initializes the application in some way.
You can, of course, get pretty creative with the re-initialization. For example, say you write screens so that they will refresh their persistent data whenever it is older than some amount of time, and write it so all entities have a timestamp. You could walk the state and "expire" all of the timestamps, and then close the dialog. Your retry could be set up to check for the expiration, which in turn would trigger loads. If the server is really having problems then the worst case is that the dialog pops back up telling them there is still a problem.
15.3.2. Being a Bit More Pessimistic — Flaky Network Operation
If your users are likely using your software from a phone on a subway then you have a completely different issue.
Fortunately, Fulcro actually makes handling this case relatively easy as well. Here is what you can do:
-
Write a custom networking implementation for the client that detects the kind of error, and retries recoverable ones until they succeed. Possibly with exponential backoff. (If an infinite loop happens, the user will eventually hit reload.)
-
Make your server mutations idempotent so that a client can safely re-apply a transaction without causing data corruption.
The default fulcro networking does not do retries because it isn’t safe without the idempotent guarantee.
The optimistic updates of Fulcro and the in-order server execution means that "offline" operation is actually quite tractable. If programmed this way, your error handling becomes isolated almost entirely to the networking layer. Of course, if the user navigates to a screen that needs server data, they will just have to wait. Writing UI code that possibly has lifecycle timers to show progress updates will improve the overall feel, but the correctness will be there with a fairly small number of additions.
However, even with these fancy tricks that make our applications better, there are times when we’d just like to block until something is complete.
The following example is a common way to do UI blocking with the mechanisms you’ve already seen.
It overrides the default result-action to look at the response from the server and decide what to do.
(ns book.server.ui-blocking-example
(:require
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.wsscode.pathom.connect :as pc]
[taoensso.timbre :as log]))
;; SERVER
(pc/defmutation submit-form-mutation [env params]
{::pc/sym `submit-form}
(log/info "Server got " params)
(if (> 0.5 (rand))
{:message "Everything went swell!"
:ok? true}
{:message "Service temporarily unavailable!"
:ok? false}))
;; CLIENT
(defsc BlockingOverlay [this {:keys [ui/active? ui/message]}]
{:query [:ui/active? :ui/message]
:initial-state {:ui/active? false :ui/message "Please wait..."}}
(dom/div {:style {:position :absolute
:display (if active? "block" "none")
:zIndex 65000
:width "400px"
:height "100px"
:backgroundColor "rgba(0,0,0,0.5)"}}
(dom/div {:style {:position :relative
:top "40px"
:color "white"
:textAlign "center"}} message)))
(def ui-overlay (comp/factory BlockingOverlay))
(defn set-overlay-visible* [state tf] (assoc-in state [:overlay :ui/active?] tf))
(defn set-overlay-message* [state message] (assoc-in state [:overlay :ui/message] message))
(defmutation submit-form [params]
(action [{:keys [state]}]
(swap! state (fn [s]
(-> s
(set-overlay-message* "Working...")
(set-overlay-visible* true)))))
(result-action [{:keys [app state result]}]
(log/info "Result:" result)
(let [mutation-result (-> result :body (get `submit-form))
{:keys [message ok?]} mutation-result]
(if ok?
(swap! state set-overlay-visible* false)
(do
(swap! state set-overlay-message* (str message " Retrying submission in 1s."))
;; could use setTimeout or immediately do it
(js/setTimeout
#(comp/transact! app [(submit-form params)])
1000)))))
(remote [_] true))
(defsc Root [this {:keys [ui/name overlay]}]
{:query [:ui/name {:overlay (comp/get-query BlockingOverlay)}]
:initial-state {:overlay {} :ui/name "Alicia"}}
(dom/div {:style {:width "400px" :height "100px"}}
(ui-overlay overlay)
(dom/p "Name: " (dom/input {:value name}))
(dom/button {:onClick #(comp/transact! this [(submit-form {:made-up-data 42})])}
"Submit")))15.3.3. Defining "Remote Errors"
Fulcro’s concept of a "remote error" is configurable.
It defaults to a function that returns true if the network result includes a :status-code attribute that is not 200.
However, it is common for applications to define errors more widely.
For example, you might consider certain data return values to be indications of an error.
You can define the meaning of "remote errors" when you create your Fulcro application via the :remote-error? option:
(app/fulcro-app {:remote-error? (fn [result] boolean)})where the result value is the raw value that your selected remote encodes. Fulcro’s HTTP remote encodes result as:
{:body raw-result
:original-transaction outgoing-tx
:status-code n
...}|
Note
|
Fulcro 3.1.x renamed the :transaction to :original-transaction on the raw response from the http-remote layer,
but you still overwrite the transaction by adding :transaction to the response in custom response middlware.
|
This result is determined by the remote implementation and client network middleware can certainly expand/modify this as needed.
15.3.4. Global Error Handler
When you create your application you can set a global function that is called on any kind of network error that happens against any remote.
The function will be called with the env, which will contain things like the AST, network result, etc.
(app/fulcro-app {:global-error-action (fn [env] ...))You can of course swap against the state atom, use the app from the env to submit a new transaction, etc.
15.3.5. Load Errors
Loads can define a mutation symbol that should be used to trigger a transaction on errors. Loads may also choose to specify a lambda
15.3.6. Server Error Demo
We recommend using Pathom for the server, and one of the recommended plugins for Pathom will convert exceptions into data errors on the response. This allows pathom to give partial responses where it can partially fulfill a request for data.
Fulcro does not default to considering these particular kinds of errors as "hard errors", and leaves them up to your interpretation; however, it is simply enough to redefine what Fulcro things of as hard errors by setting the :remote-error? option on your application.
The live example below demonstrates redefining the meaning of hard errors to look for these Pathom values, and shows the resulting use of the built-in error-action support of mutations.
(ns book.demos.server-error-handling
(:require
[com.fulcrologic.fulcro.data-fetch :as df]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[taoensso.timbre :as log]
[com.wsscode.pathom.connect :as pc]
[com.wsscode.pathom.core :as p]
[com.fulcrologic.fulcro.application :as app]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(pc/defmutation server-error-mutation [env params]
{::pc/sym `error-mutation}
;; Throw a mutation error for the client to handle
(throw (ex-info "Mutation error" {})))
(pc/defresolver child-resolver [env input]
{::pc/output [:fulcro/read-error]}
(throw (ex-info "read error" {})))
(def resolvers [server-error-mutation child-resolver])
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Mutation used as a fallback for load error: In this case the `env` from the load result *is* the params to this mutation
(defmutation read-error [params]
(action [env]
(js/alert "There was a read error")
(log/info "Result from server:" (:result params))
(log/info "Original load params:" (:load-params params))))
;; an :error key is injected into the fallback mutation's params argument
(defmutation error-mutation [params]
(ok-action [env] (log/info "Optimistic action ran ok"))
;; Error action is only called if `:remote-error?` for the application is defined to consider the response an error.
(error-action [{:keys [app ref result]}]
(js/alert "Mutation error")
(log/info "Result " result))
(remote [env] true))
(defsc Child [this props]
{:initial-state {}
:query ['*]
:ident (fn [] [:error.child/by-id :singleton])}
(dom/div
;; declare a tx/fallback in the same transact call as the mutation
;; if the mutation fails, the fallback will be called
(dom/button {:onClick #(df/load! this :fulcro/read-error nil {:fallback `read-error})}
"Failing read with a fallback")
(dom/button {:onClick #(comp/transact! this [(error-mutation {})])} "Failing mutation")
))
(def ui-child (comp/factory Child))
(defsc Root [this {:keys [child]}]
{:initial-state (fn [params] {:child (comp/get-initial-state Child {})})
:query [{:child (comp/get-query Child)}]}
(dom/div (ui-child child)))
(defn contains-error?
"Check to see if the response contains Pathom error indicators."
[body]
(when (map? body)
(let [values (vals body)]
(reduce
(fn [error? v]
(if (or
(and (map? v) (contains? (set (keys v)) ::p/reader-error))
(= v ::p/reader-error))
(reduced true)
error?))
false
values))))
(def SPA (app/fulcro-app {:remote-error? (fn [{:keys [body] :as result}]
(or
(app/default-remote-error? result)
(contains-error? body)))}))15.4. Aborting a Request
Requests that are heavy on the server or require significant data transfer often need to be cancelled. User experience, especially in mobile environments, can be heavily impacted if their navigation is blocked with no way back. Futhermore, there is no real reason for you to pay for the bandwidth to send or receive something that the user is no longer interested in.
The built-in HTTP remote support aborts.
If you use a custom or alternate remote implementation then that may affect the availability of both abort and progress reports. See the documentation and source of your remote for more information.
The abort feature requires that the request be assigned a unique identifier.
You can use any data type that supports equivalence, but we recommend using keywords.
The df/load! and comp/transact! functions both accept an option for supplying this ID:
(df/load! this :thing Thing {:abort-id :thing})
(comp/transact! this [(f)] {:abort-id :made-up-id})The application namespace includes and abort! function that can accept a component or app, and the abort ID:
(app/abort! this :made-up-id)Aborting a load or transaction while holding the thread of submission will have no effect on the load just issues (the load/mutation will be on a submission queue, not in active processing):
(df/load! this :thing Thing {:abort-id :thing})
(when bad-thing?
;; WILL NOT WORK
(app/abort! this :thing))Technically, it will abort any earlier submission(s) with abort ID :thing that have entered the processing phase.
Aborting a request that is active on the network or has yet to start networking will remove the request from the processing queue, cancel the network operation, and trigger a result action. Your definition of remote-error?
on your application will determine if the result is considered an error (which will trigger the error side of post-processing) or not (which will trigger the OK side of post-processing).
The :result reported to your remote-error? and post-processing will not include a body or status code (since the network request didn’t finish and provide one), but will instead look like this:
{::txn/aborted? true}Therefore the default remote error definition will consider aborts to be an error (since it does not have a status code of 200).
15.5. Progress Updates
Obtaining progress updates on mutations requires making a progress-action section of the mutation:
(defmutation some-mutation [params]
(progress-action [env] ...)
(remote [{:keys [ast]}] true))Progress updates are sent to the given mutation (which will also always receive the parameters you specified).
The result in the env will include a map at the :progress key that includes the current :raw-progress, along
with some additional useful stats.
The com.fulcrologic.fulcro.networking/http-remote ns includes three helpers for use in mutations:
-
(overall-progress env)- Returns a number between 0 and 100 indicating the overall network progress. -
(receive-progress env)- Returns a number between 0 and 100 indicating the receive network progress. -
(send-progress env)- Returns a number between 0 and 100 indicating the send network progress.
So, you might write a mutation that transfers a large amount of data like so:
(defmutation large-mutation [_]
(progress-action [{:keys [state] :as env}]
(swap! state assoc-in [:component/id :thing :ui/progress] (http-remote/overall-progress env)))
(remote [_] true))Then the component with ident [:component/id :thing] will be able to show progress based on the :ui/progress
attribute.
Progress updates are currently supported on mutations. Support for progress directly on loads is possible, but not yet implemented. The workaround for the moment to get progress for a load is to use mutation joins to return a value from a mutation:
(defmutation some-mutation [params]
(remote [env]
(-> env
(m/returning Thing))))where Thing is some component that defines the query for the data being returned from the mutation.
In general progress updates are only really useful for larger requests, such as file transfers.
File uploads also require that you augment the new client network middleware, since there is no reliable way to encode an image of arbitrary size into a transaction.
16. Building a Server
It turns out that the server API handling is relatively light. Most of the work goes into getting things set up for easy server restart (e.g. making components stop/start) and getting those components into your parsing environment.
In general you should probably use a template project that already has a server set up, along with the various bits you need for configuration, restart during development, testing, etc.
If you have an existing server then you’ve mostly figured out all of that stuff already and just want to plug a Fulcro API handler into it.
Here are the basic requirements:
-
Make sure your Ring stack has transit-response and transit-params.
-
Use
api-middleware/handle-api-requestto handle requests for the correct URI (defaults to/api)
An example basic Ring stack was demonstrated in the Getting Started chapter’s Going Remote section.
16.1. Use Pathom to Process the EQL
You can hand-write a server-side parser to handle EQL from the client, but you should really just use Pathom. See the Pathom Developer’s Guide.
16.2. Server Configuration
Fulcro includes a small set of functions that can help you with managing your server-side configuration data.
These functions are in the com.fulcrologic.fulcro.server.config namespace.
The primary function is load-config!.
Server configuration requires two EDN files:
-
config/defaults.edn: This file (from CLASSPATH, typically resources) should contain a single EDN map that contains defaults for everything that the application wants to configure. -
/abs/path/of/choice: This file can be named what you want (you supply the name when making the server). The content can be an empty map, but is meant to be machine-local overrides of the configuration in the defaults. This file is required. We chose to do this because it keeps people from starting the app in an production environment that is missing a configuration file. NOTE: If the path is relative it is looked for via CLASSPATH (resource). If it is absolute, the real filesystem is searched.
(defn make-system []
(server/make-fulcro-server
:config-path "/usr/local/etc/app.edn"
...The configuration loading has a number of built-in features:
-
The
defaults.ednis the target of configuration merge. Your config EDN file must be a map, and anything in it will override what is in defaults. The merge is a deep (recursive) merge. -
You can override the configuration file that will be used as
:config-pathwith a JVM option:-Dconfig=filename. This allows you to specify the file on a per-environment basis. -
Values can take the form
:env/VAR, which will use the string value of that environment variable as the value. -
Values can take the form
:env.edn/VAR, which will useread-stringto interpret the environment variable as the value. -
Relative paths for the config file can be used, and will search the CLASSPATH instead of local disk. This allows you to package your config with your application.
If you are using something like mount, then you will typically use load-config! directly:
(defstate config :start (server/load-config! {:config-path "config/dev.edn"}))and then config (after start) will simply contain the EDN of the defaults/config file merge.
17. Custom Type Support
Available in Fulcro 3.3.6+.
|
Note
|
This is API stable and definitely usable as parameters for mutations, but needs more testing with respect to usage
in the state database. We intend to support the custom types everywhere, but test your use of them carefully. We
currently recommend using deftype and not defrecord. The latter looks like a map to Fulcro’s internals, which can cause
confusion if a query is used against it (which can cause it to lose its type and turn into a plain persistent map).
|
Fulcro has leveraged Cognitect’s Transit for on-the-wire communication since the beginning. Earlier versions allowed you to extend the types supported by transit on a per-function basis (i.e. every time you used a subsystem/function that leveraged transit, you could supply transit options to install handlers).
Unfortunately as the ecosystem grew this became harder and harder to manage. Remembering to install transit handlers and passing transit options down through trees of calls just isn’t a very "black box" approach, and many very nice features of the library are "hard to reach" this way.
Starting in version 3.3.5 we added support for a central type registry, and evolved all of the dependent libraries and functions to use it. You can still pass the custom handlers as options to everything that used to accept them, but now those will be merged with whatever is in the global Fulcro registry.
The com.fulcrologic.fulcro.algorithms.transit namespace (referred to here as transit) contains both the registry
and the functions needed to create/add type support to it. It is a CLJC file, and The interface is identical for CLJ
and CLJS. Here is an example of adding support for a geometric Point type:
(ns com.app.custom-types
(:require
[com.fulcrologic.fulcro.algorithms.transit :as transit]))
(deftype Point [x y])
(defn install! []
(transit/install-type-handler!
(transit/type-handler Point "geo/point"
(fn [^Point p] [(.-x p) (.-y p)])
(fn [[x y]] (Point. x y)))))You simply support the type, a string to tag the type (globally unique within your handlers), and two functions. One that can convert from the type to a representation, and another that can convert from that representation back to the type.
The "representation" must be something Transit already supports, or a type that you have installed a custom handler for (i.e. you can nest definitions). For example, this is legal:
(deftype Point [x y])
(deftype Rectangle [^Point ul ^Point lr])
(defn install! []
(transit/install-type-handler!
(transit/type-handler Point "geo/point"
(fn [^Point p] [(.-x p) (.-y p)])
(fn [[x y]] (Point. x y))))
(transit/install-type-handler!
(transit/type-handler Rectangle "geo/rect"
(fn [^Rectangle p] [(.-ul p) (.-lr p)])
(fn [[a b]] (Rectangle. a b)))))Fulcro’s HTTP remote, Websocket Remote (v3.2.0+), string conversion support (e.g. transit/transit-clj→str),
Fulcro RAD, and even Fulcro Inspect can leverage these custom types to provide a more seamless experience around
data that needs (or already has) some kind of "type". Common examples can include things like
transmitting/receiving instances of things like Java’s LocalDate when using js-joda with CLJC java.time.
|
Important
|
It is critical that you install your type handlers as early as possible. Some aspects of libraries have to access (and close over) this type registry on initialization. For example, websockets support requires you install these before you create a client or server instance. |
18. UI State Machines
User interfaces are full of interactions that beg for the help of state machines. Just a simple login form is usually quite difficult to code (independent of tools) because its behavior depends on a number of factors…factors that are actually quite easy to represent with state machines, but get ugly quickly when spread out in various code artifacts.
This is not a new idea. People have been using state machines to control user interfaces and graphics systems for decades. For some reason most UI libraries and frameworks don’t usually have a well-known or particularly general-purpose state machine aspect. Part of the problem is that a state machine needs to interact with actual UI state and vice-versa, so it is difficult to "bolt on" something, and there is often a lot of "glue code" to make the two hang together properly.
It turns out that Fulcro’s approach to UI is quite easily amenable to state machines because it has the following facets:
-
The transactional nature of mutations and central state is already a lot like a state machine.
-
Application state is just data.
-
The application database is normalized: It is very easy to describe where particular bits of data are in a non-ambiguous manner.
-
The UI refresh is based on the normalized data model, and not the UI structure. Triggering refreshes requires only that you know what data you’re changing.
Thus, it turns out to be quite easy to build a state machine system for Fulcro with the following properties:
-
The state machine doesn’t need not know anything about the UI
-
The UI only needs to support displaying the declared state of the state machine.
-
Simple aliasing can map the state machine "values" onto Fulcro database values.
-
The aliasing makes it possible to re-use state machines on UIs that have varying shapes, and need not even name their Fulcro state according to the state machine’s conventions.
-
State machines can be instanced, so that more than one of the same kind can be running at once.
-
Active state machine data is stored in Fulcro’s app database, so it honors all history properties (e.g. support viewer, etc.) and is amenable to great tooling.
-
Any number of simultaneous state machines of varying type can be running at once (even on the same component).
-
The state machine declarations are reusable (they are just maps), and make it easy to "derive" new definitions based on existing ones with simple clj functions like
mergeandassoc-in.
18.1. Aliases
The first powerful concept for our state machines is aliasing. The first kind of aliasing is for the "actors" that will participate in our UI. An actor is simply a keyword defined in the state machine declaration, and is meant to stand for "some UI component". The actions of a state machine can then be written to abstractly refer to that component without actually needing to know anything else about it:
(defstatemachine login
{::uism/actor-names #{:actor/dialog :actor/form}
...})In this example we plan to have a "dialog" and a "form" on the UI. These could be separate UI components, or could be the same.
It doesn’t matter to the state machine!
We adopt the convention of using the actor namespace for these, but it is not required.
In reality actors are merely names for some "yet to be specified" ident that points to an entity in your database.
The next layer of aliasing is for the data our state machine will manipulate:
(defstatemachine login-machine
{::uism/actor-names #{:actor/dialog :actor/form}
::uism/aliases {:visible? [:actor/dialog :ui/active?]
:login-enabled? [:actor/form :ui/login-enabled?]
:busy? [:actor/form :ui/busy?]
:error [:actor/form :ui/login-error]
:username [:actor/form :user/email]
:password [:actor/form :user/password]}
...})Thus, the alias busy? is now the data path to some field of an entity in the database.
The actual path will be resolved at runtime based on what components actually end up being used as the actors.
For example if you use a component with ident [:modal/id :general] as the :actor/dialog then the alias
:visible? means the path [:modal/id :general :ui/active?].
This is the primary aspect of UI state machines that makes them reusable.
18.2. Derived State Machines
State machine definitions are just maps.
If you needed the field on the dialog to be called :ui/visible? instead of :ui/active? you could simply do this:
(defstatemachine custom-login-machine
(assoc-in login-machine [::uism/aliases :visible? 1] :ui/visible?))This makes it possible to easily build a library of state machines that work on your app state in a very general and configurable way without having to change any actual logic!
|
Note
|
State machine definitions must be declared with defstatemachine even though they are just maps.
The declaration registers them with the system so that they have a unique ID that can be used within the instances in Fulcro’s client database.
|
18.3. Plugins
In order for a state machine to be as reusable as possible we’d also like to be able to write logic that the state machine uses in a form that can be easily changed. We call these bits of logic "plugins". The are simply functions that will receive a map of the current UI state (by alias name) and will do some calculation. They are meant to be side-effect free calculations.
For example a login form we usually don’t want them to be able to press "Login" (or enter) until both username and password fields have something in them. If the username is an email we might also want to check that it looks like a valid email before allowing submission.
The state machine can come with a simple plugin like this:
::uism/plugins {:valid-credentials? (fn [{:keys [username password]}]
(boolean (and (seq username) (seq password))))}Plugins receive (as a map) all of the current aliased data used by the state machine (so they can easily destructure it as shown). They can return any value.
Changing a plugin is as simple as the trick shown for overriding an alias in Derived State Machines.
Plugins are called within a state handler like so:
...
:event/login {::uism/handler
(fn [env]
(let [valid? (uism/run env :valid-credentials?)]
...))}18.4. States
The final bit of a state machine definition is, of course, the actual states. In our system we define these as a map from user-defined state name to a function that will receive the running state machine environment for all events triggered on that state machine.
The states must include an :initial state, whose handler will be invoked with a
::uism/started event when the state machine is first started.
The "current state" handler is always invoked for each event that is triggered while it is active, but only the :initial state sees a ::uism/started event.
The overall configuration of states looks like this:
(defstatemachine login-machine
{::uism/actor-names #{...}
::uism/aliases {...}
::uism/states {:initial { ... } ; REQUIRED
:state/state-id { ... }
:state/state2-id { ... }
...By convention it is a good idea to name your states with a state namespace for readability, but this is not required.
You have two options for what you put in a state’s definition.
18.4.1. Option 1 — Predicate/handler (preferred)
With this option you specify a map of events to a description of what should happen:
::uism/states {:initial {::uism/events
{:event/thing-happened!
{::uism/event-predicate (fn [env] ... true)
;; target-states is doc for diagram tools
::uism/target-states #{:state/next-state :state/other-state}
::uism/handler (fn [env] ... (uism/activate env :state/next-state))}}}
:state/next-state {...}
...In this case the event :event/thing-happened! is an event that can happen while in the :initial state which:
-
If there is an event predicate, it is run. The default predicate is
(constantly true). If the predicate returnsfalsethen the event is ignored and nothing else happens. -
If the predicate returned true (or didn’t exist), then the handler is run. Any effects it has on
envare propagated.
The predicate is useful for a few reasons:
-
You may have a condition that should short-circuit triggers of numerous events. Without the predicate you’d have to code an
ifinto each handler. -
The UISM helper functions that set state (e.g.
set-string!) apply state changes before your handler. Under certain circumstances you’d like to avoid that. If predicate isfalse, then these events (as per the rules above) are not applied.
18.4.2. Option 2 — A Single Handler
This format of defining the states allows you to write just one function, but is not normally recommended, as it does not give you the ability to analyze the states/events as a diagram via simple data analysis. It does, however, allow you complete flexibility with how the state machine is defined, so you are welcome to use it. Basically you do not define an event map, and instead embed a handler in it’s place:
::uism/states {:initial
{::uism/handler
(fn [env]
(log/info "Initial state.")
...)}}18.5. Transitioning State
There are two options for transitioning to another state from within a state:
18.5.1. Option 1 — Call uism/activate from within a handler
::uism/states
{:state/some-state
{::uism/events
{:event/some-event
{::uism/handler
(fn [env]
(uism/activate env :state/some-other-state)}}}
:state/some-other-state {...}}18.5.2. Option 2 — Use the ::uism/target-state keyword shortcut
When you have an event that only changes to another state, the ::uism/target-state key is simpler. Note that uism/activate
will take precedence if it is called within a handler on this event.
::uism/states
{:state/some-state
{::uism/events
{:event/some-event {::uism/target-state :state/some-other-state}}}
:state/some-other-state {...}}18.6. Writing Handlers and Data Manipulation
From here it’s pretty easy. The handlers are functions that receive a state machine (SM) environment and must return an updated environment (or nil, which is considered "no change"). Since the environment is an immutable value you will typically thread a sequence of these together to end up with a final result to return from the handler:
(fn [env]
(-> env
(uism/assoc-aliased :visible? true)
...))The library includes many functions for manipulating the system via the state machine handler’s env:
(uism/assoc-aliased env alias new-value & more-kv-pairs)-
Sets Fulcro state associated with the given alias to the given new value. Can accept multiple k-v pairs (like
assoc). (uism/dissoc-aliased env alias & more-aliases)-
Removes given aliases from Fulcro state. Can accept multiple aliases (like
dissoc). (uism/update-aliased env alias f & args)-
Updates given aliases in Fulcro state with function f and given arguments. (like
update). (uism/integrate-ident env ident & named-parameter)-
Integrates idents (append or prepend) to aliases in Fulcro state that refer to a list of idents. (like
targeting/integrate-ident*). (uism/remove-ident env ident alias)-
Removes ident from aliases that refer to a list of idents, in Fulcro state. (like
fulcro.client.mutations/remove-ident*). (uism/alias-value env alias)-
Gets the current Fulcro state value associated with an alias.
(uism/run env plugin-name)-
Runs the given plugin (passing it all of the aliased data from current Fulcro state) and returns the value from the plugin.
(uism/activate env state-name)-
Returns a new env with
state-nameas the new active state. (uism/exit env)-
Returns a new env that will end the state machine (and GC it’s instance from Fulcro state) after the results of the handler are processed.
(uism/store env k v)-
Saves a state-machine local value. Useful for keeping track of some additional bit of data while your state machine is running.
(uism/retrieve env k)-
Get state-machine local value.
(uism/apply-action env (fn [state-map] state-map))-
use a fn of state-map (i.e. some mutation helper) via a SM env.
(uism/asm-value env ks)-
Get the value of from an active state machine based on keyword OR key-path
ks. Primarily used for extending the library and internal use. (uism/actor→ident env actor-name)-
Get the ident of an actor
Some of the utilities allow you to work fields directly on actors without having to alias fields:
(uism/actor-path env actor-name)-
Get the real Fulcro state-path for the entity of the given actor.
(uism/actor-path env actor-name k)-
Get the real Fulcro state-path for the attribute k of the entity of the given actor.
(uism/set-actor-value env actor-name k v)-
Set a value in the actor’s Fulcro entity. Only the actor is resolved. The k is not processed as an alias.
(uism/actor-value env actor-name k follow-idents?)-
Get the value of a particular key in the given actor’s entity. If follow-idents? is true (which is the default), then it will recursively follow idents until it finds a non-ident value.
18.7. Using State Machines from the UI
The next step, of course, is hooking this state machine up so it can control your UI (which really just means your app state).
18.7.1. Starting An Instance
The first thing you need to do is create an instance and start it:
(uism/begin! app-or-component machine-def instance-id actor-map)-
Installs an instance of a state machine (to be known as
instance-id, an arbitrary keyword), based on the definition inmachine-def, into Fulcro’s state and sends the::uism/startedevent.
This is a Fulcro transaction internally, so it follows the normal transactional semantics and can be used from almost anywhere (including inside of another state machine handler).
The instance is stored in your database at the well-known ::uism/asm-id table with an id that is the instance ID you supply to this call.
The Actor Map
The actor-map is a map, keyed by actor-id, that lets the state machine know what components in your Fulcro app are being acted upon.
It also supplies the necessary information that is needed when doing remote mutations and loads (since a component class or instance is needed to figure out normalization).
The actor map values must be one of the following:
- An ident
-
A raw ident is allowed, but should normally be augmented using
with-actor-classso that it can work with loads/mutations. - A component class
-
In this case the actor is assumed to be a singleton. The ident will be derived by calling
(comp/get-ident class {}). This actor will work properly with remote return values and loads. - A component instance (e.g.
this) -
A component instance can be
this, or can be found using Fulcro’s live indexes (e.g.(comp/ident→any app [:person/id 1])). A component instance is sufficient for the state machine to find the correct ident and query for the UI component, so it will work with loads/mutations.
Example Starts
For example, to start the above state machine with an instance ID of ::loginsm:
(uism/begin! this login-machine ::loginsm {:actor/dialog Dialog
:actor/session Session
:actor/form LoginForm})In this example all three of our components are singletons whose idents are constant.
If you are working with actors that are more dynamic you either need to use a react instance (such as this), or an explicit ident:
(uism/begin! this person-editing-machine ::personsm {:person (uism/with-actor-class [:person/id 3] Person)
:editor this
:dialog Dialog})18.7.2. Triggering Events
Now that you have a state machine running it is ready to receive events. It will have already run the initial state handler. For example, in our login case the initial state might show the dialog, clear the input fields, etc.
Forms may want to send an event to indicate that a value is changing in some form field.
Because this is such a common operation there are two helpers for it.
For example, to update a string from a DOM onChange event or raw string:
(uism/set-string! component state-machine-id data-alias event-or-string)-
Puts a string into the given data alias (you can pass a string or a DOM onChange event) and sends a
::uism/value-changedevent to your machine. (uism/set-value! component state-machine-id data-alias raw-value)-
Puts a raw (unmodified) value into the given data alias and sends a
::uism/value-changedevent to your machine.
You can define other "custom" events to stand for whatever you want (and they can include aux data that you can pass along to the handlers). To trigger arbitrary events use:
(uism/trigger! comp-or-app state-machine-id event)-
Trigger an arbitrary event on the given state machine.
For example:
(uism/trigger! this ::loginsm :event/failure)would send a (user-defined) :event/failure event.
Event data is just a map that can be passed as an additional parameter:
(uism/trigger! app ::loginsm :event/failure {:message "Server is down. Try in 15 minutes."})18.7.3. Looking at The Running Instance
For debugging purposes you can just look in Fulcro Inspect at the database.
The active state machines are in the ::uism/asm-id table, with the ID you assigned.
UI code can also look at the state machine’s current state:
(uism/get-active-state this asm-id)-
Returns the current state name (keyword).
(uism/asm-ident asm-id)-
Returns the ident of the active state machine with the given ID.
|
Important
|
Technically you must query for any data you use in the UI, but these functions help keep the internals of the UISM system out of your UI code. |
Any changes made to actor aliases presumably change data that a component is already querying for, meaning that those components will automatically refresh without a problem; however, if you use data without querying for it (and this is true everywhere in Fulcro) then you can experience what looks like "missed refreshes".
Remember that Fulcro won’t re-render a component unless its props change (they are all pure components).
If you use
(get-active-state) from a UI then you are "grabbing data" without it going through props.
In order to get proper refreshes on a component whose UI depends on the current state you must query for that state machine’s data.
Including the ident in your query is enough:
(defsc Component [this props]
{:query (fn [] [ (uism/asm-ident ::my-machine) ...])
...}
...
(let [s (get-active-state this ::my-machine)] ...))18.8. Mutations and State Machines
Functions are included that allow you to trigger remote mutations. Your state machine handlers are already an implementation of the client side operations of a mutation, so really what we need is a way to trigger a remote mutation and then trigger events based on the outcome.
The trigger-remote-mutation function does this.
It takes:
-
env- The SM handler environment -
actor- The name (keyword) of a defined actor. The mutation will be run in the context of this actor’s state (seepm/pmutate!), which means that progress will be visible there. THERE MUST BE A MOUNTED COMPONENT with this actor’s name ON the UI, or the mutation will abort. This does not have to be the same component as you’re (optionally) returning from the mutation itself. It is purely for progress UI. -
mutation- The symbol (or mutation declaration) of the server mutation to run. This function will not run a local version of the mutation (nor do you have to write one). -
options-and-params- The parameters to pass to your mutation. This map can also include these additional options (which will not show up in the remote and are namespaced to avoid collision):::m/returning Class-
Indicate a return value of the remote mutation (for normalizing the returned result). If you know the class you can use it. Use
(actor-class actor-name)to get the correct class for an arbitrary actor, or(comp/registry-key→class component-fully-qualified-symbol)to look a class up (for avoiding circular `require`s in Clojure). ::targeting/target explicit-target-
Option for targeting returned result using data-targeting. Should be used with
::m/returning. ::uism/target-actor actor-
Helper that can translate an actor name to a target, if returning a result.
::uism/target-alias field-alias-
Helper that can translate a data alias to a target (ident + field).
::uism/ok-event event-id-
The SM event to trigger when the pessimistic mutation succeeds (no default).
::uism/error-event event-id-
The SM event to trigger when the pessimistic mutation fails (no default).
::uism/ok-data map-of-data-
Data to include in the event-data on an ok event
::uism/error-data map-of-data-
Data to include in the event-data on an error event
::uism/mutation-remote-
The keyword name of the Fulcro remote (defaults to :remote)
The mutation response follows the same rules as normal mutations (e.g. default-result-action).
The result will also be in the ::uism/event-data under the ::uism/mutation-result key so that the ok-event and error-event handlers can simply look in event-data for the data sent back from the server.
|
Note
|
In general you should use actors as the mechanism for obtaining a return type’s class, since that will keep your state machine code decoupled from UI code. |
18.9. Loads and State Machines
The API includes these functions for doing loads in the context of a running state machine:
(load env k component-class params)-
Just like Fulcro’s load, but takes a SM env. Typically you should use
actor-classor the component registrycomp/registry-key→classto get the component class so you don’t couple UI code into your machine. (load-actor env actor-name params)-
(Re)load the given actor.
The params of these functions are the normal Fulcro load! options, but can include these additional special items:
::uism/ok-event-
An event to send when the load is done (instead of calling a mutation)
::uism/ok-event-data-
Extra parameters to send as event-data on the post-event.
::uism/error-event-
The event to send if the load triggers a fallback.
::uism/error-event-data-
Extra parameters to send as event-data on a fallback.
DEPRECATED (use the ok/error versions instead):
::uism/post-event::
An event to send when the load is done (instead of calling a mutation)
::uism/post-event-params::
Extra parameters to send as event-data on the post-event.
::uism/fallback-event::
The event to send if the load triggers a fallback.
::uism/fallback-event-params::
Extra parameters to send as event-data on a fallback.
18.9.1. Dynamic Actor Idents
There are all sorts of situations where you may not know the ident of an actor when the machine is first started, or perhaps the ident of an actor can change over time.
The reset-actor-ident function can be used to update an actor.
Say you start the machine like this, with a (made-up) :none marker as an ID.
(uism/begin! this person-editing-machine ::personsm
{:actor/selected-person (uism/with-actor-class [:person/id :none] Person)
:actor/list [:person-list :singleton})You can later set the actor’s ident like so:
... ;; somewhere in the UI
(uism/trigger! this ::personsm :event/person-selected {:new-ident [:person/id 33]})
...
;; in the machine definition:
:event/person-selected
{::uism/handler (fn [{{:keys [new-ident]} ::uism/event-data :as env}]
(uism/reset-actor-ident env :actor/selected-person new-ident))}18.10. Timer Events
Many UI interactions require some kind of timeout. For example, you don’t want to issue a load on an autocomplete search field until the user stops typing for 300ms, or perhaps you’d like to close a dialog and show an error if a data load takes more than 5 seconds.
The (uism/set-timeout env timer-id event-id event-data timeout cancel-on-events) function can be used in a handler to schedule a ms timer, where timer-id is a user-invented name for the timer (keyword), the event-id is the invented keyword for the event you want to send, event-data is additional data you’d like to send with the event, and timeout is in ms.
The cancel-on-events parameter is a function that will be sent the name of any event that occurs while the timeout is waiting.
If it returns true (not false or nil) then the timeout will be auto-cancelled.
You can cancel a timeout with `(uism/clear-timeout! env timer-id)
18.11. Sending Events from one State Machine to Another
The mechanism for sending events from one state machine to another is the trigger method (with no !).
This version takes and returns a handler env, and is composed into the threading of env in your handlers:
(fn [env]
(-> env
(uism/trigger :state-machine-id :event-id {:data :map})
...))This has the effect of queueing the event for after the current handler has finished.
18.11.1. Nested Event Order
State machines that trigger events may cause handlers to run that themselves trigger further events. The ordering of such a cascade will be that of function call semantics. That is to say that if state machine A triggers an event on B and D, and B triggers an event on C, then the runtime evaluation order will be A, B, C, D.
18.11.2. Leveraging State Machine Local Storage
There are many times that you will want to send in "configuration" information to a state machine that should be remembered for the lifetime of that machine. For example if you have code that triggers events in other state machines you might want to pass the ID of the other state machine as a parameter when you start the new one:
(uism/begin! this SM ::sm-id actor-map {:other-machine :machine-id})You can then simply add a handler for the ::uism/started event that extracts this data and stores it in the state machine’s local store:
(uism/defstatemachine SM
{...
::uism/states {:initial
{::uism/events
{:uism/started
{::uism/handler
(fn [{::uism/keys [event-data] :as env}]
(let [{:keys [other-machine]} event-data]
(-> env
(uism/store :mid other-machine))))}}}}})That value is then available via (uism/retrieve env key) for the lifetime of that state machine.
18.12. Aborting Loads and Mutations
The built-in Fulcro support for aborting network requests requires the use of the actual application.
The general recommendation is to save your app into a defonce somewhere that can be required in any other file.
The state machine load/mutation system supports abort IDs by simply adding an :abort-id to the options map:
(uism/load env ::session (uism/actor-class env :session)
{:abort-id :abort/session-load
::uism/post-event :session-checked})You can then explicitly cancel such a request in the normal way (via your app) inside of your state machine handlers:
...
::uism/handler
(fn [env]
(when @my-app
(app/abort-request! my-app :abort/session-load))
env)The trigger-remote-mutation function also support abort IDs using the ::txn/abort-id key.
|
Tip
|
Aborting mutations is a risky business. Doing so leaves you in an unknown state since you don’t know how much the server actually saw or did; also, aborting the network request usually does not affect the server processing once the mutation has been sent. |
18.13. Parting Thoughts
This relatively small set of primitives gives you quite a bit of power. Here are some things you can do with this system that you might not immediately realize:
-
Associate Multiple Machines with a Control
You might have a state machine that is interested in tracking something like the autocomplete status of a dropdown. Another state machine could be tracking the overall state of the form that the autocomplete is embedded in.
-
Create a Library of Reusable Machines
We’ve mentioned this, but it bears repeating. Common patterns exist all over the place.
Take an autocomplete dropdown.
The behavior of waiting for some period of time between keystrokes before issuing a load, cancelling a load if the user starts typing again, showing/hiding the list of options and such can all be parameterized.
The loads load an actor with parameters.
This means the actual query and results for the load portion are controlled at begin!, not from within the state machine.
Various other aspects are also easy to make "tunable" by using the state machine’s local storage:
(defstatemachine dropdown-autocomplete
{::uism/actors #{:dropdown-control ...}
::uism/aliases {:options-visible? [:dropdown-control :ui/show-options?]
...}
::uism/states
{:initial {
::uism/events {::uism/started
{::uism/handler (fn [{::uism/keys [event-data] :as env}]
(uism/store env :params event-data)
...
...
(uism/begin! this dropdown-autocomplete :dropdown-car-make-sm
{:dropdown-control (uism/with-actor-class [:dropdown/id :car-make] Dropdown))}
{:dropdown-key-timeout 200})18.13.1. Form Validation
My initial experiments lead me towards the opinion that form validation does not generally belong in a state machine. Here are my reasons:
-
Rules around validation are often large and complex. This leads to a lot of states that become hard to follow.
-
The forms-state namespace in Fulcro does a nice job of tracking field state, letting you undo, diff, etc. It is much easier to "follow" validation at the UI layer, where it is also simpler to co-locate validity checks and messages with fields.
So, simple things like a login form might be ok to validate in the state machine, but larger forms should probably localize validation to the form itself.
There is one element that you will often need within the state machine: whether or not the form is currently valid.
Remember:
-
The
envin the state machine handler includes the current Fulcro state map as the key::uism/state-map. -
You can use
fdn/db→treeto convert a state map into a tree using a component’s class and ident. -
You can get an actor’s component class with
uism/actor-class. -
You can get an actor’s ident with
uism/actor→ident. -
The form-state support in Fulcro can give you a validity check based on the form props.
You can also pass specific event data when you trigger events, so you can trigger your own state change events (instead of using uism/set-value!) that include the current validity of the form.
19. Fulcro Raw (version 3.5+)
Various interested parties in the community were interested in using the full-stack data management facilities of Fulcro without necessarily being tied to React. Fulcro itself is written almost entirely in CLJC, and many of the namespaces work in CLJ just as well as they do in CLJS. The opens the door to all sorts of interesting possibilities:
-
Using Fulcro with libraries that take care of their own rendering, but would like to use the data management facilities.
-
Developing Desktop UIs with Fulcro and JVM libraries.
This support also leads to cleaner support in Fulcro itself for creating components that are detached from the data tree.
The two new namespaces that enable this are com.fulcrologic.fulcro.raw.application and com.fulcrologic.fulcro.raw.components.
|
Important
|
You MUST NOT use the old components or application namespace if you’re trying to avoid React. The raw versions of these namespaces have all of the functions found in the non-raw version, except for the ones that require React to operate. |
We will assume you are using the following aliases for these namespaces:
(ns some-ns
(:require
[com.fulcrologic.fulcro.raw.application :as rapp]
[com.fulcrologic.fulcro.raw.components :as rc]))19.1. Normalizing Components
At this point you should understand the normalization system of Fulcro very well. In order for Fulcro to integrate a tree of data into its database it must be able to determine (via an ident function) how to split apart the denormalized tree at each EQL join.
The defsc macro generates a React component, so using it in a non-React environment is not possible.
A new function called rc/nc is instead supplied that can generate anonymous (or named) component trees. It uses
the query and a naming conventions to be as succinct as possible:
(def Person (rc/nc [:person/id :person/name {:person/address [:address/id :address/street]}]))This generates two anonymous components, complete with query and ident. How does it get the ident function? It reads
the query and assumes any attribute whose name is id is both the name of the table for that item, and how to get the
id from an instance.
If this convention is not what you want, or you want to specify more options (including a component registry name), then
you can pass it a component options map as the second argument, and the API nests cleanly
(and technically also works with the standard defsc components as well):
(ns book.raw.normalizing-components
(:require
[com.fulcrologic.fulcro.raw.components :as rc]))
(def Address (rc/nc [:address/id :address/street]
{:componentName ::Address
:initial-state (fn [{:keys [id street]}] {:address/id id :address/street street})
:ident (fn [this props] [:address/by-id (:address/id props)])}))
(def Person (rc/nc [:person/id :person/name {:person/address (rc/get-query Address)}]))
(comment
(rc/get-ident Address {:address/id 1})
;; => [:address/by-id 1]
(rc/get-query Address)
;; => [:address/id :address/street]
(rc/get-initial-state Address {:id 42 :street "111 Main"})
;; => #:address{:id 42, :street "111 Main"}
(rc/component-name Address)
;; => "book.raw.normalizing-components/Address"
(rc/get-query Person)
;; => [:person/id :person/name #:person{:address [:address/id :address/street]}]
)|
Note
|
nc is a function not a macro. As such it does no magic interpretation of the
component options map. The initial-state and ident options must be functions, and of
course these are not React components, so things like :componentDidMount mean nothing
(unless you make them mean something in your own rendering system). Technically raw components
will work in standard React Fulcro, but they will not act as components that can be rendered.
|
These components, of course, have no idea how to render anything. They are purely artifacts that can be used to do data management (pulling props trees from the Fulcro database, issuing loads, etc.)
This means that you can be quite concise with things like a network load:
;; Load just the name and age of person with ID 42. No component def needed.
(df/load! app [:person/id 42] (rc/nc [:person/name :person/age]))If you’d like a macro version of this, version 3.6+ of Fulcro includes:
(defnc Person [:person/id :person/name {:person/address [:address/id :address/street]}])which will also give the component a name and make it compatible with dynamic queries. (It still isn’t a renderable
thing). The :ident option (3rd arg is options) can take special values like :constant and a single keyword
for generating the ident function. See the docstring for more details.
19.2. Raw Applications
Fulcro always requires that you define a Fulcro application. This is where remotes are defined, the client database is stored, transaction processing is customized, etc. Of course the Fulcro application doesn’t have to be your "master controller", since without React there is no user-driven event system or rendering. Instead, a raw Fulcro application is mainly a data management system.
The constructor in the raw application namespace specifically disables Fulcro’s rendering. You can specify a custom rendering system and turn rendering back on, but then you are responsible for figuring out what to do when Fulcro notifies you that something needs to be re-rendered.
Most applications that are using the pure data management facilities want something slightly different: notifications that some data tree of interest has changed.
19.2.1. Subscribing to Data
The raw application namespace has an add-component! and remove-component! function. These
allow you to add a watch on the props of a component, and receive a callback whenever those
props change.
|
Note
|
This is not a network subscription. If you have a network request that loads something that
a component is subscribed to, then it will be notified, but Fulcro does not do the network
request automatically, as it has no opinion on the database of the back-end at all. The lifecycle,
caching, and so forth are either trivial (e.g. just load the thing once if it isn’t there) or
quite complicated (e.g. load it, but only if I’m about to edit it or it is older than 10 seconds).
All of these behaviors are easy, in isolation, to get via df/load! and Fulcro websockets, if
the data arrives, the components will know it.
|
The basic operation usage is as follows:
(ns book.raw.adding-components
(:require
[com.fulcrologic.fulcro.raw.application :as app]
[com.fulcrologic.fulcro.raw.components :as rc]
[com.fulcrologic.fulcro.raw.application :as rapp]
[com.fulcrologic.fulcro.algorithms.merge :as merge]))
(def Address (rc/nc [:address/id :address/street]
{:componentName ::Address
:initial-state (fn [{:keys [id street]}] {:address/id id :address/street street})
:ident (fn [this props] [:address/by-id (:address/id props)])}))
(def Person (rc/nc [:person/id :person/name {:person/address (rc/get-query Address)}]
{:componentName ::Person
:initial-state (fn [_]
{:person/id 10
:person/name "Bob"
:person/address (rc/get-initial-state Address
{:id 20
:street "111 Main"})})}))
(def app (rapp/fulcro-app))
(comment
(rapp/add-component! app Person {:initialize? true
:keep-existing? true
:receive-props (fn [props]
(js/console.log props))})
;; Console output:
;;{:person/id 10, :person/name "Bob", :person/address {:address/id 20, :address/street "111 Main"}
(merge/merge-component! app Address {:address/id 20
:address/street "50 Broadway"})
;; Console output:
;;{:person/id 10, :person/name "Bob", :person/address {:address/id 20, :address/street "50 Broadway"}
(merge/merge-component! app Address {:address/id 20
:address/street "50 Broadway"})
;; NO CONSOLE OUTPUT. Props didn't *actually* change
)Any transactional operation (transact!, merge-component!, load!, etc.) will cause
such a callback, but only if the props actually change. This means you get the basic
shouldComponentUpdate optimization for free!
19.2.2. Supported Namespaces in Raw Mode
The vast majority of Fulcro’s namespaces work with a raw application (and all of the raw versions of things work in standard React Fulcro applications).
The exceptions are the ones that tie to anything related to a DOM or browser.
Notable exceptions that do not work with Raw Fulcro applications:
-
com.fulcrologic.fulcro.dom* -
com.fulcrologic.fulcro.routing.dynamic-routing -
com.fulcrologic.fulcro.networking.file-upload -
com.fulcrologic.fulcro.networking.file-url -
com.fulcrologic.fulcro.react.* -
com.fulcrologic.fulcro.rendering.* -
com.fulcrologic.fulcro.application(raw.applicationis the raw version) -
com.fulcrologic.fulcro.components(raw.componentsis the raw version)
|
Note
|
The ui-state-machines namespace does work; however, any actors defined in a UISM must include a
:componentName option (i.e. use the rc/defnc macro), so that they will appear in the global component registry.
|
19.2.3. Dynamic Queries with Normalizing Components
Any component that needs to use a dynamic query must be in the global registry, and therefore must include
the :componentName option. Otherwise, normalizing components should work (at a class-level at least) with
the dynamic query API.
19.3. Raw APIs in Normal Fulcro
The non-raw namespaces actually just refer to the raw versions when possible to avoid code duplication, so all
of these APIs work perfectly fine in regular Fulcro. So, you can actually use add-component! in a normal
Fulcro application. The problem is that normal component-based React does not expect you to move props around
outside of the normal rendering mechanisms.
Fortunately, more recent versions of React include the Hooks API. The hooks API lets you build components
from simple functions (See the React documentation), and Fulcro’s com.fulcrologic.react.hooks namespace
has wrappers for the standard hooks calls, but also includes some lovely integrations that make writing
Fulcro hooks-based components very nice.
19.4. Fulcro Hook Components from Vanilla React
Classic Fulcro requires that you use the application as a container for your application. This means that the best you can do for integrating a Fulcro-controlled component into a vanilla React app is to have React generate an element that Fulcro can then be mounted on. This is sub-optimal for this kind of integration.
The new hooks support makes this use-case much easier and more flexible.
(ns book.raw.fulcro-hooks
(:require
["react" :as react]
["react-dom" :as rdom]
[book.macros]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.mutations :refer [defmutation]]
[com.fulcrologic.fulcro.raw.application :as rapp]
[com.fulcrologic.fulcro.raw.components :as rc]
[com.fulcrologic.fulcro.react.hooks :as hooks]))
;; NOTE: RAW Fulcro App, even though we're using React, because we're not going to leverage
;; Fulcro's rendering integration, but instead are just writing a RAW function using hooks.
(defonce app (rapp/fulcro-app {:id "raw-fulcro-hooks"}))
;; Makes it possible to focus inspector from book
(swap! book.macros/app-registry assoc "raw-fulcro-hooks" app)
(defmutation make-older [{:person/keys [id]}]
(action [{:keys [state]}]
(swap! state update-in [:person/id id :person/age] inc)))
(defmutation change-street [{:address/keys [id street]}]
(action [{:keys [state]}]
(swap! state assoc-in [:address/id id :address/street] street)))
(def person-component
(rc/nc [:person/id :person/name :person/age
{:person/address [:address/id :address/street]}]
{:initial-state (fn [{:keys [name address]}]
{:person/id 1
:person/name name
:person/age 25
:person/address {:address/id 10
:address/street address}})}))
(defn Person [props]
(let [{:person/keys [id name age address]} (hooks/use-component app person-component
{:keep-existing? true
:initialize? true
:initial-params {:name "Bob" :address "111 Main"}})
{:address/keys [street]} address]
(let []
(dom/div
(dom/p (str name " lives at " street " and is " age " years old."))
(dom/button
{:onClick #(rc/transact! app [(make-older {:person/id id})])}
(str "Make " name " older!"))
(dom/button
{:onClick #(rc/transact! app
[(change-street {:address/id (:address/id address)
:address/street (str
(rand-int 100)
" "
(rand-nth ["Broadway"
"Main St."
"3rd Ave."
"Peach Ln."]))})])}
(str "Move " name "!"))))))
(defn ui-person
"A low-level plain React factory function."
[] (react/createElement Person nil nil))
;; Render directly as a raw React component! The book has a div with that ID in this example block.
;; Mutations on the app will cause localized render of the dynamic content
(defonce _ (rdom/render (ui-person) (js/document.getElementById "raw-fulcro-hooks")))The hooks/use-component React effect hook connects you to the props of the component via add-component! internally,
but it also hooks that callback up to React state so that refresh will work properly. You still get the
optimization that the component will not re-render unless the props it has actually queried for have
changed.
These usages of component state can be embedded via raw js React (as shown), or within other components that Fulcro is managing directly. This is particularly useful for components that spring into existence in an ad-hoc manner during the dynamic runtime of your application.
19.5. Dynamic Lifecycle
There is also an effect hook for generating a random UUID (and also doing garbage collection on it) that can be combined with the above APIs so that you can be as dynamic as you want to be:
(ns book.raw.dynamic-hooks
(:require
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.application :as app]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.react.hooks :as hooks]))
(declare AltRootPlainClass app)
(defsc DynamicChild [this {:keys [:other/id :other/n] :as props}]
{:query [:other/id :other/n]
:ident :other/id
:initial-state {:other/id :param/id :other/n :param/n}}
(dom/div
(dom/button
{:onClick #(m/set-integer! this :other/n :value (inc n))}
(str n))))
(def ui-dynamic-child (comp/factory DynamicChild {:keyfn :other/id}))
(defsc Container [this props]
{:use-hooks? true}
(let [id (hooks/use-generated-id) ; Generate a random ID
other-props (hooks/use-component (comp/any->app this) DynamicChild
{:initialize? true
:keep-existing? false
:initial-params {:id id :n 1}})]
;; Install a GC handler that will clean up the generated data of OtherChild when this component unmounts
(hooks/use-gc this [:other/id id] #{})
(ui-dynamic-child other-props)))
(def ui-container (comp/factory Container))
(defsc Root [this _]
{}
(let [show? (comp/get-state this :show?)]
(dom/div
(dom/button {:onClick (fn [] (comp/set-state! this {:show? (not show?)}))} "Toggle")
(when show?
(ui-container {})))))In the example above we don’t even define a root query! Root renders the container just by calling the factory. We use component-local state to decide if we want to render the container.
The container uses the various hooks effects and state management to join in a proper Fulcro-managed component that is sprung into existence on mount, and cleaned up on unmount!
Be sure to open Inspect and focus the inspector while you play with this demo. When you toggle the container into view, you’ll see the button’s state appear at a random ID. Using the button works normally. Toggling the container off will clean up the state.
19.6. UI State Machines via Raw or Hooks (Fulcro 3.5+)
The UI State Machine support has a new function called uism/add-uism! that is much like rapp/add-component!. It
is not tied to React in any way, but allows you to associate normalizing components as actors in a UISM
model, and retrieve the props for these actors as they change.
The add-uism! is callback-based, and of course there is a hooks/use-uism stateful effect hook that provides
an easy way to use it from React.
The basic ideas are simple:
-
You define the state machine and actors. The state machine usage is exactly as described in the chapter on UISM
-
The hooks-based and raw usages hook you to the current state and actor values in the state machine.
So, for example, let’s say you had an actor called :actor/form. The API call (from a hooks component):
(let [{:keys [current-state actor/form]} (use-uism app some-machine-def :machine-id
{::uism/actors {:actor/form MyForm}})]
...)acts as an effect/state hook that will initialize the state machine definition under the id :machine-id (or trigger
an :event/remounted event if it was already started on the first call or component remount).
It returns :current-state which is the current state the machine is in, along with each actor’s props.
The return value is similar to the useState hook: it will automatically cause a re-render when the value changes.
Here’s a working example that emulates login (this is a half-baked implementation, but it gets the point across):
(ns book.raw.raw-uism
(:require
[com.fulcrologic.fulcro.algorithms.data-targeting :as dt]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom :refer [div p input button h2 label]]
[com.fulcrologic.fulcro.dom.events :as evt]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.raw.components :as rc]
[com.fulcrologic.fulcro.react.hooks :as hooks]
[com.fulcrologic.fulcro.ui-state-machines :as uism]
[com.wsscode.pathom.connect :as pc]
[taoensso.timbre :as log]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Mock Server and database, in Fulcro client format for ease of use in demo
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defonce pretend-server-database
(atom
{:account/id {1000 {:account/id 1000
:account/email "bob@example.com"
:account/password "letmein"}}}))
;; For the UISM DEMO
(defonce session-id (atom 1000)) ; pretend like we have server state to remember client
(pc/defresolver account-resolver [_ {:account/keys [id]}]
{::pc/input #{:account/id}
::pc/output [:account/email]}
(select-keys (get-in @pretend-server-database [:account/id id] {}) [:account/email]))
(pc/defresolver session-resolver [_ {:account/keys [id]}]
{::pc/output [{:current-session [:account/id]}]}
(if @session-id
{:current-session {:account/id @session-id}}
{:current-session {:account/id :none}}))
(pc/defmutation server-login [_ {:keys [email password]}]
{::pc/sym `login
::pc/output [:account/id]}
(let [accounts (vals (get @pretend-server-database :account/id))
account (first
(filter
(fn [a] (and (= password (:account/password a)) (= email (:account/email a))))
accounts))]
(when (log/spy :info "Found account" account)
(reset! session-id (:account/id account))
account)))
(pc/defmutation server-logout [_ _]
{::pc/sym `logout}
(reset! session-id nil))
(def resolvers [account-resolver session-resolver server-login server-logout])
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Client.
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def global-events {:event/unmounted {::uism/handler (fn [env] env)}})
(uism/defstatemachine session-machine
{::uism/actor-names
#{:actor/login-form :actor/current-account}
::uism/aliases
{:email [:actor/login-form :email]
:password [:actor/login-form :password]
:failed? [:actor/login-form :failed?]
:name [:actor/current-account :account/email]}
::uism/states
{:initial
{::uism/handler (fn [env]
(-> env
(uism/apply-action assoc-in [:account/id :none] {:account/id :none})
(uism/apply-action assoc-in [:component/id ::LoginForm]
{:component/id ::LoginForm :email "" :password "" :failed? false})
(uism/load :current-session :actor/current-account {::uism/ok-event :event/done
::uism/error-event :event/done})
(uism/activate :state/checking-session)))}
:state/checking-session
{::uism/events
(merge global-events
{:event/done {::uism/handler
(fn [{::uism/keys [state-map] :as env}]
(let [id (some-> state-map :current-session second)]
(cond-> env
(pos-int? id) (->
(uism/reset-actor-ident :actor/current-account [:account/id id])
(uism/activate :state/logged-in))
(not (pos-int? id)) (uism/activate :state/gathering-credentials))))}
:event/post-login {::uism/handler
(fn [{::uism/keys [state-map] :as env}]
(let [session-ident (get state-map :current-session)
Session (uism/actor-class env :actor/current-account)
logged-in? (pos-int? (second session-ident))]
(if logged-in?
(-> env
(uism/reset-actor-ident :actor/current-account (uism/with-actor-class session-ident Session))
(uism/activate :state/logged-in))
(-> env
(uism/assoc-aliased :failed? true)
(uism/activate :state/gathering-credentials)))))}})}
:state/gathering-credentials
{::uism/events
(merge global-events
{:event/login {::uism/handler
(fn [env]
(-> env
(uism/assoc-aliased :failed? false)
(uism/trigger-remote-mutation :actor/login-form `login {:email (uism/alias-value env :email)
:password (uism/alias-value env :password)
::m/returning (uism/actor-class env :actor/current-account)
::dt/target [:current-session]
::uism/ok-event :event/post-login
::uism/error-event :event/post-login})
(uism/activate :state/checking-session)))}})}
:state/logged-in
{::uism/events
(merge global-events
{:event/logout {::uism/handler
(fn [env]
(let [Session (uism/actor-class env :actor/current-account)]
(-> env
(uism/apply-action assoc :account/id {:none {}})
(uism/assoc-aliased :email "" :password "" :failed? false)
(uism/reset-actor-ident :actor/current-account (uism/with-actor-class [:account/id :none] Session))
(uism/trigger-remote-mutation :actor/current-account `logout {})
(uism/activate :state/gathering-credentials))))}})}}})
(def LoginForm (rc/nc [:component/id :email :password :failed?]
{:componentName ::LoginForm
:ident (fn [] [:component/id ::LoginForm])}))
(def Session (rc/nc [:account/id :account/email] {:componentName ::Session}))
(defsc MainScreen [this props]
{:use-hooks? true}
(let [app (comp/any->app this)
{:actor/keys [login-form current-account]
:keys [active-state] :as sm} (hooks/use-uism app session-machine :sessions
{::uism/actors {:actor/login-form LoginForm
:actor/current-account (uism/with-actor-class [:account/id :none] Session)}})
{:keys [email password failed?]} login-form
checking? (= :state/checking-session active-state)]
(if (= :state/logged-in active-state)
(div :.ui.segment
(dom/p {} (str "Hi," (:account/email current-account)))
(button :.ui.red.button {:onClick #(uism/trigger! app :sessions :event/logout)} "Logout"))
(div :.ui.segment
(dom/h5 :.ui.header "Username is bob@example.com, password is letmein")
(div :.ui.form {:classes [(when failed? "error")
(when checking? "loading")]}
(div :.field
(label "Email")
(input {:value (or email "")
:onChange (fn [evt] (m/raw-set-value! app login-form :email (evt/target-value evt)))}))
(div :.field
(label "Password")
(input {:type "password"
:onChange (fn [evt] (m/raw-set-value! app login-form :password (evt/target-value evt)))
:value (or password "")}))
(div :.ui.error.message
"Invalid credentials. Please try again.")
(div :.field
(button :.ui.primary.button {:onClick (fn [] (uism/trigger! app :sessions :event/login {}))} "Login")))))))
(def ui-main-screen (comp/factory MainScreen))
(defsc Root [this _]
{}
;; NOTE: Hooks and Root without a query don't mix well, so we push the example down one level.
(ui-main-screen {}))20. Dynamic Queries
Fulcro supports dynamic queries: the ability to change the query of a component at runtime. This feature is fully serializable (works with the support viewer and other time-travel features), and is necessary for code splitting since the parent component won’t be able to compose in the child’s query until it is loaded.
20.1. Query IDs
For dynamic queries to work right they have to be stored in your application database and every aspect of them must be serializable. Additionally, the UI must be able to look them up at the component level in order to do optimal refresh. The solution to this is query IDs. A query ID is a simple combination of the component’s fully-qualified class name combined with a user-defined qualifier (which defaults to the empty string).
Since this qualifier is needed both in the code that obtains queries (get-query) and in the UI rendering (the factory that draws that component), it is easiest to locate the qualifier in the UI factory itself.
This allows you to have instances of a class that can have different queries:
(defsc Thing ...)
(def ui-thing (comp/factory Thing)) ; query ID is based solely on the class itself (with no qualifier)
(def ui-thing-1 (comp/factory Thing {:qualifier :a})) ; query ID is derived from Thing plus the qualifier :a
(defsc Parent [this props]
{:query (fn [] [{:child (comp/get-query ui-thing-1)}])}
...)In the above example one can now set the query for Thing, or "Thing with qualifier :a".
The following live demo shows dynamic queries in action:
(ns book.queries.dynamic-queries
(:require
[com.fulcrologic.fulcro.dom :as dom]
[goog.object]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.mutations :as m]))
(declare ui-leaf)
; This component allows you to toggle the query between [:x] and [:y]
(defsc Leaf [this {:keys [x y]}]
{:initial-state (fn [params] {:x 1 :y 42})
:query (fn [] [:x]) ; avoid error checking so we can destructure both :x and :y in props
:ident (fn [] [:LEAF :ID])} ; there is only one leaf in app state
(dom/div
(dom/button {:onClick (fn [] (comp/set-query! this ui-leaf {:query [:x]}))} "Set query to :x")
(dom/button {:onClick (fn [] (comp/set-query! this ui-leaf {:query [:y]}))} "Set query to :y")
; If the query is [:x] then x will be defined, otherwise it will not.
(dom/button {:onClick (fn [e] (if x
(m/set-value! this :x (inc x))
(m/set-value! this :y (inc y))))}
(str "Count: " (or x y))) ; only one will be defined at a time
" Leaf"))
(def ui-leaf (comp/factory Leaf {:qualifier :x}))
(defsc Root [this {:keys [root/leaf] :as props}]
{:initial-state (fn [p] {:root/leaf (comp/get-initial-state Leaf {})})
:query (fn [] [{:root/leaf (comp/get-query ui-leaf)}])}
(dom/div (ui-leaf leaf)))20.2. Setting a Query
The whole point of a dynamic query is being able to set the query to something new on a component.
This has one critical component that you must be very careful with: normalization.
A component’s query is augmented with metadata that marks which component is used to normalize (via idents) the entity found for the given portion of the query that it handles.
Therefore, you must still use get-query to pull the query for portions of your subquery that you wish to include when setting a new query.
If done incorrectly then normalization will not work correctly on these components.
The top-level metadata will be added for you, so this is fine:
(defmutation change-a-query [_]
(action [{:keys [state]}]
(swap! state comp/set-query* B {:query [:MODIFIED]}))but as soon as there’s a join you must ensure the subqueries have the correct metadata.
This means that the following is incorrect (because [:x] probably goes with some other normalized component):
(defmutation change-a-query [_]
(action [{:keys [state]}]
(swap! state comp/set-query* B {:query [:MODIFIED {:subquery [:x]}]}))instead, you should use get-query with a state parameter to pull the query for a given component.
So, say you wanted to change the query for this:
(defsc X [_ _]
{:query [:id :name]
:ident [:x/id :id]})
(defsc A [_ _]
{:query [:id {:x (comp/get-query X)}]
:ident [:a/id :id]})and you want to change both component’s queries. The correct form for the resulting mutation is:
(defmutation change-a-query [_]
(action [{:keys [state]}]
(swap! state (fn [s]
(as-> s state-map
(comp/set-query* state-map X {:query [:id :address]})
(comp/set-query* state-map A {:query [:id :new-prop {:x (comp/get-query X state-map}]}))))))There is also a top-level API call comp/set-query! if you want to change a query outside of a mutation.
20.3. Hot Code Reload and Dynamic Queries
Dynamic queries are stored in app state. This means that if you use dynamic queries then hot code reload will not
see your static query changes to components automatically. The solution was either to reset the queries manually with
new calls to set-query! (nobody ever did this) or reload the entire page.
In order to make this work better, you need to understand how dynamic queries work:
-
The children of a query are normalized into app state.
-
Joins point to the normalized value of the child queries.
So, Fulcro closes over the tree of queries, even when you just set something on a local component (every join child has to be tracked, or you could then not reliably set a query on a child).
Needless to say, reloading the app is not a great dev experience.
We note an important (and easy to leverage) fact to fix this. We only care to keep the query for components that have their query dynamically set. This children are closed over as a matter of necessity. We can safely refresh those (static query) children without hurting our actual application operation.
As of Fulcro 3.3.0 there is a utility function that can be used in your hot code reload refresh function that
can refresh queries: (comp/refresh-dynamic-queries! app). This function scans the app state for dynamic queries
and resets the app state version to the static version.
By default it will skip any component that has a :preserve-dynamic-query? true option set on it:
(defsc MyThing [this props]
{:preserve-dynamic-query? true
...})Dynamic routers now set this option, so they will not be affected by hot reload query refresh. If you use dynamic queries on a component, then it is likely you’ll want to mark them as well.
21. Dynamic Router
The dynamic router in Fulcro 3 uses dynamic queries to change the route, and was designed with the following requirements in mind:
|
Note
|
Fulcro 3.1.23 and above added change-route! and change-route-relative! as new names for the old change-route
and change-route-relative. The old names still exist but are deprecated.
|
- Composition
-
Routers should compose in a flexible manner that includes the easy ability to refactor the application and restructure.
- There should be a way to complete network operations before moving to a given route
-
This should be a chain of operations that is derived from the target routers themselves (or their children?).
- UI Code should be able to prevent a route change
-
E.g. say there are unsaved changes on some page in a tree: a UI component must be able to "hook into" the routing system in order to prevent changes. NOTE: This is not a feature of the routers, but a feature of the content under a router. This can be modelled as a global concern, since routing (esp. that involves URI changes) is a global concern.
- Code Splitting
-
A complete routing system for SPAs should make it easy to do code splitting at particular routes so that an initial load of the application need not load the code for every feature.
- DRY
-
It should not be necessary to repeat the "route path" as an external data structure when it matches the UI structure. The UI composition itself can easily act as a "default" routing path structure.
- URI <-> UI Routes should be flexible and able to "alias"
-
Reshaping the URI can be done by optional functions that sit in-between browser URI and code.
- Navigable Code
-
During development it should be easy to see (as local concerns) what happens along a given UI route. Code navigation (jumping from root through subcomponents) should make it trivial to understand all routing concerns. Route "operations" like loading should be co-located with the components that act as routing targets.
- Introspection
-
One should be able to query for the available routes (of loaded code), and the current visible route.
21.1. Routers
Dynamic routing in Fulcro can be easily facilitated by leveraging the UI query, which is a tool of composition that is always guaranteed to be present in a properly-structured application. Each component’s state will be normalized, and the class and relative UI position can be determined by examining the current UI query.
Take the following UI layout:

The routers in this system can easily be autogenerated by a macro that is given nothing more than the classes of the components that are the targets of routing (i.e. User, Settings, etc.).
The macro can simply compose them together into a component that has a dynamic query whose "current route" points to the first class listed (marked with D in the diagram).
If the given router is to be shown on initial startup, then these default routing targets must be singletons (have an ident that does not depend on their props).
This delegates the novelty of routing targets to the target itself. Interestingly, this is quite convenient for composition and refactoring. The router is not programmed with any foreknowledge of the routing novelty of a target…only it’s symbolic name!
(defrouter RootRouter [this props]
{:router-targets [Settings User]})
(def ui-root-router (comp/factory RootRouter))
(defrouter SettingsRouter [this props]
{:router-targets [Pane1 Pane2]})
(def ui-settings-router (comp/factory SettingsRouter))The parameter list (this and props) are used with deferred routing, explained below.
The use of query scanning and dynamic queries for routing mean that you can easily add or remove a sub-route just by moving the symbol to a different router.
Such routers are simple Fulcro components, and can be composed into the UI just like any other components. The initial state parameters passed to such a router are forwarded to the first listed router target (if it has initial state).
|
Important
|
Routers are true singletons. A router ends up with a dynamic query keyed by the class itself. This means that a given router cannot be used in a UI in more than one place. This seems like a reasonable restriction given that they are so simple to declare at a given tree (sub)root, and are typically very positional in nature. |
21.2. Routing Targets
Most of the novelty about routes can now be encoded into normal components with simple declarations.
(ns app
(:require
...
[com.fulcrologic.fulcro.routing.dynamic-routing :as dr :refer [defrouter]]))
(defsc X [this props]
{...
;; the portions of the path that this component represents. typically just one, or one with params
:route-segment ["path"]
;; optional: defaults to the component's ident (singletons only)
:will-enter (fn [app route-params] ...defer or immediate...)
;; optional, defaults to nothing
:route-cancelled (fn [route-params] ...called if deferred route to here is cancelled before it completes...)
;; optional, defaults to true
:will-leave (fn [this props] ...return true or false to accept being removed from screen...)]}
(dom/div ...)):route-segment-
A (relative) path segment that this component can "consume" from an incoming route. This is purely static data. The current composition of routing targets in the UI determines the overall "absolute" path of a route. Each
routerin the UI should be thought of as a stand-in for a "/" in an HTML5 URI path. MUST contain only strings and keywords. :will-enter-
A notification that this route target will be shown. Can return a value indicating a desire to do so immediately, or that it would like a delay (for some I/O). This method is called before the component is on-screen, so it cannot receive a react component instance. It is passed the app and router parameters which can be used to do things like issues loads and run mutations. Defaults to
(route-immediate (get-ident class {}))Theparamspassed to the function will include the declared params in the route, along with any extra items in the timeouts-and-params option ofchange-route!andchange-route-relative!(extra parameter support requires v3.1.23+). :route-cancelled-
A notification that this route target was in a deferred state but the user made some other routing decision during that delay. This can be used to cancel heavy I/O operations for this target. Defaults to no-op.
:will-leave-
A method that can prevent a route change that causes this component to leave the screen. This is called on the instance, so
thisandpropsare available. A request to change routes will signal this method from deepest child towards the parent, and will stop if any returns false. Optional. WARNING: As of v3.1.23 this function’s return value is deprecated.:allow-route-change?should be used for that functionality. When using this new techniquewill-leaveis a promise, not a request. If you don’t haveallow-route-change?then the return value of this function is still used, but a deprecation warning will be shown in the console. :allow-route-change?-
v3.1.23+. A
(fn [this] boolean?)that must not side effect. Takes over HALF of the responsibility of:will-leaveand should be side-effect free. When using this:will-leaveshould be considered a promise (not a request). :route-denied-
v3.1.23+. Can be placed on route targets. Will be called when that target’s
allow-route-change?has returnedfalse, and dynamic routing was trying to route. This allows the separation of concerns: the ability for any code to ask if route changes are allowed, and the ability for routing to tell a particular target that it was responsible for a failure. This(fn [this router relative-path])can side-effect to issue UI messages, and can also do things like usejs/confirmto override its decision usingdr/retry-route!.
|
Warning
|
will-enter can be called multiple times as part of the route resolution algorithm and MUST NOT side-effect.
Any I/O must be done in the lambda passed to route-deferred, which
must then trigger the dr/target-ready mutation to indicate that the route is ready.
You can use plain transact!
to start a mutation within route-deferred, and the mutation can use target-ready! to send the signal.
|
Route targets can be singletons or regular components that have multiple instances.
In the latter case you must be sure that the ident returned from will-enter points to valid data in state by the time the route is resolved.
21.3. Initial Route
The dynamic routing relies on a call to change-route! in order to start the routing system. You can use dr/initialize!
to ensure that the state machines for all routers that can be found in the current query are started at application startup,
but your application will be in an "unrouted" state until you explicitly set a route!
Therefore you MUST make a call to change-route! on start in order for the dynamic routers to work; however, there is
also the concern of what gets rendered on the "first frame" of application mount (before you’ve had a chance to
call change-route!).
Your top-most router will be in an "uninitialized" state on initial load. You can use the body of that router to render the "first frame" of your mounted app:
(defrouter RootRouter2 [this {:keys [current-state] :as props}]
{:router-targets [Settings User]}
(case current-state
:pending (dom/div "Loading...")
:failed (dom/div "Failed!")
;; default will be used when the current state isn't yet set
(dom/div "No route selected.")))If you are doing SSR, then you will need to simulate calling change-route! there.
The function
dr/ssr-initial-state (written, but untested) can be used to help you construct the proper state for a given path (which must be used for the server-side render, and also as the initial state for the client).
Technically, this means that the function can also be used to generate initial state for the client on the front-end as well.
21.3.1. Setting the Route Early
Fulcro applications are capable of running "headless". In general we recommend you actually start your app before mounting it, set up your routes and perhaps even do some initial loads, then mount the application. This will ensure a more consistent (and less flickering) user experience.
You can do this as follows:
(defonce SPA (app/fulcro-app ...))
(defn start []
(app/set-root! SPA ui/Root {:initialize-state? true})
(dr/change-route! SPA ["landing-page"])
(app/mount! app ui/Root "app" {:initialize-state? false}))An even better approach is to use state to block rendering until such time as a route or load is ready just by looking at the current state of your top-most router’s state machine.
-
Query for the router’s state machine in order to be able to ask the current state.
-
The active state may be nil (not started)
-
For nil or :initial state, simply don’t render the router.
(defrouter RootRouter ...)
(def ui-router (comp/factory RootRouter))
(defsc Root [this {:root/keys [router]}]
{:query [{:root/router (get-query RootRouter)}
;; The UISM id of a router's state machine is just the FQ keyword name of the router's class
[::uism/asm-id ::RootRouter]]}
(let [top-router-state (or (uism/get-active-state this ::RootRouter) :initial)]
(if (= :initial top-router-state)
(dom/div :.loading "Loading...")
(ui-router router))))21.4. Composing the Router’s State into the Parent
It is essential for correct first-frame rendering that the router’s (initial) state is composed into its parent’s (initial) state. Then there also always needs to be an "edge" from the parent’s data to the child router.
If the parent’s data is loaded dynamically, you must make sure to create this edge manually. Typically with :pre-merge, like here:
(defsc Settings [this {:settings/keys [panes-router]}]
{:query [{:settings/panes-router (comp/get-query SettingPanesRouter)} ...]
:initial-state {:settings/panes-router {}} ; (1)
;; ...
:pre-merge (fn [{:keys [data-tree state-map]}]
(merge (comp/get-initial-state Settings) ; (2)
{:settings/panes-router (get-in state-map (comp/get-ident SettingPanesRouter {}))} ; (3)
data-tree)) ...}
(ui-settings-panes-router panes-router))-
Include the router’s initial state in the parent’s initial state
-
Include the router’s initial state in the dynamically-loaded state to ensure an edge between the two
-
Make sure to preserve any state the router might already have
21.5. Controlling the Route Rendering
As of Fulcro 3.1.16 you can optionally take complete control of the rendering of the router itself. Simply add the
:always-render-body? option, and then use the information from the router props to render what you want:
(defrouter TopRouter [this {:keys [current-state route-factory route-props]}]
{:router-targets [signon/Login signon/PasswordReset RootScreen]
:always-render-body? true}
(div :.container
;; Show an overlay loader on the current route when we're routing
(when (not= :routed current-state)
(div :.ui.active.inverted.dimmer
(div :.ui.text.loader
"Loading")))
(when route-factory
(route-factory (comp/computed route-props (comp/get-computed this))))))of course you could augment the computed props to the target route, etc.
21.6. Route Segments and Changing Routes
UI Composition determines the available routes, and each route target must declare what part of the current "route" they can consume. The declaration is a vector of literal strings and keywords:
["user" :user-id]Strings in the route segment MUST exactly match an incoming path prefix or the route does not match.
The keyword parameters are route parameters, and capture the incoming route element as a string (this ensures that URI’s will work just as well as code-based paths that might contain other data types).
Any data types you pass in the vector are converted via str, so if you need a more complicated coercion please do it before using it to change the route.
Path segments compose in the UI. In our earlier diagram the Settings component might have the route segments: ["settings"] and the User component ["user" :user-id]". The `Pane2 component might list ["pane1"].
Now, since the pane 1 component is currently nested as a target of the router underneath the settings component, we can derive that the full path to Pane 1 in this particular UI layout is ["settings" "pane1"].
This is the next critical step in our composition:
Routers in a tree look for targets that can consume what remains of the path after parent targets have consumed the portion that matched those route segments.
Hopefully you can see how this directly matches the necessary logic for HTML5 URI routing. The following URIs are trivial to convert between the two forms:
"/settings/pane1" <==> ["settings" "pane1"]
"/user/1" <==> ["user" "1"]This mechanism makes routing as simple as "read the URI, split the string, and call a function".
The function to cause a route change is:
(dr/change-route! this ["user" "1"])and it always starts from the root of your application and causes a full update of the correct route.
Notice that since the command to control the route is up to you, so is the path you pass to it. This makes it easy to do things like alias one path found in the URI to a different UI path, which is useful when you restructure the real UI but would like to maintain support for old paths that users may have bookmarked.
Additional useful functions are:
(current-route! component-or-app starting-component)-
Returns a vector of the path components on the current (live) route starting at the given
starting-component. If you use your root component it will be the absolute path, and using some other component router will give the relative path from there. (change-route-relative! this-or-app relative-class-or-instance new-route timeouts)-
Just like
change-route!, but can take a relativenew-routeand apply it starting and the givenrelative-class-or-instance. Thus, some module of a program can route in a relative manner which will further decouple the components, making it easier to use a module in a development card or refactor it to a different location in the app without breaking local concerns. (path-to components-and-args)-
Returns a route path vector (e.g.
["user" 1]), but derives it from the UI target classes. This function is about making your code for routing IDE-navigable. See below.
|
Note
|
This library will not have any code that connects HTML5 routing events to UI routing. That is a relatively simple exercise and there are plenty of libraries that can help with the task. The logic of transforming a URI to the correct vector and calling a function is trivial, and the concern of aliasing and legacy path transforms is something you will likely want to put in the middle of that. |
In Fulcro 3.4.2 change-route-relative! gained the ability to route relative to this:
(change-route-relative! this this [:.. "sibling-segment"])The special keyword :.. can be repeated at the start of the new path just like in filesystem navigation.
21.6.1. Partial Routes
A source of potential confusion is how dynamic routing will behave when you give it an "incomplete" path on a routing request. It is part of the intentional design to allow you to do this, but it can result in bad behavior if you misuse it.
The actual behavior of the system is very simple and easy to understand:
-
A request to affect a route is always relative (
change-route!is relative to your application’s root). -
We only trigger routing events on the specific routers and targets that are included in the destination path.
This allows for much richer composition, including the ability for multiple routers to be on-screen at the same time; however, it also means that it is easy for you to confuse yourself by not routing to a real "leaf".
Say you’ve got the example we listed earlier:
and you route to ["settings"] but you fail to add a path segment that matches either pane. This is a legal operation,
but the implicit instruction is "Change the top level route, but don’t touch the route that settings is currently
pointing to". The problem is that if you’ve never asked for a route from the nested settings router then it has
never seen a will-enter event. It is in an "undefined" state (and in fact may not even have a running state machine).
The generalized support for router composition adds this unavoidable element of complexity, but the logic for working with it is rather simple:
Every router must be given an initial routing instruction, which you must issue in order to get the correct behavior for your use-case.
The easiest way to always satisfy this rule is to use paths in routing instructions that include an ultimate leaf target.
If you were following this rule in the above example then you’d issue routes like ["settings" "pane1"] and never
["settings"]. Note, however, that in relative routing it’s perfectly fine to do
(change-route-relative! this Settings ["pane1"]), since that names an ultimate leaf in the routing tree.
There are other strategies that can work as well. For example you could pre-issue relative routing instructions at application startup for any nested routers. An off-screen router can be told to route without affecting the on-screen result.
(defn start []
(app/mount ...)
;; Routers do *not* have to be on-screen in order to handle a relative route change.
(dr/change-route-relative! SPA Settings ["pane1"])
(dr/change-route-relative! SPA SomeOtherThing ["some-child"])
(dr/change-route-relative! SPA TheOtherOtherThing ["that-other-child"])
...)Or you could change-route-relative! in the dr/route-deferred of a ancestor target’s :will-enter, if there is one.
(Just beware infinite transaction loops.)
21.6.2. Targets Denying Routes v3.1.23+
In versions prior to 3.1.23 the return value of :will-leave was used to allow an on-screen target to indicate it
did not want to be removed from the screen. This allowed applications to prevent routing that would cause the user
to lose unsaved changes.
Unfortunately, the mixture of "notifying a target it will leave" and "asking a target if it is OK to leave" led
to complexity, and in Fulcro 3.1.23 the behavior of :will-leave was updated. For backwards
compatibility it still works as it did for legacy code, but as soon as you add :allow-route-change? its return value
is no longer used.
The new behavior is as follows:
-
If a target has
:allow-route-change?, then it can be used to obtain a purely an advisory value. The new functiondr/can-change-route?will use that to provide your code with an answer that can be used anywhere in your logic to check if routing is going to be denied. This is really useful when integrating with HTML5 routing. -
When a request to change routes is sent to the dynamic routing, it will find the first target that says "no" to this question (using
will-leaveas a backup toallow-route-change?). It will then check to see if that target has a:route-deniedfunction. If so, it will call that to inform the target that it was the reason that a request to change routes was denied.:route-deniedis allowed to side-effect.
The helper function retry-route! can be using in (and only in) route-denied to indicate that the target changed
its mind, and wants to allow the route after all. It will receive this, the relative router used in the request,
and the desired path.
21.6.3. IDE-Navigable Routing
Routes are expressed as strings in the URL (e.g. /user/1) and as vectors of strings to the dynamic router (e.g. a
split on / of the URL: ["user" "1"]`); however, seeing this in some arbitrary location in your code:
(change-route! this ["root" "settings" "user" "1"])can be quite painful for the person editing the code even a few minutes after writing it. When you’re reading this line of code the only question you’ll typically have is "OK, which ones of those are route targets, and where are they?".
But remember: our targets have their route segments declared as data, so it is trivial to transform this to something that is a lot easier to manage. Assume you had the following classes in various files:
(ns com.example.root)
(defsc MyIndex [_ _]
{:route-segment ["root"]}
;; composes in settings router
...)
(defrouter RootRouter [this props] {:router-targets [MyIndex]})
...
(ns com.example.settings)
(defsc Settings [_ _]
{:route-segment ["settings"]}
; composes in SettingPanesRouter
...)
(defrouter SettingsRouter [this props] {:router-targets [Settings]})
...
(ns com.example.settings-pane)
(defsc UserPane [_ _]
{:route-segment ["user" :user-id]} ...)
(defrouter SettingPanesRouter [this props] {:router-targets [UserPane]})A route like ["root" "settings" "user" "1"] can be manually traced when you can see all of the code,
but even then it is quite inconvenient.
To make this better use the dr/path-to function, which lets you express it like this instead:
(dr/change-route! this (dr/path-to MyIndex Settings UserPane {:user-id "1"}))
;; or just
(dr/change-route! this (dr/path-to MyIndex Settings UserPane "1"))The arguments to path-to can be an interleaved sequence of route targets with their parameters, or a sequence of
route targets followed by a single map that names all of the parameters to be filled out.
Now when someone reads the route they can see (and IDE jump to) exactly the components that represent the elements of the UI route.
Of course you can also use relative paths which help decouple subsections of your application for easier refactoring later:
(dr/change-route-relative! this SettingPanesRouter (dr/path-to UserPane "1"))Now when you move the settings under a different part of the top-level app this link won’t break.
21.7. Deferred Routing
There are times when you want to delay a route change based on some I/O operation, like a load or mutation.
A router can do this via the return value of the will-enter method:
(df/route-deferred ident f)-
Record the fact that the route wants to change, but don’t actually apply it. The ident passed should be the ident of the component that should be routed to (of the current type). The function
fwill be called to allow you to issue instructions that will complete the route. (df/route-immediate ident)-
Immediately apply the route for this router.
Of course you should not do immediate routing if the ident you’re returning does not point to something that already exists in the database. Perhaps you need to load it.
Pending routes can be completed by calling the dr/target-ready mutation with a target parameter that matches the
ident you passed with route-deferred.
For example, say you wanted to load a user before routing to them:
(defsc User [this props]
{:query [:user/id :user/name]
:ident [:user/id :user/id]
:route-segment ["user" :user-id])
:route-cancelled (fn [{:keys [user-id]}] (my-abort-load (keyword "user" user-id)))
:will-enter (fn [app {:keys [user-id]}]
(when-let [user-id (some-> user-id (js/parseInt))]
(dr/route-deferred
[:user/id user-id]
#(df/load! app [:user/id user-id] User {:post-mutation `dr/target-ready
:post-mutation-params {:target [:user/id user-id]}}))))]
(dom/div ...))Note that the route parameters come in via a map keyed by the keyword in your route-segment.
Remember that the value of these elements is guaranteed to be a string, so be sure you coerce them if you need them to be a different type.
|
Important
|
The will-enter method MUST return the value of a call to either route-immediate or route-deferred.
|
21.7.1. Target Ready within Mutations
The mutation target-ready is meant for use with loads as a post-mutation.
The assumption is that there will be some natural delay before it is called.
If you need to signal that a target is ready from within a mutation (instead of in the lambda of the
route-deferred), please use the following:
(defmutation do-stuff-and-finish-routing [params]
(action [{:keys [app]}]
(dr/target-ready! app ident-of-target)))earlier versions had a mutation helper, but that is insufficient in this case and that helper was useless (and it was removed).
21.7.2. Router Rendering of a Deferred UI
The router uses a state machine internally and sets two timeouts with respect to deferred routes: and :error-timeout, and a
:deferred-timeout (which can be sent with your calls to change-route).
The error timeout is how long a route can be deferred before it moves to the :failed state, and the deferred timeout is how long a route can be deferred before it moves to a :pending state.
The router can be defined with custom UI for these various states using the defrouter macro, which looks much like
defsc, but only allows :router-targets in the options map:
(defrouter MyRouter [this {:keys [current-state pending-path-segment route-factory route-props]}]
{:router-targets [A B C]}
(case current-state
:initial (dom/div "What to show when the router is on screen but has never been asked to route")
:pending (dom/div "Loading...")
:failed (dom/div "Oops")}))|
Note
|
If you do not specify a body for the defrouter (e.g. (defrouter A [_ _] {:router-targets [X Y]})), then it will render whatever route is currently active instead of this "alternate" context-sensitive UI.
|
this is a real Fulcro component instance and turns into a defsc, but the body is only rendered in the initial/pending/failure states to do whatever you deem necessary.
The options map will be passed through to defsc (though query/ident/protocols/initial-state will be overridden), so you can define React lifecycle methods and such if that is useful for your particular use-case.
See the next section for critical notes, though.
The incoming props are actually generated to include a number of useful things:
-
:current-state- The current (transitory) state of the router (:initial, :pending, or :failed) -
:pending-path-segment- Where the router is trying to go in the :pending and :failed state. This will be the concrete path segment that was requested (e.g.["user" "1"]and not["user" :user/id]). -
:route-props- The props for the current (old, non-pending) route (if there was a route on-screen). -
:route-factory- The function to call to render the current (old, non-pending) route (if there was a route on-screen).
The route factory/props are useful if you want to continue to render the "current" page even though a timeout has occurred,
but perhaps you want to pass some computed data to indicate progress (e.g. (route-factory (comp/computed route-props {:waiting true}))).
You could also just augment the current view like so:
(defrouter MainRouter [this {:keys [route-factory route-props] :as props}]
{:router-targets [LandingPage ItemForm InvoiceForm AccountList AccountForm]}
;; Show a loader on slow route change (assuming Semantic UI CSS)
(dom/div
(dom/div :.ui.active.loader)
(when route-factory
(route-factory route-props))))Of course, you can instead route-immediate, skip timeouts altogether, and do normal load markers on the target screen.
The former method is useful on a deferred route that simply has nothing to render until the data is present.
Regular named load markers are also a good way of giving user feedback.
You can specify overrides for the default timeouts when you call change-route:
(change-route! this ["new" "path"] {:error-timeout 2000 :deferred-timeout 200})They default to 5000ms and 100ms.
|
Note
|
A deferred route that resolves after an error timeout can still auto-recover if target-ready is called after the error timeout (it will move to the correct resolved route and stop showing the error).
|
|
Note
|
A request to change the route when a deferred route was in progress will cancel the timeouts and immediately attempt the new route. |
Router React Lifecycle Methods
The props seen in react lifecycles will not be what you see in the props of the router body.
The props of the router body are synthesized for your convenience, but raw react lifecycles will see the low-level internal props of the router instead.
The id of the router is the same as the ID for the router’s UI state machine.
Using uism/current-state on that ASM will give you the current route state, and looking in that ASM’s local store will give you things like the pending segment.
The ID of the active state machine will be the keyword name of the router:
(defrouter MyRouter [this props]
{:router-target ...
:componentDidUpdate (fn [this pprops pstate]
(let [current-state (uism/current-state this :MyRouter)
route-props (:com.fulcrologic.fulcro.routing.dynamic-routing/current-route pprops)]
...))
...21.8. Path-ordered Pessimistic Transactions (Requires Fulcro 3.5.24+)
The default routing scheme assumes you don’t want to couple your components in your routing tree, and it is generally recommended that you use UISM if a group of components needs logic beyond pure rendering; however, it is convenient to be able to associate actions with a route (thus deferred routing) that can accomplish things such as I/O.
The deferrered routing system runs things in depth-first order. It does this to prevent UI flicker in the common case, and it has no way to coordinate among the parent/child without the parent simply being the one in control.
The dynamic routing system supports an additional mode that can compose transactions together from a path, and run them via a pessimistic transaction. This can be used when a parent needs to do operations that a child is dependent upon. This does introduce a coupling that is generally undesirable, but is common enough that the convenience is useful.
To use it, return the result of (dr/route-with-path-ordered-transaction target-ident [(mutation {})])
from :will-enter. The arguments to this function are the target ident, and a normal Fulcro transaction
(that could be passed to transact!). The routing system will compose these together and run them as:
[(parent-mutation) (child-mutation) (subchild-mutation) (target-ready {:target parent-ident})
(target-ready {:target child-ident}) (target-ready {:target subchild-ident})]and run that transaction pessimistically. See pessimistic transactions. Basically NOTHING about the child router will run until the full stack operations of the parent have finished.
You can interleave the target ready calls by passing :show-early? true to the options
of route-with-path-ordered-transaction. You also have the option of showing the target immediately
(before the transaction even runs) with :route-immediate? true.
Finally, you can use this as a shorthand for route-deferred by passing :optimistic? true, which
will skip the transaction composition altogether and just combine the transaction with a call
to target ready for you.
See the docstring for more information. See also the workspaces card with demo code.
21.9. Simultaneous On-Screen Routers
A more complex scenario involves the desire to have more than one router on screen at a time. Since dynamic routers don’t specifically require a mapping to URLs (of which there can only be one at a time) there is nothing preventing you from nesting routers in a way where different routers can be responsible for subsections of a UI.
The main complication is that such nested routers simply need to make more use of relative routing. Thus you won’t name the "leaves" in the nested routes when triggering top-level routes.
This also creates a situation where you must make sure that nested routers are routed to a known (relative) path in
some kind of lifecycle that you control. For example, say you have a top router that routes to ["a"], and within
that target there are two routers that render side-by-side (call them X and Y). Those two routers
will not have received any instruction to route when you do a top-level change-route! to ["a"], and are therefore
in an unrouted state.
Using a single route command could initialize one of these (i.e. path ["a" "x1"] might set the X router to its first
target), but that would still leave router Y in an incomplete state. You must use change-route-relative! to resolve
these situations (sending an explicit relative route command to router X and Y on timelines that make sense for
your use-case).
Notice that dynamic routing cannot properly resolve this situation for you. You may, in fact, not want to trigger routing
on the children. Imagine that the user was just on this route, and local relative navigation events had resulted
in X and Y showing some specific sub-routes side-by-side. The user navigates away, but then they come back. You may
want to show them what they were seeing when they last left. Finally, since the
will-enter on any give router can do I/O it is never a good idea for the library to automatically trigger routes
because that could result in unexpected I/O and side-effects for off-screen components.
Thus, routing itself is always an explicit request under your control.
21.9.1. Code Splitting
The route defer mechanism should be sufficient to implement code splitting, where the routing target is the "join point" for the dynamic code. Basically the component would not include the code-split child in the query or UI initially, but could trigger a code load and defer routing (storing the ident in a place where the loaded code could trigger the completion of the route, and a dynamic query change of the original component to point to the newly loaded component).
Something like:
(defsc CodeSplit [this props]
{:ident (fn [] [:CodeSplit 1]) ; constant ident
:query [{:loaded-component ['*]}] ; a placeholder join. Set dynamically after code load
:initial-state {:loaded-component {}} ; placeholder state data
:will-enter (fn [app route-params]
(dr/route-deferred [:CodeSplit 1]
(fn []
(loader/load :module)
;; the loaded code would issue a target-ready mutation once loaded
;; the loaded code would also use set-query to change the query of CodeSplit
)))}
...
;; The DOM can use the component registry to find the component that should be rendered
(when-let [cls (comp/registry-key->class :some.loaded.ns/Component)
factory (comp/factory cls)]
(factory loaded-component)))TODO:
A dynamic code load means that there may be path segments in the current route that cannot be evaluated until the code load is complete.
It may be necessary to "re-trigger" a route after a code load to ensure that the path segments have been fully evaluated.
This would be a good use of a relative change route function, which could be run on the newly-loaded sub-components with the remaining path.
I think it should be relatively easy to just defer the rest of the sub-routing until the given route is resolved…that is probably best, as it doesn’t require user intervention.
The problem with that is that sub-routes may also want to queue I/O, and getting it all queued at once might be preferable to delaying.
We could support something like route-blocked which would resume routing after the ready signal, and allow the route-deferred to continue down the route resolving sub-paths and queuing I/O. Undecided.
21.10. Live Router Example
The router example below uses our people server to demonstrate the various concepts covered in this chapter. It loads people by ID (the buttons could be HTML URL segments). If the loading is slow, it shows a load marker. If the route changes before the user is loaded then a proper console message prints to show you that you could have handled that to cancel network operations.
Make sure you use the server controls in the upper-right corner to see the difference between a fast server (under 100ms) and a slow one. Also be sure to crank it up to a large number so you can try moving to a different route while the user is loading.
Finally, the Person route includes a checkbox that you can check.
When checked the
Person component will prevent all route changes to simulate what you might want to do in a dirty form situation.
(ns book.dynamic-router-example
(:require
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.routing.dynamic-routing :as dr :refer [defrouter]]
[com.fulcrologic.fulcro.dom :as dom]
[taoensso.timbre :as log]
[com.fulcrologic.fulcro.data-fetch :as df]
[com.fulcrologic.fulcro.mutations :as m]))
(defsc Settings [this props]
{:ident (fn [] [:component/id ::settings])
:query [:settings]
:initial-state {:settings "stuff"}
:route-segment ["settings"]
:will-enter (fn [app route-params]
(log/info "Will enter settings with route params " route-params)
(dr/route-immediate [:component/id ::settings]))
:will-leave (fn [this props]
(js/console.log (comp/get-ident this) "props" props)
true)}
(dom/div "Settings"))
(defsc Person [this {:ui/keys [modified?]
:person/keys [id name]
:address/keys [city state]
:as props}]
{:query [:ui/modified? :person/id :person/name :address/city :address/state]
:ident :person/id
:route-segment ["person" :person/id]
:route-cancelled (fn [{:person/keys [id]}]
(log/info "Routing cancelled to user " id))
:will-leave (fn [this {:ui/keys [modified?]}]
(when modified?
(js/alert "You cannot navigate until the user is not modified!"))
(not modified?))
:will-enter (fn [app {:person/keys [id] :as route-params}]
(log/info "Will enter user with route params " route-params)
;; be sure to convert strings to int for this case
(let [id (if (string? id) (js/parseInt id) id)]
(dr/route-deferred [:person/id id]
#(df/load app [:person/id id] Person
{:post-mutation `dr/target-ready
:post-mutation-params
{:target [:person/id id]}}))))}
(dom/div
(dom/h3 (str "Person " id))
(dom/div (str name " from " city ", " state))
(dom/div
(dom/input {:type "checkbox"
:onChange (fn []
(m/toggle! this :ui/modified?))
:checked (boolean modified?)})
"Modified (prevent routing)")))
(def ui-person (comp/factory Person {:keyfn :person/id}))
(defsc Main [this props]
{:ident (fn [] [:component/id ::main])
:query [:main]
:initial-state {:main "stuff"}
:route-segment ["main"]
:will-enter (fn [app route-params]
(log/info "Will enter main" route-params)
(dr/route-immediate [:component/id ::main]))
:will-leave (fn [this props]
(log/info (comp/get-ident this) "props" props)
true)}
(dom/div "Main"))
(defrouter TopRouter [this {:keys [current-state pending-path-segment]}]
{:router-targets [Main Settings Person]}
(case current-state
:pending (dom/div "Loading...")
:failed (dom/div "Loading seems to have failed. Try another route.")
(dom/div "Unknown route")))
(def ui-top-router (comp/factory TopRouter))
(defsc Root [this {:root/keys [router]}]
{:query [{:root/router (comp/get-query TopRouter)}]
:initial-state {:root/router {}}}
(dom/div
(dom/button {:onClick #(dr/change-route this ["main"])} "Go to main")
(dom/button {:onClick #(dr/change-route this ["settings"])} "Go to settings")
(dom/button {:onClick #(dr/change-route this ["person" "1"])} "Go to person 1")
(dom/button {:onClick #(dr/change-route this ["person" "2"])} "Go to person 2")
(ui-top-router router)))
(defn client-did-mount
"Must be used as :client-did-mount parameter of app creation, or called just after you mount the app."
[app]
(dr/change-route app ["main"]))22. Legacy UI Routers
|
Note
|
This chapter describes routers from Fulcro 2 that are a bit harder to use and less feature-rich than the Dynamic Router. The basic union-based router is a great router for performance reasons, but is only concerned with swapping between queries/views at a single layer and nothing else. |
UI Routing is an important task in Fulcro, as it is an important part of keeping your application running quickly. You see, any given sub-tree of your application can query for quite a bit of data and very often a good portion of the side branches are not currently on-screen. If your entire query runs on every render frame then things can become slow. The routers in Fulcro route not only the visible DOM, but also the subquery that needs to run. It does that by using either dynamic queries or union queries with to-one relations to keep the query targeted to just the active UI.
Unfortunately many people find hand-writing union components a little challenging. Fulcro provides a nice pre-written facility that can write much of the code for you, making the process more conceptual as UI Routing.
22.1. A Basic Router
A basic router looks like this:
(ns app
(:require [com.fulcrologic.fulcro.routing.legacy-ui-routers :refer [defrouter defsc-router]]) ; requires 2.6.18 for defsc-router
(defsc Index [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/index}}
...)
(defsc Settings [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/settings}}
...)
;; Pre-2.6.18
(defrouter RootRouter :root/router
; OR (fn [t p] [(:router/page p) (:db/id p)])
[:router/page :db/id]
:PAGE/index Index
:PAGE/settings Settings)
;; Post 2.6.18
(defsc-router RootRouter [this {:keys [router/page db/id]]
{:router-id :root/router
:ident (fn [] [page id]) ; props are destructured in the context of the route TARGET
:default-route Index
:router-targets {:PAGE/index Index
:PAGE/settings Settings}}
(dom/div "What to render if the route is bad"))The newer form lets you define React lifecycle methods, and also lets you define what to render when the route is invalid (the body is only rendered under that circumstance, otherwise is renders the routed component).
It can also be set to resolve like defsc in Cursive, so you get proper symbol resolution.
See old versions of the book in Fulcro’s git history for docs on the old defrouter.
22.1.1. Details on defsc-router
The required parameters of defsc-router are:
:router-id-
An ID to give the router
:ident-
MUST be in
fnform, and can use destructured parameters fromprops(which are in the context of the route target) :default-route-
The component that should be shown by default. Should have initial state so it exists on app start.
:router-targets-
A map from the component’s Fulcro database table to the component that can be routed to. Routing switches on the FIRST element of the ident (the table name). This is because unions are used, and this allows sub-screens to have ID’s that vary. For example, you could router to
[:user/id 44]by adding:user/id Useras an entry to this map and making sure the ident function can resolve the ident correctly for the props of a user.
You may also include most other defsc options, other than :query and :initial-state, which are set internally.
The optional body of defsc-router is what to render if the route is bad (e.g. the ident in state for the route doesn’t point to a valid routing target).
(ns book.simple-router-1
(:require
[com.fulcrologic.fulcro.routing.legacy-ui-routers :as r :refer-macros [defsc-router]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.data-fetch :as df]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.mutations :as m]))
(defsc Index [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id]) ; IMPORTANT! Look up both things, don't use the shorthand for idents on screens!
:initial-state {:db/id 1 :router/page :PAGE/index}}
(dom/div nil "Index Page"))
(defsc Settings [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/settings}}
(dom/div "Settings Page"))
(defsc-router RootRouter [this {:keys [router/page db/id]}]
{:router-id :root/router
:default-route Index
:ident (fn [] [page id])
:router-targets {:PAGE/index Index
:PAGE/settings Settings}}
(dom/div "Bad route"))
(def ui-root-router (comp/factory RootRouter))
(defsc Root [this {:keys [router]}]
{:initial-state (fn [p] {:router (comp/get-initial-state RootRouter {})})
:query [{:router (comp/get-query RootRouter)}]}
(dom/div
(dom/a {:onClick #(comp/transact! this
[(r/set-route {:router :root/router
:target [:PAGE/index 1]})])} "Index") " | "
(dom/a {:onClick #(comp/transact! this
[(r/set-route {:router :root/router
:target [:PAGE/settings 1]})])} "Settings")
(ui-root-router router)))Be sure to look at the database view in the example above. Notice that all that has to happen is a change of a single ident. This as the effect of switching the rendering, and choosing the subquery for the remainder of the visible UI.
22.1.2. Rendering a "Bad Route"
If the app state doesn’t point to a proper router target then the router won’t know what to render.
This is the purpose of the body of the defsc-router.
(defsc-router Router [this props]
{...}
(dom/div "Bad route!"))It is very important to note that the props arg can be destructured in the context of a route target, but when you’re rendering the "bad route" the props will be the props of the router itself.
We recommend you use a pattern like this if you want to examine the "current route" in the body of the "bad route" rendering:
(defsc-router Router [this props]
{...}
(let [{:com.fulcrologic.fulcro.routing.legacy-ui-routers/keys [id current-route]} (comp/props this)]
(dom/div "Bad route: " current-route)))but most likely the current route is just going to be nil, since you’re looking at denormalized props, and the ident that is in state is pointing at something wrong.
So, instead you can pull the state map and see what the bad ident is instead:
(ns ...
(:require [com.fulcrologic.fulcro.routing.legacy-ui-routers :as r :refer [defsc-router]]))
(defsc-router Router [this props]
{...}
(let [state-map (comp/component->state-map this)
{:com.fulcrologic.fulcro.routing.legacy-ui-routers/keys [id]} (comp/props this)]
current-route (get-in state-map [r/routers-table ::r/id id ::r/current-route])]
(dom/div "Bad route ident: " current-route)))of course you probably don’t want to render that to the user, but in case you find it useful at least you know how to get it.
22.1.3. Composing Routers
It is very easy from here to compose together as many of these as you’d like in order to build a more complicated UI. For example, the settings could have several subscreens as in this example:
(ns book.simple-router-2
(:require
[com.fulcrologic.fulcro.routing.legacy-ui-routers :as r :refer-macros [defsc-router]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.mutations :as m]))
(defsc Index [this {:keys [router/page db/id]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/index}}
(dom/div "Index Page"))
(defsc EmailSettings [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/email}}
(dom/div "Email Settings Page"))
(defsc ColorSettings [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/color}}
(dom/div "Color Settings"))
(defsc-router SettingsRouter [this {:keys [router/page db/id]}]
{:router-id :settings/router
:ident (fn [] [page id])
:router-targets {:PAGE/email EmailSettings
:PAGE/color ColorSettings}
:default-route EmailSettings}
(dom/div "Bad route"))
(def ui-settings-router (comp/factory SettingsRouter))
(defsc Settings [this {:keys [router/page db/id subpage]}]
{:query [:db/id :router/page {:subpage (comp/get-query SettingsRouter)}]
:ident (fn [] [page id])
:initial-state (fn [p]
{:db/id 1
:router/page :PAGE/settings
:subpage (comp/get-initial-state SettingsRouter {})})}
(dom/div
(dom/a {:onClick #(comp/transact! this
[(r/set-route {:router :settings/router
:target [:PAGE/email 1]})])} "Email") " | "
(dom/a {:onClick #(comp/transact! this
[(r/set-route {:router :settings/router
:target [:PAGE/color 1]})])} "Colors")
(js/console.log :p (comp/props this))
(ui-settings-router subpage)))
(defsc-router RootRouter [this {:keys [router/page db/id]}]
{:router-id :root/router
:ident (fn [] [page id])
:default-route Index
:router-targets {:PAGE/index Index
:PAGE/settings Settings}}
(dom/div "Bad route"))
(def ui-root-router (comp/factory RootRouter))
(defsc Root [this {:keys [router]}]
{:initial-state (fn [p] {:router (comp/get-initial-state RootRouter {})})
:query [{:router (comp/get-query RootRouter)}]}
(dom/div
(dom/a {:onClick #(comp/transact! this
[(r/set-route {:router :root/router
:target [:PAGE/index 1]})])} "Index") " | "
(dom/a {:onClick #(comp/transact! this
[(r/set-route {:router :root/router
:target [:PAGE/settings 1]})])} "Settings")
(ui-root-router router)))This allows you to build up a tree of routers that keeps your query minimal, and allows for very nice dynamic structuring of the application at runtime.
If you have screens that could have different instances (for example, different reports), then each report could have an ID, and routing would involve selecting the screen’s table, as well as a distinct ID.
The problem, of course, is that managing all of these routers in your application logic becomes somewhat of a chore. Also, it is common to want to mix UI routing with HTML5 history, where only a single "route" is spelled out, but you may need to logically "switch" any number of these UI routers to reach the indicated screen.
For example, one could imagine wanting to go to /settings/colors as a URI for the previous example.
That single URI as a concept is a single route to a screen, but the mutation you’d trigger would be to set-route on two different routers:
(comp/transact! this `[(r/set-route ...) (r/set-route ...)])22.2. Routing Tree Support
|
Note
|
Fulcro’s Dynamic Routers automatically compose and understand paths, so there is no need to declare a routing tree with them. You might want to try those as an alternative. |
Fulcro includes some routing tree primitives to do the mapping from single conceptual "routes" like /settings/colors
to a set of instructions that you need to send to your UI routers.
There is an additional concern as well: route parameters.
It is quite common to want to interpret URIs like /user/436 as a route that populates a given screen with some data.
Thus, the tree support is based on the concept of a Route Handler and Route Parameters.
Defining routes requires just a few steps:
-
Define routers as shown in the prior section, giving each router a distinct ID.
-
Give each routable screen (i.e. URI) in your tree a handler name. The example below shows two routers with 5 conceptual target screen. The screens have handler names
:main,:login, etc.(top-router w/id :top-router) ---------------------- / / | \ :main :login :new-user (report router w/id :report-router) | (reports shared content screen) | / \ :status :graph -
Define your routing tree. This is a data structure that gives instructions to one-or-more routers that are necessary to display the screen with a given handler name. In the above example you need to tell both the top router and report router to change what they are showing in order to get a
:statusor:graphonto the screen.(def routing-tree "A map of route handling instructions. A given route has a handler name (e.g. `:main`) which is thought of as the target of a routing operation (i.e. interpretation of a URI). It also has a vector of `router-instruction`s, which say 1. which router should be changed 2. What component instance that router should point to (by ident) The routing tree for the diagram above is therefore: " (r/routing-tree (r/make-route :main [(r/router-instruction :top-router [:main :top])]) (r/make-route :login [(r/router-instruction :top-router [:login :top])]) (r/make-route :new-user [(r/router-instruction :top-router [:new-user :top])]) (r/make-route :graph [(r/router-instruction :top-router [:report :top]) (r/router-instruction :report-router [:graphing-report :param/report-id])]) (r/make-route :status [(r/router-instruction :top-router [:report :top]) (r/router-instruction :report-router [:status-report :param/report-id])]))) -
Compose the application as normal, placing the routers as shown in the prior section.
22.3. Using the Routing Tree
The routing namespace includes a Fulcro mutation for triggering the routing tree handler.
It takes a :handler (e.g. :main) and an optional :route-params argument:
; assumes you've aliased com.fulcrologic.fulcro.routing.legacy-ui-routers to r
(comp/transact! `[(r/route-to {:handler :main})])Running this mutation will run all of the router-instruction, and will also do route parameter substitution on the resulting idents.
22.3.1. Route Parameters
Anything you pass in the :route-params map will get automatically plugged into the parameter placeholders in your routing tree instructions.
By default anything that looks like an integer (only digits) will be coerced to an integer.
Anything that contains only letters will map to a keyword.
If the default coercion isn’t sufficient then you can customize it using parameter coercion.
It is a very common task to need to convert incoming strings (e.g. from a URL) to elements of an ident.
If you’d like to use this support in your own code then use (r/set-ident-route-params ident params) which supports the coercion and replacement:
(r/set-ident-route-params [:param/table :param/id] {:table "a" :id "1"})
; => [:a 1]Note that the params argument is just what you’d get from a URL when using something like bidi (everything will come in as strings).
Parameter Coercion
The default coercion converts integer-looking things to integers, and string-looking things to keywords.
There is a multimethod r/coerce-param that dispatches on :param/X and replaces the value with whatever you return.
You customize coercion simply by adding your own coercion for a parameter by name:
(defmethod r/coerce-param :param/NAME
[k incoming-string-value]
(transform-it incoming-string-value))Of course, be sure that your namespace with the defmethod is loaded so that your methods get installed.
22.4. Examining Routes in UI and Mutations
Your UI will often want to rely on knowing the "current" route of a given router in order to give user navigation feedback. You cannot embed your router in the query, because that would often make the query have a circular reference and blow the stack.
The only real bit of information in a router that is useful is the current route The current-route function can be used in a mutation or component (by querying for the router table) to check the route:
(ns x
(:require [com.fulcrologic.fulcro.routing.legacy-ui-routers :as r]
[com.fulcrologic.fulcro.components :as comp]))
(r/defsc-router SomeRouter [this props]
{:router-id :top-router
:ident (fn [] ...)
:default-route HomePage
:router-targets {:home-page HomePage
:about-page AboutPage}}
...)
(defmutation do-something-with-routes [params]
(action [{:keys [state]}]
(let [current (r/current-route state :top-router)] ; current will be an ident of a screen of :top-router
...)))
(defsc NavBar [this props]
{:query (fn [] [ [r/routers-table '_] ])
:initial-state (fn [p] {})}
(let [current (current-route props :top-router)] ; current will be an ident of a screen of :top-router
...))22.5. A Complete UI Routing Example
The following shows the example routing tree in a complete running demo:
(ns book.ui-routing
(:require
[com.fulcrologic.fulcro.routing.legacy-ui-routers :as r :refer-macros [defsc-router]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.data-fetch :as df]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.mutations :as m]))
(defsc Main [this {:keys [label] :as props}]
{:initial-state {:page :main :label "MAIN"}
:ident (fn [] [(:page props) :top])
:query [:page :label]}
(dom/div {:style {:backgroundColor "red"}}
label))
(defsc Login [this {:keys [label] :as props}]
{:initial-state {:page :login :label "LOGIN"}
:ident (fn [] [(:page props) :top])
:query [:page :label]}
(dom/div {:style {:backgroundColor "green"}}
label))
(defsc NewUser [this {:keys [label] :as props}]
{:initial-state {:page :new-user :label "New User"}
:ident (fn [] [(:page props) :top])
:query [:page :label]}
(dom/div {:style {:backgroundColor "skyblue"}}
label))
(defsc StatusReport [this {:keys [id page]}]
{:initial-state {:id :a :page :status-report}
:ident (fn [] [page id])
:query [:id :page :label]}
(dom/div {:style {:backgroundColor "yellow"}}
(dom/div (str "Status " id))))
(defsc GraphingReport [this {:keys [id page]}]
{:initial-state {:id :a :page :graphing-report}
:ident (fn [] [page id])
:query [:id :page :label]} ; make sure you query for everything need by the router's ident function!
(dom/div {:style {:backgroundColor "orange"}}
(dom/div (str "Graph " id))))
(defsc-router ReportRouter [this props]
{:router-id :report-router
:ident (fn [] [(:page props) (:id props)])
:default-route StatusReport
:router-targets {:status-report StatusReport
:graphing-report GraphingReport}})
(def ui-report-router (comp/factory ReportRouter))
; BIG GOTCHA: Make sure you query for the prop (in this case :page) that the union needs in order to decide. It won't pull it itself!
(defsc ReportsMain [this {:keys [page report-router]}]
; nest the router under any arbitrary key, just be consistent in your query and props extraction.
{:initial-state (fn [params] {:page :report :report-router (comp/get-initial-state ReportRouter {})})
:ident (fn [] [page :top])
:query [:page {:report-router (comp/get-query ReportRouter)}]}
(dom/div {:style {:backgroundColor "grey"}}
; Screen-specific content to be shown "around" or "above" the subscreen
"REPORT MAIN SCREEN"
; Render the sub-router. You can also def a factory for the router (e.g. ui-report-router)
(ui-report-router report-router)))
(defsc-router TopRouter [this props]
{:router-id :top-router
:default-route Main
:ident (fn [] [(:page props) :top])
:router-targets {:main Main
:login Login
:new-user NewUser
:report ReportsMain}})
(def ui-top (comp/factory TopRouter))
(def routing-tree
"A map of route handling instructions. The top key is the handler name of the route which can be
thought of as the terminal leaf in the UI graph of the screen that should be \"foremost\".
The value is a vector of routing-instructions to tell the UI routers which ident
of the route that should be made visible.
A value in this ident using the `param` namespace will be replaced with the incoming route parameter
(without the namespace). E.g. the incoming route-param :report-id will replace :param/report-id"
(r/routing-tree
(r/make-route :main [(r/router-instruction :top-router [:main :top])])
(r/make-route :login [(r/router-instruction :top-router [:login :top])])
(r/make-route :new-user [(r/router-instruction :top-router [:new-user :top])])
(r/make-route :graph [(r/router-instruction :top-router [:report :top])
(r/router-instruction :report-router [:graphing-report :param/report-id])])
(r/make-route :status [(r/router-instruction :top-router [:report :top])
(r/router-instruction :report-router [:status-report :param/report-id])])))
(defsc Root [this {:keys [top-router]}]
; r/routing-tree-key implies the alias of com.fulcrologic.fulcro.routing.legacy-ui-routers as r.
{:initial-state (fn [params] (merge routing-tree
{:top-router (comp/get-initial-state TopRouter {})}))
:query [r/routing-tree-key
{:top-router (comp/get-query TopRouter)}]}
(dom/div
; Sample nav mutations
(dom/a {:onClick #(comp/transact! this [(r/route-to {:handler :main})])} "Main") " | "
(dom/a {:onClick #(comp/transact! this [(r/route-to {:handler :new-user})])} "New User") " | "
(dom/a {:onClick #(comp/transact! this [(r/route-to {:handler :login})])} "Login") " | "
(dom/a {:onClick #(comp/transact! this [(r/route-to {:handler :status :route-params {:report-id :a}})])} "Status A") " | "
(dom/a {:onClick #(comp/transact! this [(r/route-to {:handler :graph :route-params {:report-id :a}})])} "Graph A")
(ui-top top-router)))22.6. Combining Routing with Data Management
Of course you can compose this with other mutations into a single transaction. This is common when you’re trying to switch to a screen whose data might not yet exist:
(comp/transact! `[(ensure-report-loaded {:report-id :a}) (r/route-to {:graph :a})])here we’re assuming that ensure-report-loaded is a mutation that ensures that there is at least placeholder data in place (or the UI rendering might look a bit odd or otherwise fail from lack of data).
It may also do things like trigger background loads that will fulfill the graph’s needs, something like this:
(defmutation ensure-report-loaded [{:keys [report-id]}]
(action [{:keys [app state] :as env}]
(let [when-loaded (get-in @state [:reports/id report-id :load-time-ms] 0)
is-missing? (= 0 when-loaded)
now-ms (.getTime (js/Date.))
age-ms (- now-ms when-loaded)
should-be-loaded? (or (too-old? age-ms) is-missing?)]
; if missing, put placeholder
; if too old, trigger load
(when is-missing? (swap! state add-report-placeholder report-id))
(when should-be-loaded? (df/load! app [:reports/id report-id] StatusReport)))}))Additional mutations might do things like garbage collect old data that is not in the view. You may also need to trigger renders of things like your main screen with follow-on reads (e.g. of a keyword on the root component of your UI). Of course, combining such things into functions adds a nice touch:
(defn show-report!
[component report-id]
(comp/transact! component `[(app/clear-old-reports)
(app/ensure-report-loaded {:report-id ~report-id})
(r/route-to {:graph ~report-id})
:top-level-key]))which can then be used more cleanly in the UI:
(dom/a {:onClick #(show-report! this :a)} "Report A")22.7. Mutations with Routing
In some cases you will find it most convenient to do your routing within a mutation itself. This will let you check state, trigger loads, etc. If you trigger loads, then you can also easily defer the routing until the load completes. Of course, in that case you may want to do something in the state to cause your UI to indicate the routing is in progress.
There is nothing special about this technique.
There are several functions in the routing namespace that can be used easily within your own mutations:
-
update-routing-links- For standard union-baseddefsc-router(does not support dynamic code loading routers): Takes the state map and a route match (map with :handler and :route-params) and returns a new state map with the routes updated. -
route-to-impl!- For all kinds of routers (including dynamic): Takes the mutationenvand a bidi-style match {:handler/:params}. Works with dynamic routes. Does swaps against app state, but is safe to use within a mutation. -
set-route- Changes the current route on a specificdefsc-routerinstance. Takes a state map, router ID, and a target ident. Used if not using routing trees or dynamic routers.
22.8. HTML5 Routing
Hooking HTML5 or hash-based routing up to this is relatively simple using, for example, pushy and bidi.
We do not provide direct support for this, since your application will need to make a number of decisions that really are local to the specific app:
-
How to map URIs to your leaf screens. If you use bidi then
bidi-matchwill return exactly what you need from a URI route match (e.g.{:handler :x :route-params {:p v}}). -
How to grab the URI bits you need. For example,
pushylets you hook up to HTML5 history events. -
If a routing decision should be deferred/reversed? E.g. navigation should be denied until a form is saved.
-
How you want to update the URI on routing. You can define your own additional mutation to do this (e.g. via
pushy/set-token!) and possibly compose it into a new mutations withroute-to. The functionr/update-routing-linkscan be used for such a composition:
; in some defmutation
(swap! state (fn [m]
(-> m
(r/update-routing-links { :handler :h :route-params p })
(app/your-state-updates)))
(pushy/set-token! your-uri-interpretation-of-h)See the fulcro-template on github. It supports HTML5 routing with a demo tree.
23. Forms Overview
On the surface forms are trivial: you have DOM input fields, users put stuff in them, and you submit that to a server. For really simple forms you already have sufficient tools and you can simply code them however you see fit.
The next most critical thing you’ll want is some help with managing the meta-state that goes with most form interactions:
-
When is the content of a field valid?
-
When should you show a validation error message? E.g. you should not tell a user that they made a mistake on a field they have yet to touch.
-
How do you "reset" the form if the user changes their mind or cancels an edit?
-
How do you ensure that just the data that has changed is sent to the server?
These more advanced interactions require that you track a few things:
-
The validation rules
-
Which fields are "complete" (ready for validation)?
-
What was the state of the form fields before the user started interacting with it?
-
How do you transition states (e.g. indicate that the updated form is now the new "real state"?
You will also commonly need a way to deal with the fact that a form may cross several entities in your database, generating a more global top-level form concern: are all of the entities in this form valid?
Again, you can certainly code all of this by hand, but Fulcro includes two different namespaces of helpers that can make dealing with these aspects of forms a little easier. The reason there are two is that the older version was not easy to change without breaking existing code, so new functions were written in a new namespace as an alternative.
The form state support in Fulcro concentrates just on providing utilities to manage the data, and has validation that is based on Clojure Spec but is completely pluggable.
24. Form State Support
The namespace com.fulcrologic.fulcro.algorithms.form-state (aliased to fs in this chapter) includes functions and mutations for working with your entity as a form.
This support brings functions for dealing with common state storage and form transitions with minimal opinion or additional complexity.
Your UI is still built and rendered identically to what you’re already used to. The form state support simply adds some additional state tracking that can help you manage things like field validation and minimal delta submissions to the server.
|
Important
|
The form state support is about just that: form state. It basically keeps a "pristine" copy of the data of one or more entities and allows you to track if (and how) a particular field has been interacted with. You can think of it as some bookkeeping and diff helpers. It is not intended to be a complete forms solution. You are still responsible for establishing a lifecycle for your forms, a UI, etc. Most forms will benefit from things like the UI State Machine support to keep track of your user experience in more specific detail. Automagic forms could be built on top of it, but providing all of the "knobs" that would allow you to customize such a system for general-purpose use is way beyond the goals of Fulcro core. |
24.1. Defining the Form Component
A component that wishes to act as a form must have an ident and a query. There are two additional steps you must do to prepare your component to work with form state management:
-
Add a form configuration join to your query.
-
Declare which of your props/joins are part of the form.
So, a minimal form-state-compatible component looks like this:
(defsc NameForm [this props]
{:query [:id :name fs/form-config-join]
:ident [:name-form/id :id]
:form-fields #{:name}} ; MUST be a set of keywords from your query
...)next, you’ll want to populate your state with some data. Of course during this step you’ll need to populate that form configuration data.
24.2. Form Configuration
Form state is stored in a form configuration entity in your app state database. This configuration entity includes:
-
The "pristine" state of your entity.
-
Which properties (and joins) of your entity are part of the form.
-
Which properties are "complete" (ready for validation).
-
A map of which parts of the form come from which declared component.
The form state is normalized into your state database. There are two ways of adding this configuration:
-
Add it to a tree of initial (or incoming) state, and merge that (which will normalize it all).
-
Add it directly to your state database.
these methods are described in the following section.
24.2.1. Initializing a Tree of Data
This case occurs when you have either some initial state or a function on the client side that generates a new entity (i.e. with a tempid) and you want to immediately use it with a form. Forms can be nested into a group, and the functions automatically support initializing the configuration recursively for a given form set.
Say you have a person with multiple (normalized) phone numbers. You want to make a new person and set them up with an initial phone number to fill out. The tree for that data might look like this:
(def person-tree
{ :db/id (tempid/tempid)
:person/name "Joe"
:person/phone-numbers [{:db/id (tempid/tempid) :phone/number "555-1212"}]})with components like:
(defsc PhoneForm [this props]
{:query [:db/id :phone/number fs/form-config-join]
:ident [:phone/id :db/id]
:form-fields #{:phone/number}}
...)
(defsc PersonForm [this props]
{:query [:db/id :person/name {:person/phone-numbers (comp/get-query PhoneForm)}
fs/form-config-join]
:ident [:person/id :db/id]
:form-fields #{:person/name :person/phone-numbers}}
...)Normally you might throw this into your application state with something like:
(merge/merge-component! app PersonForm person-tree)which will insert and normalize the person and phone number.
Then to get form-state support you’d add form configuration. This snapshot’s the state (person-tree) and uses the options on the component to set up state tracking of fields:
(def person-tree-with-form-support (fs/add-form-config PersonForm person-tree))
(merge/merge-component! app PersonForm person-tree-with-form-support)|
Important
|
add-form-config will look at all of the form (and subforms reachable from that form), but it will only add config to the ones that are missing it.
This means the current form state is not reset by this call.
|
24.2.2. Initializing in a Mutation
The other very common case is this: You’ve loaded something from the server, and you’d like to use it as the basis for form fields. In this case the data is already normalized in your state database, and you’ll need to work on it via a mutation.
The add-form-config* function is the helper for that.
The common pattern for using it is:
(defmutation use-person-as-form [{:keys [person-id]}]
(action [{:keys [state]}]
(swap! state (fn [s]
(-> s
(fs/add-form-config* PersonForm [:person/id person-id]) ; this will affect the joined phone as well
(assoc-in [:component :person-editor :person-to-edit] [:person/id person-id]) ; hook it into an editor?
...))))) ; other setup code|
Important
|
add-form-config* will look at all of the form (and subforms reachable from that form), but it will only add config to the ones that are missing it.
This means the current form state is not reset by this call.
This is intentional, since you might add sub-forms (e.g. a new phone number) to a form group, and this allows you to re-run the add of config data from the top without worrying about affecting pre-existing form state.
|
24.3. Validation
Validation in the form state system is completely customizable. There is built-in support for working with Clojure Spec as your validation layer. In order for this to be effective you should be sure to namespace all of your properties in a globally-unique way, and then simply write normal specs for them. The section on custom validators describes the other supported mechanism for validation.
The central function for using specs is fs/get-spec-validity, which can be used on an entire form or a single field.
This function returns one of #{:valid, :invalid, :unchecked}.
Initially, a form’s fields are marked as incomplete.
When in this state the validity will always be :unchecked.
Some additional helpers are useful for concise UI code:
-
(invalid-spec? form field)- Field is an optional argument. Returns true if the form (field) is complete and invalid. -
(valid-spec? form field)- Field is an optional argument. Returns true if the form (field) is complete and valid. -
(checked? form field)- Field is an optional argument. Returns true if the form (field) is complete. This function works no matter what validator you’re using. -
(dirty? form field)- Field is an optional argument. Returns true if the pristine copy of the form (field) doesn’t match the current entity.
For example:
(defsc PersonForm [this {:keys [person/name] :as props}]
...
;; The `mark-complete!` mutation is covered below
(dom/input {:value name :onBlur #(comp/transact! this `[(fs/mark-complete! ...)]) ...})
(when (fs/invalid-spec? props :person/name)
(dom/span "Invalid username!")
...)will show the error only if the field is complete (shown as a call to mark-complete! on blur), but only if the field’s value does not match the spec for :person/name.
As you can see, the idea of "complete" is important to validation.
24.3.1. Completing Fields
Initially the form config will not consider any of the form fields to be complete. The idea of field "completion" is so that you can prevent validation on a field until you feel it is a good time. No one wants to see error messages about fields that they have yet to interact with!
However, depending on what you are editing, you may have different ideas about when fields should be considered complete. For example, if you just loaded a saved entity from a server, then all of the fields are probably complete by definition, meaning that you need a way to mark all fields (recursively) complete.
When you first add form config to an entity, all fields are "incomplete". You can iteratively mark fields complete as the user interacts with them, or trigger a completion "event" all at once. There is a support function and a mutation for this.
The mark-complete* function is meant to be used from within mutations against the app state database.
It requires the state map (not atom), the entity’s ident, and which field you want to mark complete.
If you omit the field, then it marks everything (recursively) complete from that form down.
So, in our earlier example of loading a person for editing, we’d augment that mutation like so:
(defmutation use-person-as-form [{:keys [person-id]}]
(action [{:keys [state]}]
(swap! state (fn [s]
(-> s
(fs/add-form-config* PersonForm [:person/id person-id])
;; MUST come after the config is added. Mark all fields complete (since they came from existing entity)
(fs/mark-complete* [:person/id person-id])
;; add it to some editor as the target
(assoc-in [:component :person-editor :person-to-edit] [:person/id person-id]))))))and all validations will immediately apply in the UI.
The mark-complete! mutation can be used for the exact same purpose from the UI. Typically, it is used in things like
:onBlur handlers to indicate that a field is ready for validation.
It takes an :entity-ident and :field.
The :entity-ident is optional if the transaction is invoked on the form component of that field, and if the :field is not supplied it means to affect the entire form recursively:
(defsc PersonForm [this {:keys [db/id person/name]}]
... ; as before
;; uses the ident of the current instance as the entity-ident
(dom/input {:value name
:onBlur #(comp/transact! this `[(fs/mark-complete! {:field :person/name})])})
...)The inverse operations are clear-complete! and clear-complete*.
24.3.2. Using non-spec Validators
You may not wish to use the longer names of properties that are required in order to get stable Clojure Spec support simply for form validation. In this case you’d still like to use the idea of field completion and validation, but you’ll want to supply the mechanism whereby validity is determined.
The form traversal code for validation is already in the form state code, and a helper function is provided so you can leverage it to create your own form validation system. It is quite simple:
-
Write a function
(fn [form field] …)that returns true if the given field (a keyword) is valid on the given form (a map of the props for the form that contains that field). -
Generate a validator with
fs/make-validator
The returned validator works identically to get-spec-validity, but it uses your custom function instead of specs to determine validity.
For example, you might want to make a simple new user form validation that looks something like this:
(defn new-user-form-valid [form field]
(let [v (get form field)]
(case field
:username (and (string? v) (seq (str/trim v))) ; not empty
:password (> (count v) 8) ; longer than 8
:password-2 (= v (:password form))))) ; passwords match
(def validator (fs/make-validator new-user-form-valid))
(defsc NewUser [this {:keys [username password password-2] :as props}]
...
(dom/input {:name "password-2" :value password-2 :onBlur #(comp/transact! this `[(fs/mark-complete ...)]) ...})
(when (= :invalid (validator props :password-2))
(dom/span "Passwords do not match!")
...)As before: you won’t see the error message on an invalid entry until your code has marked the field complete. This moves a decent amount of clutter out of the primary UI code and into the form support itself.
24.4. Submitting Data
Once your form is valid and the user indicates a desire to save, then your interest shifts to sending that data to the server.
The dirty-fields function should be used from the UI in order to calculate this and pass it as a parameter to a mutation.
The mutation can then update the local pristine state of form config and indicate a remote operation.
The dirty-fields function returns a map from ident to fields that have changed.
If the ident includes a temporary ID, then all fields for that form will be included.
If the ID is not a temp id, then it will only include those fields that differ from the pristine copy of the original.
This will include subform references as to-one or to-many idents (to indicate the addition or removal of subform instances).
You can ask dirty-fields to either send the explicit new values (only), or a before/after picture of each field.
The latter is particularly useful for easily deriving the addition/removal of references, but is also quite useful if you would like to do optimistic concurrency (e.g. not apply a change to a server where the old value wasn’t still in the database).
(defmutation submit-person [{:keys [id]}]
(action [{:keys [state]}]
(swap! state fs/entity->pristine* [:person/id id])) ; updates form state to think the form is now in pristine shape
(remote [env] true)) ; diff goes over the network as a parameter from the UI layer
(defsc Person [this props]
... ; as before
(dom/button {:onClick #(comp/transact! this `[(submit-person ~{:id id :diff (fs/dirty-fields props true)})])} "Submit")
...)If you’d like to wait until the server indicates everything is ok, then you can use ptransact! and returning to get back some submission information, and move the entity→pristine* step to a later mutation:
;; Exists purely as a way to return a value into a normalized state database...
(defsc SubmissionStatus [_ _]
{:query [:id :status]
:ident [:submission-status/id :id]})
(defmutation submit-person [{:keys [id]}]
(remote [env] (com.fulcrologic.fulcro.mutations/returning env SubmissionStatus))
(defmutation finish-person-submission [{:keys [id]}]
(action [{:keys [state]}]
(if (= :ok (get-in @state [:submission-status/id id :status]))
(swap! state fs/entity->pristine* [:person/id id])
...))) ; else show some error
...
(ptransact! this `[(submit-person ~{:id id :diff (fs/dirty-fields props true)})
(finish-person-submission ~{:id id})])See pessimistic transactions for more details.
Of course, the behavior of the UI is up to you, and all of the examples above assume that the mutations in question would also be changing other things in your form/editor to show status to the user as you go. It should be relatively straightforward to combine the form state maintenance functions with your own support functions and mutations to create your "standard" look for form interactions across your application.
24.5. Form State Demos
The following two fully-functional demos show you complete code for two scenarios.
24.5.1. Selecting an Entity for Edit
A very common use case is the scenario where the entities are already loaded and are displayed in the UI. The user clicks on an entry, and you take them to a form where they can edit the item.
This demo lists some phone numbers. Clicking on one:
-
Adds form configuration to the entity
-
Switches the UI to the form editor
-
Switches back to the (updated) list on save
(ns book.forms.form-state-demo-1
(:require
[com.fulcrologic.semantic-ui.modules.dropdown.ui-dropdown :as dropdown]
[book.elements :as ele]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.fulcrologic.fulcro.algorithms.form-state :as fs]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[cljs.spec.alpha :as s]
[taoensso.timbre :as log]))
(declare Root PhoneForm)
(defn field-attrs
"A helper function for getting aspects of a particular field."
[component field]
(let [form (comp/props component)
entity-ident (comp/get-ident component form)
id (str (first entity-ident) "-" (second entity-ident))
is-dirty? (fs/dirty? form field)
clean? (not is-dirty?)
validity (fs/get-spec-validity form field)
is-invalid? (= :invalid validity)
value (get form field "")]
{:dirty? is-dirty?
:ident entity-ident
:id id
:clean? clean?
:validity validity
:invalid? is-invalid?
:value value}))
(s/def :phone/number #(re-matches #"\(?[0-9]{3}[-.)]? *[0-9]{3}-?[0-9]{4}" %))
(defmutation abort-phone-edit [{:keys [id]}]
(action [{:keys [state]}]
(swap! state (fn [s]
(-> s
; stop editing
(dissoc :root/phone)
; revert to the pristine state
(fs/pristine->entity* [:phone/id id])))))
(refresh [env] [:root/phone]))
(defmutation submit-phone [{:keys [id delta]}]
(action [{:keys [state]}]
(swap! state (fn [s]
(-> s
; stop editing
(dissoc :root/phone)
; update the pristine state
(fs/entity->pristine* [:phone/id id])))))
(remote [env] true)
(refresh [env] [:root/phone [:phone/id id]]))
(defn input-with-label
[component field label validation-message input]
(let [{:keys [dirty? invalid?]} (field-attrs component field)]
(comp/fragment
(dom/div :.field {:classes [(when invalid? "error") (when dirty? "warning")]}
(dom/label {:htmlFor (str field)} label)
input)
(when invalid?
(dom/div :.ui.error.message {} validation-message))
(when dirty?
(dom/div :.ui.warning.message {} "(dirty)")))))
(defsc PhoneForm [this {:phone/keys [id type number] :as props}]
{:query [:phone/id :phone/type :phone/number fs/form-config-join]
:form-fields #{:phone/number :phone/type}
:ident :phone/id}
(let [dirty? (fs/dirty? props)
invalid? (= :invalid (fs/get-spec-validity props))]
(dom/div :.ui.form {:classes [(when invalid? "error") (when dirty? "warning")]}
(input-with-label this :phone/number "Phone:" "10-digit phone number is required."
(dom/input {:value (or (str number) "")
:onChange #(m/set-string! this :phone/number :event %)}))
(input-with-label this :phone/type "Type:" ""
(dropdown/ui-dropdown {:value (name type)
:selection true
:options [{:text "Home" :value "home"}
{:text "Work" :value "work"}]
:onChange (fn [_ v]
(when-let [v (some-> (.-value v) keyword)]
(m/set-value! this :phone/type v)))}))
(dom/button :.ui.button {:onClick #(comp/transact! this [(abort-phone-edit {:id id})])} "Cancel")
(dom/button :.ui.button {:disabled (or (not (fs/checked? props)) (fs/invalid-spec? props))
:onClick #(comp/transact! this [(submit-phone {:id id :delta (fs/dirty-fields props true)})])} "Commit!"))))
(def ui-phone-form (comp/factory PhoneForm {:keyfn :phone/id}))
(defsc PhoneNumber [this {:phone/keys [id type number]} {:keys [onSelect]}]
{:query [:phone/id :phone/number :phone/type]
:initial-state {:phone/id :param/id :phone/number :param/number :phone/type :param/type}
:ident :phone/id}
(dom/li :.ui.item
(dom/a {:onClick (fn [] (onSelect id))}
(str number " (" (get {:home "Home" :work "Work" nil "Unknown"} type) ")"))))
(def ui-phone-number (comp/factory PhoneNumber {:keyfn :phone/id}))
(defsc PhoneBook [this {:phonebook/keys [id phone-numbers]} {:keys [onSelect]}]
{:query [:phonebook/id {:phonebook/phone-numbers (comp/get-query PhoneNumber)}]
:initial-state {:phonebook/id :main
:phonebook/phone-numbers [{:id 1 :number "541-555-1212" :type :home}
{:id 2 :number "541-555-5533" :type :work}]}
:ident :phonebook/id}
(dom/div
(dom/h4 "Phone Book (click a number to edit)")
(dom/ul
(mapv (fn [n] (ui-phone-number (comp/computed n {:onSelect onSelect}))) phone-numbers))))
(def ui-phone-book (comp/factory PhoneBook {:keyfn :phonebook/id}))
(defmutation edit-phone-number [{:keys [id]}]
(action [{:keys [state]}]
(let [phone-type (get-in @state [:phone/id id :phone/type])]
(swap! state (fn [s]
(-> s
; make sure the form config is with the entity
(fs/add-form-config* PhoneForm [:phone/id id])
; since we're editing an existing thing, we should start it out complete (validations apply)
(fs/mark-complete* [:phone/id id])
; tell the root UI that we're editing a phone number by linking it in
(assoc :root/phone [:phone/id id])))))))
(defsc Root [this {:keys [:root/phone :root/phonebook]}]
{:query [{:root/phonebook (comp/get-query PhoneBook)}
{:root/phone (comp/get-query PhoneForm)}]
:initial-state {:root/phonebook {}
:root/phone {}}}
(ele/ui-iframe {:frameBorder 0 :width 500 :height 400}
(dom/div {}
(dom/link {:rel "stylesheet" :href "https://cdnjs.cloudflare.com/ajax/libs/semantic-ui/2.4.1/semantic.min.css"})
(if (contains? phone :phone/number)
(ui-phone-form phone)
(ui-phone-book (comp/computed phonebook {:onSelect (fn [id] (comp/transact! this [(edit-phone-number {:id id})]))}))))))24.5.2. Loading or Creating Something New
This example shows the case where a graph of entities (a person and multiple phone numbers) are to be created in a UI, or are to be loaded from a server. This is a full-stack example, though it doesn’t actually persist the data (it just prints what the server receives in the Javascript console).
There are two buttons. One will load an existing entity into the editor, and of course submissions will send a minimal delta. The other button will create a new person, and submissions will send all fields.
The load case, as you can see in the code, is very similar to the prior example, but just includes some extra code to show you how to put it together with a load interaction.
|
Note
|
This example is not a fully-baked form. Integrating form control with UI state machines makes it much easier to handle the repetitive work of form handling. The form state system is more about for state and data diff, not overall form control and user interaction. |
(ns book.forms.form-state-demo-2
(:require
[com.fulcrologic.semantic-ui.modules.dropdown.ui-dropdown :as dropdown]
[com.fulcrologic.fulcro.mutations :as m :refer [defmutation]]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.algorithms.form-state :as fs]
[com.fulcrologic.fulcro.algorithms.tempid :as tempid]
[com.fulcrologic.fulcro.data-fetch :as df]
[clojure.string :as str]
[cljs.spec.alpha :as s]
[com.wsscode.pathom.connect :as pc]
[book.elements :as ele]
[taoensso.timbre :as log]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Server Code
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
; a simple query for any person, that will return valid-looking data
(pc/defresolver person-resolver [env {:person/keys [id]}]
{::pc/input #{:person/id}
::pc/output [:person/name :person/age :person/phone-numbers]}
{:person/id id
:person/name (str "User " id)
:person/age 56
:person/phone-numbers [{:phone/id 1 :phone/number "555-111-1212" :phone/type :work}
{:phone/id 2 :phone/number "555-333-4444" :phone/type :home}]})
(defonce id (atom 1000))
(defn next-id [] (swap! id inc))
; Server submission...just prints delta for demo, and remaps tempids (forms with tempids are always considered dirty)
(pc/defmutation submit-person-mutation [env inputs]
{::pc/sym `submit-person}
(let [params (-> env :ast :params)]
(js/console.log "Server received form submission with content: ")
(cljs.pprint/pprint params)
(let [ids (mapv (fn [[k v]] (second k)) (:diff params))
remaps (into {} (keep (fn [v] (when (tempid/tempid? v) [v (next-id)])) ids))]
{:tempids remaps})))
(def resolvers [person-resolver submit-person-mutation])
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Client Code
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(s/def :person/name (s/and string? #(seq (str/trim %))))
(s/def :person/age #(s/int-in-range? 1 120 %))
(defn field-attrs
"A helper function for getting aspects of a particular field."
[component field]
(let [form (comp/props component)
entity-ident (comp/get-ident component form)
id (str (first entity-ident) "-" (second entity-ident))
is-dirty? (fs/dirty? form field)
clean? (not is-dirty?)
validity (fs/get-spec-validity form field)
is-invalid? (= :invalid validity)
value (get form field "")]
{:dirty? is-dirty?
:ident entity-ident
:id id
:clean? clean?
:validity validity
:invalid? is-invalid?
:value value}))
(def integer-fields #{:person/age})
(defn input-with-label
[component field label validation-message input]
(let [{:keys [dirty? invalid?]} (field-attrs component field)]
(comp/fragment
(dom/div :.field {:classes [(when invalid? "error") (when dirty? "warning")]}
(dom/label {:htmlFor (str field)} label)
input)
(when invalid?
(dom/div :.ui.error.message {} validation-message))
(when dirty?
(dom/div :.ui.warning.message {} "(dirty)")))))
(s/def :phone/number #(re-matches #"\(?[0-9]{3}[-.)]? *[0-9]{3}-?[0-9]{4}" %))
(defsc PhoneForm [this {:phone/keys [id number type] :as props}]
{:query [:phone/id :phone/number :phone/type fs/form-config-join]
:form-fields #{:phone/number :phone/type}
:ident :phone/id}
(dom/div :.ui.segment
(dom/div :.ui.form
(input-with-label this :phone/number "Phone:" "10-digit phone number is required."
(dom/input {:value (or (str number) "")
:onBlur #(comp/transact! this [(fs/mark-complete! {:entity-ident [:phone/id id]
:field :phone/number})])
:onChange #(m/set-string! this :phone/number :event %)}))
(input-with-label this :phone/type "Type:" ""
(dropdown/ui-dropdown {:value (name type)
:selection true
:options [{:text "Home" :value "home"}
{:text "Work" :value "work"}]
:onChange (fn [_ v]
(when-let [v (some-> (.-value v) keyword)]
(m/set-value! this :phone/type v)
(comp/transact! this [(fs/mark-complete! {:field :phone/type})])))})))))
(def ui-phone-form (comp/factory PhoneForm {:keyfn :phone/id}))
(defn add-phone*
"Add the given phone info to a person."
[state-map phone-id person-id type number]
(let [phone-ident [:phone/id phone-id]
new-phone-entity {:phone/id phone-id :phone/type type :phone/number number}]
(-> state-map
(update-in [:person/id person-id :person/phone-numbers] (fnil conj []) phone-ident)
(assoc-in phone-ident new-phone-entity))))
(defmutation add-phone
"Mutation: Add a phone number to a person, and initialize it as a working form."
[{:keys [person-id]}]
(action [{:keys [state]}]
(let [phone-id (tempid/tempid)]
(swap! state (fn [s]
(-> s
(add-phone* phone-id person-id :home "")
(fs/add-form-config* PhoneForm [:phone/id phone-id])))))))
(defsc PersonForm [this {:person/keys [id name age phone-numbers]}]
{:query [:person/id :person/name :person/age
{:person/phone-numbers (comp/get-query PhoneForm)}
fs/form-config-join]
:form-fields #{:person/name :person/age :person/phone-numbers} ; phone-numbers here becomes a subform because it is a join in the query.
:ident :person/id}
(dom/div :.ui.form
(input-with-label this :person/name "Name:" "Name is required."
(dom/input {:value (or name "")
:onBlur #(comp/transact! this [(fs/mark-complete! {:entity-ident [:person/id id]
:field :person/name})
:root/person])
:onChange (fn [evt]
(m/set-string! this :person/name :event evt))}))
(input-with-label this :person/age "Age:" "Age must be between 1 and 120"
(dom/input {:value (or age "")
:onBlur #(comp/transact! this [(fs/mark-complete! {:entity-ident [:person/id id]
:field :person/age})
:root/person])
:onChange #(m/set-integer! this :person/age :event %)}))
(dom/h4 "Phone numbers:")
(when (seq phone-numbers)
(mapv ui-phone-form phone-numbers))
(dom/button :.ui.button {:onClick #(comp/transact! this `[(add-phone {:person-id ~id})])} "+")))
(def ui-person-form (comp/factory PersonForm {:keyfn :person/id}))
(defn add-person*
"Add a person with the given details to the state database."
[state-map id name age]
(let [person-ident [:person/id id]
person {:person/id id :person/name name :person/age age}]
(assoc-in state-map person-ident person)))
(defmutation edit-new-person [_]
(action [{:keys [state]}]
(let [person-id (tempid/tempid)
person-ident [:person/id person-id]
phone-id (tempid/tempid)]
(swap! state
(fn [s] (-> s
(add-person* person-id "" 0)
(add-phone* phone-id person-id :home "")
(assoc :root/person person-ident) ; join it into the UI as the person to edit
(fs/add-form-config* PersonForm [:person/id person-id])))))))
(defmutation edit-existing-person
"Turn an existing person with phone numbers into an editable form with phone subforms."
[{:keys [person-id]}]
(action [{:keys [state]}]
(swap! state
(fn [s] (-> s
(assoc :root/person [:person/id person-id])
(fs/add-form-config* PersonForm [:person/id person-id]) ; will not re-add config to entities that were present
(fs/entity->pristine* [:person/id person-id]) ; in case we're re-loading it, make sure the pristine copy it up-to-date
;; it just came from server, so all fields should be valid
(fs/mark-complete* [:person/id person-id]))))))
(defmutation submit-person [{:keys [id]}]
(action [{:keys [state]}]
(swap! state fs/entity->pristine* [:person/id id]))
(remote [env] true))
(defsc Root [this {:keys [root/person]}]
{:query [{:root/person (comp/get-query PersonForm)}]
:initial-state (fn [params] {})}
(ele/ui-iframe {:frameBorder 0 :width 800 :height 820}
(dom/div :.ui.container.segments
(dom/link {:rel "stylesheet" :href "https://cdnjs.cloudflare.com/ajax/libs/semantic-ui/2.4.1/semantic.min.css"})
(dom/button :.ui.button
{:onClick #(df/load! this [:person/id 21] PersonForm {:target [:root/person]
:post-mutation `edit-existing-person
:post-mutation-params {:person-id 21}})}
"Simulate Edit (existing) Person from Server")
(dom/button :.ui.buton {:onClick #(comp/transact! this `[(edit-new-person {})])} "Simulate New Person Creation")
(when (:person/id person)
(dom/div :.ui.segment
(ui-person-form person)))
(dom/div :.ui.segment
(dom/button :.ui.button {:onClick #(comp/transact! this `[(fs/reset-form! {:form-ident [:person/id ~(:person/id person)]})])
:disabled (not (fs/dirty? person))} "Reset")
(dom/button :.ui.button {:onClick #(comp/transact! this `[(submit-person {:id ~(:person/id person) :diff ~(fs/dirty-fields person false)})])
:disabled (or
(fs/invalid-spec? person)
(not (fs/dirty? person)))} "Submit")))))24.6. Full Stack Form Demo
TODO: Rewrite to use semantic UI
24.6.1. Application Load
When the application loads it uses data-fetch/load to query the server for
:all-numbers.
(df/load! app :all-numbers PhoneDisplayRow {:target [:screen/phone-list :tab :phone-numbers]})We have a very simple database that looks like this on the server:
(defn make-phone-number [id type num]
{:db/id id :phone/type type :phone/number num})
(defonce server-state (atom {:all-numbers [(make-phone-number 1 :home "555-1212")
(make-phone-number 2 :home "555-1213")
(make-phone-number 3 :home "555-1214")
(make-phone-number 4 :home "555-1215")]}))The server query handler is just:
;; TODO: PATHOM Demo24.6.2. The UI
We’re using a UI router via defsc-router to create two screens: A phone list and phone editor screen.
The basic UI tree looks like this:
Root
|
TopLevelRouter
/ \\
PhoneEditor PhoneList
| / | \\
PhoneForm PhoneDisplayRow...The UI starts out showing PhoneList. Clicking on an element leads to editing.
24.6.3. The Mutations
Note: PhoneForm and PhoneDisplayRow share the same ident since they render two differing views of the same entity in our database.
Editing
Since the phone numbers were loaded from raw data on a server, they are not form capable yet.
Thus, the application must do a few things in order for editing to work:
24.6.4. Commit and Reset
TODO: example
25. Batched Reads
As of Fulcro 3.6 there are two alternative transaction processing systems to choose from that can affect the performance of full-stack operations.
The synchronous processing is somewhat complex, and is covered in the Syncrhonous Operation chapter.
Batched processing is somewhat simpler. It attempts to combine loads that are in the submission queue into a single network request. This reduces the round trips, and thus eliminates a good deal of latency.
Enabling it is quite simple, just wrap your application definition with a function that adds in the proper options:
(ns example
(:require
[com.fulcrologic.fulcro.application :refer [fulcro-app]]
[com.fulcrologic.fulcro.algorithms.tx-processing.batched-processing :refer [with-batched-reads]]))
(defonce SPA (-> (fulcro-app)
(with-batched-reads)))Now any loads that are submitted together (while holding the js thread) will all be sent in a single network request.
|
Note
|
The synchronous system can also support batching, but it typically doesn’t get much out of it since the first load is always submitted immediately, and others are stacked behind it. See the docstrings on the synchronous transaction processing for instructions on enabling it. |
25.1. Aborting Batched Requests
If you assign abort IDs to your loads, then the following behavior takes effect:
-
If NO loads have an abort ID, then can all batch together.
-
The first load’s abort id is used to gather all loads with the same abort id for a batch.
-
Asking for an abort aborts all entries with the same ID (this is also the standard behavior).
This means that loads can end up going in an order other than their submission:
(df/load! this :h T {:abort-id 1})
(df/load! this :j T {:abort-id 2})
(df/load! this :k T {:abort-id 1})will send a network request for :h and :k in the first batch, then :j. Aborting 1 will stop the first
batch if it isn’t done (both loads).
26. Synchronous Operation
The default transaction processing system of Fulcro 3 is highly asynchronous. This is partly for legacy compatibility with some now-deprecated features that were inherited from Fulcro 2, and partly an attempt to provide semantics that make sense when transactions are submitted from within the action handlers of mutations (nested transactions).
Unfortunately this asynchrony adds in a bit of overhead, leads to occasional over-rendering (a top-level + nested tx will lead to 2 renders even though only one is probably necessary), and makes any kind of full-app unit testing quite difficult.
Fulcro 3 was designed with extreme flexibility in mind, and most of the internal algorithms are replaceable. The transaction processing itself is one of these algorithms. Of course, replacing such a central item can lead to all sorts of application regressions and problems since the tx processing is the central mode of operation in Fulcro overall.
In Fulcro 3.2.17 and above there is a new version of the tx processing algorithm in
com.fulcrologic.fulcro.algorithms.tx-processing.synchronous-tx-processing (stx). You can plug it in when you create your
application:
(stx/with-synchronous-transactions
(app/fulcro-app {}))and now any call to (transact! …) will do as much work as possible synchronously, while preserving the expressed
transactional semantics of Fulcro’s transaction system:
-
The top-level transaction’s optimistic actions will all complete before any nested submission (i.e. a call to
transact!within a mutation body) starts. -
The top-level transaction’s remote actions will be queued (and idle remotes will start the sends)
-
Any synchronous remote (e.g. a Datatscript database behind Pathom in the client) that reports results will cause action handlers in mutations to run after the optimistic actions of the top-level transaction are complete, but still synchronously overall.
Futhermore, any nested transaction submission that happen in the above synchronous steps will be post-processed on the same synchronous call before rendering.
Finally, a synchronous call to an immediate synchronous render will happen once there is no more immediate work to do. Technically
this could lead to an attempt to render more than 60fps, but in reality the next transaction will have to be triggered by
a user-driven event or network response. The only real consideration is if you’re transacting in response to something
like a mouse move event, in which case you might consider debouncing your calls to transact! or use component-local state.
(NOTE: browsers often limit event reporting to animation frames, so it is actually unlikely you’ll submit transactions
faster than 60fps).
Some other notes:
-
Using the
synchronous? trueoption (which is auto-added to options when using the!!variants of functions) when leveraging the sync tx processing will additionally render only the component that submitted the top-most transaction. This meansset-string!!,transact!!, and such will all do the absolute minimum work to get the single submitting component up-to-date with as little overhead as possible. This only applies if the component in question has an ident. Remember that your Root component is special and cannot have an ident. -
Other rendering options (specified by your renderer of choice) are still passed through to render.
26.1. Testing Full Apps using Synchronous Operation
Synchronous operation can be quite useful even if you find the syncrhonous operation unsuitable for your production application. It
comes in particularly handy when you’d like to set your remotes to something synchronous, and run full integration tests
against a headless app. This is such a handy thing that there is a helper function that will set up an app for just this
purpose: app/headless-synchronous-app.
Here is an example test from Fulcro’s own ui_state_machine_spec.cljc that demonstrates how you might use this to
test the full operation of your application (sans rendering):
(uism/defstatemachine test-machine2
{::uism/aliases {:name [:actor/child :name]}
::uism/states {:initial {::uism/handler (fn [env] (-> env
(uism/assoc-aliased :name "Tony")
(uism/activate :state/a)))}
:state/a {::uism/events {:event/bang! {::uism/handler (fn [env]
(-> env
(uism/apply-action update :WOW inc)
(uism/activate :state/b)))}}}
:state/b {::uism/events {:event/bang! {::uism/handler (fn [env]
(-> env
(uism/apply-action update :WOW inc)
(uism/activate :state/a)))}}}}})
(defsc Child [this {:keys [:name] :as props}]
{:query [:name]
:ident (fn [] [:component/id :child])
:initial-state {:name "Bob"}})
(defsc TestRoot [_ _]
{:query [{:root/child (comp/get-query Child)}]
:initial-state {:root/child {}}})
(specification "Integration test (using sync tx processing)"
(let [app (app/headless-synchronous-app TestRoot {})
fget-in (fn [path] (get-in (app/current-state app) path))]
(uism/begin! app test-machine2 ::id {:actor/child Child} {})
(assertions
"After begin, ends up in :state/a"
(uism/get-active-state app ::id) => :state/a
"Applies the action from the handler"
(fget-in [:component/id :child :name]) => "Tony")
(behavior "Triggering an event from state a"
(uism/trigger! app ::id :event/bang!)
(assertions
"Moves to the correct state"
(uism/get-active-state app ::id) => :state/b
"Applies the expected actions"
(fget-in [:WOW]) => 1))
(behavior "Triggering an event from state b"
(uism/trigger! app ::id :event/bang!)
(assertions
"Moves to the correct state"
(uism/get-active-state app ::id) => :state/a
"Applies the expected actions"
(fget-in [:WOW]) => 2))))Note in the test above we make a couple of components with no UI, just queries/idents/initial state. The headless app
will properly initialize, and will be ready for any calls. Everything that applications do in Fulcro that affect
state boils down calls to transact! (including loads). With the sync tx processing you can therefore simply walk through
a sequence of calls and check the resulting state as you go.
27. Security
|
Note
|
This chapter has not been updated for Fulcro 3. Some information is likely out of date. |
Full production Fulcro apps, just like any other web-based software need some additional attention to ensure that there are no security holes that can be exploited. Fulcro can do nothing for you if you trust user strings in SQL string composition or make any of the other "old school" errors like those in The OWASP Top 10 Proactive Controls.
The most critical part of your application to secure is your network-based API. This involves low-level network security measures, authentication, and then often some additional authorization.
If you’re using unmodified Fulcro server code and client remotes then it is likely that you have not done enough to ensure your user’s safety. Here are the minimum measures (also note that I am not a security expert, and you system may have additional needs. You should do your homework.):
-
Use HTTPS for all authenticated access. Most people put something like nginx in front of their webapp for this.
-
Use secure cookies for authenticated sessions, to ensure you don’t accidentally send an authenticated session cookie over a non-secure connection.
-
If you’re using
wrap-sessionand assign a cookie to your user on pre-login HTTP access and then "upgrade" it on login you are opening your users to man-in-the-middle attacks.
-
-
Add middleware that checks for unexpected cross-origin requests.
-
Add code to prevent websocket hijacking (if you use websockets). Sente with its built-in CSRF is not sufficient.
-
Add code to do proper cross-site scripting prevention.
-
If you can see the CSRF token go across any AJAX interaction as payload data that requires nothing more than the session cookie (or less), then your security is broken. See this Stack Overflow Discussion for more information on correct ways to use CSRF tokens, and their relative pros/cons.
-
Fulcro 2.6.8+ includes some built-in support that implement some of these. Your application auth logic and server deployment matter, so do not trust that any web application (using Fulcro or any other library) is secure. You should always go through a complete security checklist and penetration testing.
27.1. Low-Level Network Security
First, start by reviewing your server middleware.
You should read through
Ring Defaults and understand what each one of the recommended middleware bits does, and add the ones that apply for you.
Pay particular attention to any related to SSL and cross-site things (wrap-frame-options, wrap-xss-protection, wrap-content-type-options, etc.).
Fulcro is not involved in your cookie/session/auth/SSL story. You will need to design, add, and configure that middleware and logic yourself. Do not trust Fulcro templates for security. They are meant to be starting points, and not production-ready code. These, by necessity, do not force SSL for example.
The ring.middleware.ssl has a few things you should throw in once you’ve got SSL working.
If you’re forcing all access to HTTPS before wrap-session can assign a cookie, then you won’t have to re-assign a different cookie for authenticated access, and it also allows you to add the :secure true option to wrap-session so that you can stop worrying about that mess.
See the Ring wrap-session documentation for more details about things like how to handle cookie regeneration on privilege escalation if you started out (i.e. need) a non-secure cookie for pre-authenticated session things.
27.1.1. CSRF
The most difficult and intricate thing to secure in your application is cross-site API requests.
Much of the "official" documentation on the web about XSS is about form submission, and wrap-anti-forgery middleware is built to allow you to secure form POST in exactly this scenario.
Fulcro does use POST for both queries and mutations, so adding this middleware will "work", in that all of your API requests will fail everywhere! This is probably stronger security than your users will find useful.
There are a number of approaches you can take to correct this. The easiest is to:
-
Configure your deployment for SSL always. Development mode can be configurable to turn off the middleware redirects and the secure marker on cookies, but you might want to have a careful deployment test to ensure non-SSL requests are always redirected in production and cookies are secure.
-
Put the CSRF token in a secure (but js-accessible) cookie or embed it in the HTML of the page of your Fulcro application. This will allow the startup code to access it. Make sure you understand the security around the generation of this token and how it works.
-
Add the CSRF to the headers of your Fulcro remote(s) as
X-CSRF-Token. This will allow your POSTs to get past thewrap-anti-forgerymiddleware. -
I also recommend that you enforce an origin header check just before the API handler. As you expand your software you might add endpoints that make you want to open up things with
Access-Control-Allow-Originon your server, but you probably don’t want those requests ever making it to your API as possible cross-site attacks. Fulcro comes with (as of 2.6.8)fulcro.server/wrap-protect-originsfor this purpose.
27.1.2. Example Securing a Normal Remote
When deploying to production you should stop using the "easy" server and roll your own. This section will cover the steps you need to do so, and you can also clone the complete source of this example.
The Server Config and Middleware
TODO: This chapter is still based on Fulcro 2. Most of the code is correct, but minor name tweaks are required (and of course testing).
Our demo app is going to take the approach of embedding the CSRF token in the HTML page that serves our Fulcro app. This is relatively easy to understand, and is as secure as form-based CSRF embedding. Hiccup makes short work of generating such a page:
(defn generate-index [{:keys [anti-forgery-token]}]
(timbre/info "Embedding CSRF token in index page")
(-> (h.page/html5 {}
[:head {:lang "en"}
[:meta {:charset "UTF-8"}]
[:script (str "var fulcro_network_csrf_token = '" anti-forgery-token "';")]]
[:body
[:div#app]
[:script {:src "/js/main/app.js"}]
[:script "security_demo.client.init()"]])
response/response
(response/content-type "text/html")))For middleware we can adopt ring-defaults to get most of the bits we need.
You want to be able to work in development, and also safely deploy to production, and since ring-defaults needs a number of config options we’d like to be able to tweak between the two we’ll put a secure set of those into our Fulcro defaults.edn config file as follows:
{:http-kit/config
{:port 3000}
:legal-origins
#{"localhost" "security-demo.lvh.me"}
:ring.middleware/defaults-config
{:params {:keywordize true
:multipart true
:nested true
:urlencoded true}
:cookies true
:responses {:absolute-redirects true
:content-types true
:default-charset "utf-8"
:not-modified-responses true}
:session {:cookie-attrs {:http-only true, :same-site :strict}}
:static {:resources "public"}
:security {:anti-forgery true
:hsts true
:ssl-redirect true
:frame-options :deny
:xss-protection {:enable? true
:mode :block}}}}and then create a middleware stack like this:
(ns security-demo.components.middleware
(:require
[clojure.pprint :refer [pprint]]
[fulcro.server :as server]
[hiccup.page :as h.page]
[mount.core :refer [defstate]]
[ring.middleware.defaults :refer [wrap-defaults]]
[ring.middleware.gzip :refer [wrap-gzip]]
[ring.util.response :as response]
[ring.util.response :refer [response file-response resource-response]]
[security-demo.api.mutations] ;; ensure reads/mutations are loaded
[security-demo.api.read]
[security-demo.components.config :refer [config]]
[security-demo.components.server-parser :refer [server-parser]]
[taoensso.timbre :as timbre]
[clojure.string :as str]))
(def ^:private not-found-handler
(fn [_]
{:status 404
:headers {"Content-Type" "text/plain"}
:body "NOPE"}))
(defn wrap-api
"Fulcro's API handler"
[handler]
(fn [request]
(if (= "/api" (:uri request))
(server/handle-api-request
server-parser
{:config config}
(:transit-params request))
(handler request))))
(defn generate-index [{:keys [anti-forgery-token]}]
(timbre/info "Embedding CSRF token in index page")
(-> (h.page/html5 {}
[:head {:lang "en"}
[:meta {:charset "UTF-8"}]
[:script (str "var fulcro_network_csrf_token = '" anti-forgery-token "';")]]
[:body
[:div#app]
[:script {:src "/js/main/app.js"}]
[:script "security_demo.client.init()"]])
response/response
(response/content-type "text/html")))
(defn wrap-uris
"Wrap the given request URIs to a generator function."
[handler uri-map]
(fn [{:keys [uri] :as req}]
(if-let [generator (get uri-map uri)]
(generator req)
(handler req))))
(defstate middleware
:start
(let [defaults-config (:ring.middleware/defaults-config config)
legal-origins (get config :legal-origins #{"localhost"})]
(timbre/debug "Configuring middleware-defaults with" (with-out-str (pprint defaults-config)))
(timbre/info "Restricting origins to " legal-origins)
(when-not (get-in defaults-config [:security :ssl-redirect])
(timbre/warn "SSL IS NOT ENFORCED: YOU ARE RUNNING IN AN INSECURE MODE (only ok for development)"))
(-> not-found-handler
wrap-api
server/wrap-transit-params
server/wrap-transit-response
(server/wrap-protect-origins {:allow-when-origin-missing? true
:legal-origins legal-origins})
(wrap-uris {"/" generate-index
"/index.html" generate-index})
(wrap-defaults defaults-config)
wrap-gzip)))|
Note
|
We delete index.html from our public resources, so that the wrap-uris middleware can dynamically generate it.
This is also handy for embedding things like hashed javascript names (e.g. from a shadow-cljs manifest.edn file).
|
Really, there is no change to how you set up APIs, but by putting it behind the CSRF protection of ring-defaults all POSTs will be rejected before they reach it.
The wrap-protect-origins is really paranoia, since a cross-site script would never know the token; however, the paranoia could be nice if the token was somehow exposed (or guessed).
|
Warning
|
When you deploy this to production behind a proxy server, you’ll want to set the :proxy option in Ring or you’ll get infinite redirects.
The production EDN config file for this example is shown below:
|
{:http-kit/config {:port 8080}
:ring.middleware/defaults-config {:proxy true}}Of course, now your client won’t be able to run queries or mutations against the server (since it isn’t sending the CSRF token)! Let’s fix that.
Securing the Client
Really all the client has to do is add CSRF headers to the request. You can do this with a very simple bit of Fulcro client middleware (supplied in 2.6.8+, but trivial to write):
;; in fulcro.client.network as of 2.6.8
(defn wrap-csrf-token
"Client remote request middleware. This middleware can be added to add an X-CSRF-Token header to the request."
([csrf-token] (wrap-csrf-token identity csrf-token))
([handler csrf-token]
(fn [request]
(handler (update request :headers assoc "X-CSRF-Token" csrf-token)))))The client should be changed to look like this:
(def secured-request-middleware
(->
(net/wrap-csrf-token (or js/fulcro_network_csrf_token "TOKEN-NOT-IN-HTML!"))
(net/wrap-fulcro-request)))
...
(fc/make-fulcro-client
{:networking {:remote (net/fulcro-http-remote {:url "/api"
:request-middleware secured-request-middleware})}})The client simply pulls the token out of the js var, and puts it in the correct header.
You could also use a js-accessible cookie for this step, which would let you go back to static HTML serving. See the earlier comments and links about CSRF.
Securing Sente Websockets (Fulcro 2.7+ with Sente 1.14+)
Older versions of Sente had a CSRF security hole, for which we had the documented workaround. New versions of Sente have a fix, so the implementation is much easier:
-
Make sure to include
wrap-anti-forgery(or enable it inwrap-defaults) in your middleware. -
Embed the CSRF token in your HTML as a js var or in the DOM itself. Serving the CSRF token in the HTML is an accepted security practice that prevents external discovery.
-
Send the CSRF token you find in cljs to the websocket constructor.
The websocket remote need only be passed the CSRF token:
(let [csrf-token js/embedded_csrf_token]
(fulcro.websockets/make-websocket-networking {:uri "/chsk"
:csrf-token csrf-token
...)See the documentation on general websockets for more information on their server-side setup other general options, but be sure to include the anti-forgery middleware so it runs before your API if you want to enforce CSRF protections.
28. Workspaces
The Fulcro template includes Workspaces. Please examine the template and Workspaces documentation for an example of a detailed setup. Workspace cards can house plain React components, non-active display of data-driven components, and complete segments of live applications. This makes them a very powerful way to focus your development effort.
29. Code Splitting (modules)
TODO: This chapter could use some updates, even though what it says will "work".
Clojurescript 1.9.854+ has expanded support for code splitting (older versions do too, but require a bit more code). The main things you need to do to accomplish code splitting are:
-
Make sure your main app doesn’t accidentally refer to things in the module. Hard dependencies make it impossible to split the code.
-
Define a mechanism whereby your loaded code can find and install itself into the application.
Since you’re working with a data-driven application with components that have queries, this typically means that you’re going to need to have the newly loaded components somehow modify the main application’s query to tie them in. Also, since parents technically render children, you’re going to need to have an extensible mechanism for that as well.
To demonstrate one technique we’ll assume that what you load is a "section" of the application that can be routed to. The main application knows to provide the link, but it does not yet have the rendering factory, class, or query.
29.1. Dynamic Routing and Code Splitting
The com.fulcrologic.fulcro.routing.legacy-ui-routers namespace includes a second kind of UI router that can be used with the routing tree: DynamicRouter.
A DynamicRouter uses a dynamic query to change routes instead of a union, and it can derive the details of the target component at runtime, meaning that it can be used to route to screens that were not in the loaded application code base at start-time.
Furthermore, the routing tree has been designed to trigger the proper dynamic module loads for your dynamically loaded routes so that code splitting your application can be a fairly simple exercise. Here are the basic steps:
-
Pick a keyword for the name of a given screen. Say
:main -
Write the
defscfor that screen, and design it so that the TYPE (first element) of the ident is the keyword from (1).-
The initial state must be defined, and it must have the name (1) under the key r/dynamic-route-key
-
The bottom of the file that defines the target screen must include a
defmethodthat associates the keyword (1) with the component (2). This is how the dynamic router finds the initial state of the screen, and the query to route to. -
IMPORTANT: Your dynamically loaded screen MUST have a call to
(cljs.loader/set-loaded! KW)at the bottom of the file (where KW is from (1)).
-
-
Configure your cljs build to use modules. Place the screen from (2) into a module with the name from (1).
-
Use a DynamicRouter for the router that will route to the screen (2). This means you won’t have to explicitly refer to the class of the component.
-
The Query that composes in the router must use the special
get-dynamic-router-queryto join in the DynamicRouter’s query.
-
-
Create your routing tree as usual. Remember that a routing tree is just routing instructions (keywords).
If you are routing through a DynamicRouter as part of your initial startup, then there are a few more steps. See Pre-loaded routes below.
Trigger routing via the route-to mutation.
That’s it!
The module rooted at the screen will be automatically loaded when needed.
The defsc and defmethod needed for step 2 look like this:
(comp/defsc Main [this {:keys [label]}]
{:initial-state (fn [params] {r/dynamic-route-key :main :label "MAIN"})
:ident (fn [] [:main :singleton])
:query [r/dynamic-route-key :label]}
(dom/div {:style {:backgroundColor "red"}}
label))
(defmethod r/get-dynamic-router-target :main [k] Main)
(cljs.loader/set-loaded! :main)29.1.1. Pre-loaded Routes
Screens used with DynamicRouter that are loaded at start-time are written identically to the dynamically loaded screen, but you will have to make sure their state and multimethod are set up at load time.
This can be done via the mutation r/install-route.
This mutation adds the screen’s state and multimethod component dispatch.
The demo application includes two such pre-installed routes (Login and NewUser), and one dynamically loaded one (main).
The code (called at application startup via :client-did-mount) to set up the pre-loaded routes and is:
(defn application-loaded! [app]
; Let the dynamic router know that two of the routes are already loaded.
(comp/transact! app `[(r/install-route {:target-kw :new-user :component ~NewUser})
(r/install-route {:target-kw :login :component ~Login})
(r/route-to {:handler :login})])
; Clojurescript requires you call this on every successfully "loaded" module:
(loader/set-loaded! :entry-point))
...
(make-fulcro-client Root {:client-did-mount application-loaded!})|
Warning
|
:client-did-mount in Fulcro isn’t the safest primitive, since it has to work with Native and Web. There
are some calls that require the React system to have fully-initialized before the system is truly stable. If you
need the system to be fully started before running code you may want to consider an alternative, such as
:componentDidMount of your real root component.
|
29.1.2. The Demo
Notice on initial load that the [:main :singleton] path in app state is not present.
You could use the console to verify that cards.dynamic_ui_main.Main is not present (via Javascript) either.
Once you route to Main, both will be present.
You should see the network load of the code when you route as well.
The book build configuration in project.clj has the module definitions, and looks like this:
{:id "book"
:source-paths ["src/main" "src/book"]
:compiler {:output-dir "resources/public/js/book"
:asset-path "js/book"
:modules {:entry-point {:output-to "resources/public/js/book/book.js"
:entries #{book.main}}
; For the dynamic code splitting demo
:main {:output-to "resources/public/js/book/main-ui.js"
:entries #{book.demos.dynamic-ui-main}}}}}The HTML file to start this up must load the base CLJS module (js/book/cljs_base.js) and the entry point book.js file.
The other code will be in main-ui.js and will be loaded when you route to that screen.
The file dynamic_ui_main.cljs is the code that will be dynamically loaded.
It looks like this:
(ns book.demos.dynamic-ui-main
(:require
[com.fulcrologic.fulcro.components :refer [defsc]]
[com.fulcrologic.fulcro.routing.legacy-ui-routers :as r]
[com.fulcrologic.fulcro.dom :as dom]
cljs.loader
[taoensso.timbre :as log]))
; This is a "screen" that we want to load with code-splitting modules. See the "demos" build in project.clj. The name
; of the module needs to match the first element of the ident, as that's how the dynamic router figures out what module
; to load.
(defsc Main [this {:keys [label main-prop]}]
{:query [r/dynamic-route-key :label :main-prop]
:initial-state (fn [params] {r/dynamic-route-key :ui-main :label "MAIN" :main-prop "main page data"})
:ident (fn [] [:ui-main :singleton])}
(dom/div {:style {:backgroundColor "red"}}
(str label " " main-prop)))
(defn ^:export init []
(log/info "dynamic ui main loaded"))
(defmethod r/get-dynamic-router-target :ui-main [k] Main)
(cljs.loader/set-loaded! :ui-main)The main entry point code is in the code below the demo:
(ns book.demos.dynamic-ui-routing
(:require
[com.fulcrologic.fulcro.routing.legacy-ui-routers :as r]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[cljs.loader :as loader]
[taoensso.timbre :as log]))
(defsc Login [this {:keys [label login-prop]}]
{:initial-state (fn [params] {r/dynamic-route-key :login :label "LOGIN" :login-prop "login data"})
:ident (fn [] [:login :singleton])
:query [r/dynamic-route-key :label :login-prop]}
(dom/div {:style {:backgroundColor "green"}}
(str label " " login-prop)))
(defsc NewUser [this {:keys [label new-user-prop]}]
{:initial-state (fn [params] {r/dynamic-route-key :new-user :label "New User" :new-user-prop "new user data"})
:ident (fn [] [:new-user :singleton])
:query [r/dynamic-route-key :label :new-user-prop]}
(dom/div {:style {:backgroundColor "skyblue"}}
(str label " " new-user-prop)))
(defsc Root [this {:keys [top-router :com.fulcrologic.fulcro.routing.legacy-ui-routers/pending-route]}]
{:initial-state (fn [params] (merge
(r/routing-tree
(r/make-route :ui-main [(r/router-instruction :top-router [:ui-main :singleton])])
(r/make-route :login [(r/router-instruction :top-router [:login :singleton])])
(r/make-route :new-user [(r/router-instruction :top-router [:new-user :singleton])]))
{:top-router (comp/get-initial-state r/DynamicRouter {:id :top-router})}))
:query [:ui/react-key {:top-router (r/get-dynamic-router-query :top-router)}
:com.fulcrologic.fulcro.routing.legacy-ui-routers/pending-route
r/routing-tree-key]}
(dom/div nil
; Sample nav mutations
(dom/a {:onClick #(comp/transact! this [(r/route-to {:handler :ui-main})])} "Main") " | "
(dom/a {:onClick #(comp/transact! this [(r/route-to {:handler :new-user})])} "New User") " | "
(dom/a {:onClick #(comp/transact! this [(r/route-to {:handler :login})])} "Login") " | "
(dom/div (if pending-route "Loading" "Done"))
(r/ui-dynamic-router top-router)))
; Use this as started-callback. These would happen as a result of module loads:
(defn application-loaded [app]
; Let the dynamic router know that two of the routes are already loaded.
(comp/transact! app [(r/install-route {:target-kw :new-user :component NewUser})
(r/install-route {:target-kw :login :component Login})
(r/route-to {:handler :login})]))29.2. Code Splitting and Server-Side Rendering
|
Note
|
This section has not been updated for Fulcro 3 and may not work as described. |
Version 2.5.2 of Fulcro added the support functions necessary to support server-side rendering of dynamic routes. The basics can be see in this example below:
One screen is defined in other.cljc:
(ns ssr-dynamic-routing.ui.other
(:require
#?(:cljs [cljs.loader :as loader])
#?(:cljs [com.fulcrologic.fulcro.dom :as dom] :clj
[com.fulcrologic.fulcro.dom-server :as dom])
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.routing.legacy-ui-routers :as r]))
(defsc Other [this {:keys [x]}]
{:query [r/dynamic-route-key :x]
:ident (fn [] [:other :singleton])
:initial-state (fn [_] {:x 1
r/dynamic-route-key :other})}
(dom/div nil (str "Other:" x)))
(defmethod r/get-dynamic-router-target :other [_] Other)
#?(:cljs (loader/set-loaded! :other))Another (with Root and the routing tree) is in main.cljc:
(ns ssr-dynamic-routing.ui.root
(:require
#?(:cljs [cljs.loader :as loader])
#?(:cljs [com.fulcrologic.fulcro.dom :as dom] :clj
[com.fulcrologic.fulcro.dom-server :as dom])
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.routing.legacy-ui-routers :as r]))
(def routing-tree (r/routing-tree
(r/make-route :main [(r/router-instruction :top-router [:main :singleton])])
(r/make-route :other [(r/router-instruction :top-router [:other :singleton])])))
(defsc Main [this {:keys [y]}]
{:query [r/dynamic-route-key :y]
:initial-state (fn [_] {r/dynamic-route-key :main
:y 3})
:ident (fn [] [:main :singleton])}
(dom/div (str "MAIN " y)))
(def ui-main (comp/factory Main))
(defsc Root [this {:keys [top-router]}]
{:query [{:top-router (r/get-dynamic-router-query :top-router)}]
:initial-state (fn [_] (merge
routing-tree
{r/dynamic-route-key :main
:top-router (comp/get-initial-state r/DynamicRouter {:id :top-router})}))}
(r/ui-dynamic-router top-router))
(defmethod r/get-dynamic-router-target :main [_] Main)
#?(:cljs (loader/set-loaded! :main))Notice that these look pretty much like what was described in the normal client stuff.
Next, the basic server is then:
(ns ssr-dynamic-routing.server
(:require
[ring.util.response :as resp]
[fulcro.easy-server :refer [make-fulcro-server]]
[fulcro.server-render :as ssr]
[ssr-dynamic-routing.ui.other :as other]
[ssr-dynamic-routing.ui.root :as root]
[com.fulcrologic.fulcro.dom-server :as dom]
[com.fulcrologic.fulcro.components :as comp]
[com.fulcrologic.fulcro.algorithms.denormalize :as fdn]
[com.fulcrologic.fulcro.routing.legacy-ui-routers :as r]))
(defn build-ui-tree [match]
(let [client-db (ssr/build-initial-state (comp/get-initial-state root/Root {}) root/Root)
final-db (-> client-db
;; CRITICAL: Install the routes, or their state won't be in the db
(r/install-route* :main root/Main)
(r/install-route* :other other/Other)
(r/route-to* match))]
;; CRITICAL: Pass the final database to get-query!!! Or you won't get the updated dynamic query
(fdn/db->tree (comp/get-query root/Root final-db) final-db final-db)))
(defn server-side-render [env {:keys [handler] :as match}]
(let [ui-tree (build-ui-tree match)
html (dom/render-to-str ((comp/factory root/Root) ui-tree))]
(-> (resp/response (str
"<html><body><div id='app'>"
html
"</div></body></html>"))
(resp/content-type "text/html"))))
(defn build-server
[{:keys [config] :or {config "config/dev.edn"}}]
(make-fulcro-server
:parser-injections #{:config}
;; Quick way to hack a couple of pages in with different match handlers
:extra-routes {:routes ["/" {"main.html" :main
"other.html" :other}]
:handlers {:main server-side-render
:other server-side-render}}
:config-path config))We’re using the easy server extra routes system to serve the pages.
These handlers conveniently return a map in bidi match format, which can be used with route-to*.
The critical pieces are marked:
-
Install the routes with
r/install-route*for each screen -
Use
route-to*to update the database to the correct desired route -
When you generate the UI tree with
db→tree, be sure to pass theget-querythe final db state after routing, otherwise the dynamic queries won’t be seen, and rendering will be incorrect.
30. Performance
Fulcro and React behave in a very performant manner for most data-driven applications. There are ways, however, in which you can negatively affect performance.
30.1. Development Compile Times
One of the most annoying performance problems when building your application is slow compile times. We all want sub-second rebuilds on our code base so that we can continue to work quickly. Here are some tips about keeping your compile times low:
-
Use shadow-cljs instead of the plain CLJS compiler. Especially if you plan on using external Javascript libraries from npm.
-
Keep your namespaces small and
:requiresections pruned. This is about "size of code to compile", but it’s more about the dependency graph. Whenever a save happens that new file needs to be compiled along with everything that depends on it, and files that depend on those files up the dependency tree. Having large files means a high false-positive factor in these reloads (reloading files whose code didn’t really depend on the subsection you changed). If a file has just a few artifacts (e.g. functions) per file then less code will depend on it and the recompile tree will be smaller for a given change.When you put large amounts of code in a single namespace then many of your other namespaces will likely depend on it (the probability of needing to
requireit goes up with the number of artifacts within it).Changing a single line of code in that large namespace not only will take a long time for that single namespace, but will trigger tons of unnecessary dependent recompiles. I’ve adopted this in my recent personal projects, and this successfully keeps my compile times quite low even as the source grows. Technically this could probably be solved at the compiler level, but it is a "hard problem" that may not be solved for some time (if ever).
-
You might want to use a [linter](https://github.com/candid82/joker) to detect unused requires.
-
Keep the compiler up-to-date. I’ve seen 10-20% performance boosts in single releases.
30.2. Removing Debug Logging
Fulcro uses https://github.com/ptaoussanis/timbre for logging. Several namespaces include high levels of debug or trace logging to help you debug dev-time issues. Timbre uses macros for logging such that all performance overhead of logging under a certain level can be completely removed from the code on a release build.
See compile time elision in the Timbre docs.
|
Warning
|
Elision can be done via an ENVIRONMENT variable that must be set before the compiler runs. Environment variables
cannot be changed by the running VM. Thus if you are running shadow-cljs server you cannot set the env variable in another
terminal and run a release build and expect it to work! If the server is running, then the command shadow-cljs release X
just sends a command to the already-running server, which will not have the environment variable.
|
30.3. Callbacks causing Over-rendering
A lot of people don’t realize that placing lambdas in their DOM can cause performance problems of various kinds:
-
A lambda closes over the surrounding environment, so it is regenerated every time it is executed.
-
The value of a lambda won’t compare as equal to the new one, meaning
shouldComponentUpdatechecks end up being useless.
The following code snippet contains both kinds of problems:
(defsc Comp [this props]
{:query ...}
(dom/div
;; computed props affect shouldComponentUpdate. The child will render any time the parent does, even if nothing
;; else changed but the lamda
(ui-child (comp/computed child-props {:onDelete #(comp/transact! this [(delete-child {:id %})])}))
;; The lamda in the on-click will be regenerated on every render
(dom/button {:onClick #(js/alert "Click!!!"))))Most of the time these kinds of functions can be fixed by generating the functions in a different context:
;; if there is no real data dependency on the component, just use a normal function defn
(defn click-alert! []
(js/alert "Click!"))
(defsc Comp [this props]
{:query ...
:initLocalState (fn [this props]
;; put the onDelete (which needs to close over `this`) into component-local state
{:onDelete #(comp/transact! this [(delete-child {:id %})])})}
(let [{:keys [onDelete]} (comp/get-state this)]
(dom/div
;; The computed props are no longer changing, so shouldComponentUpdate will be accurate on child-props
(ui-child (comp/computed child-props {:onDelete onDelete}))
;; The onClick now points to a pre-calculated value
(dom/button {:onClick click-alert!))))30.4. Poor Query Performance
This is a potential source of performance issues in Fulcro UIs. Evaluating the UI query is relatively fast, but relative is the key word. The larger the query, the more work that has to be done to get the data for it. Remember that you compose all component queries to the root. If you do this with only joins and props, then your root query will ask for everything that your UI could ever show! This will perform poorly as your application gets large.
The solution to this is to ensure that your query contains only the currently relevant things. There are two primary solutions for this: use union or dynamic queries. Fortunately this is what you naturally want to do anyhow to get UI "routing".
The com.fulcrologic.fulcro.routing.legacy-ui-routers namespace includes primitives for building UI routes using unions
(the unions are written for you).
It has a number of features, including the ability to nicely integrate with HTML5 history events for full HTML5 routing
in your application.
In the dynamic query approach you use comp/set-query! to actually change the query of a component at runtime in
response to user events.
There are two "dynamic routers" that use dynamic queries to change their current query so it only includes the "current" route.
The older of these is present in the legacy-ui-routers namespace for legacy support, and should probably not be used for new projects.
It is also important to note that you need not normalize things that are really just big blobs of data that you don’t intend to mutate. An example of this is large reports where the data is read-only and only displayed in one place. You could write a big nested bunch of components, normalize all of the parts, and write a query that joins it all back together; however, that incurs a lot of overhead both in loading the data, and every time you render.
Instead, realize that a property query like [:report-data] can pull any kind of (serializable, if you want tools
support) value from the application state. You can put a js/Date there. You can put a map there. Anything.
Furthermore, this query is super-fast since it just pulls that big blob of data from app state and adds it to the result tree. Structural sharing makes that a very simple and fast operation.
Link queries back to the root node that do not use a join are also quite fast. You can query for an entire
(normalized) table or other root prop (from anywhere) with the query element [:table-name '_] (that would go
inside of the query vector). That is fast because it just puts a reference to the entire map into the props
result with no further processing. This is particularly good when you’re trying to let the user select something
from a table, and denormalizing the items in the table (and keeping a list of idents) would be somewhat slow. You can
easily process 1000’s of items from a table in a UI component on-the-fly using this query trick, since it has so little
overhead itself.
30.5. Poor React Performance
|
Important
|
If you are using Guardrails, then many function calls in Fulcro will incur a spec check overhead that can severely impact performance. Additionally Fulcro Inspect instrumentation in development mode will add quite a bit of overhead to transaction processing. Measurements should always be done with Guardrails disabled, and preferably against a release build where Inspect instrumentation is completely stripped. |
In general Fulcro should be able to handle a pretty high frame-rate. In fact, the design is meant to provide 60FPS rendering in general-purpose use. Remember, however, that there are a number of stages in rendering, and each of them has an overhead. Large UIs can have negative performance impacts at both the query and DOM layers.
Since React does your rendering it is best to understand how to best optimize it using their suggestions and documentation.
Note that Fulcro already ensures that shouldComponentUpdate is defined to an optimal value that should prevent a
regen/diff of VDOM when data hasn’t really changed.
Some general tips to start with in React are:
-
Make sure your components have a stable react key. If the key changes, React will ignore the diff and redo the DOM. This is very slow. So, if you’ve generated keys using something like random numbers just to get warnings to go away, then you’re asking for trouble.
-
You’re generally better off changing CSS classes than DOM structure to affect visibility. For example, having a
(when render? (dom/div …))will cause entire sections to be inserted and removed from the DOM. Using a class is much more efficient:(dom/div {:classes [(when-not render? " hidden")]} …). -
Large DOM. React is pretty good with eliminating unnecessary changes, but that is still no reason to try to render a table with 1000’s of rows. Paginate. Use virtual scrolling.
-
Use query-free
defsccomponents to break up large UI within a component. In this case the idea is that you may not need subcomponents for query/normalization, but if you define them they will provide theshouldComponentUpdateoptimization for the props you pass them. -
DO include empty props maps, even though they are optional. The DOM generators in Fulcro allow you to elide the props if you don’t have any, but doing so means the macro cannot do certain compile-time optimizations.
(dom/div {} (dom/div {} …))is about 3x faster at runtime than(dom/div (dom/div …)).
30.5.1. Pluggable Rendering Optimization
Different applications will have differing needs. Fulcro 3 makes it possible to plug in different optimization strategies so that you can tune the global rendering optimization to your needs.
There are 3 pre-defined plugins, and you can write your own:
- Keyframe-render
-
Defined in
com.fulcrologic.fulcro.rendering.keyframe-render/render!. Relies completely on:shouldComponentUpdateand always renders from root. Simplest to use, because you are guaranteed correctness without hassle; however, may be slow in some circumstances (complex UIs). - Ident-optimized Render
-
DEPRECATED. React 18 make this approach difficult with async rendering. Defined in
com.fulcrologic.fulcro.rendering.ident-optimized-render/render!. Uses on-screen components to figure out what to diff in state (compares db from prior render) and targets refreshes to just those components. Does not understand dependent data (i.e. you render a calculated fact derived from ui data, like a count of items). Slightly more complex to use, but works much faster than keyframe when only one thing typically changes on the screen at a time. - Keyframe-render2
-
RECOMMENDED. (Available in 3.0.12 and above). Defined in
com.fulcrologic.fulcro.rendering.keyframe-render2/render!. Just like keyframe render, but allows a:only-refresh [..list of idents…]parameter ontransact!that tells the system to ONLY update the given components. This can give you component-local state performance, but requires you to tell it when such a targeted update is allowed (so there is no calculation overhead). This is a great renderer for optimizing when inputs are too slow, since you know exactly the ident of the thing you are changing, and otherwise keeps the application as simple as possible.
Using Keyframe Render 2
As of 3.1 we highly recommend using keyframe render 2 in most applications. By default it prevents confusion around dependent data rendering, and can also be made about as fast as component-local state for targeted optimization.
In general you should set up your application as follows when using keyframe render 2:
-
Read the IMPORTANT note above about turning off Guardrails and using a release build when measuring.
-
Set the renderer to
keyframe-render2. -
Set
:shouldComponentUpdatein your top-most components to(fn [_ _ _] true). This seems counter-intuitive, but the keyframe render is going to try to render your root on most data changes, and the chances your props changed in some way at the top-most layers of your component tree are very high. The defaultshouldComponentUpdatein Fulcro components compares old and new props, which is a rather expensive operation the closer you are to the root (props have more in them). If the path you’re struggling with on performance has parents that don’t (themselves) render much on the way to your problem child then circumventing this check can be a big win. -
In the operations that "feel slow" add an
:only-refreshparameter to the optional parameter map oftransact!. This option is implemented in thekeyframe-render2renderer, and will do targeted updates of components related to the data listed.
For example:
(defsc SomeForm [this props]
{:ident (fn [this props] [:component/id :form])
:query [:some/prop]}
(dom/input {:onChange (fn [evt] (comp/transact! this [(save ...)] {:only-refresh [[:component/id :form]]}))}))will queue up a refresh of components that have the ident [:component/id :form].
or
(defsc SomeForm [this props]
{:ident (fn [this props] [:component/id :form])
:query [:some/prop]}
(dom/input {:onChange (fn [evt] (comp/transact! this [(save ...)] {:only-refresh [:some/prop]}))}))will queue up refresh of components that query for :some/prop.
In either case no data diff calculations occur, and the renderer will skip rendering from root and will instead directly refresh just the components requested. This allows you fine-grained control refresh and can easily achieve the performance levels of component-local state while still using the central database!
Ident-optimized render
DEPRECATED: Async rendering (React 18) and hooks make this renderer obsolete. You should no longer use it.
The ident-optimized render is the most complex of the options. It is described below mainly
to inform you of the kind of things an optimized renderer can do, in case you want to roll your own. The description
includes the optimizations that are always done by the defsc component.
-
Each component has a
shouldComponentUpdatethat checks to see if the props have actually changed. If a component is asked to "double render" or render without changed props, then it will short-circuit (e.g. it is a PureComponent). Checking this fact in CLJS is very fast, since we use immutable data structures where reference comparisons are enough to ensure two things are identical. -
Fulcro keeps indexes of mounted components by their idents (and can also look them up by query keywords). Thus, at any given time it knows exactly which on-screen components "represent" something like
[:person/id 1]or query for attributes like:person/name. It keeps these up to date via hooks on React’s lifecycle. -
At certain points in processing (e.g. after any optimistic action in a mutation or the arrival of a network result) a refresh is scheduled.
-
AFTER every render, it records a snapshot of what the state database looked like. This is cheap because of immutable data and structural sharing (e.g. ns time-scale…copy a single 64-bit reference).
-
The ident-optimized render does the following:
-
It reads all of the "mounted component" idents from its internal indexes. This is the list of "data that matters" to things on the screen. This usually be significantly smaller than what is actually in the database.
-
If finds the "component to refresh" by checking to see if the table entries at these idents are identical (reference compare) to the last rendered version. It can then translate a "change table entry" into a set of components using the indexes. Typically only 1-2 components will be found. This stage typically takes under a millisecond.
-
For all components that need a refresh:
-
It runs those component’s queries to get new props and "tunnels" those new props to the components (via a hidden property in component-local state (e.g. React
setState)).
-
-
So, a form with 50 fields on-screen will do roughly 50 64-bit compares (to find stale data), run 1-2 queries against
the state database targeted at the affected components, and call React setState a couple of times (which has
the exact speed of component-local state, since that’s what it’s leveraging).
In some applications the number of components to refresh might be more than 2 or 3. In those cases it turns out that
the overhead of 4+ calls to React’s setState can start to add up to more than a root render. In those cases we
recommend that you try the keyframe-render2, where you can isolate rendering to a single component or the entire
root.
31. Production Debug
Sometimes it happens that data in production causes a hard-to-diagnose issue that you just cannot reproduce locally. In cases like these it is sometimes quite useful to have Inspect available. The Inspect hooks are normally elided at compile time for UI performance, but you can force the hooks to remain by setting a compiler option:
;; inside of any build config
:compiler-options {:closure-defines {com.fulcrologic.fulcro.inspect.inspect_client/INSPECT true}}Release builds that have that define set will allow the Inspect tool to work in production.
|
Warning
|
Exposing the internal application details makes it much easier to see the data of the application, which may not be acceptable from a security perspective. The performance implications can also be significant. Ideally you would make an "alternate index" page that loads an inspect-enabled version of your app so that your primary page can serve the fully-optimized one. |
It is also possible to include proper source maps in a production build, which makes source-level debugging the production application easier. See the Shadow-cljs or Clojurescript compiler documentation for details on doing that.
32. Testing
Fulcro has a companion library called Fulcro Spec. It includes some BDD helper macros that wraps Clojure(script) test, and provides you with a number of helpful features:
-
Outline-based specification output.
-
A Mocking/expectation system.
-
Improved assertions with easier labelling.
-
All of the functions from
clojure.testwork inside of specifications (e.g.is,are, etc).
See the documentation at the repository for more details.
32.1. Specifications
A specification is just a helpful wrapper around clojure.test/deftest.
It looks like this:
(specification "The thing you're testing"
...)You may wish to use deftest if your tooling recognizes it better.
32.1.1. Controlling Which Tests Run
Adding keywords after the string name of a specification marks that specification for targeting (it adds metadata with that keyword set to true to the test). You can define any number of these targeting keywords:
(specification "Some Database Operation" :integration :focused
...)32.2. Behaviors, Components, and Assertions
These macros assist you in organizing your specification.
The behavior and component macros just increase readability.
The assertions macro can add descriptions for each assertion, and gives a nice human-readable notation:
(specification "Math"
(component "Addition"
(assertions
"Works with positive integers"
(+ 1 1) => 2
"Works with negative integers"
(+ -2 -2) => -4)))32.3. Exceptions
It is common to want to test error handling code.
The assertions macro supports checking for, and pattern-matching against, exceptions.
It supports several notations for the right-hand side.
The most platform-neutral syntax for exceptions is to use a map on the right-hand side which can contain the keys (all optional, but you should supply at least one):
...
(assertions
"Throws when arg is nil"
(f nil) =throws=> ExceptionInfo
(g nil) =throws=> #"message pattern"
...Using an exception type passes if that kind of exception is thrown.
Using a regex passes if the message in the exception matches.
Of course you can also use is and clojure.test exception facilities for other combinations, if needed.
32.4. Functional Assertions
Often you don’t need a data comparison as much as you need to run a predicate on the result of a function:
...
(assertions
"Returns odd numbers"
(f) =fn=> odd?)32.5. Mocking and Spies
One of the most important features of sustainable testing is the ability to test things in isolation. Any kind of coupling can result in cascading failures that make tests difficult to write/maintain/understand. Fulcro Spec has a mocking system that is concise and allows you to do a number of advanced things. The basic syntax looks like this:
(defn f [v] ...)
(defn g [] (f 1) 33)
(specification "g"
(let [real-f f] ; save f into a temporary binding
(when-mocking
(f arg) => (do ; rebinds `f` to this code
(real-f arg) ; spy! Call the real original f
(assertions
"calls f with 1"
arg => 1))
(g))))There’s a lot going on here.
The when-mocking macro looks for any number of arrow-separated triples (like (f v) ⇒ 1) and re-binds the real function to an internally scripted one that captures the arguments and makes them available to the code on the right-hand side of the triple (see arg above).
The form to the right of the ⇒ is run instead of the original function, and it can make assertions on the args or even invoke the original.
If you specify a mock and it isn’t called, then the specification will fail.
Thus, a check that f is actually called is also implied by this test!
32.5.1. Specifying Call Count
It may be useful (or even necessary) to specify the number of times a function is called when mocking. The default is "at least once". You can write a more complex scenario simply by adding a multiplier into the arrow!
(defn f [] 99)
(defn g [] (+ (f) (f))
(specification "g"
(assertions
"produces the sum of two calls to f (coupled to the real definition of f)"
(g) => 198))
(when-mocking
(f arg) => 2
(assertions
"produces the sum of two calls to f (mocking returns same thing over and over)"
(g) => 4))
(when-mocking
(f arg) =1x=> 2
(f arg) =1x=> 4
(assertions
"produces the sum of two calls to f (called exactly twice is enforced, and different values returned)"
(g) => 6)))32.5.2. Checking Order
When call counts are specified they imply order, and that order is checked as well by the internals of mocking.
For example a 1x mock of f, g, f will fail if f is called twice before g.
32.5.3. Limitations
Fulcro spec has some limitations that are inherent to the underlying programming language/VM.
-
It cannot mock inline, protocols, or macros.
-
You’re always creating "partial mocks". Expanding a function will often invalidate the mocking around it.
33. Headless Framework
The headless framework is designed for developers who want to drive their Fulcro application entirely from a Clojure REPL, whether for testing, rapid prototyping, or exploring application behavior without browser overhead. It provides the same synchronous execution model as the CLJ testing framework, but adds richer capabilities for inspecting rendered output and simulating user interactions.
33.1. Why a Headless Framework?
Traditional web development involves a tight loop between your editor and browser. You make a change, refresh the browser, click through the UI to reach the state you want to test, and observe the results. This works, but it has friction: browser startup time, manual navigation, and the cognitive overhead of context-switching between code and UI.
The headless framework offers an alternative workflow. Because Fulcro components are pure functions of their props, and because the entire application state lives in a single atom, there’s no fundamental reason the application needs a browser to run. The framework renders your components to hiccup data structures instead of DOM nodes, preserving event handler functions so you can invoke them programmatically.
This means you can write a component, create a headless app at the REPL, populate it with test data, render a frame, and inspect exactly what the UI would look like - all without leaving your editor. When you find a bug, you can step through mutations and examine state changes one transaction at a time. When you’re satisfied, you can codify your REPL explorations into automated tests.
33.2. Getting Started
The framework spans several namespaces, each with a conventional alias:
(require
[com.fulcrologic.fulcro.headless :as h]
[com.fulcrologic.fulcro.headless.hiccup :as hic]
[com.fulcrologic.fulcro.headless.loopback-remotes :as remotes]
[com.fulcrologic.fulcro.headless.timers :as timers]
[com.fulcrologic.fulcro.raw.application :as rapp]
[com.fulcrologic.fulcro.dom-server :as dom])The main namespace headless (aliased as h) provides app creation, render frame capture, and state inspection.
The hiccup namespace (aliased as hic) provides conversion from dom-server Element trees to hiccup, plus utilities for searching and interacting with hiccup trees.
The remotes namespace provides various remote implementations that execute locally rather than over HTTP.
The timers namespace provides mock timer control for testing timeout-dependent behavior.
The rapp namespace (raw.application) provides current-state for direct state access.
The dom-server namespace provides DOM element functions that produce server-side Element records - the same alias you’d use for com.fulcrologic.fulcro.dom in ClojureScript, which is the point: your CLJC components use dom/div, dom/button, etc., and the reader conditionals swap in the appropriate implementation.
Creating a headless application is straightforward:
(def app (h/build-test-app {:root-class Root}))This returns a standard Fulcro application configured for synchronous execution.
You interact with it using all the normal Fulcro APIs - comp/transact!, df/load!, and so on.
The key difference is that when these functions return, all resulting work has completed: optimistic updates applied, remote calls made and responses merged, renders triggered.
33.3. Configuring build-test-app
The build-test-app function creates a Fulcro application configured for synchronous testing with several configurable options:
(h/build-test-app
{:root-class Root
:remotes {:remote (remotes/pathom-remote my-parser)}
:initial-state {:app/current-user [:user/id 1]}
:render-history-size 20
:shared {:translations {...}}
:shared-fn (fn [root-tree] {:app-root root-tree})})33.3.1. Options
- root-class
-
(Required for frame capture) The root component class of your application. Without this, render frame capture won’t work, though you can still use the app for mutations and state management.
- remotes
-
A map of remote-name to remote implementation. Each remote should implement the Fulcro remote protocol with
:transmit!and:abort!functions. If not provided, a default no-op remote is created that logs a warning and returns empty responses.{:remote (remotes/pathom-remote my-parser) :api (remotes/sync-remote api-handler) :metrics (remotes/mock-remote {`send-metric {:status :ok}})} - initial-state
-
Initial state map to merge with the root component’s initial state. This lets you override or extend the default initial state for specific test scenarios. The merge happens after
initialize-state!runs, so this value takes precedence.:initial-state {:ui/loading? false :current-user [:user/id 1] :user/id {1 {:user/id 1 :user/name "Test User"}}} - render-history-size
-
Number of render frames to keep in history (default 10). Each frame captures the full state, denormalized tree, and rendered output, so larger values use more memory. Adjust based on how far back you need to look during testing.
- shared
-
Static shared props available to all components via
comp/shared. Useful for configuration, i18n functions, or other app-wide utilities.:shared {:translations tr-fn :api-base-url "https://test.example.com"} - shared-fn
-
Function that computes shared props from the root component’s denormalized tree. Called on each render, allowing shared props to depend on current app state. Use this for values that need to stay in sync with app state.
:shared-fn (fn [root-tree] {:current-locale (:user/locale root-tree)})
33.3.2. Return Value
build-test-app returns a standard Fulcro application with these enhancements:
-
Synchronous transaction processing - all operations complete before function returns
-
Frame-capturing render - each render is automatically captured to history
-
Event capture - transactions and network events are recorded for inspection
-
Hook support - React-style hooks work via simulated state management
The returned app supports all normal Fulcro APIs: comp/transact!, df/load!, merge/merge-component!, etc.
33.3.3. Event Capture
|
Important
|
Event capture requires the JVM property -Dcom.fulcrologic.fulcro.inspect=true to be set.
This enables Fulcro’s inspect notification system, which the headless framework uses to capture events.
|
Event capture is automatically installed when you create an app with build-test-app.
It records all transactions (mutations) and network events for later inspection:
;; Create app
(def app (h/build-test-app {:root-class Root
:remotes {:remote my-remote}}))
;; Trigger some mutations
(comp/transact! app [(add-todo {:text "Buy milk"})])
(df/load! app :current-user User)
;; Inspect what happened
(h/captured-transactions app)
;; => [{:fulcro.history/tx [(add-todo {:text "Buy milk"})]
;; :fulcro.history/network-sends #{:remote}
;; :component "app.ui/TodoList"
;; :ident-ref [:todo-list/id :main]}
;; ...]
(h/captured-network-events app)
;; => [{:event-type :started
;; :fulcro.inspect.ui.network/remote :remote
;; :fulcro.inspect.ui.network/request-edn [:current-user ...]
;; ...}
;; {:event-type :finished
;; :fulcro.inspect.ui.network/remote :remote
;; :fulcro.inspect.ui.network/response-edn {:current-user ...}
;; ...}]Each captured transaction includes:
-
:fulcro.history/tx- The transaction form (mutation symbol and params) -
:fulcro.history/network-sends- Set of remotes that will be contacted -
:component- Name of the component that initiated the transaction (if any) -
:ident-ref- The ident of the component (if any)
Each captured network event includes:
-
:event-type- One of:started,:finished, or:failed -
:fulcro.inspect.ui.network/remote- The remote name -
:fulcro.inspect.ui.network/request-id- Unique request identifier -
:fulcro.inspect.ui.network/request-edn- The EQL sent (on:started) -
:fulcro.inspect.ui.network/response-edn- The response body (on:finished) -
:fulcro.inspect.ui.network/error- Error info (on:failed)
33.3.4. Convenience Functions for Event Capture
The headless namespace provides several convenience functions for working with captured events:
last-transaction
Get the most recently captured transaction:
(h/click! app "add-button")
(let [tx (h/last-transaction app)]
(is (= 'app.mutations/add-item (-> tx :fulcro.history/tx first))))transaction-mutations
Extract just the mutation symbols from all captured transactions:
(h/click! app "btn1")
(h/click! app "btn2")
(is (= ['app.mutations/action1 'app.mutations/action2]
(h/transaction-mutations app)))clear-captured-events!
Clear all captured transactions and network events. Useful for isolating assertions between test phases:
;; Phase 1
(h/click! app "load-btn")
(is (= 1 (count (h/captured-transactions app))))
;; Clear for phase 2
(h/clear-captured-events! app)
;; Phase 2
(h/click! app "save-btn")
(is (= 1 (count (h/captured-transactions app))))33.4. DOM Rendering and Hiccup Conversion
Before diving into the API, it’s worth understanding how the framework handles DOM rendering.
In the browser, Fulcro’s dom namespace provides functions like dom/div and dom/button that create React elements.
These eventually become actual DOM nodes that the user sees and interacts with.
In the headless environment, the dom-server namespace provides identically-named functions that produce Element records - the same records used for server-side rendering:
(dom/div {:id "container" :onClick handle-click}
(dom/span {} "Hello")
(dom/button {:onClick submit} "Submit"))
;; Produces a dom-server Element record
;; => #com.fulcrologic.fulcro.dom_server.Element{:tag "div" :attrs {...} :children [...]}To inspect and interact with this structure, you convert Element records to hiccup using hic/rendered-tree→hiccup:
(hic/rendered-tree->hiccup element)
;; => [:div {:id "container" :onClick #function[...]}
;; [:span {} "Hello"]
;; [:button {:onClick #function[...]} "Submit"]]The function rendered-tree→hiccup accepts dom-server Element records or component instances (the result of calling a factory with props).
It cannot render a component class directly since there would be no props.
To render a specific component from app state, use h/hiccup-for:
;; Render a specific component by class and ident
(h/hiccup-for app UserProfile [:user/id 42])
;; For components with constant idents (like Root), ident is optional
(h/hiccup-for app Root)The crucial detail is that event handlers remain as actual functions, not stringified or lost.
This is what enables the framework to simulate user interactions - when you "click" a button, you find the element in the hiccup tree, extract its :onClick function, and call it.
Because your Fulcro components are written in CLJC files, they can use either DOM implementation depending on whether they’re compiled for ClojureScript or run on the JVM:
(ns app.ui
(:require
#?(:clj [com.fulcrologic.fulcro.dom-server :as dom]
:cljs [com.fulcrologic.fulcro.dom :as dom])))The namespace aliasing handles this automatically.
33.5. Inspecting Application State
The most basic form of inspection is reading the normalized database directly.
Use rapp/current-state from com.fulcrologic.fulcro.raw.application:
(require '[com.fulcrologic.fulcro.raw.application :as rapp])
(rapp/current-state app)This returns the raw state map - the same thing you’d see in Fulcro Inspect’s DB tab. For quick checks and debugging, this is often sufficient.
More often, you want to see the denormalized props that a component would receive.
The current-props function handles the denormalization for you:
(h/current-props app UserProfile [:user/id 42])This runs the component’s query against the state, following ident references and assembling the nested data structure. The result is exactly what your component’s render function would receive as its first argument.
For simple entity lookups without query-based denormalization, use get-in on the state:
(get-in (rapp/current-state app) [:user/id 42])This returns the entity map stored at that location in the state.
33.6. Render Frames
A render frame is a snapshot of your application at a specific moment. It captures the normalized state, the denormalized prop tree, and the rendered dom-server Element tree. The framework maintains a bounded history of frames, allowing you to compare before and after states.
To capture a frame:
(h/render-frame! app)This forces a render cycle and stores the result. You can then access it:
(h/last-frame app)
;; => {:state {...} :tree {...} :rendered #Element{...} :timestamp 1234567890}The :tree key contains the denormalized props that flowed through your component hierarchy.
The :rendered key contains the raw dom-server Element tree.
The :state key is a snapshot of the normalized database at render time.
To inspect the rendered output as hiccup, use hic/rendered-tree→hiccup on the :rendered value, or use the convenience function h/hiccup-frame:
;; Convert manually
(hic/rendered-tree->hiccup (:rendered (h/last-frame app)))
;; Or use the convenience function
(h/hiccup-frame app) ; most recent frame
(h/hiccup-frame app 1) ; one frame agoFor testing, the ability to capture multiple frames is particularly valuable. A common pattern is to capture a frame, perform an operation, capture another frame, and then assert on the differences:
(h/render-frame! app)
(comp/transact! app [(toggle-completed {:id 1})])
(h/render-frame! app)
(let [history (h/render-history app)
after (first history)
before (second history)]
;; Compare states, verify specific changes
)The history is kept in newest-first order, and its size is controlled by the :render-history-size option when creating the app.
33.7. Simulating User Interaction
The real power of preserved event handlers is the ability to simulate what happens when a user interacts with your UI.
The headless.hiccup namespace provides functions for common interactions.
The workflow is: get the hiccup tree, find the element, invoke its handler.
To simulate clicking an element:
(let [hiccup (h/hiccup-frame app)
button (hic/find-by-id hiccup "submit-button")]
(hic/click! button))This finds the element with id="submit-button" in the hiccup tree, extracts its :onClick handler, and invokes it.
Because transaction processing is synchronous, when this call returns, all the effects of that click have completed - the mutation ran, any remote calls finished, the state updated.
For form inputs:
(let [hiccup (h/hiccup-frame app)
field (hic/find-by-id hiccup "email-field")]
(hic/type-text! field "user@example.com"))This invokes the :onChange handler with a synthetic event containing the specified value.
There’s also a generic invoke-handler! for other event types like :onBlur or :onFocus:
;; Invoke onBlur handler
(hic/invoke-handler! (hic/find-by-id hiccup "field") :onBlur {})
;; Submit a form
(hic/invoke-handler! (hic/find-by-id hiccup "login-form") :onSubmit {})These functions let you write tests that read like user stories: fill in this field, click this button, verify this message appears. The synchronous execution eliminates the need for async test machinery or arbitrary waits.
33.8. Finding Elements in Hiccup
The headless.hiccup namespace provides flexible element finding.
All search functions operate on a hiccup tree (get one with h/hiccup-frame).
Find an element by its ID attribute:
(let [hiccup (h/hiccup-frame app)]
(hic/find-by-id hiccup "my-element"))For finding elements by predicate, use find-all or find-first:
(let [hiccup (h/hiccup-frame app)]
;; Find all email inputs
(hic/find-all hiccup
(fn [elem]
(and (= :input (hic/element-tag elem))
(= "email" (hic/element-attr elem :type))))))There are also convenience functions find-by-tag and find-by-class for common queries:
(let [hiccup (h/hiccup-frame app)]
;; Find all buttons
(hic/find-by-tag hiccup :button)
;; Find all elements with a specific class
(hic/find-by-class hiccup "error-message"))For testing assertions, you can use the element-exists?, text-of, and attr-of functions:
(let [hiccup (h/hiccup-frame app)]
;; Check if an element exists
(is (hic/element-exists? hiccup "submit-button"))
;; Get text content of an element
(is (= "Invalid email" (hic/text-of hiccup "error-message")))
;; Check an attribute value
(is (= true (hic/attr-of hiccup "submit-button" :disabled))))Additional element inspection functions:
;; Get element parts
(hic/element-tag elem) ;; => :div
(hic/element-attrs elem) ;; => {:id "foo" :className "bar"}
(hic/element-children elem) ;; => ["text" [:span {} "child"]]
(hic/element-text elem) ;; => "text child" (recursive)
;; CSS class helpers
(hic/element-classes elem) ;; => #{"bar" "baz"}
(hic/has-class? elem "bar") ;; => true33.9. App-Level UI Interaction Helpers
While you can always work with hiccup directly via the headless.hiccup namespace, the headless namespace provides convenience functions that operate on the most recent render frame of your app.
These are ideal for simple test scenarios where you just want to interact with the current UI state.
All of these functions work on the most recent frame captured by the app. They find the element in the hiccup tree and invoke the appropriate handler.
33.9.1. click!
Click an element by its ID:
(h/click! app "submit-btn")This finds the element with id="submit-btn" in the most recent frame and invokes its :onClick handler.
Because transaction processing is synchronous, when this returns, all effects of the click have completed.
33.9.2. type-into!
Type text into an input element by ID:
(h/type-into! app "email-input" "user@example.com")This invokes the element’s :onChange handler with {:target {:value "user@example.com"}}.
33.9.3. change!
Invoke an onChange handler with a custom event:
;; For a checkbox
(h/change! app "remember-me" {:target {:checked true}})
;; For a select
(h/change! app "country-select" {:target {:value "US"}})For simple text input, prefer type-into!.
Use change! when you need to provide custom event properties.
33.9.4. blur!
Trigger blur on an element:
(h/blur! app "username-input")Invokes the element’s :onBlur handler.
33.9.5. invoke-handler!
Invoke an arbitrary event handler on an element:
(h/invoke-handler! app "my-element" :onMouseEnter {})
(h/invoke-handler! app "draggable" :onDragStart {:dataTransfer ...})Use this for handlers not covered by the convenience functions above.
33.10. App-Level UI Inspection Helpers
The headless namespace also provides convenience functions for inspecting the rendered UI. Like the interaction helpers, these operate on frames from your app’s render history.
All inspection functions support an optional frame index parameter. Frame index 0 is the most recent frame, 1 is one frame ago, etc.
33.10.1. element
Find an element by ID:
(h/element app "submit-btn")
;; => [:button {:id "submit-btn" :onClick #fn} "Submit"]
;; Check element from 2 frames ago
(h/element app "submit-btn" 2)Returns the hiccup element or nil if not found.
33.10.2. elements-by-class
Find all elements with a CSS class:
(h/elements-by-class app "error-message")
;; => [[:div {:className "error-message"} "Invalid email"]]33.10.3. elements-by-tag
Find all elements with a specific tag:
(h/elements-by-tag app :button)
;; => [[:button {...} "Save"] [:button {...} "Cancel"]]33.10.4. text-of
Get the text content of an element by ID:
(h/text-of app "welcome-message")
;; => "Hello, John!"
;; Compare text before and after
(let [before (h/text-of app "counter" 1)
after (h/text-of app "counter" 0)]
(is (not= before after)))33.10.5. attr-of
Get an attribute value from an element by ID:
(h/attr-of app "email-input" :value)
;; => "user@example.com"
(h/attr-of app "submit-btn" :disabled)
;; => true33.10.6. classes-of
Get the CSS classes of an element as a set:
(h/classes-of app "submit-btn")
;; => #{"btn" "btn-primary" "loading"}33.10.7. exists?
Check if an element exists:
(is (h/exists? app "welcome-message"))
(is (not (h/exists? app "error-message")))33.10.8. has-class?
Check if an element has a specific CSS class:
(is (h/has-class? app "submit-btn" "loading"))
(is (not (h/has-class? app "submit-btn" "disabled")))33.10.9. visible?
Check if an element is visible:
(is (h/visible? app "modal"))|
Note
|
This only checks inline styles for display: none or visibility: hidden.
CSS classes that hide elements are not detected.
|
33.10.10. input-value
Get the current value of an input element:
(is (= "user@example.com" (h/input-value app "email-input")))Shorthand for (h/attr-of app id :value).
33.10.11. checked?
Check if a checkbox or radio input is checked:
(is (h/checked? app "remember-me"))33.10.13. count-elements
Count elements matching a predicate:
;; Count all list items
(is (= 5 (h/count-elements app #(= :li (hic/element-tag %)))))
;; Count error messages
(is (= 0 (h/count-elements app #(hic/has-class? % "error"))))33.11. Text-Based Interaction
When writing tests, it’s often more natural to interact with UI elements by their visible text rather than by IDs. The headless framework provides functions for finding and clicking elements by their text content.
These functions work on the most recent render frame and support flexible text matching.
33.11.1. click-on-text!
Click an element by its text content:
(h/click-on-text! app "View All")
(h/click-on-text! app "New" 1) ; click second 'New' link
(h/click-on-text! app #"Logout")
(h/click-on-text! app ["Account" "View"]) ; element containing bothPattern can be:
-
A string (substring match)
-
A regex (pattern match)
-
A vector of patterns (all must match)
The optional n parameter specifies which match to click (0-indexed, default 0).
This function implements event bubbling semantics: if the matched element doesn’t have an :onClick handler, it walks up the ancestor chain to find one.
This mirrors how real DOM events work.
The function also checks :text and :label attributes on React component elements, making it work with custom components.
33.11.2. type-into-labeled!
Type into an input field identified by its label:
(h/type-into-labeled! app "Username" "john.doe")
(h/type-into-labeled! app "Password" "secret123")
(h/type-into-labeled! app #"(?i)email" "user@example.com")
(h/type-into-labeled! app "Amount" "100.00" 1) ; second Amount fieldThis finds an input element associated with a label matching the pattern, then invokes the input’s :onChange handler.
Pattern matching works the same as click-on-text!: strings, regexes, or vectors.
The optional n parameter specifies which matching labeled field to use (0-indexed, default 0), useful when multiple fields have similar labels.
33.11.3. find-by-text
Find all elements whose text content matches the pattern:
(h/find-by-text app "Submit")
(h/find-by-text app #"Account.*")
(h/find-by-text app ["Important" "Notice"])Returns a vector of matching hiccup elements.
33.11.4. text-exists?
Check if any element with the given text content exists:
(is (h/text-exists? app "Welcome, John!"))
(is (not (h/text-exists? app "Error")))33.12. Component Testing Without a Full App
For testing individual components in isolation, the headless framework provides functions that don’t require a full Fulcro application. This is faster and simpler when you just want to test a component’s rendering logic.
33.12.1. render-component
Render a component instance with hook support:
(require '[com.fulcrologic.fulcro.react.hooks :as hooks])
(let [ctx (hooks/make-rendering-context)
result (h/render-component ctx (ui-counter {:count 0}))]
(is (= [:div ...] (hic/rendered-tree->hiccup result))))The ctx parameter can be either:
-
A headless app from
build-test-app -
A lightweight rendering context from
hooks/make-rendering-context
Use a rendering context for pure component tests. Use a full app when you need remotes, routing, or other app infrastructure.
The function returns a dom-server Element tree.
Use hic/rendered-tree→hiccup to convert to hiccup for assertions.
33.12.2. render-component-hiccup
Convenience function that renders a component and returns hiccup directly:
(let [ctx (hooks/make-rendering-context)
hiccup (h/render-component-hiccup ctx (ui-counter {:label "Count:"}))]
(is (= "Count:" (hic/element-text (hic/find-by-id hiccup "label")))))33.12.3. mount-component
Mount a component with automatic re-render on state changes:
(let [ctx (hooks/make-rendering-context)
mounted (h/mount-component ctx ui-counter {:label "Count:"})]
;; Check initial render
(is (= "0" (hic/element-text (hic/find-by-id (h/current-hiccup mounted) "count"))))
;; Click increment - re-renders automatically!
(hic/click! (hic/find-by-id (h/current-hiccup mounted) "inc"))
;; State is updated
(is (= "1" (hic/element-text (hic/find-by-id (h/current-hiccup mounted) "count")))))Unlike render-component, this sets up a render callback so that when a state setter (from useState) is called, the component automatically re-renders.
This makes tests more natural - you interact with the component and the hiccup updates automatically.
Returns a MountedComponent record.
Use current-hiccup to get the latest render.
current-hiccup
Get the current hiccup from a mounted component:
(let [mounted (h/mount-component ctx ui-widget {:id 1})
hiccup (h/current-hiccup mounted)]
(is (hic/element-exists? hiccup "widget-title")))This reflects the latest render after any state changes.
update-props! and set-props!
Update the props of a mounted component and re-render:
;; Update with a function
(h/update-props! mounted #(assoc % :count 5))
;; Set directly
(h/set-props! mounted {:count 10 :label "Total:"})unmount-component!
Unmount a component, running any cleanup effects:
(h/unmount-component! mounted)This clears the render callback and hook state. Use it when testing component cleanup behavior.
33.13. Loopback Remotes
The headless.loopback-remotes namespace provides a comprehensive suite of remote implementations for different testing scenarios.
Each remote executes locally (loopback) instead of making network requests, giving you full control over the testing environment.
33.13.1. sync-remote - Direct Handler Integration
The simplest remote wraps any function:
(remotes/sync-remote
(fn [eql]
;; Receive EQL, return response
{:user/id 1 :user/name "Alice"}))The handler receives the EQL query/mutation and should return the response body (the data to merge into app state).
Options
- simulate-latency-ms
-
Add artificial delay to simulate network latency. Useful for testing loading states.
(remotes/sync-remote handler :simulate-latency-ms 500) - transform-request
-
Transform the EQL before calling the handler.
(remotes/sync-remote handler :transform-request (fn [eql] ;; Add metadata or modify query (with-meta eql {:user-id 1}))) - transform-response
-
Transform the response after the handler.
(remotes/sync-remote handler :transform-response (fn [response] ;; Add computed properties (assoc response :timestamp (System/currentTimeMillis)))) - on-error
-
Custom error handling.
(remotes/sync-remote handler :on-error (fn [error eql] {:status-code 404 :body {:error-message "Not found"}}))
Async Handler Support
The handler can return a core.async channel:
(remotes/sync-remote
(fn [eql]
(async/go
;; Do async work
(async/<! (async/timeout 100))
{:result :success})))The remote will block on <!! until the channel delivers a value.
33.13.2. pathom-remote - Pathom Integration
For backends using Pathom (version 2 or 3), you can connect directly to your parser:
(remotes/pathom-remote my-parser
:env-fn (fn [] {:db (get-db-connection)
:current-user (test-user)}))The :env-fn is called for each request, allowing you to provide request-scoped context.
This tests your actual resolver logic without HTTP serialization overhead.
Pathom 3 Example
(require '[com.wsscode.pathom3.connect.operation :as pco])
(require '[com.wsscode.pathom3.interface.eql :as p.eql])
(def env
(pci/register
[(pco/resolver 'current-user
{::pco/output [:user/id :user/name]}
(fn [_env _input]
{:user/id 1 :user/name "Test User"}))]))
(remotes/pathom-remote
(p.eql/boundary-interface env)
:env-fn (fn [] {:db (test-db)}))Pathom 2 Example
(remotes/pathom-remote my-pathom2-parser
:env-fn (fn []
{:request {:session {:user/id 1}}}))Async Parsers
If your parser returns a core.async channel, use the :async? option:
(remotes/pathom-remote async-parser
:async? true
:env-fn (fn [] {...}))33.13.3. ring-remote - Ring Handler Testing
Test your full Ring middleware stack:
(remotes/ring-remote my-ring-app
:uri "/api/graphql"
:session {:user/id 1}
:headers {"Authorization" "Bearer token"})This simulates a full HTTP round-trip, useful for testing authentication, authorization, and other middleware behavior.
Options
- uri
-
API endpoint URI (default "/api")
- method
-
HTTP method (default :post)
- content-type
-
Request content type (default "application/edn")
- headers
-
Additional headers to include
- session
-
Session data to include in request
- encode-fn
-
Function to encode EQL to request body (default
pr-str) - decode-fn
-
Function to decode response body (default
read-string)
Example with Custom Encoding
(require '[clojure.data.json :as json])
(remotes/ring-remote my-app
:content-type "application/json"
:encode-fn json/write-str
:decode-fn #(json/read-str % :key-fn keyword))33.13.4. fulcro-ring-remote - Full Fulcro Middleware Stack
Simulates the complete Fulcro HTTP remote with Transit encoding:
(remotes/fulcro-ring-remote my-ring-app
:uri "/api"
:cookies {"session" {:value "abc123"}}
:session {:user/id 1})This provides the same middleware pipeline as the ClojureScript fulcro-http-remote, but calls a Ring handler directly instead of making HTTP requests.
Cookies set by responses are automatically included in subsequent requests, enabling testing of authentication flows:
(let [app (h/build-test-app
{:root-class Root
:remotes {:remote (remotes/fulcro-ring-remote my-handler)}})]
;; First request - server sets session cookie
(comp/transact! app [(login {:username "test" :password "pass"})])
;; Second request - session cookie automatically included
(df/load! app :current-user User)
;; Server sees the session cookie and knows who we are
;; Can inspect the remote state
(-> app :com.fulcrologic.fulcro.application/runtime-atom
deref :com.fulcrologic.fulcro.application/remotes
:remote :state deref :cookies))Options
- uri
-
API endpoint URI (default "/api")
- request-middleware
-
Client request middleware chain. Defaults to
wrap-fulcro-request. Build chains using→orcomp.(defn wrap-auth-header [handler token] (fn [request] (handler (update request :headers assoc "Authorization" (str "Bearer " token))))) (remotes/fulcro-ring-remote my-app :request-middleware (-> identity (remotes/wrap-fulcro-request) (wrap-auth-header "my-token"))) - response-middleware
-
Client response middleware chain. Defaults to
wrap-fulcro-response.(defn wrap-error-logging [handler] (fn [response] (when (not= 200 (:status-code response)) (log/error "Request failed:" response)) (handler response))) (remotes/fulcro-ring-remote my-app :response-middleware (-> identity (remotes/wrap-fulcro-response) wrap-error-logging)) - cookies
-
Initial cookies map. Format:
{"name" {:value "value"}}or{"name" "value"}. - session
-
Session data to include in requests.
- transit-write-handlers
-
Additional transit handlers for encoding.
- transit-read-handlers
-
Additional transit handlers for decoding.
33.13.5. mock-remote - Canned Responses
Return predefined responses based on query patterns:
(remotes/mock-remote
{`my-mutation {:result :success}
[{:users [:user/id :user/name]}] [{:user/id 1 :user/name "John"}]
:default {}})Keys can be:
-
A complete EQL query/mutation (exact match)
-
A mutation symbol (matches any mutation with that symbol)
-
:default- Fallback for unmatched requests
Function-Based Mocking
For more dynamic behavior, pass a function:
(remotes/mock-remote
(fn [eql]
(cond
(= eql [{:users [:user/id]}])
[{:user/id 1} {:user/id 2}]
(and (list? (first eql))
(= 'app.mutations/delete-user (ffirst eql)))
{:deleted true}
:else
nil)) ; Use default behavior
:default-response {})Return nil to fall through to default behavior.
Options
- default-response
-
Response for unmatched requests (default {})
- simulate-latency-ms
-
Add artificial delay
- on-unmatched
-
Function called for unmatched requests when no default
33.13.6. recording-remote - Request Verification
Wrap another remote to record all requests:
(let [{:keys [remote recordings]} (remotes/recording-remote
:delegate (remotes/sync-remote handler))]
(set-remote! app :remote remote)
;; Make requests
(comp/transact! app [(my-mutation)])
(df/load! app :users User)
;; Verify what was sent
(is (= 2 (count @recordings)))
(is (= 'my-mutation (ffirst (:eql (first @recordings)))))
(is (= [{:users [:user/id :user/name]}]
(:eql (second @recordings)))))Each recording is a map with:
-
:eql- The EQL query/mutation -
:timestamp- When the request was made -
:response- The response returned
33.13.7. failing-remote - Error Testing
Always fail with a specific status code:
;; Always fail
(remotes/failing-remote
:status-code 500
:error-message "Server error")
;; Fail after 2 successful requests
(remotes/failing-remote
:fail-after 2
:delegate (remotes/sync-remote handler)
:status-code 503
:error-message "Service unavailable")Useful for testing error handling and retry logic.
Options
- status-code
-
HTTP status code (default 500)
- error-message
-
Error message to include
- body
-
Response body (default {})
- fail-after
-
Number of successful requests before failing (default 0)
- delegate
-
Remote to use for successful requests
33.13.8. delayed-remote - Loading State Testing
Hold results until explicitly delivered:
(def remote (remotes/delayed-remote (remotes/sync-remote handler)))
(def app (h/build-test-app
{:root-class Root
:remotes {:remote remote}}))
;; Start a load
(df/load! app :users User)
;; Load is pending - can test loading UI
(is (= :loading (h/attr-of app "spinner" :data-state)))
;; Deliver the results
(remotes/deliver-results! remote)
;; Now the data is loaded
(is (seq (h/elements-by-class app "user-card")))This is invaluable for testing loading states and spinners.
Unlike simulate-latency-ms, you have precise control over when results arrive.
33.13.9. Choosing the Right Remote
The choice of remote depends on what you’re testing:
-
For unit testing a mutation’s optimistic behavior, use
mock-remotewith simple canned responses -
For integration testing your resolver logic, use
pathom-remote -
For verifying your middleware behaves correctly, use
fulcro-ring-remote -
For testing error handling, use
failing-remote -
For testing loading states with precise control, use
delayed-remote -
For verifying what requests were sent, wrap any remote with
recording-remote
33.14. Controlling Time
Many Fulcro features involve timeouts: UI state machines can schedule delayed events, dynamic routing has timeout states, and application code might debounce user input. Testing timeout behavior is notoriously difficult because real time is unpredictable.
The headless.timers namespace solves this by intercepting Fulcro’s scheduling system.
Within the with-mock-timers macro, time is frozen and under your control:
(timers/with-mock-timers
;; Time starts at 0
;; Start a state machine that schedules a 5-second timeout
(uism/begin! app login-machine ::login {} {})
(uism/trigger! app ::login :submit {})
;; The timeout is scheduled but hasn't fired
(is (= :authenticating (uism/get-active-state app ::login)))
(is (= 1 (timers/pending-timer-count)))
;; Advance time past the timeout
(timers/advance-time! 5001)
;; Now the timeout handler has executed
(is (= :timed-out (uism/get-active-state app ::login))))You can advance time incrementally with advance-time!, jump to a specific time with set-time!, fire all pending timers immediately with fire-all-timers!, or cancel everything with clear-timers!.
The pending-timers and pending-timer-count functions let you verify that the expected timeouts are scheduled.
This makes timeout testing completely deterministic. You can verify the exact moment a timeout fires, test that operations complete before timeouts, and ensure your timeout durations are correct.
33.15. Practical Workflow
A typical REPL-driven development session with the headless framework might look like this:
Start by creating an app with your root component and appropriate remotes:
(def app (h/build-test-app
{:root-class Root
:remotes {:remote (remotes/pathom-remote my-parser)}}))Render a frame and examine the initial state:
(h/render-frame! app)
(h/hiccup-frame app)Simulate user interactions and observe the results:
(let [hiccup (h/hiccup-frame app)]
(hic/type-text! (hic/find-by-id hiccup "search") "clojure")
(hic/click! (hic/find-by-id hiccup "search-button")))
;; After the transaction, get a fresh render
(h/render-frame! app)
(hic/find-by-class (h/hiccup-frame app) "search-result")When something unexpected happens, inspect the state:
(rapp/current-state app)
(h/current-props app SearchResults [:search/id :current])Once you understand the behavior, codify it as a test:
(deftest search-returns-results
(let [app (h/build-test-app {...})]
(let [hiccup (h/hiccup-frame app)]
(hic/type-text! (hic/find-by-id hiccup "search") "clojure")
(hic/click! (hic/find-by-id hiccup "search-button")))
(h/render-frame! app)
(is (= 3 (count (hic/find-by-class (h/hiccup-frame app) "search-result"))))))Between test scenarios, reset the app to a clean state:
(h/reset-app! app)This workflow keeps you in the REPL where Clojure shines, while still exercising your complete application stack.
33.16. Integration with Dynamic Routing
Dynamic routing in Fulcro involves the router component, route targets with will-enter, and an underlying state machine.
Routes can be immediate or deferred depending on whether data needs to load first.
With synchronous execution, testing routing is straightforward:
(let [app (h/build-test-app {:root-class Root
:remotes {:remote my-remote}})]
(dr/initialize! app)
(dr/change-route! app ["users" "42"])
;; Route has completed synchronously
(is (= ["users" "42"] (dr/current-route app Root))))For deferred routes that load data, the remote call completes synchronously, so the route transitions to its final state immediately. Combined with timer mocking, you can test timeout states for slow routes:
(timers/with-mock-timers
(dr/change-route! app ["slow-page"]
{:deferred-timeout 100})
;; Advance past the deferred timeout
(timers/advance-time! 150)
;; Verify we're showing the loading UI
(is (some? (hic/find-by-id (h/hiccup-frame app) "loading-indicator"))))33.17. Summary
The headless framework transforms Fulcro development by removing the browser from the inner loop. You can explore your application interactively at the REPL, simulate user interactions programmatically, and write comprehensive integration tests that run quickly as part of your normal test suite.
The key insight is that Fulcro’s architecture - pure component functions, centralized state, declarative queries - naturally supports running without a DOM. The headless framework simply provides the infrastructure to make this practical: dom-server rendering with hiccup conversion, synchronous transaction processing, loopback remotes, and mock timers.
Whether you use it for test-driven development, debugging complex state transitions, or just exploring how your UI behaves, the framework provides a powerful complement to browser-based development.
34. Server-side Rendering
Single-page applications have a couple of concerns when it comes to how they behave on the internet at large.
The first is size.
It is not unusual for a SPA to be several megabytes in size. This means that users on slow networks may wait a while before they see anything useful. Network speeds are continually on the rise so this is becoming less and less of an issue. If this is your only concern then it might be poor accounting to complicate your application just to shave a few ms off the initial load.
After all, with proper serving you can get their browser to cache the js file for all but the first load of your site.
You often, in fact, would do well to follow examples like gmail that simply show a loading progress bar. You’re writing client-side applications, and this is often quite good enough (and much simpler).
Another concern is SEO. If you have pages on your application that do not require login and you would like to have in search engines, then a blank HTML page with a javascript file may have a more limited reach (though search engines are getting better and better about indexing even SPAs).
Fortunately, Fulcro has you covered for any of these options!
Server-side rendering not only works well in Fulcro, the central mechanisms of Fulcro (a client-side database with mutations) and the fact that you’re writing in one language actually make server-side rendering shockingly simple, even for pages that require data from a server-side store!
After all, all of the functions and UI component queries needed to normalize the tree that you already know how to generate on your server can be in CLJC files and can be used without writing anything new!
If you’re writing your UI in CLJC files to support server-side rendering then you need to make sure you use a conditional reader to pull in the proper server DOM functions for Clojure:
(ns app.ui
(:require
#?(:clj [com.fulcrologic.fulcro.dom-server :as dom]
:cljs [com.fulcrologic.fulcro.dom :as dom]))34.1. Overall Structure
Here’s how to structure your application to support SSR:
-
Write the entire client in CLJC.
-
Any pure js components from NPM will need to have wrappers that emit something "sane" for clojure.
-
-
The server will use the client initial app state plus a sequence of mutation implementations to build a "starting state" normalized database based on the route.
-
The server will serve the same basic HTML page (from code) that has the following:
-
The CSS and other head-related stuff and the div on which your app will mount.
-
A div with the ID of your SPA’s target mount, which will contain the HTML of the server-rendered application state
-
A script tag that embeds the server-generated normalized db (the one used in to render on the server) as a transit-encoded string on
js/window. -
A script tag at the bottom that loads your client SPA code
-
-
The client will look for initial state via a var set on
js/window(transit-encoded string), and use that as the initial state of the app. -
The client will mount (using the
:hydrate?application option), which will cause react to hook up to the existing DOM.
34.1.1. Building the App State on the Server
There are two approaches to building the app state on the server.
- Headless App
-
You can actually run the application itself in a headless mode with "loopback" remotes (e.g. a remote that directly calls your parser instead of doing network ops), trigger mutations, wait for things to settle down (queues are done on timeouts), and then get the props from that app’s state for rendering. This is currently not the recommended approach since the feature is not well-tested and is missing a few hooks that would make it more approachable. Contributions desired.
- State Building
-
You can grab the initial state using
build-initial-state, and then run a series of mutation helpers (functions from state db → state db) to evolve the state into the one desired, and then use that db to generate props, render the first frame, and send that state for use on the client. This is the preferred approach, since it is free from timing issues.
The com.fulcrologic.fulcro.algorithms.server-render namespace has a function called build-initial-state that takes the root component and an initial state tree.
It normalizes this and plugs in any union branch data that was not in the tree itself (by walking the query and looking for components that have initial state and are union branches).
It returns a normalized client application db that would be what you’d have on the client at initial startup if you’d started the client normally.
So, now all you need to do is run any combination of operations on that map to bring it to the proper state. Here’s the super-cool thing: your renderer is pure! It will render exactly what the state says the application is in!
(let [base-state (ssr/build-initial-state (my-app/get-initial-state) my-app/Root)
user (get-current-user (:session req))
user-ident (comp/get-ident my-app/User user)]
(-> base-state
(todo-check-item-impl* 3 true) ; some combo of mutation impls
(assoc :current-user user-ident) ; put normalized user into root
(assoc-in user-ident user)))So now you’ve got the client-side db on the server. Now all you need to do is pre-render it, and also get this generated state to the client!
34.1.2. Rendering with Initial State
Of course, the whole point is to pre-render the page. Now that you have a complete client database this is trivial:
(let [props (fdn/db->tree (comp/get-query app/Root normalized-db) state-map state-map)
root-factory (comp/factory app/Root)]
(binding [comp/*app* YOUR-APP] ; some APIs look for your fulcro-app in this bound var.
(dom/render-to-str (root-factory props))))will generate a string that contains the current HTML rendering of that database state!
34.1.3. Send The Completed Package!
Now, while you have the correct initial look, you will still need to get this database state into the client. While you could technically try loading your UI’s initial state, it would make the UI flicker because when React mounts it needs to see the exact DOM that is already there. So, you must pass the server-side generated-database as initial-state to your client.
The function com.fulcrologic.fulcro.algorithms.server-render/initial-state→script-tag will give you a <script> tag that includes a string-encoded EDN data structure (using transit).
We now combine what we learned about generating the application’s rendering with this to get the overall response from the server:
(defn top-html [app normalized-db root-component-class]
(let [props (db->tree (get-query root-component-class) normalized-db normalized-db)
root-factory (factory root-component-class)
app-html (binding [comp/*app* app] (dom/render-to-str (root-factory props)))
initial-state-script (ssr/initial-state->script-tag normalized-db)]
(str "<!DOCTYPE html>\n"
"<html lang='en'>\n"
"<head>\n"
"<meta charset='UTF-8'>\n"
"<meta name='viewport' content='width=device-width, initial-scale=1'>\n"
initial-state-script
"<title>Home Page</title>\n"
"</head>\n"
"<body>\n"
"<div id='app'>"
app-html
"</div>\n"
"<script src='js/app.js' type='text/javascript'>app.client.start_from_ssr();</script>\n"
"</body>\n"
"</html>\n")))Now let’s move on to the client.
34.1.4. Client-Side – Use Initial State
When creating your client, you will now be explicit about initial state and use a helper function (provided) to decode the server-sent state:
(ns app.client
(:require ...))
(defonce app (app/fulcro-app))))
(defn ^:export start-from-ssr
"Start the application after a server-side render"
[]
(let [db (ssr/get-SSR-initial-state)]
(reset! (::app/state-atom app) db)
(app/mount! app Root "app" {:hydrate? true :initialize-state? false})))You can keep your original start code for cases where you want to start the app without SSR (e.g. development?).
35. Logging
Fulcro 3 uses Timbre. Read the documentation on that website for changing logging levels, eliding logging statements, etc.
35.1. Logging Helpers
The logging output of errors in CLJS leaves something to be desired when used with stock Timbre. Fortunately, this is quite configurable, and Fulcro provides a couple of useful helpers that can make the js console error messages much more useful and readable.
If you use Ghostwheel to spec and instrument your functions, then problems with parameters and return values will have much better error messages (see also expount, which ghostwheel will help configure). Unfortunately the logging defaults in cljs will munge these nice error messages into a very poorly wrapped string format.
The com.fulcrologic.fulcro.algorithms.timbre-support namespace includes functions that will make this better.
The recommended use of these functions is as follows:
-
Make sure you’re using Binaryage devtools (on classpath. shadow-cljs will auto-add it when detected).
-
IMPORTANT: Enable custom formatters in console settings for Chrome. This will print cljs data as cljs (instead of raw js).
-
Make a development preload cljs file, and tell shadow-cljs to preload it.
-
In the preload file, add something like this:
(ns app.development-preload
(:require
[taoensso.timbre :as log]
[com.fulcrologic.fulcro.algorithms.timbre-support :refer [console-appender prefix-output-fn]))
(log/set-level! :debug)
(log/merge-config! {:output-fn prefix-output-fn
:appenders {:console (console-appender)}})and you’ll get much more readable error messages in the js console.
|
Note
|
when logging errors, be sure to log the exception first. This is documented in timbre, but easy to miss: |
(try
...
(catch :default ex
(log/error ex ...))36. Advanced Fulcro Internals
Fulcro, as with any library, has quite a bit of internal implementation detail. It is difficult for the outside developer to know which of these details are "safe to touch". Fulcro 3 is intended to be easily moddable, and many of the internal data structures, algorithms, and configuration values are open to modification. Of course, it pays to understand what you’re getting into when you attempt such a modification.
36.1. The Transaction Processing System
Most things that happen in a Fulcro app go through the transaction processing system.
Even loads (e.g. df/load!) issue a special transaction that is only interested in the server’s response. UISM adds
functions in front of transact!, but they still go through there.
It might help to further clarify that fulcro does not watch the state atom (Inspect does, but that’s a tool,
not the library itself). So, if you swap! against the state atom outside of a mutation, then you are doing
an advanced thing that is circumventing a lot of Fulcro.
Rendering refresh is a by-product of transaction steps (or an explicit request to do so). The default built-in tx processing schedules renders after optimistic updates from mutations, on the arrival/merge of network results, etc.
The default algorithm is in tx_processing.cljc. You can replace this algorithm with an option on the application, but
realize that the core algorithm provides the implementation for many features:
-
Pessimistic transactions
-
Ordered Network operations
-
Sending writes before reads
-
Parallel reads
-
Read/write combining
-
Splitting transactions across multiple remotes
-
Scheduling rendering
-
Running optimistic (action) code
-
Sending updates to Inspect (when enabled)
As you can see, much of Fulcro’s interesting behaviors are directly implemented here, so touching it can break a lot of stuff.
If you want to change the transaction processing, you set the :submit-transaction! setting of your application
and change it to submit the transaction to your own system. You can of course derive a new one from the existing
source.
The safest use of this option is as a wrapper that does some additional stuff you’d like to do on every transaction (or even morphs the submitted parameters), but then calls the existing logic.
36.2. Fulcro Application – What’s in there?
A Fulcro application is just a map. You can hold it as a value in a defonce. Anything that needs to change within the app is
represented as an atom within that map.
The application is an open map. You can put anything in the app just about anywhere you want, as long as your keys are namespaced to a domain you own to ensure nothing will collide. Certain data structures, such as network queues, are probably best left alone unless you really know what you’re doing.
Here is what the starting map looks like (from application.cljc):
(ns com.fulcrologic.fulcro.application
(:require
[com.fulcrologic.fulcro.algorithms.tx_processing :as txn])
...
(let [tx! (or submit-transaction! txn/default-tx!)]
{::id (tempid/uuid)
::state-atom (atom (or initial-db {}))
::config {:load-marker-default load-marker-default
:client-did-mount (or client-did-mount (:started-callback options))
:external-config external-config
:query-transform-default query-transform-default
:load-mutation load-mutation}
::algorithms {:com.fulcrologic.fulcro.algorithm/tx! tx!
:com.fulcrologic.fulcro.algorithm/abort! (or abort-transaction! txn/abort!)
:com.fulcrologic.fulcro.algorithm/optimized-render! (or optimized-render! mrr/render!)
:com.fulcrologic.fulcro.algorithm/initialize-state! initialize-state!
:com.fulcrologic.fulcro.algorithm/shared-fn shared-fn
:com.fulcrologic.fulcro.algorithm/render-root! render-root!
:com.fulcrologic.fulcro.algorithm/hydrate-root! hydrate-root!
:com.fulcrologic.fulcro.algorithm/unmount-root! unmount-root!
:com.fulcrologic.fulcro.algorithm/render! render!
:com.fulcrologic.fulcro.algorithm/remote-error? (or remote-error? default-remote-error?)
:com.fulcrologic.fulcro.algorithm/global-error-action global-error-action
:com.fulcrologic.fulcro.algorithm/merge* merge/merge*
:com.fulcrologic.fulcro.algorithm/default-result-action! (or default-result-action! mut/default-result-action!)
:com.fulcrologic.fulcro.algorithm/global-eql-transform (or global-eql-transform default-global-eql-transform)
:com.fulcrologic.fulcro.algorithm/index-root! indexing/index-root!
:com.fulcrologic.fulcro.algorithm/index-component! indexing/index-component!
:com.fulcrologic.fulcro.algorithm/drop-component! indexing/drop-component!
:com.fulcrologic.fulcro.algorithm/props-middleware props-middleware
:com.fulcrologic.fulcro.algorithm/render-middleware render-middleware
:com.fulcrologic.fulcro.algorithm/schedule-render! schedule-render!}
::runtime-atom (atom
{::app-root nil
::mount-node nil
::root-class root-class
::root-factory nil
::basis-t 1
::last-rendered-state {}
::static-shared-props shared
::shared-props {}
::remotes (or remotes
{:remote {:transmit! (fn [{::txn/keys [result-handler]}]
(log/fatal "Remote requested, but no remote defined.")
(result-handler {:status-code 418 :body {}}))}})
::indexes {:ident->components {}}
::mutate mut/mutate
::render-listeners (cond-> {}
(= tx! txn/default-tx!) (assoc ::txn/after-render txn/application-rendered!))
::txn/activation-scheduled? false
::txn/queue-processing-scheduled? false
::txn/sends-scheduled? false
::txn/submission-queue []
::txn/active-queue []
::txn/send-queues {}})})))Many of the names are somewhat revealing, but we’ll expand on some important ones below. We’re assuming we’re in the
com.fulcrologic.fulcro.application namespace when we use :::
::state-atom-
This is where your app’s Fulcro DB is stored. You are allowed to directly view this atom, or even
swap!orreset!it. Remember that Fulcro does not watch this atom for rendering. So do not expect refresh to recognize your changes. You can, however, callschedule-render!to notify Fulcro that state has changed. While you can read atom in your UI (i.e.(app/current-state this)) do not expect UI refreshes to understand that you did. Refresh is strictly based on props that pass to the component from its parent. Therefore, reading it in any UI code is almost certainly the sign of broken code. See Link Queries. ::runtime-atom-
This is where Fulcro keeps track of things over time that are not your application’s data (and are never rendered). Things like network queues, remotes, shared props, what "relative time" it is (basis-t), etc. You are allows to read anything in here, and you are allowed to add your own keys for things you need to track. In fact this is a sanctioned place for you to track anything that has a time-based component to it that isn’t app state. RAD, for example, uses this to track the definitions for rendering plugins (which need to be refreshed on hot code reload). Remember that you can easily get access to the application map via
(comp/any→app this), meaning that most runtime code has easy access to this atom without any namespace requires. This makes it very easy to access "global" configuration and runtime information in a non-global way. ::indexes-
This is an index of UI classes and on-screen React instances. These indexes are created and managed as components are added to the system and mounted/unmounted. The
componentnamespace includes functions for using these indexes, but they are simple data structures you are allowed to read directly. You should not modify the indexes unless you’re working on Fulcro internals (e.g. changing how components work, adding React hooks support). ::config-
This is a static map that cannot change over time (no atom) that can hold anything that you expect won’t change for the lifetime of the app. THIS MAP IS CONSIDERED UNSTABLE, so if you read the values from it directly you will have to keep track of Fulcro’s internal changes over time. It is possible that some or all of these values could move to the
runtime-atom. You are allowed to put your own nsed keys in this map. ::basis-t-
An integer indicating the current "render time". This time is added to props metadata during
db→treeand is part of the props tunnelling algorithm that allows local refreshes of components without having to render from root. Targeted refresh sends new props to a component viaset-state!at an internal, hidden key. Your render body is given the props that either came from the parent, or are in component-local state: whichever are newer. This value is increased every time the application renders.
36.3. Algorithms
The algorithms map in the application has two purposes:
-
To cope with the inevitable dependency that can happen when core systems like component and transaction processing need things from each other.
-
To allow users to override built-in algorithms.
All of the items that are intended to be overridden are documented in the fulcro-app function’s docstring
and in this book.
36.4. Auditing Fulcro’s Operation
Fulcro 2 had a built-in history mechanism that was primarily intended for a Support Viewer feature, but it was only for the state database, and did not track/correlate full-stack operations. Due to time constraints on development this feature was not included by default in Fulcro 3; however, the new application layout is much more extensible and easy to hook into, so implementing your own level of history tracking is not a lot of effort.
When adding any kind of auditing system to Fulcro you’re going to be interested in the following things:
- Watching the state atom
-
Optimistic actions have no middleware. So, your choices are to write your own macro for
defmutationthat wraps the realdefmutationso you can instrument it, but that won’t cover the cases where other code in your application modifies state. Tracking the state changes is best done with an atomadd-watch. - Wrapping transaction submission
-
Set the
:submit-transaction!option on your application so you can record when a load or mutation is actually submitted. Optimistic updates will follow very quickly thereafter. If you need absolute accuracy on which mutations does what, then the best option is to write a wrapper macro fordefmutationthat instruments theactionsection. - Tracking mutation remote results
-
Set the
:default-result-action!option on your app to your own instrumented version of the one Fulcro defines. - Tracking loads
-
Set the
:load-mutationoption (to a fully-qualified symbol). The default can be found indata_fetch.cljc. Simply copy the code of that one (which is written as a multimethod) and instrument it as needed.
An audit trail can then be a simple vector of nodes that is kept trimmed to some length, where each node indicates the type of thing that happened with a timestamp. Remember that at runtime the state atom is immutable data that has structural sharing, so saving a "copy" of it over time is not memory intensive.
[{:type :state-changed
:timestamp #inst "..."
:before { ... } ; ENTIRE app data value
:after { ... }}
{:type :remote-finished
:remote :remote
:mutation '(com.boo.bah/foo {:x 1})
:result {'com.boo.bah/foo {:v 42}}}
...]You can use transit (perhaps the transit-clj→str functions in Fulcro, which already know about tempids) to encode
for network transmission as long as you’re very careful not to put things in state (or mutation args) that cannot
be encoded.
Compression of this history for transmission could do all manner of things, including transforming all but the first state change of before/after pairs into diffs. A gzip step on a transit encoded string should also be able to remove quite a lot of redundancy.
36.5. Time Travel
When your application is written so that your view is a (f state-map) then
UI Time travel in Fulcro is trivial, assuming you follow some rules when writing the application and understand
the limitations:
-
Everything you want to track must be in the Fulcro db. Component-local state is not tracked, and is lost on component unmount/mount.
-
If you serialize/deserialize the state map, then that process must preserve all data that you care about.
-
Full-stack operation is a distributed system. Time travel in such a setting implies server interaction, the ability to "undo" operations in a shared environment, etc. True time travel is a very hard problem. We are only speaking about time travel with respect to the UI views of optimistic state, not time travel in a real full-stack application sense.
Time travel is therefore most useful for debugging and diagnosis of problems via an audit trail from a client.
36.5.1. Implementing a Support Viewer
A support viewer is mostly just a fully-functional Fulcro app that provides a UI to control a "dumbed down" version of your production app. One way to approach this is:
-
Create an HTML page that has two mount point divs. Use CSS to lay it out so support view can be in one of those divs covering one area, and the other will be your app.
-
Create a normal Fulcro app that is your support viewer. It will have access to loads from your support server that can list the "crash reports", can choose one, and can load it (as a NON-NORMALIZED OPAQUE VALUE). The crash report will be the audit trail described in the last section.
-
You may need to have several versions of your production app available. Your audit logs should indicate what version of the app they were running against. Loading the right js for your production app is up to you. Do not use the normal start for this app.
Each version of your app must have a way to access the Root of the UI. You do not want to run the application defined by that app. You only want the UI. Remember, you’re just viewing an audit log, so all you want is rendering to function. If you do dynamic code loading in the normal app, your support app will probably need to be a monolithic build.
The support viewer will allow you to select a "crash report" or other audit trail. It will load that data, and then create a new Fulcro app which:
-
Has no remotes.
-
Sets the submit-transaction and load mutation to no-ops (so that interactions with the view don’t do anything).
-
Uses the correct
Rootas the app root -
Mounts that root on the "app view" div in the HTML
At this point the support viewer can display/control navigation through the audit.
36.5.2. Forcing the render of a point in time.
There are two ways to make a Fulcro application display a specific point in time:
-
You can reset the state atom and schedule a render.
-
You can generate the UI props tree from state + query and render that yourself.
The former is trivial:
(defn reset-app-state!
"Time travel to the given app state. Can be called before mounting. Will refresh the UI to the new state if it was
already mounted. NOTE: Does nothing with respect to full-stack operations. Network operations will not be cancelled,
etc."
[app new-state]
(reset! (::app/state-atom app) new-state)
(app/schedule-render! app {:force-root? true}))The latter is also not difficult, and can even be done in a "live app" without hurting operation (i.e. the next Fulcro-initiated render will snap you back to the "present"). There are two tricky bits:
-
Dynamic queries are tracked in state. So, if you use them (or any feature of Fulcro that does) you must be careful to get the current query, which requires passing the state map to
get-query. -
If it is possible that the code has changed since the last render (i.e. you changed which version of the app you’re working with or hot code reloaded), in which case you want
shouldComponentUpdateto be ignored.
Note that the following algorithm is almost exactly keyframe render’s code, but uses a passed-in state for the render instead of the app’s current state:
(defn show-state!
"Show an alternate state of the app's view *without* affecting the app's state or operation. Can be used to see
some past version of state you've recorded. Fulcro's next proper render will snap you back to the present.
You MUST have already mounted the application before this function will work."
[app state-map]
(binding [comp/*blindly-render* true]
(let [{:com.fulcrologic.fulcro.application/keys [runtime-atom]} app
{:com.fulcrologic.fulcro.application/keys [root-factory root-class mount-node]} @runtime-atom
r! (or (ah/app-algorithm app :render-root!) js/ReactDOM.render)
query (comp/get-query root-class state-map)
data-tree (if query
(fdn/db->tree query state-map state-map)
state-map)]
(r! (root-factory data-tree) mount-node))))37. Demos
|
Note
|
This chapter has not been completely reviewed for Fulcro 3. A number of the demos used Bootstrap support, which was dropped from the library, and have not been ported to other CSS. |
This chapter includes some additional running demos with source that will give you insight on how to approach various problems. Remember that the server latency can be set using the controls in the upper-right corner in the live HTML version, so you can more easily watch state changes during server interactions.
37.1. Autocomplete
A fairly common desire in user interfaces is to try to help the user complete an input by querying the server or possible completions. Like many of the demos, the UI for this example is intentionally very bare-bones so that we can primarily concentrate on the data-flow that you’ll want to use to achieve the effect.
Typically you will want to trigger autocomplete on a time interval (e.g. using goog.functions/debounce) or after some number of characters have been entered into the field.
We’re going to implement it in the following way:
-
The autocomplete query will trigger when the input has at least 2 characters of input.
-
The server will be asked for 10 suggestions, and will update on a debounced interval.
-
The autocomplete suggestion list will clear if length goes below 2
-
The user must use the mouse to select the desired completion (we’re not handling keyboard events)
37.1.1. Basic Operation
The basic idea is as follows:
-
Make a component that has isolated state, so you can have more than one
-
Decide when to trigger the server query
-
Use load, but target it for a place that is not on the UI
-
Allows the UI to continue displaying old list while new load is in progress
-
Use a post-mutation to move the finished load into place
-
37.1.2. The Server Query
For our server we have a simple list of all of the airports in the world that have 3-letter codes. Our server just grabs 10 that match your search string:
(defn airport-search [s]
(->> airports
(filter (fn [i] (str/includes? (str/lower-case i) (str/lower-case s))))
(take 10)
vec))
(defquery-root :autocomplete/airports
(value [env {:keys [search]}] (airport-search search)))37.1.3. The UI and Post Mutation
We create a helper function so we don’t have to manually generate the ident for autocomplete wherever we need it:
(defn autocomplete-ident
"Returns the ident for an autocomplete control. Can be passed a map of props, or a raw ID."
[id-or-props]
(if (map? id-or-props)
[:autocomplete/id (:db/id id-or-props)]
[:autocomplete/id id-or-props]))We use Google Closure’s debounce to generate a function that will not bash the server too hard.
Load’s will run at most once every 500ms.
Notice that the server query itself is for airport suggestions, and we use the :target option to place the results in our autocomplete’s field:
(def get-suggestions
"A debounced function that will trigger a load of the server suggestions into a temporary locations and fire
a post mutation when that is complete to move them into the main UI view."
(letfn [(load-suggestions [component new-value id]
(df/load component :autocomplete/airports nil
{:params {:search new-value}
:post-mutation `populate-loaded-suggestions
:post-mutation-params {:id id}
:target (conj (autocomplete-ident id) :autocomplete/loaded-suggestions)}))]
(gf/debounce load-suggestions 500)))Notice when we trigger the load it goes into the auto-complete widget’s :autocomplete/loaded-suggestions field.
The UI renders the :autocomplete/suggestions.
We do this so we can continue filtering the list as they type independently of the load, but at the end of the load we need to update the suggestions.
We do this by running a post mutation (see the demo source).
The running demo (with source) is below:
(ns book.demos.autocomplete
(:require
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.data-fetch :as df]
[book.demos.airports :refer [airports]]
[clojure.string :as str]
[goog.functions :as gf]
[com.wsscode.pathom.connect :as pc]
))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn airport-search [search-string]
(->> airports
(filter (fn [airport] (str/includes? (str/lower-case airport) (str/lower-case search-string))))
(take 10)
vec))
(pc/defresolver list-resolver [env params]
{::pc/output [:autocomplete/airports]}
(let [search (get-in env [:ast :params :search])]
{:autocomplete/airports (airport-search search)}))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn autocomplete-ident
"Returns the ident for an autocomplete control. Can be passed a map of props, or a raw ID."
[id-or-props]
(if (map? id-or-props)
[:autocomplete/by-id (:db/id id-or-props)]
[:autocomplete/by-id id-or-props]))
(defsc CompletionList [this {:keys [values onValueSelect]}]
(dom/ul nil
(mapv (fn [v]
(dom/li {:key v}
(dom/a {:href "javascript:void(0)" :onClick #(onValueSelect v)} v))) values)))
(def ui-completion-list (comp/factory CompletionList))
(m/defmutation populate-loaded-suggestions
"Mutation: Autocomplete suggestions are loaded in a non-visible property to prevent flicker. This is
used as a post mutation to move them to the active UI field so they appear."
[{:keys [id]}]
(action [{:keys [state]}]
(let [autocomplete-path (autocomplete-ident id)
source-path (conj autocomplete-path :autocomplete/loaded-suggestions)
target-path (conj autocomplete-path :autocomplete/suggestions)]
(swap! state assoc-in target-path (get-in @state source-path)))))
(def get-suggestions
"A debounced function that will trigger a load of the server suggestions into a temporary locations and fire
a post mutation when that is complete to move them into the main UI view."
(letfn [(load-suggestions [comp new-value id]
(df/load! comp :autocomplete/airports nil
{:params {:search new-value}
:marker false
:post-mutation `populate-loaded-suggestions
:post-mutation-params {:id id}
:target (conj (autocomplete-ident id) :autocomplete/loaded-suggestions)}))]
(gf/debounce load-suggestions 500)))
(defsc Autocomplete [this {:keys [db/id autocomplete/suggestions autocomplete/value] :as props}]
{:query [:db/id ; the component's ID
:autocomplete/loaded-suggestions ; A place to do the loading, so we can prevent flicker in the UI
:autocomplete/suggestions ; the current completion suggestions
:autocomplete/value] ; the current user-entered value
:ident (fn [] (autocomplete-ident props))
:initial-state (fn [{:keys [id]}] {:db/id id :autocomplete/suggestions [] :autocomplete/value ""})}
(let [field-id (str "autocomplete-" id) ; for html label/input association
;; server gives us a few, and as the user types we need to filter it further.
filtered-suggestions (when (vector? suggestions)
(filter #(str/includes? (str/lower-case %) (str/lower-case value)) suggestions))
; We want to not show the list if they've chosen something valid
exact-match? (and (= 1 (count filtered-suggestions)) (= value (first filtered-suggestions)))
; When they select an item, we place it's value in the input
onSelect (fn [v] (m/set-string! this :autocomplete/value :value v))]
(dom/div {:style {:height "600px"}}
(dom/label {:htmlFor field-id} "Airport: ")
(dom/input {:id field-id
:value value
:onChange (fn [evt]
(let [new-value (.. evt -target -value)]
; we avoid even looking for help until they've typed a couple of letters
(if (>= (.-length new-value) 2)
(get-suggestions this new-value id)
; if they shrink the value too much, clear suggestions
(m/set-value! this :autocomplete/suggestions []))
; always update the input itself (controlled)
(m/set-string! this :autocomplete/value :value new-value)))})
; show the completion list when it exists and isn't just exactly what they've chosen
(when (and (vector? suggestions) (seq suggestions) (not exact-match?))
(ui-completion-list {:values filtered-suggestions :onValueSelect onSelect})))))
(def ui-autocomplete (comp/factory Autocomplete))
(defsc AutocompleteRoot [this {:keys [airport-input]}]
{:initial-state (fn [p] {:airport-input (comp/get-initial-state Autocomplete {:id :airports})})
:query [{:airport-input (comp/get-query Autocomplete)}]}
(dom/div
(dom/h4 "Airport Autocomplete")
(ui-autocomplete airport-input)))37.2. Cascading Dropdowns
A common UI desire is to have dropdowns that cascade. I.e. a dropdown populates in response to a selection in an earlier dropdown, like Make/Model for cars. This can be done quite easily.
The basic implementation is as follows:
-
Define dropdowns that can display the items
-
Don’t initialize the extra ones with items
-
When the first one is given a selection, load the next one
A couple of simple implementation details are needed:
-
We’re using bootstrap dropdowns, and we need to know where they normalize their data. Looking at the data inspector for the card makes this easy to see. For example, we can see that items are stored in the
:bootstrap.dropdown/idtable, in the:fulcro.ui.bootstrap3/itemscolumn. -
The IDs of the dropdowns (which we generate)
On the server, we define the query handler as follows (remember you can affect the server latency with the server controls to watch things happen):
(defquery-root :models
(value [env {:keys [make]}]
(case make
:ford [(bs/dropdown-item :escort "Escort")
(bs/dropdown-item :F-150 "F-150")]
:honda [(bs/dropdown-item :civic "Civic")
(bs/dropdown-item :accort "Accord")])))and we define a mutation for showing a "Loading…" item in the dropdown that is loading as:
(defmutation show-list-loading
"Change the items of the dropdown with the given ID to a single item that indicates Loading..."
[{:keys [id]}]
(action [{:keys [state]}]
(swap! state assoc-in
[:bootstrap.dropdown/id id :fulcro.ui.bootstrap3/items]
[(assoc (bs/dropdown-item :loading "Loading...") :fulcro.ui.bootstrap3/disabled? true)])))The main action is in the onSelect of the first dropdown, which just issues the transact to set the loading visualization, followed by the remote load.
(ns book.demos.cascading-dropdowns
(:require
[com.fulcrologic.semantic-ui.modules.dropdown.ui-dropdown :as dropdown]
[com.fulcrologic.fulcro.data-fetch :as df]
[com.fulcrologic.fulcro.mutations :refer [defmutation]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[book.elements :as ele]
[taoensso.timbre :as log]
[com.wsscode.pathom.connect :as pc]
[com.fulcrologic.fulcro.mutations :as m]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Server
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn option [text]
{:text text :value text})
(pc/defresolver model-resolver [env _]
{::pc/output [::models]}
(let [{:car/keys [make]} (-> env :ast :params)]
{::models
(case make
"Ford" [(option "Escort") (option "F-150")]
"Honda" [(option "Civic") (option "Accord")]
[])}))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Client
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn render-example
"Wrap an example in an iframe so we can load external CSS without affecting the containing page."
[width height & children]
(ele/ui-iframe {:frameBorder 0 :height height :width width}
(apply dom/div {:key "example-frame-key"}
(dom/style ".boxed {border: 1px solid black}")
(dom/link {:rel "stylesheet" :href "https://cdnjs.cloudflare.com/ajax/libs/semantic-ui/2.4.1/semantic.min.css"})
children)))
(defsc Car [this {:car/keys [id make model]
:ui/keys [car-model-options] :as props}]
{:query [:car/id :car/make :car/model
:ui/car-model-options
;; Link queries goes to root of database. Here we're accessing the named load markers
[df/marker-table '_]]
:initial-state {:car/id 1}
:ident :car/id}
(let [models-loading? (df/loading? (get props [df/marker-table ::dropdown-loading]))]
(dom/div :.ui.container.form
(dom/h4 "Car")
(dom/div :.ui.field
(dom/label {:htmlFor "carmake"} "Make")
(dropdown/ui-dropdown
{:value make
:name "carmake"
:button true
:placeholder "Select"
:options [{:text "Ford" :value "Ford"}
{:text "Honda" :value "Honda"}]
:onChange (fn [_ item] (let [v (.-value item)]
(m/set-string! this :car/make :value v)
(m/set-string! this :car/model :value "")
(df/load this ::models nil {; custom marker so we can show that the dropdown is busy
:marker ::dropdown-loading
; A server parameter on the query
:params {:car/make v}
:target [:car/id id :ui/car-model-options]})))}))
(dom/div :.ui.field
(dom/label "Model")
(dropdown/ui-dropdown
{:onSelect (fn [item] (log/info item))
:button true
:placeholder "Select"
:options (or car-model-options [{:text "Select Make" :value ""}])
:value (or model "")
:onChange (fn [_ item]
(m/set-string! this :car/model :value (.-value item)))
:loading models-loading?})))))
(def ui-car (comp/factory Car {:keyfn :car/id}))
(defsc Root [this {:keys [form]}]
{:initial-state {:form {}}
:query [{:form (comp/get-query Car)}]}
(render-example "400px" "400px"
(ui-car form)))37.3. Loading due to a UI Event
Tabbed interfaces typically use a UI Router (which can be further integrated into HTML5 routing as a routing tree). See this YouTube video for more details.
This example not only shows the basic construction of an interface that allows content (and query) to be switched, it also demonstrates how one goes about triggering loads of data that some screen might need.
If you look at the source for the root component you’ll see two buttons with transactions on their click handlers.
(defsc Root [this {:keys [current-tab] :as props}]
; Construction MUST compose to root, just like the query. The resulting tree will automatically be normalized into the
; app state graph database.
{:initial-state (fn [params] {:ui/react-key "initial" :current-tab (comp/get-initial-state UITabs nil)})
:query [{:current-tab (comp/get-query UITabs)}]}
(dom/div
; The selection of tabs can be rendered in a child, but the transact! must be done from the parent (to
; ensure proper re-render of the tab body). See comp/computed for passing callbacks.
(dom/button {:onClick #(comp/transact! this `[(choose-tab {:tab :main})])} "Main")
(dom/button {:onClick #(comp/transact! this `[(choose-tab {:tab :settings})
; extra mutation: sample of what you would do to lazy load the tab content
(lazy-load-tab {:tab :settings})])} "Settings")
(ui-tabs current-tab)))The first is simple enough: run a mutation that chooses which tab to show. The routing library includes a helper function for building that, so the mutation just looks like this:
(m/defmutation choose-tab [{:keys [tab]}]
(action [{:keys [state]}] (swap! state r/set-route* :ui-router [tab :tab])))The transaction to go to the settings tab is more interesting. It switches tabs but also runs another mutation to load data needed for that screen. The intention is to just load it if it is missing. That mutation looks like this:
(defn missing-tab? [state tab] (empty? (-> @state :settings :tab :settings)))
(m/defmutation lazy-load-tab [{:keys [tab]}]
(action [{:keys [app state] :as env}]
(when (missing-tab? state tab)
(df/load! app :all-settings SomeSetting
{:target [:settings :tab :settings]
:refresh [:settings]}))))Fairly standard fare at this point: Look at the database to see if it has what you want, and if not trigger a load.
(ns book.demos.loading-in-response-to-UI-routing
(:require
[com.fulcrologic.fulcro.routing.legacy-ui-routers :as r]
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.data-fetch :as df]
[com.wsscode.pathom.connect :as pc]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(pc/defresolver all-settings-resolver [env input]
{::pc/output [{::all-settings [:id :value]}]}
{::all-settings [{:id 1 :value "Gorgon"}
{:id 2 :value "Thraser"}
{:id 3 :value "Under"}]})
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defsc SomeSetting [this {:keys [id value]}]
{:query [:ui/fetch-state :id :value]
:ident [:setting/by-id :id]}
(dom/p nil "Setting " id " from server has value: " value))
(def ui-setting (comp/factory SomeSetting {:keyfn :id}))
(defsc SettingsTab [this {:keys [settings-content settings]}]
{:initial-state {:kind :settings
:settings-content "Settings Tab"
:settings []}
; This query uses a "link"...a special ident with '_ as the ID. This indicates the item is at the database
; root, not inside of the "settings" database object. This is not needed as a matter of course...it is only used
; for convenience (since it is trivial to load something into the root of the database)
:query [:kind :settings-content {:settings (comp/get-query SomeSetting)}]}
(dom/div nil
settings-content
(if (seq settings)
(mapv ui-setting settings)
(dom/div "No settings."))))
(defsc MainTab [this {:keys [main-content]}]
{:initial-state {:kind :main :main-content "Main Tab"}
:query [:kind :main-content]}
(dom/div nil main-content))
(r/defsc-router UITabs [this props]
{:router-id :ui-router
:ident (fn [] [(:kind props) :tab])
:default-route MainTab
:router-targets {:main MainTab
:settings SettingsTab}})
(def ui-tabs (comp/factory UITabs))
(m/defmutation choose-tab [{:keys [tab]}]
(action [{:keys [state]}] (swap! state r/set-route* :ui-router [tab :tab])))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; LAZY LOADING TAB CONTENT
;; This is the shape of what to do. We define a method that can examine the
;; state to decide if we want to trigger a load. Then we define a mutation
;; that the UI can call during transact (see the transact! call for Settings on Root in ui.cljs).
;; The mutation itself (app/lazy-load-tab) below uses a data-fetch helper function to
;; set :remote to the right thing, and can then give one or more load-data-action's to
;; indicate what should actually be retrieved. The server implementation is trivial in
;; this case. See api.clj.
;; When to consider the data missing? Check the state and find out.
(defn missing-tab? [state tab]
(let [settings (-> @state :settings :tab :settings)]
(or (not (vector? settings))
(and (vector? settings) (empty? settings)))))
(m/defmutation lazy-load-tab [{:keys [tab]}]
(action [{:keys [app state] :as env}]
; Specify what you want to load as one or more calls to load-action (each call adds an item to load):
(when (missing-tab? state tab)
(df/load! app ::all-settings SomeSetting {:target [:settings :tab :settings]}))))
(defsc Root [this {:keys [current-tab] :as props}]
; Construction MUST compose to root, just like the query. The resulting tree will automatically be normalized into the
; app state graph database.
{:initial-state (fn [params] {:current-tab (comp/get-initial-state UITabs nil)})
:query [{:current-tab (comp/get-query UITabs)}]}
(dom/div
; The selection of tabs can be rendered in a child, but the transact! must be done from the parent (to
; ensure proper re-render of the tab body). See comp/computed for passing callbacks.
(dom/button {:onClick #(comp/transact! this [(choose-tab {:tab :main})])} "Main")
(dom/button {:onClick #(comp/transact! this [(choose-tab {:tab :settings})
; extra mutation: sample of what you would do to lazy load the tab content
(lazy-load-tab {:tab :settings})])} "Settings")
(ui-tabs current-tab)))37.4. Paginating Large Lists
This demo is showing a (dynamically generated) list of items. The server can generate any number of them, so you can page ahead as many times as you like. Each page is dynamically loaded if and only if the browser does not already have it. The demo also ensures you cannot run out of browser memory by removing items and pages that are more than 4 steps away from your current position. You can demonstrate this by moving ahead by more than 4 pages, then page back 5. You should see a reload of that early page when you go back to it.
The UI of this example is a great example of how a complex application behavior remains very simple at the UI layer with Fulcro.
We represent the list items as you might expect:
(defsc ListItem [this {:keys [item/id]}]
{:query [:item/id :ui/fetch-state]
:ident [:items/id :item/id]}
(dom/li (str "Item " id)))We then generate a component to represent a page of them. This allows us to associate the items on a page with a particular component, which makes tracking the page number and items on that page much simpler:
(defsc ListPage [this {:keys [page/number page/items] :as props}]
{:initial-state {:page/number 1 :page/items []}
:query [:page/number {:page/items (comp/get-query ListItem)}
[df/marker-table :page]]
:ident [:page/by-number :page/number]}
(let [status (get props [df/marker-table :page])]
(dom/div
(dom/p "Page number " number)
(if (df/loading? status)
(dom/div "Loading...")
(dom/ul (mapv ui-list-item items))))))Next we build a component named LargeList to control which page we’re on.
This component does nothing more than show the current page, and transact mutations that ask for the specific page.
Not that we could easily add a control to jump to any page, since the mutation itself is goto-page.
(defsc LargeList [this {:keys [list/current-page]}]
{:initial-state (fn [params] {:list/current-page (comp/get-initial-state ListPage {})})
:query [{:list/current-page (comp/get-query ListPage)}]
:ident (fn [] [:list/id 1])}
(let [{:keys [page/number]} current-page]
(dom/div
(dom/button {:disabled (= 1 number)
:onClick #(comp/transact! this `[(goto-page {:page-number ~(dec number)})])} "Prior Page")
(dom/button {:onClick #(comp/transact! this `[(goto-page {:page-number ~(inc number)})])}
"Next Page")
(ui-list-page current-page))))37.4.1. The goto-page Mutation
So you can infer that all of the complexity of this application is hidden behind a single mutation: goto-page.
This mutation is a complete abstraction to the UI, and the UI designer would need to very little about it.
We’ve decided that this mutation will:
-
Ensure the given page exists in app state (with its page number)
-
Check to see if the page has items
-
If not: it will trigger a server-side query for those items
-
-
Update the `LargeList’s current page to point to the correct page
-
Garbage collect pages/items in the app database that are 5 or more pages away from the current position.
The mutation itself looks like this:
(m/defmutation goto-page [{:keys [page-number]}]
(action [{:keys [state] :as env}]
(load-if-missing! env page-number)
(swap! state (fn [s]
(-> s
(init-page page-number)
(set-current-page page-number)
(gc-distant-pages page-number))))))Let’s break this down.
The Action
The load-if-missing function is composed of the following bits:
(defn page-exists? [state-map page-number]
(let [page-items (get-in state-map [:page/by-number page-number :page/items])]
(boolean (seq page-items))))
(defn load-if-missing! [{:keys [app state] :as env} page-number]
(when-not (page-exists? @state page-number)
(let [start (inc (* 10 (dec page-number)))
end (+ start 9)]
(df/load! app :paginate/items ListItem {:params {:start start :end end}
:target [:page/by-number page-number :page/items]}))))and you can see that it just detects if the page is missing its items. If the items are missing, it loads them.
37.4.2. The Server-Side Code
The server in this example is trivial. It is just a query that generates items on the fly:
(defmethod api/server-read :paginate/items [env k {:keys [start end]}]
(when (> 1000 (- end start)) ; ensure the server doesn't die if the client does something like use NaN for end
{:value (vec (for [id (range start end)]
{:item/id id}))}))(ns book.demos.paginating-large-lists-from-server
(:require
[com.fulcrologic.fulcro.mutations :as m]
[com.fulcrologic.fulcro.components :as comp :refer [defsc]]
[com.fulcrologic.fulcro.dom :as dom]
[com.fulcrologic.fulcro.data-fetch :as df]
[com.fulcrologic.fulcro.components :as comp]
[com.wsscode.pathom.connect :as pc]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(pc/defresolver infinite-pages [env input]
{::pc/output [{:paginate/items [:item/id]}]}
(let [params (-> env :ast :params)
{:keys [start end]} params]
{:paginate/items (mapv (fn [id] {:item/id id}) (range start end))}))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn page-exists? [state-map page-number]
(let [page-items (get-in state-map [:page/by-number page-number :page/items])]
(boolean (seq page-items))))
(defn init-page
"An idempotent init function that just ensures enough of a page exists to make the UI work.
Doesn't affect the items."
[state-map page-number]
(assoc-in state-map [:page/by-number page-number :page/number] page-number))
(defn set-current-page
"Point the current list's current page to the correct page entity in the db (via ident)."
[state-map page-number]
(assoc-in state-map [:list/by-id 1 :list/current-page] [:page/by-number page-number]))
(defn clear-item
"Removes the given item from the item table."
[state-map item-id] (update state-map :items/by-id dissoc item-id))
(defn clear-page
"Clear the given page (and associated items) from the app database."
[state-map page-number]
(let [page (get-in state-map [:page/by-number page-number])
item-idents (:page/items page)
item-ids (mapv second item-idents)]
(as-> state-map s
(update s :page/by-number dissoc page-number)
(reduce (fn [acc id] (update acc :items/by-id dissoc id)) s item-ids))))
(defn gc-distant-pages
"Clears loaded items from pages 5 or more steps away from the given page number."
[state-map page-number]
(reduce (fn [s n]
(if (< 4 (Math/abs (- page-number n)))
(clear-page s n)
s)) state-map (keys (:page/by-number state-map))))
(declare ListItem)
(defn load-if-missing [{:keys [app state] :as env} page-number]
(when-not (page-exists? @state page-number)
(let [start (inc (* 10 (dec page-number)))
end (+ start 9)]
(df/load! app :paginate/items ListItem {:params {:start start :end end}
:marker :page
:target [:page/by-number page-number :page/items]}))))
(m/defmutation goto-page [{:keys [page-number]}]
(action [{:keys [state] :as env}]
(load-if-missing env page-number)
(swap! state (fn [s]
(-> s
(init-page page-number)
(set-current-page page-number)
(gc-distant-pages page-number))))))
(defsc ListItem [this {:keys [item/id]}]
{:query [:item/id :ui/fetch-state]
:ident [:items/by-id :item/id]}
(dom/li (str "Item " id)))
(def ui-list-item (comp/factory ListItem {:keyfn :item/id}))
(defsc ListPage [this {:keys [page/number page/items] :as props}]
{:initial-state {:page/number 1 :page/items []}
:query [:page/number {:page/items (comp/get-query ListItem)}
[df/marker-table :page]]
:ident [:page/by-number :page/number]}
(let [status (get props [df/marker-table :page])]
(dom/div
(dom/p "Page number " number)
(if (df/loading? status)
(dom/div "Loading...")
(dom/ul (mapv ui-list-item items))))))
(def ui-list-page (comp/factory ListPage {:keyfn :page/number}))
(defsc LargeList [this {:keys [list/current-page]}]
{:initial-state (fn [params] {:list/current-page (comp/get-initial-state ListPage {})})
:query [{:list/current-page (comp/get-query ListPage)}]
:ident (fn [] [:list/by-id 1])}
(let [{:keys [page/number]} current-page]
(dom/div
(dom/button {:disabled (= 1 number) :onClick #(comp/transact! this [(goto-page {:page-number (dec number)})])} "Prior Page")
(dom/button {:onClick #(comp/transact! this [(goto-page {:page-number (inc number)})])} "Next Page")
(ui-list-page current-page))))
(def ui-list (comp/factory LargeList))
(defsc Root [this {:keys [pagination/list]}]
{:initial-state (fn [params] {:pagination/list (comp/get-initial-state LargeList {})})
:query [{:pagination/list (comp/get-query LargeList)}]}
(dom/div (ui-list list)))
(defn initialize
"To be used as started-callback. Load the first page."
[{:keys [app]}]
(comp/transact! app [(goto-page {:page-number 1})]))38. React Native
Fulcro works quite well with React Native, and is a great way to build mobile apps. At the present time we recommend using Expo, and there is a small starter library you should add that will help you get an app up and running.

See the README for current details on that library’s support.
In general, there are just a few steps to getting a React Native app going in Fulcro:
-
Make sure your
package.jsonhas the correct extra dependencies -
Modify the rendering (pluggable) of Fulcro to initialized React Native
-
Wrap the UI components of native so they work with Fulcro
A small functioning template for a native app can be found at https://github.com/fulcrologic/fulcro-native-template
38.1. Sharing Source
You will often have projects that have a server, web interface, and one or more mobile app(s). One of the great things about using Clojure(script) is that all of this source can be leveraged across all of these platforms. One of the main limitations is that the mobile platform does not have a DOM, and require chains can easily "leak" DOM-related components into your mobile app, leading to compile or runtime failures.
There are two development-time tasks that typically evolve as a result of this complication:
-
Figuring out where you the extra dependency leaked into your source code from.
-
Refactor code to eliminate the accidental inclusions.
38.1.1. Finding Accidental Inclusions
If you’re using shadow-cljs the web interface has a tool that will tell you exactly where a particular artifact came
from. Go to the web interface, and click on the menu item Builds → name-of-your-build (not the checkbox). This will
take you to a detail screen for that build. Scroll down to the bottom and find this control:
External js libraries are the typical source of problems, and they are "shimmed" by shadow-cljs. Thus their names
look like shadow.js.shim.module$name-of-npm-library. Choose the problem-library from that dropdown (typing s to jump
to that section of the list will speed things along) and it will show you the require chain that led to the
undesirable inclusion.
38.1.2. Working Around Inclusions
When working with a project that has both web and native UIs you will often have logic code that has the same abstract meaning, but whose implementation really does need access to a web or native API. One approach is to simply have some global that knows which runtime is being used. This is fine if there are no requires involved, but there is no runtime "require" in the js environment, so it won’t work if you’re trying to do alternate requires for the two platforms.
One solution is to use protocols to front your desired logic, and them implement those protocols in alternate namespaces. The primary trick is getting the correct implementation to be used for a given platform. Here is a pattern you can follow to achieve this:
- Create a Runtime Environment Variable
-
(ns app.targets.runtime) (defonce runtime (atom {})) - Create a namespace for each target type
-
These serve as a "collection point" for the various APIs you decide need target-specific runtimes. These requires will follow the platform-specific chains. You call each target’s
initto install the platform-specific runtime (an implementation of the protocol).(ns app.targets.browser (:require [api.auth-browser :as auth] [api.routing-browser :as routing])) (auth/init) (routing/init)(ns app.targets.native (:require [api.auth-native :as auth] [api.routing-native :as routing])) (auth/init) (routing/init) - Create a Generic Abstraction for the API
-
The trick here is that you define functions that will use the global runtime to look up an API-specific runtime instance that implements the protocol. This instance will either be the browser or native API depending on which initialization gets called.
(ns app.auth (:require [app.targets.runtime :refer [runtime]])) (defprotocol Auth (-save-session-key! [_ k] "target independent interface. Use save-session-key! instead.") (-get-session-key [_] "target independent interface. Use get-session-key instead.")) (defn save-session-key! "Sets a current session key in locally-accessible storage" [k] (some-> @runtime (::impl) (-set-session-key! k))) (defn get-session-key "Returns the session key from locally-accessible storage" [] (some-> @runtime (::impl) (-session-key-local-storage))) - Create Each Platform’s Implementation
-
(ns app.auth-browser (:require [app.auth :as auth] [com.fulcrologic.fulcro.algorithms.transit :as fcutil])) (defn set-item! "Set `key' in browser's localStorage to `val`." [key val] (.setItem (.-localStorage js/window) (str key) (fcutil/transit-clj->str val))) (defn get-item "Returns value of `key' from browser's localStorage." [key] (if-let [result (.getItem (.-localStorage js/window) (str key))] (fcutil/transit-str->clj result))) (defn init "Installs the browser-specific implementations of auth functions" [] (swap! runtime assoc ::auth/impl (reify auth/Auth (-save-session-key! [_ k] (set-item! "session-key" k)) (-get-session-key [_] (get-item "session-key")))))(ns app.auth-native (:require ["some-native-store" :as store] [com.fulcrologic.fulcro.algorithms.transit :as fcutil])) (defn init "Installs the browser-specific implementations of auth functions" [] (swap! runtime assoc ::auth/impl (reify auth/Auth (-save-session-key! [_ k] (native-save! "session-key" k)) (-get-session-key [_] (native-get "session-key"))))) - Require the correct target in the entry point of your target
-
(ns app.browser.main (:require app.targets.browser)) ...(ns app.native.main (:require app.targets.native)) ... - Use the generalized API throughout the rest of your code
-
(ns any-old-ns (:require [app.auth :as auth])) ... (auth/save-session-key! "abc123")which will resolve the current runtime implementation, and then call the correct method on the underlying protocol.
Your final source tree will end up with three files for each API that has target-specific needs:
api.cljs - The protocol, the runtime passthrough delegation functions, and any platform-independent functions you care to include.
api-browser.cljs - An init function to reify the browser implementation, and browser-specific requires.
api-native.cljs - The native version of the same.and then three runtime target files:
runtime.cljs - An atom to hold the implementation(s), keyed by protocol namespace (e.g. ::auth/impl).
native.cljs - A namespace that requires all of the `*-native` namespaces, and calls `init` on each.
broser.cljs - A namespace that requires all of the `*-browser` namespaces, and calls `init` on each.and finally your two top-level entry points, each of which will require the correct runtime (native or browser) to include it in the build.
39. Fulcro and GraphQL
GraphQL is rapidly becoming the standard for writing graph-based servers. As a result there are many existing ways to deploy such an API, and many businesses have decided that their back-end will simply use the standard. There are BaaS (back-end as a service) providers that also let you quickly define and deploy a GraphQL API.
All of this makes GraphQL an attractive server-side solution for Fulcro.
Luckily, Pathom has all of the tools necessary to make this integration simple and easy!
You can see some of it in action in one of the Fulcro video series, and read about configuring it in the Pathom Documentation.
The simplest integration is to simply use Pathom’s GraphQL remote:
(ns app
(:require
...
[com.wsscode.pathom.fulcro.network :as pfn]))
(def client (fulcro/make-fulcro-client
{:networking {:remote (pfn/graphql-network
{::pfn/url (str "https://api.github.com/graphql?access_token=" token)})}})The more powerful and extensible method allows you to combine GraphQL access with Pathom Connect. This gives you very powerful features, including many useful ones that GraphQL doesn’t support natively!
40. Appendix: Fulcro Errors and Warnings, Explained
40.1. Fulcro warning and error logs
Explanations of the Fulcro warnings errors that you might see in the browser Console.
40.1.1. Errors
application
- Cannot compute shared
-
Your custom
:shared-fnon the application likely threw an exception. - Render listener failed.
-
A custom-installed render listener threw an exception. Fulcro uses the render listener for certain hooks behaviors as well, and it is possible this could happen due to a bug in those listeners.
- Mount cannot find DOM node
nodeto mount(comp/class→registry-key root) -
Could not find a DOM element with the given ID to mount to. Perhaps your HTML is wrong?
browser_edn_store
- Local storage denied.
edn -
The browser denied storing more in local storage. Perhaps it is full?
- Cannot list items in storage.
-
The browser denied looking in local storage. Browser Permissions?
- Load failed.
-
The browser’s local storage refused the load. Permissions?
- Delete failed.
-
The browser’s local storage refused the load. Permissions?
- Cannot update edn.
-
The browser’s local storage refused the load. Permissions?
components
- Cannot create proper fulcro component, as app isn’t bound. This happens when something renders a Fulcro component outside of Fulcro’s render context. See
with-parent-context. -
This can happen for example when you want a third-party component to render a Fulcro component. Wrap it with
with-parent-contextto preserve the important data.
It also happens more rarely that this error appears in production code when you try to render a lazy-seq and then replace it with another one. See: https://github.com/fulcrologic/fulcro/discussions/477 In this case you should force your sequences with mapv or a vec around your lazy-seq.
- Query ID received no class (if you see this warning, it probably means metadata was lost on your query)
-
Dynamic queries use metadata on the query itself to track which part of the query is normalized by which component. If you morph the query in any way and forget to maintain this metadata, then certain parts of Fulcro will fail. This could also mean you somehow used a hand-built query (not
defscornc) to build a raw EQL query that has no such metadata, and then somehow used it in the context of rendering or normalization. - A Fulcro component was rendered outside of a parent context. This probably means you are using a library that has you pass rendering code to it as a lambda. Use
with-parent-contextto fix this. -
Standard Fulcro rendering requires dynamic vars to be set, which are unset when you try to render components from some kind of async context (e.g. raw js container). You may want to consider using the raw support (via hooks) to make this kind of case easier to code.
- Props middleware seems to have corrupted props for
(component-name class) -
Check what the props produced by the middleware are. They must not be nil.
- Props passed to
(component-name class)are of the type<type>instead of a map. Perhaps you meant tomapthe component over the props? -
Props must be a map but isn’t. Look at the code in the parent component and its props. Perhaps the value is actually a vector of maps (such as "people") and you should map this component over it? Or it is just the ident of the component, which happens sometimes when the data graph is not connected properly. Tip: Log the value of the props in the body of the target component to see what it is actually getting.
- Query normalization failed. Perhaps you tried to set a query with a syntax error?
-
Dynamic queries use a normalization mechanism to remember your new query in the actual state database. That normalization process must parse through your newly-suggested query and do this, but if there is a syntax error in the EQL it can fail. Check your query.
- Set query failed. There was no query ID. Use a class or factory for the second argument.
-
Every dynamic query must have a query ID (usually the fully-qualified class name as a keyword). This indicates that Fulcro was unable to determine which component/id you were trying to set the query of.
- Unable to set query. Invalid arguments.
-
Most likely you forgot to pass a map containing at least
:query. - Cannot re-render a non-component
-
The argument passed to
refresh-component!should be a Fulcro component but is not.
data_targeting
- Replacement path must be a vector. You passed:
data-path -
The
targetpassed toreplace-atmust be a vector (path) in the normalized database of the to-many list of idents. - Path for replacement must be a vector
-
When using
replace-atto target a to-many prop then the value of this prop should be a vector but it is not. Example:[:person/id "123" :person/kids 0]to replace the 0th element in the vector under:person/kids. - Path for replacement must end in a vector index
-
When using
replace-atto target a to-many prop (which is a vector), then the last element of the path should be a number index into the vector. Example:[:person/id "123" :person/kids 0]. - Target vector for replacement does not have an item at index
index -
You have used
replace-atto target an element under a to-many prop (which is a vector) but there is no such element. Perhaps the target vector is shorter than you expected. Check your data.
durable_mutations
- Save failed. Running transaction now, non-durably.
-
Durable mutations was not able to save the mutation into a durable storage, and therefore had to try sending the mutation without any ability to recover. The mutation will succeed if the network is OK, but cannot be retried if it isn’t.
- The transaction that submitted this mutation did not assign it a persistent store ID. This probably means you did not submit it as a durable mutation.
-
There was an inconsistent submission of a mutation. You wanted it to be durable, but didn’t say how.
- INTERNAL ERROR: TXN ID MISSING!
-
Indicates an unexpected bug in Fulcro’s code.
- Failed to update durable mutation!
-
Durable mutations tracks retry attempts and backoff. This indicates that for some reason it could not write these updates to the durable store. This could result in the mutation being retried forever, and not backing off correctly. Fix the durable store.
dynamic_routing
- Component must have an ident for routing to work properly:
(comp/component-name class) -
If you want to use a component as a router target, it needs to have an ident.
- Cannot evaluate route change. Assuming ok. Exception message:
(ex-message e) -
Dynamic routing asks the current target(s) if it is ok to change routes. One of your components in the old route probably threw an exception, which is considered an error, not a request to deny the route. The routing request will proceed, but you should fix the bug in your
:allow-route-change?or:will-leavehandlers. - <route-immediate|deferred> was invoked with the ident
identwhich doesn’t seem to match the ident of the wrapping component (classtarget-class, ident …) -
The ident that you pass to
route-immediateorroute-deferredmust match the ident of the wrapping component, where the:will-enteris defined. Check your code. - apply-route* was called without a proper :router argument.
-
You used the
apply-route*helper with invalid arguments. - apply-route* for router
router-classwas given a target that did not have a component. Did you remember to call route-deferred or route-immediate? -
The
targetpassed to theapply-routemutation needs to metadata containing the key:component, containing the class of the target. - There is a router in state that is missing an ID. This indicates that you forgot to compose it into your initial state! It will fail to operate properly.
-
Routers require that their initial state is composed to the parent component (i.e. it defines
:initial-statein lambda form with(comp/get-initial-state <the router>)or in the template form) and so on all the way up to the root. If the parent of the router is loaded dynamically (i.e. it is not in the client DB during the initial render) then you must make sure to include the router’s data in it manually, typically with`:pre-merge. See (Router) Initial State. target-readyshould route totargetbut there is no data in the DB for the ident. Perhaps you supplied a wrong ident?-
Target components are expected to have non-nil state in the client DB. Check whether the ident you provided is correct and use Fulcro Inspect to see what data is in the DB for the ident.
target-ready!was called but there was no router waiting for the target listed:targetThis could mean you sent one ident, and indicated ready on another.-
Make sure that the ident you provided to
route-deferredmatches exactly the one provided totarget-ready[!]. You can also check the routers in the DB and see their pending routes under::dr/id ::dr/pending-route :target. - will-enter for router target
(comp/component-name target)did not return a valid ident. Instead it returned:target-ident -
The ident provided to
route-immediate/route-deferredis not a valid ident, i.e. a vector of two elements where the first one is a keyword and the second one is not nil. - will-enter for router target
(comp/component-name target)did not wrap the ident in route-immediate or route-deferred. -
:will-entermust return either(route-immediate …)or(route-deferred …)and not just an ident. - Could not find route targets for new-route
new-route -
The
new-routeprovided tochange-route-relative!does not point to router target(s) relative to the given starting class. Look at your tree of components starting at that class and look at the route segments of the targets under it. - You are routing to a router
router-idwhose state was not composed into the app from root. Please check your :initial-state. -
Routers require that their initial state is composed to the parent component (i.e. it defines
:initial-statein lambda form with(comp/get-initial-state <the router>)or in the template form) and so on all the way up to the root. If the parent of the router is loaded dynamically (i.e. it is not in the client DB during the initial render) then you must make sure to include the router’s data in it manually, typically with`:pre-merge. See (Router) Initial State. Also make sure that the application has been initialized before you tried to route - see Setting the Route Early. - Route target
(comp/component-name t)of router(comp/component-name router-instance)does not declare a valid :route-segment. Route segments must be non-empty vector that contain only strings and keywords -
Check the
:route-segmentof the component and see Routing Targets.
file_upload
- Unable to associate a file with a mutation
file -
The server received a file in the multipart submission that did not indicate which mutation it was supposed to go with. The file upload support uses low-level multipart forms to attach uploads to the EQL request. Something went wrong when trying to do that. No mutation will see the file.
- Unable to attach uploads to the transaction.
-
An exception was thrown while trying to decode file upload(s) on the server. This probably means the client sent a corrupted file upload request. Check your client and server middleware for encode/decode problems.
- Incoming transaction with uploads had no files attached.
-
The client sent a transaction to the server that indicated there would be attached files; however, when the server middleware tried to find files there were none attached. Check your client and server middleware to make sure things are properly configured.
- Exception while converting mutation with file uploads.
-
The client file upload middleware caught an exception while trying to encode file uploads with a transaction. This could mean that your mutation failed to properly attach js File objects.
form_state
- FORM NOT NORMALIZED:
entity-ident -
The value of client DB →
<entity-ident>→::fs/configshould be an ident. If it is not then you have done something wrong. See the sections under Form Configuration. You should likely have usedfs/add-form-config[*].
http_remote
- Attempt to request alternate response from HTTP remote from multiple items in a single transaction. This could mean more than one transaction got combined into a single request.
-
The HTTP remote has to determine what MIME type to use for the response of a request. Normally this is just transit over JSON; however, customizations to your application (e.g. including ::http/response-type on the AST params) are allowed to change this type. If the internals also COMBINE more than one transaction, and they each want a different MIME type, then the HTTP remote has no way of asking for both on a single request.
- Unable to extract response from XhrIO Object
e -
A low-level failure happened when trying to read the underlying XhrIO object. Probably means something bad happened at a very low network layer that is beyond your control.
- Client response middleware threw an exception.
e. Defaulting to raw response. -
Middleware you installed threw an exception, so the response was NOT run through your middleware, but was instead passed on to the next layer as-is. This probably means other things failed as well. Fix your middleware.
- Client middleware threw an exception
middleware-exception -
Basically the same as prior.
- Result handler for remote
urlfailed with an exception. -
The
result-handlerfor the network request threw an exception. The result handler is a function created by the internals of Fulcro to merge the response back into the database, and/or invoke the result-action of a mutation. Check that your response seems correct for the request, and that your middleware hasn’t corrupted the data in some way. - Update handler for remote
urlfailed with an exception. -
The
update-handlerfor the network request threw an exception. The update handler is a function created by the internals of Fulcro to give progress updates. - `Remote Error
-
This error is a catch-all. Check the logs for other error messages that preceeded it for details.
- Error handler for remote
urlfailed with an exception. -
An attempt to deliver the result of an error failed. In other words there was a remote error, and then the delivery of that error to the application layer of Fulcro also threw an exception. This is not the source of your problem, but instead an indication that the kind of error that happened was unforseen in the original design or some customization of the result handling at the application layer is incorrect.
- Send aborted due to middleware failure
-
Your request middleware crashed while processing a send request. Check your middleware and your request.
indexing
Indexing tracks which components are currently mounted on-screen. This is used for things like rendering optimizations.
- Component
(comp/component-name this)supplied an invalid identidentusing propsprops -
The indexing system was asked to index a component that just mounted, but that component’s props, when passed to
get-ident, resulting in something that didn’t look like a proper ident. Check your:identon that component. - Unable to re-index root. App was not set in the mutation env.
-
A change was detected that required indexing to re-index the root query, however, the indexing needs access to the app to do so. This probably indicates it was triggered via some async call, and that the dynamic
appvar was unbound. Seewith-parent-context.
inspect_client
- Cannot send to inspect. Channel closed.
-
-
- Transact on invalid uuid
app-uuid -
-
- Element picker not installed in app. You must add it to you preloads.
-
Add
com.fulcrologic.fulcro.inspect.dom-picker-preloadto the:devtools - :preloadsin yourshadow-cljs.ednand restart shadow-cljs. - Unable to find app/state for preview.
-
-
merge
- Unable to mark missing on result. Returning unmarked result
-
-
- Cannot merge component
componentbecause it does not have an ident! -
merge-componentrequires that the component passed to it has an ident. Perhaps you wanted to usemerge!? - merge-component!: component must implement Ident. Merge skipped.
-
merge-component!, just likemerge-component, requires that the component passed to it has an ident. Perhaps you wanted to usemerge!?
mutations
- set-props requires component to have an ident.
-
The mutation needs to be transacted from a component that has an ident (so that we know where to change the data).
- toggle requires component to have an ident.
-
The mutation needs to be transacted from a component that has an ident (so that we know where to change the data).
- Unknown app state mutation. Have you required the file with your mutations?
(:key ast) -
We could not find the
defmethod mutate(normally generated bydefmutation) for the given mutation name. That means that either you provided the wrong name or that the file containing defining it has not been loaded. Make sure that you require the mutation’s namespace, f.ex. in the namespace that uses it or e.g. in the namespace where you createfulcro-app. See Mutations - Using the Multimethod Directly for details about the internals.
tx_processing
- Send threw an exception for tx:
<query> -
-
- Transmit was not defined on remote
remote-name -
The map defining the remote MUST contain a
:transmit!key whose value is a(fn [send-node] ). See Writing Your Own Remote Implementation. - Dispatch for mutation
<query>failed with an exception. No dispatch generated. -
-
- The
actionsection of mutationmutation-symbolthrew an exception. -
-
- The
actionsection threw an exception for mutation:<mutation> -
-
- Network result for
remotedoes not have a valid node on the active queue! -
-
- Remote dispatch for
remotereturned an invalid value.remote-desire -
-
- The result-action mutation handler for mutation
<mutation>threw an exception. -
-
- Progress action threw an exception in mutation
<mutation> -
-
- Cannot abort network requests. The remote has no abort support!
-
See Aborting a Request.
- Failed to abort send node
-
-
ui_state_machines
- Invalid (nil) event ID
-
The
:event-idprovided totrigger-state-machine-eventmust not benil. - Activate called for invalid state:
state-idon(asm-id env) -
Check the UISM definition for the IDs of valid states (plus ::exit, ::started).
- Unable to find alias in state machine:
alias -
See UISM - Aliases.
- Cannot run load. Could not derive Fulcro class (and none was configured) for
actor-name -
Make sure that the
component-class-or-actor-nameargument toloadas actually a Fulcro component class or that it is the name of an actor that has a class associated with it - see UISM - The Actor Map for details. If you use a raw ident in the actor map, make sure to wrap it withwith-actor-class. - Cannot run load. query-key cannot be nil.
-
The query-key should be a Fulcro component class. Check what
key-or-identyou have supplied to theload. - INTERNAL ERROR: Cancel predicate was nil for timer
timer-id -
-
- Attempted to trigger event
event-idon state machineasm-id, but that state machine has not been started (call begin! first). -
Perhaps you expected the UISM to be started automatically by something but it has not happend and you need to start it manually. See UISM - Starting An Instance.
- Handler for event
event-idthrew an exception for ASM IDasm-id -
-
- The value given for actor
actor-idhad (or was) an invalid ident:v -
See UISM - The Actor Map.
40.1.2. Warnings
components
- get-ident was invoked on
(component-name x)with nil props (this could mean it wasn’t yet mounted):x -
It could also mean that the component is missing data in the Fulcro client DB (for example beacuse you have routed to a component without having loaded data for it) or that there is a missing "edge" somewhere between the root and this component. Use the DB Explorer in Fulcro Inspect and see whether you can navigate (click-through) from the top down to the component. See also A Warning About Ident and Link Queries.
- get-ident returned an invalid ident:
id<component display name> -
An ident must be a vector of two elements, where the first one is a keyword. You can define it either via a keyword, a template, or a lambda - see Ident Generation.
- get-ident called with something that is either not a class or does not implement ident:
<class> - React key for
(component-name class)is not a simple scalar value. This could cause spurious component remounts. -
The value returned by the
:keyfnyou have defined for the component’s factory should be a simple scalar such as a string or a number. React does need something that can be checked using javascript equality. - String ref on
(component-name class)should be a function. -
I.e. the props should include something like
:ref (fn [r] (gobj/set this "svg" r)), not simply"svg". See the D3 example. - Component
(component-name c)has a constant ident (id in the ident is not nil for empty props), but it has no initial state. This could cause this component’s props to appear as nil unless you have a mutation or load that connects it to the graph after application startup. -
The client DB must contain non-nil (but possibly empty) data for this component (i.e. you need to run at least
(assoc-in your-client-db <the ident>) {}). Or set its:initial-stateto at least{}. - Component
(component-name c)does not INCLUDE initial state for(component-name target)at join keyk; however,(component-name target)HAS initial state. This probably means your initial state graph is incomplete and props on(component-name target)will be nil. -
You need to make sure that initial state is composed up all the way to the root component, otherwise Fulcro will not "see" it. I.e. you should likely define
:initial-stateon this component using either the template ({<the join key> {}}) or lambda ((fn [params] {<the join key> (comp/get-initial-state <target component> {}))) form.
data_fetch
- Unions are not designed to be used with fewer than two children. Check your calls to Fulcro load functions where the :without set contains
(pr-str union-key) -
-
- Boolean load marker no longer supported.
-
Load marker should be a keyword unique to what you are loading, not
true. See Working with Normalized Load Markers. - Data load targets of two elements imply that you are targeting a table entry. That is probably incorrect. Normalization targets tables. Targeting is for creating missing edges, which are usually 3-tuples.
-
Targeting via
targeting/append-toetc. is intended to add a connection from one entity to another so you should provide it with the triplet<component id prop> - <id value> - prop-namesuch as[:person/id "123" :person/spouse]. If you want to get the data inserted at the given path instead of the default one then use:targetdirectly with the 2-element vector instead of using the targeting namespace. Ex.::target [:component/id :user-session]. - Query-transform-default is a dangerous option that can break general merge behaviors. Do not use it.
-
Use fulcro-app’s
:global-eql-transforminstead.
denormalize
- Loop detected in data graph - we have already seen
entityinside/underkey. Recursive query stopped. -
The recursive query has hit an ident that it already has included before, which may indicate a loop. This may be a "false positive" if the repeated ident is not on the recursive path and just has been included by at least two entities that are on the path. If you want the recursion to ignore possible duplicates then use a specific depth limit (a number) instead of just
…. See Recursive Queries for details.
dom
- There is a mismatch for the data type of the value on an input with value
element-value. This will cause the input to miss refreshes. In general you should force the :value of an input to be a string since that is how values are stored on most real DOM elements. -
This is a low-level js limitation. ALL inputs in the DOM world work with strings. If you use a non-string for
:valuejs will coerce it, but that can lead to weird behavior. You should do the coercion yourself.
dynamic_routing
- DEPRECATED USE OF
:will-leaveto check for allowable routing. You should add :allow-route-change? to:(comp/component-name this) -
Historical dynamic routing used
:will-leavefor two purposes. If you define:will-leaveyou should also define:allow-route-change?to eliminate this warning. - More than one route target matches
path -
Check the
:route-segmentof your target components.
http_remote
- Transit decode failed!
-
The body was either not transit-compatible (e.g. you tried to send a fn/class/etc as a parameter over the network) or you have not installed the correct transit read/write handlers. See
com.fulcrologic.fulcro.algorithms.transit/install-type-handler!and how it is used to handle tempids.
tx_processing
- Synchronous transaction was submitted on the app or a component without an ident. No UI refresh will happen.
-
Synchronous transactions will not cause a full UI refresh. It will only target refreses to the component passed as an argument, which must have an ident. If it does not, no UI will be refreshed, which likely is not what you wanted. Perhaps try to use the normal, asynchronous transaction (e.g.
transact!instead oftransact!!or transact! with:synchronously? true). See Fulcro 3.2 Inputs. - Remote does not support abort. Clearing the queue, but a spurious result may still appear.
-
-
ui_state_machines
- Attempt to get an ASM path
ksfor a state machine that is not in Fulcro state. ASM ID:asm-id -
This can happen e.g. if you are rendering routers before you’ve started their associated UISMs (and is mostly harmless) - you can use
app/set-root!with initialize state, thendr/initialize!ordr/change-route!, thenapp/mount!with NO initialize state to get rid of most or all of those. Basically: Make sure you’ve explicitly routed to a leaf (target) before mounting. In other cases - make sure the UISM has been started before you try to use it. - A fallback occurred, but no event was defined by the client. Sending generic ::uism/load-error event.
-
Fallbacks are an old mechanism for dealing with remote errors. UISM can wrap these in a named event, but you did not define what that event should be called.
- UNEXPECTED EVENT: Did not find a way to handle event
event-idin the current active state:current-state -
An event the UISM did not expect and cannot handle has been received. Whether that is a problem or not depends on your app. A common example is this warning from Dynamic Routing: "UNEXPECTED EVENT: Did not find a way to handle event
:timeout!in the current active state: `:failed`" - which is no problem.
Basically this just means the list of events in the current state does not list the given event. The most typical cause of this is async deliver of an event that expected the state machine to be in one state, but when it arrived it was in another. You can eliminate this warning by making a noop handler for that event in all the possible (unexpected) states it could arrive for.
41. Appendix: Fulcro Subsystems in Diagram Form
41.1. Startup
Fulcro startup is pretty trivial. It copies the initial tree from the co-located initial state on the component tree, normalizes it using the application’s query, and does a single keyframe render to make the initial DOM appear.

41.2. Transaction Processing
Once started, you could actually work with Fulcro by manipulating the database in the
state atom and call the schedule-render! function. But you really should not do that except
in extreme cases (e.g. external tooling for development).
Instead, Fulcro provides a very configurable transaction processing system where all side-effects and asynchronous behaviors can be safely encapsulated and reasoned about.
|
Note
|
The Default Result Action in the diagram is pluggable, and can even be overriden by each mutation (using a (result-action []) clause). The default is what most people rely on.
|

41.2.1. Load Transaction Processing
Loads are transactions. In fact, pretty much every side-effect in Fulcro should run as a transaction. Loads use the exact diagram above but manually modify the outgoing EQL on the remote handler, and use an alternative result action.
41.3. Targeted Refresh
Certain operations, such as set-value!! and transact!! (usually denoted with a !! suffix) trust the programmer that no parent components will need to be refreshed in the UI as a result of the changes that the operation will make to state. This is a pure optimization, and Fulcro can use this to "tunnel" a subtree of props to the component from which these calls are made (the component MUST be used as the first argument, instead of the app, or a root render will be done instead). Another optimization that is often applied with targeted refresh is that the optimistic updates to the state atom are done synchronously. This dramatically reduces latency and overhead.

41.4. Graph Manipulation
The overall design of Fulcro is centered around the idea of incoming graphs of data which are auto-normalized to a client database. The initial state is the "starting graph", and any operation done from that point forward is simply some form of graph manipulation. The fact that this data is normalized just means you don’t have to worry about keeping data that appears in more than one place in the graph "in sync", but you really can just think of your overall application as a graph of data you can manipulate.
By itself, normalization does not attach new nodes to anything that already exists in the graph (unless the nodes of the new graph normalize over exising nodes).
So, besides normalization you almost always want to join some new subgraph to the exising graph in one of the following ways:
-
Place the newly-loaded subgraph(s) at some root key in the database (default)
-
Add the root of the newly-added subgraph to a ref contained in some pre-existing node.
-
Add all of the elements of the new subgraph to a to-many ref in some pre-existing node.
The source of the "new subgraph node(s)" can be a merge of data you created locally, or data that was obtained from some remote.

We might want to merge a replacement list of items.
[{:item/id "Item1c" :item/label "Foo"} {:item/id "Item2c"}]Just merging these to the root level with:
(doseq [item items]
(merge-component! app TodoItem item))just results in disconnected nodes:

Let’s say we loaded these via (df/load! this :some-items TodoItem). The required "root query key" of load implies
a "default" target node at the root of the graph, so now we’d get this:

and since we are rendering Root, those items are just data hanging out in the database and will not be on-screen.
So what we actually want it to patch the incoming nodes into a particular spot in the tree. This is done with data targeting.
So something like this:
(doseq [item items]
(merge-component! app TodoItem item :append [:todolist/id 1 :items))results in adding the new items to the end of the items at Todo List 1’s :items key:

and an operation like (df/load-field! this :items) (where this is within the render body of TodoList with ID 2) will
send the server query [{[:todolist/id 2] [{:items (get-query TodoItem)}]}], which because it uses an ident as a "root"
key will auto-target to the TODO list in question, resulting in:

Remember that all of this data is kept normalized at all times, so the "target path" of a merge or load is one of:
-
A top-level ident (e.g. loading or merging one)
-
A top-level keyword
-
A "field" of a normalized entity (a path that has two elements of the ident, and one element that names the attribute)
So, you can think of graph manipulation abstractly in terms of the overall graph, and treat normalization as a pure implementation detail.