1. Prologue
|
Warning
|
This book covers Fulcro 2.0. New applications should start with version 3.0, and use The Developer’s Guide for that version. |
1.1. About This Book
This is a stand-alone book for Fulcro developers that can be used by beginners and experienced developers and covers most of the library in detail. Fulcro has a pretty extensive set of resources on the web tailored to fit your learning style. There is this book, YouTube videos, an interactive tutorial, and full-blown sample applications.
A lot of time and energy went into creating these libraries and materials and providing them free of charge. If you find them useful please consider contributing to the project. Also contributing fixes to this guide is appreciated.
This book includes quite a bit of live code. Live code demos with their source look like this:
(ns book.example-1
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.mutations :refer [defmutation]]
#?(:cljs [fulcro.client.dom :as dom]
:clj
[fulcro.client.dom-server :as dom])))
(defmutation bump-number [ignored]
(action [{:keys [state]}]
(swap! state update :ui/number inc)))
(defsc Root [this {:keys [ui/number]}]
{:query [:ui/number]
:initial-state {:ui/number 0}}
(dom/div
(dom/h4 "This is an example.")
(dom/button {:onClick #(prim/transact! this `[(bump-number {})])}
"You've clicked this button " number " times.")))All of the full stack examples use a mock server embedded in the browser to simulate the interaction, but the source that you’ll read for the application is identical to what you’d write for a real server.
|
Warning
|
If you’re viewing this directly from the GitHub Fulcro repository then you won’t see the live code! Use http://book.fulcrologic.com instead. |
The mock server has a built-in latency to simulate a moderately slow network so you can observe behaviors over time. You can control the length of this latency in milliseconds using the "Server Controls" in the upper-right corner of this document (if you’re reading the HTML version with live examples).
1.1.1. Common Prefixes and Namespaces
Many of the code examples assume you’ve required the proper namespaces in your code. This book adopts the following general set of requires and aliases:
(ns your-ns
(:require [fulcro.client.primitives :as prim :refer [defsc defui]]
[fulcro.client.dom :as dom]
[fulcro.util :as util]
[fulcro.client.util :as cutil]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.server :as server :refer [defquery-root defquery-entity]]
[fulcro.client :as fc]])others will be identified as they are used.
The next chapter, "Getting Started", is an exception. The code you see in that chapter is meant to be added to a template that you create and run on your own machine.
2. Getting Started
This chapter takes you through a step-by-step guide of how to go from nothing to a full-stack basic application. Concepts are introduced as we go, and given a very cursory definition in the interest of concision. Once you’ve got the general idea you can use other materials to refine your understanding.
The Leiningen template is the very quickest way to get started. It gives you a number of useful things like workspaces (a place to build components and even apps in cards), production builds, CI integration and more while also giving you the minimal amount of actual code. This can save you hours of setup.
|
Important
|
This document assumes you’re working with Fulcro 2.6 and above. Any differences should be minor. |
2.1. Install Fulcro Inspect
You should use Chrome for development because we have a developer tool called Fulcro Inspect that is available
from the Chrome store for free. There are also devtools that are installed via preloads which will autoformat
EDN that is sent via console.log. When properly configured, these tool will let you view the internal state of your
Fulcro application, the local and remote transaction history, save "snapshots" of state so you can quickly retry a
UI flow by hitting a "reset" button, "scroll" over state history and watch the UI change, run queries (with autocomplete
if you’re using Pathom) against your EQL server, and even (via binaryage devtools) source-level debug your Fulcro application in CLJS with
stack frame analysis and proper clojure names for things! Doing without either of these tools will be like working
in the dark.
Fulcro Inspect is a free extension for Chrome, and Binaryage devtools is a library that can be injected via a preload. The setup for these is done automatically when you use the Fulcro lein template, but you still have to install the chrome extension via Chrome itself.
2.2. Project setup
You can get a basic working app using:
$ lein new fulcro appThis gives you a shell of a project that still contains everything you’d want to set up (workspaces, testing, a development web server, shadow-cljs, etc.) without much actual code to understand or delete.
You should stop here for a moment and read the README in your generated project to see how that is laid out.
2.2.1. Starting the Compiler
The Fulcro template uses shadow-cljs. We’ve been using this tool for over a year and it is a really great experience.
The additions over the stock Clojurescript compiler make for a much more polished experience.
It allows you to use the normal js ecosystem of components very easily, is really good about caching, doesn’t get easily
confused (I almost never have to do a clean of project builds, which I used to have to do with the standard tools
all the time). You should check out the User’s Guide when
you have a chance, but for now you can simply start the compiler server:
$ npm install # only need to do this once
$ npx shadow-cljs serverand navigate to the URL it prints out for the compiler server (usually http://localhost:9630). You can then use the "Builds" menu to turn on/off different client builds and see the progress live as it happens!
It also has hot-code reload built in, so there is no need for an additional tool like figwheel.
2.2.2. Starting the Server
Simply start a REPL (see the README in your generated project for instructions) and use:
(start)to start the server (which defaults to port 3000). If you’ve turn on the main build in shadow-cljs, then you
should see the base template page. Please refer to the README in your template app if this doesn’t work, as
this could get out of date with respect to the template.
|
Note
|
At the time of this writing you’ll have the fewest problems running JDK 8 (newer versions work, but have various extra options you have to pass). Also make sure you don’t have anything strange in your personal Leingingen profile, and that your Clojure tools.deps version is up-to-date. |
2.2.3. Choosing a React Version
Fulcro supports React 15 and 16 (and should even be fine with 17 when it is released). The template uses shadow-cljs
for compiles, so you simple include the version you’d like to use in the standard package.json file. This is already
done for you in the template.
2.3. The Code Client Files
A complete Fulcro front-end client can be created in about two lines of code. Hot-load concerns require just a few more lines.
Your project should have a src/main/app/client.cljs file that looks something like this:
(ns app.client
(:require [fulcro.client :as fc]
[app.ui.root :as root]
[fulcro.client.network :as net]))
(defonce app (atom nil))
(defn mount []
(reset! app (fc/mount @app root/Root "app")))
(defn start []
(mount))
(def secured-request-middleware
;; The CSRF token is embedded in the server_components/html.clj
(->
(net/wrap-csrf-token (or js/fulcro_network_csrf_token "TOKEN-NOT-IN-HTML!"))
(net/wrap-fulcro-request)))
(defn ^:export init []
(reset! app (fc/make-fulcro-client
;; This ensures your client can talk to a CSRF-protected server.
;; See middleware.clj to see how the token is embedded into the HTML
{:networking {:remote (net/fulcro-http-remote
{:url "/api"
:request-middleware secured-request-middleware})}}))
(start))|
Note
|
The client construction function new-fulcro-client still exists and may be
what you see in applications and videos. The new function changes some of the defaults
and takes a map instead of named parameters. The old function still exists and works, but is
discouraged.
|
These functions are used from the HTML page to initialize the application. The reason things
are split into multiple functions is to allow the application to be remounted on hot-code reload.
The client isn’t active until you mount it, and to mount it
you need a UI. The file src/main/ui/root.cljc contains some simple UI.
(ns app.ui.root
(:require
[fulcro.client.dom :as dom :refer [div]]
[fulcro.client.primitives :as prim :refer [defsc]]
[app.ui.components :as comp]))
(defsc Root [this {:keys [root/message]}]
{:query [:root/message]
:initial-state {:root/message "Hello!"}}
(div :.ui.segments
(div :.ui.top.attached.segment
(div :.content
"Welcome to Fulcro!"))
(div :.ui.attached.segment
(div :.content
(comp/ui-placeholder {:w 50 :h 50})
(div message)
(div "Some content here would be nice.")))))If you look at the shadow-cljs.edn file you’ll see it is configured to re-call start after every hot load.
Mounting an already mounted app is the same as asking for a forced UI refresh. This ensures you’ll see UI changes
even if your props don’t change (all Fulcro components are pure and don’t render unless forced to, or see a prop change).
...
:builds {:main {...
:devtools {:after-load app.client/start}
...This is all the real code you need to get started with a hot-code reload capable application! However, the
browser needs instructions to load this stuff up, and the target div of the mount needs to exist.
2.3.1. The HTML
Your HTML file to load the app needs these things:
-
Include a DIV on the DOM with the ID you want to mount on.
-
Include the generated JS file.
-
Call your exported
initfunction.
This corresponds to:
<!DOCTYPE html>
<html>
<body>
<div id="app"></div>
<script src="js/app.js" type="text/javascript"></script>
<script>app.client.init();</script>
</body>
</html>but you won’t find this in your template resources. The template generates a secure app with CSRF (cross-site request forgery) protection.
This means a CSRF token needs to be embedded in the page,
and this is a complication you can ignore for the most part right now; however, it explains why we dynamically
generate the HTML file in the server using hiccup (in middleware.clj):
(defn index [csrf-token]
(html5
[:html {:lang "en"}
[:head {:lang "en"}
[:title "Application"]
[:meta {:charset "utf-8"}]
[:meta {:name "viewport" :content "width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no"}]
[:link {:href "https://cdnjs.cloudflare.com/ajax/libs/semantic-ui/2.4.1/semantic.min.css"
:rel "stylesheet"}]
[:link {:rel "shortcut icon" :href "data:image/x-icon;," :type "image/x-icon"}]
[:script (str "var fulcro_network_csrf_token = '" csrf-token "';")]]
[:body
[:div#app]
[:script {:src "js/main/app.js"}]
[:script "app.client.init();"]]]))REMINDER: When developing it is a good idea to: Use Chrome (the devtools only work there) and install the Fulcro Inspect extension from the Chrome store. Keep the developer’s console open, and in the developer console settings: "Network, Disable cache (while DevTools is open)", and "Console, Enable custom formatters".
Cached files can, as everywhere else, cause you lots of headaches. Fortunately they only really affect you poorly on the initial load in Fulcro. Hot reloads typically work very well.
The Fulcro Inspect tab will show the state of your Fulcro application (along with lot of other useful details like your transaction log) if you’ve included the proper dependencies and preloads (which the template should have done for you).
2.4. Basic UI Components
Fulcro supplies defsc to build React components. This macro emits React components that work as 100% raw React
components (i.e. once you compile them to Javascript they could be used from other native React code).
There are also factory functions for generating all standard HTML5 DOM elements in React in the fulcro.client.dom namespace.
2.4.1. The defsc Macro
The basic code to build a simple component has the following form:
(defsc ComponentName
[this props] ; parameters. Available in body, and in *some* of the options
; optional: { ...options... }
(dom/div {:className "a" :id "id" :style {:color "red"}}
(dom/p "Hello")))This macro emits the equivalent of a React component with a render method.
Class names and IDs can be written in a more compact format instead of the map (or in front of it if you have other props to pass):
(dom/div :.a#id {:style {:color "red"}}
(dom/p "Hello"))of course you can also :refer the common tags in your namespace declaration:
(ns ui
(:require [fulcro.client.dom :as dom :refer [div p]]))and make this even tighter:
(div :.a#id {:style {:color "red"}}
(p "Hello"))For our purposes we won’t be saying much about the React lifecycle methods, though they can be added. The basic intention of this macro’s syntax is to declare a component that can render UI and participate in our data-driven story.
2.4.2. The render method.
The body of defsc is the render for the component and can do whatever work you need, but it should return
a react element (see React Components, Elements, and Instances).
As of React 16 you can return a sequence of elements as well (though each must have a unique :key).
There are factory methods for all of HTML5 in fulcro.client.dom. These functions can take an optional keyword that
specifies classes and an ID, followed by an optional map or additional props. If the tag allows children then
they are simply placed after these two optional things:
(dom/div :.a#thing "Hi") ; keyword can contain any number of classes preceeded by dots, and an id with #
(dom/div :.a#thing {:data-prop 3} "Hi") ; props can still be supplied with the keyword
(dom/div :.a.b.c "Hi") ; Any number of static classes (a b, and c).
(dom/div {:className "a" :data-prop 3} "Hi") ; or it can all be done in props
(dom/div {:classes [(when hidden "hidden") (if tall :.tall :.short)]} ...) ; :classes is nice for expressions (2.5.12+)These are macros that obtain very good runtime speed by converting the maps and such to low-level js at compile time.
|
Note
|
The class keyword requires each class to be preceeded by a ., and will give a compile error if you forget to do that.
|
|
Important
|
If you’re writing your UI in CLJC files then you need to make sure you use a conditional reader to pull in the proper server DOM functions for Clojure: |
(ns app.ui
(:require #?(:clj [fulcro.client.dom-server :as dom] :cljs [fulcro.client.dom :as dom]))
... the actual code is the same as beforeThe reason this is necessary is that CLJS requires macros to be in CLJ files, but in order to get higher-order functions to operate in CLJ the DOM elements must be functions. In CLJS, you can have both a macro and function with the same name, but this is not true in CLJ. Therefore, in order to get the optimal (inlined) client performance two namespaces are required.
2.4.3. Props
React components receive their data through props and state (which is local mutable state on the component).
In Fulcro we highly recommend using props for most things. This
ensures that various other features work well. The data passed to a component can be accessed (as a cljs map) by
calling prim/props on this, or by destructuring in the second argument of defsc.
So, let’s define a Person component to display details about
a person. We’ll assume that we’re going to pass in name and age as properties:
(defsc Person [this {:keys [person/name person/age]}]
(dom/div
(dom/p "Name: " name)
(dom/p "Age: " age)))Now, in order to use this component we need an element factory. An element factory lets
us use the component within our React UI tree. Name confusion can become an
issue (Person the component vs. person the factory?) we recommend prefixing the factory with ui-:
(def ui-person (prim/factory Person))Now we can compose people into our root:
(defsc Root [this props]
(dom/div
(ui-person {:person/name "Joe" :person/age 22})))2.4.4. Hot Code Reload
Part of our quick development story is getting hot code reload to update the UI whenever we change the source.
Try editing the UI of Person and save. You should see the UI update even though the person’s data didn’t change.
2.4.5. Composing
You should already be getting the picture that your UI is going to be a tree composed from a root element. The method of data passing (via props) should also be giving you the picture that supplying data to your UI (through root) means you need to supply an equivalently structured tree of data. This is true of basic React. However, just to drive the point home let’s make a slightly more complex UI and see it in detail:
Replace your content with this:
(defsc Person [this {:keys [person/name person/age]}]
(dom/li
(dom/h5 (str name " (age: " age ")"))))
(def ui-person (prim/factory Person {:keyfn :person/name}))
(defsc PersonList [this {:keys [person-list/label person-list/people]}]
(dom/div
(dom/h4 label)
(dom/ul
(map ui-person people))))
(def ui-person-list (prim/factory PersonList))
(defsc Root [this {:keys [ui/react-key]}]
(let [ui-data {:friends {:person-list/label "Friends" :person-list/people
[{:person/name "Sally" :person/age 32}
{:person/name "Joe" :person/age 22}]}
:enemies {:person-list/label "Enemies" :person-list/people
[{:person/name "Fred" :person/age 11}
{:person/name "Bobby" :person/age 55}]}}]
(dom/div
(ui-person-list (:friends ui-data))
(ui-person-list (:enemies ui-data)))))So that the UI graph looks like this:
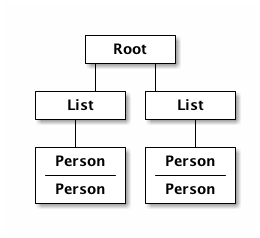
and the data graph matches the same structure, with map keys acting as the graph "edges":
{ :friends { :person-list/people [PERSON ...]
; ==to-one list=> ==to-many people==>
:enemies { :person-list/people [PERSON ...] }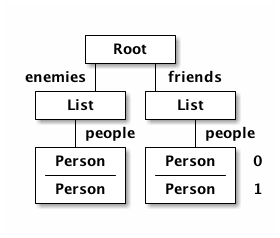
2.4.6. The Component Registry (version 2.8.8+)
We don’t need it at the moment, but you may find it useful to note that any component that is required in your application will appear in a global component registry. You can look up such components using a symbol or keyword that matches the fully namespace-qualified name of the component:
(prim/classname->class `app.ui/Root)
;; OR
(prim/classname->class :app.ui/Root)This comes in handy for things like code splitting (where the dynamically loaded code will appear in the registry), tracking classes (by name) in app state (which cannot appear there as "code").
2.5. Feeding the Data Tree
Obviously it isn’t going to be desirable to hand-manage this very well for anything but the most trivial application (which is the crux of the problems with most UI libraries).
At best it does give us a persistent data structure that represents the current "view" of the application (which has many benefits), but at worst it requires us to "think globally" about our application. We want local reasoning. We also want to be able to easily re-compose our UI as needed, and a static data graph like this would have to be updated every time we made a change! Almost equally as bad: if two different parts of our UI want to show the same data then we’d have to find and update a bunch of copies spread all over the data tree.
So, how do we solve this?
2.5.1. Why not have components just "grab" their data (sideband)?
This is certainly a possibility; however, it leads to other complications. What is the data model? How do you interact with remotes to fill your data needs? Fulcro has a very nice cohesive story for these questions, while other systems end up with complications like event handler middleware, coeffect accretion, and signal graphs…not to mention that the sideband solution says nothing definitive about how you actually accomplish the server interactions with said data model.
Fulcro has a model for all of this, and it is surprising how simple it makes your application once you put your application together. Let’s look at the steps and parts:
2.5.2. Step 1 — The Initial State
All applications have some starting initial state. Since our UI is a tree, our starting state needs to somehow establish what goes to the initial nodes.
In Fulcro, there is a way to construct the initial tree of data in a way that allows for local reasoning and easy refactoring: co-locate the initial desired part of the tree with the component that uses it. This allows you to compose the state tree in exactly the same way as the UI tree.
The defsc macro makes short work of this with the initial-state option. Simply give it a
lambda that gets parameters (optionally from the parent) and returns a map representing the state of the component.
You can retrieve this data using (prim/get-initial-state Component).
It looks like this:
(ns app.ui.root
(:require
#?(:clj [fulcro.client.dom-server :as dom] :cljs [fulcro.client.dom :as dom])
[fulcro.client.primitives :as prim :refer [defsc]]))
(defsc Person [this {:keys [person/name person/age]}]
{ :initial-state (fn [{:keys [name age] :as params}] {:person/name name :person/age age}) }
(dom/li
(dom/h5 (str name "(age: " age ")"))))
(def ui-person (prim/factory Person {:keyfn :person/name}))
(defsc PersonList [this {:keys [person-list/label person-list/people]}]
{:initial-state
(fn [{:keys [label]}]
{:person-list/label label
:person-list/people (if (= label "Friends")
[(prim/get-initial-state Person {:name "Sally" :age 32})
(prim/get-initial-state Person {:name "Joe" :age 22})]
[(prim/get-initial-state Person {:name "Fred" :age 11})
(prim/get-initial-state Person {:name "Bobby" :age 55})])})}
(dom/div
(dom/h4 label)
(dom/ul
(map ui-person people))))
(def ui-person-list (prim/factory PersonList))
; Root's initial state becomes the entire app's initial state!
(defsc Root [this {:keys [friends enemies]}]
{:initial-state (fn [params] {:friends (prim/get-initial-state PersonList {:label "Friends"})
:enemies (prim/get-initial-state PersonList {:label "Enemies"})}) }
(dom/div
(ui-person-list friends)
(ui-person-list enemies)))|
Note
|
You must reload your browser for this to show up. Fulcro pulls this data into the database when the application first mounts, not on hot code reload (because that would change your app state, and hot code reload is more useful without state changes). |
Now a lot of the specific data here is just for demonstration purposes. Data like this (people) would almost
certainly come from a server, but it serves to illustrate that we can localize the initial data needs of a
component to the component, and then compose that into the parent in an abstract way
(by calling get-initial-state against that child).
There are several benefits of this so far:
-
It generates the exact tree of data needed to feed the initial UI.
-
That initial state becomes your initial application database.
-
It restores local reasoning (and easy refactoring). Moving a component just means local reasoning about the component being moved and the component it is being moved from/to: You remove the
get-initial-statefrom one parent and add it to a different one.
You can see that there is no magic if you just pull the initial tree at the REPL:
dev:cljs.user=> (fulcro.client.primitives/get-initial-state app.ui.root/Root {})
{:friends
{:person-list/label "Friends",
:person-list/people
[{:person/name "Sally", :person/age 32}
{:person/name "Joe", :person/age 22}]},
:enemies
{:person-list/label "Enemies",
:person-list/people
[{:person/name "Fred", :person/age 11}
{:person/name "Bobby", :person/age 55}]}}It’s nothing more than function composition. The initial state option on defsc encodes your initial state
into a function that can be accessed via get-initial-state on a class.
So behind the scenes Fulcro detects the initial state on the first mount and automatically uses it to initialize your application state.
By default, the entire initial state database is passed into your root node on render, so it is available for destructuring in Root’s props.
If you even want to see your current application state, you can do so through the atom that is holding your mounted application:
dev:cljs.user=> @(fulcro.client.primitives/app-state (get @app.client/app :reconciler))Let’s see how we program our UI to access the data in the application state!
2.5.3. Step 2 — Establishing a Query
Fulcro unifies the data access story using a co-located query on each component. This sets up data access for both the client and server, and also continues our story of local reasoning and composition.
Queries go on a component in the same way as initial state: as static implementations of a protocol.
The query notation is relatively light, and we’ll just concentrate on two bits of query syntax: props and joins.
Queries form a tree just like the UI and data. Obtaining a value at the current node in the tree traversal is done using the keyword for that value. Walking down the graph (a join) is represented as a map with a single entry whose key is the keyword for that nested bit of state.
So, a data tree like this:
{:friends
{:person-list/label "Friends",
:person-list/people
[{:person/name "Sally", :person/age 32}
{:person/name "Joe", :person/age 22}]},
:enemies
{:person-list/label "Enemies",
:person-list/people
[{:person/name "Fred", :person/age 11}
{:person/name "Bobby", :person/age 55}]}}would have a query that looks like this:
[{:friends ; JOIN
[ :person-list/label
{:person-list/people ; JOIN
[:person/name :person/age]}]}]This query reads "At the root you’ll find :friends, which joins to a nested entity that has a label and people,
which in turn has nested properties name and age.
-
A vector always means "get this stuff at the current node"
-
:friendsis a key in a map, so at the root of the application state the query engine would expect to find that key, and would expect the value to be nested state (because maps mean joins on the tree) -
The value in the
:friendsjoin must be a vector, because we have to indicate what we want out of the nested data.
Joins are automatically to-one if the data found in the state is a map, and to-many if the data found is a
vector. In the example above the :friends field from root pointed to a single PersonList, whereas the PersonList
field :person-list/people pointed to a vector of Person. Beware that you don’t confuse yourself with
naming (e.g. friends is plural, but points to a single list).
The namespacing of keywords in your data (and therefore your query) is highly encouraged, as it makes it clear to the reader what kind of entity you’re working against (it also ensures that over-rendering doesn’t happen on refreshes later).
You can try this query stuff out in your REPL. Let’s say you just want the friends list label. The function
db→tree can take an application database (which we can generate from initial state) and run a query
against it:
dev:cljs.user=> (fulcro.client.primitives/db->tree [{:friends [:person-list/label]}] (fulcro.client.primitives/get-initial-state app.ui.root/Root {}) {})
{:friends {:person-list/label "Friends"}}HINT: The mirror of initial state with query is a great way to error-check your work (and defsc does some of that
for you): For each scalar property in
initial state, there should be an identical simple property in your query. For each join of initial state to a child via
get-initial-state there should be a query join via get-query to that same child.
Adding Queries to Our Example
We want our queries to have the same nice local-reasoning as our initial data tree. The get-query function
works just like the get-initial-state function, and can pull the query from a component. In this case, you
should not ever call query directly. The get-query function augments the subqueries with metadata that is
important at a later stage.
So, the Person component queries for just the properties it needs:
(defsc Person [this {:keys [person/name person/age]}]
{:query [:person/name :person/age]
:initial-state (fn [{:keys [name age] :as params}] {:person/name name :person/age age})}
(dom/li
(dom/h5 (str name "(age: " age ")"))))Notice that the entire rest of the component did not change.
Next up the chain, we compose the Person query into PersonList (notice how the composition of state and query
are mirrored):
(defsc PersonList [this {:keys [person-list/label person-list/people]}]
{:query [:person-list/label {:person-list/people (prim/get-query Person)}]
:initial-state
(fn [{:keys [label]}]
{:person-list/label label
:person-list/people (if (= label "Friends")
[(prim/get-initial-state Person {:name "Sally" :age 32})
(prim/get-initial-state Person {:name "Joe" :age 22})]
[(prim/get-initial-state Person {:name "Fred" :age 11})
(prim/get-initial-state Person {:name "Bobby" :age 55})])})}
(dom/div
(dom/h4 label)
(dom/ul
(map ui-person people))))again, nothing else changes.
2.5.4. Step 3 — Receive the Data Feed as Props in Root
Finally, we compose to Root:
(defsc Root [this {:keys [friends enemies]}]
{:query [{:friends (prim/get-query PersonList)}
{:enemies (prim/get-query PersonList)}]
:initial-state (fn [params] {:friends (prim/get-initial-state PersonList {:label "Friends"})
:enemies (prim/get-initial-state PersonList {:label "Enemies"})})}
(dom/div
(ui-person-list friends)
(ui-person-list enemies)))This all looks like a minor (and useless) change. The operation is the same; however, we’re getting close to the magic, so stick with us. The major difference in this code is that even though the database starts out with the initial state, there is nothing to say we have to query for everything that is in there, or that the state has to start out with everything we might query for in the future. We’re getting close to having a dynamic data-driven application.
Notice that everything we’ve done so far has global client database implications, but that each component codes only the portion it is concerned with. Local reasoning is maintained. All software evolution in this model preserves this critical aspect.
Also, you now have application state that can evolve (the query is running against the active application database stored in an atom)!
|
Important
|
You should always think of the query as "running from root". You’ll
notice that Root still expects to receive the entire data tree for the UI (even though it doesn’t have to
know much about what is in it, other than the names of direct children), and it still picks out those sub-trees
of data and passes them on. In this way an arbitrary component in the UI tree is not querying
for its data directly in a side-band sort of way, but is instead being composed in from parent to parent all the
way to the root. Later, we’ll learn how Fulcro can optimize this and pull the data from the database for
a specific component, but the reasoning will remain the same.
|
2.6. Passing Callbacks and Other Parent-computed Data
The queries on component describe what data the component wants from the database; however, you’re not allowed to put code in the database, and sometimes a parent might compute something it needs to pass to a child like a callback function.
It turns out that we can optimize away the refresh of components (if their data has not changed). This means that we can use a component’s query to directly re-supply data for refresh; however, since doing so skips the rendering of the parent, if we are not careful this can lead to "losing" these extra bits of computationally generated data passed from the parent, like callbacks.
Let’s say we want to render a delete button on our individual people in our UI. This button will mean "remove the person from this list"…but the person itself has no idea which list it is in. Thus, the parent will need to pass in a function that the child can call to affect the delete properly:
2.6.1. The Incorrect Way:
(defsc Person [this {:keys [person/name person/age onDelete]}] ; (3)
{:query (fn [] [:person/name :person/age])
:initial-state (fn [{:keys [name age] :as params}] {:person/name name :person/age age})}
(dom/li
(dom/h5 (str name " (age: " age ")") (dom/button {:onClick #(onDelete name)} "X")))) ; (4)
(def ui-person (prim/factory Person {:keyfn :person/name}))
(defsc PersonList [this {:keys [person-list/label person-list/people]}]
{:query [:person-list/label {:person-list/people (prim/get-query Person)}]
:initial-state
(fn [{:keys [label]}]
{:person-list/label label
:person-list/people (if (= label "Friends")
[(prim/get-initial-state Person {:name "Sally" :age 32})
(prim/get-initial-state Person {:name "Joe" :age 22})]
[(prim/get-initial-state Person {:name "Fred" :age 11})
(prim/get-initial-state Person {:name "Bobby" :age 55})])})}
(let [delete-person (fn [name] (println label "asked to delete" name))] ; (1)
(dom/div
(dom/h4 label)
(dom/ul
(map (fn [p] (ui-person (assoc p :onDelete delete-person))) people))))) ;; (2)-
A function acting in as a stand-in for our real delete
-
Adding the callback into the props (WRONG)
-
Pulling the onDelete from the passed props (WRONG). The query has to be changed to a lambda to turn off error checking to even try this method.
-
Invoking the callback when delete is pressed.
This method of passing a callback will work initially, but not consistently. The problem is that we can optimize away a re-render of a parent when it can figure out how to pull just the data of the child on a refresh, and in that case the callback will get lost because only the database data will get supplied to the child! Your delete button will work on the initial render (from root), but may stop working at a later time after a UI refresh.
2.6.2. The Correct Way:
There is a special helper function that can record the computed data like callbacks onto the child that receives them
such that an optimized refresh will still know them. There is also an additional (optional) component parameter to defsc
that you can use to deconstruct them:
(defsc Person [this {:keys [person/name person/age]} {:keys [onDelete]}] (2)
{:query [:person/name :person/age]
:initial-state (fn [{:keys [name age] :as params}] {:person/name name :person/age age})}
(dom/li
(dom/h5 (str name " (age: " age ")") (dom/button {:onClick #(onDelete name)} "X")))) ; (4)
(def ui-person (prim/factory Person {:keyfn :person/name}))
(defsc PersonList [this {:keys [person-list/label person-list/people]}] ;
{:query [:person-list/label {:person-list/people (prim/get-query Person)}]
:initial-state
(fn [{:keys [label]}]
{:person-list/label label
:person-list/people (if (= label "Friends")
[(prim/get-initial-state Person {:name "Sally" :age 32})
(prim/get-initial-state Person {:name "Joe" :age 22})]
[(prim/get-initial-state Person {:name "Fred" :age 11})
(prim/get-initial-state Person {:name "Bobby" :age 55})])})}
(let [delete-person (fn [name] (println label "asked to delete" name))] ; (1)
(dom/div
(dom/h4 label)
(dom/ul
(map (fn [p] (ui-person (prim/computed p {:onDelete delete-person}))) people))))) ; (1)-
The
prim/computedfunction is used to add the computed data to the props being passed. -
The child adds an additional parameter, and pulls the computed data from there. You can also use
(prim/get-computed this)to pull all of the computed props in the body.
Now you can be sure that your callbacks (or other parent-computed data) won’t be lost to render optimizations.
2.7. Updating the Data Tree
Now the real fun begins: Making things dynamic.
In general you don’t have to think about how the UI updates, because most changes are run within the context that needs refreshed. But for general knowledge UI Refresh is triggered in two ways:
-
Running a data modification transaction on a component (which will re-render the subtree of that component), and refresh only the DOM for those bits that had actual changes.
-
Telling Fulcro that some specific data changed (e.g.
:person/name).
The former is most common, but the latter is often needed when a change executed in one part of the application modifies data that some UI component elsewhere in the tree needs to respond to.
So, if we run the code that affects changes from the component that will need to refresh (a very common case) we’re covered. If a child needs to make a change that will affect a parent (as in our earlier example), then the modification should run from the parent via a callback so that refresh will not require further interaction. Later we’ll show you how to deal with refreshes that could be in far-flung parts of the UI. First, let’s get some data changing.
2.7.1. Transactions
Every change to the application database must go through a transaction processing system. This has two goals:
-
Abstract the operation (like a function)
-
Treat the operation like data (which allows us to generalize it to remote interactions)
The operations are written as quoted data structures. Specifically as a vector of mutation invocations. The entire transaction is just data. It is not something run in the UI, but instead passed into the underlying system for processing.
You essentially just "make up" names for the operations you’d like to do to your database, just like function names. Namespacing is encouraged, and of course syntax quoting honors namespace aliases.
(prim/transact! this `[(ops/delete-person {:list-name "Friends" :person "Fred"})])is asking the underlying system to run the mutation ops/delete-person (where ops can be an alias established
in the ns). Of course, you’ll typically use unquote to embed data from local variables:
(prim/transact! this `[(ops/delete-person {:list-name ~name :person ~person})])2.7.2. Handling Mutations
When a transaction runs in Fulcro it passes things off to a multimethod. The multi-method is described in more
detail in the section on the mutation multimethod, but Fulcro provides a macro that makes
building (and using) mutations easier: defmutation.
Mutations typically can go wherever you want. The macro augments a multimethod, so you need to make sure that
namespace is required by files that your program already uses. Something like src/main/app/api/mutations.cljs
is fine, but you might also find it useful to place your mutations in something topical so you can write
the server mutations in the CLJ version of the file, and the client ones in the cljs. Mutations are namespaced,
so this makes things easier.
A mutation looks a bit like a method. It can have a docstring, and the argument list will always receive a single argument (params) that will be a map (which then allows destructuring).
The body looks a bit like a letfn, but the names we use for these methods are pre-established. The one
we’re interested in at the moment is action, which is what to do locally. The action method will be
passed the application database’s app-state atom, and it should change the data in that atom to reflect
the new "state of the world" indicated by the mutation.
For example, delete-person must find the list of people on the list in question, and filter out the one
that we’re deleting:
(ns app.api.mutations
(:require [fulcro.client.mutations :as m :refer [defmutation]]))
(defmutation delete-person
"Mutation: Delete the person with name from the list with list-name"
[{:keys [list-name name]}] ; (1)
(action [{:keys [state]}] ; (2)
(let [path (if (= "Friends" list-name)
[:friends :person-list/people]
[:enemies :person-list/people])
old-list (get-in @state path)
new-list (vec (filter #(not= (:person/name %) name) old-list))]
(swap! state assoc-in path new-list))))-
The argument list for the mutation itself
-
The thing to do, which receives the app-state atom as an argument.
Then all that remains is to change ui.root in the following ways:
-
Add a require and alias for app.operations to the ns
-
Change the callback to run the transaction
(ns app.ui.root
(:require [fulcro.client :as fc]
[fulcro.client.dom :as dom]
; ADD THIS:
[app.api.mutations :as api] ; (1)
[fulcro.client.primitives :as prim :refer [defui defsc]]))
...
(defsc PersonList [this {:keys [person-list/label person-list/people]}]
...
(let [delete-person (fn [name] (prim/transact! this `[(api/delete-person {:list-name ~label :name ~name})]))] ; (2)
...-
The require ensures that the mutations are loaded, and also gives us an alias to the namespace of the mutation’s symbol.
-
Running the transaction in the callback.
Note that our mutation’s symbol is actually app.api.mutations/delete-person, but the syntax quoting will fix it.
Also realize that the mutation is not running in the UI, it is instead being handled "behind the scenes". This
allows a snapshot of the state history to be kept, and also a more seamless integration to full-stack operation
over a network to a server (in fact, the UI code here is already full-stack capable without any changes!).
This is where the power starts to show: all of the minutiae above is leading us to some grand unifications when it comes to writing full-stack applications.
2.7.3. Hold on – This Sucks!
But first, we should address a problem that many of you may have already noticed: The mutation code is tied to the shape of the UI tree!!!
This breaks our lovely model in several ways:
-
We can’t refactor our UI without also rewriting the mutations (since the data tree would change shape)
-
We can’t locally reason about any data. Our mutations have to understand things globally!
-
Our mutations could get rather large and ugly as our UI gets big
-
If a fact appears in more than one place in the UI and data tree, then we’ll have to update all of them in order for things to be correct. Data duplication is never your friend.
2.8. The Secret Sauce – Normalizing the Database
Fortunately, we have a very good solution to the mutation problem above, and it is one that has been around for decades: database normalization!
Here’s what we’re going to do:
Each UI component represents some conceptual entity with data (assuming it has state and a query). In a fully normalized database, each such concept would have its own table, and related things would refer to it through some kind of foreign key. In SQL land this looks like:
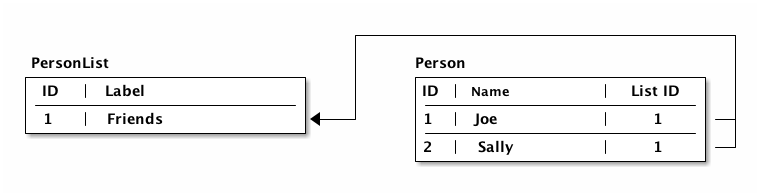
In a graph database (like Datomic) a reference can have a to-many arity, so the direction can be more natural:
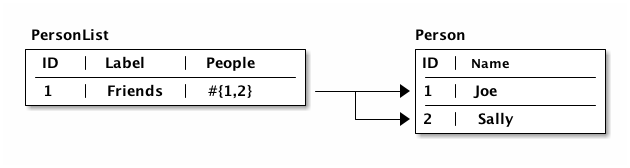
Since we’re storing things in a map, we can represent "tables" as an entry in the map where the key is the table name, and the value is a map from ID to entity value. So, the last diagram could be represented as:
{ :PersonList { 1 { :label "Friends"
:people #{1, 2} }}
:Person { 1 {:id 1 :name "Joe" }
2 {:id 2 :name "Sally"}}}This is close, but not quite good enough. The set in :person-list/people is a problem. There is no schema, so there is no
way to know what kind of thing "1" and "2" are!
The solution is rather easy: code the foreign reference to include the name of the table (is a single such "pointer", and to-many relations store many such "pointers" in a vector (so you end up with a doubly-nested vector)):
{ :PersonList { 1 { :label "Friends"
:people [ [:Person 1] [:Person 2] ] }}
:Person { 1 {:id 1 :name "Joe" }
2 {:id 2 :name "Sally"}}}A foreign key as a vector pair of [TABLE ID] is known as an Ident.
So, now that we have the concept and implementation, let’s talk about conventions:
-
Properties are usually namespaced (as shown in earlier examples)
-
Table names are usually namespaced with the entity type, and given a name that indicates how it is indexed. For example:
:person/by-id,:person-list/by-name, etc. If you use Clojure spec, you may choose to alter this a bit for convenience in namespace-aliasing keywords (e.g.::my-db-schema/person-by-id).
2.8.1. Automatic Normalization
Fortunately, you don’t have to hand-normalize your data. The components have almost everything they need to
do it for you, other than the actual value of the Ident. So, we’ll add one more option to your components
(and we’ll add IDs to the data at this point, for easier implementation):
The program will now look like this:
(ns app.ui.root
(:require
translations.es
[fulcro.client.dom :as dom]
[app.api.mutations :as api]
[fulcro.client.primitives :as prim :refer [defsc]]))
(defsc Person [this {:keys [db/id person/name person/age]} {:keys [onDelete]}]
{:query [:db/id :person/name :person/age] ; (2)
:ident [:person/by-id :db/id] ; (1)
:initial-state (fn [{:keys [id name age]}] {:db/id id :person/name name :person/age age})} ; (3)
(dom/li
(dom/h5 (str name " (age: " age ")") (dom/button {:onClick #(onDelete id)} "X")))) ; (4)
(def ui-person (prim/factory Person {:keyfn :person/name}))
(defsc PersonList [this {:keys [db/id person-list/label person-list/people]}]
{:query [:db/id :person-list/label {:person-list/people (prim/get-query Person)}]
:ident [:person-list/by-id :db/id] ; (5)
:initial-state
(fn [{:keys [id label]}]
{:db/id id
:person-list/label label
:person-list/people (if (= label "Friends")
[(prim/get-initial-state Person {:id 1 :name "Sally" :age 32})
(prim/get-initial-state Person {:id 2 :name "Joe" :age 22})]
[(prim/get-initial-state Person {:id 3 :name "Fred" :age 11})
(prim/get-initial-state Person {:id 4 :name "Bobby" :age 55})])})}
(let [delete-person (fn [person-id] (prim/transact! this `[(api/delete-person {:list-id ~id :person-id ~person-id})]))] ; (4)
(dom/div
(dom/h4 label)
(dom/ul
(map (fn [p] (ui-person (prim/computed p {:onDelete delete-person}))) people)))))
(def ui-person-list (prim/factory PersonList))
(defsc Root [this {:keys [ui/react-key friends enemies]}]
{:query [:ui/react-key {:friends (prim/get-query PersonList)}
{:enemies (prim/get-query PersonList)}]
:initial-state (fn [params] {:friends (prim/get-initial-state PersonList {:id :friends :label "Friends"})
:enemies (prim/get-initial-state PersonList {:id :enemies :label "Enemies"})})}
(dom/div
(ui-person-list friends)
(ui-person-list enemies)))-
Adding an ident allows Fulcro to know how to build a FK reference to a person (given its props). The first element is the table name, the second is the name of the property that contains the ID of the entity.
-
We will be using IDs now, so we need to add
:db/idto the query (and props destructuring). This is just a convention for the ID attribute -
The state of the entity will also need the ID
-
The callback can now delete people by their ID, which is more reliable.
-
The list will have an ID, and an Ident as well
If you reload the web page (needed to reinitialize the database state), then you can look at the newly normalized database at the REPL (NOTE: It is much easier to look at this using Fulcro Inspect in your developer tools tab):
dev:cljs.user=> @(fulcro.client.primitives/app-state (-> app.client/app deref :reconciler))
{:friends [:person-list/by-id :friends],
:enemies [:person-list/by-id :enemies],
:person/by-id
{1 {:db/id 1, :person/name "Sally", :person/age 32},
2 {:db/id 2, :person/name "Joe", :person/age 22},
3 {:db/id 3, :person/name "Fred", :person/age 11},
4 {:db/id 4, :person/name "Bobby", :person/age 55}},
:person-list/by-id
{:friends
{:db/id :friends,
:person-list/label "Friends",
:person-list/people [[:person/by-id 1] [:person/by-id 2]]},
:enemies
{:db/id :enemies,
:person-list/label "Enemies",
:person-list/people [[:person/by-id 3] [:person/by-id 4]]}}}Note that db→tree understands this normalized form, and can convert it (via a query)
to the proper data tree. db→tree (for legacy reasons) requires a way to resolve references (idents) and the
database. In Fulcro these are the same. So, try this at the REPL:
dev:cljs.user=> (def current-db @(fulcro.client.primitives/app-state (-> app.client/app deref :reconciler)))
dev:cljs.user=> (def root-query (fulcro.client.primitives/get-query app.ui.root/Root))
#'cljs.user/current-db
dev:cljs.user=> (fulcro.client.primitives/db->tree root-query current-db current-db)
{:friends
{:db/id :friends,
:person-list/label "Friends",
:person-list/people
[{:db/id 1, :person/name "Sally", :person/age 32}
{:db/id 2, :person/name "Joe", :person/age 22}]},
:enemies
{:db/id :enemies,
:person-list/label "Enemies",
:person-list/people
[{:db/id 3, :person/name "Fred", :person/age 11}
{:db/id 4, :person/name "Bobby", :person/age 55}]}}2.8.2. Mutations on a Normalized Database
We have now made it possible to fix the problems with our mutation. Now, instead of removing a person from a tree, we can remove a FK from a TABLE entry!
This is not only much easier to code, but it is completely independent of the shape of the UI tree:
(ns app.api.mutations
(:require [fulcro.client.mutations :as m :refer [defmutation]]))
(defmutation delete-person
"Mutation: Delete the person with name from the list with list-name"
[{:keys [list-id person-id]}]
(action [{:keys [state]}]
(let [ident-to-remove [:person/by-id person-id] ; (1)
strip-fk (fn [old-fks]
(vec (filter #(not= ident-to-remove %) old-fks)))] ; (2)
(swap! state update-in [:person-list/by-id list-id :person-list/people] strip-fk)))) ; (3)-
References are always idents, meaning we know the value to remove from the FK list
-
By defining a function that can filter the ident from (1), we can use update-in on the person list table’s people.
-
This is a very typical operation in a mutation: swap on the application state, and update a particular thing in a table (in this case the people to-many ref in a specific person list).
If we were to now wrap the person list in any amount of additional UI (e.g. a nav bar, sub-pane, modal dialog, etc) this mutation will still work perfectly, since the list itself will only have one place it ever lives in the database.
2.8.3. How Automatic Normalization Works (optional)
It is good to know how an arbitrary tree of data (the one in InitialAppState) can be converted to the normalized form. Understanding how this is accomplished can help you avoid some mistakes later.
When you compose your query (via prim/get-query), the get-query function adds metadata to the query fragment that
names which component that query fragment came from.
For example, try this at the REPL:
dev:cljs.user=> (meta (fulcro.client.primitives/get-query app.ui.root/PersonList))
{:component app.ui.root/PersonList}The get-query function adds the component itself to the metadata for that query fragment. We already know that
we can call the static methods on a component (in this case we’re interested in ident).
So, Fulcro includes a function called tree→db that can simultaneously walk a data tree (in this case initial-state) and a
component-annotated query. When it reaches a data node whose query metadata names a component with an Ident, it
places that data into the appropriate table (by calling your ident function on it to obtain the table/id), and
replaces the data in the tree with its FK ident.
Once you realize that the query and the ident work together to do normalization, you can more easily
figure out what mistakes you might make that could cause auto-normalization to fail (e.g. stealing a query from
one component and placing it on another, writing the query of a sub-component by-hand instead of pulling it
with get-query, etc.).
2.9. Review So Far
-
An Initial app state sets up a tree of data for startup to match the UI tree
-
Component query and ident are used to normalize this initial data into the database
-
The query is used to pull data from the normalized db into the props of the active Root UI
-
Transactions invoke abstract mutations
-
Mutations modify the (normalized) db
-
The transaction’s subtree of components re-renders
-
2.10. Using Better Tools
So far we’ve been hacking things in place and using the REPL to watch what we’re doing. There are better ways to work on Fulcro applications, and now that we’ve got one basically working, let’s take a look at them both.
2.10.1. Fulcro Inspect
We’ve mentioned this before, but now that you know about the centralized database, we want to mention it again: Use it! The DB tab of this tool shows you your application’s database and has a time slider to see the history of states. It also has tabs for showing you transactions that have run, and network interactions. See the tool’s documentation for more information. In fact, by the time you read this it will probably have even more features.
2.10.2. Workspaces
There is a build in the template project called workspaces. This starts up a development environment where you can
code components, full-stack elements, or even entire applications in a flexible environment.
Remember, we can actually split off chunks of the application because they are all fed data via a normalized database
and coupled only to their parent.
See the README of your template for instructions on using it.
2.11. Going Remote!
OK, back to the main story!
Believe it or not, there’s not much to add/change on the client to get it talking to a server, and there is also a relatively painless way to get a server up and running.
Of course, your template already has a server.
2.11.1. Setting up a Server
The template generates a pretty complete server that uses ring-defaults and has CSRF protection configured.
The code in the template is pretty well documented, and it is mostly standard Ring stuff. The main part
of interest is the wrap-api handler:
(def server-parser (server/fulcro-parser))
(defn wrap-api [handler uri]
(fn [request]
(if (= uri (:uri request))
(server/handle-api-request
;; Sub out a pathom parser here if you want to use pathom.
server-parser
;; this map is `env`. Put other defstate things in this map and they'll be
;; in the mutations/query env on server.
{:config config}
(:transit-params request))
(handler request))))This generates a Fulcro query/mutation parser and sets it up to be called on some uri (which the server sets to
/api).
Fulcro includes an EDN configuration file reader that allows for easy configuration of your server. It bases
all configs on config/defaults.edn, and deep merges a runtime-selected EDN file over that so that each developer,
test environment, or production system can make it’s own configuration changes.
Your template already has these in src/main/config. See your template content for their content.
The config/defaults.edn file is always looked for by the server (on CLASSPATH, so in your source or resources folder),
and should contain all of the default settings you think you want independent of where the server is started.
The server (for safety reasons in production) will not start if there isn’t also a user-specified file containing potential overrides.
Basically, it will deep-merge the two and have the latter override things in the former. This makes mistakes in
production harder to make. If you read the source of the config.clj file you’ll see that it defaults to development mode.
If you look in server_main.clj (the production main) you’ll see this is overridden.
You can also override this with the JVM option -Dconfig=path-to-file. If the path is relative, it will look for it
in application resources. If it is absolute, it will look for it on the disk:
java -Dconfig=/usr/local/etc/app.edn -jar app.jarThis command-line option overrides any config file that was specified in the application itself (except for defaults.edn,
which is always the base).
Starting the Server
If you now start a local Clojure REPL (with no special options), it should start in the user namespace.
You can kick off your own application’s easy web server with:
user=> (start)The console should tell you the URL, and if you browse there you should see your index.html file.
Server Refresh
When you add/change code on the server you will want to see those changes in the live server without having to restart your REPL.
user=> (restart)will do this.
If there are compiler errors, then the user namespace might not reload properly. In that case, you should be able
to recover using:
user=> (tools-ns/refresh)
user=> (start)|
Warning
|
Don’t call refresh while the server is running. It will refresh the code, but it will lose the reference to the running server, meaning you won’t be able to stop it and free up the network port. If you do this, you’ll have to restart your REPL. |
|
Warning
|
If you’ve built an AOT compiled uberjar, then you might end up with classes loaded into your VM, and hot
code reload on the server can then fail for very strange reasons. Clear your target folder if you’re seeing
mysterious behavior.
|
2.11.2. Loading Data
Now we will start to see more of the payoff of our UI co-located queries and auto-normalization. Our application so far is quite unrealistic: the people we’re showing should be coming from a server-side database, they should not be embedded in the code of the client. Let’s remedy that.
Fulcro provides a few mechanisms for loading data, but every possible load scenario can be done using
the fulcro.client.data-fetch/load function.
It is very important to remember that our application database is completely normalized, so anything we’d want to put in that application state will be at most 3 levels deep (the table name, the ID of the thing in the table, and the field within that thing). We’ve also seen that Fulcro can also auto-normalize complete trees of data, and has graph queries that can be used to ask for those trees.
Thus, there really are not very many scenarios!
The three basic scenarios are:
-
Load something into the root of the application state
-
Load something into a particular field of an existing thing
-
Load some pile of data, and shape it into the database (e.g. load all of the people, and then separate them into a list of friends and enemies).
Let’s try out these different scenarios with our application.
First, let’s correct our application’s initial state so that no people are there:
(defsc PersonList [this {:keys [db/id person-list/label person-list/people]}]
{:query [:db/id :person-list/label {:person-list/people (prim/get-query Person)}]
:ident [:person-list/by-id :db/id]
:initial-state
(fn [{:keys [id label]}]
{:db/id id
:person-list/label label
:person-list/people []})} ; REMOVE THE INITIAL PEOPLE
...If you now reload your page you should see two empty lists.
Normalization
When you load something you will use a query from something on your UI (it is rare to load something you don’t want to show). Since those components (should) have a query and ident, the result of a load can be sent from the server as a tree, and the client can auto-normalize that tree just like it did for our initial state!
Loading something into the DB root
This case is less common, but it is a simple starting point. It is typically used to obtain something that you’d want
to access globally (e.g. the user info about the current session). Let’s assume that our Person component represents
the same kind of data as the "logged in" user. Let’s write a load that can ask the server for the "current user" and
store that in the root of our database under the key :current-user.
Loads, of course, can be triggered at any time (startup, event, timeout). Loading is just a function call.
For this example, let’s trigger the load just after the application has started.
Triggering the Load
To do this, we can add an option to our client. In app.client change app:
(ns app.client
(:require [fulcro.client :as fc]
[fulcro.client.data-fetch :as df] ; (1)
[app.ui.root :as root]))
...
(fc/make-fulcro-client
{:client-did-mount
(fn [app] ; (2)
(df/load app :current-user root/Person))})
...-
Require the
data-fetchnamespace -
Issue the load in the application’s
client-did-mount
|
Note
|
If you are using workspaces you will need to place the option for the application under a special app key: |
(ns myapp.workspaces.fulcro-demo-cards
(:require [fulcro.client.primitives :as fp]
[fulcro.client.localized-dom :as dom]
[nubank.workspaces.core :as ws]
[nubank.workspaces.card-types.fulcro :as ct.fulcro]
[nubank.workspaces.lib.fulcro-portal :as f.portal]))
...
(ws/defcard fulcro-demo-card
(ct.fulcro/fulcro-card
{::f.portal/root FulcroDemo
::f.portal/wrap-root? true ; generates a root. Useful for embedding normalized components with a placeholder root.
::f.portal/app {:client-did-mount (fn [app] ...)}}))|
Note
|
Prior to Fulcro 2.8.1 the client was created with new-fulcro-client which had a :started-callback option.
The old method is still available (and unchanged). The new make-fulcro-client method changes some defaults,
and renames started-callback to client-did-mount.
|
Of course hot code reload does not restart the app (it just hot patches the code), so to see this load trigger we must reload the browser page.
If you do that at the moment, you should see an error in the various consoles related to the failure of the load.
|
Important
|
Make sure any card is running from your server (port 3000), and not the workspaces dev server. |
Technically, load is just writing a query for you (in this case [{:current-user (prim/get-query Person)}]) and sending it to the
server. The server will receive exactly that query as a CLJ data structure.
Implementing the Server Handler
You now need to convert the raw CLJ query into a response. You can read more about the gory details of that in the developer’s guide; however, Fulcro’s has some helpers that make our job much easier.
You’ll need to put your read handling code somewhere. For example you could create
src/main/app/api/read.clj.
Since we’re on the server and we’re going to be supplying and manipulating people, we’ll just make a single atom-based
in-memory database. This could easily be stored in a database of any kind.
To handle the incoming "current user" request, we can use a macro to write the handler for us.
Something like this:
(ns app.api.read
(:require
[fulcro.server :refer [defquery-root defquery-entity defmutation]]))
(def people-db (atom {1 {:db/id 1 :person/name "Bert" :person/age 55 :person/relation :friend}
2 {:db/id 2 :person/name "Sally" :person/age 22 :person/relation :friend}
3 {:db/id 3 :person/name "Allie" :person/age 76 :person/relation :enemy}
4 {:db/id 4 :person/name "Zoe" :person/age 32 :person/relation :friend}
99 {:db/id 99 :person/name "Me" :person/role "admin"}}))
(defquery-root :current-user
"Queries for the current user and returns it to the client"
(value [env params]
(get @people-db 99)))This macro actually augments a multimethod, which means we need to make sure this namespace is loaded by our server, so edit one of your components (like the middleware.clj) and require it there.
Now you should be able to restart/refresh the server at the SERVER REPL:
user=> (restart)If you’ve done everything correctly, then reloading your application should successfully load your current user. You can verify this by examining the network data, but it will be even more convincing if you look at your client database via the dev card visualization on Fulcro Inspect. It should look something like this:
{:current-user [:person/by-id 99]
:person/by-id {99 {:db/id 99 :person/name "Me" :person/role "admin"}}
...}Notice that the top-level key is a normalized FK reference to the person, which has been placed into the correct database table.
|
Note
|
The defquery macros make it easy to get started, but we recommend migrating away from them to
Pathom as soon as you have the basic hang of Fulcro. The Pathom library provides a much more powerful GraphQL-like
experience for writing your Fulcro server. You can also use Pathom to create a GraphQL client remote that can interface
between a Fulcro front-end and regular GraphQL servers. The Fulcro template can easily be modified to use Pathom by
substituting a Pathom parser in middleware.clj (search for fulcro-parser).
|
Using Data from Root
Of course, the question is now "how do I use that in some arbitrary component?" We won’t completely
explore that right now, but the answer is easy: The query syntax has a notation for "query something at the root". It looks like this:
[ {[:current-user '_] (prim/get-query Person)} ]. You should recognize this as a query join, but on something that
looks like an ident without an ID (implying there is only one, at root).
We’ll just use it on the Root UI node, where we don’t need to "jump to the top":
(defsc Root [this {:keys [ui/react-key friends enemies current-user]}] ; (2)
{:query [:ui/react-key
{:current-user (prim/get-query Person)} ; (1)
{:friends (prim/get-query PersonList)}
{:enemies (prim/get-query PersonList)}]
:initial-state (fn [params] {:friends (prim/get-initial-state PersonList {:id :friends :label "Friends"})
:enemies (prim/get-initial-state PersonList {:id :enemies :label "Enemies"})})}
(dom/div
(dom/h4 (str "Current User: " (:person/name current-user))) ; (3)
(ui-person-list friends)
(ui-person-list enemies)))-
Add the current user to the query
-
Pull of from the props
-
Show something about it in the UI
Loading something that gets "added in" to an existing entity
The next common scenario is loading something into some other existing entity in your database. Remember that since the database is normalized this will cover all of the other loading cases (except for the one where you want to convert what the server tells you into a different shape (e.g. paginate, sort, etc.)).
Fulcro’s load method accomplishes this by loading the data into the root of the database, normalizing it, then (optionally) allowing you to re-target the top-level FK to different location(s) in the database.
Targeting the Load
The load looks very much like what we just did, but with one addition:
(df/load app :my-friends Person {:target [:person-list/by-id :friends :person-list/people]})The :target option indicates that once the data is loaded and normalized (which will leave the FK reference
at the root as we saw in the last section) this top-level reference (or vector of references) will be moved into the key-path provided.
Since our database is normalized, this means a 3-tuple (table, id, target field).
|
Warning
|
It is important to choose a keyword for this load that won’t stomp on real data in your database’s root.
We already have the top-level keys :friends and :enemies as part of our UI graph from root. So, we’re making up
:my-friends as the load key. One could also namespace the keyword with something like :server/friends.
|
Since friend and enemies are the same kind of query, let’s add both into the startup code (in the card/client):
...
:client-did-mount
(fn [app]
(df/load app :current-user root/Person)
(df/load app :my-enemies root/Person {:target [:person-list/by-id :enemies :person-list/people]})
(df/load app :my-friends root/Person {:target [:person-list/by-id :friends :person-list/people]}))
...Handling the Load Request on the Server
The server query processing is what you would expect from the last example (in read.clj):
(def people-db ...) ; as before
(defn get-people [kind keys]
(->> @people-db
vals
(filter #(= kind (:person/relation %)))
vec))
(defquery-root :my-friends
"Queries for friends and returns them to the client"
(value [{:keys [query]} params]
(get-people :friend query)))
(defquery-root :my-enemies
"Queries for enemies and returns them to the client"
(value [{:keys [query]} params]
(get-people :enemy query)))A refresh of the server and reload of the page should now populate your lists from the server!
user=> (restart)Morphing the Loaded Data
It is somewhat common for a server to return data that isn’t quite what we want in our UI. So far we’ve just been placing the data returned from the server directly in our UI. Fulcro’s load mechanism allows a post mutation of the loaded data once it arrives, allowing you to re-shape it into whatever form you might desire.
For example, you may want the people in your lists to be sorted by name. You’ve already seen how to write client
mutations that modify the database, and that is really all you need. The client mutation for sorting the people
in the friends list could be (in mutations.cljs):
(defn sort-friends-by*
"Sort the idents in the friends person list by the indicated field. Returns the new app-state."
[state-map field]
(let [friend-idents (get-in state-map [:person-list/by-id :friends :person-list/people] [])
friends (map (fn [friend-ident] (get-in state-map friend-ident)) friend-idents)
sorted-friends (sort-by field friends)
new-idents (mapv (fn [friend] [:person/by-id (:db/id friend)]) sorted-friends)]
(assoc-in state-map [:person-list/by-id :friends :person-list/people] new-idents)))
(defmutation sort-friends [no-params]
(action [{:keys [state]}]
(swap! state sort-friends-by* :person/name)))|
Note
|
When building larger applications we’ve often found it useful to put the client mutations in one
topically-named file (e.g. person.cljs) and the server mutations right next to it in (e.g. person.clj). This makes
code navigation very easy.
|
Of course this mutation could be triggered anywhere you could run a transact!, but since we’re interested in morphing
just-loaded data, we’ll add it there. Our dev card would now look like this:
(ns app.intro
(:require [fulcro.client.cards :refer [defcard-fulcro]]
[app.ui.root :as root]
[fulcro.client.data-fetch :as df]
[app.api.mutations :as api]))
(defcard-fulcro sample-app
root/Root
{}
{:inspect-data true
:fulcro {:client-did-mount
(fn [app] (df/load app :current-user root/Person)
(df/load app :my-friends root/Person {:target [:person-list/by-id :friends :person-list/people]
:post-mutation `api/sort-friends})
(df/load app :my-enemies root/Person {:target [:person-list/by-id :enemies :person-list/people]}))}})Notice the syntax quoting. The post mutation has to be the symbol of the mutation. Remember that
our require has app.api.mutations aliased to api, and syntax quoting will expand that for us.
If you reload your UI you should now see the people sorted by name. Hopefully you can see how easy it is to change this sort order to something like "by age". Try it!
Loading a specific entity and its subgraph (by ident)
Once things are loaded from the server they are immediately growing stale (unless you’re pushing updates with websockets). It is very common to want to re-load a particular thing in your database. Of course, you can trigger a load just like we’ve been doing, but in that case we would be reloading a whole bunch of things. What if we just wanted to refresh a particular person (e.g. in preparation for editing it).
The load function can be used for that as well. Just replace the keyword with an ident, and you’re there!
Load can take the app or any component’s this as the first argument, so from within the UI we can trigger a load
using this:
(df/load this [:person/by-id 3] Person)Trigger the Load via a User Event
Let’s embed that into our UI at the root:
(defsc Root [this {:keys [ui/react-key friends enemies current-user]}]
{:query [:ui/react-key
{:current-user (prim/get-query Person)}
{:friends (prim/get-query PersonList)}
{:enemies (prim/get-query PersonList)}]
:initial-state (fn [params] {:friends (prim/get-initial-state PersonList {:id :friends :label "Friends"})
:enemies (prim/get-initial-state PersonList {:id :enemies :label "Enemies"})})}
(dom/div
(dom/h4 (str "Current User: " (:person/name current-user)))
; NEW BUTTON HERE:
(dom/button {:onClick (fn [] (df/load this [:person/by-id 3] Person))} "Refresh Person with ID 3")
(ui-person-list friends)
(ui-person-list enemies)))Handling an Entity Query on the Server
|
Note
|
The defquery* macros are meant as a quick entry point. Once inside you’ll have access to the subquery in
the env as :query. It is highly recommended that you use pathom to further
process queries. Specifically, we recommend using the "Connect" functionality of Pathom.
|
The incoming query will have a slightly different form, so there is an alternate macro for making a handler for entity
loading. Let’s add this in our server’s read.clj:
(defquery-entity :person/by-id
"Server query for allowing the client to pull an individual person from the database"
(value [env id params]
; the update is just so we can see it change in the UI
(update (get @people-db id) :person/name str " (refreshed)")))The defquery-entity takes the "table name" as the dispatch key. The value method of the query handler will receive
the server environment, the ID of the entity to load, and any parameters passed with the query (see the :params option
of load).
In the implementation above we’re augmenting the person’s name with "(refreshed)" so that you can see it happen in the UI.
Remember to (restart) your server to load this code.
Your UI should now have a button, and when you press it you should see one person update!
Refreshing "This"
There is a special case that is somewhat common: you want to trigger a refresh from an event on the item that needs
the refresh. The code for that is identical to what we’ve just presented (a load with an ident and component); however,
the data-fetch namespace includes a convenience function for it.
So, say we wanted a refresh button on each person. We could leverage df/refresh for that:
(defsc Person [this {:keys [db/id person/name person/age]} {:keys [onDelete]}]
{:query [:db/id :person/name :person/age]
:ident [:person/by-id :db/id]
:initial-state (fn [{:keys [id name age]}] {:db/id id :person/name name :person/age age})}
(dom/li
(dom/h5 (str name " (age: " age ")")
(dom/button {:onClick #(onDelete id)} "X")
(dom/button {:onClick #(df/refresh! this)} "Refresh")))) ; ADD THISThis should already work with your server, so once the browser hot code reload has happened this button should just work!
Additional Permutations
Fulcro’s load system covers a number of additional bases that bring the story to completion. There are load markers (so you can show network activity), UI refresh add-ons (when you modify data that isn’t auto-detected, e.g. through a post mutation), server query parameters, and error handling. See the Developers Guide, doc strings, or source for more details.
2.11.3. Handling Mutations on The Server
Mutations are handled on the server using the server’s defmutation macro (if you’re using Fulcro’s built-in request parser).
This has the identical syntax to the client version!
|
Important
|
You want to place your mutations in the same namespace on the client and server since the defmutation
macros namespace the symbol into the current namespace. So, this is really why we have a duplicated namespace in
Clojure called mutations.clj right next to our mutations.cljs. The defmutation macro will accept a fully-qualified
symbol as well, but that becomes painful for code navigation. If many of your mutations are full-stack, you might
even consider using cljc files and placing the server/client mutations in the same exact code block.
|
So, let’s add an implementation for our server-side delete-person. Your mutations.clj should end
up looking like this (don’t forget the require to get access to the people db):
(ns app.api.mutations
(:require
[taoensso.timbre :as timbre]
[app.api.read :refer [people-db]]
[fulcro.server :refer [defmutation]]))
;; Place your server mutations here
(defmutation delete-person
"Server Mutation: Handles deleting a person on the server"
[{:keys [person-id]}]
(action [{:keys [state]}]
(timbre/info "Server deleting person" person-id)
(swap! people-db dissoc person-id)))Refresh the code on your server with (restart) at the REPL. However, don’t expect it to work just yet. We have
to tell the client to send the remote request.
Triggering the Remote Mutation from the Client
Mutations are simply optimistic local updates by default. To make them full-stack, you need to add a method-looking
section to your defmutation handler:
(defmutation delete-person
"Mutation: Delete the person with person-id from the list with list-id"
[{:keys [list-id person-id]}]
(action [{:keys [state]}]
(let [ident-to-remove [:person/by-id person-id]
strip-fk (fn [old-fks]
(vec (filter #(not= ident-to-remove %) old-fks)))]
(swap! state update-in [:person-list/by-id list-id :person-list/people] strip-fk)))
(remote [env] true)) ; This one line is it!!!The syntax for the addition is:
(remote-name [env] boolean-or-ast)where remote is the name of a remote server (the default is remote). You can have any number of network remotes.
The default one talks to the
page origin at /api. What is this AST we speak of? It is the abstract syntax tree of the mutation itself (as data).
Using a boolean true means "send it just as the client specified". If you wish you can pull the AST from the env,
augment it (or completely change it) and return that instead. See the Developers Guide for more details.
Now that you’ve got the UI in place, try deleting a person. It should disappear from the UI as it did before; however, now if you’re watching the network you’ll see a request to the server. If you server is working right, it will handle the delete.
Try reloading your page from the server. That person should still be missing, indicating that it really was removed from the server.
Now that you’ve gotten an overview and have written some code, you can read through the remaining chapters for more detail on each topic.
3. Core Concepts
This chapter covers some detail about the core language features and theory that are important in the Fulcro ecosystem. You need not read this chapter to use Fulcro, but it will aid in your understanding of it quite a bit, especially if you’re relatively new to Clojurescript.
3.1. Immutable Data Structures
Many of the most interesting and compelling features of Fulcro are directly or indirectly enabled (or made simpler) by the use of persistent data structures that are a first-class citizen of the language.
In imperative programming languages like Java and Javascript you have no idea what a function or method might do to your program state:
Person p = new Person();
doSomethingOnAnotherThread(p);
p.fumble();
// did p just change??? Did I just cause a race condition???This leads to all sorts of subtle bugs and is arguably the source of many of
the hardest problems in keeping software sustainable today. What if Person couldn’t
change and you instead had to copy instead if you wanted to modify?
Person p = new Person();
doSomethingOnAnotherThread(p);
Person q = p.fumble();
// p is definitely unchanged, but q could be differentNow you can reason about what will happen. The other thread will see p exactly as
it was when you (locally) reasoned about it. Furthermore, q cannot be affected
because if p is truly "read-only" then I still know what it is when I use it to
derive q (the other thread can’t modify it either).
In order to derive these benefits you need to either write objects that enforce this behavior (which is highly inconvenient and hard to make efficient in imperative langauges), or use a programming language that supplies the ability to do so as a first-class feature.
Another benefit is that persistent data structures can do structural sharing. Basically the new version of a map, vector, list, or set can use references to point to any parts of the old version that are still the same in the new version. This means, for example, that adding an element to the head of a list that had 1,000,000 entries (where only one is being changed) is still a constant time operation!
Here are some of the features in Fulcro that trivially result from using persistent data structures:
-
A Time-travel UI history viewer that consumes little space.
-
Extremely efficient detection of data changes that affect the UI (can be ref compare instead of data compare)
-
"Pure Rendering" is possible and convenient without having to resort to hidden variables in the UI.
3.2. Pure Rendering
Fulcro uses Facebook’s React to accomplish updates to the browser DOM. React, in concept, is really simple:
Render is a function you make that generates a data structure known as the VDOM (a lightweight virtual DOM)
-
On The first "frame", the real DOM is made to match this data structure.
-
On every subsequent frame, render is used to make a new VDOM. React compares the prior VDOM (which is cached) to the new one, and then applies the changes to the DOM.
The cool realization the creators of React had was that the DOM operations that are slow and heavy, but there are efficient ways to figure out what needs to be changed via the VDOM without you having to write a bunch of controller logic.
Now, because React lives in a mutable space (Javascript), it allows all sorts of things that can embed "rendering logic" within a component. This sounds like a good idea to our OOP brains, but consider this:
What if you could have a complete snapshot of the state of your application, pass that to a function, and have the screen just "look right". Like writing a 2D game: you just redraw the screen based on the new "state of the world". All of the sudden your mind shifts away from "bit twiddling" to thinking more about the representation of your model with minimal data!
That is what we mean by "pure rendering".
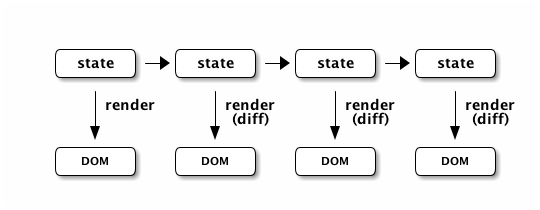
Here’s an example to whet your appetite: Nested check-boxes. In imperative programming each checkbox has its own state, and when we want a "check all" we end up writing nightmares of logic to make sure the thing works right because we’re having to store a mutable value into an object that then does the rendering. Then we play with it and find out we forgot to handle that event where some sub-box gets unchecked to fire an event to ensure to uncheck the "select all"…oh wait, but when I do that it accidentally fires the event from "check all" which unchecks everything and then goes into an infinite loop!
What a mess! Maybe you eventually figure out something that’s tractable, but that extra bit of state in the "check all" is definitely the source of bugs.
Here’s what you do in pure rendering with immutable data:
Each sub-item checkbox is a simple data structure with a :checked? key that has a boolean
value. You use that to directly tell the checkbox what its state should be
(and React enforces that…making it impossible for the UI to draw it any
differently)
(def state {:items [{:id :a :checked? true} {:id :b :checked? false} ...]})For a "state of the world", these are read-only. (you have to make a "new
state of the world" to change one). When you render, the state of the
check-all is just the conjunction of its children’s :checked?:
(let [all-checked (every? :checked? (get state :items)]
(dom/input {:checked all-checked}))The check-all button would have no application state at all, and React will force it to the correct state based on the calculated value. When the sub-items change, a new "state of the world" is generated with the altered item:
(def next-state (assoc-in state [:items 0 :checked?] false))and the entire UI is re-rendered (React makes this fast using the VDOM diff), the "check all" checkbox will just be right!
If the "check all" button is pressed, then the logic is similarly very simple: change the state for the subitems to checked if any were unchecked, or set them all to unchecked if they were all checked:
(def next-state-2
(let [all-checked? (every? :checked? (get state :items))
c (not all-checked?)
old-items (get state :items)
new-items (mapv #(assoc % :checked? c) old-items)]
(assoc state :items new-items)))and again you get to pretend you’re rendering an entire new frame on the screen!
You’ll be continually surprised at how simple your logic gets in the UI once you adjust to this way of thinking about the problem.
3.3. Data-Driven
Data-driven concepts were pioneered in web development by Facebook’s GraphQL and Netflix’s Falcor. The idea is quite powerful, and eliminates huge amounts of complexity in your network communication and application development.
The basic idea is this: Your UI, which might have various versions (mobile, web, tablet) all have different, but related, data needs. The prevalent way of talking to our servers is to use REST, but REST itself isn’t a very good query 'or' update language. It creates a lot of complexity that we have to deal with in order to do the simplest things. In the small, it is "easy". In the large, it isn’t the best fit.
Data-driven applications basically use a more detailed protocol that allows the client UIs to specify what they need, and also typically includes a "mutation on the wire" notation that allows the client to abstractly say what it needs the server to do.
So, instead of /person/3 you can instead say "I need person 3, but only their
name, age, and billing info. But in the billing info, I only need to know their
billing zip code".
Notice that this abstract expression (which of course has a syntax we’re not showing you yet) is "walking a graph". This is why Facebook calls their language "GraphQL".
You can imagine that the person and billing info might be stored in two tables of a database, with a to-one relationship, and our query is basically asking to query this little sub-graph:

Modifications are done in a similar, abstract way. We model them as if they were "function calls on the wire". Like RPC/RMI:
'(change-person {:id 3 :age 44})but instead of actually 'calling' the function, we encode this list as a data structure (it is a list containing a symbol and a map: the power of Clojure!) and then process that data locally (in the back-end of the UI) and optionally also transmit it 'as data' over the wire for server processing!
3.4. Graph Database
The client-side of Fulcro keeps all relevant data in a simple graph database, which is referenced by a single top-level atom. The database itself is a persistent map.
The database should be thought of as a root-level node (the top-level map itsef), and tables that can hold data relevant to any particular component or entity in your program (component or entity nodes).
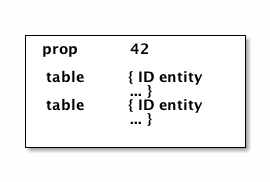
The tables are also simple maps, with a naming convention and well-defined structure. The name of the table is typically namespaced with the "kind" of thing you’re storing, and has a name that indicates the way it is indexed:
{ :person/by-id { 4 { :id 4 :person/name "Joe" }}}
; ^ ^ ^ ^
; kind indexed id entity value itself3.4.1. Idents
Items are joined together into a graph using a tuple of the table name and the key of
an entity. For example, the item above is known as [:person/by-id 4]. Notice that this
tuple is also exactly the vector you’d need in an operation that would pull data from that
entity or modify it:
(update-in state-db [:person/by-id 4] assoc :person/age 33)
(get-in state-db [:person/by-id 4])These tuples are known as 'idents'. Idents can be used anywhere one node in the graph needs to point to another. If the idents (which are vectors) 'appear' in a vector, then you are creating a 'to-many' relation:
{ :person/by-id
{ 1 {:id 1 :person/name "Joe"
:person/spouse [:person/by-id 2] ; (1)
:person/children [ [:person/by-id 3]
[:person/by-id 4] ] } ; (2)
2 { :id 2 :person/name "Julie"
:person/spouse [:person/by-id 1]} ; (3)
3 { :id 3 :person/name "Billy" }
4 { :id 4 :person/name "Heather"}}-
A to-one relation to Joe’s spouse (Julie)
-
A to-many relation to Joe’s kids
-
A to-relation back to Joe from Julie
Notice in the example above that Joe and Julie point at each other. This creates a 'loop' in the graph. This is perfectly legal. Graphs can contain loops. The table in the example contains 4 nodes.
The client database treats the 'root' node as a special set of non-table properties in the top of the database map. Thus, an entire state database with 'root node' properties might look like this:
The above data structure is now a graph database that looks like this:
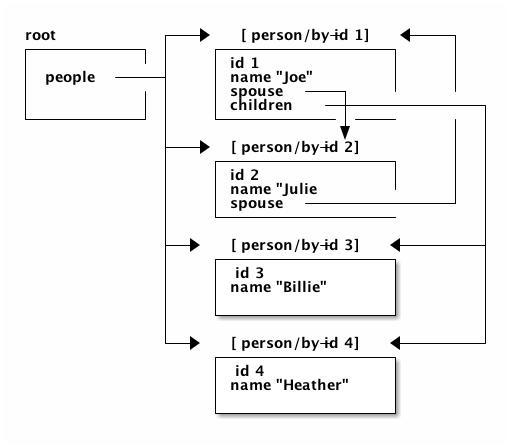
This makes for a very compact representation of a graph with an arbitrary number of nodes and edges. All nodes but the special "root node" live in tables. The root node itself is special because it is the storage location for both root properties and for the tables themselves.
|
Important
|
Since the root node and the tables containing other nodes are merged together into the same overall map it is important that you use care when storing things so as not to accidentally collide on a name. Larger programs should namespace all keywords. |
3.4.2. A Special Note about The Client-Side Database
The graph database on the client is the most central and key concept to understand in Fulcro. Remember that we are doing pure rendering. This means that the UI is simply a function transforming this graph database into the UI.
There are two primary things to write in Fulcro: the UI and the mutations. The UI pulls data from this database and displays it. The mutations evolve this database to a new version. Every interaction that changes the UI should be thought of as a data manipulation. You’re making a new state of the world that your pure renderer turns into DOM.
The graph format of the database means that your data manipulation, the main dynamic thing in the entire application, is simplified down to updating properties/nodes, which themselves live at the top of the state atom or are only 2-3 levels deep:
; change the root list of people, and modify the name and age of person 2
(swap! state (fn [s]
(-> s
(assoc :people [[:people/by-id 1] [:people/by-id 2]])
(assoc-in [:people/by-id 2 :person/name] "George")
(assoc-in [:people/by-id 2 :person/age] 33))))For the most part the UI takes care of itself. Clojure has very good functions for manipulating maps and vectors, so even when your data structures get more complex the task is still about as simple as it can be.
3.4.3. Client Database Naming Conventions
To avoid collisions in your database, the following naming conventions are recommended for use in the Fulcro client-side graph database:
| UI-only Properties |
|
| Tables |
|
| Root properties |
|
| Targeted Loads |
Loads temporarily place their results in root. Targeting relocates them. If you’ve followed the other naming conventions, then these can elide a namespace if that facilitates server interactions. |
| Node properties |
|
4. Component Rendering
4.1. HTML5 Element Factories
The core HTML5 elements all have simple factory functions that generate the core elements that stand-in for the real DOM. These stand-ins (commonly referred to as the virtual DOM or VDOM) are ultimately what React uses to generate, diff, and update the real DOM.
So, there are functions for every possible HTML5 element. These are in the
fulcro.client.dom namespace.
(ns app.ui
(:require [fulcro.client.dom :as dom]))
...
(dom/div :.some-class
(dom/ul {:style {:color :red}}
(dom/li ...)))|
Important
|
If you’re writing your UI in CLJC files then you need to make sure you use a conditional
reader to pull in the proper server DOM functions for Clojure:
(ns app.ui (:require #?(:clj [fulcro.client.dom-server :as dom] :cljs [fulcro.client.dom :as dom]))
|
The notation allowed is as follows:
(dom/div "Hello") ; no props
(dom/div nil "Hello") ; nil props (may perform slightly better)
(dom/div #js {:data-x 1} ...) ; js objects are allowed
(dom/div :.cls.cls2#id ...) ; shorthand for specifying static classes and ID
(dom/div :.cls {:data-x 2} "Ho") ; shorthand + propsThere is also a :classes property that can be used to add (typically via expressions) additional
classes. It drops nil, and allows classname keywords and strings as well:
(dom/div :.a {:className "other" :classes [(when hidden "hidden") (if tall :.tall :.short)]} ...)Assuming hidden and (not tall) would yield classes "a other hidden short" on output. Of course you probably don’t need
all of these at once, but supporting them all lets you programmatically combine them when generating props. NOTE: This feature
does not work on props sent with #js notation.
Remember that this (nested) call of functions results in a representation (VDOM) of what you’d like to end up on the screen.
The next level of abstraction is simply a function. Combining more complex bits of UI into a function is a great way to group re-usable nested DOM:
(defn my-header []
(dom/div :.some-class
(dom/ul
(dom/li ...))))4.1.1. Fulcro and React DOM – Notes
Here are some common things you’ll want to know how to do that are different when rendering with Fulcro:
-
dom/pis a function for generating p tags for use in React components. There is one of these for every legal HTML tag.-
Attributes follow the react naming conventions for [Tags and Attributes](https://facebook.github.io/react/docs/tags-and-attributes.html)
-
-
As an example - CSS class names are specified with
:classNameinstead of:class.-
Any time a VDOM includes a collection of elements they should each have a unique
:keyattribute. This helps the React diff figure out how that collection has changed. You will get warnings in the browser console if you fail to do so.
-
4.2. The Reconciler
When you start a Fulcro application your :client-did-mount will get the completed app as a parameter.
|
Note
|
Prior to Fulcro 2.8.1 the client was created with new-fulcro-client which had a :started-callback option.
The old method is still available (and unchanged). The new make-fulcro-client method changes some defaults,
and renames started-callback to client-did-mount.
|
Inside of this app is a reconciler under the key :reconciler. The reconciler is a central component in the system
that is responsible reconciling the differences between the database and the UI. Therefore it
is involved in processing the queries, merging novel data into the database, network interactions, and tracking
mounted components that might need refresh.
You will see it mentioned in many places in this book, and we’ll point out where you’ll use it directly.
4.2.1. Useful Reconciler Options
When you create a new client you can pass options directly to the reconciler with :reconciler-options.
There are a number of options that are used internally by the higher-level layers of Fulcro and should not
really be used directly, but there are a number of options that can be quite useful.
:shared
|
A map of global (immutable) properties that will be visible to all components. See Shared State. |
:shared-fn
|
A function to compute shared properties from the root props on UI refresh. only recomputed on
root-level refresh, such as a call to |
:root-render
|
The root render function. Defaults to ReactDOM.render. Useful for switching to React Native. |
:root-unmount
|
The root unmount function. Defaults to ReactDOM.unmountComponentAtNode. Useful for React Native. |
:render-mode
|
One of |
:lifecycle
|
A function (fn [component event]) that is called when react components either :mount or :unmount. Useful for debugging tools. |
:tx-listen
|
A function of 2 arguments that will listen to transactions. Called when |
:instrument
|
A function that will wrap all rendering. |
4.2.2. Rendering Optimizations
The reconciler does a number of things to optimize rendering beyond the basics of React.
-
Fulcro provides a built-in
shouldComponentUpdatethat uses a comparison of the prior props to tell React to skip no-op updates that would lead to a useless VDOM diff. -
When more than one component needs a refresh Fulcro analyzes the tree and only renders the parent of common children to to prevent multiple-rendering of children.
-
If a component is the target of a refresh and has an ident then Fulcro will run the query for just that component, avoiding quite a bit of database processing. This is the biggest performance win in "flame graph" tests.
-
NOTE: a component without an ident will always trigger a root query/refresh, since there is no way to figure out how to run that component’s query (queries are relative, and idents give you an anchor point for them).
-
The shouldComponentUpdate optimization reduces the render load by quite a bit, but running the query from root can
be somewhat costly depending on how well you optimized your UI query. Thus, idents become a major
factor in both normalization and rendering performance since Fulcro relies on them in order to reduce
the query overhead of UI refresh. This isn’t something you typically need to remember, since you should be using
idents on all components so they are easier to refactor and reuse.
4.2.3. Rendering Modes
Version 2.1+ of Fulcro include the ability to tell the reconciler which rendering mode to use.
:normal-
The default mode. Uses all possible optimizations.
:keyframe-
Disables the ident-based targeted refresh. Thus every render is considered a key frame of the DOM. This means that every transaction/change will run the root UI query and render from root. The
shouldComponentUpdateoptimization is in force and prevents quite a bit of work from React. This mode can be plenty fast and has the advantage of not needing you to program with follow-on reads. :brutal-
Disables all optimizations, runs queries from root, runs refresh from root, and forces React to do a full DOM diff. Primarily useful to compare how much benefit optimizations are actually giving you beyond React’s DOM diff.
4.3. The defsc Macro
|
Note
|
If you’re new to Fulcro and started with version 2.0, you can safely ignore most comments about defui. The two
are rougly equivalent, with defsc being the newer.
|
Fulcro’s defsc is a front-end to the legacy defui macro. It is sanity-checked for the most common elements: ident (optional), query, render, and initial state (optional). The sanity checking prevents a lot of the most common errors when writing a component, and the concise syntax reduces boilerplate to the essential novelty. The name means "define stateful component" and is intended to be used with components that have queries (though that is not a requirement).
4.3.1. The Argument List
The primary argument list contains the common elements you might need to use in the body:
(defsc [this props <optional-computed> <optional-css-map-if-using-css>]
{ ...options... }
(dom/div {:onClick (:onClick computed)} (:db/id props)))The last parameter will let you destructure fulcro-css names, if and only if you’re using the Fulcro CSS library.
Only the first two parameters are required, so you can even write:
(defsc [this props]
{ ...options... }
(dom/div (:db/id props)))Argument Destructuring
The parameter list fully supports Clojure destructuring on the props, computed, and css-name-map without having to write a separate let:
(defsc DestructuredExample [this
{:keys [db/id] :as props}
{:keys [onClick] :as computed :or {onClick identity}}
{:keys [my-css-class] :as css-name-map}]
{:query [:db/id]
:initial-state {:db/id 22}
:css [[:.my-css-class {:color :black}]]}
(dom/div {:className my-css-class}
(str "Component: " id)))4.3.2. Options – Lambda vs. Template
The core options (:query, :ident, :initial-state, :css, and :css-include) of defsc support both a lambda and a template
form. The template form is shorter and enables some sanity checks; however, it is not expressive enough to cover all
possible cases. The lambda form is slightly more verbose, but enables full flexibility at the expense of the sanity checks.
IMPORTANT NOTE: In lambda mode use this and props from the defsc argument list. So, for example, (fn [] [:x]) is
valid for query (this is added by the macro), and (fn [] [:table/by-id id]) is valid for ident.
4.3.3. Ident Generation
If you include :ident, it can take two forms: a template or lambda.
Template Idents
A template ident is just a vector that patterns what goes in the ident. The first element is always literal, and the second is the name of the property to pull from props to get the ID.
This is the most common case, and if you use the template mechanism you get some added sanity checks: it won’t compile if your ID key isn’t in your query, eliminating some possible frustration.
Lambda Idents
Template idents are great for the common case, but they don’t work if you have a single instance ever (i.e. you want a literal second element), and they won’t work at all for union queries. They also do not support embedded code. Therefore, if you want a more advanced ident, you’ll need to spell out the code.
defsc at least eliminates some of the boilerplate:
(defsc UnionComponent [this {:keys [db/id component/type]}]
{:ident (fn [] (union-ident type id))} ; id and type are destructured into the method for you.
...)4.3.4. Query
defsc also allows you to specify the query as a template or lambda.
Template Query
The template form is strongly recommended for most cases, because without it many of the sanity checks won’t work.
In template mode, the following sanity checks are enabled:
-
The props destructuring
-
The ident’s id name is in the query (if ident is in template mode)
-
The initial app state only contains things that are queried for (if it is in template mode as well)
Lambda Query
This mode is necessary if you use more complex queries. The template mode currently does not support union queries.
To use this mode, specify your query as (fn [] [:x]). In lambda mode, this comes from the argument list of defsc.
4.3.5. Initial State
As with :query and :ident, :initial-state supports a template and lambda form.
The template form for initial state is a bit magical, because it tries to sanity check your initial state, but also has to support relations through joins. Finally it tries to eliminate typing for you by auto-wrapping nested relation initializations in get-initial-state for you by deriving the correct class to use from the query. This further reduces the chances of error; however, you may find the terse result more difficult to read and instead choose to write it yourself. Both ways are supported:
Lambda mode
This is simple to understand, and all you need to see is a simple example:
(defsc Component [this props]
{:initial-state (fn [params] ...exactly the state this component should start with...)}
...)Template Mode
In template mode :initial-state converts incoming parameters (which must use simple keywords) into :param/X keys. So,
(defsc Person [this props]
{:initial-state {:db/id :param/id}}
...)means:
(defsc Person [this props]
{:initial-state (fn [params] {:db/id (:id params)}})}
...)It is even more powerful than that, because it analyzes your query and can deal with to-one and to-many join initialization as well:
(defsc Person [this props]
{:query [{:person/job (prim/get-query Job)}]
:initial-state {:person/job {:job/name "Welder"}}
...)means (in simplified terms):
(defsc Person [this props]
{:initial-state (fn [params] {:person/job (prim/get-initial-state Job {:job/name "Welder"})})}
...)Notice the magic there. Job was pulled from the query by looking for joins on the initialization keyword (:person/job).
To-many relations are also auto-derived:
(defsc Person [this props]
{:query [{:person/prior-jobs (prim/get-query Job)}]
:initial-state {:person/prior-jobs [{:job/name "Welder"} {:job/name "Cashier"]}
...)means (in simplified terms):
(defsc Person [this props]
{:initial-state (fn [params]
{:person/prior-jobs [(prim/get-initial-state Job {:job/name "Welder"})
(prim/get-initial-state Job {:job/name "Cashier"})]})}
...)The internal steps for processing this template are:
-
Replace all uses of :param/nm with (get params :nm)
-
The query is analyzed for joins on keywords (ident joins are not supported).
-
If a key in the initial state matches up with a join, then the value in initial state must be a map or a vector. In that case (get-initial-state JoinClass p) will be called for each map (to-one) or mapped across the vector (to-many).
-
REMEMBER: the value that you use in the initial-state for children is the parameter map to use against that child’s initial state function. To-one and to-many relations are implied by what you pass (a map is to-one, a vector is to-many).
Step (1) means that nesting of param-namespaced keywords is supported, but realize that the params come from the declaring component’s initial state parameters, they are substituted before being passed to the child.
4.3.6. Pre-Merge
Available from Fulcro 2.8+.
The :pre-merge option offers a hook to manipulate data entering your Fulcro app at component level. The option looks like this:
(defsc Countdown [this props]
{:pre-merge (fn [env] ...)}]The :pre-merge lambda receives a single map containing the following keys:
-
:data-tree- the new data tree entering the database -
:current-normalized- the current entity value (if any), comes normalized from the db (as in(get-in state ref)) -
:state-map- the current app state map (you may use to lookup refs). -
:query- the query used to do this request (user may have modified the original using:focus,:withoutor:update-queryduring the load call
and returns the data that should actually be merged into app state. This feature requires an more complete understanding of normalization and full stack operation, and is covered in a later chapter.
4.3.7. CSS Support
Support for using fulcrologic/fulcro-css is built-in. Before 2.4 it was a dynamic dependency so to use needed to include
the fulcrologic/fulcro-css library in your project dependencies and require the fulcro-css.css namespace in any file
that used this support.
As of version 2.4 it is intregrated with Fulcro, and requires no special dependency.
The keys in the defsc options map to leverage co-located CSS are:
-
:css- The items to put in protocol method css/local-rules. Can be pure garden data, or(fn [] …) -
:css-include- The items to put in protocol method css/include-children. Can be a vector of classes, or(fn [] …)
Both are optional. If you use neither, then your code will not incur a dependency on the fulcro-css library.
See Colocated CSS for more details.
4.3.8. Component Constructor
It is sometimes useful to be able to run some code once on component construction. In React this is particularly useful
when you want a function for saving off :ref or as other callbacks (so the function isn’t changing all the time).
There is no formal constructor for defsc, but you can get exactly the effect of a constructor by placing the
code for it in :initLocalState, which is guaranteed to run once and only once per instance construction:
(defsc Component [this props]
{:initLocalState (fn [] ;; this is accessible
(set! (.-saveref this) (fn [r] (set! (.-ref this) r)))
;; just also remember to return something to act as your React component initial local state!
{})}
(dom/input {:ref (.-saveref this)}))4.3.9. React Lifecycle Methods
The options of defsc allow for React Lifecycle methods to be defined (as lambdas). The this parameter of defsc is
in scope for all of them, but not props or computed. You can obtain computed using prim/get-computed. This is
because the lifecycle method may receive prior or next props, and using the top parameter list could be confusing.
The signatures are:
(defsc Component [this props]
; remember that 'this' is in scope for lifecycle
:initLocalState (fn [] ...)
:shouldComponentUpdate (fn [next-props next-state] ...)
:componentWillReceiveProps (fn [next-props] ...)
:componentWillUpdate (fn [next-props next-state] ...)
:componentDidUpdate (fn [prev-props prev-state] ...)
:componentWillMount (fn [] ...)
:componentDidMount (fn [] ...)
:componentWillUnmount (fn [] ...)
;; Replacements for deprecated methods in React 16.3+
:UNSAFE_componentWillReceiveProps (fn [next-props] ...)
:UNSAFE_componentWillUpdate (fn [next-props next-state] ...)
:UNSAFE_componentWillMount (fn [] ...)
;; ADDED for React 16:
:componentDidCatch (fn [error info] ...)
:getSnapshotBeforeUpdate (fn [prevProps prevState] ...)
:getDerivedStateFromProps (fn [props state] ...)
;; ADDED for React 16.6:
:getDerivedStateFromError (fn [error] ...) **NOTE**: Sets low-level state, Use get-react-state.See the React documentation for more details on how these work.
Component Local State and Errors
Fulcro wraps React’s state such that you can easily store cljs data in the component (e.g.
arguments to methods like componentDidUpdate prev-state will be a cljs map, NOT the raw JS one
that React uses).
The same is true for the return value of initLocalState: You return a CLJS map, and it is safely stored in react
state and behave just like the native.
The advantage of this is twofold:
-
Convenience: You get to use immutable data for component-local state
-
Speed: Fulcro is able to very quickly compare and short-circuit React rendering because immutable state is very fast to compare (it can mostly be a single reference compare).
This is accomplished by storing the "Fulcro" version of component state under the fulcro$state key in the low-level js
state. Normally, this is of no concern to you at all, but React 16.7 added a static lifecycle method
called getDerivedStateFromError whose return value is meant to be a js map that gets merged to the low-level state,
and there is no internal hook or hack (yet found) to merge that into the correct Fulcro location.
Thus, if you provide a getDerivedStateFromError your return value (a CLJS map) will overwrite your current
component local state.
If you’re not using component local state for anything else, then this is probably just fine, but if you have important information in component-local state you may want to choose an alternative.
One workaround is to set state in componentDidCatch. This is deprecated by React because it happens in a different
phase of the React processing, so you should read up on that in the React docs to see if it is acceptable for your
case.
Another (trivial but possibly annoying) workaround is to write a wrapper component that does nothing but deal with errors, so that the state is never used for anything but error handling.
Additional Protocol Support
If you need to include additional protocols (or lifecycle React methods) on the generated class then you can use the
:protocols option. It takes a list of forms that have the same shape as the body of a defui, and the static qualifier
is supported. If you supply Object methods then they will be properly combined with the generated render:
Here is an example of adding Fulcro CSS using protocols instead of options:
(defsc MyComponent [this props]
{:protocols (Object
static css/CSS
(local-rules [_] [])
(include-children [_] []))
...}
(dom/div ...))This gives you the full protocol capabilities of defui, but you only need the extra protocol additions when you
use methods and protocols beyond the central ones.
4.3.10. Sanity Checking
The sanity checking mentioned in the earlier sections causes compile errors. The errors are intended to be self-explanatory. They will catch common mistakes (like forgetting to query for data that you’re pulling out of props, or misspelling a property).
Feel free to edit the components in this source file and try out the sanity checking. For example, try:
-
Mismatching the name of a prop in options with a destructured name in props.
-
Destructuring a prop that isn’t in the query
-
Including initial state for a field that is not listed as a prop or child in options.
-
Using a scalar value for the initial value of a child (instead of a map or vector of maps)
-
Forget to query for the ID field of a component that is stored at an ident
In some cases the sanity checking is more aggressive that you might desire. To get around it simply use the lambda style.
4.4. Factories
Factories are how you generate React elements (the virtual DOM nodes) from your React classes defined with
defsc. You make a new factory using fulcro.client.primitives/factory:
(def ui-component (prim/factory MyComponent {:keyfn f :validator v :instrument? true}))There are 3 supported options to a factory:
:keyfn
|
A function from |
:validator
|
A function from props to boolean. If it returns false then an assertion will be thrown at runtime. |
:instrument?
|
A boolean. If true, it indicates that instrumentation should be enabled on the component. |
Instrumentation is a function you can install on the reconciler that wraps component render allowing you to add
measurement and debugging code to your component’s rendering.
In Fulcro documentation we generally adopt the naming convention for UI factories to be prefixed with ui-. This
is because you often want to name joins the same thing as a component: e.g. your query might be
[{:child (prim/get-query Child)}], and then when you destructure in render: (let [{:keys [child]} (prim/props this) …
you have local data in the symbol child. If your UI factory was also called child then it would cause annoying name
collisions. Prefixing the factories with ui- makes it very clear what is data and what is an element factory.
4.5. Render and Props
Properties are always passed to a component factory as the first argument. The properties can be accessed
from within render by calling fulcro.client.primitives/props on the parameter passed to render (typically named this
to remind you that it is a reference to the instance itself).
In components with queries there is a strong correlation between the query (which must join the child’s query), props (from which you must extract the child’s props), and calling of the child’s factory (to which you must pass the child’s data).
If you are using components that do not have queries, then you may pass whatever properties you deem useful.
Details about additional aspects of rendering are in the sections that follow.
4.5.1. Derived Values
It is possible that your logic and state will be much simpler if your UI components derive some values at render time. A prime example of this is the state of a "check all" button. The state of such a button is dependent on other components in the UI, and it is not a separate value. Thus, your UI should compute it and not store it else it could easily become out of sync and lead to more complex logic.
(defn item-checked? [item] (:checked? item))
(defsc Checkboxes [this {:keys [items]}]
{:query [{:items (prim/get-query CheckboxItem)}]}
(let [all-checked? (every item-checked? items)]
(dom/div
"All: " (dom/input {:checked all-checked? ...})
(dom/ul ...))))General Guidelines for Derived Values
You should consider computing a derived value when: * The known data from the props already gives you sufficient information to calculate the value. * The computation is relatively light.
Some examples where UI computation are effective, light, or even necessary:
-
Rendering an internationalized value. (e.g.
tr) -
Rendering a check-all button
-
Rendering "row numbering" or other decorations like row highlighting
There are some trade-offs, but most significantly you generally do not want to compute things like the order/pagination of a list of items. The logic and overhead in sorting and pagination often needs caching, and there are clear and easy "events" (user clicking on sort-by-name) that make it clear when to call the mutation to update the database. You still have to store the selected sort order, and you have to have idents pointing to the list of items. It is possible for your "selected sort order" and list to become out of sync, but the trade-offs of sorting in the UI are typically high, particularly when pagination is involved and large amounts of data would have to be fed to the UI.
4.5.2. Computed Props and Callbacks
Many reusable components will need to tell their parent about some event. For example, a list item generally wants to tell the parent when the user has clicked on the "remove" button for that item. The item itself cannot be truly composable if it has to know details of the parent. But a parent must always know the details of a child (it rendered it, didn’t it?). As such, manipulations that affect the content of a parent should be communicated to that parent for processing. The mechanism for this is identical to what you’d do in stock React: callbacks from the child.
The one major difference is how you pass the callback to a component.
The query and data feed mechanisms that supply props to a component are capable of refreshing a child without refreshing a parent. This UI optimization can pull the props directly from the database using the query, and re-feed them to the child.
But this mechanism knows nothing about callbacks, because they are not (and should not be) stored in the client database. Such a targeted refresh of a component cannot pass callbacks through the props because the parent is where that is coded, but the parent may not be involved in the refresh!
So, any value (function or otherwise) that is generated on-the-fly by the parent must be passed via
fulcro.client.primitives/computed. This tells the data feed system how to reconstruct the complete data should it do a targeted update.
(defsc Child [this {:keys [y]}]
{:query [:y]}
(let [onDelete (prim/get-computed this :onDelete)]
...))
(defsc Parent [this {:keys [x child]}]
{:query [:x {:child (prim/get-query Child)}]}
(let [onDelete (fn [id] (prim/transact! ...))
child-props-with-callbacks (prim/computed child {:onDelete onDelete})]
(ui-child child-props-with-callbacks)))|
Warning
|
Not understanding this can cause a lot of head scratching: The initial render will always work perfectly, because the parent is involved. All events will be processed, and you’ll think everything is fine; however, if you have passed a callback incorrectly it will mysteriously stop working after a (possibly unnoticeable) refresh. This means you’ll "test it" and say it is OK, only to discover you have a bug that shows up during heavier use. |
4.5.3. Children
A very common pattern in React is to define a number of custom components that are intended to work in a nested fashion. So,
instead of just passing props to a factory, you might also want to pass other React elements. This is fully supported
in Fulcro, but can cause confusion when you first try to mix it with the data-driven aspect of the system.
Working with Children
Fulcro includes a few functions that are helpful when designing React components that are intended to be nested as direct children within a single render:
(prim/children this)
|
Returns the React children of |
(cutil/react-instance? Component instance)
|
Returns true if the given element is an instance of the given component class. Otherwise |
(cutil/first-node Component child-seq)
|
Returns the first of a sequence of elements that has the given component class. |
So, say you wanted to create the following kind of rendering scheme:
(defsc Panel ...)
(def ui-panel (prim/factory Panel))
(defsc PanelHeader ...)
(def ui-panel-header (prim/factory PanelHeader))
(defsc PanelBody ...)
(def ui-panel-body (prim/factory PanelBody))
(ui-panel {}
(ui-panel-header {} "Some Heading Text")
(ui-panel-body {}
(dom/div "Some sub-DOM")))The DOM generation for Panel will need to find the header and body children:
(defsc Panel [this props]
(let [children (prim/children this)
header (util/first-node PanelHeader children)
body (util/first-node PanelBody children)]
(when header
(dom/h4 header))
(when body
(dom/div body))))Basically, the child or children can simply be dropped into the place where they should be rendered.
React 16 Fragments and Returning Multiple Children
Fulcro 2.6+ with React 16 allows you to return a vector of children or a Fragment from a component (so you no longer
are forced to have a single child as a return value). Fulcro DOM namespaces include a fragment
function to wrap elements in a fragment:
(defsc X [this props]
(prim/fragment ; in the prim namespace, because it isn't DOM specific. Could be used with native.
(dom/p "a")
(dom/p "b")))or
(defsc X [this props]
[(dom/p {:key "a"} "a") (dom/p {:key "b"} "b")])allows your component to return multiple elements that are spliced into the parent without any "wrapping" elements in the DOM. Notice when returning a vector you need to supply React keys.
(dom/div (ui-x)) => <div><p>a</p><p>b</p></div>See React documentation for more details.
Mixing Data-Driven Children with UI-Only Concerns
At first this seems a little mind-bending, because you are in fact nesting components in the UI, but the query nesting need only mimic the stateful portion of the UI tree. This means there is ample opportunity to use React children in a way that looks incorrect from what you’ve learned so far. On deeper inspection it turns out it is alignment with the rules, but it takes a minute on first exposure.
Take the Bootstrap collapse component: It needs state of its own in order to know when it is collapsed, and we’d like that to be part of the application database so that the support history viewer can show the correct thing. However, the children of the collapse cannot be known in advance when writing the collapse reusable library component.
The solution is simple once you see it: Query for the collapse component’s state and the child state in the common parent component, then do the UI nesting in that component. Technically the component that is "laying out" the UI (the ultimate parent) is in charge of both obtaining and rendering the data. The fact that the UI child ends up nested in a query sibling is perfectly fine.
The collapse component itself is only concerned with the fact that it is open/closed, and that it has children that should be shown/hidden. The actual DOM elements of those children are immaterial, and can be assembled by the parent:
(defsc CollapseExample [this {:keys [collapse-1 child]}]
{:initial-state (fn [p] {:collapse-1 (prim/get-initial-state b/Collapse {:id 1 :start-open false})})
:query [{:collapse-1 (prim/get-query b/Collapse)}
{:child (prim/get-query SomeChild)}]}
(dom/div
(b/button {:onClick (fn [] (prim/transact! this `[(b/toggle-collapse {:id 1})]))} "Toggle")
(b/ui-collapse collapse-1
(ui-child child))))4.6. Controlled Inputs
Form inputs in React can take two possible approaches: controlled and uncontrolled. The browser normally maintains the value state of inputs for you as mutable data; however, this breaks our overall model of pure rendering! The advantage is UI interaction speed: If your UI gets rather large, it is possible that UI updates on keystrokes in form inputs may be too slow. This is the same sort of trade-off that we talked about when covering component local state for rendering speed with more graphical components. If you follow the basic optimization guidelines then your application should be fast enough to do database updates on every keystroke, and you can keep all input changes in your client database.
In general it is recommended that you use controlled inputs and retain the benefits of pure rendering: no embedded state, your UI exactly represents your data representation, concrete devcards support for UI prototyping, and full support viewer support.
Most inputs become controlled when you set their :value property. The table below lists the mechanism whereby
a form input is completely controlled by React:
| Input type | Attribute | Notes |
|---|---|---|
input |
:value |
(not checkboxes or radio) |
checkbox |
:checked |
|
radio |
:checked |
(only one in a group should be checked) |
textarea |
:value |
|
select |
:value |
Instead of marking an option selected. Match |
|
Important
|
React will consider nil to mean you want an uncontrolled component. This can result in
a warning about converting uncontrolled to controlled components. In order to prevent this warning you should make
sure that :checked is always a boolean, and that other inputs have a valid :value (e.g. an empty string). The
select input can be given an "extra" option that stands for "not selected yet" so that you can start its value
at something valid.
|
See React Forms for more details.
4.7. React Lifecycle Examples
|
Note
|
Fulcro 2.6+ includes React 16.4+ Lifecycle support. |
There are some common use-cases that can only be solved by working directly with the React Lifecycle methods.
Some topics you should be familiar with in React to accomplish many of these things are:
-
Component references: A mechanism that allows you access to the real DOM of the component once it’s on-screen.
-
Component-local state: A stateful mechanism where mutable data is stored on the component instance.
-
General DOM manipulation. Clojurescript builds using the Google Closure compiler and therefore includes the Google Closure library, which in turn has all sorts of helpful low-level functions should you need them.
4.7.1. Focusing an input
Focus is a stateful browser mechanism, and React cannot force the rendering of "focus". As such, when you need
to deal with UI focus it generally involves some interpretation, and possibly component local state. One way
of dealing with deciding when to focus is to look at a component’s prior vs. next properties. This can be
done in componentDidUpdate. For example, say you have an item that renders as a string, but when clicked
turns into an input field. You’d certainly want to focus that, and place the cursor at the end of the
existing data (or highlight it all).
If your component had a property called editing? that you made true to indicate it should render as an input
instead of just a value, then you could write your focus logic based on the transition of your component’s props
from :editing? false to :editing? true.
(ns book.ui.focus-example
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[fulcro.client.mutations :as m]))
(defsc ClickToEditField [this {:keys [value editing?]}]
{:initial-state {:value "ABC"
:db/id 1
:editing? false}
:query [:db/id :value :editing?]
:ident [:field/by-id :db/id]
:componentDidUpdate (fn [prev-props _]
(when (and (not (:editing? prev-props)) (:editing? (prim/props this)))
(let [input-field (dom/node this "edit_field")
input-field-length (.. input-field -value -length)]
(.focus input-field)
(.setSelectionRange input-field input-field-length input-field-length))))}
(dom/div
; trigger a focus based on a state change (componentDidUpdate)
(dom/a {:onClick #(m/toggle! this :editing?)}
"Click to focus (if not already editing): ")
(dom/input {:value value
:onChange #(m/set-string! this :event %)
:ref "edit_field"})
; do an explicit focus
(dom/button {:onClick (fn []
(let [input-field (dom/node this "edit_field")
input-field-length (.. input-field -value -length)]
(.focus input-field)
(.setSelectionRange input-field 0 input-field-length)))}
"Highlight All")))
(def ui-click-to-edit (prim/factory ClickToEditField))
(defsc Root [this {:keys [field] :as props}]
{:query [{:field (prim/get-query ClickToEditField)}]
:initial-state {:field {}}}
(ui-click-to-edit field))|
Note
|
React documentation encourages a more functional form of ref (you supply a function instead of a string).
This example could also cache that on the component like this:
|
(ns app
(:require [goog.object :as gobj]))
(defsc ClickToEditField [this {:keys [value editing?]}]
...
(dom/input {:ref (fn [r] (gobj/set this "input-ref" r))})
...However, The wrapped inputs of Fulcro 2.3.0 and earlier (which fixed a different issue with React) did
not work with the functional ref technique (use strings and dom/node
instead). As of 2.3.1 this is fixed, and while inputs still have the internal wrapping to prevent "lost keys" bugs,
they work with both the older string support or functional refs.
4.7.2. Taking control of the sub-DOM (D3, etc)
Libraries like D3 are great for dynamic visualizations, but they need full control of the portion of the DOM that they create and manipulate.
In general this means that your render method should be called once
(and only once) to install the base DOM onto which the other library
will control.
For example, let’s say we wanted to use D3 to render things. We’d first write a function that would take the real DOM node and the incoming props:
(defn db-render [DOM-NODE props] ...)This function should do everything necessary to render the sub-dom (and
update it if the props change). Then we’d wrap that under a component that
doesn’t allow React to refresh that sub-tree via shouldComponentUpdate.
Below is a demo of this:
(ns book.ui.d3-example
(:require [fulcro.client.dom :as dom]
;; REQUIRES shadow-cljs, with "d3" in package.json
["d3" :as d3]
[goog.object :as gobj]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.client.primitives :as prim :refer [defsc]]))
(defn render-squares [dom-node props]
(let [svg (-> d3 (.select dom-node))
data (clj->js (:squares props))
selection (-> svg
(.selectAll "rect")
(.data data (fn [d] (.-id d))))]
(-> selection
.enter
(.append "rect")
(.style "fill" (fn [d] (.-color d)))
(.attr "x" "0")
(.attr "y" "0")
.transition
(.attr "x" (fn [d] (.-x d)))
(.attr "y" (fn [d] (.-y d)))
(.attr "width" (fn [d] (.-size d)))
(.attr "height" (fn [d] (.-size d))))
(-> selection
.exit
.transition
(.style "opacity" "0")
.remove)
false))
(defsc D3Thing [this props]
{:componentDidMount (fn []
(when-let [dom-node (gobj/get this "svg")]
(render-squares dom-node (prim/props this))))
:shouldComponentUpdate (fn [next-props next-state]
(when-let [dom-node (gobj/get this "svg")]
(render-squares dom-node next-props))
false)}
(dom/svg {:style {:backgroundColor "rgb(240,240,240)"}
:width 200 :height 200
:ref (fn [r] (gobj/set this "svg" r))
:viewBox "0 0 1000 1000"}))
(def d3-thing (prim/factory D3Thing))
(defn random-square []
{
:id (rand-int 10000000)
:x (rand-int 900)
:y (rand-int 900)
:size (+ 50 (rand-int 300))
:color (case (rand-int 5)
0 "yellow"
1 "green"
2 "orange"
3 "blue"
4 "black")})
(defmutation add-square [params]
(action [{:keys [state]}]
(swap! state update :squares conj (random-square))))
(defmutation clear-squares [params]
(action [{:keys [state]}]
(swap! state assoc :squares [])))
(defsc Root [this props]
{:query [:squares]
:initial-state {:squares []}}
(dom/div
(dom/button {:onClick #(prim/transact! this
`[(add-square {})])} "Add Random Square")
(dom/button {:onClick #(prim/transact! this
`[(clear-squares {})])} "Clear")
(dom/br)
(dom/br)
(d3-thing props)))The things to note for this example are:
-
We override the React lifecycle method
shouldComponentUpdateto return false. This tells React to never ever call render once the component is mounted. D3 is in control of the underlying stuff. -
We override
componentWillReceivePropsandcomponentDidMountto do the actual D3 render/update. The former will get incoming data changes, and the latter is called on initial mount. Our render method delegates all of the hard work to D3.
4.7.3. Dynamically rendering into a canvas
Sometimes you need to use component-local state to avoid the overhead in running a query to feed props. An example of this is when handing mouse interactions like drag. You’ll typically use React refs to grab the actual low-level canvas.
In Fulcro version before 2.6 there are actually two ways to change component-local state. One of them defers rendering to the next animation frame, but it also reconciles the database with the stateful components. This one will not give you as much of a speed boost (though it may be enough, since you’re not changing the database or recording more UI history).
The other mechanism completely avoids this, and just asks React for an immediate forced update.
In Fulcro 2.6 set-state! is a Fulcro wrapper of React’s setState, but it let’s you use cljs maps instead of
js ones. The shallow merge described by React is honored as if you used an updater function (there is no need
for an updater function). The set-state! also allows a callback to give you full React compatibility. Note, however,
that React 16’s setState schedule a state update and render. It is not guaranteed to be immediate.
The update-state! function in Fulcro is like Clojurescripts swap! function, and uses set-state! behind the
scenes.
In older versions of Fulcro:
-
(set-state! this data)and(update-state! this data)- trigger a reconcile against the database at the next animation frame. Limits frame rate to 60 fps (in 2.6+ is identical to ReactsetStatewith anupdaterand optionalcallback, but you just supply the map that will be merged. Useupdate-state!if you need more functional control. -
(react-set-state! this data)- triggers a React render according to React’ssetStatedocumentation.
In this example we’re using set-state!, and you can see it is still plenty fast (in 2.6 there is no difference)!
(ns book.ui.hover-example
(:require
[fulcro.client.cards :refer [defcard-fulcro]]
[fulcro.client.mutations :refer [defmutation]]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[goog.object :as gobj]
[fulcro.client.dom :as dom]))
(defn change-size*
"Change the size of the canvas by some (pos or neg) amount.."
[state-map amount]
(let [current-size (get-in state-map [:child/by-id 0 :size])
new-size (+ amount current-size)]
(assoc-in state-map [:child/by-id 0 :size] new-size)))
; Make the canvas smaller. This will cause
(defmutation ^:intern make-smaller [p]
(action [{:keys [state]}]
(swap! state change-size* -20)))
(defmutation ^:intern make-bigger [p]
(action [{:keys [state]}]
(swap! state change-size* 20)))
(defmutation ^:intern update-marker [{:keys [coords]}]
(action [{:keys [state]}]
(swap! state assoc-in [:child/by-id 0 :marker] coords)))
(defn event->dom-coords
"Translate a javascript evt to a clj [x y] within the given dom element."
[evt dom-ele]
(let [cx (.-clientX evt)
cy (.-clientY evt)
BB (.getBoundingClientRect dom-ele)
x (- cx (.-left BB))
y (- cy (.-top BB))]
[x y]))
(defn event->normalized-coords
"Translate a javascript evt to a clj [x y] within the given dom element as normalized (0 to 1) coordinates."
[evt dom-ele]
(let [cx (.-clientX evt)
cy (.-clientY evt)
BB (.getBoundingClientRect dom-ele)
w (- (.-right BB) (.-left BB))
h (- (.-bottom BB) (.-top BB))
x (/ (- cx (.-left BB))
w)
y (/ (- cy (.-top BB))
h)]
[x y]))
(defn render-hover-and-marker
"Render the graphics in the canvas. Pass the component props and state. "
[canvas props coords]
(let [marker (:marker props)
size (:size props)
real-marker-coords (mapv (partial * size) marker)
; See HTML5 canvas docs
ctx (.getContext canvas "2d")
clear (fn []
(set! (.-fillStyle ctx) "white")
(.fillRect ctx 0 0 size size))
drawHover (fn []
(set! (.-strokeStyle ctx) "gray")
(.strokeRect ctx (- (first coords) 5) (- (second coords) 5) 10 10))
drawMarker (fn []
(set! (.-strokeStyle ctx) "red")
(.strokeRect ctx (- (first real-marker-coords) 5) (- (second real-marker-coords) 5) 10 10))]
(.save ctx)
(clear)
(drawHover)
(drawMarker)
(.restore ctx)))
(defn place-marker
"Update the marker in app state. Derives normalized coordinates, and updates the marker in application state."
[child evt]
(let [canvas (gobj/get child "canvas")]
(prim/transact! child `[(update-marker
{:coords ~(event->normalized-coords evt canvas)})])))
(defn hover-marker
"Updates the hover location of a proposed marker using canvas coordinates. Hover location
is stored in component local state (meaning that a low-level app database query will not
run to do the render that responds to this change)"
[child evt]
(let [canvas (gobj/get child "canvas")
updated-coords (event->dom-coords evt canvas)]
(prim/set-state! child {:coords updated-coords})
(render-hover-and-marker canvas (prim/props child) updated-coords)))
(defsc Child [this {:keys [id size] :as props}]
{:query [:id :size :marker]
:initial-state (fn [_] {:id 0 :size 50 :marker [0.5 0.5]})
:ident (fn [] [:child/by-id id])
:initLocalState (fn [] {:coords [-50 -50]})}
; Remember that this "render" just renders the DOM (e.g. the canvas DOM element). The graphical
; rendering within the canvas is done during event handling.
; size comes from props. Transactions on size will cause the canvas to resize in the DOM
(when-let [canvas (gobj/get this "canvas")]
(render-hover-and-marker canvas props (prim/get-state this :coords)))
(dom/canvas {:width (str size "px")
:height (str size "px")
:onMouseDown (fn [evt] (place-marker this evt))
:onMouseMove (fn [evt] (hover-marker this evt))
; This is a pure React mechanism for getting the underlying DOM element.
; Note: when the DOM element changes this fn gets called with nil
; (to help you manage memory leaks), then the new element
:ref (fn [r]
(when r
(gobj/set this "canvas" r)
(render-hover-and-marker r props (prim/get-state this :coords))))
:style {:border "1px solid black"}}))
(def ui-child (prim/factory Child))
(defsc Root [this {:keys [child]}]
{:query [{:child (prim/get-query Child)}]
:initial-state (fn [params] {:ui/react-key "K" :child (initial-state Child nil)})}
(dom/div
(dom/button {:onClick #(prim/transact! this `[(make-bigger {})])} "Bigger!")
(dom/button {:onClick #(prim/transact! this `[(make-smaller {})])} "Smaller!")
(dom/br)
(dom/br)
(ui-child child)))The component receives mouse move events to show a hover box. To make this move in real-time we use component local state. Clicking to set the box, or resize the container are real transactions, and will actually cause a refresh from application state to update the rendering.
4.8. Using Javascript React Components
One of the great parts about React is the ecosystem. There are some great libraries out there. However, the interop story isn’t always straight forward. The goal of this section is to make that story a little clearer.
4.8.1. Factory Functions for JS React Components
Integrating React components is fairly straightforward if you have used React from JS before. The curve comes having spent time with libraries or abstractions like Om and friends. JSX will also abstract some of this away, so it’s not just the cljs wrappers. For a good article explaining some of the concepts read, React Elements The take-aways here are:
-
If you are importing third party components, you should be importing the class, not a factory.
-
You need to explicitly create the react elements with factories. The relevant js functions are React.createElement, and React.createFactory.
It is very important to consider when using any of these functions - the children. JS does not have a built in notion of lazy sequences. Clojurescript does. This can create subtle bugs when evaluating the children of a component.
fulcro.util/force-children helps us in this regard by taking a seq and returning a vector. We can use this to
create our own factory function, much like React.createFactory:
(defn factory-force-children
[class]
(fn [props & children]
(js/React.createElement class
props
(util/force-children children))))This is fine, but you will notice that children in our factory may be missing keys. Because we passed a vector in, React won’t attach the key attribute. We can solve this problem by using the apply function.
(defn factory-apply
[class]
(fn [props & children]
(apply js/React.createElement
class
props
children)))Here the apply function will pass the children in as args to React.createElement, thus avoiding the key problem
as well as the issue with lazy sequences.
Now that we have some background on creating React Elements it’s pretty simple to implement something. Let' look at making a chart using Victory. We are going to make a simple line chart, with an X axis that contains years, and a Y axis that contains dollar amounts. Really the data is irrelavent, it’s the implementation we care about.
The running code and source are below:
(ns book.ui.victory-example
(:require [cljs.pprint :refer [cl-format]]
;; REQUIRES shadow-cljs, with "victory" in package.json
["victory" :refer [VictoryChart VictoryAxis VictoryLine]]
[fulcro.client.cards :refer [defcard-fulcro]]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.util :as util]))
(defn us-dollars [n]
(str "$" (cl-format nil "~:d" n)))
(defn factory-force-children
[class]
(fn [props & children]
(js/React.createElement class
props
(util/force-children children))))
(defn factory-apply
[class]
(fn [props & children]
(apply js/React.createElement
class
props
children)))
(def vchart (factory-apply VictoryChart))
(def vaxis (factory-apply VictoryAxis))
(def vline (factory-apply VictoryLine))
;; " [ {:year 1991 :value 2345 } ...] "
(defsc YearlyValueChart [this {:keys [label plot-data x-step]}]
(let [start-year (apply min (map :year plot-data))
end-year (apply max (map :year plot-data))
years (range start-year (inc end-year) x-step)
dates (clj->js (mapv #(new js/Date % 1 2) years))
{:keys [min-value
max-value]} (reduce (fn [{:keys [min-value max-value] :as acc}
{:keys [value] :as n}]
(assoc acc
:min-value (min min-value value)
:max-value (max max-value value)))
{}
plot-data)
min-value (int (* 0.8 min-value))
max-value (int (* 1.2 max-value))
points (clj->js (mapv (fn [{:keys [year value]}]
{:x (new js/Date year 1 2)
:y value})
plot-data))]
(vchart nil
(vaxis #js {:label label
:standalone false
:scale "time"
:tickFormat (fn [d] (.getFullYear d))
:tickValues dates})
(vaxis #js {:dependentAxis true
:standalone false
:tickFormat (fn [y] (us-dollars y))
:domain #js [min-value max-value]})
(vline #js {:data points}))))
(def yearly-value-chart (prim/factory YearlyValueChart))
(defsc Root [this props]
{:initial-state {:label "Yearly Value"
:x-step 2
:plot-data [{:year 1983 :value 100}
{:year 1984 :value 100}
{:year 1985 :value 90}
{:year 1986 :value 89}
{:year 1987 :value 88}
{:year 1988 :value 85}
{:year 1989 :value 83}
{:year 1990 :value 80}
{:year 1991 :value 70}
{:year 1992 :value 80}
{:year 1993 :value 90}
{:year 1994 :value 95}
{:year 1995 :value 110}
{:year 1996 :value 120}
{:year 1997 :value 160}
{:year 1998 :value 170}
{:year 1999 :value 180}
{:year 2000 :value 180}
{:year 2001 :value 200}
]}}
(dom/div
(yearly-value-chart props)))4.8.2. The Function-As-a-Child Pattern
A common pattern in React libraries is to use a function as a single child instead of an actual element. This is an accepted and widely used pattern, but you need to do a simple extra step for it to work properly with Fulcro. You see, Fulcro components use some behind-the-scenes bindings to allow for targeted UI rendering optimizations, and when you embed them in a function that is invoked from external JS out of that context, things won’t work correctly.
For example, the react-motion library gives you React tools that can animate DOM motion. It animates variables
that you apply to nested DOM, and it does this through the function-as-a-child pattern. Here’s an example from
a demo project (which uses shadow-cljs to get easy access to NPM
libraries):
(ns sample
(:require ["react-motion" :refer [Motion spring]]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[goog.object :as gobj]))
(def ui-motion (factory-apply Motion))
(defsc Demo [this {:keys [ui/slid? block]}]
{:query [:ui/slid? {:block (prim/get-query Block)}]
:initial-state {:ui/slid? false :block {:id 1 :name "N"}}
:ident (fn [] [:control :demo])}
(dom/div
(dom/button {:onClick (fn [] (m/toggle! this :ui/slid?))} "Toggle")
(ui-motion (clj->js {:style {"x" (spring (if slid? 400 0))}})
(fn [p]
(let [x (gobj/get p "x")]
; The binding wrapper ensures that internal fulcro bindings are held within the lambda
(prim/with-parent-context this
(dom/div :.demo
(ui-block (prim/computed block {:x x})))))))))The key is the call to with-parent-context. It causes the enclosed elements to have bindings pulled
from the component passed as the first parameter (in this case this). Rendering will work
correctly without this wrapper, but interactions (particularly transact!) will not operate correctly
without it.
4.9. Colocated CSS
Fulcro includes support for localizing CSS rules to components. It leverages Garden for interpreting component-localized hiccup-style CSS rules.
Before 2.4 you needed to include fulcrologic/fulcro-css as a dependency. As of 2.4, this is no longer
the case.
The support make it easy to co-locate and compose localized component CSS with your UI! This leads to all sorts of wonderful and interesting results:
-
Your CSS is name-localized, so your component’s CSS is effectively private
-
You don’t have to go find the CSS file to include it in your application. It’s already in the code.
-
Since it’s code, you can use data manipualtion, variables, and more to create your CSS. It is the ultimate in code reuse and generality.
-
The composition facilities prevent duplication.
-
It becomes much easier to allow themed components with additional tool chains! Variables can be supplied that can simply be modified via code before CSS injection.
-
Google Closure’s minification can be applied to reduce the size of the resulting files during your normal compilation!
-
Server-side rendering can pre-inject CSS rules into the server-side rendered page! No more waiting for your CSS to load for the UI to look right!
4.9.1. Basics
CSS can be co-located on any component. This CSS does not take effect until it is embedded on the page (see Embedding The CSS below). The typical steps for usage are:
-
Add localized rules to your component via the
:cssoption ofdefscor by implementing thefulcro-css.css-protocols/CSSprotocol’slocal-rules. NOTE: (in olders versions this protocol was namedfulcro-css.css/CSS) The result of this must be a vector in Garden notation. Any rules included here will be automatically prefixed with the CSSified namespace and component name to ensure name collisions are impossible. -
(optional) Add "global" rules. The vector of rules (in the prior step) can use a
$prefix to prevent localization (:$containerinstead of:.container). -
(optional) Add the
:css-includeoption todefsc. This MUST be a vector of components that are used within therenderthat also supply CSS. This allows the library to compose together your CSS according to what components you use. Pulling the CSS rules from some top-level component will dedupe any inclusions before generating the actual on-DOM CSS. See CSS Injection for a way to avoid this. -
Use one of many options to get the "munged" classnames for use in your code:
-
(fulcro-css.css/get-classnames Component)returns a map of namespaced CSS classes keyed by the simple name you used in your garden rules. -
The 4th argument to
defscis that same map, on which you can apply destructuring to get the munged class names. -
Use
fulcro.client.localized-domfor DOM rendering, and have it all automatically done for you!
-
-
Before Fulcro 2.6: Use the
fulcro-css.css/upsert-cssorfulcro-css.css/style-elementfunction (or your own style element) to embed the CSS. -
Fuclro 2.6+: Use the
fulcro-css.css-injection/upsert-cssorfulcro-css.css-injection/style-elementto embed the CSS. See CSS Injection.
A typical file will have the following layout:
(ns my-ui
(:require [fulcro.client.dom :as dom]
[fulcro-css.css :as css]
[fulcro.client.primitives :as prim :refer [defui defsc]]))
; the item binding is destructured as the fourth param. The actual CSS classname
; will be namespaced to the component as my_ui_ListItem__item, but will be available
; as the value :item in css-classnames map parameter, so you can easily
; destructure if and use it in the DOM without having to worry about how it is prefixed.
(defsc ListItem [this {:keys [label] :as props} computed {:keys [item] :as css-classes}]
{:css [[:.item {:font-weight "bold"}]]}
(dom/li {:className item} label))
(def ui-list-item (om/factory ListItem {:keyfn :id}))
(defsc ListComponent [this {:keys [id items]} computed {:keys [items-wrapper]}]
{:css [[:.items-wrapper {:background-color "blue"}]] ; this component's css
:css-include [ListItem]} ; components whose CSS should be included if this component is included (optional in 2.6+)
(dom/div {:className items-wrapper}
(dom/h2 (str "List " id))
(dom/ul (map ui-list-item items))))
(def ui-list (om/factory ListComponent {:keyfn :id}))
(defsc Root [this props computed {:keys [text]}]
{:css [[:.container {:background-color "red"}]]
:css-include [ListComponent]} ; NOTE: optional in Fulcro 2.6+
(let [the-list {:id 1 :items [{:id 1 :label "A"} {:id 2 :label "B"}]}]
(dom/div {:className text}
(ui-list the-list))))
; ...
; Add the CSS from Root as a HEAD style element. If it already exists, replace it. This
; will recursively follow all of the CSS includes *just* for components that Root includes!
(css/upsert-css "my-css" {:component Root}) ; NOTE: Use css-injection in Fulcro 2.6+In the above example, the upsert results in this CSS on the page:
<style id="my-css">
.fulcro-css_cards-ui_Root__container {
background-color: red;
}
.text {
color: yellow;
}
.fulcro-css_cards-ui_ListComponent__items-wrapper {
background-color: blue;
}
.fulcro-css_cards-ui_ListItem__item {
font-weight: bold;
}
</style>with a DOM for the UI of:
<div class="text">
<div class="fulcro-css_cards-ui_ListComponent__items-wrapper">
<h2>List 1</h2>
<ul>
<li class="fulcro-css_cards-ui_ListItem__item">A</li>
<li class="fulcro-css_cards-ui_ListItem__item">B</li>
</ul>
</div>
</div>Garden’s selectors are supported. These include the CSS combinators and the special & selector. Using the
$-prefix will also prevent the selectors from being localized.
:css [[(garden.selectors/> :.a :$b) {:color "blue"}]].namespace_Component__a > .b {
color: blue;
}See Garden’s documentation for more details on more complex rules.
4.9.2. Upsert vs. Style Element
There are two ways of placing the CSS for a (group of) components on a page:
(upsert-css ID {:component Component}) will pull (recursively) the rules of Component, translate them to legal CSS, and then insert them
on the body of the page’s DOM at the given ID (overwriting the old style element with that same ID). If you ensure that
this upsert happens on hot code reload, then your CSS will update as you edit your code.
Typically, you’ll run upsert-css with your initial mount and in your hot code reload trigger. This means that the
computational overhead for the CSS is limited to initial startup.
(style-element {:component Component}) will pull (recursively) the rules for Component and return a React style element. This allows
you to embed CSS for a sub-tree of components in an "on-demand" fashion, since the element will only render of the component
that uses it renders. The problem with this method is that the computational overhead for computing the CSS is moved into
your primary rendering. This, however, is quite convenient in situations like devcards where you’d like to easily ensure
that the CSS is there, but don’t want to have to worry about conflicting with existing style elements on the top-level page.
The live demo below upserts the co-located CSS from the code itself, but the embedded rules also base the color on the value in an atom (think theme color). At any time you can change your various embedded data on colocated CSS and re-upsert the generated result!
(ns book.demos.component-localized-css
(:require
[fulcro-css.css :as css]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[fulcro.client.dom :as dom]
[fulcro.client.localized-dom :as ldom]))
(defonce theme-color (atom :blue))
(defsc Child [this {:keys [label]} _ {:keys [thing]}] ;; css destructuring on 4th argument, or use css/get-classnames
{; define local rules via garden. Defined names will be auto-localized
:css [[:.thing {:color @theme-color}]]}
(dom/div
(dom/h4 "Using css destructured value of CSS name")
(dom/div {:className thing} label)
(dom/h4 "Using automatically localized DOM in fulcro.client.localized-dom")
(ldom/div :.thing label)))
(def ui-child (prim/factory Child))
(declare change-color)
(defsc Root [this {:keys [ui/react-key]}]
{; Compose children with local reasoning. Dedupe is automatic if two UI paths cause re-inclusion.
:css-include [Child]}
(dom/div
(dom/button {:onClick (fn [e]
; change the atom, and re-upsert the CSS. Look at the elements in your dev console.
; Figwheel and Closure push SCRIPT tags too, so it may be hard to find on
; initial load. You might try clicking one of these
; to make it easier to find (the STYLE will pop to the bottom).
(change-color "blue"))} "Use Blue Theme")
(dom/button {:onClick (fn [e]
(change-color "red"))} "Use Red Theme")
(ui-child {:label "Hello World"})))
(defn change-color [c]
(reset! theme-color c)
(css/upsert-css "demo-css-id" Root))
; Push the real CSS to the DOM via a component. One or more of these could be done to, for example,
; include CSS from different modules or libraries into different style elements.
(css/upsert-css "demo-css-id" Root)4.9.3. Localized CSS and Server-Side Rendering (Fulcro 2.5 and earlier)
|
Note
|
See CSS Injection for Fulcro 2.6+. |
The upsert-css and style-element functions are conveniences for CLJS DOM, but they do not work in CLJ.
Instead use (garden/css (fulcro-css.css/get-css Component)) to get a string version of the generated CSS and embed that
in the page. Version 2.4.1+ includes fulcro-css.css/raw-css for this expression.
You can use the raw string in generated HTML, or use the server-compatible DOM functions:
(ns app.ui
(:require
[fulcro.client.dom :as dom]
[garden.core :as g]
[fulcro-css.css :as css]))
(dom/style {:dangerouslySetInnerHTML {:__html (g/css (css/get-css component))}})4.10. Improved CSS Injection (Fulcro 2.6+)
Fulcro has had component-local CSS for quite some time. The ability to write your CSS inside of your components is a very powerful feature, but the injection support in prior versions had a couple of weaknesses:
-
You had to manually compose your CSS by including children in the parent.
-
It sorted components in breadth-first order.
-
The
style-elementmethod of injection had high overhead (computed new content on every refresh)
Fulcro 2.6 adds a new fulcro-css.css-injection namespace that gives you
better control and performance:
(ns my-app
(:require [fulcro-css.css-injection :as injection]))
(defsc A [this props]
{:css [[ARules]]} ...)
(defsc MyRoot [this props]
{:css [[rules]]
; NO css includes
:query [{:a (prim/get-query A)}]}
(dom/div
(injection/style-element {:component this})
...))The new style-element has the following benefits:
-
By default it will automatically use the query to find all children (even through unions) that have CSS.
-
It defaults to a depth-first ordering in the output rules.
-
It caches the computed CSS, so it has much less rendering overhead than the old one.
You can get just the performance benefits (with exact behavior of the old one) by passing :auto-include? false and
:order :breadth-first in the options.
4.10.1. Upserts and SSR
The new injections namespace also has an improved upsert (client-only DOM node upsert), and a compute-css function the returns
the CSS as a string (useful for generating the upserted node in SSR). They take the exact same options map as the
style-element.
4.11. CSS Localized DOM
If you choose to add localized CSS rules to your components, then you will probably also
want to use the DOM elements that support it natively. The fulcro.client.localized-dom
uses the same more compact notation of dom, but
it interprets the CSS keywords in the context of the component! This means that you can
use localized CSS without having to destructure the munged names at all.
Instead of writing:
(ns app.ui
(:require [fulcro.client.dom :as dom]))
(defsc Component [this props comp {:keys [a]}]
{:css [[:.a {:color :red}]]}
(dom/div {:className a} "Hi!))you can instead write (note the different require for DOM):
(ns app.ui
(:require [fulcro.client.localized-dom :as dom]))
(defsc Component [this props]
{:css [[:.a {:color :red}]]}
(dom/div :.a "Hi!))and avoid the argument destructuring, and JS properties map.
This localization of the keyword does require a small bit of runtime overhead, but inline macro expansion is used wherever possible to make this as performant as possible.
The features include:
-
A class keyword may precede the props.
:.cwill be localized to the class, whereas:$cwill be treated as a top-level (raw) class name. -
The keyword can contain any number of classes, and one ID:
:..c$c2.c3#id -
Props are optional, but may contain
:classNameor:classes -
:classNameis a literal string. Its contents will be combined with the:classesand prefix keywords -
:classesmust be a vector of keywords (or expressions the result in keywords). Nil is allowed in the vector but is ignored.
Some examples:
(div :.a "Hi") ; <div class="namespace_Component__a">Hi</div>
(div :$a "Hi") ; <div class="a">Hi</div>
(div :$a$b "Hi") ; <div class="a b">Hi</div>
(div :$a.b "Hi") ; <div class="a namespace_Component__b">Hi</div>
(div {:classes [(when true :$hide) :.a]} "Hi") ; <div class="hide namespace_Component__a">Hi</div>
(div {:classes [(when false :$hide) :.a]} "Hi") ; <div class="namespace_Component__a">Hi</div>
(div :$c {:className "boo" :classes [:$a]} "Hi") ; <div class="c boo a">Hi</div>The demo below shows most of these techniques combined with theme and rendering logic:
(ns book.demos.localized-dom
(:require
[fulcro-css.css :as css]
[fulcro.client.mutations :refer [defmutation]]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[fulcro.client.localized-dom :as dom]))
(defonce theme-color (atom :blue))
(defsc Child [this {:keys [label invisible?]}]
{:css [[:.thing {:color @theme-color}]]
:query [:id :label :invisible?]
:initial-state {:id :param/id :invisible? false :label :param/label}
:ident [:child/by-id :id]}
(dom/div :.thing {:classes [(when invisible? :$hide)]} label))
(def ui-child (prim/factory Child))
(declare change-color)
(defmutation toggle-child [{:keys [id]}]
(action [{:keys [state]}]
(swap! state update-in [:child/by-id id :invisible?] not)))
(defsc Root [this {:keys [child]}]
{:css [[:$hide {:display :none}]] ; a global CSS rule ".hide"
:query [{:child (prim/get-query Child)}]
:initial-state {:child {:id 1 :label "Hello World"}}
:css-include [Child]}
(dom/div
(dom/button {:onClick (fn [e] (change-color "blue"))} "Use Blue Theme")
(dom/button {:onClick (fn [e] (change-color "red"))} "Use Red Theme")
(dom/button {:onClick (fn [e] (prim/transact! this `[(toggle-child {:id 1})]))} "Toggle visible")
(ui-child child)))
(defn change-color [c]
(reset! theme-color c)
(css/upsert-css "demo-css-id" Root))
; Push the real CSS to the DOM via a component. One or more of these could be done to, for example,
; include CSS from different modules or libraries into different style elements.
(css/upsert-css "demo-css-id" Root)4.11.1. Localized DOM and Server-Side Rendering
There is a fulcro.client.localized-dom-server namespace that provides the CLJ versions of the DOM functions. In
order to write UI in CLJC files you will need to make sure you use a conditional reader tag to include the
correct namespace for the correct langauge:
(ns app.ui
(:require #?(:clj [fulcro.client.localized-dom-server :as dom] :cljs [fulcro.client.localized-dom :as dom]))
... same as before4.12. Complex Graphical UI Demo: An Image Clip Tool
Fulcro has the start of an image clip tool. Right now it is mainly for demonstration purposes, and is a good example of a complex UI component where two components have to talk to each other and share image data.
You should study the source code (src/main/fulcro/ui/clip_tool.cljs) to get the full details,
but here is an overview of the critical facets:
-
ClipTool creates a canvas on which to draw
-
It uses initial state and a query to track the setup (e.g. size, aspect ratio, image to clip)
-
For speed (and because some data is not serializable), it uses component-local state to track current clip region, a javascript Image object and the DOM canvas (via React ref) for rendering, and the current active operation (e.g. dragging a handle).
-
The mouse events are essentially handled as updates to the component local state, which causes a local component render update.
-
-
PreviewClip is a React component, but not data-driven (no query). Everything is just passed through props.
-
It technically knows nothing of the clip tool.
-
It expects an :image-object and clip data to be passed in…it just renders it on a canvas.
-
It uses React refs to get the reference to the real DOM canvas for rendering
-
It renders whenever props change
-
-
A callback on the ClipTool communicates through the common parent’s component local state. The parent will re-render when its state changes, which will in turn force a new set of props to be passed to the preview).
As you can see, the interaction performance is quite good.
(ns book.ui.clip-tool-example
(:require [cljs.pprint :refer [cl-format]]
[fulcro.ui.clip-tool :as ct]
[fulcro.client.cards :refer [defcard-fulcro]]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]))
(def minion-image "https://s-media-cache-ak0.pinimg.com/736x/34/c2/f5/34c2f59284fcdff709217e14df2250a0--film-minions-minions-images.jpg")
(defsc Root [this {:keys [ctool]}]
{:initial-state
(fn [p] {:ctool (prim/get-initial-state ct/ClipTool {:id :clipper :aspect-ratio 0.5
:image-url minion-image})})
:query [:ctool]}
(dom/div
(ct/ui-clip-tool (prim/computed ctool {:onChange (fn [props] (prim/set-state! this props))}))
(ct/ui-preview-clip (merge (prim/get-state this) {:filename "minions.jpg"
:width 100 :height 200}))))4.13. React Higher-Order Components
When using external libraries with Fulcro you’ll often run into the higher-order component pattern. React Higher Order Components (HOC) can be used with Fulcro but due to how Fulcro works internally interop/glue code is needed.
Higher Order Components is a pattern in React similar to the Decorator pattern in object-oriented programming: you wrap one component class with another component to decorate it with extra behaviour.
Some React reusable components provide HOC components to wrap cross cutting logic needed for the wrapped components to work.
For example google-maps-react provides GoogleApiWrapper HOC that handles
dynamic loading and initialisation of Google Maps Javascript library so it doesn’t have to be handled manually in every place where
Google Maps React component (like Map or Marker) is used. In this particular example, GoogleApiWrapper creates a wrapper
component class that behaves in the following way:
- it will display a placeholder "Loading" component and trigger Google Maps script loading and initialisation
- when the script loading and initialisation is complete it will replace "Loading" placeholder with the wrapped component
4.13.1. Fulcro and React HOC
So what’s the issue with using React HOC in Fulcro Interop: * Fulcro will embed React JS components (ones created by HOC) * React JS HOC will wrap Fulcro components
In the first case React JS components (like these from google-maps-react) expect props to be plain JavaScript objects, not ClojureScript maps. Fulcro components pass ClojureScript to nested components thus props need to be converted. This part is described in Fulcro Book’s chapter on Factory Functions for JS React Components. All we need to do is to have a factory function that will do the conversion. For example:
(ns hoc-example
(:require
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]
["google-maps-react" :refer [GoogleApiWrapper Map Marker]]))
(defn factory-apply [js-component-class]
(fn [props & children]
(apply js/React.createElement
js-component-class
(dom/convert-props props) ;; convert-props makes sure that props passed to React.createElement are plain JS object
children)))
(def ui-google-map (factory-apply Map)) ;; Fulcro wrapper factory for google-maps-react's Map component
(def ui-map-marker (factory-apply Marker)) ;; Another wrapper factory for Marker componentIn the second scenario we will have React JS component passing plain JS object props to our Fulcro component and we need to add a layer that will do JS → Cljs props conversion.
Let’s create our sample Fulcro LocationView component. It queries for view title, location’s lat and lng and google
which is the Google Maps API object required by google-maps-react components. It’s managed by google-maps-react HOC wrapper
and provided in props passed in our wrapped component.
(defsc LocationView [this {:keys [title lat lng google]}]
{:query [:lat :lng :google]}
(dom/div
(dom/h1 title)
(dom/div {:style {:width "250px" :height "250px"}}
(ui-google-map {:google google
:zoom 15
:initialCenter {:lat lat :lng lng}
:style {:width "90%" :height "90%"}}
(ui-map-marker {:position {:lat lat :lng lng}})))))Now we need to create a factory for our LocationView. It will need to sneak props as Cljs map so it’s available
for our wrapped LocationView component:
(defn hoc-wrapper-factory-apply [component-class]
(fn [props & children]
(apply js/React.createElement
component-class
#js {:hocFulcroCljPropsPassthrough props}
children)))We also need LocationView factory that will get JS props received from HOC
and will recover our Cljs map props enhancing it also with google object provided by HOC. We use "function as child" React pattern.
;; Plain Fulcro factory that will be used in our interop layer.
;; It won't be used directly in our client UI code.
(def ui-location-view-wrapped (prim/factory LocationView)
(defn ui-location-view-interop [js-props]
(let [fulcro-clj-props (.-hocFulcroCljPropsPassthrough js-props) ;; unwrapping Fulcro Cljs props wrapped by hoc-factory-apply
google (.-google js-props) ;; we need to extract google object passed by google-maps-react HOC
props (assoc fulcro-clj-props :google google)] ;; final version of cljs props that has a proper format for our LocationView component
(ui-location-view-wrapped props)))Now we can finally create a factory for LocationView component that will be used in our client UI code:
(def ui-location-view
;; GoogleApiWrapper is a function returning HOC with specified configuration parameters like API key
;; Notice that it's a plain JS function thus it requires its options to be plain JS map thus #js usage
(let [hoc (GoogleApiWrapper #js {:apiKey "AIzaSyDAiFHA9fwVjW83jUFjgL43D_KP9EFcIfE"})
WrappedLocationView (hoc ui-location-view-interop)]
(hoc-wrapper-factory-apply WrappedLocationView)))Now we can use our LocationView in our views:
(ui-location-view {:lat 37.778519 :lng -122.405640})4.13.2. Reusable HOC factory
utils-hoc namespace presented below provides a reusable hoc-factory that can be used to handle all
the boilerplate code and interop gluing. It supports :extra-props-fn in the opts argument that can be
used to customize the final props passed to the wrapped component. The code below shows its usage where google value
from js-props (injected by google-maps-react HOC wrapper) needs to be propagated under :google entry in Cljs
props passed to the wrapped LocationView component.
(ns utils.hoc
(:require
goog.object
[fulcro.client.primitives :as prim]))
(defn hoc-factory
"Creates a factory for HOC wrapped component class.
extra-props-fn allows for additional customization of props passed to the wrapped component. It will be provided
plain js-props and cljs-props unwrapped from js-props and must return cljs-props with modified contents if needed."
([hoc-wrapper-fn wrapped-component-class]
(hoc-factory hoc-wrapper-fn wrapped-component-class nil))
([hoc-wrapper-fn wrapped-component-class {:keys [extra-props-fn]}]
(let [cljs-props-key (name (gensym "fulcro-cljs-props"))
wrapped-component-factory (prim/factory wrapped-component-class)
js->clj-props-interop (fn js->clj-props-interop [js-props]
(let [clj-props (goog.object/get js-props cljs-props-key)
props (if extra-props-fn
(extra-props-fn js-props clj-props)
clj-props)]
(wrapped-component-factory props)))
hoc-wrapped-component-class (hoc-wrapper-fn js->clj-props-interop)]
(fn [props & children]
(apply js/React.createElement
hoc-wrapped-component-class
(js-obj cljs-props-key props)
children)))))
(comment
"Example usage"
(defsc LocationView [this {:keys [lat lon google]}]
{:query [:lat :lon :google]}
(dom/div {:style {:width "250px" :height "250px"}}
(ui-google-map {:zoom 15
:google google
:initialCenter {:lat lat :lng lon}
:style {:width "90%" :height "90%"}}
(ui-map-marker {:position {:lat lat :lng lon}}))))
(def google-maps-hoc (gmaps/google-api-wrapper #js {:apiKey "AIzaSyDAiFHA9fwVjW83jUFjgL43D_KP9EFcIfE"}))
(def ui-location-view
(hoc-factory
google-maps-hoc
LocationView
{:extra-props-fn (fn propagate-google-api [js-props cljs-props]
(assoc cljs-props :google (goog.object/get js-props "google")))}))
(ui-location-view {:lat 37.778519 :lng -122.405640}))4.14. The defui Macro (Fulcro 1.x. Legacy support in 2.x)
The defui macro generates a React component. It does the same thing as the
defsc macro, but looks more like a defrecord and is a bit more OO in style. It
does not error-check your work, nor does it allow you to destructure incoming data
over the body or options; however, it is syntax-comptible with Om Next so if you’re
porting from that library it can be useful.
It is 100% compatible with the React ecosystem. The macro is intended
to look a bit like a class declaration, and borrows generation notation style from defrecord. There is no
minimum required list of methods (e.g. you don’t even have to define render). This latter fact is useful
for cases where you want a component for server queries and database normalization, but not for rendering.
4.14.1. React (Object) methods
defui is aware of the following React-centric methods, which you can override:
(defui MyComponent
Object
(initLocalState [this] ...)
(shouldComponentUpdate [this next-props next-state] ...)
(componentWillReceiveProps [this next-props] ...)
(componentWillUpdate [this next-props next-state] ...)
(componentDidUpdate [this prev-props prev-state] ...)
(componentWillMount [this] ...)
(componentDidMount [this] ...)
(componentWillUnmount [this] ...)
(render [this] ...))See React Lifecycle Examples for some specific examples, and the React documentation for a complete description of each of these.
|
Note
|
Fulcro does override shouldComponentUpdate to short-circuit renders of a component whose props have not changed. You
generally do not want to change this to make it render more frequently; however, when using Fulcro with
libraries like D3 that want to "own" the portion of the DOM they render you may need to make it so that
React never updates the component once mounted (by returning false always). The Developer’s Guide shows an example
of this in the UI section.
|
4.14.2. The static Protocol Qualifier
defui supports implementations of protocols in a static context. It basically
means that you’d like the methods you’re defining to go on the class (instead of instance), but conform to the
given protocol. There is no Java analogue for this, but in Javascript the classes themselves are open.
|
Warning
|
Since there is no JVM equivalent of implementing static methods, a hack is used internally where the
protocol methods are placed in metadata on the resulting symbol. This is the reason functions like
get-initial-state exist. Calling the protocol (e.g. initial-state) in Javascript will work, but if you
try that when doing server-side rendering on the JVM, it will blow up.
|
4.14.3. IQuery and Ident
There are two core protocols for supporting a component’s data in the graph database. They work in tandem to find data in the database for the component, and also to take data (e.g. from a server response or initial state) and normalize it into the database.
Both of these protocols must be declared static. The reason for this is initial normalization and query: The system has to be able to ask components about their ident and query generation in order to turn a tree of data into a normalized database.

Queries must be composed towards the root component (so you end up with a UI query that can pull the entire tree of data for the UI).
(defui ListItem
static prim/IQuery
(query [this] [:db/id :item/label])
static prim/Ident
(ident [this props] [:list-item/by-id (:db/id props)])
...)
(defui List
static prim/IQuery
(query [this] [:db/id {:list/items (prim/get-query ListItem)}])
static prim/Ident
(ident [this props] [:list/by-id (:db/id props)])
...)
;; queries compose up to rootNotes on the IQuery Protocol
Even though the method itself is declared statically, there are some interesting things about the query method:
-
Once mounted, a component can have a dynamic query. This means calling
(prim/get-query this)will return either the static query, or whatever has been set on that component via(prim/set-query! …). -
The
get-queryaccessor method not only helps with server-side invocation, it annotates the query with metadata that includes the component info. This is what makes normalization work.
Some rules about the query itself:
-
A query must not be stolen from another component (even if it seems more DRY):
(defui PersonView1 static prim/IQuery (query [this] (prim/get-query PersonView2)) ;; WRONG!!!!This is wrong because the query will end up annotated with
PersonView2’s metadata. Never use the return value of `get-queryas the return value for your ownquery. -
The query will be structured with joins to follow the UI tree. In this manner the render and query follow form. If you query for some subcomponent’s data, then you should pass that data to that component’s factory function for rendering.
Notes on the Ident Protocol
The ident of a component is often needed in mutations, since you’re always manipulating the graph. To avoid typos, it is generally recommended that you write a function like this:
(defn person-ident [id-or-props]
(if (map? id-or-props)
[:person/by-id (:db/id id-or-props)]
[:person/by-id id-or-props]))and use that in both your component’s ident implementation and all of your mutations:
(defui Person
static prim/Ident
(ident [this props] (person-ident props)))
...
(defmutation change-name [{:keys [id name]}]
(action [{:keys [state]}]
(let [name-path (conj (person-ident id) :person/name)]
(swap! state assoc-in name-path name))))4.14.4. Om Next Compatibility
Fulcro’s defui is identical in syntax to Om Next’s defui. Porting
Om Next UI code to Fulcro is a simple matter of changing namespaces.
5. EQL — The Query and Mutation Language
Before reading this chapter you should make sure you’ve read The Graph Database Section. It details the low-level format of the application state, and talks about general details that are referenced in this chapter.
In Fulcro all data is queried and manipulated from the UI using the EDN Query Language (EQL). EQL is a subset of Datomic’s pull query syntax with extensions for unions and mutations. A query is a graph walk, so it is a relative notation: it must start at some specific spot, but that spot is not always named in the query itself. On the client side the starting point is usually the root node of your database. Thus, a complete query from the Root UI component will be a graph query that can start at the root node of the database.
However, you’ll note that any query fragment is implied to be relative to where we are in the walk of the graph
database. This is important to understand: no component’s query can just be grabbed and run against the database
as-is. Then again, if you know the ident of a component, then you can start at that table entry in the database
and go from there.
The mutation portion of the language is a data representation of the abstract actions you’d like to take on the data model. It is intended to be network agnostic: The UI need not be aware that a given mutation does local-only modifications and/or remote operations against any number of remote servers. As such, the mutations, like queries, are simply data. Data that can be interpreted by local logic, or data that can be sent over the wire to be interpreted by a server.
Queries can either be a vector or a map of vectors. The former is a regular component query, and the latter is known as a union query. Union queries are useful when you’re walking a graph edge and the target could be one of many different kinds of nodes, so you’re not sure which query to use until you actually are walking the graph.
5.1. Properties
The simplest thing to query are properties "right here" in the relative node of the graph. Properties are queried by a simple keyword. Their values can be any scalar data value that is serializable in EDN.
The query
[:a :b]is asking for the properties known as :a and :b at the "current node" in the graph traversal.
5.2. Joins
A join represents a traversal of an edge to another node in the graph. The notation is a map with a single key (the local key on the current node that holds the "pointer" to another node) whose single value is the query for the remainder of the graph walk:
[{:children (prim/get-query Child)}]The query itself cannot specify that this is a to-one or to-many join. The data in the database graph itself determines the arity when the query is being run. Basically, if walking the join property leads to a vector of links, it is to-many. If it leads to a single link, then it is to-one. Rendering the data is going to have the same concern so the arity of the relation more strongly affects the rendering code.
Joins should always use get-query to get the next component in the graph. This annotates (with metadata) the sub-query
so that normalization can work correctly.
5.3. Unions
Unions represent a map of queries, only one of which applies at a given graph edge. This is a form of dynamic query that adjusts based on the actual linkage of data. Unions cannot stand alone. They are meant to select one of many possible alternate queries when a link (to-one or to-many join) in the graph is reached. Unions are always used in tandem with a join, and can therefore not be used on root-level components. The union query itself is a map of the possible queries:
(defsc PersonPlaceOrThingUnion [this props]
; lambda form required for unions (a limitation of the error checking routines in defsc)
{:query (fn [] {:person/by-id (prim/get-query Person)
:place/by-id (prim/get-query Place)
:thing/by-id (prim/get-query Thing)})}
...)and such a query must be joined by a parent component. Therefore, you’ll always end up with something like this:
(defsc Parent [this props]
{:query [{:person-place-or-thing (prim/get-query PersonPlaceOrThingUnion)}]})Union queries take a little getting used to because there are a number of rules to follow when using them in order for everything to work correctly (normalization, queries, and rendering).
Here is what a graph database might look like for the above query assuming we started at Parent:
{ :person-place-or-thing [:place/by-id 3]
:place/by-id { 3 { :id 3 :location "New York" }}}The query would start at the root. When it saw the join it would detect a union. The union would be resolved
by looking at the first element of the ident in the database (in this case :place from [:place 3]). That keyword
would then be used to select the query from the subcomponent union (in this example, (prim/get-query Place)).
Processing of the query then continues as normal as if the join was just on Place.
A to-many linkage works just as well:
{ :peron-place-or-thing [[:person/by-id 1] [:place/by-id 3]]
:person/by-id { 1 { :id 1 :name "Julie" }}
:place/by-id { 3 { :id 3 :location "New York" }}}and now you have a mixed to-many relationship where the correct sub-query will be used for each item in turn.
Normalization of unions requires that the union component itself have an ident function that can properly generate idents for all of the possible kinds of things that could be found. Often this means that you’ll need to encode some kind of type indicator in the data itself.
Say you had this incoming tree of data:
{:person-place-or-thing [ {:id 1 :name "Joe"} {:id 3 :location "New York"} ]}In order to normalize this correctly we need to end up with the correct person and place idents. The resulting
ident function might look like this:
(defsc PersonPlaceOrThingUnion [this props]
{:ident (fn []
(cond
(contains? props :name) [:person/by-id (:id props)]
(contains? props :location) [:place/by-id (:id props)]
:else [:thing/by-id (:id props)]))}
...)Often it is easier to just include a :type field so that ident can look up both the type and id.
Rendering the correct thing in the UI of the union component has the same concern: you must detect what
kind of data (among the options) that you actually receive, and pass that on to the correct child factory (e.g.
ui-person, ui-place, or ui-thing. This is most commmonly done with a simple case statement.
5.3.1. Demo – Using Unions as a UI Type Selector
|
Important
|
There is an older defrouter that is supported but no longer recommended. It has been superceeded by the
more functional macro called defsc-router in the same namespace in Fulcro 2.6.18+.
|
The fulcro.client.routing/defsc-router macro (2.6.18+) emits a union component that can be switched to point at any kind
of component that it knows about. The support for parameterized routers in the routing tree makes it possible
to very easily reuse the UI router as a component that can show one of many screens in the same location.
This is particularly useful when you have a list of items that have varying types, and you’d like to, for example, show the list on one side of the screen and the detail on the other.
To write such a thing one would follow these steps:
-
Create one component for each item type that represents how it will look in the list.
-
Create one component for each item type that represents the fine detail view for that item.
-
Join (1) together into a union component and use it in a component that shows them as a list. In other words the union will represent a to-many edge in your graph. Remember that unions cannot stand alone, so there will be a union component (to switch the UI) and a list component to iterate through the items.
-
Combine the detail components from (2) into a
defsc-router(e.g. with ID :detail-router). -
Create a routing tree that includes the :detail-router, and parameterize both elements of the target ident (kind and id)
-
Hook a click event from the items to a
route-tomutation, and send route parameters for the kind and id.
The output of the macro:
(defsc-router ItemDetail [this props]
{:router-id :detail-router
:ident (fn [] (item-ident props))
:default-route PersonDetail
:router-targets {:person/by-id PersonDetail
:place/by-id PlaceDetail
:thing/by-id ThingDetail}}
(dom/div "Route not set"))is roughly this (cleaned up from macro output):
(defsc ItemDetail-Union [this props]
{:initial-state [clz params] (prim/get-initial-state PersonDetail params)) ;; defaults to the first one listed
:ident [this props] (item-ident props))
:query (fn [] {:person/by-id (prim/get-query PersonDetail),
:place/by-id (prim/get-query PlaceDetail),
:thing/by-id (prim/get-query ThingDetail)}}
(let [page (first (prim/get-ident this))]
(case page
:person/by-id ((prim/factory PersonDetail) (prim/props this))
:place/by-id ((prim/factory PlaceDetail) (prim/props this))
:thing/by-id ((prim/factory ThingDetail) (prim/props this))
(dom/div (str "Cannot route: Unknown Screen " page))))
(defsc ItemDetail [this props]
{:initial-state (fn [params] {:fulcro.client.routing/id :detail-router
:fulcro.client.routing/current-route (prim/get-initial-state ItemDetail-Union params)})
:ident (fn [] [:fulcro.client.routing.routers/by-id :detail-router])
:query [this] [:fulcro.client.routing/id {:fulcro.client.routing/current-route (prim/get-query ItemDetail-Union)}]}
(let [computed (prim/get-computed this)
props (:fulcro.client.routing/current-route (prim/props this))
props-with-computed (prim/computed props computed)]
((prim/factory ItemDetail-Union) props-with-computed)))))You can see that this just defines a union whose "selection" is controlled by the :current-route property!
Here is a complete working example that uses this to make a UI around displaying things of various types:
(ns book.queries.union-example-1
(:require [fulcro.client.dom :as dom]
[fulcro.client.routing :as r :refer [defsc-router]]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client :as fc]
[fulcro.ui.bootstrap3 :as b]
[fulcro.ui.elements :as ele]
[fulcro.client.cards :refer [defcard-fulcro]]))
(defn item-ident
"Generate an ident from a person, place, or thing."
[props] [(:kind props) (:db/id props)])
(defn item-key
"Generate a distinct react key for a person, place, or thing"
[props] (str (:kind props) "-" (:db/id props)))
(defn make-person [id n] {:db/id id :kind :person/by-id :person/name n})
(defn make-place [id n] {:db/id id :kind :place/by-id :place/name n})
(defn make-thing [id n] {:db/id id :kind :thing/by-id :thing/label n})
(defsc PersonDetail [this {:keys [db/id person/name] :as props}]
; defsc-router expects there to be an initial state for each possible target. We'll cause this to be a "no selection"
; state so that the detail screen that starts out will show "Nothing selected". We initialize all three in case
; we later re-order them in the defsc-router.
{:ident (fn [] (item-ident props))
:query [:kind :db/id :person/name]
:initial-state {:db/id :no-selection :kind :person/by-id}}
(dom/div
(if (= id :no-selection)
"Nothing selected"
(str "Details about person " name))))
(defsc PlaceDetail [this {:keys [db/id place/name] :as props}]
{:ident (fn [] (item-ident props))
:query [:kind :db/id :place/name]
:initial-state {:db/id :no-selection :kind :place/by-id}}
(dom/div
(if (= id :no-selection)
"Nothing selected"
(str "Details about place " name))))
(defsc ThingDetail [this {:keys [db/id thing/label] :as props}]
{:ident (fn [] (item-ident props))
:query [:kind :db/id :thing/label]
:initial-state {:db/id :no-selection :kind :thing/by-id}}
(dom/div
(if (= id :no-selection)
"Nothing selected"
(str "Details about thing " label))))
(defsc PersonListItem [this
{:keys [db/id person/name] :as props}
{:keys [onSelect] :as computed}]
{:ident (fn [] (item-ident props))
:query [:kind :db/id :person/name]}
(dom/li {:onClick #(onSelect (item-ident props))}
(dom/a {:href "javascript:void(0)"} (str "Person " id " " name))))
(def ui-person (prim/factory PersonListItem {:keyfn item-key}))
(defsc PlaceListItem [this {:keys [db/id place/name] :as props} {:keys [onSelect] :as computed}]
{:ident (fn [] (item-ident props))
:query [:kind :db/id :place/name]}
(dom/li {:onClick #(onSelect (item-ident props))}
(dom/a {:href "javascript:void(0)"} (str "Place " id " : " name))))
(def ui-place (prim/factory PlaceListItem {:keyfn item-key}))
(defsc ThingListItem [this {:keys [db/id thing/label] :as props} {:keys [onSelect] :as computed}]
{:ident (fn [] (item-ident props))
:query [:kind :db/id :thing/label]}
(dom/li {:onClick #(onSelect (item-ident props))}
(dom/a {:href "javascript:void(0)"} (str "Thing " id " : " label))))
(def ui-thing (prim/factory ThingListItem item-key))
(defsc-router ItemDetail [this props]
{:router-id :detail-router
:ident (fn [] (item-ident props))
:default-route PersonDetail
:router-targets {:person/by-id PersonDetail
:place/by-id PlaceDetail
:thing/by-id ThingDetail}}
(dom/div "No route"))
(def ui-item-detail (prim/factory ItemDetail))
(defsc ItemUnion [this {:keys [kind] :as props}]
{:ident (fn [] (item-ident props))
:query (fn [] {:person/by-id (prim/get-query PersonListItem)
:place/by-id (prim/get-query PlaceListItem)
:thing/by-id (prim/get-query ThingListItem)})}
(case kind
:person/by-id (ui-person props)
:place/by-id (ui-place props)
:thing/by-id (ui-thing props)))
(def ui-item-union (prim/factory ItemUnion {:keyfn item-key}))
(defsc ItemList [this {:keys [items]} {:keys [onSelect]}]
{
:initial-state (fn [p]
; These would normally be loaded...but for demo purposes we just hand code a few
{:items [(make-person 1 "Tony")
(make-thing 2 "Toaster")
(make-place 3 "New York")
(make-person 4 "Sally")
(make-thing 5 "Pillow")
(make-place 6 "Canada")]})
:ident (fn [] [:lists/by-id :singleton])
:query [{:items (prim/get-query ItemUnion)}]}
(dom/ul
(map (fn [i] (ui-item-union (prim/computed i {:onSelect onSelect}))) items)))
(def ui-item-list (prim/factory ItemList))
(defsc Root [this {:keys [item-list item-detail]}]
{:query [{:item-list (prim/get-query ItemList)}
{:item-detail (prim/get-query ItemDetail)}]
:initial-state (fn [p] (merge
(r/routing-tree
(r/make-route :detail [(r/router-instruction :detail-router [:param/kind :param/id])]))
{:item-list (prim/get-initial-state ItemList nil)
:item-detail (prim/get-initial-state ItemDetail nil)}))}
(let [; This is the only thing to do: Route the to the detail screen with the given route params!
showDetail (fn [[kind id]]
(prim/transact! this `[(r/route-to {:handler :detail :route-params {:kind ~kind :id ~id}})]))]
; devcards, embed in iframe so we can use bootstrap css easily
(ele/ui-iframe {:frameBorder 0 :height "300px" :width "100%"}
(dom/div {:key "example-frame-key"}
(dom/style ".boxed {border: 1px solid black}")
(dom/link {:rel "stylesheet" :href "bootstrap-3.3.7/css/bootstrap.min.css"})
(b/container-fluid {}
(b/row {}
(b/col {:xs 6} "Items")
(b/col {:xs 6} "Detail"))
(b/row {}
(b/col {:xs 6} (ui-item-list (prim/computed item-list {:onSelect showDetail})))
(b/col {:xs 6} (ui-item-detail item-detail))))))))5.4. Mutations
Mutations are also just data, as we mentioned earlier. However, they are intended to look like single- argument function calls where the single argument is a map of parameters:
[(do-something)]The main concern is that this expression, in normal Clojure, will be evaluated because it contains a raw list.
In order to keep it data, one must quote expressions with mutations. Of course you may use syntax quoting
or literal quoting. Usually we recommend namespacing your mutations (with defmutation) and then using
syntax quoting to get reasonably short expressions:
(ns app.mutations)
(defmutation do-something [params] ...)(ns app.ui
(:require [app.mutations :as am]))
...
(prim/transact! this `[(am/do-something {})])We talked about syntax quoting transactions in the Getting Started chapter. You may want to review that or just read more online about Clojure syntax quoting.
The parameter map on mutations is optional, but recommended, if you’re using IDE support since the IDE will always see mutations as if they were function calls with an arity of one.
5.5. Parameters
Most of the query elements also support a parameter map. In Fulcro these are mainly useful when sending a query to the server, and it is rare you will write such a query "by hand". However, for completeness you should know what these look like. Basically, you just surround the property or join with parentheses, and add a map as parameters. This is just like mutations, except instead of a symbol as the first element of the list it is either a keyword (prop) or a map (join).
Thus a property can be parameterized:
[(:prop {:x 1})]This would cause, for example, a server’s query processing to see {:x 1} in the params when handling the read
for :prop.
A join is similarly parameterized:
[({:child (prim/get-query Child)} {:x 1})]with the same kind of effect.
|
Note
|
The plain list has the same requirement as for mutations: quoting. Generally syntax quoting is again the best choice, since you’ll often need unquoting. For example, the join example above would actually be written in code as: |
...
(query [this] `[({:child ~(prim/get-query Child)} {:x 1})])
...to avoid trying to use the map as a function for execution, yet allowing the nested get-query to run and embed
the proper subquery.
5.6. Queries on Idents
Idents are valid in queries as a plain prop or a join. When used alone (not in a join) this will pull a table entry from the database without normalizing it or following any subquery:
[ [:person/by-id 1] ]results in something like this:
(defsc Phone [this props]
{:query [:id :phone/number]
:ident [:phone/by-id :id]}
...)
(defsc Person [this props]
{:query [:id {:person/phone (prim/get-query Phone)}]
:ident [:person/by-id :id]}
...)
(defsc X [this props]
{:query [ [:person/by-id 1] ] } ; query just for the ident
(let [person (get props [:person/by-id 1]) ; NOT get-in. The key of the result is an ident
...
; person contains {:id 1 :person/phone [:phone/by-id 4]}This is not typically what you want because you’d typically want it to follow the graph links (resolving phone number).
Therefore these kinds of queries are normally done via a join:
(defsc X [this props]
{:query [{[:person/by-id 1] (prim/get-query Person)}]}
(let [person (get props [:person/by-id 1])
...
; person contains {:id 1 :person/phone {:phone/id 4 :phone/number "555-1212"}}This has the effect of "re-rooting" the graph walk at that ident’s table entry and continuing from there for the rest of the subtree. In fact this is how Fulcro’s ident-based rendering optimization works.
5.7. Link Queries
There are times when you want to start "back at the root" node. This is useful for pulling data that has a singleton representation in the root node itself. For example, the current UI locale or currently logged-in user. There is a special notation for this the looks like an ident without an ID:
[ [:ui/locale '_] ]This component query would result in :ui/locale in your props (not an ident) with a value that came from the
overall root node of the database. Of course, denormalization just requires you use a join:
[ {[:current-user '_] (prim/get-query Person)} ]would pull :current-user into the component’s props with a continued walk of the graph. In other words this is
just like the ident join, except the special symbol _ indicates there is only one of them and it is in the root
node.
5.8. A Warning About Ident and Link Queries
Components can query for whatever they want, and sometimes it is useful to write components that only query for things "elsewhere" in the database:
(defsc LocaleSwitcher [this {:keys [ui/locale]}]
{:query [[:ui/locale '_]]}
(dom/div ...))When the database is constructed for such components they will have no state of their own.
Sadly, even if you compose it into your UI properly it may not receive any data:
(defsc Root [this {:keys [locale-switcher]}]
{:query [{:locale-switcher (prim/get-query LocaleSwitcher)}]}
(ui-locale-switcher locale-switcher)) ; data comes back nil!!!The problem is that the query engine walks the database and query in tandem. When it sees a join
(:locale-switcher in this case) it goes looking for an entry in the database at the current location
(root node in this case) to process the subquery against. If it finds an ident it follows it and processes
the subquery. If it is a map it uses that to fulfill the subquery. If it is a vector then it processes the
subquery against every entry. But if it is missing then it stops.
The fix is simple: make sure the component has a presence in the database, even if empty:
(defsc LocaleSwitcher [this {:keys [ui/locale]}]
{:query [[:ui/locale '_]]
:initial-state {}} ; empty map
(dom/div ...))
(defsc Root [this {:keys [locale-switcher]}]
{:query [{:locale-switcher (prim/get-query LocaleSwitcher)}]
:initial-state (fn [params] {:locale-switcher (prim/get-initial-state LocaleSwitcher)})} ; empty map from child
(ui-locale-switcher locale-switcher)) ; link query data is found/passed5.8.1. Using Shared State
An alternative to ident and link queries is shared state. The first thing to note is that it is not a complete replacement for link queries. It is a low-level feature that is meant for two basic scenarios:
-
Data that needs to be visible to all components, but never changes once the app is mounted.
-
Data that is derived from the UI props (from root) or globals, but only updates on root-level renders (not component-local updates).
The first use-case might be handy if you pass some data to your mount through the HTML page itself. The latter is useful for data that affects everything in your application, such as the current user.
The primary thing to remember is that components that look at shared state will not see updates unless a
root render occurs with those updates. This typically means calling prim/force-root-render!.
Say we wanted all components to be able to see :pi (a constant) and :current-user (a value from
the database). We could declare this as follows:
(fc/make-fulcro-client
{:reconciler-options {:shared {:pi 3.14} ; never changes
:shared-fn #(select-keys % :current-user)}}) ; updates on root renderNow any component can access these as follows:
(defsc C [this props]
(let [{:keys [pi current-user]} (prim/shared this)]
; current-user will be DEnormalized...it comes from the root props (Root must query for it still)
...))|
Warning
|
Remember that this is not equivalent to a link query for [:current-user '_]. There are two differences.
The first is that pulling :current-user still requires that your root component query for it (or it
won’t even be in the props). Second, the shared value will not visibly change until a root render happens, where
link queries can refresh locally with a component. The final difference is that if you use data in
your shared-fn that is derived from anything other than the state database then it will not work correctly
in the history support viewer.
|
5.9. Recursive Queries
EQL includes support for recursive queries. Recursion is always expressed on a join,
and it always means that the recursive item has the same type as the component you’re on.
There are two notations for this: … and a number. The former means "recurse until there are no more links
(circular detection is included to prevent infinite loops)", and the other is the recursion limit:
|
Note
|
At the time of this writing you must use the lamba mode of defsc for queries that include recursion.
|
The following demo (with source) demonstrates the core basics of recursion:
(ns book.queries.recursive-demo-1
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]))
(defn make-person
"Make a person data map with optional children."
[id name children]
(cond-> {:db/id id :person/name name}
children (assoc :person/children children)))
(declare ui-person)
; The ... in the query means there will be children of the same type, of arbitrary depth
; it is equivalent to (prim/get-query Person), but calling get query on yourself would
; lead to infinite compiler recursion.
(defsc Person [this {:keys [:person/name :person/children]}]
{:query (fn [] [:db/id :person/name {:person/children '...}])
:initial-state (fn [p]
(make-person 1 "Joe"
[(make-person 2 "Suzy" [])
(make-person 3 "Billy" [])
(make-person 4 "Rae"
[(make-person 5 "Ian"
[(make-person 6 "Zoe" [])])])]))
:ident [:person/by-id :db/id]}
(dom/div
(dom/h4 name)
(when (seq children)
(dom/div
(dom/ul
(map (fn [p]
(ui-person p))
children))))))
(def ui-person (prim/factory Person {:keyfn :db/id}))
(defsc Root [this {:keys [person-of-interest]}]
{:initial-state {:person-of-interest {}}
:query [{:person-of-interest (prim/get-query Person)}]}
(dom/div
(ui-person person-of-interest)))5.9.1. Circular Recursion
It is perfectly legal to include recursion in your graph, and it is equally fine to query for it. The query engine will automatically stop if a loop is detected.
However, this is not the whole story. You see, components can be updated in a relative fasion when all optimizations are enabled. This means that a refresh could happen anywhere in the (recursive) UI, and the query would run until it detects the loop again. This can lead to funny-looking results.
The demo below lets you modify people and their spouse (a circular relation). Try it out and you’ll see that something isn’t quite right (try making Sally older):
(ns book.queries.recursive-demo-2
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.mutations :refer [defmutation]]
[fulcro.client.dom :as dom]))
(declare ui-person)
(defmutation make-older [{:keys [id]}]
(action [{:keys [state]}]
(swap! state update-in [:person/by-id id :person/age] inc)))
(defsc Person [this {:keys [db/id person/name person/spouse person/age]}]
{:query (fn [] [:db/id :person/name :person/age {:person/spouse 1}]) ; force limit the depth
:initial-state (fn [p]
; this does look screwy...you can nest the same map in the recursive position,
; and it'll just merge into the one that was previously normalized during normalization.
; You need to do this or you won't get the loop in the database.
{:db/id 1
:person/name "Joe"
:person/age 20
:person/spouse {:db/id 2
:person/name "Sally"
:person/age 22
:person/spouse {:db/id 1 :person/name "Joe"}}})
:ident [:person/by-id :db/id]}
(dom/div
(dom/div "Name:" name)
(dom/div "Age:" age
(dom/button {:onClick
#(prim/transact! this `[(make-older {:id ~id})])} "Make Older"))
(when spouse
(dom/ul
(dom/div "Spouse:" (ui-person spouse))))))
(def ui-person (prim/factory Person {:keyfn :db/id}))
(defsc Root [this {:keys [person-of-interest]}]
{:initial-state {:person-of-interest {}}
:query [{:person-of-interest (prim/get-query Person)}]}
(dom/div
(ui-person person-of-interest)))The problem is that when you touch Sally the UI refresh updates just that component; however, that component has a recursive query of depth 1, so it ends up returning Joe as her spouse! This is technically correct, but almost certainly isn’t what you want!
The fix is equally simple: calculate depth and pass it to the child. Use the calculated depth to prevent the extra rendering when local refresh gives you data you don’t need. The demo below has this fix.
(ns book.queries.recursive-demo-3
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.mutations :refer [defmutation]]
[fulcro.client.dom :as dom]))
(declare ui-person)
(defmutation make-older [{:keys [id]}]
(action [{:keys [state]}]
(swap! state update-in [:person/by-id id :person/age] inc)))
; We use computed to track the depth. Targeted refreshes will retain the computed they got on
; the most recent render. This allows us to detect how deep we are.
(defsc Person [this
{:keys [db/id person/name person/spouse person/age]} ; props
{:keys [render-depth] :or {render-depth 0}}] ; computed
{:query (fn [] [:db/id :person/name :person/age {:person/spouse 1}]) ; force limit the depth
:initial-state (fn [p]
{:db/id 1 :person/name "Joe" :person/age 20
:person/spouse {:db/id 2 :person/name "Sally"
:person/age 22
:person/spouse {:db/id 1 :person/name "Joe"}}})
:ident [:person/by-id :db/id]}
(dom/div
(dom/div "Name:" name)
(dom/div "Age:" age
(dom/button {:onClick
#(prim/transact! this `[(make-older {:id ~id})])} "Make Older"))
(when (and (= 0 render-depth) spouse)
(dom/ul
(dom/div "Spouse:"
; recursively render, but increase the render depth so we can know when a
; targeted UI refresh would accidentally push the UI deeper.
(ui-person (prim/computed spouse {:render-depth (inc render-depth)})))))))
(def ui-person (prim/factory Person {:keyfn :db/id}))
(defsc Root [this {:keys [person-of-interest]}]
{:initial-state {:person-of-interest {}}
:query [{:person-of-interest (prim/get-query Person)}]}
(dom/div
(ui-person person-of-interest)))5.9.2. Duplicates and Recursion
Of course it is perfectly fine for there to be multiple edges in your graph that point
to the same node. Below is a recursive bullet list example. We’ve intentionally nested
item B.1 under B and D so you can see that it all works itself out.
Normalization of initial state (which must be a tree) is perfectly happy to see duplcate entries. It simply merges the multiple copies into the same normalized entry in the table.
Since the two entries merge to the same entry, it also means the modifications will
be shared among them. Try checking item B.1 in either location.
(ns book.queries.recursive-demo-bullets
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.client.dom :as dom]
[clojure.string :as str]))
(declare ui-item)
(defsc Item [this {:keys [ui/checked? item/label item/subitems]}]
{:query (fn [] [:ui/checked? :db/id :item/label {:item/subitems '...}])
:ident [:item/by-id :db/id]}
(dom/li
(dom/input {:type "checkbox"
:checked (if (boolean? checked?) checked? false)
:onChange #(m/toggle! this :ui/checked?)})
label
(when subitems
(dom/ul
(map ui-item subitems)))))
(def ui-item (prim/factory Item {:keyfn :db/id}))
(defsc ItemList [this {:keys [db/id list/items] :as props}]
{:query [:db/id {:list/items (prim/get-query Item)}]
:ident [:list/by-id :db/id]}
(dom/ul
(map ui-item items)))
(def ui-item-list (prim/factory ItemList {:keyfn :db/id}))
(defsc Root [this {:keys [list]}]
{:initial-state (fn [p]
{:list {:db/id 1
:list/items [{:db/id 2 :item/label "A"
:item/subitems
[{:db/id 7
:item/label "A.1"
:item/subitems
[{:db/id 8
:item/label "A.1.1"
:item/subitems []}]}]}
{:db/id 3
:item/label "B"
:item/subitems
[{:db/id 6 :item/label "B.1"}]}
{:db/id 4
:item/label "C"
:item/subitems []}
{:db/id 5
:item/label "D"
; just for fun..nest a dupe under D
:item/subitems [{:db/id 6 :item/label "B.1"}]}]}})
:query [{:list (prim/get-query ItemList)}]}
(dom/div
(ui-item-list list)))5.10. The AST
You can convert any expression of EQL into an AST (abstract syntax tree) and vice
versa. This lends itself to doing complex parsing of the query (typically on the server). The functions
of interest are fulcro.client.primitives/query→ast and ast→query.
There are many uses for this. One such use might be to convert the graph expression into another form. For
example, say you wanted to run a query against an SQL database. You could write an algorithm that translates
the AST into a series of SQL queries to build the desired result. The AST is always available as one
of the parameters in the mutation/query env on the client and server.
Another use for the AST is in mutations targeted at a remote: it turns out you can morph a mutation before sending it to the server.
5.10.1. Morphing Mutations
The most common use of the AST is probably adding parameters that the UI is unaware need to be sent to
a remote. When processing a mutation with defmutation (or just the raw defmethod) you will receive
the AST of the mutation in the env. It is legal to return any valid AST from the remote side of a
mutation. This has the effect of changing what will be sent to the server:
(defmutation do-thing [params]
(action [env] ...)
(remote [{:keys [ast]}] ast)) ; same effect as `true`
(defmutation do-thing [params]
(action [env] ...)
(remote [{:keys [ast]}] (prim/query->ast `[(do-other-thing)])) ; completely change what gets sent to `remote`
(defmutation do-thing [params]
(action [env] ...)
(remote [{:keys [ast]}] (assoc ast :params {:y 3}))) ; change the parametersFor more on mutations see the chapter on Handling Mutations
6. Initial Application State
When starting any application one thing has to be done before just about anything else: Establish a starting state. In Fulcro this just means generating a client-side application database (normalized). Other parts of this guide have talked about the Graph Database. You can well imagine that hand-coding one of these for a large application’s starting state could be kind of a pain. Actually, even though coding it would be a pain, it turns out that the bigger pain happens later when you want to refactor! That can become a real mess!
However, Fulcro already knows how to normalize a tree of data, and your UI is already the tree you’re interested in. So, Fulcro encourages you to co-locate initial application state with the components that need the state and compose it towards the root, just like you do for queries. This gives some nice results:
-
Your initial application state is reasoned about locally to each component, just like the queries.
-
Refactoring the UI just means modifying the local composition of queries and initial state from one place to another in the UI.
-
Fulcro understands unions (you can only initialize one branch of a to-one relation), and can scan for and initialize alternate branches.
6.1. Adding Initial State to Components
To add initial state, follow these steps:
-
For each component that should appear initially: add the
:initial-stateoption. -
Compose the components in (1) all the way to your root.
That’s it! Fulcro will automatically detect initial state on the root, and use it for the application!
|
Note
|
Pulling the initial state from a component should be done with fulcro.core/get-initial-state. Calling a static
protocol cannot work on the server, so this helper method makes server-side rendering possible for your components.
|
(defui Child
static fulcro.core/InitialAppState
(initial-state [cls params] { :x 1 }) ; set :x to 1 for this component's state
static prim/IQuery
(query [this] [:x]) ; query for :x
static prim/Ident
(ident [this props] ...) ; how to normalize
Object
(render [this]
(let [{:keys [x]} (prim/props this)] ; pull x from props
...)))
(defui Parent
static fulcro.core/InitialAppState
(initial-state [cls params] { :y 2 :child (prim/get-initial-state Child {}) }) ; set y, and compose in child's state
static prim/IQuery
(query [this] [:y {:child (prim/get-query Child)}]) ; query for :y and compose child's query
static prim/Ident
(ident [this props] ...) ; how to normalize
Object
(render [this]
(let [{:keys [y child]} (prim/props this)] ; pull y and child from props
...)))
...Notice the nice symmetry here. The initial state is (usually) a map that represents (recursively) the entity and
its children. The query is a vector that lists the "scalar" props, and joins as maps. So, in Child we have
initial state for :x and a query for :x. In the parent we have a query for the property :y and a join to
the child, and initial state for the scalar value of :y and the composed initial state of the Child. Render has
the same thing: the things you pull out of props will be the things for which you queried. Thus, all three essentially
list the same things, but in slightly different forms.
6.1.1. Initial State and Alternate Branches of Unions
The one "extra" feature that initial state support does for you is to initialize alternate branches of components that have to-one union query. Remember that a to-one relation from a union could be to any number of alternates.
Take this union query: {:person (prim/get-query Person) :place (prim/get-query Place)}
It means "if you find an ident in the graph pointing to a :person, then query for the person. If you find one
for :place, then query for a place. The problem is: if it is a to-one relation then only one can be in the
initial state tree at startup!
{ :person-or-place [:person 2]
:person {2 {:id 2 ...}}}If you look at a proposed initial state, it will make the problem more clear:
(defui Person
static prim/InitialAppState
(initial-state [c {:keys [id name]}] {:id id :name name :type :person})
...)
(defui PersonPlaceUnion
static prim/InitialAppState
(initial-state [c p] (prim/get-initial-state Person {:id 1 :name "Joe"})) ; I can only put in one of them!
static prim/IQuery
(query [this] {:person (prim/get-query Person) :place (prim/get-query Place)})
...)
(defui Parent
static prim/InitialAppState
(initial-state [c p] {:person-or-place (prim/get-initial-state PersonPlaceUnion)})
static prim/IQuery
(query [this] [{:person-or-place (prim/get-query PersonPlaceUnion)}]))This would result in a person in the initial state, but not a place.
Fulcro solves this at startup in the following manner: It pulls the query from root and walks it. If it finds
a union component, then for each branch it sees if that component (via the query metadata) has initial state. If
it does, it places it in the correct table in app state. This does not, of course, join it to anything in the graph
since it isn’t the "default branch" that was explicitly listed (in PersonPlaceUnion’s `InitialAppState).
This behavior is critical when using unions to handle UI routing, which is in turn essential for good application performance.
6.1.2. Initial State Demo
The following demo shows all of this in action.
(ns book.demos.initial-app-state
(:require
[fulcro.client.dom :as dom]
[fulcro.client :as fc]
[fulcro.client.mutations :as m]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]))
(defonce app (atom (fc/make-fulcro-client {})))
(defmethod m/mutate 'nav/settings [{:keys [state]} sym params]
{:action (fn [] (swap! state assoc :panes [:settings :singleton]))})
(defmethod m/mutate 'nav/main [{:keys [state]} sym params]
{:action (fn [] (swap! state assoc :panes [:main :singleton]))})
(defsc ItemLabel [this {:keys [value]}]
{:initial-state (fn [{:keys [value]}] {:value value})
:query [:value]
:ident (fn [] [:labels/by-value value])}
(dom/p value))
(def ui-label (prim/factory ItemLabel {:keyfn :value}))
;; Foo and Bar are elements of a mutli-type to-many union relation (each leaf can be a Foo or a Bar). We use params to
;; allow initial state to put more than one in place and have them be unique.
(defsc Foo [this {:keys [label]}]
{:query [:type :id {:label (prim/get-query ItemLabel)}]
:initial-state (fn [{:keys [id label]}] {:id id :type :foo :label (prim/get-initial-state ItemLabel {:value label})})}
(dom/div
(dom/h2 "Foo")
(ui-label label)))
(def ui-foo (prim/factory Foo {:keyfn :id}))
(defsc Bar [this {:keys [label]}]
{:query [:type :id {:label (prim/get-query ItemLabel)}]
:initial-state (fn [{:keys [id label]}] {:id id :type :bar :label (prim/get-initial-state ItemLabel {:value label})})}
(dom/div
(dom/h2 "Bar")
(ui-label label)))
(def ui-bar (prim/factory Bar {:keyfn :id}))
;; This is the to-many union component. It is the decision maker (it has no state or rendering of it's own)
;; The initial state of this component is the to-many (vector) value of various children
;; The render just determines which thing it is, and passes on the that renderer
(defsc ListItem [this {:keys [id type] :as props}]
{:initial-state (fn [params] [(prim/get-initial-state Bar {:id 1 :label "A"}) (prim/get-initial-state Foo {:id 2 :label "B"}) (prim/get-initial-state Bar {:id 3 :label "C"})])
:query (fn [] {:foo (prim/get-query Foo) :bar (prim/get-query Bar)}) ; use lambda for unions
:ident (fn [] [type id])} ; lambda for unions
(case type
:foo (ui-foo props)
:bar (ui-bar props)
(dom/p "No Item renderer!")))
(def ui-list-item (prim/factory ListItem {:keyfn :id}))
;; Settings and Main are the target "Panes" of a to-one union (e.g. imagine tabs...we use buttons as the tab switching in
;; this example). The initial state looks very much like any other component, as does the rendering.
(defsc Settings [this {:keys [label]}]
{:initial-state (fn [params] {:type :settings :id :singleton :label (prim/get-initial-state ItemLabel {:value "Settings"})})
:query [:type :id {:label (prim/get-query ItemLabel)}]}
(ui-label label))
(def ui-settings (prim/factory Settings {:keyfn :type}))
(defsc Main [this {:keys [label]}]
{:initial-state (fn [params] {:type :main :id :singleton :label (prim/get-initial-state ItemLabel {:value "Main"})})
:query [:type :id {:label (prim/get-query ItemLabel)}]}
(ui-label label))
(def ui-main (prim/factory Main {:keyfn :type}))
;; This is a to-one union component. Again, it has no state of its own or rendering. The initial state is the single
;; child that should appear. Fulcro (during startup) will detect this component, and then use the query to figure out
;; what other children (the ones that have initial-state defined) should be placed into app state.
(defsc PaneSwitcher [this {:keys [id type] :as props}]
{:initial-state (fn [params] (prim/get-initial-state Main nil))
:query (fn [] {:settings (prim/get-query Settings) :main (prim/get-query Main)})
:ident (fn [] [type id])}
(case type
:settings (ui-settings props)
:main (ui-main props)
(dom/p "NO PANE!")))
(def ui-panes (prim/factory PaneSwitcher {:keyfn :type}))
;; The root. Everything just composes to here (state and query)
;; Note, in core (where we create the app) there is no need to say anything about initial state!
(defsc Root [this {:keys [panes items]}]
{:initial-state (fn [params] {:panes (prim/get-initial-state PaneSwitcher nil)
:items (prim/get-initial-state ListItem nil)})
:query [{:items (prim/get-query ListItem)}
{:panes (prim/get-query PaneSwitcher)}]}
(dom/div
(dom/button {:onClick (fn [evt] (prim/transact! this '[(nav/settings)]))} "Go to settings")
(dom/button {:onClick (fn [evt] (prim/transact! this '[(nav/main)]))} "Go to main")
(ui-panes panes)
(dom/h1 "Heterogenous list:")
(dom/ul
(mapv ui-list-item items))))6.2. Initial State and State Progressions
If you remember from the diagram about pure rendering, then you’ll also note that this step generates the first state in that progression. Rendering any state results in the UI for that state.
An interesting note is that this model also results in a really useful property: You can take the initial state, run it though the implementation of one or more mutations, and end up with any other state. This means you can easily reason about initializing your application into any state, which is useful for things like testing and server-side rendering.
There are all sorts of very useful features that fall out of this. For example, it is also possible to record a series of "user interactions" (which can be recorded as a list of the mutations that ran) and replay those. This could be used to send a tester a sequence of steps to show recent development work, run automated demos/tests, teleport your development environment to a specific page, etc.
Writing tests against the state model and mutation implementations is a great way to unit test your application without needing to involve the UI itself at all! You can read more about that in the section on Visual Regression Testing
7. Normalization
Normalization is a central mechanism in Fulcro. It is the means by which your data trees (which you receive from component queries against servers) can be placed into your normalized graph database.
7.1. Internals
The function prim/tree→db is the workhorse that turns an incoming tree of data into normalized data (which can then
be merged into the overall database).
Imagine an incoming tree of data:
{ :people [ {:db/id 1 :person/name "Joe" ...} {:db/id 2 ...} ... ] }and the query:
[{:people (prim/get-query Person)}]which expands to:
[{:people [:db/id :person/name]}]
^ metadata {:component Person}tree→db recursively walks the data structure and query:
-
At the root, it sees
:peopleas a root key and property. It remembers it will be writing:peopleto the root. -
It examines the value of
:peopleand finds it to be a vector of maps. This indicates a to-many relationship. -
It examines the metadata on the subquery of
:peopleand discovers that the entries are represented by the componentPerson -
For each map in the vector, it calls the
identfunction ofPerson(which it found in the metadata) to get a database location. It then places the "person" values into the result viaassoc-inon the ident. -
It replaces the entries in the vector with the idents.
If the metadata was missing then it would assume the person data did not need normalization. This is why it is
critical to compose queries correctly. The query and tree of data must have a parallel structure, as should the
UI. In template mode defsc will try to check some things for you, but you must ensure that you
compose the queries correctly.
7.2. Normalization: Initial State, Server Interactions, and Mutations
The process described above is how most data interactions occur. At startup the :initial-state supplies data that
exactly matches the tree of the UI. This gives your UI some initial state to render. The normalization mechanism
described above is exaclty what happens to that initial tree when it is detected by Fulcro at startup.
Network interactions send a UI-based query (which remember is annotated with the components). The query is remembered and when a response tree of data is received (which must match the tree structure of the query), the normalization process is applied and the resulting normalized data is merged with the database.
If using websockets, it is the same thing: A server push gives you a tree of data. You could hand-normalize that data,
but actually if you know the structure of the incoming data you can easily generate a client-side query (using
defsc or defui) that can be used in conjunction with prim/tree→db to normalize that incoming data.
Mutations can do the same thing. If a new instance of some entity is being generated by the UI as a tree of data, then the query for that UI component can be used to turn it into normalized data that can be merged into the state within the mutation.
Some useful functions to know about:
-
prim/merge-component- A utility function for merging new instances of a (possibly recursive) entity state into the normalized database. Usable from within mutations. -
prim/merge-state!- A utility function for merging out-of-band (e.g. push notification) data into your application. Includes ident integration options, and honors the Fulcro merge clobbering algorithm (if the query doesn’t ask for it, then merge doesn’t affect it). Also queues rendering for affected components (derived from integration of idents). Generally not used within mutations (usemerge-componentandintegrate-ident*instead). -
prim/tree→db- General utility for normalizing data via a query and chunk of data. -
fulcro.client.mutations/integrate-ident*- A utility for adding an ident into existing to-one and to-many relations in your database. Can be used within mutations. -
fulcro.client.util/deep-merge- An implementation of merge that is recursive
8. Handling Mutations
Mutations are known by their symbol and are dispatched to the internal multimethod
fulcro.client.mutations/mutate. To handle a mutation you can do two basic things: use defmethod
to add a mutation support, or use the macro defmutation. The macro is recommended for most cases
because it namespaces the mutation, prevents some common errors, and works better with IDEs.
8.1. Stages of Mutation
There are multiple passes on a mutation: one local, and one for each possible remote. It is
technically the job of the mutation handler to return a lambda for the local pass, and a boolean (or AST)
for each remote. Returning nil from any pass means to not do anything for that concern.
For example, say you have three remotes: one for normal API, one that hits a REST API, and one for file uploads. Each would have a name, and each pass of the mutation handling would be interested in knowing what you’d like to do for the local or remote.
The mutation environment (env in the examples) contains a target that is set to a remote’s name when
the mutation is being asked for details about how to handle the mutation with respect to that remote.
For each pass the mutation is supposed to return a map whose key is :action or the name of the remote, and
whose value is the thing to do (a lambda for :action, and AST or true/false for remotes).
Summary:
-
You
transact!somewhere in the UI -
The internals call your mutation with
:targetset to nil inenv. You return a map with an:actionkey whose value is the function to run. -
The internals call your mutation once for each remote, with
:targetset. You return a map with that remote’s keyword as the key, and either a boolean or AST as the remote action. (true means send the AST for the expression sent in (1) to the remote)
8.2. Using the Multimethod Directly
Typically the multipass nature is ignored by the mutation itself, and it just returns a map containing all of the possible things that should be done. This looks like:
(defmethod fulcro.client.mutations/mutate `mutation-symbol [{:keys [state ast target] :as env} k params]
{:action (fn [] ...)
:rest-api true ; trigger this remotely on the rest API AND the normal one.
:remote true })Since the action is just data, it doesn’t matter that we "generate" it for the multiple passes. Same for the remotes.
Some common possible mistakes are:
-
You side-effect. Your mutation will be called at least two times so this is a bad idea. Side effects should be wrapped in the action.
-
You assume that the remote expression "sees" the old state (e.g. you might build an AST based on what is in app state). The local action is usually run before the remote passes, meaning the state has already changed and the remote logic is seeing the "new" client database state.
-
You forget to return a map with the correct keys (usually if you made mistake 1).
There is no guaranteed order to evaluation. Therefore if you need a value from state as it was seen when the mutation was triggered: send it as a parameter to the mutation from the UI (where you knew the old value). That way the call itself has captured the old value.
8.3. Using defmutation
defmutation is a macro that writes the multimethod for you. It looks like this:
(defmutation mutation-symbol
"docstring"
[params]
(action [{:keys [state] :as env}]
(swap! state ...))
(rest-api [env] true)
(remote [env] true))Thus it ends up looking more like a function definition. IDE’s like Cursive can be told how to resolve
the macro (as defn in this case) and will then let you read the docstrings and navigate to the definition
from the usage site in transact. This makes development a lot easier.
Another advantage is that the symbol is placed into the namespace in which it is declared (not interned, just given the namespace…it is still just symbol data). Syntax quoting can expand aliasing, which means you get a very nice tool experience at usage site:
(ns app
(:require [app.mutations :as am]))
...
(prim/transact! this `[(am/mutation-symbol {})]) ; am gets expanded to app.mutationsThe final advantage is it is harder to accidentally side-effect. The action section of defmutation
will wrap the logic in a lambda, meaning that it can read as-if you’re side-effecting, but in fact
will do the right thing.
In general these advantages mean you should generally use the macro to define mutations, but it is good to be aware that underneath is just a multimethod.
8.4. Refreshing Non-local UI
In the default rendering mode Fulcro is capable of optimizing your rendering refresh so that the bare minimum amount of activity happens in the query engine and React. The basic rules are as follows:
-
Refresh the subtree starting at the component that ran
transact!. If it was the reconciler, run from root. -
Refresh any components that share the same
identwith the component that ran the transaction. -
Refresh any component that queries for any of the data that was indicated in "follow-on" reads.
8.4.1. Parent-Child Relationships
The most common case of non-local UI refresh comes up with parent-child relationships. In these cases, the parent can be seen as a UI component in control of the children (it is responsible for telling them to render). In such cases it is usually better to reason about the management logic (i.e. deleting, reordering, etc) from the parent; however, it is commonly the case the you want the child to render some controls, such as a delete button. Thus, the control that wants to modify the state (the delete button on the item) is not local to the component that will need to refresh (the parent’s list).
The solution is simple: create a callback in the parent that can run the delete transaction and pass it through as a computed value.
In our example, we’ll assume the delete is global (removes the item from the list and the normalized table):
(m/defmutation delete-item
"Mutation: Delete an item from a list"
[{:keys [id]}]
(action [{:keys [state]}]
(swap! state
(fn [s]
(-> s
(update :items dissoc id) ; remove the item from the db (optional)
(m/remove-ident* [:lists 1 :list/items] [:items id])))))) ; remove the item from the list of identsThe source of the components for this demo are below. Make note of the use of computed.
(ns book.demos.parent-child-ownership-relations
(:require
[fulcro.client.dom :as dom]
[fulcro.client.mutations :as m]
[fulcro.client :as fc]
[fulcro.client.primitives :as prim :refer [defsc]]))
; Not using an atom, so use a tree for app state (will auto-normalize via ident functions)
(def initial-state {:ui/react-key "abc"
:main-list {:list/id 1
:list/name "My List"
:list/items [{:item/id 1 :item/label "A"}
{:item/id 2 :item/label "B"}]}})
(defonce app (atom (fc/make-fulcro-client {:initial-state initial-state})))
(m/defmutation delete-item
"Mutation: Delete an item from a list"
[{:keys [id]}]
(action [{:keys [state]}]
(swap! state
(fn [s]
(-> s
(update :items dissoc id)
(m/remove-ident* [:items id] [:lists 1 :list/items]))))))
(defsc Item [this
{:keys [item/id item/label] :as props}
{:keys [on-delete] :as computed}]
{:initial-state (fn [{:keys [id label]}] {:item/id id :item/label label})
:query [:item/id :item/label]
:ident [:items :item/id]}
(dom/li label (dom/button {:onClick #(on-delete id)} "X")))
(def ui-list-item (prim/factory Item {:keyfn :item/id}))
(defsc ItemList [this {:keys [list/name list/items]}]
{:initial-state (fn [p] {:list/id 1
:list/name "List 1"
:list/items [(prim/get-initial-state Item {:id 1 :label "A"})
(prim/get-initial-state Item {:id 2 :label "B"})]})
:query [:list/id :list/name {:list/items (prim/get-query Item)}]
:ident [:lists :list/id]}
(let [; pass the operation through computed so that it is executed in the context of the parent.
item-props (fn [i] (prim/computed i {:on-delete #(prim/transact! this `[(delete-item {:id ~(:item/id i)})])}))]
(dom/div
(dom/h4 name)
(dom/ul
(map #(ui-list-item (item-props %)) items)))))
(def ui-list (prim/factory ItemList))
(defsc Root [this {:keys [main-list]}]
{:initial-state (fn [p] {:main-list (prim/get-initial-state ItemList {})})
:query [{:main-list (prim/get-query ItemList)}]}
(dom/div (ui-list main-list)))8.4.2. Follow-on Reads
A follow-on read is a property listed in a transaction:
(transact! this `[(f) :person/name])It indicates that the given data will have changed, and therefore any on-screen component that queries for that particular data should also be refreshed when the transaction completes the optimistic update (and again after the remote interaction, if there is one).
Follow-on reads allow the developer to reason more abstractly about non-local UI refresh. They need only think about what data is changing, and not about what components might be displaying it. This allows the UI to evolve without additional concerns that refresh will be slow (due to expensive data analysis) or will become broken (because you didn’t know a component needed refresh).
(defsc Right [this {:keys [db/id right/value]}]
{:query [:db/id :right/value]}
(dom/div
; needs a follow-on read because it is updating something that is queried elsewhere...
(dom/button {:onClick #(prim/transact! this `[(ping-left {}) :left/value])} "Ping Left")
value))This model was inherited from Om Next, and it is the correct model to use when the transaction might, for example, modify opaque data that is not directly queried but which would cause a component to need a refresh; however, since most transactions run a mutation that is really more aware of what data is changing it makes quite a bit of sense for you to be able to declare this on the mutation itself.
8.4.3. Declarative Refresh
Fulcro 2.0+ supports a way of declaring follow-on reads that allows for better local reasoning: co-locate the
follow-on reads with the mutation itself. The mechanism is quite simple: add a refresh section on your mutation
and return the list of keywords for the data that changed:
(defmutation ping-left [params]
(action [{:keys [state]}]
(swap! state update-in [:left/by-id 5 :left/value] inc))
(refresh [env] [:left/value]))The above mutation just indicates what it changed: :left/value.
The UI can then drop the follow-on reads:
(defsc Right [this {:keys [db/id right/value]}]
{:query [:db/id :right/value] }
(dom/div
; no longer need the :left/value as a follow-on read
(dom/button {:onClick #(prim/transact! this `[(ping-left {})])} "Ping Left")
value))In this case the transaction is running on a component that doesn’t query for the data being changed (it is pinging the Left component). The built-in refresh list on the mutation takes care of the update!
The live example below is a full-stack demo of this. The buttons update data that the other button displays. The `transact!`s on these would normally require follow-on reads or a callback to the parent to refresh properly. With the refresh list on the mutation itself the UI designer is freed from this responsibility.
The right button uses data from the server in a pessimistic fashion (it does no optimistic update, and you can increase the simulated delay on the server), so pinging it from the left actually reads a value from the server. This demonstrates that the refresh is working for full-stack operations.
(ns book.demos.declarative-mutation-refresh
(:require [fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.client.data-fetch :as df]
[fulcro.server :as server]
[fulcro.util :as util]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(server/defmutation ping-right [params]
(action [env]
{:db/id 1 :right/value (util/unique-key)}))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defmutation ping-left [params]
(action [{:keys [state]}]
(swap! state update-in [:left/by-id 5 :left/value] inc))
(refresh [env] [:left/value]))
(declare Right)
(defmutation ping-right [params]
(remote [{:keys [state ast]}]
(m/returning ast state Right))
(refresh [env] [:right/value]))
(defsc Left [this {:keys [db/id left/value]}]
{:query [:db/id :left/value]
:initial-state {:db/id 5 :left/value 42}
:ident [:left/by-id :db/id]}
(dom/div {:style {:float "left"}}
(dom/button {:onClick #(prim/transact! this `[(ping-right {})])} "Ping Right")
value))
(def ui-left (prim/factory Left {:keyfn :db/id}))
(defsc Right [this {:keys [db/id right/value]}]
{:query [:db/id :right/value]
:initial-state {:db/id 1 :right/value 99}
:ident [:right/by-id :db/id]}
(dom/div {:style {:float "right"}}
(dom/button {:onClick #(prim/transact! this `[(ping-left {})])} "Ping Left")
value))
(def ui-right (prim/factory Right {:keyfn :db/id}))
(defsc Root [this {:keys [left right]}]
{:query [{:left (prim/get-query Left)}
{:right (prim/get-query Right)}]
:initial-state {:left {} :right {}}}
(dom/div {:style {:width "600px" :height "50px"}}
(ui-left left)
(ui-right right)))8.5. Mutations Without Quoting or Circular References
There are times when using just defmutation is inconvenient. If you need to use a component in a mutation (for a merge, for example),
then you can easily end up with circular references in your code. You could just use the fully-qualified mutation name in
the UI, but that is quite inconvenient (we’d rather alias it, but circular refs are not allowed).
Another inconvenience is quoting. It is very easy to foget to unquote values in a tx.
What if you could write your transactions "as-if" they were functions, but have them work as data? Well, we live in Clojure-land, so that is not only possible, but relatively easy.
Fulcro Incubator now includes suppport for declaring mutations in any namespace (think of it like an interface namespace), and those declarations can be used quote-free!
To use this support, add Fulcro Incubator to your project:
[fulcrologic/fulcro-incubator "0.0.2"]and then declare your mutations together in some namespace:
(ns my-mutations
(:require [fulcro.incubator.mutation-interface :as mi :refer [declare-mutation]]
[cljs.spec.alpha :as s])
(s/def ::a string?)
(s/def ::b pos-int?)
(declare-mutation boo
"Mutation to do blah" ; doc string optional
'real-ns.of.mutations/boo
(s/keys :req-un [::a ::b])) ; spec not currently optional, probably should be :)and now you can use boo without quoting!
(ns real-ui
(:require
[my-mutations :refer [boo]]
...))
...
(prim/transact! this [(boo {:a "hello" :b 22})])There’s really not much to the magic. boo becomes a function-like thing that just returns a list with the proper
stuff in it:
(boo {:a "hello"}) => '(real-ns.of.mutations/boo {:a "hello"})Additionally, since your real mutation is in a whole different namespace that is never required by the UI or the interface you are now free to require the UI in the mutation namespace if you need it for merges and other component-centric mutations concerns without causing circular references.
This requires an extra namespace and a little extra declaration work, but cleans up the UI and ns requires quite well.
Fulcro 2.8.8 includes a global component registry. Any component that is (transitively) required in your application will appear in the registry, which makes it possible to track component classes in app state (since the name is serializable) and also look up a component class for merges from within mutations:
(defmutation f [params]
(action [{:keys [state]}]
(let [todo-list-class (prim/classname->class :com.company.app/TodoList)]
(swap! prim/merge-component todo-list-class {:list/id ...}))))8.5.1. Parameter specs
Currently the specs are not enforced unless checked-mutations is bound to true in the context they are used:
(binding [mi/*checked-mutations* true]
(prim/transact! this [(boo {:a 22})]))should throw an exception.
This should be considered an experimental part of the API. Feedback is welcome.
8.5.2. IDE Integration
The syntax of defmutation and declare-mutation are both intentionally "shaped" like defn and def so that you
can tell your IDE how to resolve them. In IntelliJ, you can do this by clicking on the macro name (e.g. defmutation)
and waiting for the light bulb. Then select "Resolve as" and then defn for defmutation and def for delcare-mutation.
You may not need to do this for defmutation, as IntelliJ does have some predefined resolutions for Fulcro built-in.
8.5.3. Future Status of declare-mutation
Expect this to make it into Fulcro proper in the near future, but for now we’ve got it in incubator while we work on refining the API.
8.6. Recommendations About Writing Mutations
Mutations themselves are meant to be abstractions across the entire stack; however, the optimistic side of them are really just functions on your application state. Components have nice clean abstractions, and you will often benefit from writing low-level functions that represent the general operations on a component’s data. As you move towards higher-level abstractions you’ll want to compose those lower-level functions. As such, it pays to think a little about how this will look over time.
If you write the actual logic of a mutation into a defmutation, then composition is difficult because the
model does not encourage recursive calls to transact!. This will either lead to code duplication or other bad
practices.
To maximize code reuse, local reasoning, and general readability it pays to think about your mutations in the following manner:
-
A mutation is a function that changes the state of the application:
state → mutation → state' -
Within a mutation, you are essentially doing operations to a graph, which means you have operations that work on some node in the graph:
node → op → node'. These operations may modifiy a scalar or an edge to another node.
8.6.1. Node-Specific Mutation
You can run a node-specific operation with:
(swap! state update-in node-ident op args)For example, say you want to implement a mutation that adds a person to another person’s friend list. The data
representation of a person is: {:db/id 1 :person/name "Nancy" :person/friends []}.
The ident function can be coded into a top-level function and used by the component:
(defn person-ident [id-or-props]
(if (map? id-or-props)
(person-ident (:db/id id-or-props))
[:person/by-id id-or-props]))
(defsc Person [this props]
{:ident (fn [] (person-ident props))}
...)and our desired operation on the general state of a person can also be written as a simple function (add an ident to the :person/friends field):
(defn add-friend*
"Add a friend to an existing person. Returns the updated person."
[person target-person-id]
(update person :person/friends (fnil conj []) (person-ident target-person-id)))Note, in particular, that we always choose to put the item to be updated as the first argument so that functions
like update are easier to use with it.
Now (add-friend* {:db/id 1 :person/name "Nancy"} 33) results in
{:db/id 1, :person/name "Nancy", :person/friends [[:person/by-id 33]]}.
You can write a mutation to support this operation within Fulcro:
(defmutation add-friend [{:keys [source-person-id target-id]}]
(action [{:keys [state]}]
(swap! state update-in (person-ident source-person-id)
add-friend* target-id)))You could even take it a step further with a little more sugar by defining a helper that can turn a node-specific op into a db-level operation (again note that the thing being updated is the first argument):
(defn update-person [state-map person-id person-fn & args]
(apply update-in state-map (person-ident person-id) person-fn args))
(defmutation add-friend [{:keys [source-person-id target-id]}]
(action [{:keys [state]}]
(swap! state update-person source-person-id add-friend* target-id)))If you find that a given entity is always modified in the context of the state map itself (a common case) then it can be a bit shorter to just push the table logic (ident resolution) into the operation itself:
(defn add-friend**
"Add a friend to an existing person in the client database."
[app-state person-id friend-id]
(update-in app-state [:person/by-id person-id :person/friends] (fnil conj []) (person-ident friend-id)))
(defmutation add-friend [{:keys [source-person-id target-id]}]
(action [{:keys [state]}]
(swap! state add-friend** source-person-id target-id)))8.6.2. Composition in Mutations
Once you have your general operations written as basic functions on either the entire state (like update-person) or
targeted to nodes or the state map itself (like add-friend*), then it becomes much easier to create mutations that
compose together operations to accomplish any higher-level task.
For example, the fulcro.client.routing/update-routing-links function takes a state map, and changes all of the routers
in the application state to show that particular screen. So, say you wanted add-friend to also
take you to the screen that shows the details of that particular person. The top-level abstract mutation in the UI
might still be called add-friend, but the internals now have two things to do.
Having all of these functions on the graph database allows you to write this in a very nice form as a sequence of operations on the state map itself through threading:
(defmutation add-friend
"Locally add a friend, and show them. Full stack operation.
[{:keys [source-id target-id]}]
(action [{:keys [state]}]
(swap! state
(fn [s]
(-> s
(r/update-routing-links {:handler :show-friend :route-params {:person-id target-id}})
; Could use (add-friend** source-id target-id) or:
(update-person source-id add-friend* target-id)))))
(remote [env] true)and your mutations become a thing of beauty!
Of course, this can also be overkill. It is true that it is often handy to be able to compose many db operations together
into one abstract mutation, but don’t forget that more that one mutation can be triggered by a single call
to transact!:
(prim/transact! this `[(route-to {:handler :show-friend :route-params {:person-id ~target-id}})
(add-friend {:source-person-id ~my-id :target-id ~target-id})])You’ll want to balance your mutations just like you do any other library of code: so that reuse and clarity are maximized. In the case of mutations the deciding factor is often how you want to deal with remote mutations.
8.7. Advanced Mutation Topics
This section covers a number of additional mutation techniques that arise in more advanced situations.
Almost all of these circumstances arise
from needing to modify your application database outside of the normal prim/transact! mechanism at the UI layer.
A lot of these things are handled for you with normal full-stack operations, so you might want to skip this section until you’re comfortable with that material.
8.7.1. Saving a Reconciler
The first note is that prim/transact! can be used on the reconciler. If you’ve saved your Fulcro Application
in a top-level atom then you can run a transaction "globally" like this:
(prim/transact! (:reconciler @app) ...)This should generally be used in cases where there is an abstract operation (e.g. you want setTimeout to update
a js/Date to the current time and have the screen refresh). Using (prim/transact! (:reconciler @app) '[(update-time) :current-time]) is
much clearer and in the spirit of the framework than any other low-level data tweaking. That could also be done in
the context of a component to prevent an overall root re-render, though you’d want to be careful to use both sides of
the component lifecycle to install and remove a timer that triggers such an update.
8.7.2. Swapping on the State Atom?
Yes. There is a watch on Fulcro’s state atom. Doing so will cause a refresh from the root of your UI.
(let [{:keys [reconciler]} @app
state-atom (prim/app-state reconciler)]
(swap! state-atom …))
8.7.3. Leveraging fulcro.client.primitives/tree→db
In some cases you will have obtained some data (or perhaps invented it) and you need to integrate that data into the
database. If the data matches your UI structure (as a tree) and you have proper Ident declarations on those components
then you can simply transform the data into the correct shape via the tree→db function using a component’s
query.
Unfortunately, you would then need to follow that transform by a sequence of operations on app state to merge those various bits.
The function also requires a query in order to do normalization (split the tree into tables).
|
Important
|
The general interaction with the world requires integration of external data (often in a tree format) with your app database (normalized graph of maps/vectors). As a result, you almost always want a component-based query when integrating data so that the result is normalized. |
8.7.4. Using integrate-ident
When in a mutation you very often need to place an ident in various spots in your graph database. The helper
function fulcro.client.mutations/integrate-ident* can by used from within mutations to help you do this. It accepts
any number of named parameters that specify operations to do with a given ident:
(swap! state
(fn [s]
(-> s
(do-some-op)
(integrate-ident* the-ident
:append [:table id :field]
:prepend [:other id :field]))))This function checks for the existence of the given ident in the target list, and will refuse to add it if it is
already there. The :replace option can be used on a to-one or to-many relation. When replacing on a to-many, you
use an index in the target path (e.g. [:table id :field 2] would replace the third element in a to-many :field)
8.7.5. Creating Components Just For Their Queries
If your UI doesn’t have a query that is convenient for sending to the server (or for working on tree data like this), then it is considered perfectly fine to generate components just for their queries (no render). This is often quite useful, especially in the context of pre-loading data that gets placed on the UI in a completely different form (e.g. the UI queries don’t match what you’d like to ask the server).
(defsc SubQuery [t p]
{:ident [:sub/by-id :id]
:query [:id :data]})
(defsc TopQuery [t p]
{:ident [:top/by-id :id]
:query [:id {:subs (prim/get-query SubQuery)}]})(ns book.tree-to-db
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[devcards.util.edn-renderer :refer [html-edn]]
[fulcro.client.mutations :as m :refer [defmutation]]))
(defsc SubQuery [t p]
{:ident [:sub/by-id :id]
:query [:id :data]})
(defsc TopQuery [t p]
{:ident [:top/by-id :id]
:query [:id {:subs (prim/get-query SubQuery)}]})
(defmutation normalize-from-to-result [ignored-params]
(action [{:keys [state]}]
(let [result (prim/tree->db TopQuery (:from @state) true)]
(swap! state assoc :result result))))
(defmutation reset [ignored-params] (action [{:keys [state]}] (swap! state dissoc :result)))
(defsc Root [this {:keys [from result]}]
{:query [:from :result]
:initial-state (fn [params]
; some data we're just shoving into the database from root...***not normalized***
{:from {:id :top-1 :subs [{:id :sub-1 :data 1} {:id :sub-2 :data 2}]}})}
(dom/div
(dom/div
(dom/h4 "Pretend Incoming Tree")
(html-edn from))
(dom/div
(dom/h4 "Normalized Result (click below to normalize)")
(when result
(html-edn result)))
(dom/button {:onClick (fn [] (prim/transact! this `[(normalize-from-to-result {})]))} "Normalized (Run tree->db)")
(dom/button {:onClick (fn [] (prim/transact! this `[(reset {})]))} "Clear Result")))of course, you can see that you’re still going to need to merge the database table contents into your main app state and carefully integrate the other bits as well.
8.7.6. Using fulcro.client.primitives/merge!
Fulcro includes a function that takes care of the rest of these bits for you. It requires the reconciler (which
as we mentioned earlier can be obtained from the Fulcro App). The arguments are similar to tree→db:
(prim/merge! (:reconciler @app) ROOT-data ROOT-query)The same things apply as tree→db (idents especially), however, the result of the transform will make it’s way into
the app state (which is owned by the reconciler).
IMPORTANT: The biggest challenge with using this function is that it requires the data and query to be structured from the ROOT of the database! That is sometimes perfectly fine, but our next section talks about a helper that might be easier to use.")
8.7.7. Using fulcro.client.primitives/merge-component!
There is a common special case that comes up often: You want to merge something that is in the context of some particular UI component.
(prim/merge-component! app ComponentClass ComponentData)Think of this case as: I have some data for a given component (which MUST have an ident). I want to merge into that component’s entry in a table, but I want to make sure the recursive tree of data also gets normalized properly.
merge-component! also integrates the functionality of integrate-ident* to pepper the ident of the merged entity throughout
your app database, and can often serve as a total one-stop
shop for merging data that is coming from some external source.
This first argument can be an application or reconciler.
Merge-component! Demo
In the card below the button simulates some external event that has brought in data that we’d like to merge (a newly arrived counter entity):
{ :counter/id 5 :counter/n 66 }We’ll want to:
-
Add the counter to the counter’s table (which is not even present because we have none in our initial app state)
-
Add the ident of the counter to the UI panel so its UI shows up
(defsc Counter [this {:keys [counter/id counter/n] :as props} {:keys [onClick] :as computed}]
{:query [:counter/id :counter/n]
:ident [:counter/by-id :counter/id]}
...
(defn add-counter
"Merge the given counter data into app state and append it to our list of counters"
[reconciler counter]
(prim/merge-component! reconciler Counter counter
:append [:panels/by-kw :counter :counters]))
...
(defsc Root ...
(let [reconciler (prim/get-reconciler this)] ; one way to get to the reconciler
(dom/button {:onClick #(add-counter reconciler {:counter/id 4 :counter/n 22})} "Simulate Data Import")
...Here is the full running example with source:
(ns book.merge-component
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[fulcro.client.cards :refer [defcard-fulcro]]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.client.data-fetch :as df]))
(defsc Counter [this {:keys [counter/id counter/n] :as props} {:keys [onClick] :as computed}]
{:query [:counter/id :counter/n]
:ident [:counter/by-id :counter/id]}
(dom/div :.counter
(dom/span :.counter-label
(str "Current count for counter " id ": "))
(dom/span :.counter-value n)
(dom/button {:onClick #(onClick id)} "Increment")))
(def ui-counter (prim/factory Counter {:keyfn :counter/id}))
; the * suffix is just a notation to indicate an implementation of something..in this case the guts of a mutation
(defn increment-counter*
"Increment a counter with ID counter-id in a Fulcro database."
[database counter-id]
(update-in database [:counter/by-id counter-id :counter/n] inc))
(defmutation increment-counter [{:keys [id] :as params}]
; The local thing to do
(action [{:keys [state] :as env}]
(swap! state increment-counter* id))
; The remote thing to do. True means "the same (abstract) thing". False (or omitting it) means "nothing"
(remote [env] true))
(defsc CounterPanel [this {:keys [counters]}]
{:initial-state (fn [params] {:counters []})
:query [{:counters (prim/get-query Counter)}]
:ident (fn [] [:panels/by-kw :counter])}
(let [click-callback (fn [id] (prim/transact! this
`[(increment-counter {:id ~id}) :counter/by-id]))]
(dom/div
; embedded style: kind of silly in a real app, but doable
(dom/style ".counter { width: 400px; padding-bottom: 20px; }
button { margin-left: 10px; }")
; computed lets us pass calculated data to our component's 3rd argument. It has to be
; combined into a single argument or the factory would not be React-compatible (not would it be able to handle
; children).
(map #(ui-counter (prim/computed % {:onClick click-callback})) counters))))
(def ui-counter-panel (prim/factory CounterPanel))
(defonce timer-id (atom 0))
(declare sample-of-counter-app-with-merge-component-fulcro-app)
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; The code of interest...
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn add-counter
"NOTE: A function callable from anywhere as long as you have a reconciler..."
[reconciler counter]
(prim/merge-component! reconciler Counter counter
:append [:panels/by-kw :counter :counters]))
(defsc Root [this {:keys [panel]}]
{:query [{:panel (prim/get-query CounterPanel)}]
:initial-state {:panel {}}}
(let [reconciler (prim/get-reconciler this)] ; pretend we've got the reconciler saved somewhere...
(dom/div {:style {:border "1px solid black"}}
; NOTE: A plain function...pretend this is happening outside of the UI...we're doing it here so we can embed it in the book...
(dom/button {:onClick #(add-counter reconciler {:counter/id 4 :counter/n 22})} "Simulate Data Import")
(dom/hr)
"Counters:"
(ui-counter-panel panel))))9. Full Stack Operation
One of the most interesting and powerful things about Fulcro is that the model for server interaction is unified into a clean data-driven structure. At first the new concepts can be challenging, but once you’ve seen the core primitive (component-based queries/idents for normalization) we think you’ll find that it dramatically simplifies everything!
In fact, now that you’ve completed the materials of this guide on the graph database, queries, idents, and normalization, it turns out that the server interactions become nearly trivial!
Not only is the structure of server interaction well-defined, Fulcro come with pre-written server-side code that handles all of the Fulcro plumbing for you. You can choose to provide as little or as much as you like. The easy server code provides everything in a Ring-based stack, and you can also choose to hand-build your server using a simple API handler for the Fulcro API route.
Even then, there are a lot of possible pitfalls when writing distributed applications. People often underestimate just how hard it is to get web applications right because they forget that.
So, while the API and mechanics of how you write Fulcro server interactions are as simple as possible there is no getting around that there are some hairy things to navigate in distributed apps independent of your choice of tools. Fulcro tries to make these things apparent, and it also tries hard to make sure you’re able to get it right without pulling out your hair.
Here are some of the basics:
-
Networking is provided.
-
The protocol is EDN on the wire (via transit), which means you just speak Clojure data on the wire, and can easily extend it to encode/decode new types.
-
-
All network requests (queries and mutations) are processed sequentially unless you specify otherwise. This allows you to reason about optimistic updates (Starting more than one at a time via async calls could lead to out-of-order execution, and impossible-to-reason-about recovery from errors).
-
You may provide fallbacks that indicate error-handling mutations to run on failures.
-
Writes and reads that are enqueued together will always be performed in write-first order. This ensures that remote reads are as current as possible.
-
Any
:ui/namespaced query elements are automatically elided when generating a query from the UI to a server, allowing you to easily mix UI concerns with server concerns in your component queries. You can also globally modify queries via load’s:update-queryoption, and even set it to a global default via an option tomake-fulcro-client. -
Normalization of a remote query result is automatic.
-
Deep merge of query results uses intelligent overwrite for properties that are already present in the client database.
-
Any number of remotes can be defined (allowing you to easily integrate with microservices).
-
Protocol and communication is strictly constrained to the networking layer and away from your application’s core structure, meaning you can actually speak whatever and however you want to a remote. In fact the concept of a remote is just "something you can talk to via queries and mutations". You can easily define a "remote" that reads and writes browser local storage or a Datascript database in the browser. This is an extremely powerful generalization for isolating side-effect code from your UI.
|
Note
|
To those of you with REST or GraphQL APIs: See the Pathom library for ways of converting those services into custom client remotes that isolate the specific of those APIs to the networking layers of your client. |
9.1. General Theory of Operation
There are only a few general kinds of interactions with a server:
-
Initial loads when the application starts
-
Incremental loads of sub-graphs of something that was previously loaded.
-
Event-based loads (e.g. user or timed events)
-
Integrating data from other external sources (e.g. server push)
In standard Fulcro networking, all of the above have the following similarities:
-
A component-based graph query needs to be involved to enable auto-normalization. This is true even for a server push (though in that case the client needs to know what implied question the server is sending data about).
-
The data from the server will be a tree that has the same shape as the query.
-
The data needs to be normalized into the client database.
-
Optionally: after integrating new data there may be some need to transform the result to a form the UI needs (e.g. perhaps you need to sort or paginate some list of items that came in).
IMPORTANT: Remember what you learned about the graph database, queries, and idents. This section cannot possibly be understood properly if you do not understand those topics!
9.1.1. Integration of ALL new external data is just a Query-Based Merge
So, here is the secret: When external data needs to go into your database it all uses the exact same mechanism: a query-based merge. So, for a simple load: you send a UI-based query to the server, the server responds with a tree of data that matches that graph query, and then the query itself (which is annotated with the components and ident functions) can be used to normalize the result. Finally, the normalized result can be merged into your existing client database.
Query --> Server --> Response + Original Query w/Idents --> Normalized Data --> Database Merge --> New DatabaseAny other kind of external data integration just starts at the "Response" step by manually providing the query that is annotated with components/idents:
New External Data + Query w/Idents --> Normalized Data --> Database Merge --> New DatabaseThere is a primitive function merge! function that implements this, so that you can simplify the picture to:
Tree of Data + Query --> merge! --> New Database9.1.2. The Central Functions: transact! and merge!
The two core functions that allow you to trigger abstract operations or data merges externally (via a reconciler) are:
prim/transact!-
The central function for running abstract changes in the application. Can be run with a component or reconciler. If run with the reconciler, will typically cause a root re-render.
prim/merge!-
A function that can be run against the reconciler to merge a tree of data via a UI query. This is the primary function that is used to integrate data in response to things like websocket server push.
These (and related/derived helpers) are the primary tools to use when trying to make your application respond to external stimuli that is not triggered from the UI.
9.1.3. Query Mismatch
We have all sorts of ways we’d like to view data. Perhaps we’d like to view "all the people who’ve ever had a particular phone number". That is something we can very simply represent with a UI graph, but may not be trivial to pull from our database.
In general, there are a few approaches to resolving our graph differences:
-
Use a query parser on the server to piece together data based on the graph of the query.
-
Ask the server for exactly what you want, using an invented well-known "root" keyword, and hand-code the database code to create the UI-centric view.
-
Ask the server for the data in a format it can easily provide and morph it on the client.
The first two have the advantage of making the client blissfully unaware of the server schema. It just asks for what it needs, and someone on the server programming team is stuck with satisfying the query. This is the down-side: the number of possible UI-centric queries could become quite large. Theoretically a parser solution makes this more tractable than a hand-coded variant, but in practice the parser is hard to make general in a way that allows UI developers to just run willy-nilly queries and get what they want.
In the example of "people who’ve had a particular phone number", the graph would be phone-number centric. Maybe
[:db/id :phone/number {:phone/historical-owners (prim/get-query Person)}]. There probably isn’t a graph edge in the
real database called :phone/historical-owners. One could write parser code that understood this particular edge,
and did the logic. In this case, that really isn’t even that hard and may be a good choice.
Fulcro gives you another easy-to-access option: morph something the server can easily provide (on the real graph without custom code). We’ll show you an example of this as we explore the data fetch options.
9.1.4. Server Interaction Order
Fulcro will serialize requests unless you mark queries as parallel (an option you can specify on load). Two different
events that queue mutations or loads will be processed in order. For example, if the user clicks on something and you trigger two loads
during that event, then both of those will be combined (if they don’t conflict by querying for the same thing)
and sent as one network request. If the user clicks on something else and that handler queues two more loads, then the latter two
loads will not start over the network until the first load sequence has completed.
This ensures that you don’t get out-of-order server execution. This is a distributed system, so it is possible for a second request to hit a less congested server (or even thread) than the first and get processed out of order. That would hurt your ability to reason about your program, so the default behavior in Fulcro is to ensure that server interactions happen on the server in the same order as they do on the client.
If you combine mutations and reads in the same event processing (before giving up the thread), then Fulcro also ensures that remote mutations go over the wire and complete before reads. The idea being that you don’t want to fetch data and then immediately make it stale through mutations. This additional detail is also aimed at preventing subtle classes of application bugs.
In Summary:
-
Loads/transactions queued while "holding the UI thread" will be joined together in a single network request.
-
Remote writes go before reads
-
Loads/transactions queued at a later event "new UI thread event" are guaranteed to be processed after ones queued earlier.
-
You can override this behavior with the
paralleloption ofload.
9.1.5. Server Result Query Merging
There is a potential for a data-driven app to create a new class of problem related to merging data. The normalization guarantees that the data for any number of views of the same thing are normalized to the same node in the graph database.
Thus, your PersonListRow view and PersonDetail view should both normalize the same person data to
a location like [:person/by-id id]. Let’s say you have a quick list of people on the screen that is paginated and
demand-loaded, where each row is a PersonListRow with query [:db/id :person/name {:person/image (prim/get-query Image)}].
Now say that you can click on one of these rows and a side-by-side view of that person’s PersonDetail is shown,
but the query for that is a whole bunch of stuff: name, age, address, phone numbers, etc. A much larger query.
A naive merge could cause you all sorts of nightmares. For example, Refreshing the list rows would load only name and image, but if merge overwrote the entire table entry then the current detail would suddenly empty out!
Fulcro provides you with an advanced merging algorithm that ensures these kinds of cases don’t easily occur. It does an intelligent merge with the following algorithm:
-
It is a detailed deep merge. Thus, the target table entry is updated, not overwritten.
-
If the query asks for a value but the result does not contain it, then that value is removed.
-
If the query didn’t ask for a value, then the existing database value is untouched.
This reduces the problem to one of potential staleness. It is technically possible for an entity in the resulting client database to be in a state that has never existed on the server because of such a partial update. This is considered to be a better result than the arbitrary UI madness that a more naive approach would cause.
For example, in the example above a query for a list row will update the name and image. All of the other details (if already loaded) would remain the same; however, it is possible that the server has run a mutation that also updated this person’s phone number. The detail part of the UI will be showing an updated name and image, but the old phone number. Technically this "state of Person" has never existed in the server’s timeline, but from a user’s perspective it looks better than the phone number disappearing.
In practice this isn’t that big of a deal; however, if you are switching the UI to an edit mode it is generally a good practice to on-demand load the entity being edited to help prevent user confusion and accidental overwrite based on stale values.
9.1.6. React Lifecycle and Load
React lifecycle and Load may not mix well. It is technically legal to issue transactions and loads from React Lifecycle, methods, but it is recommended that you carefully check the state of the system in said mutations before actually queuing network traffic. Perhaps you wish to ensure something is loaded. To do that: trigger a mutation that checks state and optionally submits a load. You’ll learn how to do this in the sections on the data fetch API.
9.2. The Data Fetch API: load
Let’s say we want to load all of our friends from the server. A query has to be rooted somewhere, so we’ll invent
a root-level keyword, :all-friends, and join it to the UI query for a Person:
[{:all-friends (prim/get-query Person)}]What we’d like to see then from the server is a return value with the shape of the query:
{ :all-friends [ {:db/id 1 ...} {:db/id 2 ...} ...] }If we combine that query with that tree result and were to manually call merge! we’d end up with this:
{ :all-friends [ [:person/by-id 1] [:person/by-id 2] ...]
:person/by-id { 1 { :db/id 1 ...}
2 { :db/id 2 ...}
...}}The data fetch API has a simple function for this that will do all of these together (query derivation, server interaction, and merge):
(ns my-thing
(:require [fulcro.client.data-fetch :as df]))
...
(df/load comp-reconciler-or-app :all-friends Person)An important thing to notice is that load can be thought of as a function that loads normalized data into the
root node of your graph (:all-friends appears in your root node).
This is sometimes what you want, but more often you really want data loaded at some other spot in your graph. We’ll talk about this more in a moment, first, let’s see how to handle that on the server.
9.2.1. Handling a Root Query
|
Note
|
The defquery* macros are meant as a quick entry point. Once inside you’ll have access to the subquery in
the env as :query. It is highly recommended that you use pathom to further
process queries. Specifically, we recommend using the "Connect" functionality of Pathom.
|
If you’re using the standard server support of Fulcro, then the API hooks are already predefined for you and you
can use helper macros to generate handlers for queries. If your load specified a keyword then this is seen by
the server as a load targeted to your root node. Thus, the server macro is called defquery-root:
(ns api
(:require [fulcro.server :refer [defquery-root defquery-entity defmutation]]))
(defquery-root :all-friends
"optional docstring"
(value [env params]
[{:db/id 1 :person/name ....} {:db/id 2 ...} ...]))It’s as simple as that! Write a function that returns the correct value for the query. The query itself will be available
in the env, and you can use libraries like pathom, Datomic, and fulcro-sql to parse those queries into the proper tree
result from various data sources. See the Query Parsing chapter.
9.2.2. Entity Queries
You can also ask to load a specific entity. You do this simply by telling load the ident of the thing you’d like to load:
(load this [:person/by-id 22] Person)Such a load will send a query to the server that is a join on that ident. The helper macro to handle those
is defquery-entity, and is dispatched by the table name:
(defquery-entity :person/by-id
"optional docstring"
(value [env id params]
{:db/id id ...}))Note that this call gets an id in addition to parameters (in the above call, id would be 22). Again, the full query
is in env so you can process the data driven response properly.
9.2.3. A Loading Example
This example shows two very common ways that data is loaded (or reloaded) in an application.
On startup, the following loads are run via the started callback:
(fc/make-fulcro-client
{:client-did-mount
(fn [app]
(df/load app :load-samples/people Person {:target [:lists/by-type :enemies :people]
:params {:kind :enemy}})
(df/load app :load-samples/people Person {:target [:lists/by-type :friends :people]
:params {:kind :friend}}))})In this demo we’re loading lists of people (thus the keyword’s name). There are two kinds of people available from the
server: friends and enemies. We use the :params config parameter to add a map of parameters to the network request
to specify what we want. The :target key is the path to the (normalized) entity’s property under which the response
should be stored once received.
Since all components should be normalized, this target path is almost always 2 (loading a whole component into a table) or 3 elements (loading one or more things into a property of an existing component).
The server-side code for handling these queries uses a global table on the server, and is:
(def all-users [{:db/id 1 :person/name "A" :kind :friend}
{:db/id 2 :person/name "B" :kind :friend}
{:db/id 3 :person/name "C" :kind :enemy}
{:db/id 4 :person/name "D" :kind :friend}])
; incoming param (kind) is destructured from third arg
(server/defquery-root :load-samples/people
(value [env {:keys [kind]}]
(let [result (->> all-users
(filter (fn [p] (= kind (:kind p))))
(mapv (fn [p] (-> p
(select-keys [:db/id :person/name])
(assoc :person/age-ms (now))))))]
result)))Once started, any given person can be refreshed at any time. Timeouts, user event triggers, etc. There are two ways
to refresh a given entity in a database. In the code of Person below you’ll see that we are using load again, but
this time with an ident:
(df/load this (prim/ident this props) Person)All of the parameters of this call can be easily derived when calling it from the component needing refreshed, so
there is a helper function called refresh! that makes this a bit shorter to type:
(df/refresh! this)The server-side implementation of refresh for person looks like this:
(server/defquery-entity :load-samples.person/by-id
(value [{:keys [] :as env} id p]
(let [person (first (filter #(= id (:db/id %)) all-users))]
(assoc person :person/age-ms (now))))) ; include a timestamp so we can see refreshes change something(ns book.demos.loading-data-basics
(:require
[fulcro.client :as fc]
[fulcro.client.data-fetch :as df]
[book.demos.util :refer [now]]
[fulcro.client.mutations :as m]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[fulcro.client.data-fetch :as df]
[fulcro.server :as server]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-users [{:db/id 1 :person/name "A" :kind :friend}
{:db/id 2 :person/name "B" :kind :friend}
{:db/id 3 :person/name "C" :kind :enemy}
{:db/id 4 :person/name "D" :kind :friend}])
(server/defquery-entity :load-samples.person/by-id
(value [{:keys [] :as env} id p]
(let [person (first (filter #(= id (:db/id %)) all-users))]
(assoc person :person/age-ms (now)))))
(server/defquery-root :load-samples/people
(value [env {:keys [kind]}]
(let [result (->> all-users
(filter (fn [p] (= kind (:kind p))))
(mapv (fn [p] (-> p
(select-keys [:db/id :person/name])
(assoc :person/age-ms (now))))))]
result)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defsc Person [this {:keys [db/id person/name person/age-ms] :as props}]
{:query [:db/id :person/name :person/age-ms :ui/fetch-state]
:ident (fn [] [:load-samples.person/by-id id])}
(dom/li
(str name " (last queried at " age-ms ")")
(dom/button {:onClick (fn []
; Load relative to an ident (of this component).
; This will refresh the entity in the db. The helper function
; (df/refresh! this) is identical to this, but shorter to write.
(df/load this (prim/ident this props) Person))} "Update")))
(def ui-person (prim/factory Person {:keyfn :db/id}))
(defsc People [this {:keys [people]}]
{:initial-state (fn [{:keys [kind]}] {:people/kind kind})
:query [:people/kind {:people (prim/get-query Person)}]
:ident [:lists/by-type :people/kind]}
(dom/ul
; we're loading a whole list. To sense/show a loading marker the :ui/fetch-state has to be queried in Person.
; Note the whole list is what we're loading, so the render lambda is a map over all of the incoming people.
(df/lazily-loaded #(map ui-person %) people)))
(def ui-people (prim/factory People {:keyfn :people/kind}))
(defsc Root [this {:keys [friends enemies]}]
{:initial-state (fn [{:keys [kind]}] {:friends (prim/get-initial-state People {:kind :friends})
:enemies (prim/get-initial-state People {:kind :enemies})})
:query [{:enemies (prim/get-query People)} {:friends (prim/get-query People)}]}
(dom/div
(dom/h4 "Friends")
(ui-people friends)
(dom/h4 "Enemies")
(ui-people enemies)))
(defn initialize
"To be used in :started-callback to pre-load things."
[app]
; This is a sample of loading a list of people into a given target, including
; use of params. The generated network query will result in params
; appearing in the server-side query, and :people will be the dispatch
; key. The subquery will also be available (from Person). See the server code above.
(df/load app :load-samples/people Person {:target [:lists/by-type :enemies :people]
:params {:kind :enemy}})
(df/load app :load-samples/people Person {:target [:lists/by-type :friends :people]
:params {:kind :friend}}))9.2.4. Targeting Loads
A short while ago we noted that loads are targeted at the root of your graph, and that this wasn’t always what you wanted. After all, your graph database will always have other UI stuff. For example there might be the concept of a "current screen" (join from root) that might currently point to a "friends screen", which in turn is where you want to load that list of friends:
{ :current-screen [:screens/by-type :friends]
...
:screens/by-type { :friends { :friends/list [] ... }}}If you’ve followed our earlier recommendations then your application’s UI is normalized and any given
spot in your graph is really just an entry in a top-level table. Thus, the path to the desired location
of our friends is usually just 3 deep. In this case: [:screens/by-type :friends :friends/list].
If we were to merge the earlier load into that database we could get what we want by just moving graph edges (where a to-one edge is an ident, and a to-many edge is a vector of idents):
{ :all-friends [ [:person/by-id 1] [:person/by-id 2] ...] ; (1) MOVE this to (2)
:person/by-id { 1 { :db/id 1 ...}
2 { :db/id 2 ...}
:current-screen [:screens/by-type :friends]
:screens/by-type { :friends { :friends/list [] ... }}} ; (2) where friends *should* beSince the graph database is just nodes and edges, there really aren’t many more operations to worry about! You’ve essentially got to normalize a tree, merge normalized data, and move graph edges.
The load API supports several kinds of graph edge targeting to allow you to put data where you want it in your graph.
|
Warning
|
Technically data is always loaded into the root, then relocated. So, be careful not to name your top-level edge after something that already exists there! |
Simple Targeting
The simplest targeting is to just relocate an edge from the root to somewhere else. The load function can do
that with a simple additional parameter:
(df/load comp :all-friends Person {:target [:screens/by-type :friends :friends/list]})So, the server will still see the well-known query for :all-friends, but your local UI graph will end up seeing the
results in the list on the friends screen.
Advanced Targets
You can also ask the target parameter to modify to-many edges instead of replacing them. For example, say you were loading one new person, and wanted to append it to the current list of friends:
(df/load comp :best-friend Person {:target (df/append-to [:screens/by-type :friends :friends/list])})The append-to function in the data-fetch namespace augments the target to indicate that the incoming items
(which will be normalized) should have their idents appended onto the to-many edge found at the given location.
|
Note
|
append-to will not create duplicates.
|
The other available helper is prepend-to. Using a plain target is equivalent to full replacement.
You may also ask the targeting system to place the result(s) at more than one place in your graph. You do this
with the multiple-targets wrapper:
(df/load comp :best-friend Person {:target (df/multiple-targets
(df/append-to [:screens/by-type :friends :friends/list])})
[:other-spot]
(df/prepend-to [:screens/by-type :summary :friends]))})Note that multiple-targets can use plain target vectors (replacement) or any of the special wrappers.
An Example of Targeting
In the example below, you’ll see we’ve set up two panes in a panel, and each pane can render a person.
Initially, there are no people loaded (none in initial state). The load buttons in the root component let you see entity loads targeted at one or both of them.
The main loader looks like this (and is called from root):
(defn load-random-person [component where]
(let [load-target (case where
(:left :right) [:pane/by-id where :pane/person]
:both (df/multiple-targets
[:pane/by-id :left :pane/person]
[:pane/by-id :right :pane/person]))
person-ident [:person/by-id (rand-int 100)]]
(df/load component person-ident Person {:target load-target})))The server is rather simple. It just makes up a person for any given ID:
(server/defquery-entity :person/by-id
(value [env id params]
{:db/id id :person/name (str "Person" id)}))(ns book.demos.loading-data-targeting-entities
(:require
[fulcro.client.mutations :as m]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[fulcro.server :as server]
[fulcro.client.data-fetch :as df]
[fulcro.client.primitives :as prim]))
;; SERVER
(server/defquery-entity ::person-by-id
(value [env id params]
{:db/id id :person/name (str "Person " id)}))
;; CLIENT
(defsc Person [this {:keys [person/name]}]
{:query [:db/id :person/name]
:ident [::person-by-id :db/id]}
(dom/div (str "Hi, I'm " name)))
(def ui-person (prim/factory Person {:keyfn :db/id}))
(defsc Pane [this {:keys [db/id pane/person] :as props}]
{:query [:db/id {:pane/person (prim/get-query Person)}]
:initial-state (fn [{:keys [id]}] {:db/id id :pane/person nil})
:ident [:pane/by-id :db/id]}
(dom/div
(dom/h4 (str "Pane " id))
(if person
(ui-person person)
(dom/div "No person loaded..."))))
(def ui-pane (prim/factory Pane {:keyfn :db/id}))
(defsc Panel [this {:keys [panel/left-pane panel/right-pane]}]
{:query [{:panel/left-pane (prim/get-query Pane)}
{:panel/right-pane (prim/get-query Pane)}]
:initial-state (fn [params] {:panel/left-pane (prim/get-initial-state Pane {:id :left})
:panel/right-pane (prim/get-initial-state Pane {:id :right})})
:ident (fn [] [:PANEL :only-one])}
(dom/div
(ui-pane left-pane)
(ui-pane right-pane)))
(def ui-panel (prim/factory Panel {:keyfn :db/id}))
(defn load-random-person [component where]
(let [load-target (case where
(:left :right) [:pane/by-id where :pane/person]
:both (df/multiple-targets
[:pane/by-id :left :pane/person]
[:pane/by-id :right :pane/person]))
person-ident [::person-by-id (rand-int 100)]]
(df/load component person-ident Person {:target load-target :marker false})))
(defsc Root [this {:keys [root/panel] :as props}]
{:query [{:root/panel (prim/get-query Panel)}]
:initial-state (fn [params] {:root/panel (prim/get-initial-state Panel {})})}
(dom/div
(ui-panel panel)
(dom/button {:onClick #(load-random-person this :left)} "Load into Left")
(dom/button {:onClick #(load-random-person this :right)} "Load into Right")
(dom/button {:onClick #(load-random-person this :both)} "Load into Both")))9.2.5. Refreshing the UI After Load
The component that issued the load will automatically be refreshed when the load completes. You may use the data-driven
nature of the app to request other components refresh as well. The :refresh option tells the system what data has
changed due to the load. It causes all live components that have queried those things to refresh.
You can supply keywords and/or idents:
; load my best friend, and re-render every live component that queried for the name of a person
(df/load comp :best-friend Person {:refresh [:person/name]})9.2.6. Other Load Options
Loads allow a number of additional arguments. Many of these are discussed in more detail in later sections:
:post-mutation and :post-mutation-params
|
A mutation to run once the load is complete (local data transform only). |
:remote
|
The name of the remote you want to load from. |
:refresh
|
A vector of keywords and idents. Any component that queries these will be re-rendered once the load completes. |
:parallel
|
Boolean. Defaults to false. When true, bypasses the sequential network queue. Allows multiple loads to run at once, but causes you to lose any guarantees about ordering since the server might complete them out-of-order. |
:fallback
|
A mutation to run if the server throws an error during the load. |
:focus
|
A subquery to filter from your component query. Covered in Incremental Loading. |
:without
|
A set of keywords to elide from the query. Covered in Incremental Loading. |
:update-query
|
A function that will take the component original query and should return a query that will be sent to the remote |
:params
|
A map. If supplied the params will appear as the params of the query on the server. |
:initialize bool|map
|
If true, uses component’s initial state as a basis for incoming merge. If a map, uses the map as the basis for incoming merge. |
Parallel vs. Sequential Loading
The :parallel option of load bypasses the normal network sequential queue. Below is a simple live
example that shows off the difference between regular loads and those marked parallel. In
order to see the effect increase your server latency to something like 5 seconds.
Normally, Fulcro runs separate event-based loads in sequence, ensuring that your reasoning can be synchronous;
however, for loads that might take some time to complete, and for which you can guarantee order of
completion doesn’t matter, you can specify an option on load (:parallel true) that allows them to proceed in parallel.
Pressing the sequential buttons on all three (in any order) will take at least 3x your server latency to complete from the time you click the first one (since each will run after the other is complete). If you rapidly click the parallel buttons, then the loads will not be sequenced and you will see them all complete in roughly 1x your server latency (from the time you click the last one).
(ns book.demos.parallel-vs-sequential-loading
(:require
[fulcro.server :refer [defquery-root defquery-entity defmutation]]
[fulcro.client.data-fetch :as df]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defquery-entity :background.child/by-id
(value [{:keys [parser query] :as env} id params]
(when (= query [:background/long-query])
(parser env query))))
(defquery-root :background/long-query
(value [{:keys [ast query] :as env} params] 42))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn render-result [v] (dom/span v))
(defsc Child [this {:keys [name name background/long-query]}]
{:query [:id :name :background/long-query]
:ident [:background.child/by-id :id]}
(dom/div {:style {:display "inline" :float "left" :width "200px"}}
(dom/button {:onClick #(df/load-field this :background/long-query :parallel true)} "Load stuff parallel")
(dom/button {:onClick #(df/load-field this :background/long-query)} "Load stuff sequential")
(dom/div
name
(df/lazily-loaded render-result long-query))))
(def ui-child (prim/factory Child {:keyfn :id}))
(defsc Root [this {:keys [children] :as props}]
; cheating a little...raw props used for child, instead of embedding them there.
{:initial-state (fn [params] {:children [{:id 1 :name "A"} {:id 2 :name "B"} {:id 3 :name "C"}]})
:query [{:children (prim/get-query Child)}]}
(dom/div
(mapv ui-child children)
(dom/br {:style {:clear "both"}}) (dom/br)))Initializing Loaded Items
|
Warning
|
This support is not complete yet (in version 2.0.0). It should be considered ALPHA and subject to change. |
On occasion you may find that your entities have :ui/??? attributes that you would like to
default to something on a loaded entity. This is the purpose of the :initialize option to load.
If it is set to true, then load will call get-initial-state on the component of the
load, and merge the return value from the server into that before merging it to app state.
Alternatively, you can pass :initialize a map, and that will be used as the target for
the server response merge before normalizing the result into app state.
|
Note
|
The value of :initialize must either be true or a map that matches the correct
shape of the component’s sub-tree of data. It must not be a normalized database fragment.
|
The steps are:
-
Send the request
-
Merge the response into the basis defined by
:initialize. -
Merge the result of (2) into the database using the component’s query (auto-normalize)
Post Mutations – Morphing Loaded Data
The targeting system that we discussed in the prior section is great for cases where your data-driven query gets you exactly what you need for the UI. In fact, since you can process the query on the server it is entirely possible that load with targeting is all you’ll ever need; however, from a practical perspective it may turn out that you’ve got a server that can easily understand certain shapes of data-driven queries, but not others.
For example, say you were pulling a list of items from a database. It might be trivial to pull that graph of data from the server from the perspective of a list of items, but let’s say that each item had a category. Perhaps you’d like to group the items by category in the UI.
The data-driven way to handle that is to make the server understand the UI query that has them grouped by category; however, that implies that you might end up embedding code on your server to handle a way of looking at data that is really specific to one kind of UI. That tends to push us back toward a proliferation of code on the server that was a nightmare in REST.
Another way of handling this is to accept the fact that our data-driven queries have some natural limits: If the database on the server can easily produce the graph, then we should let it do so from the data-driven query; however, in some cases it may make more sense to let the UI morph the incoming data into a shape that makes more sense to that UI.

We all understand doing these kinds of transforms. It’s just data manipulation. So, you may find this has some distinct advantages:
-
Simple query to the server (only have to write one query handler) that is a natural fit for the database there.
-
Simple layout in resulting UI database (normalized into tables and a graph)
-
Straightforward data transform into what we want to show
Using defsc For Server Queries
It is perfectly legal to use defsc to define a graph query (and normalization) for something like this that doesn’t exactly
exist on your UI. This can be quite useful in the presence of post mutations that can re-shape the data.
Simply code your (nested) queries using defsc, and skip writing the body:
(defsc ItemQuery [this props]
{:query [:db/id :item/name {:item/category (prim/get-query CategoryQuery)}]
:ident [:items/by-id :db/id]})(df/load this :all-items ItemQuery {:post-mutation `group-items})|
Note
|
We know that the name defsc seems a bit of a misnomer for this, so feel free to create an alias for it.
|
Live Demo of Post Mutations
The example below simulates post mutations to show how a load of simple data could be morphed into something that the UI wants to display. In this case we’re pretending that the load has brought in a number of items (as a collection) and normalized it, but we’d prefer to show the items organized by category..
You can interact with it and view the database to A/B compare the before/after state.
(ns book.server.morphing-example
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[book.macros :refer [defexample]]
[fulcro.client.cards :refer [defcard-fulcro]]
[fulcro.client.mutations :refer [defmutation]]
[fulcro.client :as fc]))
(defsc CategoryQuery [this props]
{:query [:db/id :category/name]
:ident [:categories/by-id :db/id]})
(defsc ItemQuery [this props]
{:query [:db/id :item/name {:item/category (prim/get-query CategoryQuery)}]
:ident [:items/by-id :db/id]})
(def sample-server-response
{:all-items [{:db/id 5 :item/name "item-42" :item/category {:db/id 1 :category/name "A"}}
{:db/id 6 :item/name "item-92" :item/category {:db/id 1 :category/name "A"}}
{:db/id 7 :item/name "item-32" :item/category {:db/id 1 :category/name "A"}}
{:db/id 8 :item/name "item-52" :item/category {:db/id 2 :category/name "B"}}]})
(def component-query [{:all-items (prim/get-query ItemQuery)}])
(def hand-written-query [{:all-items [:db/id :item/name
{:item/category [:db/id :category/name]}]}])
(defsc ToolbarItem [this {:keys [item/name]}]
{:query [:db/id :item/name]
:ident [:items/by-id :db/id]}
(dom/li name))
(def ui-toolbar-item (prim/factory ToolbarItem {:keyfn :db/id}))
(defsc ToolbarCategory [this {:keys [category/name category/items]}]
{:query [:db/id :category/name {:category/items (prim/get-query ToolbarItem)}]
:ident [:categories/by-id :db/id]}
(dom/li
name
(dom/ul
(map ui-toolbar-item items))))
(def ui-toolbar-category (prim/factory ToolbarCategory {:keyfn :db/id}))
(defmutation group-items-reset [params]
(action [{:keys [state]}]
(reset! state (prim/tree->db component-query sample-server-response true))))
(defn add-to-category
"Returns a new db with the given item added into that item's category."
[db item]
(let [category-ident (:item/category item)
item-location (conj category-ident :category/items)]
(update-in db item-location (fnil conj []) (prim/ident ItemQuery item))))
(defn group-items*
"Returns a new db with all of the items sorted by name and grouped into their categories."
[db]
(let [sorted-items (->> db :items/by-id vals (sort-by :item/name))
category-ids (-> db (:categories/by-id) keys)
clear-items (fn [db id] (assoc-in db [:categories/by-id id :category/items] []))
db (reduce clear-items db category-ids)
db (reduce add-to-category db sorted-items)
all-categories (->> db :categories/by-id vals (mapv #(prim/ident CategoryQuery %)))]
(assoc db :toolbar/categories all-categories)))
(defmutation ^:intern group-items [params]
(action [{:keys [state]}]
(swap! state group-items*)))
(defsc Toolbar [this {:keys [toolbar/categories]}]
{:query [{:toolbar/categories (prim/get-query ToolbarCategory)}]}
(dom/div
(dom/button {:onClick #(prim/transact! this `[(group-items {})])} "Trigger Post Mutation")
(dom/button {:onClick #(prim/transact! this `[(group-items-reset {})])} "Reset")
(dom/ul
(map ui-toolbar-category categories))))
(defexample "Morphing Data" Toolbar "morphing-example" :initial-state (atom (prim/tree->db component-query sample-server-response true)))9.2.7. Pre-Merge
Available from Fulcro 2.8+.
Pre merge offers a hook to manipulate data entering your Fulcro app at component level.
During the lifetime of a Fulcro application data will enter the system, the most common are:
-
During app initialization
-
New data loaded from remote
-
Data add via mutations
In the first case the data comes from the component initial state or user provided initial state, these usually include both domain and ui initialized data.
In the second case the data comes from a remote and contain domain data, but not UI data since
it’s not a concern from the remote to know about then, but the UI might still need to
do some type of initialization when creating data for new entities in the local database. Before
pre hooks the only way to populate these UI specific data was to use a :post-mutation with
the load call to manually populate it. This solution is powerful because it allows any changes
to be done at any part of the DB, but using it offers some challanges:
-
Component specific data initialization is separated from the component itself, reducing local reasoning
-
Composition gets affected, every parent component has to write new logic to manually compose the initialization tree
-
Initialization of to-many lists requires tedios code to manipulate tables in the app db
To illustrate these issues we are going to write a small app that has some count down buttons, the idea is that each counter gets clicked until it reaches zero, the important detail will be how we can handle the initial counter value, first using post-mutations and then pre-merge.
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]}
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))The important part is the :ui/count must start with some value, we can arbitrarily
choose 5 as a start, whatever it is we need to initialize when the data for this
enter the system.
We are going to use this post-mutation to initialize this ui property, at this point the example is loading a single counter from the remote:
(m/defmutation initialize-counter [{::keys [counter-id]}]
(action [{:keys [state]}]
(swap! state update-in [::counter-id counter-id] #(merge {:ui/count 5} %))))And this is the call to load:
(df/load this [::counter-id 1] Countdown
{:target [:counter]
:post-mutation `initialize-counter
:post-mutation-params {::counter-id 1}})With all hook up here is the demo:
(ns book.demos.pre-merge.post-mutation-countdown
(:require
[fulcro.client :as fc]
[fulcro.client.data-fetch :as df]
[book.demos.util :refer [now]]
[fulcro.client.mutations :as m]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[fulcro.client.data-fetch :as df]
[fulcro.server :as server]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}])
(server/defquery-entity ::counter-id
(value [_ id _]
(first (filter #(= id (::counter-id %)) all-counters))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(m/defmutation initialize-counter [{::keys [counter-id]}]
(action [{:keys [state]}]
(swap! state update-in [::counter-id counter-id] #(merge {:ui/count 5} %))))
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]}
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))
(def ui-countdown (prim/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {:keys [counter]}]
{:initial-state (fn [_] {})
:query [{:counter (prim/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq counter)
(ui-countdown counter)
(dom/button {:onClick #(df/load this [::counter-id 1] Countdown
{:target [:counter]
:post-mutation `initialize-counter
:post-mutation-params {::counter-id 1}})}
"Load one counter"))))
(defn initialize
"To be used in :started-callback to pre-load things."
[app])Now let’s see in case of a to-many, this is what our new mutation looks like:
(m/defmutation initialize-counters [_]
(action [{:keys [state]}]
(swap! state
(fn [state]
(reduce
(fn [state ref]
(update-in state ref #(merge {:ui/count 5} %)))
state
(get state ::all-counters))))))(ns book.demos.pre-merge.post-mutation-countdown-many
(:require
[fulcro.client :as fc]
[fulcro.client.data-fetch :as df]
[book.demos.util :refer [now]]
[fulcro.client.mutations :as m]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[fulcro.client.data-fetch :as df]
[fulcro.server :as server]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}
{::counter-id 2 ::counter-label "B"}
{::counter-id 3 ::counter-label "C"}
{::counter-id 4 ::counter-label "D"}])
(server/defquery-root ::all-counters
(value [_ _]
all-counters))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(m/defmutation initialize-counters [_]
(action [{:keys [state]}]
(swap! state
(fn [state]
(reduce
(fn [state ref]
(update-in state ref #(merge {:ui/count 5} %)))
state
(get state ::all-counters))))))
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]}
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))
(def ui-countdown (prim/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {})
:query [{::all-counters (prim/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq all-counters)
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))
(dom/button {:onClick #(df/load this ::all-counters Countdown
{:post-mutation `initialize-counters})}
"Load many counters"))))
(defn initialize
"To be used in :started-callback to pre-load things."
[app])As you can see, adding a single depth to the query can yield a fair amount of extra code to hook things up, and as you app grows each join depth will add more post-mutation code to compose over. Solving this composition issue is the main motivation behind pre-merge.
Working with pre-merge
Pre merge addresses these issues by providing a component level hook that allows the data entering logic to be colocated with the rest of the component.
It works by hooking in the new data normalization process, if you are not familiar with how the normalization works I suggest you check it there and come back after.
You can setup the pre-merge by adding the :pre-merge key to your component configuration,
this is how we can setup our Countdown using :pre-merge:
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
; (1)
(merge
{:ui/count 5} ; (2)
current-normalized ; (3)
data-tree))} ; (4)
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))-
This merge setup works for most of the cases
-
We start the merge with a map containing defaults
-
Then we merge with the data that is already there for this component (may be
nilif component doesn’t has previous data) -
Finally merge in the data tree, since it’s the last it will win over any of the previous
The :pre-merge lambda receives a single map containing the following keys:
-
:data-tree- the new data tree entering the database -
:current-normalized- the current entity value (if any), comes normalized from the db (as in(get-in state ref)) -
:state-map- the current app state map (you may use to lookup refs). -
:query- the query used to do this request (user may have modified the original using:focus,:withoutor:update-queryduring the load call
With this setup we can get rid of the post-mutation. The to-one case example with pre-merge:
(ns book.demos.pre-merge.countdown
(:require
[fulcro.client :as fc]
[fulcro.client.data-fetch :as df]
[book.demos.util :refer [now]]
[fulcro.client.mutations :as m]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[fulcro.client.data-fetch :as df]
[fulcro.server :as server]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}])
(server/defquery-entity ::counter-id
(value [_ id _]
(first (filter #(= id (::counter-id %)) all-counters))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
{:ui/count 5}
current-normalized
data-tree))}
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))
(def ui-countdown (prim/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {:keys [counter]}]
{:initial-state (fn [_] {})
:query [{:counter (prim/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq counter)
(ui-countdown counter)
(dom/button {:onClick #(df/load this [::counter-id 1] Countdown {:target [:counter]})}
"Load one counter"))))
(defn initialize
"To be used in :started-callback to pre-load things."
[app])For the to-many case it’s the same, no need for post-mutation.
(ns book.demos.pre-merge.countdown-many
(:require
[fulcro.client :as fc]
[fulcro.client.data-fetch :as df]
[book.demos.util :refer [now]]
[fulcro.client.mutations :as m]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[fulcro.client.data-fetch :as df]
[fulcro.server :as server]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}
{::counter-id 2 ::counter-label "B"}
{::counter-id 3 ::counter-label "C"}
{::counter-id 4 ::counter-label "D"}])
(server/defquery-root ::all-counters
(value [_ _]
all-counters))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defsc Countdown [this {::keys [counter-label]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
{:ui/count 5}
current-normalized
data-tree))}
(dom/div
(dom/h4 counter-label)
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))
(def ui-countdown (prim/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {})
:query [{::all-counters (prim/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq all-counters)
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))
(dom/button {:onClick #(df/load this ::all-counters Countdown)}
"Load many counters"))))
(defn initialize
"To be used in :started-callback to pre-load things."
[app])To spicy this example, let’s make so the initial counter number can be defined by the server, but we want to keep this is a separated attribute that doesn’t going to be displayed to the right of the counter label.
(ns book.demos.pre-merge.countdown-with-initial
(:require
[fulcro.client :as fc]
[fulcro.client.data-fetch :as df]
[book.demos.util :refer [now]]
[fulcro.client.mutations :as m]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[fulcro.client.data-fetch :as df]
[fulcro.server :as server]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}
{::counter-id 2 ::counter-label "B" ::counter-initial 10}
{::counter-id 3 ::counter-label "C" ::counter-initial 2}
{::counter-id 4 ::counter-label "D"}])
(server/defquery-root ::all-counters
(value [_ _]
all-counters))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def default-count 5)
(defsc Countdown [this {::keys [counter-label counter-initial]
:ui/keys [count]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label ::counter-initial :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
; (1)
{:ui/count (or (prim/nilify-not-found (::counter-initial data-tree)) default-count)}
current-normalized
data-tree))}
(dom/div
(dom/h4 (str counter-label " [" (or counter-initial default-count) "]"))
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count))))))
(def ui-countdown (prim/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {})
:query [{::all-counters (prim/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq all-counters)
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))
(dom/button {:onClick #(df/load this ::all-counters Countdown)}
"Load many counters"))))
(defn initialize
"To be used in :started-callback to pre-load things."
[app])-
During the normalization step of a load Fulcro will put
::prim/not-foundvalue on keys that were not delivered by the server, this is used to do asweep-mergelater, theprim/nilify-not-foundwill return the same input value (likeidentity) unless it’s a::prim/not-found, in which case it returnsnil, this way theorworks in both cases.
Next, we are going to extract the counter button into its own component, this serves to illustrate how you can hook up pure UI components in remote based components.
(defsc CountdownButton [this {:ui/keys [count]}]
{:ident [:ui/id :ui/id]
:query [:ui/id :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
; (1)
{:ui/id (random-uuid)
:ui/count default-count}
current-normalized
data-tree))}
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count)))))
(defsc Countdown [this {::keys [counter-label counter-initial]
:ui/keys [counter]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label ::counter-initial
{:ui/counter (prim/get-query CountdownButton)}]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(let [initial (prim/nilify-not-found (::counter-initial data-tree))]
(merge
; (2)
{:ui/counter (cond-> {} initial (assoc :ui/count initial))}
current-normalized
data-tree)))}
(dom/div
(dom/h4 (str counter-label " [" (or counter-initial default-count) "]"))
(ui-countdown-button counter)))-
For the UI element we can also set the initial id using pre-merge, and now we moved the default there
-
Note we pass a blank map to the
:ui/counter, this will reach the pre-merge fromCountdownButtonas thedata-treepart
Full demo:
(ns book.demos.pre-merge.countdown-extracted
(:require
[fulcro.client :as fc]
[fulcro.client.data-fetch :as df]
[book.demos.util :refer [now]]
[fulcro.client.mutations :as m]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[fulcro.client.data-fetch :as df]
[fulcro.server :as server]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}
{::counter-id 2 ::counter-label "B" ::counter-initial 10}
{::counter-id 3 ::counter-label "C" ::counter-initial 2}
{::counter-id 4 ::counter-label "D"}])
(server/defquery-root ::all-counters
(value [_ _]
all-counters))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def default-count 5)
(defsc CountdownButton [this {:ui/keys [count]}]
{:ident [:ui/id :ui/id]
:query [:ui/id :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
; (1)
{:ui/id (random-uuid)
:ui/count default-count}
current-normalized
data-tree))}
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count)))))
(def ui-countdown-button (prim/factory CountdownButton {:keyfn ::counter-id}))
(defsc Countdown [this {::keys [counter-label counter-initial]
:ui/keys [counter]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label ::counter-initial
{:ui/counter (prim/get-query CountdownButton)}]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(let [initial (prim/nilify-not-found (::counter-initial data-tree))]
(merge
; (2)
{:ui/counter (cond-> {} initial (assoc :ui/count initial))}
current-normalized
data-tree)))}
(dom/div
(dom/h4 (str counter-label " [" (or counter-initial default-count) "]"))
(ui-countdown-button counter)))
(def ui-countdown (prim/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {})
:query [{::all-counters (prim/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq all-counters)
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))
(dom/button {:onClick #(df/load this ::all-counters Countdown)}
"Load many counters"))))
(defn initialize
"To be used in :started-callback to pre-load things."
[app])Another interesting property about pre-merge is that it also runs during normalization of app initialization, this means you can provide the minimum amount of data as the initial state and let the pre-merge fill the UI needs, to illustrate let’s add some initial state to our demo:
(defsc Root [this _]
{:initial-state (fn [_] {::all-counters
[{::counter-id (prim/tempid)
::counter-label "X"}
{::counter-id (prim/tempid)
::counter-label "Y"}
{::counter-id (prim/tempid)
::counter-label "Z"
::counter-initial 9}]})
:query [{::all-counters (prim/get-query Countdown)}]}
...)Pre merge will be applied on top of that running the pre-merge on the respective data parts. Full demo:
(ns book.demos.pre-merge.countdown-initial-state
(:require
[fulcro.client :as fc]
[fulcro.client.data-fetch :as df]
[book.demos.util :refer [now]]
[fulcro.client.mutations :as m]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[fulcro.client.data-fetch :as df]
[fulcro.server :as server]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def all-counters
[{::counter-id 1 ::counter-label "A"}
{::counter-id 2 ::counter-label "B" ::counter-initial 10}
{::counter-id 3 ::counter-label "C" ::counter-initial 2}
{::counter-id 4 ::counter-label "D"}])
(server/defquery-root ::all-counters
(value [_ _]
all-counters))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def default-count 5)
(defsc CountdownButton [this {:ui/keys [count]}]
{:ident [:ui/id :ui/id]
:query [:ui/id :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
{:ui/id (random-uuid)
:ui/count default-count}
current-normalized
data-tree))}
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count)))))
(def ui-countdown-button (prim/factory CountdownButton {:keyfn ::counter-id}))
(defsc Countdown [this {::keys [counter-label counter-initial]
:ui/keys [counter]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label ::counter-initial
{:ui/counter (prim/get-query CountdownButton)}]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(let [initial (prim/nilify-not-found (::counter-initial data-tree))]
(merge
{:ui/counter (cond-> {} initial (assoc :ui/count initial))}
current-normalized
data-tree)))}
(dom/div
(dom/h4 (str counter-label " [" (or counter-initial default-count) "]"))
(ui-countdown-button counter)))
(def ui-countdown (prim/factory Countdown {:keyfn ::counter-id}))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {::all-counters
[{::counter-id (prim/tempid)
::counter-label "X"}
{::counter-id (prim/tempid)
::counter-label "Y"}
{::counter-id (prim/tempid)
::counter-label "Z"
::counter-initial 9}]})
:query [{::all-counters (prim/get-query Countdown)}]}
(dom/div
(dom/h3 "Counters")
(if (seq all-counters)
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))
(dom/button {:onClick #(df/load this ::all-counters Countdown)}
"Load many counters"))))
(defn initialize
"To be used in :started-callback to pre-load things."
[app])Time to talk about mutations the third case, the mutations. Fulcro already offered some
ways to integrate new data given a component and some data using functions like prim/merge-component.
This means we can leverage the pre-merge hooks also when adding new data on mutations, like so:
(m/defmutation create-countdown [countdown]
(action [{:keys [state ref]}]
(swap! state prim/merge-component Countdown countdown :append [::all-counters])
(swap! state update-in ref assoc :ui/new-countdown-label "")))And add some UI to trigger this mutation:
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {::all-counters
[{::counter-id (prim/tempid)
::counter-label "X"}
{::counter-id (prim/tempid)
::counter-label "Y"}
{::counter-id (prim/tempid)
::counter-label "Z"
::counter-initial 9}]})
:query [{::all-counters (prim/get-query Countdown)}
:ui/new-countdown-label]}
(dom/div
(dom/h3 "Counters")
(dom/button {:onClick #(prim/transact! this [`(create-countdown ~{::counter-id (prim/tempid)
::counter-label "New"})])}
"Add counter")
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))))Full demo:
(ns book.demos.pre-merge.countdown-mutation
(:require
[book.demos.util :refer [now]]
[fulcro.client.mutations :as m]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def default-count 5)
(defsc CountdownButton [this {:ui/keys [count]}]
{:ident [:ui/id :ui/id]
:query [:ui/id :ui/count]
:pre-merge (fn [{:keys [current-normalized data-tree]}]
(merge
{:ui/id (random-uuid)
:ui/count default-count}
current-normalized
data-tree))}
(let [done? (zero? count)]
(dom/button {:disabled done?
:onClick #(m/set-value! this :ui/count (dec count))}
(if done? "Done!" (str count)))))
(def ui-countdown-button (prim/factory CountdownButton {:keyfn ::counter-id}))
(defsc Countdown [this {::keys [counter-label counter-initial]
:ui/keys [counter]}]
{:ident [::counter-id ::counter-id]
:query [::counter-id ::counter-label ::counter-initial
{:ui/counter (prim/get-query CountdownButton)}]
:pre-merge (fn [{:keys [current-normalized data-tree] :as x}]
(let [initial (prim/nilify-not-found (::counter-initial data-tree))]
(merge
{:ui/counter (cond-> {} initial (assoc :ui/count initial))}
current-normalized
data-tree)))}
(dom/div
(dom/h4 (str counter-label " [" (or counter-initial default-count) "]"))
(ui-countdown-button counter)))
(def ui-countdown (prim/factory Countdown {:keyfn ::counter-id}))
(m/defmutation create-countdown [countdown]
(action [{:keys [state ref]}]
(swap! state prim/merge-component Countdown countdown :append [::all-counters])
(swap! state update-in ref assoc :ui/new-countdown-label "")))
(defsc Root [this {::keys [all-counters]}]
{:initial-state (fn [_] {::all-counters
[{::counter-id (prim/tempid)
::counter-label "X"}
{::counter-id (prim/tempid)
::counter-label "Y"}
{::counter-id (prim/tempid)
::counter-label "Z"
::counter-initial 9}]})
:query [{::all-counters (prim/get-query Countdown)}
:ui/new-countdown-label]}
(dom/div
(dom/h3 "Counters")
(dom/button {:onClick #(prim/transact! this [`(create-countdown ~{::counter-id (prim/tempid)
::counter-label "New"})])}
"Add counter")
(dom/div {:style {:display "flex" :alignItems "center" :justifyContent "space-between"}}
(mapv ui-countdown all-counters))))
(defn initialize
"To be used in :started-callback to pre-load things."
[app])9.3. Augmenting the Ring Response
The Ring stack is supplied for you in the server code and most responses are simple EDN with the HTTP details taken care of for you; however, there are times when you need to modify something about the low-level response itself (such as adding a cookie).
If you’re using the Fulcro server tools (handle API request or the easy server) then you can add a fully general response transform to your EDN response as follows:
(fulcro.server/augment-response your-EDN-response
(fn [ring-response]
...
modified-ring-response))For example, if you were using Ring and Ring Session, you could cause a session cookie to be generated, and user information to be stored in a server session store simply by returning this from a query on user:
(server/augment-response user (fn [resp] (assoc-in resp [:session :uid] real-uid)))9.4. Full-Stack Mutations
You’ve already seen how to define local mutations on the client. In this chapter we’re going to go into the details of making mutations work against the server.
9.5. Remote Mutations
Mutations are already plain data, so Fulcro can pass them over the network as-is when the client invokes them. All you need to do to indicate that a given mutation should affect a given remote is add that remote to the mutation:
(defmutation add-friend [params]
(action ...) ; optimistic update of client state
(remote [env] true)) ; send the mutation to the remote known as :remote
; or using the multimethod directly:
(defmethod m/mutate `add-friend [env k params]
{:action (fn [] ...)
:remote true})Now you can see why choosing the right real mutations and amount of composition on the client
can give you optimal server interaction: Anything that you run in transact! itself can stand
alone as a remote mutation call in the transaction on the wire.
9.5.1. Optimistic by Default
The action portion of a mutation is run immediately on the client. When there is also a server interaction
then the client-side operation is known as an optimistic update because by default we assume that the server
will succeed in replicating the action. This gives the user immediate feedback and the ability to proceed quickly
even in the presence of a slow network. We’ll discuss more on error handling shortly.
9.5.2. Mutations Revisited
A multi-method in Fulcro client (which is manipulated with defmutation) can indicate that a given mutation
should be sent to any number of remotes. The default remote is named :remote, but you can define new ones or even
rename the default one.
The technical structure of this looks like:
(require [fulcro.client.mutations :refer [mutate]])
(defmethod mutate 'some/mutation [env k params]
;; sends this mutation with the same `env`, `k`, and `params` arguments to the server
{:remote true
:action (fn[] ... )})or preferably using the defmutation macro:
(defmutation do-thing [params]
(action [env] ...)
(remote [env] true))Basically, you use the name of the remote as an indicator of which remote you want to replicate the mutation to. From
there you either return true (which means send the mutation as-is), or you may return an expression AST that represents
the mutation you’d like to send instead. The fulcro.client.primitives namespace includes ast→query and query-ast
for arbitrary generation of ASTs, but the original AST of the mutation is also available in the mutation’s environment.
Therefore, you can alter a mutation simply by altering and returning the ast given in env:
(defmutation do-thing [params]
(action [env] ...)
; send (do-thing {:x 1}) even if params are different than that on the client
(remote [{:keys [ast]}] (assoc ast :params {:x 1})) ; change the param list for the remote
; or using the with-params helper
(defmutation do-thing [params]
(action [env] ...)
; send (do-thing {:x 1}) even if params are different than that on the client
(remote [{:keys [ast]}] (m/with-params ast {:x 1})) ; change the param list for the remoteor even change which mutation the server sees:
(defmutation some-mutation [ params]
;; Changes the mutation from the incoming client-side some-mutation to server-mutation
(remote [{:keys [ast] :as env}] (assoc ast :key 'server-mutation :dispatch-key 'server-mutation)))|
Warning
|
The state is available in remote, but the action will run first. This means that you should not
expect the "old" values in state when computing anything for the remote because the optimistic
update of the action will have already been applied! If you need to rely on data as it existed at the time of
transact! then you must pass it as a parameter to the mutation so that the original data is closed over for the
duration of the mutation processing.
|
9.5.3. Writing The Server Mutations
Server-side mutations in Fulcro are written the same way as on the client: A mutation returns a map with a key :action
and a function of no variables as a value. The mutation then does whatever server-side operation is indicated. The env
parameter on the server can contain anything you like (for example database access interfaces). You’ll see how
to configure that when you study how to build a server.
The recommended approach to writing a server mutation is to use the pre-written server-side parser and multimethods, which allow you
to mimic the same code structure of the client (there is a defmutation in fulcro.server for this).
If you’re using this approach (which is the default in the lein template and easy server), then here are the client-side and server-side implementations of the same mutation:
;; client
;; src/my_app/mutations.cljs
(ns my-app.mutations
(:require [fulcro.client.mutations :refer [defmutation]]))
(defmutation do-something [{:keys [p]}]
(action [{:keys [state]}]
(swap! state assoc :value p))
(remote [env] true));; server
;; src/my_app/mutations.clj
(ns my-app.mutations
(:require [fulcro.server :refer [defmutation]]))
(defmutation do-something [{:keys [p]}]
(action [{:keys [some-server-database]}]
... server code to make change ...))or even a CLJC file:
(ns my-app.mutations
(:require
#?(:cljs [fulcro.client.mutations :refer [defmutation]]
:clj [fulcro.server :as server])))
#?(:cljs
(defmutation do-something [{:keys [p]}]
(action [{:keys [state]}]
(swap! state assoc :value p))
(remote [env] true))
:clj
(server/defmutation do-something [{:keys [p]}]
(action [{:keys [some-server-database]}]
... server code to make change ...)))It is recommended that you use the same namespace on the client and server for mutations so it is easy to find them, but the macro allows you to namespace the symbol if you choose to use a different namespace on the server:
(ns my-app.server
(:require [fulcro.server :refer [defmutation]]))
(defmutation my-app.mutations/do-something [{:keys [p]}]
(action [{:keys [some-server-database]}]
... server code to make change ...))The ideal structure for many people is to use a CLJC file, where they can co-locate the mutations in the same
source file. The only trick is that you have to make sure you use the correct defmutation!
(ns my-app.api
(:require
#?(:clj [fulcro.server :as server]
:cljs [fulcro.client.mutations :refer [defmutation]])))
#?(:clj (server/defmutation do-thing [params]
(action [server-env] ...))
:cljs (defmutation do-thing [params]
(remote [env] true)))|
Note
|
The server namespace includes support for defining a server mutation in the browser. This allows you to simulate a server in the browser instead of having to have a real server. |
Please see Building A Server for more information about setting up a server with injected components in the mutation environment.
The Server Multimethods for Mutations
The defmutation macro on the server simply hits a multimethod. You can use defmethod on fulcro.server/server-mutate to define your mutations. The advantage of this is that you might want
to write your own wrappers, macros, or code around the low-level implementation.
In general, we recommend using defmutation because it is better supported by IDEs (for navigation, docstrings, etc)
and eliminates some classes of syntactic error.
9.5.4. New item creation – Temporary IDs
Fulcro has a built in function prim/tempid that will generate a unique temporary ID. This allows the normalization
and denormalization of the client side database to continue working while the server processes the new data and returns
the permanent identifier(s).
The idea is that these temporary IDs can be safely placed in your client database (and network queues), and will be automatically rewritten to their real ID when the server has managed to create the real persistent entity. Of course, since you have optimistic updates on the client it is important that things go in the correct sequence, and that queued operations for the server don’t get confused about what ID is correct!
|
Warning
|
Because mutation code can be called multiple times (at least once + once per each remote),
you should take care to not call fulcro.client.primitives/tempid inside your mutation.
Instead call it from your UI code that builds the mutation params.
|
Fulcro’s implementation works as follows:
-
Mutations always run in the order specified in the call to
transact! -
Transmission of separate calls to
transact!run in the order they were called. -
If remote mutations are separated in time, then they go through a sequential networking queue, and are processed in order.
-
As mutations complete on the server, they return tempid remappings. Those are applied to the application state and network queue before the next network operation (load or mutation) is sent.
This set of rules helps ensure that you can reason about your program, even in the presence of optimistic updates that could theoretically be somewhat ahead of the server.
For example, you could create an item, edit it, then delete it. The UI responds immediately, but the initial create might still be running on the server. This means the server has not even given it a real ID before you’re queuing up a request to delete it! With the above rules, it will just work! The network queue will have two backlogged operations (the edit and the delete), each with the same tempid that you currently know. When the create finally returns it will automatically rewrite all of the tempids in state and the network queues, then send the next operation. Thus, the edit will apply to the current server entity, as will the delete.
All the server code has to do is return a map with the special key :fulcro.client.primitives/tempids
(or the legacy :tempids) whose value is a map of tempid→realid whenever it sees an ID during persistence operations.
Here are the client-side and server-side implementations of the same mutation that create a new item:
;; client
;; src/my_app/mutations.cljs
(ns my-app.mutations
(:require [fulcro.client.mutations :refer [defmutation]]))
(defmutation new-item [{:keys [tempid text]}]
(action [{:keys [state]}]
(swap! state assoc-in [:item/by-id tempid] {:db/id tempid :item/text text}))
(remote [env] true));; server
;; src/my_app/mutations.clj
(ns my-app.mutations
(:require [fulcro.client.primitives :as prim]
[fulcro.server :refer [defmutation]]))
(defmutation new-item [{:keys [tempid text]}]
(action [{:keys [state]}]
(let [database-tempid (make-database-tempid)
database-id (add-item-to-database database {:db/id database-tempid :item/text text})]
{::prim/tempids {tempid database-id}})))Other mutation return values are covered in Mutation Return Values.
9.5.5. Remote Reads After a Mutation
In earlier sections you learned that you can list properties with your mutation to indicate re-renders. These follow-on read keywords are always local re-render reads, and nothing more:
(prim/transact! this '[(app/f) :thing])
; Does mutation, and re-renders anything that has :thing in a queryFulcro will automatically queue remote reads after writes when they are submitted in the same thread interaction:
(prim/transact! this `[(f)])
(df/load this :thing Thing)
(prim/transact! this `[(g)])will result in two network interactions. The first will run [(f) (g)], and the second will be a load of :thing. This
is a defined and official behavior.
Thus, one way you can implement a sequence of mutation followed by learning a result is to run a mutation and a load.
9.5.6. Pessimistic Transactions
There are scenarios where the above behavior is not what you want. In particular are cases like form submission where you might want to wait until the server completes, so that the user can be kept in the form until you’ve confirmed the server isn’t down or something.
Fulcro 2.0+ has support for pessimistic transactions that enable exactly this sort of behavior:
(prim/ptransact! this `[(a) (b)])Will run `a’s action, `a’s remote, then `b’s action and `b’s remote. This can be combined with analysis of mutation return values to allow you to follow a remote operation with a UI one:
; assume submit-my-form blocks the UI, and leave-form-if-ok checks app state and moves on.
(prim/ptransact! this `[(submit-my-form) (leave-form-if-ok)])|
Warning
|
Use caution when using mutations with conditional remote behavior.
ptransact! detects which mutations are remote by pre-running them (they are side-effect free)
against the app state as it is at the beginning of the transaction. If you have a mutation in the middle
that relies on the state modifications of a prior mutation in the same transaction in order to decide if
it is remote then it will be mis-detected.
|
9.5.7. Using Loads as Mutations
There is technically nothing wrong with issuing a load that has side-effects on the server (though one could argue that this is a bit sketchy from a design perspective). For example, one way to implement login is to issue a load with the user’s credentials:
(df/load :current-user User {:params {:username u :password p}})The server query response can validate the credentials, set a cookie, and return the user info all at once! Your UI can
simply base rendering on the values in :current-user. If they’re valid, you’re logged in.
If you remember from the General Operations section, you can modify the low-level Ring response by associating a lambda with your return value. If you were using Ring Session, then this might be how the query would be implemented on the server:
(ns my-api
(:require [fulcro.server :as server :refer [defmutation defquery-root]]))
(def bad-user {:db/id 0})
(defquery-root :current-user
(value [env params]
(if-let [{:keys [db/id] :as user} (authenticate params)] ; look up the user, return nil if bad
(server/augment-response user (fn [resp] (assoc-in resp [:session :uid] id)))
bad-user)))9.5.8. Running Mutations in the Context of an Entity
If you submit a transaction and include an ident:
(transact! reconciler [:person/by-id 4] `[(f)])then the transaction will run as-if it were executed in the context of any live component on the screen that currently has
that ident. This will make the ident available in the mutation’s environment as :ref, and will focus refresh at that
component sub-tree(s). This can be useful when you have out-of-band data that causes you to want to run a
transaction outside of the UI using the reconciler.
9.5.9. Mutations that Trigger one or more Loads
Mutations generally need not expose their full-stack nature to the UI. For
example a next-page mutation might trigger a load for the next page of
data or simply swap in some already cached data. The UI need not be
aware of the logic of this distinction (though typically the UI will
want to include loading markers, so it is common for there to be some
kind of knowledge about lazy loading).
Instead of coding complex "do I need to load that?" logic in the UI (where it most certainly does not belong) one should instead write mutations that abstract it into a nice concept.
Fulcro handles loads by placing entries in a load queue in the application database. Whenever a remote operation is triggered, the networking layer will check this queue and process it.
The fulcro.client.data-fetch/load function simply runs a transact!
that does both (adds the load to the queue and triggers remote processing).
If you’d like to compose one or more loads into a mutation there are helper
functions that will help you do just that: df/load-action and df/remote-load.
The basic pattern is:
(defmutation next-page [params]
(action [{:keys [state] :as env}]
(swap! state ...) ; local optimistic db updates
(df/load-action env :prop Component {:remote :remote}) ; same basic args as `load`, except state atom instead of `this`
(df/load-action env :other Other) {:remote :other-remote}) ; as many as you need...
(remote [env]
(df/remote-load env))) ; notifies back-end that there is some loading to do|
Important
|
The remote-load call need only be done for any one of the remotes you’re talking to. It merely tells the
back-end code to process remote requests (which will hit all remote queues). Thus, the parameters to the load-action
calls are where you actually specify which remote a given load should actually talk to.
|
9.6. Network Activity Indicators
Rendering is completely up to you, but Fulcro handles the networking (technically this is pluggable, but Fulcro still initiates the interactions). That means that you’re going to need some help when it comes to showing the user that something is happening on the network.
The first and easiest thing to use is a global activity marker that is automatically maintained at the root node of your client database.
9.6.1. Global loading activity marker
Fulcro will automatically maintain a global network activity marker at the top level of the app state under the
keyword :ui/loading-data. This key will have a true value when there are network loads awaiting a response from
the server, and will have a false value when there are no network requests in process.
You can access this marker from any component that composes to root by including a link in your component’s query:
(defsc Item ... )
(def ui-item (prim/factory Item {:keyfn :id}))
(defsc List [this {:keys [title items ui/loading-data]}]
{:query [:id :title {:items (prim/get-query Item)} [:ui/loading-data '_]]}
...
(if (and loading-data (empty? items))
(dom/div "Loading...")
(dom/div
(dom/h1 title)
(map ui-item items))))Because the global loading marker is at the top level of the application state, do not use the keyword as a follow-on read to mutations because it may unnecessarily trigger a re-render of the entire application.
In Fulcro 2.6.10+ there is a top-level key called :fulcro.client.network/status that holds a map from remotes to their
current general status (:inactive or :active). These are correct for all Fulcro remotes you’ve added to the
application, and can be used (via a link query) to watch for global activity. Since these are not tied to specific
requests, they have only minor advantages over the older :ui/loading-data marker: They are correct for loads
and mutations, and are split out by remote.
9.6.2. Mutation Activity
Mutations can be passed off silently to the server. You may choose to block the UI if you have reason to believe there will be a problem, but there is usually no other reason to prevent the user from just continuing to use your application while the server processes the mutation. See Pessimistic Transactions for a method of controlling UI around the network activity of remote mutations.
Fulcro Incubator also has "pessimistic mutations", an extention of the mutation system that allows for more pessimistic general operation, and is easier to use.
9.6.3. Tracking Specific Loads
Loads are a different story. It is very often the case that you might have a number of loads running to populate different parts of your UI all at once. In this case it is quite useful to have some kind of load-specific marker that you can use to show that activity.
9.6.4. Normalized Load Markers
Load markers are normalized into a well-known table via an ID that you choose. You can use just about any value (except a boolean) for the id. This has the following behavior:
-
Load markers are placed in a top-level table (the var fulcro.client.data-fetch/marker-table holds the table name), using your marker value as their ID.
-
You can explicitly query for them using an ident join.
|
Warning
|
Do not use a boolean for a marker’s ID as this causes a legacy behavior that is undesirable
(but supported for backwards compatibility). The :marker false option on loads completely disables load markers for
a load, and is the default.
|
Working with Normalized Load Markers
The steps are rather simple: Include the :marker parameter with load, and issue a query for the load marker on
the marker table. The table name for markers is stored in the data-fetch namespace in the var df/marker-table.
(defsc SomeComponent [this props]
{:query [:data :prop2 :other [df/marker-table :marker-id]]} ; an ident in queries pulls in an entire entity
(let [marker (get props [df/marker-table :marker-id])]
...)))
...
(df/load this :key Item {:marker :marker-id})The data fetch load marker will be missing if no loading is in progress. You can use the following functions to detect what state the load is in:
-
(df/ready? m)- Returns true if the item is queued, but not yet active on the network -
(df/loading? m)- Returns true if the item is active on the network
The marker will disappear from the table when network activity completes.
The rendering is up to you, but that is really all there is to it.
Marker IDs for Items That Have Many Instances
In this case you will need to generate a marker ID based on the entity ID, and then use a link query to pull the entire load marker table to see what is loading.
For example, you might define the marker IDs as (keyword "person-load-marker" (str person-id)). Your person
component could then find its load marker like this:
(defn person-markerid [id] (keyword "person-load-marker" (str id)))
(defsc Person [this {:keys [db/id person/name] :as props}]
{:query [:db/id :person/name [df/marker-table '_]]
:ident [:person/by-id :db/id]}
(let [marker-id (person-markerid id)
all-markers (get props df/marker-table)
marker (get all-markers marker-id)]
...))the load might look something like this:
(df/load this [:person/by-id 42] Person {:marker (person-markerid 42)})The example below uses these techniques to name load markers.
|
Note
|
Open up the DB view and turn your server’s latency way up so you can watch the marker state. |
(ns book.demos.loading-indicators
(:require
[fulcro.client.dom :as dom]
[fulcro.client.data-fetch :as df]
[fulcro.logging :as log]
[fulcro.client :as fc]
[fulcro.server :as server]
[fulcro.client.primitives :as prim :refer [defsc]]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(server/defquery-entity :lazy-load/ui
(value [env id params]
(case id
:panel {:child {:db/id 5 :child/label "Child"}}
:child {:items [{:db/id 1 :item/label "A"} {:db/id 2 :item/label "B"}]}
nil)))
(server/defquery-entity :lazy-load.items/by-id
(value [env id params]
(log/info "Item query for " id)
{:db/id id :item/label (str "Refreshed Label " (rand-int 100))}))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def initial-state {:ui/react-key "abc"
:panel {}})
(defonce app (atom (fc/make-fulcro-client {:initial-state initial-state})))
(declare Item)
(defsc Item [this {:keys [db/id item/label] :as props}]
; query for the entire load marker table. use the lambda form of query for link queries
{:query (fn [] [:db/id :item/label [df/marker-table '_]])
:ident (fn [] [:lazy-load.items/by-id id])}
(let [marker-id (keyword "item-marker" (str id))
marker (get-in props [df/marker-table marker-id])]
(dom/div label
; If an item is rendered, and the fetch state is present, you can use helper functions from df namespace
; to provide augmented rendering.
(if (df/loading? marker)
(dom/span " (reloading...)")
; the `refresh!` function is a helper that can send an ident-based join query for a component.
; it is equivalent to `(load reconciler [:lazy-load.items/by-id id] Item)`, but finds the params
; using the component itself.
(dom/button {:onClick #(df/refresh! this {:marker marker-id})} "Refresh")))))
(def ui-item (prim/factory Item {:keyfn :db/id}))
(defsc Child [this {:keys [child/label items] :as props}]
{:query [:child/label {:items (prim/get-query Item)}]
:ident (fn [] [:lazy-load/ui :child])}
(let [render-list (fn [items] (map ui-item items))]
(dom/div
(dom/p "Child Label: " label)
(if (seq items)
(map ui-item items)
(dom/button {:onClick #(df/load-field this :items :marker :child-marker)} "Load Items")))))
(def ui-child (prim/factory Child {:keyfn :child/label}))
(defsc Panel [this {:keys [ui/loading-data child] :as props}]
{:initial-state (fn [params] {:child nil})
:query (fn [] [[:ui/loading-data '_] [df/marker-table '_] {:child (prim/get-query Child)}]) ; link querys require lambda
:ident (fn [] [:lazy-load/ui :panel])}
(let [markers (get props df/marker-table)
marker (get markers :child-marker)]
(dom/div
(dom/div {:style {:float "right" :display (if loading-data "block" "none")}} "GLOBAL LOADING")
(dom/div "This is the Panel")
(if marker
(dom/h4 "Loading child...")
(if child
(ui-child child)
(dom/button {:onClick #(df/load-field this :child :marker :child-marker)} "Load Child"))))))
(def ui-panel (prim/factory Panel))
; Note: Kinda hard to do idents/lazy loading right on root...so generally just have root render a div
; and then render a child that has the rest.
(defsc Root [this {:keys [panel] :as props}]
{:initial-state (fn [params] {:panel (prim/get-initial-state Panel nil)})
:query [{:panel (prim/get-query Panel)}]}
(dom/div (ui-panel panel)))|
Note
|
You can also just use something like a component’s ident for the marker ID. This sounds confusing at first, but
just think of the marker ID as any opaque value that supports comparison under =.
|
9.7. Server Mutation Return Values
The server mutation is always allowed to return a value. Normally the only value that makes sense is the temporary ID remapping as previoiusly discussed in the main section of full-stack mutations. It is automatically processed by the client and causes the tempid to be rewritten everywhere in your state and network backlog:
; server-side
(defmutation new-thing [params]
(action [env]
...
{::prim/tempids {old-id new-id}}))In some cases you’d like to return other details. However, remember that any data merge needs a tree of data and a query. With a mutation there is no query! As such, return values from mutations are ignored by default because there is no way to understand how to merge the result into your database. Remember we’re trying to eliminate the vast majority of callback hell and keep asynchrony out of the UI. The processing pipeline is always: update the database state, re-render the UI.
If you want to make use of the returned values from the server then you need to add something to remedy the lack of a query.
9.7.1. Using Mutation Joins
The solution might be obvious to you: include the query with the mutation! This is called a mutation join. The explicit syntax for a mutation join looks like this:
`[{(f) [:x]}]but you never write them this way because a manual query doesn’t have ident information and cannot aid normalization. Instead, you write them just like you do when grabbing queries for anything else:
`[{(f) ~(prim/get-query Item)}]Running a mutation with this notation allows you to return a value from the server’s mutation that exactly matches the graph
of the item, and it will be automatically normalized and merged into your database. So, if the Item query ended up being
[:db/id :item/value] then the server mutation could just return a simple map like so:
; server-side
(defmutation f [params]
(action [env]
{:db/id 1 :item/value 42})) ; ok to return one (a map) OR many (as a vector of maps)|
Note
|
At the time of this writing the query must come from a UI component that has an ident. Thus, mutations joins essentially normalize things into a specific table in your database (determined by the ID(s) of the return value and the ident on the query’s component). Newer versions may relax this restriction. |
9.7.2. Mutation Joins: Simpler Notation
Writing transact! using mutation joins is a bit visually noisy. It turns out there is a better way.
If you remember: the remote section of client mutations can return a boolean or an AST. Fulcro comes with helper functions that can
rewrite the AST of the mutation to modify the parameters or convert it to a mutation join! This can simplify how the
mutations look in the UI.
Here’s the difference. With the manual syntactic technique we just described your UI and client mutation would look something like this:
; in the UI
(transact! this `[{(f) ~(prim/get-query Item)}])
; in your mutation definition (client-side)
(defmutation f [params]
(action [env] ...)
(remote [env] true))However, using the helpers you can instead write it like this:
(ns api
(:require [fulcro.client.mutations :refer [returning]]))
; in the UI
(transact! this `[(f)])
; in your mutation definition (client-side)
(defmutation f [params]
(action [env] ...)
(remote [{:keys [ast state]}] (returning ast state Item))This makes the mutation join an artifact of the network interaction, and less for you to manually code (and read) in the UI.
The server-side code is the same for both: just return a proper graph value!
9.7.3. Targeting Return Values From Mutation Joins
If you use the AST with mutation joins, then Fulcro gives you an additional bonus: A helper you can use with your mutation to indicate that the given mutation return value should be further integrated into your app state. By default, you’re just returning an entity. The data gets normalized, but there is no further linkage into your app state.
You will sometimes want to pepper idents around your app state as a result of the return. You can add this kind of targeting through the AST in the remote (not available at the UI layer):
(defmutation f [params]
(action [env] ...)
(remote [{:keys [ast state]}]
(-> ast
(m/returning state Item)
(m/with-target [:path :to :field])))Special targets are also supported:
(defmutation f [params]
(action [env] ...)
(remote [{:keys [ast state]}]
(-> ast
(m/returning state Item) ; Returns something of type Item, will merge/normalize
(m/with-target ; Place the ident pointing to the loaded item in app state at additional locations
(df/multiple-targets
(df/append-to [:table 3 :field])
(df/prepend-to [:table-2 4 :field]))))))Demo of Mutation Joins
The demo below cover the basics of using mutation joins. It demonstrates:
-
Targeting Raw Values
If you don’t specify a component with
returning, then your returned data can be targeted, but of course it won’t normalize. The error triggering mutation does this:(defmutation trigger-error "This mutation causes an unstructured error (just a map), but targets that value to the field `:error-message` on the component that invokes it." [_] (remote [{:keys [ast ref]}] (m/with-target ast (conj ref :error-message))))and the server simply returns a raw value (map is recommended)
(server/defmutation trigger-error [_] (action [env] {:error "something bad"})) -
Targeting Graph Results
In the demo The bulk of the work is done in the
create-entitymutation. which is targeting to-many so we can demo more features.(defmutation create-entity "This mutation simply creates a new entity, but targets it to a specific location (in this case the `:child` field of the invoking component)." [{:keys [where?] :as params}] (remote [{:keys [ast ref state]}] (let [path-to-target (conj ref :children) ; replacement cannot succeed if there is nothing present...turn those into appends no-items? (empty? (get-in @state path-to-target)) where? (if (and no-items? (= :replace-first where?)) :append where?)] (cond-> (-> ast ; always set what kind of thing is coming back (m/returning state Entity) ; strip the where?...it is for local use only (not server) (m/with-params (dissoc params :where?))) ; Add the targeting...based on where? (= :append where?) (m/with-target (df/append-to path-to-target)) ; where to put it (= :prepend where?) (m/with-target (df/prepend-to path-to-target)) (= :replace-first where?) (m/with-target (df/replace-at (conj path-to-target 0)))))))The server mutation just returns the entity (mixed with tempid remappings, if you need them).
(server/defmutation create-entity [{:keys [db/id]}] (action [env] (let [real-id (swap! ids inc)] {:db/id real-id :entity/label (str "Entity " real-id) :tempids {id real-id}})))
(ns book.demos.server-targeting-return-values-into-app-state
(:require
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.server :as server]
[fulcro.client.data-fetch :as df]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def ids (atom 1))
(server/defmutation trigger-error [_]
(action [env]
{:error "something bad"}))
(server/defmutation create-entity [{:keys [db/id]}]
(action [env]
(let [real-id (swap! ids inc)]
{:db/id real-id
:entity/label (str "Entity " real-id)
:tempids {id real-id}})))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(declare Item Entity)
(defmutation trigger-error
"This mutation causes an unstructured error (just a map), but targets that value
to the field `:error-message` on the component that invokes it."
[_]
(remote [{:keys [ast ref]}]
(m/with-target ast (conj ref :error-message))))
(defmutation create-entity
"This mutation simply creates a new entity, but targets it to a specific location
(in this case the `:child` field of the invoking component)."
[{:keys [where?] :as params}]
(remote [{:keys [ast ref state]}]
(let [path-to-target (conj ref :children)
; replacement cannot succeed if there is nothing present...turn those into appends
no-items? (empty? (get-in @state path-to-target))
where? (if (and no-items? (= :replace-first where?))
:append
where?)]
(cond-> (-> ast
; always set what kind of thing is coming back
(m/returning state Entity)
; strip the where?...it is for local use only (not server)
(m/with-params (dissoc params :where?)))
; Add the targeting...based on where?
(= :append where?) (m/with-target (df/append-to path-to-target)) ; where to put it
(= :prepend where?) (m/with-target (df/prepend-to path-to-target))
(= :replace-first where?) (m/with-target (df/replace-at (conj path-to-target 0)))))))
(defsc Entity [this {:keys [entity/label]}]
{:ident [:entity/by-id :db/id]
:query [:db/id :entity/label]}
(dom/div label))
(def ui-entity (prim/factory Entity {:keyfn :db/id}))
(defsc Item [this {:keys [db/id error-message children]}]
{:query [:db/id :error-message {:children (prim/get-query Entity)}]
:initial-state {:db/id :param/id :children []}
:ident [:item/by-id :db/id]}
(dom/div {:style {:float "left"
:width "200px"
:margin "5px"
:border "1px solid black"}}
(dom/h4 (str "Item " id))
(when error-message
(dom/div "The generated error was: " (pr-str error-message)))
(dom/button {:onClick (fn [evt] (prim/transact! this `[(trigger-error {})]))} "Trigger Error")
(dom/h6 "Children")
(map ui-entity children)
(dom/button {:onClick (fn [evt] (prim/transact! this `[(create-entity {:where? :prepend :db/id ~(prim/tempid)})]))} "Prepend one!")
(dom/button {:onClick (fn [evt] (prim/transact! this `[(create-entity {:where? :append :db/id ~(prim/tempid)})]))} "Append one!")
(dom/button {:onClick (fn [evt] (prim/transact! this `[(create-entity {:where? :replace-first :db/id ~(prim/tempid)})]))} "Replace first one!")))
(def ui-item (prim/factory Item {:keyfn :db/id}))
(defsc Root [this {:keys [root/items]}]
{:query [{:root/items (prim/get-query Item)}]
:initial-state {:root/items [{:id 1} {:id 2} {:id 3}]}}
(dom/div
(mapv ui-item items)
(dom/br {:style {:clear "both"}})))9.7.4. Augmenting the Merge
There is also a sledge-hammer approach to return values: plug into Fulcro’s merge routines. This is an advanced technique and is not recommended for most applications.
Fulcro gives a hook for a mutation-merge function that you can install when you’re creating the application. If you
use a multi-method, then it will make it easier to co-locate your return value logic near the client-local mutation itself:
(defmulti return-merge (fn [state mutation-sym return-value] mutation-sym))
(defmethod return-merge :default [s m r] s)
(make-fulcro-client {:mutation-merge return-merge ...})Now you should be able to write your return merging logic next to the mutation that it goes with. For example:
(defmethod m/mutate 'some-mutation [env k p] {:remote true })
(defmethod app/return-merge 'some-mutation [state k returnval] ...new-state...)Note that the API is a bit different between the two: mutations get the app state atom in an environment, and you
swap! on that atom to change state. The return merge function is in an already running swap! during the state merge
of the networking layer. So, it is a function that takes the application state as a map and must
return a new state as a map.
This technique is fully general in terms of handling arbitrary return values, but is limited in that your only recourse is to merge the data into you app state. Of course, since your rendering is a pure function of app state this means you can, at the very least, visualize the result.
This works, but is not the recommended approach because it is very easy to make mistakes that affect your entire application.
|
Note
|
Mutation merge happens after server return values have been merged; however, it does happen before tempid remapping. Just work with the tempids, and they will be rewritten once your merge is complete. |
Live Example of a Mutation Merge
In the example below the displayed volume is coming from the server’s mutation return value. Use the server latency to convince yourself of this. Notice if you click too rapidly then the value doesn’t increase any faster than the server can respond (since it computes the new volume based on what the client sends).
The merge function is most easily dealt with as a multimethod so you can dispatch on the mutation symbol:
(defmulti merge-return-value (fn [state sym return-value] sym))We’re going to return a map with :new-volume in it from the server, so our merge can look like this:
(defmethod merge-return-value `crank-it-up
[state _ {:keys [new-volume]}]
(assoc-in state [:child/by-id 0 :volume] new-volume))Our mutation asks a remote server to increase the volume. The client and server mutations are:
;; client-side
(m/defmutation crank-it-up [params]
(remote [env] true))(server/defmutation crank-it-up [{:keys [value]}]
(action [env]
{:new-volume (inc value)}))The remainder of the setup is just giving the merge handler function to the application at startup:
(fc/make-fulcro-client {:mutation-merge merge-return-value})(ns book.demos.server-return-values-manually-merging
(:require
[fulcro.client.dom :as dom]
[fulcro.server :as server]
[fulcro.client.mutations :as m]
[fulcro.client.primitives :as prim :refer [defsc]]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(server/defmutation crank-it-up [{:keys [value]}]
(action [env]
{:new-volume (inc value)}))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defmulti merge-return-value (fn [state sym return-value] sym))
; Do all of the work on the server.
(m/defmutation crank-it-up [params]
(remote [env] true))
(defmethod merge-return-value `crank-it-up
[state _ {:keys [new-volume]}]
(assoc-in state [:child/by-id 0 :volume] new-volume))
(defsc Child [this {:keys [id volume]}]
{:initial-state (fn [params] {:id 0 :volume 5})
:query [:id :volume]
:ident [:child/by-id :id]}
(dom/div
(dom/p "Current volume: " volume)
(dom/button {:onClick #(prim/transact! this `[(crank-it-up ~{:value volume})])} "+")))
(def ui-child (prim/factory Child))
(defsc Root [this {:keys [child]}]
{:initial-state (fn [params] {:child (prim/get-initial-state Child {})})
:query [{:child (prim/get-query Child)}]}
(dom/div (ui-child child)))9.8. Loads From Within Mutations
It is often the case that a load results from user interaction with the UI. But it is also the case that the load isn’t everything you want to do, or that you’d like to hide the load logic or base it on current state that the triggering component does not know.
9.8.1. Load Actions in Mutations
In reality load and load-field call prim/transact! under the hood, targeting fulcro’s built-in fulcro/load
mutation, which is responsible for sending your request to the server.
There are similar functions: load-action and load-field-action
that do not call prim/transact!, but instead just push a load request into the load queue and can be used to
inside of one of your own client-side mutations.
Let’s look at an example of a standard load. Say you want to load a list of people from the server:
(require [fulcro.client.data-fetch :as df])
(defsc Person [this props]
{:query [:id :name]}
... )
(def ui-person (prim/factory Person))
(defsc PeopleList [this {:keys [people]}]
{:query [:db/id :list-title {:people (prim/get-query Person}]
:ident [:people-list/by-id :db/id]}
(dom/div
(if (seq people)
(dom/button {:onClick #(df/load-field this :people)} "Load People")
(map ui-person people))))Since we are in the UI and not inside of a mutation’s action thunk, we can use load-field to initialize the
call to prim/transact!.
The action-suffixed load functions are useful when performing an action in the user interface that must both modify the client-side database and load data from the server.
|
Note
|
You must use the result of the
fulcro.client.data-fetch/remote-load funtion as the value of the remote in the mutation. The
action calls of load-action place the request on a queue. The remote-load returns the correct indicator to
Fulcro so that it knows you queued a load. If you forget it, then your load won’t be processed until the next
operation causes remote interactions.
|
(require [fulcro.client.data-fetch :as df]
[fulcro.client.mutations :refer [mutate]]
[app.ui :as ui])
(defmutation change-view [{:keys [new-view]}]
(action [{:keys [state] :as env}]
(let [new-view-comp (cond
(= new-view :main) ui/Main
(= new-view :settings) ui/Settings]
(df/load-action env new-view new-view-comp) ;; Add the load request to the queue
(swap! state update :app/current-view new-view))}))
(remote [env] (df/remote-load env))) ;; Tell Fulcro you did something that requires remoteThis snippet defines a mutation that modifies the app state to display the view passed in via the mutation parameters and loads the data for that view. A few important points:
-
If an action thunk calls one or more
action-suffixed load functions (which do nothing but queue the load request) then it MUST also callremote-loadon the remote side. -
The
remote-loadfunction changes the mutation’s dispatch key tofulcro/loadwhich in turn triggers the networking layer that one or more loads are ready. IMPORTANT: Remote loading cannot be mixed with a mutation that also needs to be sent remotely. I.e. one could not sendchange-viewto the server in this example. -
If you find yourself wanting to put a call to any
load-*in a React Lifecycle method try reworking the code to use your own mutations (which can check if a load is really needed) and the use the action-suffixed loads instead. Lifecycle methods are often misunderstood, leading to incorrect behaviors like triggering loads over and over again.
9.8.2. Using the fulcro/load Mutation Directly (NOT recommended)
Fulcro has a built-in mutation fulcro/load (also aliased as fulcro.client.data-fetch/load).
The mutation can be used from application startup or anywhere you’d run a mutation (transact!). This covers almost
all of the possible remote data integration needs!
The helper functions described above simply trigger this built-in Fulcro mutation
(the *-action variants do so by modifying the remote mutation AST via the remote-load helper function).
You are allowed to use this mutation directly in a call to transact!, but you should never need to.
The arguments to this mutation include most of the options that load can take, but you do
need to specify query. For most direct use-cases you’ll probably skip using the load-field specific parameters
described in the docstring (:field and :ident). You can read the source of load-field if you’d like to simulate
it by hand.
For example:
(load reconciler :prop nil)is a simple helper that is ultimately identical to:
(prim/transact! reconciler '[(fulcro/load {:query [:prop]}) :ui/loading-data])(the follow-on read is to ensure load markers update).
9.9. Incremental Loading
It is very common for your UI query to have a lot more in it than you want to load at any given time. In some cases, even a specific entity asks for more than you’d like to load. A good example of this is a component that allows comments. Perhaps you’d like the initial load of the component to not include the comments at all, then later load the comments when the user, for example, opens (or scrolls to) that part of the UI.
Fulcro makes this quite easy. There are three basic steps:
-
Put the full query on the UI
-
When you use that UI query with load, prune out the parts you don’t want.
-
Later, ask for the part you do want.
Step 2 sounds like it will be hard, but it isn’t:
9.9.1. Pruning the Query
Sometimes your UI graph asks for things that you’d like to load incrementally. Let’s say you were loading a blog post that has comments. Perhaps you’d like to load the comments later:
(df/load app :server/blog Blog {:params {:id 1 }
:target [:screens/by-name :blog :current-page]
:without #{:blog/comments}})The :without parameter can be used to elide portions of the query (it works recursively). The query sent to the
server will not ask for :blog/comments. Of course, your server has to parse and honor the exact details
of the query for this to work (if the server decides it’s going to returns the comments, you get them…but this is why
we disliked REST, right?)
(server/defquery-root :server/blog
(value [{:keys [query]} {:keys [id]}] ; query will be the query of Blog, without the :comments
; use a parser on query to get the proper blog result. See Server Interactions - Query Parsing
(get-blog id query)))9.9.2. Filling in the Subgraph
Later, say when the user scrolls to the bottom of the screen or clicks on "show comments" we can load the rest
from of this previously partially-loaded graph within the Blog itself using load-field, which does the opposite
of :without on the query:
(defsc Blog [this props]
{:ident [:blog/by-id :db/id]
:query [:db/id :blog/title {:blog/content (prim/get-query BlogContent)} {:blog/comments (prim/get-query BlogComment)}]}
(dom/div
...
(dom/button {:onClick #(load-field this :blog/comments)} "Show Comments")
...)))The load-field function prunes everything from the query except for the branch
joined through the given key. It also generates an entity rooted query based on the calling component’s ident:
[{[:table ID] subquery}]where the [:table ID] are the ident of the invoking component, and subquery is (prim/get-query invoking-component), but
focused down to the one field. In the example above, this would end up something like this:
[{[:blog/by-id 1] [{:blog/comments [:db/id :comment/author :comment/body]}]}]This kind of query can be handled on the server with defquery-entity (which is triggered on these kinds of ident joins):
(server/defquery-entity :blog/by-id
(value [{:keys [query]} id params]
(get-blog id query))) ; SAME HANDLER WORKS!!!Load Focus
Another way to load a subgraph part is to use the :focus setting on the load, :focus
allow you to define a subquery to be loaded from the component query, to start simple here
is how we can write the same previous example using :focus:
(defsc Blog [this props]
{:ident [:blog/by-id :db/id]
:query [:db/id :blog/title {:blog/content (prim/get-query BlogContent)} {:blog/comments (prim/get-query BlogComment)}]}
(dom/div
...
(dom/button {:onClick #(load this (prim/get-ident this) Blog {:focus [:blog/comments]})}
"Show Comments")
...)))Although the interface requires more code, it’s more flexible, let’s say for instance you only want to load the comment id and author, you can write as:
(load this (get-ident this) Blog {:focus [{:blog/comments [:db/id :comment/author]}]})As you might notice, in the first :focus example when we point to a join, the whole
join sub-query will be pulled, but you can get more precise by expressing more of the
sub-query.
Load focus on unions
A special case that worth mention about focus sub-query is how it handles unions. Other
than on unions, :focus will only use the attributes mentioned on the sub-query, but
on unions, if you don’t express some union branch it will be pulled as is, for example, let’s
say you have this given query:
[{:feed/item {:message [:message/text :message/timestamp]
:activity [:activity/source-id :activity/url]}}]If you :focus on this:
[{:feed/item {:message [:message/text]}}]Then you get out the query:
[{:feed/item {:message [:message/text]
:activity [:activity/source-id :activity/url]}}]This makes sure you will keep all union branches.
9.10. Full-Stack Error Handling
The first thing I want to challenge you to think about is this: why do errors happen, and what can we do about them?
In the early days of web apps, our UI was completely dumb: the server did all of the logic. The answer to these questions were clear, because it wasn’t even a distributed app: it was a remote display of an app running on a remote machine. In other words, the context of the error handling was available at the same time as our request to do the operation.
So we often block the UI so that the user cannot get ahead of things (like submit a form and move on before the server has confirmed the submission). Over the years we’ve gotten a little more clever with our error handling, but largely our users (and our ability to reason about our programs) has kept us firmly rooted to the block-until-we-know method of error handling because it is actually less like a distributed system. Unfortunately, such UI interactions are doomed to feel sluggish in congested or bandwidth-limited environments.
More and more code is moving to the client machine. In the world of single-page apps we want things to "make sense" and we also want them to be snappy. Unfortunately, we still also have security concerns at the server, so we get confused by the following fact: the server has to be able to validate a request for security reasons. There is no getting around this. You cannot trust a client.
However, I think many of us take this too far: security concerns are often a lot easier to enforce than the full client-level interaction with these concerns. For example, we can say on a server that a field must be a number. This is one line of code that can be done with an assertion.
The UI logic for this is much larger: we have to tell the user what we expected, why we expected it, constrain the UI to keep them from typing letters, etc. In other words, almost all of the real logic is already on the client, and unless there is a bug, our UI won’t cause a server error because it is pre-checking everything before sending it out.
So, in a modern UI, here are the scenarios for errors from the server:
-
You have a bug. Is there anything you can really do? No, because it is a bug. If you could predict it going wrong, you would have already fixed it. Testing and user bug reports are your only recourse.
-
There is a security violation. There is nothing for your UI to do, because your UI didn’t do it! This is an attack. Throw an exception on the server, and never expect it in the UI. If you get it, it is a bug. See (1).
-
There is a user perspective outage (LAN/WiFi/phone). These are possibly recoverable. You can block the UI, and allow the user to continue once networking is re-established.
-
There is an infrastructure outage. You’re screwed. Things are just down. If you’re lucky, it is networking and your user is seeing it as (3) and is just blocked. If you’re not lucky, your database crashed and you have no idea if your data is even consistent.
So, I would assert that the only full-stack error handling worth doing in any detail is for case (3). If communications are down, the client can retry. But in a distributed system this can be a little nuanced. Did that mutation partially complete?
If your application can assume reasonably reliable networking and you write your server operations to be atomic then your error handling can be a relatively small amount of code. Unrecoverable problems will be rare and at worst you throw up a dialog that says you’ve had an error and the user hits reload on their browser. If this happens to users once or twice a year, it isn’t going to hurt you.
But of course there is more to the story, and the devil is in the details.
9.10.1. Programming with Pure Optimism
The general philosophy of a Fulcro application is that optimistic updates are not even triggered on the client unless they expect to succeed on the server. In other words, you write the application in such a way that operations cannot be triggered from the UI unless you’re certain that a functioning server will execute them. A server should not throw an exception and trigger a need for error handling unless there is a real, non-recoverable situation.
If this is true, then a functioning server does need to do sanity checking for security reasons, but in general you don’t need to give friendly errors when those checks fail: you should assume they are attempted hacks. Other serious problems are similar: there is usually nothing you can do but throw an exception and let the user contact support. Exceptions to this rule certainly exist, but they are few and far between.
There are some cases where the server has to be involved in a validation interaction non-optimistically. Login is a great example of this. However, invalid credentials on login need not be treated as an error! Instead they can be treated as a response to a question. "Can I log in with these credentials?". Yes or no. This is a query and response, not an error handling interaction. Thus, something like login can be handled with a query (to get the answer) and post-mutation (to update the screen with a message or change the UI route).
This philosophy eases the overhead in general application programming. You need not write a bunch of code in the UI that gives a nice friendly message for every kind of error that can possibly occur (nor does anyone really do that anywhere anyhow). If an error occurs, you can pretty much assume it is either a bug or a real outage. In both cases, there isn’t a lot you can do that will work "well" for the user. If it is a bug, then you really have no chance of predicting what will fix it, otherwise you would have already fixed the bug. If it’s an outage you might be able to do retries, but in many cases you have no way of knowing what has gone wrong.
So, one approach is to treat most error conditions as a rare problem that needs fairly radical recovery. One such method is to use a global error handler that is configured during the setup of your client application (you have to explicitly configure networking). This function could update application state to show some kind of top-level modal dialog that describes the problem, possibly allows the user to submit application history (for support viewer) to your servers, and then re-initializes the application in some way.
You can, of course, get pretty creative with the re-initialization. For example, say you write screens so that they will refresh their persistent data whenever it is older than some amount of time, and write it so all entities have a timestamp. You could walk the state and "expire" all of the timestamps, and then close the dialog. Your retry could be set up to check for the expiration, which in turn would trigger loads. If the server is really having problems then the worst case is that the dialog pops back up telling them there is still a problem.
9.10.2. Being a Bit More Pessimistic — Flaky Network Operation
If your users are likely using your software from a phone on a subway then you have a completely different issue.
Fortunately, Fulcro actually makes handling this case relatively easy as well. Here is what you can do:
-
Write a custom networking implementation for the client that detects the kind of error, and retries recoverable ones until they succeed. Possibly with exponential backoff. (If an infinite loop happens, the user will eventually hit reload.)
-
Make your server mutations idempotent so that a client can safely re-apply a transaction without causing data corruption.
The default fulcro networking does not do retries because it isn’t safe without the idempotent guarantee.
The optimistic updates of Fulcro and the in-order server execution means that "offline" operation is actually quite tractable. If programmed this way, your error handling becomes isolated almost entirely to the networking layer. Of course, if the user navigates to a screen that needs server data, they will just have to wait. Writing UI code that possibly has lifecycle timers to show progress updates will improve the overall feel, but the correctness will be there with a fairly small number of additions.
However, even with these fancy tricks that make our applications better, there are times when we’d just like to block until something is complete.
9.10.3. Detecting Errors From the Server
The built-in remote and networking in Fulcro has a few hooks for dealing with errors:
-
A global network error handler for dealing with actual network errors (i.e. you can’t talk to the server).
-
A global root node value (at
:fulcro/server-error) you can query that holds the last network error. (You manually clear this if you wish to use it to track errors over time.) -
The ability to run a mutation if a load fails with an application-level error (load option
:fallback). See fallbacks. -
Mutation fallbacks for responding to full-stack application-level mutation errors.
Global Error Handler
This is only available if you use the built-in remote with the Fulcro client. If you write your own networking then you can handle errors at the network layer any way you want. To install a network error handler on the default remote support simply write a function like this:
;; this function is called on *every* network error, regardless of cause
(defn error-handler "To be used as network-error-callback"
[state status-code error]
(log/warn "Global callback:" error " with status code: " status-code))and install it:
(fc/make-fulcro-client {:network-error-callback error-handler})Server Error Demo
The live example below does various things to demonstrate various ways of reacting to errors. There is a load that fails and uses a fallback to log a message.
The next button tries a mutation that fails (by throwing on the server in a way that propagates the error back to the client). The final one tries a read that will fail, but does nothing with the error, though you’ll still see that the global indicator updates.
(ns book.demos.server-error-handling
(:require
[fulcro.client :as fc]
[fulcro.client.data-fetch :as df]
[fulcro.logging :as log]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.server :as server]
[fulcro.client.dom :as dom]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(server/defmutation error-mutation [params]
;; Throw a mutation error for the client to handle
(action [env] (throw (ex-info "Server error" {:type :fulcro.client.primitives/abort :status 401 :body "Unauthorized User"}))))
(server/defquery-entity :error.child/by-id
(value [env id params]
(throw (ex-info "other read error" {:status 403 :body "Not allowed."}))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Just send the mutation to the server, which will return an error
(defmutation error-mutation [params]
(remote [env] true))
;; an :error key is injected into the fallback mutation's params argument
(defmutation disable-button [{:keys [error ::prim/ref] :as params}]
(action [{:keys [state]}]
(log/warn "Mutation specific fallback -- disabling button due to error from mutation invoked at " ref)
(swap! state assoc-in [:error.child/by-id :singleton :ui/button-disabled] true)))
(defmutation log-read-error [{:keys [error]}]
(action [env] (log/warn "Read specific fallback: " error)))
(defsc Child [this {:keys [fulcro/server-error ui/button-disabled]}]
;; you can query for the server-error using a link from any component that composes to root
{:initial-state (fn [p] {})
:query (fn [] [[:fulcro/server-error '_] :ui/button-disabled :fulcro/read-error])
:ident (fn [] [:error.child/by-id :singleton])} ; lambda so we get a *literal* ident
(dom/div
;; declare a tx/fallback in the same transact call as the mutation
;; if the mutation fails, the fallback will be called
(dom/button {:onClick #(df/load this :data nil {:fallback `log-read-error})}
"Click me to try a read with a fallback (logs to console)")
(dom/button {:onClick #(prim/transact! this `[(error-mutation {}) (df/fallback {:action disable-button})])
:disabled button-disabled}
"Click me for error (disables on error)!")
(dom/button {:onClick #(df/load-field this :fulcro/read-error)}
"Click me for other error!")
(dom/div "Server error (root level): " (str server-error))))
(def ui-child (prim/factory Child))
(defsc Root [this {:keys [child]}]
{:initial-state (fn [params] {:child (prim/get-initial-state Child {})})
:query [{:child (prim/get-query Child)}]}
(dom/div (ui-child child)))9.10.4. UI Blocking
Fulcro defaults to optimistic updates, which in turn encourages you to write a UI that is very responsive. However, as soon as you start writing remote mutations you start worrying about the fact that your user submitted some data but you let them go off and do other things (like leave the screen they’re on) before the server has responded. In effect, we’ve told the user "success", but we know we’re kind of lying to them.
Another way of looking at it is: we’re letting them leave the visual context of the information, but we know that if a server error happens then we need to inform them about that error. We’d like to be sure they understand the error by still seeing that context when it arrives.
This is a rather complicated way of saying something like "if their email change didn’t work, then we’d like to show the error next to the email input box".
There is nothing in Fulcro that prevents you from writing a blocking UI. You just have to remember that the UI is a pure rendering of application state: meaning that if you want to block the UI, then you need a way to put a "block the ui" marker in state (that renders in a way that prevents navigation), and remove that marker when the operation is complete.
Fulcro has a number of ways that you can accomplish this, but we’ll cover the simplest and most obvious.
Blocking on Remote Mutations
This technique uses the following pattern:
-
We use the
prim/ptransact!to submit a transaction, which will run each mutation in pessimistic mode (each element runs only after the prior element has completed a round-trip to the server). -
The first call in the tx will block the UI, and do the remote operation. We’ll also leverage mutation return values so the server can indicate success to us.
-
Once the first call finishes, the second call in the tx can choose to unblock the UI, or handle any problem it sees. The mutation return value is merged (and visible) in app state.
Unlike normal mode, pessimistic transactions expect that you might have to nest another one within a mutation in order to retry a
prior call. This is a supported use, and you will find the reconciler in the mutation’s env parameter to facilitate it as
shown in the example below.
To show how this all works we’ll use an in-browser server emulation and show you a working example.
First, we need something to block our UI (which in the card measures 400x100 px). It is a simple div with some style that will overlay the main UI and prevent further interactions while also showing some kind of feedback message. The CSS sucks, but let’s ignore that for now.
We define it, along with some helper functions that can manipulate its state. It does not have an ident, and we
plan to just place it in root at :overlay:
(defn set-overlay-visible* [state tf] (assoc-in state [:overlay :ui/active?] tf))
(defn set-overlay-message* [state message] (assoc-in state [:overlay :ui/message] message))
(defsc BlockingOverlay [this {:keys [ui/active? ui/message]}]
{:query [:ui/active? :ui/message]
:initial-state {:ui/active? false :ui/message "Please wait..."}}
(dom/div (clj->js {:style {:position :absolute
:display (if active? "block" "none")
:zIndex 65000
:width "400px"
:height "100px"
:backgroundColor "rgba(0,0,0,0.5)"}})
(dom/div (clj->js {:style {:position :relative
:top "40px"
:color "white"
:textAlign "center"}}) message)))The main UI is just a simple one-field form and submission button. Note, however, that it submits the form
with ptransact!, which will force each call to complete before the next one can start. Thus the second call can
check the result and run whatever in response to it.
(defsc Root [this {:keys [ui/name overlay]}]
{:query [:ui/name {:overlay (prim/get-query BlockingOverlay)}]
:initial-state {:overlay {} :ui/name "Alicia"}}
(dom/div {:style (clj->js {:width "400px" :height "100px"})}
(ui-overlay overlay)
(dom/p "Name: " (dom/input {:value name}))
(dom/button {:onClick #(prim/ptransact! this `[(submit-form) (retry-or-hide-overlay)])}
"Submit")))Now a bit of information about our "server". It has the following definition of the remote mutation:
(server/defmutation submit-form [params]
(action [env]
(if (> 0.5 (rand))
{:message "Everything went swell!"
:result 0}
{:message "There was an error!"
:result 1})))As you can see it’s just a stub that randomly responds with success or error. The client mutation looks like this:
(defmutation submit-form [params]
(action [{:keys [state]}] (swap! state set-overlay-visible* true))
(remote [{:keys [state ast] :as env}]
(m/returning ast state MutationStatus)))It just shows the overlay, and goes remote. Notice the remote part is using returning from the mutations namespace
to indicate a merge of the result value of the mutation. For that we’ve defined a singleton component (for its query only):
(defsc MutationStatus [this props]
{:ident (fn [] [:remote-mutation :status])
:query [:message :result]})This means that when this remote mutation is done, we should see a the return value of the server mutation
at [:remote-mutation :status] (which is the constant ident of MutationStatus).
Now for our second client mutation. First, we need a function that can look in state and see if the mutation status looks ok:
(defn submit-ok? [env] (= 0 (some-> env :state deref :remote-mutation :status :result)))Then we can leverage that to make something that reads well:
(defmutation retry-or-hide-overlay [params]
(action [{:keys [reconciler state] :as env}]
(if (submit-ok? env)
(swap! state (fn [s]
(-> s
(set-overlay-message* "Please wait...") ; reset the overlay message for the next appearance
(set-overlay-visible* false))))
(do
(swap! state set-overlay-message* (str (-> state deref :remote-mutation :status :message) " (Retrying...)"))
(prim/ptransact! reconciler `[(submit-form {}) (retry-or-hide-overlay {})])))))It’s the real work-horse. The optimistic side can assume the result is updated, so it looks for the result code via
submit-ok?. If things are OK, then it resets the overlay message and hides it.
If the submission had an error, then it
-
Adds "retrying" to the server message and puts that on the overlay
-
Does a new call to
ptransact!.
You can try out the finished product in the example below. Try it a few times so you can see the error-handling in action.
(ns book.server.ui-blocking-example
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[fulcro.client.cards :refer [defcard-fulcro]]
[fulcro.client.mutations :as m]
[fulcro.server :as server]
[fulcro.client.mutations :as m :refer [defmutation]]
[book.macros :refer [defexample]]))
;; SERVER
(server/defmutation submit-form [params]
(action [env]
(if (> 0.5 (rand))
{:message "Everything went swell!"
:result 0}
{:message "There was an error!"
:result 1})))
;; CLIENT
(defsc BlockingOverlay [this {:keys [ui/active? ui/message]}]
{:query [:ui/active? :ui/message]
:initial-state {:ui/active? false :ui/message "Please wait..."}}
(dom/div (clj->js {:style {:position :absolute
:display (if active? "block" "none")
:zIndex 65000
:width "400px"
:height "100px"
:backgroundColor "rgba(0,0,0,0.5)"}})
(dom/div (clj->js {:style {:position :relative
:top "40px"
:color "white"
:textAlign "center"}}) message)))
(def ui-overlay (prim/factory BlockingOverlay))
(defn set-overlay-visible* [state tf] (assoc-in state [:overlay :ui/active?] tf))
(defn set-overlay-message* [state message] (assoc-in state [:overlay :ui/message] message))
(defsc MutationStatus [this props]
{:ident (fn [] [:remote-mutation :status])
:query [:message :result]})
(defmutation submit-form [params]
(action [{:keys [state]}] (swap! state set-overlay-visible* true))
(remote [{:keys [state ast] :as env}]
(m/returning ast state MutationStatus)))
(defn submit-ok? [env] (= 0 (some-> env :state deref :remote-mutation :status :result)))
(defmutation retry-or-hide-overlay [params]
(action [{:keys [reconciler state] :as env}]
(if (submit-ok? env)
(swap! state (fn [s]
(-> s
(set-overlay-message* "Please wait...") ; reset the overlay message for the next appearance
(set-overlay-visible* false))))
(do
(swap! state set-overlay-message* (str (-> state deref :remote-mutation :status :message) " (Retrying...)"))
(prim/ptransact! reconciler `[(submit-form {}) (retry-or-hide-overlay {})]))))
(refresh [env] [:overlay])) ; we need this because the mutation runs outside of the context of a component
(defsc Root [this {:keys [ui/name overlay]}]
{:query [:ui/name {:overlay (prim/get-query BlockingOverlay)}]
:initial-state {:overlay {} :ui/name "Alicia"}}
(dom/div {:style {:width "400px" :height "100px"}}
(ui-overlay overlay)
(dom/p "Name: " (dom/input {:value name}))
(dom/button {:onClick #(prim/ptransact! this `[(submit-form {}) (retry-or-hide-overlay {})])}
"Submit")))9.10.5. Fallbacks
If you’re running a mutation is likely to trigger server errors then you can explicitly encode a fallback behavior with the mutation. Fallbacks are triggered the mutation on the server throws an error that is detectable, or if there is a network error.
The requirement for a server mutation to trigger fallbacks is for it to throw an ex-info exception and
include {:type :fulcro.client.primitives/abort} in the data. Otherwise the server-side parser will swallow
the exception and continue with the transaction.
Defining a fallback for a transaction is done by including a special mutation in the transaction that names the mutation to invoke on error:
(prim/transact! this `[(some/mutation) (fulcro.client.data-fetch/fallback {:action handle-failure})])(require [fulcro.client.mutations :refer [mutate]]
[fulcro.client.primitives :as prim)
(defmutation handle-failure [{:keys [error ::prim/ref] :as params}]
;; fallback mutations are designed to recover the client-side app state from server failures
;; THEY DO NOT CHECK FOR REMOTE. You cannot chain a remote interaction in a fallback.
(action [{:keys [state]}]
(swap! state undo-stuff error)))Assuming that some-mutation is remote, then if the server throws a hard error (e.g. status code not 200)
then the fallback action’s mutation symbol (a dispatch key for mutate) is invoked on the
client with params that include an :error key that includes the details of the server exception (error type, message,
and ex-info’s data). Be sure to only include serializable data in the server exception!
If triggered due to a mutation fallback (not load), then the fallback will also receive the ident of the component
that invoked the original transaction in parameters under the key fulcro.client.primitives/ref.
You can have any number of fallbacks in a tx, and they will run in order if the transaction fails.
|
Note
|
It is not recommended that you rely on fallbacks for very much. They are provided for cases where you’d like to code instance-targeted recovery, but we believe this to be a rarely useful feature. You’re much better off preventing errors by coding your UI to validate, authorize, and error check things on the client before sending them to the server. The server should still verify sanity for security reasons, but optimistic systems like Fulcro put more burden on the client code in order to provide a better experience under normal operation. See the earlier discussion about error handling. |
If you do use fallback then you probably also need to clear the network queue so that additional queued operations don’t continue to fail.
9.10.6. Clearing Network Queue
If the server sends back a failure it may be desirable to clear any pending network requests from the client network queue. For example, if you’re adding an item to a list and get a server error you might have a mutation waiting in your network queue that was some kind of modification to that (now failed) item. Continuing the network processing might just cause more errors.
The FulcroApplication protocol (implemented by your client app) includes the protocol method
clear-pending-remote-requests! which will drain all pending network requests.
(fulcro.client/clear-pending-remote-requests! my-app)A common recovery strategy from errors could be to clean the network queue and run a mutation that resets your application to a known state, possibly loading sane state from the server.
9.10.7. Pessimistic Transaction Fallbacks
The fallback mechanism described for error handling works in ptransact!. Fallbacks are clustered to the remote they follow
up until the next remote mutation (with one exception: fallbacks at the beginning of the entire tx are clustered to the first remote mutation):
(ptransact! this `[(L) (df/fallback {...}) (L) (R) (df/fallback {...}) (L2) (R2) (L3) (df/fallback {...}) ])will associate the first two fallbacks with remote call R, and the last one with R2.
10. Building a Server
In the Getting Started chapter you saw a little on how to build and use Fulcro’s easy server. That server is acually flexible enough for many production needs, but Fulcro also comes with code to help you very quickly get a custom server for your application up and running. In this chapter we’ll give you more detail on these two main approaches to the server-side of Fulcro:
-
How to use the pre-built bits to manually build your own server.
-
More details on the easy server.
10.1. Rolling Your Own Server
If you’re integrating with an existing server then you probably just want to know how to get things working without having to use a Component library, and all of the other stuff that comes along with it.
It turns out that the server API handling is relatively light. Most of the work goes into getting things set up for easy server restart (e.g. making components stop/start) and getting those components into your parsing environment.
If you have an existing server then you’ve mostly figured out all of that stuff already and just want to plug a Fulcro API handler into it.
Here are the basic requirements:
-
Make sure your Ring stack has transit-response and transit-params. You can see a sample Ring stack in [Fulcro’s source](https://github.com/fulcrologic/fulcro/blob/1.2.0/src/main/fulcro/easy_server.clj#L94)
-
Check to see if the incoming request is for "/api". If so:
-
Call [
handle-api-request](https://github.com/fulcrologic/fulcro/blob/1.2.0/src/main/fulcro/server.clj#L354). Pass a parser to it (recommend usingfulcro.server/fulcro-parser), an environment, and the EDN of the request. It will give back a Ring response.
You’re responsible for creating the parser environment. I’d recommend using
the fulcro.server/fulcro-parser because it is already hooked to the server multimethods
like defquery-root and defmutation. Those won’t work unless you use it, but any parser
that can deal with the query/mutation syntax is technically legal.
Here’s a complete little server with full defaults/dev/prod configuration support (see configuration),
and hot code reload using mount instead of component:
(ns demo.server
(:require
[fulcro.server :as server]
[immutant.web :as web]
[mount.core :refer [defstate]]
[ring.middleware.content-type :refer [wrap-content-type]]
[ring.middleware.gzip :refer [wrap-gzip]]
[ring.middleware.params :refer [wrap-params]]
[ring.middleware.multipart-params :refer [wrap-multipart-params]]
[ring.middleware.not-modified :refer [wrap-not-modified]]
[ring.middleware.resource :refer [wrap-resource]]
[ring.util.response :refer [response file-response resource-response]]))
;; You'll need defaults.edn and dev.edn in resources/config with at least {} as content.
(defstate config :start (server/load-config {:config-path "config/dev.edn"}))
(def ^:private not-found-handler
(fn [req]
{:status 404
:headers {"Content-Type" "text/plain"}
:body "NOPE"}))
(defstate server-parser :start (server/fulcro-parser))
(defn wrap-api [handler uri]
(fn [request]
(if (= uri (:uri request))
(server/handle-api-request
server-parser
;; this map is `env`. Put other defstate things in this map and they'll be in the mutations/query env on server.
{:config config}
(:transit-params request))
(handler request))))
(defstate middleware
:start
(-> not-found-handler
(wrap-api "/api")
server/wrap-transit-params
server/wrap-transit-response
(wrap-resource "public")
wrap-content-type
wrap-not-modified
wrap-gzip))
(defstate http-server
:start
(web/run middleware {:host "0.0.0.0"
:port (get config :port 3000)}) ; defaults to 3000, but can also come from config file
:stop
(web/stop http-server))and the user namespace (typically in src/dev):
(ns user
(:require
[clojure.tools.namespace.repl :as tools-ns :refer [set-refresh-dirs]]
demo.server
[mount.core :as mount]))
(set-refresh-dirs "src/dev" "src/main")
(defn go [] (mount/start))
(defn restart []
(mount/stop)
(tools-ns/refresh :after 'user/go))In a REPL, you could start this one up and restart it with:
$ clj -A:dev
user=> (start)
user=> (restart)
...hot code reload/restart...If you used the lein template to setup your project, see it’s README doc for instructions about how to run the dev environment.
10.1.1. Configuration
Since you’ll need to configure your web server, it might be useful to note that the configuration used
by the easy server is a component you can inject into your own server. A number of add-on components for Fulcro
assume a :config keyed component will be in your system, so if you choose to use such components you can
create a config component via fulcro.server/new-config.
It supports pulling in values from the system environment, overriding configs with a JVM option, and more. See
the section in easy server about configuration, and the docstrings on new-config for more details.
10.2. The "Easy" Server
The pre-built easy server component for Fulcro uses Stuart Sierra’s Component library. The server has no global state except for a debugging atom that holds the entire system, and can therefore be easily restarted with a code refresh to avoid costly restarts of the JVM.
You should have a firm understanding of [Stuart’s component library](https://github.com/stuartsierra/component), since we won’t be covering that in detail here.
10.2.1. Constructing a base server
The base server is trivial to create:
(ns app.system
(:require
[fulcro.easy-server :as server]
[app.api :as api]
[fulcro.server :as prim]))
(defn make-system []
(server/make-fulcro-server
; where you want to store your override config file
:config-path "/usr/local/etc/app.edn"
; The keyword names of any components you want auto-injected into the query/mutation processing parser env (e.g. databases)
:parser-injections #{}
; Additional components you want added to the server
:components {}))10.2.2. Configuring the server [ServerConfig]
Server configuration requires two EDN files:
-
resources/config/defaults.edn: This file should contain a single EDN map that contains defaults for everything that the application wants to configure. -
/abs/path/of/choice: This file can be named what you want (you supply the name when making the server). It can also contain an empty map, but is meant to be machine-local overrides of the configuration in the defaults. This file is required. We chose to do this because it keeps people from starting the app in an unconfigured production environment. NOTE: If the path is relative it is looked for via CLASSPATH (resource). If it is absolute, the real filesystem is searched.
(defn make-system []
(server/make-fulcro-server
:config-path "/usr/local/etc/app.edn"
...The only parameter that the default server looks for is the network port to listen on:
{ :port 3000 }The configuration component has a number of built-in features:
-
You can override the configuration to use with a JVM option:
-Dconfig=filename -
The
defaults.ednis the target of configuration merge. Your config EDN file must be a map, and anything in it will override what is in defaults. The merge is a deep merge. -
Values can take the form
:env/VAR, which will use the string value of that environment variable as the value -
Values can take the form
:env.edn/VAR, which will useread-stringto interpret the environment variable as the value -
Relative paths for the config file can be used, and will search the CLASSPATH resources. This allows you to package your config with you jar.
If you choose not to use components (see mount), then you can use load-config directly:
(defstate config :start (server/load-config {:config-path "config/dev.edn"}))and config (after start) will simply contain the EDN of the defaults/config file merge.
10.2.3. Pre-installed components
When you start a Fulcro server it comes pre-supplied with injectable components upon which your component can depend and/or inject into the server-side parsing environment.
The most important of these, of course, is the configuration itself. The available components are known by the following keys:
-
:config: The configuration component. The actual EDN value is in the:valuefield of the component. -
:handler: The component that handles web traffic. You can inject your own Ring handlers into two different places in the request/response processing: before or after the API handler. -
:server: The actual web server.
The component library, of course, figures out the dependency order and ensures things are initialized and available where necessary.
10.2.4. Making components available in the processing environment
Any components in the server can be injected into the processing pipeline so they are
available when writing your mutations and query procesing. Making them available is as simple
as putting their component keyword into the :parser-injections set when building the server:
(defn make-system []
(server/make-fulcro-server
:parser-injections #{:config}
...))10.2.5. Adding to the Ring Stack
The easy server has a hook in front of the API processing (pre-hook), and one at the end of the ring stack
after API processing and just before the not-found handler (post-hook). You can have a component join into
the stack by making it depend on :handler. Here is an example:
(defrecord Authentication [handler]
c/Lifecycle
(start [this]
(log/info "Hooking into pre-processing to add user info")
(let [old-pre-hook (fulcro.easy-server/get-pre-hook handler)
new-hook (fn [ring-handler] (fn [req] ((old-pre-hook ring-handler) (new-behavior req)))]
(fulcro.easy-server/set-pre-hook! handler new-hook))
this)
(stop [this] this))
...
(def server (fulcro.easy-server/make-fulcro-server
:components { :auth (component/using (map->Authentication {}) [:handler]))}))The same pattern is used for fallback hooks.
The nesting of these functions can be a bit confusing, especially since none of the types are explicit. Here’s a description of each:
- middleware
-
A function that takes a "default handler" and returns a function of request → response (which is where you can choose to call the default, or do your own thing).
ring-handler-
A function from Ring request maps to responses
(fn [req] resp) old-pre-hook-
The prior value of the hook. It is middleware.
So in the example above you have complete control over what happens in your new hook. Here are some examples:
Ignore the request altogether, and short-circuit everything with a literal response:
(let [...
new-hook (fn [ring-handler] (fn [req] (ring.util.response "Hello world")]
...Ignore the old hook (this is like uninstalling all hooks):
(let [...
new-hook (fn [ring-handler] (fn [req] (ring-handler req))]
...Serve index.html from your public resources folder if the uri of the request ends in html (useful for HTML5 routing):
(let [...
new-hook (fn [ring-handler]
(fn [req]
(if (re-find #".*html$" uri)
(ring.middleware.resource/resource-request (assoc req :uri "index.html") "public")
((old-pre-hook ring-handler) req)))]
...|
Note
|
Remember that if you serve something like index.html for alternate paths you should use absolute paths for the
resources (e.g. scripts) in that file. If the requested resource wasn’t an html file, then you’ll also need to set the
content type on the response with something like (→ (ring.middleware.resource/resource-request …) (ring.util.response/content-type "text/html")).
|
10.2.6. Handling Filesystem Resources
The easy server will serve any files that are placed in resources/public. The easy server does pre-map
URI "/" to "/index.html".
10.2.7. Modifying the /api route
The easy server (and client) default to using /api as the URI on which to handle traffic. If you are proxying multiple
Fulcro applications to a single server, you may want to place them under different URI paths (e.g. /app-1/api and /app-2/api.
; server API at "/app-1/api":
(def server (fulcro.easy-server/make-fulcro-server :app-name "app-1" ...))The :app-name option of the easy server will add such a prefix to the API route. If you do that, then the client
will also need to have manual configuration of networking to ensure that it tries to contact the correct URI for
API calls.
(def client (fc/make-fulcro-client {:networking {:remote (fulcro.client.network/fulcro-http-remote {:url "/app1/api"})})})10.2.8. Adding Non-API Routes
The easy server also supplies a way to add in URI handlers via BIDI:
(defn page-handler [env bidi-match]
(ring/response ...))
; define routes (see BIDI documentation)
(def my-routes ["/" {"page.html" :page}])
(def server (fulcro.easy-server/make-fulcro-server
:extra-routes { :routes my-routes
:handlers {:page page-handler}}))The extra routes are processed right after the pre-hook, but just before the resource (filesystem) serving. Thus, you can respond to any URI that isn’t already handled by your pre-hook.
11. Fulcro and GraphQL
GraphQL is rapidly becoming the standard for writing graph-based servers. As a result there are many existing ways to deploy such an API, and many businesses have decided that their back-end will simply use the standard. There are BaaS (back-end as a service) providers that also let you quickly define and deploy a GraphQL API.
All of this makes GraphQL an attractive server-side solution for Fulcro.
Luckily, Pathom has all of the tools necessary to make this integration simple and easy!
You can see some of it in action in one of the Fulcro video series, and read about configuring it in the Pathom Documentation (link goes to a pre-release version at the time of this writing).
The simplest integration is to simply use Pathom’s GraphQL remote:
(ns app
(:require
...
[com.wsscode.pathom.fulcro.network :as pfn]))
(def client (fulcro/make-fulcro-client
{:networking {:remote (pfn/graphql-network
{::pfn/url (str "https://api.github.com/graphql?access_token=" token)})}})The more powerful and extensible method allows you to combine GraphQL access with Pathom Connect. This gives you very powerful features, including many useful ones that GraphQL doesn’t support natively!
12. Dynamic Queries
Fulcro supports dynamic queries: the ability the change the query of a component at runtime. This feature is fully serializable (works with the support viewer and other time-travel features), and is necessary code splitting where you may need to compose in a query of an as-yet unloaded component tree of your application.
|
Warning
|
This feature is not widely used yet, and should be considered of ALPHA quality. |
12.1. Query IDs
For dynamic queries to work right they have to be stored in your application database and every aspect of them must be serializable. Additionally, the UI must be able to look them up at the component level in order to do optimal refresh. The solution to this is query IDs. A query ID is a simple combination of the component’s fully-qualified class name combined with a user-defined qualifier (which defaults to the empty string).
Since this qualifier is needed both in the code that obtains queries (get-query) and in the UI rendering (the factory
that draws that component), it is easiest to locate the qualifier in the UI factory itself. This allows you
to have instances of a class that can have different queries:
(defsc Thing ...)
(def ui-thing (prim/factory Thing)) ; query ID is based solely on the class itself (with no qualifier)
(def ui-thing-1 (prim/factory Thing {:qualifier :a})) ; query ID is derived from Thing plus the qualifier :a
(defsc Parent [this props]
{:query (fn [] [{:child (prim/get-query ui-thing-1)}])}
...)In the above example one can now set the query for Thing, or “Thing` with qualifier `:a”.
The following live demo shows dynamic queries in action:
(ns book.queries.dynamic-queries
(:require
[fulcro.client.dom :as dom]
[goog.object]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.mutations :as m]))
(declare ui-leaf)
; This component allows you to toggle the query between [:x] and [:y]
(defsc Leaf [this {:keys [x y]}]
{:initial-state (fn [params] {:x 1 :y 42})
:query (fn [] [:x]) ; avoid error checking so we can destructure both :x and :y in props
:ident (fn [] [:LEAF :ID])} ; there is only one leaf in app state
(dom/div
(dom/button {:onClick (fn [] (prim/set-query! this ui-leaf {:query [:x]}))} "Set query to :x")
(dom/button {:onClick (fn [] (prim/set-query! this ui-leaf {:query [:y]}))} "Set query to :y")
; If the query is [:x] then x will be defined, otherwise it will not.
(dom/button {:onClick (fn [e] (if x
(m/set-value! this :x (inc x))
(m/set-value! this :y (inc y))))}
(str "Count: " (or x y))) ; only one will be defined at a time
" Leaf"))
(def ui-leaf (prim/factory Leaf {:qualifier :x}))
(defsc Root [this {:keys [root/leaf] :as props}]
{:initial-state (fn [p] {:root/leaf (prim/get-initial-state Leaf {})})
:query (fn [] [{:root/leaf (prim/get-query ui-leaf)}])}
(dom/div (ui-leaf leaf)))12.2. Setting a Query
The whole point of a dynamic query is being able to set the query to something new on a component. This has one
critical component that you must be very careful with: normalization. A component’s query is augmented with metadata
the marks which component is used to normalize (via idents) the entity found for the given portion of the query that
it handles. Therefore, you must still use get-query to pull the query for portions of your subquery that you wish
to include when setting a new query. If done incorrectly, then normalization when using these components will not
work.
The top-level metadata will be added for you, so this is fine:
(defmutation change-a-query [_]
(action [{:keys [state]}]
(swap! state prim/set-query* B {:query [:MODIFIED]}))but as soon as there’s a join you must ensure the subqueries have the correct metadata. This means that this is probably
incorrect (because [:x] probably goes with some other component):
(defmutation change-a-query [_]
(action [{:keys [state]}]
(swap! state prim/set-query* B {:query [:MODIFIED {:subquery [:x]}]}))instead, you should use get-query with a state parameter to pull the query for a given component. So, say you
wanted to change the query for this:
(defsc X [_ _]
{:query [:id :name]
:ident [:x/by-id :id]})
(defsc A [_ _]
{:query [:id {:x (prim/get-query X)}]
:ident [:a/by-id :id]})and you want to change both component’s queries. The correct form for the resulting mutation is:
(defmutation change-a-query [_]
(action [{:keys [state]}]
(swap! state (fn [s]
(as-> s state-map
(prim/set-query* state-map X {:query [:id :address]})
(prim/set-query* state-map A {:query [:id :new-prop {:x (prim/get-query X state-map}]}))))))13. Query Parsing
|
Note
|
This chapter is here to help you understand how the internals of query parsing work. It used to be more necessary to interact at this level, but now libraries exist that make this much easier. It is highly recommended that you use the "Connect" feature of pathom to process queries. |
In the Loading and Incremental Loading sections we showed you the central entry
points for responding to server queries:
defquery-root and defquery-entity. These are fine for simple examples and for getting into your
processing; however, to be truly data-driven you need to change how the server responds based
on what the client actually asked for (in detail).
So far, we’ve sort of been spewing entire entities back from the server without taking care to prune them down to the actual query of the client.
Unless you modify the network stack all client communication will be in the form of Query/Mutation expressions, which of course are recursive in nature. There is no built-in recursive processing, since Fulcro does not know anything about your server-side storage; however, there is a parsing mechanism that you can use to build processing to interface with it, and there are a number of libraries that can also help.
13.1. Avoiding Parsing
If you’re lucky, you can make use of a library to do this stuff for you. Here are some options we know about:
-
A really nice library for building recursive Fulcro query parsers. The Connect functionality lets you easily build parsers that can bridge any kind of data source (even Datomic schema mismatches) to your desired UI query. This is the recommended library for writing server-side query processing logic. It will let you accomplish anything you need, give you autocomplete in the Query tab of Fulcro Inspect, flatten schema, deepen nesting, etc. If you’re writing a full-stack Fulcro application, this will be your best general choice.
-
A library that can run Fulcro graph queries against SQL databases. This library lets you define your joins in relation to the Fulcro join notion. It can walk to-one, to-many, and many-to-many joins in an SQL database in response to a Fulcro join. This allows it to handle many Fulcro queries as graph queries against your SQL database with just a little configuration and invocatin code. This library is contributor maintained, so it may not fit with production needs.
-
Another SQL-centric offering. This one actually uses Pathom internally to give you a more declarative way to define parsers against an SQL database/schema. It can directly parse EQL and turn it into SQL queries, and handles the N+1 problem on to-many relations automatically.
-
If you’re lucky enough to be using Datomic, Fulcro’s graph query syntax will run in their
pullAPI; however, you’ll quickly find that mismatches in how Datomic does things (and your schema) will make you want higher-level parsing. Use Pathom.
Of these, Pathom is the most general and allows you to easily process a query in a more abstract way. However, you should know a little bit about parsing the queries yourself.
13.2. Doing the Parsing Yourself
The expression parser needs two things: A function to dispatch reads to, and a function to dispatch mutations. Since we’re talking about query parsing we’ll only be talking about the read dispatch function.
The signature of the read function is (read [env dispatch-key params])
where the env contains the state of your application, a reference to your parser (so you can
call it recursively, if you wish), a query root marker, an AST node describing the exact
details of the element’s meaning, and anything else you want to put in there if
you call the parser recursively.
The most important item in the query processing is the received environment (env). On
the server it contains:
-
Any components you’ve asked to be injected. Perhaps database and config components.
-
ast: An AST representation of the item being parsed. -
query: The subquery (e.g. of a join) -
parser: The query expression parser itself (which allows you to do recursive calls). If you’re using the built-in parser, this this will be that same parser that is already hooked into your dispatch mechanism (e.g. defquery-root). -
request: The full incoming Ring request, which will contain things like the headers, cookies, session, user agent info, etc.
The return value of your read must be the value for the dispatch-key. The parser assembles these back together and
returns a map containing those keys for all of the items for which you return a non-nil result.
If you understand that, you can probably already write a simple recursive parse of a query. If you need a bit more hand-holding, then read on.
|
Note
|
When doing recursive parsing You do not have to use the parser from env. Parsers are cheap. If you want to
make one to deal with a particular graph, go for it! The fulcro.client.primitives/parser can make one.
|
Now, let’s get a feeling for the parser in general. The example below runs a parser on an arbitrary query that you supply, records the calls to the read emitter, and shows the trace of those calls in order.
See the source code comments for a full description of how it works.
Try some queries like these:
-
[:a :b] -
[:a {:b [:c]}](note that the AST is recursively built, but only the top keys are actually parsed to trigger reads) -
[(:a { :x 1 })](note the value of params)
(ns book.queries.parsing-trace-example
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[devcards.util.edn-renderer :refer [html-edn]]
[cljs.reader :as r]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.client.dom :as dom]))
(defn tracer-path
"The assoc-in path of a field on the ParsingTracer in app state."
[field] [:widget/by-id :tracer field])
(defn tracing-reader
"Creates a parser read handler that can record the trace of the parse into the given state-atom at the proper
tracer path."
[state-atom]
(fn [env k params]
(swap! state-atom update-in (tracer-path :trace)
conj {:env (assoc env :parser :function-elided)
:dispatch-key k
:params params})))
(defmutation record-parsing-trace
"Mutation: Run and record the trace of a query."
[{:keys [query]}]
(action [{:keys [state]}]
(let [parser (prim/parser {:read (tracing-reader state)})] ; make a parser that records calls to read
(try
(swap! state assoc-in (tracer-path :trace) []) ; clear the last trace
(swap! state assoc-in (tracer-path :error) nil) ; clear the last error
(parser {} (r/read-string query)) ; Record the trace
(catch js/Error e (swap! state assoc-in (tracer-path :error) e)))))) ; Record and exceptions
(defsc ParsingTracer [this {:keys [trace error query result]}]
{:query [:trace :error :query :result]
:ident (fn [] [:widget/by-id :tracer])
:initial-state {:trace [] :error nil :query ""}}
(dom/div
(when error
(dom/div (str error)))
(dom/input {:type "text"
:value query
:onChange #(m/set-string! this :query :event %)})
(dom/button {:onClick #(prim/transact! this `[(record-parsing-trace ~{:query query})])} "Run Parser")
(dom/h4 "Parsing Trace")
(html-edn trace)))
(def ui-tracer (prim/factory ParsingTracer))
(defsc Root [this {:keys [ui/tracer]}]
{:query [{:ui/tracer (prim/get-query ParsingTracer)}]
:initial-state {:ui/tracer {}}}
(ui-tracer tracer))13.2.1. Injecting some kind of database
In order to play with this on a server, you’ll want to have some kind of state available. The most trivial thing you can do is just create a global top-level atom that holds data. This is sufficient for testing, and we’ll assume we’ve done something like this on our server:
(defonce state (atom {}))One could also wrap that in a Stuart Sierra component and inject it into the parser (for details on modifying the parser environment, see Making Components Available in the Parsing Environment).
Much of the remainder of this section assumes this.
13.3. Read Dispatching
When building your server there must be a read function that can
pull data to fufill what the parser needs to fill in the result of a query. Fulcro supplies this by default
and gives you the defquery-* macros as helpers to hook into it, but really it is just a multi-method.
For educational purposes, we’re going to walk you through implementing this read function yourself.
The parser understands the grammar, and is written to work as follows:
-
The parser calls your
readwith the key that it parsed, along with some other helpful information. -
Your read function returns a value for that key (possibly calling the parser recursively if it is a join).
-
The parser generates the result map by putting that key/value pair into the result at the correct position (relative to the query).
Note that the parser only processes the query one level deep. Recursion (if you need it) is controlled by you calling the parser again from within the read function.
The example below is similar to the prior one, but it has a read function that just records what keys it was triggered for. Give it an arbitrary legal query, and see what happens.
Some interesting queries:
-
[:a :b :c] -
[:a {:b [:x :y]} :c] -
[{:a {:b {:c [:x :y]}}}]
(ns book.queries.parsing-key-trace
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[devcards.util.edn-renderer :refer [html-edn]]
[cljs.reader :as r]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.client.dom :as dom]))
(defn tracer-path
"The assoc-in path of a field on the ParsingTracer in app state."
[field] [:widget/by-id :tracer field])
(defn tracing-reader
"Creates a parser read handler that can record just the dispatch keys of a parse."
[state-atom]
(fn [env k params]
(swap! state-atom update-in (tracer-path :trace) conj {:read-called-with-key k})))
(defmutation record-parsing-trace
"Mutation: Run and record the trace of a query."
[{:keys [query]}]
(action [{:keys [state]}]
(let [parser (prim/parser {:read (tracing-reader state)})] ; make a parser that records calls to read
(try
(swap! state assoc-in (tracer-path :trace) []) ; clear the last trace
(swap! state assoc-in (tracer-path :error) nil) ; clear the last error
(parser {} (r/read-string query)) ; Record the trace
(catch js/Error e (swap! state assoc-in (tracer-path :error) e)))))) ; Record and exceptions
(defsc ParsingTracer [this {:keys [trace error query result]}]
{:query [:trace :error :query :result]
:ident (fn [] [:widget/by-id :tracer])
:initial-state {:trace [] :error nil :query ""}}
(dom/div
(when error
(dom/div (str error)))
(dom/input {:type "text"
:value query
:onChange #(m/set-string! this :query :event %)})
(dom/button {:onClick #(prim/transact! this `[(record-parsing-trace ~{:query query})])} "Run Parser")
(dom/h4 "Parsing Trace")
(html-edn trace)))
(def ui-tracer (prim/factory ParsingTracer))
(defsc Root [this {:keys [ui/tracer]}]
{:query [{:ui/tracer (prim/get-query ParsingTracer)}]
:initial-state {:ui/tracer {}}}
(ui-tracer tracer))In the example above you should have seen that only the top-level keys trigger reads.
So, the query:
[:kw {:j [:v]}]would result in a call to your read function on :kw and :j. Two calls. No
automatic recursion. Done. The output value of the parser will be a map (that
parse creates) which contains the keys (from the query, copied over by the
parser) and values (obtained from your read):
{ :kw value-from-read-for-kw :j value-from-read-for-j }Note that if your read accidentally returns a scalar for :j then you’ve not
done the right thing…a join like { :j [:k] } expects a result that is a
vector of (zero or more) things or a singleton map that contains key
:k.
{ :kw 21 :j { :k 42 } }
; OR
{ :kw 21 :j [{ :k 42 } {:k 43}] }Dealing with recursive queries is a natural fit for a recusive algorithm, and it
is perfectly fine to invoke the parser function to descend the query. In fact,
the parser is passed as part of your environment.
So, the read function you write will receive three arguments, as described below:
-
An environment containing:
-
:ast: An abstract syntax tree for the element, which contains:-
:type: The type of node (e.g. :prop, :join, etc.) -
:dispatch-key: The keyword portion of the triggering query element (e.g. :people/by-id) -
:key: The full key of the triggering query element (e.g. [:people/by-id 1]) -
:query: (same as the query inenv) -
:children: If this node has sub-queries, will be AST nodes for those -
others…see documentation
-
-
:parser: The query parser -
:query: if the element had one E.g.{:people [:user/name]}has:query[:user/name] -
Components you requested be injected
-
-
A dispatch key for the item that triggered the read (same as dispatch key in the AST)
-
Parameters (which are nil if not supplied in the query)
It must return a value that has the shape implied by the grammar element being read.
|
Note
|
The following examples run various parsers against arbitrary queries. The ParseRunner component source looks like
this:
|
(ns book.queries.parse-runner
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[devcards.util.edn-renderer :refer [html-edn]]
[cljs.reader :as r]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.client.dom :as dom]))
(defn parse-runner-path
([] [:widget/by-id :parse-runner])
([field] [:widget/by-id :parse-runner field]))
(defmutation run-query [{:keys [query database parser]}]
(action [{:keys [state]}]
(try
(let [query (r/read-string query)
result (parser {:state (atom database)} query)]
(swap! state update-in (parse-runner-path) assoc
:error ""
:result result))
(catch js/Error e (swap! state assoc-in (parse-runner-path :error) e)))))
(defsc ParseRunner [this {:keys [ui/query error result]} {:keys [parser database]}]
{:query [:ui/query :error :result]
:initial-state (fn [{:keys [query] :or {query ""}}] {:ui/query query :error "" :result {}})
:ident (fn [] [:widget/by-id :parse-runner])}
(dom/div
(dom/input {:type "text"
:value query
:onChange (fn [evt] (m/set-string! this :ui/query :event evt))})
(dom/button {:onClick #(prim/transact! this `[(run-query ~{:query query :database database :parser parser})])} "Run Parser")
(when error
(dom/div (str error)))
(dom/div
(dom/h4 "Query Result")
(html-edn result))
(dom/div
(dom/h4 "Database")
(html-edn database))))
(def ui-parse-runner (prim/factory ParseRunner))13.3.1. Reading a keyword
If the parser encounters a keyword :kw, your function will be called with:
(your-read
{ :dispatch-key :kw :parser (fn ...) } ;; the environment: parser, etc.
:kw ;; the keyword
nil) ;; no parametersyour read function should return some value that makes sense for that spot in the grammar. There are no real restrictions on what that data value has to be in this case. You are reading a simple property. There is no further shape implied by the grammar. It could be a string, number, Entity Object, JS Date, nil, etc.
Due to additional features of the parser, your return value must be wrapped in a
map with the key :value. If you fail to do this, you will get nothing
in the result.
Thus, a very simple read for props (keywords) could be:
(defn read [env key params] { :value 42 })below is an example that implements exactly this read and plugs it into a
parser like this:
(defn read-42 [env key params] {:value 42})
(def parser-42 (prim/parser {:read read-42}))The UI just passes your query off to the parser and shows the results.
Thus, the example returns the value 42 no matter what it is asked for. Run any query you want in it, and check out the answer.
Some examples to try:
-
[:a :b :c] -
[:what-is-6-x-7] -
[{:a {:b {:c {:d [:e]}}}}](yes, there is only one answer)
(ns book.queries.naive-read
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[book.queries.parse-runner :refer [ParseRunner ui-parse-runner]]
[fulcro.client.dom :as dom]))
(defn read-42 [env key params] {:value 42})
(def parser-42 (prim/parser {:read read-42}))
(defsc Root [this {:keys [parse-runner]}]
{:initial-state {:parse-runner {}}
:query [{:parse-runner (prim/get-query ParseRunner)}]}
(dom/div
(ui-parse-runner (prim/computed parse-runner {:parser parser-42 :database {}}))))So now you have a read function that returns the meaning of life the universe and everything in a single line of code! But now it is obvious that we need to build an even bigger machine to understand the question.
If your server state is just a flat set of scalar values with unique keyword identities, then a better read is similarly trivial:
(defn property-read [{:keys [state]} key params] {:value (get @state key :not-found)})
(def property-parser (prim/parser {:read property-read}))It just assumes the property will be in the top-level of some injected state atom. Let’s try that out. The database we’re emulating is shown at the bottom of the example. Run some queries and see what you get. Some suggestions:
-
[:a :b :c] -
[:what-is-6-x-7] -
[{:a {:b {:c {:d [:e]}}}}](yes, there is only one answer)
(ns book.queries.simple-property-read
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[book.queries.parse-runner :refer [ParseRunner ui-parse-runner]]
[fulcro.client.dom :as dom]))
(defn property-read [{:keys [state]} key params] {:value (get @state key :not-found)})
(def property-parser (prim/parser {:read property-read}))
(defsc Root [this {:keys [parse-runner]}]
{:initial-state {:parse-runner {}}
:query [{:parse-runner (prim/get-query ParseRunner)}]}
(dom/div
(ui-parse-runner (prim/computed parse-runner {:parser property-parser :database {:a 1 :b 2 :c 99}}))))The result of those nested queries (the last suggestion above) is supposed to be a nested map. So, obviously we have more work to do.
13.3.2. Reading a join
Your state probably has some more structure to it than just a flat bag of properties. Joins are naturally recursive in syntax, and those that are accustomed to writing parsers probably already see the solution.
First, let’s clarify what the read function will receive for a join. When parsing:
{ :j [:a :b :c] }your read function will be called with:
(your-read { :state state :parser (fn ...) :query [:a :b :c] } ; the environment
:j ; keyword of the join
nil) ; no parametersBut just to prove a point about the separation of database format and query structure we’ll implement this next example with a basic recursive parse, but use more flat data (the following is live code):
(def flat-app-state {:a 1 :user/name "Sam" :c 99})
(defn flat-state-read [{:keys [state parser query] :as env} key params]
(if (= :user key)
{:value (parser env query)} ; recursive call. query is now [:user/name]
{:value (get @state key)})) ; gets called for :user/name :a and :c
(def my-parser (prim/parser {:read flat-state-read}))The important bit is the then part of the if. Return a value that is
the recursive parse of the sub-query. Otherwise, we just look up the keyword
in the state (which as you can see is a very flat map).
Try running the query [:a {:user [:user/name]} :c]:
(ns book.queries.parsing-simple-join
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[book.queries.parse-runner :refer [ParseRunner ui-parse-runner]]
[fulcro.client.dom :as dom]))
(def flat-app-state {:a 1 :user/name "Sam" :c 99})
(defn flat-state-read [{:keys [state parser query] :as env} key params]
(if (= :user key)
{:value (parser env query)} ; recursive call. query is now [:user/name]
{:value (get @state key)})) ; gets called for :user/name :a and :c
(def my-parser (prim/parser {:read flat-state-read}))
(defsc Root [this {:keys [parse-runner]}]
{:initial-state (fn [params] {:parse-runner (prim/get-initial-state ParseRunner {:query "[:a {:user [:user/name]} :c]"})})
:query [{:parse-runner (prim/get-query ParseRunner)}]}
(dom/div
(ui-parse-runner (prim/computed parse-runner {:parser my-parser :database flat-app-state}))))The first (possibly surprising thing) is that your result includes a nested object. The parser creates the result, and the recursion naturally nested the result correctly.
Next you should remember that a join implies there could be one OR many results. The singleton case is fine (e.g. putting a single map there). If there are multiple results it should be a vector.
In this case we’re just showing calling the parser recursively. Notice that it in turn will call your read function again. In a real application your data will not be this flat so you will almost certainly not do things in quite this way.
Let’s put a little better state in our application and write a more realistic parser.
13.3.3. A Non-trivial, recursive example
Let’s start with the following hand-normalized application state:
(def app-state (atom {
:window/size [1920 1200]
:friends [[:people/by-id 1] [:people/by-id 3]]
:people/by-id {
1 {:id 1 :name "Sally" :age 22 :married false}
2 {:id 2 :name "Joe" :age 22 :married false}
3 {:id 3 :name "Paul" :age 22 :married true}
4 {:id 4 :name "Mary" :age 22 :married false}}}))Our friend db→tree could handle queries against this database,
but let’s implement it by hand.
Say we want to run this query:
(def query [:window/size {:friends [:name :married]}])From the earlier discussion you see that we’ll have to handle the top level keys one at a time.
For this query there are only two keys to handle: :friends
and :window-size. So, let’s write a case for each:
(defn read [{:keys [state query]} key params]
(case key
:window/size {:value (get @state :window/size)}
:friends (let [friend-ids (get @state :friends)
get-friend (fn [id] (select-keys (get-in @state id) query))
friends (mapv get-friend friend-ids)]
{:value friends})
nil))The default case is nil, which means if we supply an errant key in the query no
exception will happen.
You can try it out below:
(ns book.queries.parsing-recursion-one
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[book.queries.parse-runner :refer [ParseRunner ui-parse-runner]]
[fulcro.client.dom :as dom]))
(def database {:window/size [1920 1200]
:friends #{[:people/by-id 1] [:people/by-id 3]}
:people/by-id {
1 {:id 1 :name "Sally" :age 22 :married false}
2 {:id 2 :name "Joe" :age 22 :married false}
3 {:id 3 :name "Paul" :age 22 :married true}
4 {:id 4 :name "Mary" :age 22 :married false}}})
(defn read [{:keys [state query]} key params]
(case key
:window/size {:value (get @state :window/size)}
:friends (let [friend-ids (get @state :friends)
get-friend (fn [id] (select-keys (get-in @state id) query))
friends (mapv get-friend friend-ids)]
{:value friends})
nil))
(def parser (prim/parser {:read read}))
(def query "[:window/size {:friends [:name :married]}]")
(defsc Root [this {:keys [parse-runner]}]
{:initial-state (fn [params] {:parse-runner (prim/get-initial-state ParseRunner {:query query})})
:query [{:parse-runner (prim/get-query ParseRunner)}]}
(dom/div
(ui-parse-runner (prim/computed parse-runner {:parser parser :database database}))))Those of you paying close attention will notice that we have yet to need
recursion. We’ve also done something a bit naive: select-keys assumes
that query contains only keys! What if query followed an ident link to
:married-to:
[:window/size {:friends [:name :age {:married-to [:name]}]}]and the database was:
{:window/size [1920 1200]
:friends [[:people/by-id 1] [:people/by-id 3]]
:people/by-id {
1 {:id 1 :name "Sally" :age 22 :married false}
2 {:id 2 :name "Joe" :age 33 :married false}
3 {:id 3 :name "Paul" :age 45 :married true :married-to [:people/by-id 1]}
4 {:id 4 :name "Mary" :age 19 :married false}}}Now things get interesting, and I’m sure more than one reader will have an opinion on how to proceed. My aim is to show that the parser can be called recursively to handle these things, not to find the perfect structure for the parser in general, so I’m going to do something simple.
The primary trick I’m going to exploit is the fact that env is just a map, and
that we can add stuff to it. When we are in the context of a person, we’ll add
:person to the environment, and pass that to a recursive call to parser.
The example below (with source) shows the result:
(ns book.queries.parsing-recursion-two
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[book.queries.parse-runner :refer [ParseRunner ui-parse-runner]]
[fulcro.client.dom :as dom]))
(def database {:window/size [1920 1200]
:friends [[:people/by-id 1] [:people/by-id 3]]
:people/by-id {
1 {:id 1 :name "Sally" :age 22 :married false}
2 {:id 2 :name "Joe" :age 33 :married false}
3 {:id 3 :name "Paul" :age 45 :married true :married-to [:people/by-id 1]}
4 {:id 4 :name "Mary" :age 19 :married false}}})
; we're going to add person to the env as we go
(defn read [{:keys [parser ast state query person] :as env} dispatch-key params]
(letfn [(parse-friend
; given a person-id, parse the current query by placing that person's data in the
; environment, and call the parser recursively.
[person-id]
(if-let [person (get-in @state person-id)]
(parser (assoc env :person person) query)
nil))]
(case dispatch-key
; These trust that a person has been found and placed in the env
:name {:value (get person dispatch-key)}
:id {:value (get person dispatch-key)}
:age {:value (get person dispatch-key)}
:married {:value (get person (:key ast))}
; a to-one join
:married-to (if-let [pid (get person dispatch-key)]
{:value (parse-friend pid)}
nil)
; these assume we're asking for the top-level state
:window/size {:value (get @state :window/size)}
; a to-many join
:friends (let [friend-ids (get @state :friends)]
{:value (mapv parse-friend friend-ids)})
nil)))
(def parser (prim/parser {:read read}))
(def query "[:window/size {:friends [:name :age {:married-to [:name]}]}]")
(defsc Root [this {:keys [parse-runner]}]
{:initial-state (fn [params] {:parse-runner (prim/get-initial-state ParseRunner {:query query})})
:query [{:parse-runner (prim/get-query ParseRunner)}]}
(dom/div
(ui-parse-runner (prim/computed parse-runner {:parser parser :database database}))))It can be a little bit of work to build these parsers for the queries (which is why libraries exist so you don’t have to); however, we hope you can see that it is actually pretty tractable to build them once you understand the basics.
Now we’ll move on to another thing that servers typically need in their queries: parameters!
13.4. Parameters
The Fulcro query grammar accept parameters on most elements. These are intended to be combined with dynamic queries that will allow your UI to have some control over what you want to read from the application state (think filtering, pagination, sorting, and such).
As you might expect, the parameters on a particular expression in the query are just passed into your read function as the third argument. You are responsible for both defining and interpreting them. They have no rules other than that they are maps.
To read the property :load/start-time with a parameter indicating a particular
time unit you might use a query like:
[(:load/start-time {:units :seconds})]this will invoke read with:
(your-read env :load/start-time { :units :seconds})the implication is clear. The code is up to you. Let’s add some quick support for this in our read so you can try it out.
The parser below understands the following queries:
[(:load/start-time {:units :seconds})]
[(:load/start-time {:units :minutes})]
[(:load/start-time {:units :ms})](ns book.queries.parsing-parameters
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[book.queries.parse-runner :refer [ParseRunner ui-parse-runner]]
[fulcro.client.dom :as dom]))
(def database {
:load/start-time 40000.0 ;stored in ms
})
(defn convert [ms units]
(case units
:minutes (/ ms 60000.0)
:seconds (/ ms 1000.0)
:ms ms))
(defn read [{:keys [state]} key params]
(case key
:load/start-time {:value (convert (get @state key) (or (:units params) :ms))}
nil))
(def parser (prim/parser {:read read}))
(defsc Root [this {:keys [parse-runner]}]
{:initial-state (fn [params] {:parse-runner (prim/get-initial-state ParseRunner {:query "[(:load/start-time {:units :seconds})]"})})
:query [{:parse-runner (prim/get-query ParseRunner)}]}
(dom/div
(ui-parse-runner (prim/computed parse-runner {:parser parser :database database}))))13.5. Using a Completely Custom Parser
Most of this book has assumed you’ll be using Fulcro’s predefined server parser. Note that you can still do that
and switch out to an alternate (custom) parser at any phase of parsing. You can even install a custom parser in your server
(though then the macros for defining mutations and query handlers won’t work for you).
Parsers can be constructed using the prim/parser function.
13.6. Parsing on the Client
Fulcro allows you to augment the built-in query parser for local reads on the client. It uses the exact same techniques discussed above, and it is similar in that you must be able to start at the root of the query (even though you may only want to augment something rather deep in the query tree).
Actually, there are two cases that such a custom read must be able to do:
-
Handle the path from root to the point of interest (it can hand off uninteresting side branches to
db→tree. -
Handle (or safely ignore) ident-based queries for any "virtual" entities that are purely parser-generated.
The first is a limitation of how queries are processed. Fulcro normally runs the query through db→tree, which attempts to
fill the entire result. If you supply a :read-local function during client construction, then your :read-local will
get first shot at each element of the query that was submitted. Note that the query can start at an ident.
If your read-local function returns nil for an element, then the normal Fulcro
processing takes place on that sub-query. If your read-local returns a value, then that is all of the processing that
is done for the sub-tree rooted at that key. Thus, custom client parsing always requires you to process sub-trees of the query, not just
individual elements. Of course, you can use db→tree at any time to "finish out" some subquery against real data.
This has the advantage of letting you dynamically fill queries without having to have a concrete representation of the graph in your database. This can be helpful if you have some rapidly changing data (e.g. updated by a web worker) and some views of that data that would otherwise be hard to keep up-to-date.
It is also useful if you’re trying to port from Om Next.
14. UI Routing
UI Routing is a very important task in Fulcro. It is the primary means by which you keep your application running quickly. You see, in Fulcro your query is run from root. If your entire application’s query runs on every render frame things can get slow indeed.
The solution is easy: use union queries with to-one relations to ensure only the portions of your query that are active on the UI are processed.
Unfortunately many people find hand-writing union components a litle challenging. Fulcro provides a nice pre-written facility that can write much of the code for you, making the process more conceptual as UI Routing.
|
Note
|
Fulcro Incubator includes a new routing namespace that is more feature complete, and as of
version 2.6.18 Fulcro’s routing namespace includes defsc-router, which is a replacement for
defrouter.
|
14.1. A Basic Router
A basic router looks like this:
(ns app
(:require [fulcro.client.routing :refer [defrouter defsc-router]]) ; requires 2.6.18 for defsc-router
(defsc Index [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/index}}
...)
(defsc Settings [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/settings}}
...)
;; Pre-2.6.18
(defrouter RootRouter :root/router
; OR (fn [t p] [(:router/page p) (:db/id p)])
[:router/page :db/id]
:PAGE/index Index
:PAGE/settings Settings)
;; Post 2.6.18
(defsc-router RootRouter [this {:keys [router/page db/id]]
{:router-id :root/router
:ident (fn [] [page id]) ; props are destructured in the context of the route TARGET
:default-route Index
:router-targets {:PAGE/index Index
:PAGE/settings Settings}}
(dom/div "What to render if the route is bad"))The newer form lets you define React lifecycle methods, and also lets you define what to render when the route is
invalid (the body is only rendered under that circumstance, otherwise is renders the routed component). It can also
be set to resolve like defsc in Cursive, so you get proper symbol resolution.
See old versions of the book in Fulcro’s git history for docs on the old defrouter.
14.1.1. Details on defsc-router
The required parameters of defsc-router are:
:router-id-
An ID to give the router
:ident-
MUST be in
fnform, and can use destructured parameters fromprops(which are in the context of the route target) :default-route-
The component that should be shown by default. Should have initial state so it exists on app start.
:router-targets-
A map from the component’s Fulcro database table to the component that can be routed to. Routing switches on the FIRST element of the ident (the table name). This is because unions are used, and this allows sub-screens to have ID’s that vary. For example, you could router to
[:user/by-id 44]by adding:user/by-id Useras an entry to this map and making sure the ident function can resolve the ident correctly for the props of a user.
You may also include most other defsc options, other than :query and :initial-state, which are set internally.
The optional body of defsc-router is what to render if the route is bad (e.g. the ident in state for the route doesn’t
point to a valid routing target).
(ns book.simple-router-1
(:require [fulcro.client.routing :as r :refer-macros [defsc-router]]
[fulcro.client.dom :as dom]
[fulcro.client :as fc]
[fulcro.client.data-fetch :as df]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.mutations :as m]))
(defsc Index [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id]) ; IMPORTANT! Look up both things, don't use the shorthand for idents on screens!
:initial-state {:db/id 1 :router/page :PAGE/index}}
(dom/div nil "Index Page"))
(defsc Settings [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/settings}}
(dom/div "Settings Page"))
(defsc-router RootRouter [this {:keys [router/page db/id]}]
{:router-id :root/router
:default-route Index
:ident (fn [] [page id])
:router-targets {:PAGE/index Index
:PAGE/settings Settings}}
(dom/div "Bad route"))
(def ui-root-router (prim/factory RootRouter))
(defsc Root [this {:keys [router]}]
{:initial-state (fn [p] {:router (prim/get-initial-state RootRouter {})})
:query [{:router (prim/get-query RootRouter)}]}
(dom/div
(dom/a {:onClick #(prim/transact! this
`[(r/set-route {:router :root/router
:target [:PAGE/index 1]})])} "Index") " | "
(dom/a {:onClick #(prim/transact! this
`[(r/set-route {:router :root/router
:target [:PAGE/settings 1]})])} "Settings")
(ui-root-router router)))Be sure to look at the database view in the example above. Notice that all that has to happen is a change of a single ident. This as the effect of switching the rendering, and choosing the subquery for the remainder of the visible UI.
14.1.2. Rendering a "Bad Route"
If the app state doesn’t point to a proper router target then the router won’t know what to render. This is the
purpose of the body of the defsc-router.
(defsc-router Router [this props]
{...}
(dom/div "Bad route!"))It is very important to note that the props arg can be destructured in the context of a route target, but when
you’re rendering the "bad route" the props will be the props of the router itself. We recommend you use a pattern
like this if you want to examine the "current route" in the body of the "bad route" rendering:
(defsc-router Router [this props]
{...}
(let [{:fulcro.client.routing/keys [id current-route]} (prim/props this)]
(dom/div "Bad route: " current-route)))but most likely the current route is just going to be nil, since you’re looking at denormalized props, and the ident
that is in state is pointing at something wrong. So, instead you can pull the state map and see what the bad ident is
instead:
(ns ...
(:require [fulcro.client.routing :as r :refer [defsc-router]]))
(defsc-router Router [this props]
{...}
(let [state-map (prim/component->state-map this)
{:fulcro.client.routing/keys [id]} (prim/props this)]
current-route (get-in state-map [r/routers-table ::r/id id ::r/current-route])]
(dom/div "Bad route ident: " current-route)))of course you probably don’t want to render that to the user, but in case you find it useful at least you know how to get it.
14.1.3. Composing Routers
It is very easy from here to compose together as many of these as you’d like in order to build a more complicated UI. For example, the settings could have several subscreens as in this example:
(ns book.simple-router-2
(:require [fulcro.client.routing :as r :refer-macros [defsc-router]]
[fulcro.client.dom :as dom]
[fulcro.client :as fc]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.mutations :as m]))
(defsc Index [this {:keys [router/page db/id]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/index}}
(dom/div "Index Page"))
(defsc EmailSettings [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/email}}
(dom/div "Email Settings Page"))
(defsc ColorSettings [this {:keys [db/id router/page]}]
{:query [:db/id :router/page]
:ident (fn [] [page id])
:initial-state {:db/id 1 :router/page :PAGE/color}}
(dom/div "Color Settings"))
(defsc-router SettingsRouter [this {:keys [router/page db/id]}]
{:router-id :settings/router
:ident (fn [] [page id])
:router-targets {:PAGE/email EmailSettings
:PAGE/color ColorSettings}
:default-route EmailSettings}
(dom/div "Bad route"))
(def ui-settings-router (prim/factory SettingsRouter))
(defsc Settings [this {:keys [router/page db/id subpage]}]
{:query [:db/id :router/page {:subpage (prim/get-query SettingsRouter)}]
:ident (fn [] [page id])
:initial-state (fn [p]
{:db/id 1
:router/page :PAGE/settings
:subpage (prim/get-initial-state SettingsRouter {})})}
(dom/div
(dom/a {:onClick #(prim/transact! this
`[(r/set-route {:router :settings/router
:target [:PAGE/email 1]})])} "Email") " | "
(dom/a {:onClick #(prim/transact! this
`[(r/set-route {:router :settings/router
:target [:PAGE/color 1]})])} "Colors")
(js/console.log :p (prim/props this))
(ui-settings-router subpage)))
(defsc-router RootRouter [this {:keys [router/page db/id]}]
{:router-id :root/router
:ident (fn [] [page id])
:default-route Index
:router-targets {:PAGE/index Index
:PAGE/settings Settings}}
(dom/div "Bad route"))
(def ui-root-router (prim/factory RootRouter))
(defsc Root [this {:keys [router]}]
{:initial-state (fn [p] {:router (prim/get-initial-state RootRouter {})})
:query [{:router (prim/get-query RootRouter)}]}
(dom/div
(dom/a {:onClick #(prim/transact! this
`[(r/set-route {:router :root/router
:target [:PAGE/index 1]})])} "Index") " | "
(dom/a {:onClick #(prim/transact! this
`[(r/set-route {:router :root/router
:target [:PAGE/settings 1]})])} "Settings")
(ui-root-router router)))This allows you to build up a tree of routers that keeps your query minimal, and allows for very nice dynamic structuring of the applicataion at runtime.
If you have screens that could have different instances (for example, different reports), then each report could have an ID, and routing would involve selecting the screen’s table, as well as a distinct ID.
The problem, of course, is that managing all of these routers in your application logic becomes somewhat of a chore. Also, it is common to want to mix UI routing with HTML5 history, where only a single "route" is spelled out, but you may need to logically "switch" any number of these UI routers to reach the indicated screen.
For example, one could imagine wanting to go to /settings/colors as a URI for the previous example. That single
URI as a concept is a single route to a screen, but the mutation you’d trigger would be to set-route on
two different routers:
(prim/transact! this `[(r/set-route ...) (r/set-route ...)])14.2. Routing Tree Support
|
Note
|
Fulcro Incubator’s Dynamic Routers automatically compose and understand paths, so there is no need to declare a routing tree with them. You might want to try those as an alternative. |
Fulcro includes some routing tree primitives to do the mapping from single conceptual "routes" like /settings/colors
to a set of instructions that you need to send to your UI routers. There is an additional concern as well: route
parameters. It is quite common to want to interpret URIs like /user/436 as a route that populates a given screen
with some data.
Thus, the tree support is based on the concept of a Route Handler and Route Parameters.
Defining routes requires just a few steps:
-
Define routers as shown in the prior section, giving each router a distinct ID.
-
Give each routable screen (i.e. URI) in your tree a handler name. The example below shows two routers with 5 conceptual target screen. The screens have handler names
:main,:login, etc.(top-router w/id :top-router) ---------------------- / / | \ :main :login :new-user (report router w/id :report-router) | (reports shared content screen) | / \ :status :graph -
Define your routing tree. This is a data structure that gives instructions to one-or-more routers that are necessary to display the screen with a given handler name. In the above example you need to tell both the top router and report router to change what they are showing in order to get a
:statusor:graphonto the screen.(def routing-tree "A map of route handling instructions. A given route has a handler name (e.g. `:main`) which is thought of as the target of a routing operation (i.e. interpretation of a URI). It also has a vector of `router-instruction`s, which say 1. which router should be changed 2. What component instance that router should point to (by ident) The routing tree for the diagram above is therefore: " (r/routing-tree (r/make-route :main [(r/router-instruction :top-router [:main :top])]) (r/make-route :login [(r/router-instruction :top-router [:login :top])]) (r/make-route :new-user [(r/router-instruction :top-router [:new-user :top])]) (r/make-route :graph [(r/router-instruction :top-router [:report :top]) (r/router-instruction :report-router [:graphing-report :param/report-id])]) (r/make-route :status [(r/router-instruction :top-router [:report :top]) (r/router-instruction :report-router [:status-report :param/report-id])]))) -
Compose the application as normal, placing the routers as shown in the prior section.
14.3. Using the Routing Tree
The routing namespace includes a Fulcro mutation for triggering the routing tree handler.
It takes a :handler (e.g. :main) and an optional :route-params argument:
; assumes you've aliased fulcro.client.routing to r
(prim/transact! `[(r/route-to {:handler :main})])Running this mutation will run all of the router-instruction, and will also do route parameter substitution on the
resulting idents.
14.3.1. Route Parameters
Anything you pass in the :route-params map will get automatically plugged into the parameter
placeholders in your routing tree instructions. By default anything that looks like an integer (only digits) will
be coerced to an integer. Anything that contains only letters will map to a keyword.
If the default coercion isn’t sufficient then you can customize it using parameter coercion.
It is a very common task to need to convert incoming strings (e.g. from a URL) to elements of an ident. If you’d like
to use this support in your own code then use (r/set-ident-route-params ident params) which
supports the coercion and replacement:
(r/set-ident-route-params [:param/table :param/id] {:table "a" :id "1"})
; => [:a 1]Note that the params argument is just what you’d get from a URL when using something like bidi (everything will come in as strings).
Parameter Coercion
The default coercion converts integer-looking things to integers, and string-looking things to keywords.
There is a multimethod r/coerce-param that dispatches on :param/X and replaces the value with
whatever you return. You customize coercion simply by adding your own coercion for
a parameter by name:
(defmethod r/coerce-param :param/NAME
[k incoming-string-value]
(transform-it incoming-string-value))Of course, be sure that your namespace with the defmethod is loaded so that your methods get installed.
14.4. Examining Routes in UI and Mutations
Your UI will often want to rely on knowing the "current" route of a given router in order to give user navigation feedback. You cannot embed your router in the query, because that would often make the query have a circular reference and blow the stack.
The only real bit of information in a router that is useful is the current route
The current-route function can be used in a mutation or component (by querying for the router
table) to check the route:
(ns x
(:require [fulcro.client.routing :as r]
[fulcro.client.primitives :as prim]))
(r/defsc-router SomeRouter [this props]
{:router-id :top-router
:ident (fn [] ...)
:default-route HomePage
:router-targets {:home-page HomePage
:about-page AboutPage}}
...)
(defmutation do-something-with-routes [params]
(action [{:keys [state]}]
(let [current (r/current-route state :top-router)] ; current will be an ident of a screen of :top-router
...)))
(defsc NavBar [this props]
{:query (fn [] [ [r/routers-table '_] ])
:initial-state (fn [p] {})}
(let [current (current-route props :top-router)] ; current will be an ident of a screen of :top-router
...))14.5. A Complete UI Routing Example
The following shows the example routing tree in a complete running demo:
(ns book.ui-routing
(:require [fulcro.client.routing :as r :refer-macros [defrouter]]
[fulcro.client.dom :as dom]
[fulcro.client :as fc]
[fulcro.client.data-fetch :as df]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.mutations :as m]))
(defsc Main [this {:keys [label]}]
{:initial-state {:page :main :label "MAIN"}
:query [:page :label]}
(dom/div {:style {:backgroundColor "red"}}
label))
(defsc Login [this {:keys [label]}]
{:initial-state {:page :login :label "LOGIN"}
:query [:page :label]}
(dom/div {:style {:backgroundColor "green"}}
label))
(defsc NewUser [this {:keys [label]}]
{:initial-state {:page :new-user :label "New User"}
:query [:page :label]}
(dom/div {:style {:backgroundColor "skyblue"}}
label))
(defsc StatusReport [this {:keys [id]}]
{:initial-state {:id :a :page :status-report}
:query [:id :page :label]}
(dom/div {:style {:backgroundColor "yellow"}}
(dom/div (str "Status " id))))
(defsc GraphingReport [this {:keys [id]}]
{:initial-state {:id :a :page :graphing-report}
:query [:id :page :label]} ; make sure you query for everything need by the router's ident function!
(dom/div {:style {:backgroundColor "orange"}}
(dom/div (str "Graph " id))))
(defrouter ReportRouter :report-router
; This router expects numerous possible status and graph reports. The :id in the props of the report will determine
; which specific data set is used for the screen (though the UI of the screen will be either StatusReport or GraphingReport
; IMPORTANT: Make sure your components (e.g. StatusReport) query for what ident needs (i.e. in this example
; :page and :id at a minimum)
[:page :id]
:status-report StatusReport
:graphing-report GraphingReport)
(def ui-report-router (prim/factory ReportRouter))
; BIG GOTCHA: Make sure you query for the prop (in this case :page) that the union needs in order to decide. It won't pull it itself!
(defsc ReportsMain [this {:keys [report-router]}]
; nest the router under any arbitrary key, just be consistent in your query and props extraction.
{:initial-state (fn [params] {:page :report :report-router (prim/get-initial-state ReportRouter {})})
:query [:page {:report-router (prim/get-query ReportRouter)}]}
(dom/div {:style {:backgroundColor "grey"}}
; Screen-specific content to be shown "around" or "above" the subscreen
"REPORT MAIN SCREEN"
; Render the sub-router. You can also def a factory for the router (e.g. ui-report-router)
(ui-report-router report-router)))
(defrouter TopRouter :top-router
(fn [this props] [(:page props) :top])
:main Main
:login Login
:new-user NewUser
:report ReportsMain)
(def ui-top (prim/factory TopRouter))
(def routing-tree
"A map of route handling instructions. The top key is the handler name of the route which can be
thought of as the terminal leaf in the UI graph of the screen that should be \"foremost\".
The value is a vector of routing-instructions to tell the UI routers which ident
of the route that should be made visible.
A value in this ident using the `param` namespace will be replaced with the incoming route parameter
(without the namespace). E.g. the incoming route-param :report-id will replace :param/report-id"
(r/routing-tree
(r/make-route :main [(r/router-instruction :top-router [:main :top])])
(r/make-route :login [(r/router-instruction :top-router [:login :top])])
(r/make-route :new-user [(r/router-instruction :top-router [:new-user :top])])
(r/make-route :graph [(r/router-instruction :top-router [:report :top])
(r/router-instruction :report-router [:graphing-report :param/report-id])])
(r/make-route :status [(r/router-instruction :top-router [:report :top])
(r/router-instruction :report-router [:status-report :param/report-id])])))
(defsc Root [this {:keys [top-router]}]
; r/routing-tree-key implies the alias of fulcro.client.routing as r.
{:initial-state (fn [params] (merge routing-tree
{:top-router (prim/get-initial-state TopRouter {})}))
:query [{:top-router (prim/get-query TopRouter)}]}
(dom/div
; Sample nav mutations
(dom/a {:onClick #(prim/transact! this `[(r/route-to {:handler :main})])} "Main") " | "
(dom/a {:onClick #(prim/transact! this `[(r/route-to {:handler :new-user})])} "New User") " | "
(dom/a {:onClick #(prim/transact! this `[(r/route-to {:handler :login})])} "Login") " | "
(dom/a {:onClick #(prim/transact! this `[(r/route-to {:handler :status :route-params {:report-id :a}})])} "Status A") " | "
(dom/a {:onClick #(prim/transact! this `[(r/route-to {:handler :graph :route-params {:report-id :a}})])} "Graph A")
(ui-top top-router)))14.6. Combining Routing with Data Management
Of course you can compose this with other mutations into a single transaction. This is common when you’re trying to switch to a screen whose data might not yet exist:
(prim/transact! `[(ensure-report-loaded {:report-id :a}) (r/route-to {:graph :a})])here we’re assuming that ensure-report-loaded is a mutation that ensures that there is at least placeholder data in
place (or the UI rendering might look a bit odd or otherwise fail from lack of data). It may also do things like trigger background
loads that will fufill the graph’s needs, something like this:
(defmutation ensure-report-loaded [{:keys [report-id]}]
(action [{:keys [state] :as env}]
(let [when-loaded (get-in @state [:reports/by-id report-id :load-time-ms] 0)
is-missing? (= 0 when-loaded)
now-ms (.getTime (js/Date.))
age-ms (- now-ms when-loaded)
should-be-loaded? (or (too-old? age-ms) is-missing?)]
; if missing, put placeholder
; if too old, add remote load to Fulcro queue (see data-fetch for remote-load and load-action)
(when is-missing? (swap! state add-report-placeholder report-id))
(when should-be-loaded? (df/load-action env [:reports/by-id report-id] StatusReport)))})
(remote [env] (df/load-action env)))Additional mutations might do things like garbage collect old data that is not in the view. You may also need to trigger renders of things like your main screen with follow-on reads (e.g. of a keyword on the root component of your UI). Of course, combining such things into functions adds a nice touch:
(defn show-report!
[component report-id]
(prim/transact! component `[(app/clear-old-reports)
(app/ensure-report-loaded {:report-id ~report-id})
(r/route-to {:graph ~report-id})
:top-level-key]))which can then be used more cleanly in the UI:
(dom/a {:onClick #(show-report! this :a)} "Report A")14.7. Mutations with Routing
In some cases you will find it most convenient to do your routing within a mutation itself. This will let you check state, trigger loads, etc. If you trigger loads, then you can also easily defer the routing until the load completes. Of course, in that case you may want to do something in the state to cause your UI to indicate the routing is in progress.
There is nothing special about this technique. There are several functions in the routing namespace
that can be used easily within your own mutations:
-
update-routing-links- For standard union-baseddefsc-router(does not support dynamic code loading routers): Takes the state map and a route match (map with :handler and :route-params) and returns a new state map with the routes updated. -
route-to-impl!- For all kinds of routers (including dynamic): Takes the mutationenvand a bidi-style match {:handler/:params}. Works with dynamic routes. Does swaps against app state, but is safe to use within a mutation. -
set-route- Changes the current route on a specificdefsc-routerinstance. Takes a state map, router ID, and a target ident. Used if not using routing trees or dynamic routers.
14.8. HTML5 Routing
Hooking HTML5 or hash-based routing up to this is relatively simple using, for example, pushy and bidi.
We do not provide direct support for this, since your application will need to make a number of decisions that really are local to the specific app:
-
How to map URIs to your leaf screens. If you use bidi then
bidi-matchwill return exactly what you need from a URI route match (e.g.{:handler :x :route-params {:p v}}). -
How to grab the URI bits you need. For example,
pushylets you hook up to HTML5 history events. -
If a routing decision should be deferred/reversed? E.g. navigation should be denied until a form is saved.
-
How you want to update the URI on routing. You can define your own additional mutation to do this (e.g. via
pushy/set-token!) and possibly compose it into a new mutations withroute-to. The functionr/update-routing-linkscan be used for such a composition:
; in some defmutation
(swap! state (fn [m]
(-> m
(r/update-routing-links { :handler :h :route-params p })
(app/your-state-updates)))
(pushy/set-token! your-uri-interpretation-of-h)See the fulcro-template on github. It supports HTML5 routing with a demo tree.
15. Forms Overview
On the surface forms are trivial: you have DOM input fields, users put stuff in them, and you submit that to a server. For really simple forms you already have sufficient tools and you can simply code them however you see fit.
The next most critical thing you’ll want is some help with managing the meta-state that goes with most form interactions:
-
When is the content of a field valid?
-
When should you show a validation error message? E.g. you should not tell a user that they made a mistake on a field they have yet to touch.
-
How do you "reset" the form if the user changes their mind or cancels an edit?
-
How do you ensure that just the data that has changed is sent to the server?
These more advanced interactions require that you track a few things:
-
The validation rules
-
Which fields are "complete" (ready for validation)?
-
What was the state of the form fields before the user started interacting with it?
-
How do you transition states (e.g. indicate that the updated form is now the new "real state"?
You will also commonly need a way to deal with the fact that a form may cross several entities in your database, generating a more global top-level form concern: are all of the entities in this form valid?
Again, you can certainly code all of this by hand, but Fulcro includes two different namespaces of helpers that can make dealing with these aspects of forms a little easier. The reason there are two is that the older version was not easy to change without breaking existing code, so new functions were written in a new namespace as an alternative.
The form state support concentrates just on providing utilities to manage the data, and has validation that is based on Clojure Spec but is completely pluggable. The full form management support is the older version that attempts to isolate your components a bit more from the event and state management, but at the expense of some added complexity.
Both are fully supported, though the form state support is considered the cleaner implementation.
16. Form State Support (version 2.1.4+)
The namespace fulcro.ui.form-state (aliased to fs in this chapter) includes functions and mutations for
working with your entity as a form. This support brings functions for dealing with common state storage and form transitions
with minimal opinion or additional complexity.
Your UI is still built and rendered identically to what you’re already used to. The form state support simply adds some additional state tracking that can help you manage things like field validation and minimal delta submissions to the server.
16.1. Defining the Form Component
A component that wishes to act as a form must have an ident and a query. There are two additional steps you must do to prepare your component to work with form state management:
-
Add a form configuration join to your query.
-
Declare which of your props/joins are part of the form.
So, a minimal form-state-compatible component looks like this:
(defsc NameForm [this props]
{:query [:id :name fs/form-config-join] ; fs is fulcro.ui.form-state
:ident [:name-form/by-id :id]
:form-fields #{:name}} ; MUST be a set of keywords from your query
...)Technically this adds a protocol to the generated component. If you’re using defui, it looks like this:
(defui NameForm
static fs/IFormFields
(form-field [this] #{:name})
...)next, you’ll want to populate your state with some data. Of course during this step you’ll need to populate that form configuration data.
16.2. Form Configuration
Form state is stored in a form configuration entity in your app state database. This configuration entity includes:
-
The "pristine" state of your entity.
-
Which properties (and joins) of your entity are part of the form.
-
Which properties are "complete" (ready for validation).
-
A map of which parts of the form come from which declared component.
The form state is normalized into your state database. There are two ways of adding this configuration:
-
Add it to a tree of initial (or incoming) state, and merge that (which will normalize it all).
-
Add it directly to your state database.
these methods are described in the following section.
16.2.1. Initializing a Tree of Data
This case occurs when you have either some initial state or a function on the client side that generates a new entity (i.e. with a tempid) and you want to immediately use it with a form. Forms can be nested into a group, and the functions automatically support initializing the configuration recursively for a given form set.
Say you have a person with multiple (normalized) phone numbers. You want to make a new person and set them up with an initial phone number to fill out. The tree for that data might look like this:
(def person-tree
{ :db/id (prim/tempid)
:person/name "Joe"
:person/phone-numbers [{:db/id (prim/tempid) :phone/number "555-1212"}]})with components like:
(defsc PhoneForm [this props]
{:query [:db/id :phone/number fs/form-config-join]
:ident [:phone/by-id :db/id]
:form-fields #{:phone/number}}
...)
(defsc PersonForm [this props]
{:query [:db/id :person/name {:person/phone-numbers (prim/get-query PhoneForm)}
fs/form-config-join]
:ident [:person/by-id :db/id]
:form-fields #{:person/name :person/phone-numbers}}
...)Normally you might throw this into your application state with something like:
(prim/merge-component! reconciler PersonForm person-tree)which will insert and normalize the person and phone number.
If you also are supporting form interactions then you can augment the form with form configuration data like so:
(def person-tree-with-form-support (fs/add-form-config PersonForm person-tree))
(prim/merge-component! reconciler PersonForm person-tree-with-form-support)|
Important
|
add-form-config will look at all of the form (and subforms reachable from that form), but it will
only add config to the ones that are missing it. This means the current form state is not reset by this call.
|
16.2.2. Initializing in a Mutation
The other very common case is this: You’ve loaded something from the server, and you’d like to use it as the basis for form fields. In this case the data is already normalized in your state database, and you’ll need to work on it via a mutation.
The add-form-config* function is the helper for that. The common pattern for using it is:
(defmutation use-person-as-form [{:keys [person-id]}]
(action [{:keys [state]}]
(swap! state (fn [s]
(-> s
(fs/add-form-config* PersonForm [:person/by-id person-id]) ; this will affect the joined phone as well
(assoc-in [:component :person-editor :person-to-edit] [:person/by-id person-id]) ; hook it into an editor?
...))))) ; other setup code|
Important
|
add-form-config* will look at all of the form (and subforms reachable from that form), but it will
only add config to the ones that are missing it. This means the current form state is not reset by this call. This
is intentional, since you might add sub-forms (e.g. a new phone number) to a form group, and this allows you to
re-run the add of config data from the top without worrying about affecting pre-existing form state.
|
16.3. Validation
Validation in the form state system is completely customizable. There is built-in support for working with Clojure Spec as your validation layer. In order for this to be effective you should be sure to namespace all of your properties in a globally-unique way, and then simply write normal specs for them. The section on custom validators describes the other supported mechanism for validation.
The central function for using specs is fs/get-spec-validity, which can be used on an entire form or a single field.
This function returns one of #{:valid, :invalid, :unchecked}.
Initially, a form’s fields are marked as incomplete. When in this state the validity will always be :unchecked.
Some additional helpers are useful for concise UI code:
-
(invalid-spec? form field)- Field is an optional argument. Returns true if the form (field) is complete and invalid. -
(valid-spec? form field)- Field is an optional argument. Returns true if the form (field) is complete and valid. -
(checked? form field)- Field is an optional argument. Returns true if the form (field) is complete. This function works no matter what validator you’re using. -
(dirty? form field)- Field is an optional argument. Returns true if the pristine copy of the form (field) doesn’t match the current entity.
For example:
(defsc PersonForm [this {:keys [person/name] :as props}]
...
;; The `mark-complete!` mutation is covered below
(dom/input {:value name :onBlur #(prim/transact! this `[(fs/mark-complete! ...)]) ...})
(when (fs/invalid-spec? props :person/name)
(dom/span "Invalid username!")
...)will show the error only if the field is complete (shown as a call to mark-complete! on blur), but only if the field’s value
does not match the spec for :person/name.
As you can see, the idea of "complete" is important to validation.
16.3.1. Completing Fields
Initially the form config will not consider any of the form fields to be complete. The idea of field "completion" is so that you can prevent validation on a field until you feel it is a good time. No one wants to see error messages about fields that they have yet to interact with!
However, depending on what you are editing, you may have different ideas about when fields should be considered complete. For example, if you just loaded a saved entity from a server, then all of the fields are probably complete by definition, meaning that you need a way to mark all fields (recursively) complete.
When you first add form config to an entity, all fields are "incomplete". You can iteratively mark fields complete as the user interacts with them, or trigger a completion "event" all at once. There is a support function and a mutation for this.
The mark-complete* is meant to be used from within mutations against the app state database. It requires the
state map (not atom), the entity’s ident, and which field you want to mark complete. If you omit the field, then
it marks everything (recursively) complete form that form down.
So, in our earlier example of loading a person for editing, we’d augment that mutation like so:
(defmutation use-person-as-form [{:keys [person-id]}]
(action [{:keys [state]}]
(swap! state (fn [s]
(-> s
(fs/add-form-config* PersonForm [:person/by-id person-id])
;; MUST come after the config is added. Mark all fields complete (since they came from existing entity)
(fs/mark-complete* [:person/by-id person-id])
;; add it to some editor as the target
(assoc-in [:component :person-editor :person-to-edit] [:person/by-id person-id]))))))and all validations will immediately apply in the UI.
The mark-complete! mutation can be used for the exact same purpose from the UI. Typically, it is used in things like
:onBlur handlers to indicate that a field is ready for validation. It takes an :entity-ident and :field.
The :entity-ident is optional if the transaction is invoked on the form component of that field, and if the :field is
not supplied it means to affect the entire form recursively:
(defsc PersonForm [this {:keys [db/id person/name]}]
... ; as before
;; uses the ident of the current instance as the entity-ident
(dom/input {:value name
:onBlur #(prim/transact! this `[(fs/mark-complete! {:field :person/name})])})
...)The inverse operations are clear-complete! and clear-complete*.
16.3.2. Using non-spec Validators
You may not wish to use the longer names of properties that are required in order to get stable Clojure Spec support simply for form validation. In this case you’d still like to use the idea of field completion and validation, but you’ll want to supply the mechanism whereby validity is determined.
The form traversal code for validation is already in the form state code, and a helper function is provided so you can leverage it to create your own form validation system. It is quite simple:
-
Write a function
(fn [form field] …)that returns true if the given field (a keyword) is valid on the given form (a map of the props for the form that contains that field). -
Generate a validator with
fs/make-validator
The returned validator works identically to get-spec-validity, but it uses your custom function instead of specs to
determine validity.
For example, you might want to make a simple new user form validation that looks something like this:
(defn new-user-form-valid [form field]
(let [v (get form field)]
(case field
:username (and (string? v) (seq (str/trim v))) ; not empty
:password (> (count v) 8) ; longer than 8
:password-2 (= v (:password form))))) ; passwords match
(def validator (fs/make-validator new-user-form-valid))
(defsc NewUser [this {:keys [username password password-2] :as props}]
...
(dom/input {:name "password-2" :value password-2 :onBlur #(prim/transact! this `[(fs/mark-complete ...)]) ...})
(when (= :invalid (validator props :password-2))
(dom/span "Passwords do not match!")
...)As before: you won’t see the error message on an invalid entry until your code has marked the field complete. This moves a decent amount of clutter out of the primary UI code and into the form support itself.
16.4. Submitting Data
Once your form is valid and the user indicates a desire to save, then your interest shifts to sending that data to the
server. The dirty-fields function should be used from the UI in order to calculate this and pass it as a parameter
to a mutation. The mutation can then update the local pristine state of form config and indicate a remote operation.
The dirty-fields function returns a map from ident to fields that have changed. If the ident includes a temporary ID,
then all fields for that form will be included. If the ID is not a temp id, then it will only include those fields that
differ from the pristine copy of the original. This will include subform references as to-one or to-many idents (to
indicate the addition or removal of subform instances).
You can ask dirty-fields to either send the explicit new values (only), or a before/after picture of each field. The
latter is particularly useful for easily deriving the addition/removal of references, but is also quite useful if you
would like to do optimistic concurrency (e.g. not apply a change to a server where the old value wasn’t still in the
database).
(defmutation submit-person [{:keys [id]}]
(action [{:keys [state]}]
(swap! state fs/entity->pristine* [:person/by-id id])) ; updates form state to think the form is now in pristine shape
(remote [env] true)) ; diff goes over the network as a parameter from the UI layer
(defsc Person [this props]
... ; as before
(dom/button {:onClick #(prim/transact! this `[(submit-person ~{:id id :diff (fs/dirty-fields props true)})])} "Submit")
...)If you’d like to wait until the server indicates everything is ok, then you can use ptransact! and returning to get back
some submission information, and move the entity→pristine* step to a later mutation:
;; Exists purely as a way to return a value into a normalized state database...
(defsc SubmissionStatus [_ _]
{:query [:id :status]
:ident [:submission-status/by-id :id]})
(defmutation submit-person [{:keys [id]}]
(remote [{:keys [ast state]] (fulcro.client.mutations/returning ast @state SubmissionStatus))
(defmutation finish-person-submission [{:keys [id]}]
(action [{:keys [state]}]
(if (= :ok (get-in @state [:submission-status/by-id id :status]))
(swap! state fs/entity->pristine* [:person/by-id id])
...))) ; else show some error
...
(ptransact! this `[(submit-person ~{:id id :diff (fs/dirty-fields props true)})
(finish-person-submission ~{:id id})])See pessimistic transactions for more details.
Of course, the behavior of the UI is up to you, and all of the examples above assume that the mutations in question would also be changing other things in your form/editor to show status to the user as you go. It should be relatively straightforward to combine the form state maintenance functions with your own support functions and mutations to create your "standard" look for form interactions across your application.
16.5. Form State Demos
The following two fully-functional demos show you complete code for two scenarios.
16.5.1. Selecting an Entity for Edit
A very common use case is the scenario where the entities are already loaded and are displayed in the UI. The user clicks on an entry, and you take them to a form where they can edit the item.
This demo lists some phone numbers. Clicking on one:
-
Adds form configuration to the entity
-
Switches the UI to the form editor
-
Switches back to the (updated) list on save
(ns book.forms.form-state-demo-1
(:require [fulcro.ui.elements :as ele]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.ui.form-state :as fs]
[fulcro.ui.bootstrap3 :as bs]
[fulcro.client.primitives :as prim :refer [defui defsc]]
[fulcro.client.dom :as dom]
[clojure.spec.alpha :as s]
[garden.core :as g]))
(declare Root PhoneForm)
(defn render-field
"A helper function for rendering just the fields."
[component field renderer]
(let [form (prim/props component)
entity-ident (prim/get-ident component form)
id (str (first entity-ident) "-" (second entity-ident))
is-dirty? (fs/dirty? form field)
clean? (not is-dirty?)
validity (fs/get-spec-validity form field)
is-invalid? (= :invalid validity)
value (get form field "")]
(renderer {:dirty? is-dirty?
:ident entity-ident
:id id
:clean? clean?
:validity validity
:invalid? is-invalid?
:value value})))
(defn input-with-label
"A non-library helper function, written by you to help lay out your form."
([component field field-label validation-string input-element]
(render-field component field
(fn [{:keys [invalid? id dirty?]}]
(bs/labeled-input {:error (when invalid? validation-string)
:id id
:warning (when dirty? "(unsaved)")
:input-generator input-element} field-label))))
([component field field-label validation-string]
(render-field component field
(fn [{:keys [invalid? id dirty? value invalid ident]}]
(bs/labeled-input {:value value
:id id
:error (when invalid? validation-string)
:warning (when dirty? "(unsaved)")
:onBlur #(prim/transact! component `[(fs/mark-complete! {:entity-ident ~ident
:field ~field})])
:onChange #(m/set-string! component field :event %)} field-label)))))
(s/def ::phone-number #(re-matches #"\(?[0-9]{3}[-.)]? *[0-9]{3}-?[0-9]{4}" %))
(defmutation abort-phone-edit [{:keys [id]}]
(action [{:keys [state]}]
(swap! state (fn [s]
(-> s
; stop editing
(dissoc :root/phone)
; revert to the pristine state
(fs/pristine->entity* [:phone/by-id id])))))
(refresh [env] [:root/phone]))
(defmutation submit-phone [{:keys [id delta]}]
(action [{:keys [state]}]
(js/console.log delta)
(swap! state (fn [s]
(-> s
; stop editing
(dissoc :root/phone)
; update the pristine state
(fs/entity->pristine* [:phone/by-id id])))))
(remote [env] true)
(refresh [env] [:root/phone [:phone/by-id id]]))
(defsc PhoneForm [this {:keys [:db/id ::phone-type root/dropdown] :as props}]
{:query [:db/id ::phone-type ::phone-number
{[:root/dropdown '_] (prim/get-query bs/Dropdown)} ;reusable dropdown
fs/form-config-join]
:form-fields #{::phone-number ::phone-type}
:ident [:phone/by-id :db/id]}
(dom/div :.form
(input-with-label this ::phone-number "Phone:" "10-digit phone number is required.")
(input-with-label this ::phone-type "Type:" ""
(fn [attrs]
(bs/ui-dropdown dropdown
:value phone-type
:onSelect (fn [v]
(m/set-value! this ::phone-type v)))))
(bs/button {:onClick #(prim/transact! this `[(abort-phone-edit {:id ~id})])} "Cancel")
(bs/button {:disabled (or (not (fs/checked? props)) (fs/invalid-spec? props))
:onClick #(prim/transact! this `[(submit-phone {:id ~id :delta ~(fs/dirty-fields props true)})])} "Commit!")))
(def ui-phone-form (prim/factory PhoneForm {:keyfn :db/id}))
(defsc PhoneNumber [this {:keys [:db/id ::phone-type ::phone-number]} {:keys [onSelect]}]
{:query [:db/id ::phone-number ::phone-type]
:initial-state {:db/id :param/id ::phone-number :param/number ::phone-type :param/type}
:ident [:phone/by-id :db/id]}
(dom/li
(dom/a {:onClick (fn [] (onSelect id))}
(str phone-number " (" (phone-type {:home "Home" :work "Work" nil "Unknown"}) ")"))))
(def ui-phone-number (prim/factory PhoneNumber {:keyfn :db/id}))
(defsc PhoneBook [this {:keys [:db/id ::phone-numbers]} {:keys [onSelect]}]
{:query [:db/id {::phone-numbers (prim/get-query PhoneNumber)}]
:initial-state {:db/id :main-phone-book
::phone-numbers [{:id 1 :number "541-555-1212" :type :home}
{:id 2 :number "541-555-5533" :type :work}]}
:ident [:phonebook/by-id :db/id]}
(dom/div
(dom/h4 "Phone Book (click a number to edit)")
(dom/ul
(map (fn [n] (ui-phone-number (prim/computed n {:onSelect onSelect}))) phone-numbers))))
(def ui-phone-book (prim/factory PhoneBook {:keyfn :db/id}))
(defmutation edit-phone-number [{:keys [id]}]
(action [{:keys [state]}]
(let [phone-type (get-in @state [:phone/by-id id ::phone-type])]
(swap! state (fn [s]
(-> s
; make sure the form config is with the entity
(fs/add-form-config* PhoneForm [:phone/by-id id])
; since we're editing an existing thing, we should start it out complete (validations apply)
(fs/mark-complete* [:phone/by-id id])
(bs/set-dropdown-item-active* :phone-type phone-type)
; tell the root UI that we're editing a phone number by linking it in
(assoc :root/phone [:phone/by-id id])))))))
(defsc Root [this {:keys [:root/phone :root/phonebook]}]
{:query [{:root/dropdown (prim/get-query bs/Dropdown)}
{:root/phonebook (prim/get-query PhoneBook)}
{:root/phone (prim/get-query PhoneForm)}]
:initial-state (fn [params]
{:root/dropdown (bs/dropdown :phone-type "Type" [(bs/dropdown-item :work "Work")
(bs/dropdown-item :home "Home")])
:root/phonebook (prim/get-initial-state PhoneBook {})})}
(ele/ui-iframe {:frameBorder 0 :width 500 :height 200}
(dom/div
(dom/link {:rel "stylesheet" :href "bootstrap-3.3.7/css/bootstrap.min.css"})
(if (contains? phone ::phone-number)
(ui-phone-form phone)
(ui-phone-book (prim/computed phonebook {:onSelect (fn [id] (prim/transact! this `[(edit-phone-number {:id ~id})]))}))))))16.5.2. Loading or Creating Something New
This example shows the case where a graph of entities (a person and multiple phone numbers) are to be created in a UI, or are to be loaded from a server. This is a full-stack example, though it doesn’t actually persist the data (it just prints what the server receives in the Javascript console).
There are two buttons. One will load an existing entity into the editor, and of course submissions will send a minimal delta. The other button will create a new person, and submissions will send all fields.
The load case, as you can see in the code, is very similar to the prior example, but just includes some extra code to show you how to put it together with a load interaction.
(ns book.forms.form-state-demo-2
(:require [devcards.core]
[fulcro.ui.elements :as ele]
[fulcro.server :as server]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.ui.bootstrap3 :as bs]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[fulcro.ui.form-state :as fs]
[clojure.string :as str]
[cljs.spec.alpha :as s]
[fulcro.client.data-fetch :as df]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Server Code
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
; a simple query for any person, that will return valid-looking data
(server/defquery-entity :person/by-id
(value [env id params]
{:db/id id
::person-name (str "User " id)
::person-age 56
::phone-numbers [{:db/id 1 ::phone-number "555-111-1212" ::phone-type :work}
{:db/id 2 ::phone-number "555-333-4444" ::phone-type :home}]}))
(defonce id (atom 1000))
(defn next-id [] (swap! id inc))
; Server submission...just prints delta for demo, and remaps tempids (forms with tempids are always considered dirty)
(server/defmutation submit-person [params]
(action [env]
(js/console.log "Server received form submission with content: ")
(cljs.pprint/pprint params)
(let [ids (map (fn [[k v]] (second k)) (:diff params))
remaps (into {} (keep (fn [v] (when (prim/tempid? v) [v (next-id)])) ids))]
{:tempids remaps})))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Client Code
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(s/def ::person-name (s/and string? #(seq (str/trim %))))
(s/def ::person-age #(s/int-in-range? 1 120 %))
(defn render-field [component field renderer]
(let [form (prim/props component)
entity-ident (prim/get-ident component form)
id (str (first entity-ident) "-" (second entity-ident))
is-dirty? (fs/dirty? form field)
clean? (not is-dirty?)
validity (fs/get-spec-validity form field)
is-invalid? (= :invalid validity)
value (get form field "")]
(renderer {:dirty? is-dirty?
:ident entity-ident
:id id
:clean? clean?
:validity validity
:invalid? is-invalid?
:value value})))
(def integer-fields #{::person-age})
(defn input-with-label
"A non-library helper function, written by you to help lay out your form."
([component field field-label validation-string input-element]
(render-field component field
(fn [{:keys [invalid? id dirty?]}]
(bs/labeled-input {:error (when invalid? validation-string)
:id id
:warning (when dirty? "(unsaved)")
:input-generator input-element} field-label))))
([component field field-label validation-string]
(render-field component field
(fn [{:keys [invalid? id dirty? value invalid ident]}]
(bs/labeled-input {:value value
:id id
:error (when invalid? validation-string)
:warning (when dirty? "(unsaved)")
:onBlur #(prim/transact! component `[(fs/mark-complete! {:entity-ident ~ident
:field ~field})
:root/person])
:onChange (if (integer-fields field)
#(m/set-integer! component field :event %)
#(m/set-string! component field :event %))} field-label)))))
(s/def ::phone-number #(re-matches #"\(?[0-9]{3}[-.)]? *[0-9]{3}-?[0-9]{4}" %))
(defsc PhoneForm [this {:keys [::phone-type ui/dropdown] :as props}]
{:query [:db/id ::phone-number ::phone-type
{:ui/dropdown (prim/get-query bs/Dropdown)}
fs/form-config-join]
:form-fields #{::phone-number ::phone-type}
:ident [:phone/by-id :db/id]}
(dom/div :.form
(input-with-label this ::phone-number "Phone:" "10-digit phone number is required.")
(input-with-label this ::phone-type "Type:" ""
(fn [attrs]
(bs/ui-dropdown dropdown
:value phone-type
:onSelect (fn [v]
(m/set-value! this ::phone-type v)
(prim/transact! this `[(fs/mark-complete! {:field ::phone-type})
:root/person])))))))
(def ui-phone-form (prim/factory PhoneForm {:keyfn :db/id}))
(defn add-phone-dropdown*
"Add a phone type dropdown to a phone entity"
[state-map phone-id default-type]
(let [dropdown-id (random-uuid)
dropdown (bs/dropdown dropdown-id "Type" [(bs/dropdown-item :work "Work") (bs/dropdown-item :home "Home")])]
(-> state-map
(prim/merge-component bs/Dropdown dropdown) ; we're being a bit wasteful here and adding a new dropdown to state every time
(bs/set-dropdown-item-active* dropdown-id default-type)
(assoc-in [:phone/by-id phone-id :ui/dropdown] (bs/dropdown-ident dropdown-id)))))
(defn add-phone*
"Add the given phone info to a person."
[state-map phone-id person-id type number]
(let [phone-ident [:phone/by-id phone-id]
new-phone-entity {:db/id phone-id ::phone-type type ::phone-number number}]
(-> state-map
(update-in [:person/by-id person-id ::phone-numbers] (fnil conj []) phone-ident)
(assoc-in phone-ident new-phone-entity)
(add-phone-dropdown* phone-id type))))
(defmutation add-phone
"Mutation: Add a phone number to a person, and initialize it as a working form."
[{:keys [person-id]}]
(action [{:keys [state]}]
(let [phone-id (prim/tempid)]
(swap! state (fn [s]
(-> s
(add-phone* phone-id person-id :home "")
(fs/add-form-config* PhoneForm [:phone/by-id phone-id])))))))
(defsc PersonForm [this {:keys [:db/id ::phone-numbers]}]
{:query [:db/id ::person-name ::person-age
{::phone-numbers (prim/get-query PhoneForm)}
fs/form-config-join]
:form-fields #{::person-name ::person-age ::phone-numbers} ; ::phone-numbers here becomes a subform because it is a join in the query.
:ident [:person/by-id :db/id]}
(dom/div :.form
(input-with-label this ::person-name "Name:" "Name is required.")
(input-with-label this ::person-age "Age:" "Age must be between 1 and 120")
(dom/h4 "Phone numbers:")
(when (seq phone-numbers)
(map ui-phone-form phone-numbers))
(bs/button {:onClick #(prim/transact! this `[(add-phone {:person-id ~id})])} (bs/glyphicon {} :plus))))
(def ui-person-form (prim/factory PersonForm {:keyfn :db/id}))
(defn add-person*
"Add a person with the given details to the state database."
[state-map id name age]
(let [person-ident [:person/by-id id]
person {:db/id id ::person-name name ::person-age age}]
(assoc-in state-map person-ident person)))
(defmutation edit-new-person [_]
(action [{:keys [state]}]
(let [person-id (prim/tempid)
person-ident [:person/by-id person-id]
phone-id (prim/tempid)]
(swap! state
(fn [s] (-> s
(add-person* person-id "" 0)
(add-phone* phone-id person-id :home "")
(assoc :root/person person-ident) ; join it into the UI as the person to edit
(fs/add-form-config* PersonForm [:person/by-id person-id])))))))
(defn add-dropdowns* [state-map person-id]
(let [phone-number-idents (get-in state-map [:person/by-id person-id ::phone-numbers])]
(reduce (fn [s phone-ident]
(let [phone-id (second phone-ident)
phone-type (get-in s [:phone/by-id phone-id ::phone-type])]
(add-phone-dropdown* s phone-id phone-type)))
state-map
phone-number-idents)))
(defmutation edit-existing-person
"Turn an existing person with phone numbers into an editable form with phone subforms."
[{:keys [person-id]}]
(action [{:keys [state]}]
(swap! state
(fn [s] (-> s
(assoc :root/person [:person/by-id person-id])
(fs/add-form-config* PersonForm [:person/by-id person-id]) ; will not re-add config to entities that were present
(fs/entity->pristine* [:person/by-id person-id]) ; in case we're re-loading it, make sure the pristine copy it up-to-date
(fs/mark-complete* [:person/by-id person-id]) ; it just came from server, so all fields should be valid
(add-dropdowns* person-id)))))) ; each phone number needs a dropdown
(defmutation submit-person [{:keys [id]}]
(action [{:keys [state]}]
(swap! state fs/entity->pristine* [:person/by-id id]))
(remote [env] true))
(defsc Root [this {:keys [root/person]}]
{:query [{:root/person (prim/get-query PersonForm)}]
:initial-state (fn [params] {})}
(ele/ui-iframe {:frameBorder 0 :width 800 :height 700}
(dom/div
(dom/link {:rel "stylesheet" :href "bootstrap-3.3.7/css/bootstrap.min.css"})
(bs/button {:onClick #(df/load this [:person/by-id 21] PersonForm {:target [:root/person]
:marker false
:post-mutation `edit-existing-person
:post-mutation-params {:person-id 21}})}
"Simulate Edit (existing) Person from Server")
(bs/button {:onClick #(prim/transact! this `[(edit-new-person {})])} "Simulate New Person Creation")
(when (::person-name person)
(ui-person-form person))
(dom/div
(bs/button {:onClick #(prim/transact! this `[(fs/reset-form! {:form-ident [:person/by-id ~(:db/id person)]})])
:disabled (not (fs/dirty? person))} "Reset")
(bs/button {:onClick #(prim/transact! this `[(submit-person {:id ~(:db/id person) :diff ~(fs/dirty-fields person false)})])
:disabled (or
(fs/invalid-spec? person)
(not (fs/dirty? person)))} "Submit")))))17. Full Form Management (Older Support)
Fulcro includes alternate (older) support for working with forms. It is recommended that new applications use form-state support instead. This older form support will probably move to an external library at some point in the future.
The core purpose of the support is to help you with the fact that you usually need roughly the same pattern for each form:
-
A place to store what the form was before the user started editing
-
A way to indicate validation for fields
-
A way to calculate and submit the changes the user has made (ideally as a minimal diff)
-
A way to relate joined entities as sub forms of a form.
All of these things can be written with the primitives that you already have
at your disposal, but the fulcro.ui.forms namespace gives you something to start out with
that may very well fit your needs.
17.1. The Basics
Generic form support is a primary rapid application development feature. Fortunately, the overall structure of Fulcro makes it relatively simple to write form support in a general-purpose, composeable manner. This library defines form support that has:
-
Declarative forms
-
An extensible set of form fields
-
Extensible validation
-
Separation of form UI from form logic
-
Remote integration between the form and entity
-
Local integration with entities in the browser database
The following requires define the namespaces used in the examples:
(ns your-ns
(:require
[fulcro.client.cards :refer [defcard-fulcro]]
[clojure.string :as str]
[com.stuartsierra.component :as component]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defui defsc]]
[fulcro.client :as fc]
[fulcro.client.mutations :as m]
[fulcro.ui.forms :as f]
[fulcro.i18n :refer [tr]]))|
Note
|
When we use the parameter form or the word 'form' in the descriptions below, we mean the data
of the entire entity from a table that normally represents something in your application (like a person, phone number, etc).
This library augments your database entry with form support data (your 'person' becomes a 'person' AND a 'form'). In
raw technical terms, the build-form function takes a map, and adds a f/form-key { … } entry to it. The only
implication for your UI is that your component queries must be expanded to include queries for this additional support
data.
|
17.2. Your Component as a Form
Components that wish to act as forms must meet the following requirements (here f is an alias for the forms namespace):
-
Must implement the
f/IFormprotocol.-
The
fieldsmethod must return a list of fields that includes anid-field
-
-
Must have an ident.
-
Must have a query that includes
f/form-key(an opaque entry the holds the pristine state and definition of the form). -
Entity must be initialized via
f/build-form(e.g. using a mutation or app initialization). -
Render the form fields using
f/form-field.
17.2.1. Step 1: Declare the Form Fields
Form fields are declared on the ui component that will render the form via a static f/IForm protocol. The fields themselves
are declared with function calls that correspond to the field type:
id-field
|
A (meant-to-be-hidden) form field that corresponds to the attribute that uniquely identifies the entity being edited. Required for much of the interesting support. |
text-input
|
An optionally validated input for strings. |
dropdown-input
|
A menu that allows the user to choose from a set of values. |
checkbox-input
|
A boolean control |
| your-input-here! |
Form support is extensible. Whatever interaction you can imagine can be added to a form. |
Form fields are really just simple maps of attributes that describe the configuration of the specified input.
The built-in support for doing form logic expects the fields to be declared on the component that will render the form.
You can use the :protocols option of defsc to add the IForm to your component:
(defsc MyForm [this props]
{:protocols [static f/IForm
(form-spec [this] [(f/id-field :db/id)
(f/text-input :person/name)
...])]}
...)The defsc macro supports adding this protocol through the :form-fields option:
(defsc MyForm [this props]
{:form-fields [(f/id-field :db/id)
(f/text-input :person/name)]}
...)17.3. Step 2: Rendering the Form Fields
The form fields themselves are rendered by calling (f/form-field form field-name). This method only renders
the simple input itself.
(f/form-field my-form :name) ;; results in: (dom/input { ... })This is the minimum we can do to ensure that the logic is correctly connected, while not interfering with your ability to render the form however you please.
You’ll commonly write some functions of your own that combine other DOM markup with this, such as the function
field-with-label shown in the example. Additional functions like f/invalid? can be used to make decisions about
showing/hiding validation messages.
(defn field-with-label
"A non-library helper function, written by you to help lay out your form."
([comp form name label] (field-with-label comp form name label nil))
([comp form name label validation-message]
(dom/div {:className (str "form-group" (if (f/invalid? form name) " has-error" ""))}
(dom/label {:className "col-sm-2" :htmlFor name} label)
;; THE LIBRARY SUPPLIES f/form-field. Use it to render the actual field
(dom/div {:className "col-sm-10"} (f/form-field comp form name))
(when (and validation-message (f/invalid? form name))
(dom/span {:className (str "col-sm-offset-2 col-sm-10" name)} validation-message)))))The rendering of the form is up to you! Thus, your forms can be as pretty (or ugly) as you care to make them. No worrying about figuring out how we render them, and then trying to make that look good.
That said, there is nothing preventing you (or us) from supplying a library function that can produce reasonable looking reusable form rendering.
17.4. Step 3: Setting Up the Form State
A form can augment any entity in an app database table in your client application. The f/build-form function
can take any such entity and add form support to it (under the special key f/form-key as an opaque value in state).
The result is perfectly compatible with the original entity. You can do this in initial-state if you
know at application startup that a form needs to work on some entity, but more likely
you will compose f/build-form into a mutation (for example, a mutation that is changing the UI to display
the form can simultaneously initialize the entity to-be-edited at the same time.
|
Important
|
If you’re doing server-side rendering you should not use build-form via initial state. The server cannot
do that properly. There is a mutation that can be run from a component’s React componentWillMount to recursively
initialize the form support on a specific form with its subforms:
|
(defsc MyForm [this props]
{:query (fn [] [f/form-key ...])
:componentWillMount (fn [] (when-not (f/is-form? (prim/props this)) (prim/transact! this `[(f/initialize-form {})])))
...}
...)Note that this mutation derives all the info it needs by being run on the top-level entity of the form.
17.5. A Complete Form Component
Below is a simple form component (with source) that you can interact with:
(ns book.forms.forms-demo-1
(:require
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.ui.forms :as f]))
(defn field-with-label
"A non-library helper function, written by you to help lay out your form."
([comp form name label] (field-with-label comp form name label nil))
([comp form name label validation-message]
(dom/div :.form-group {:className (when (f/invalid? form name) " has-error")}
(dom/label :.col-sm-2 {:htmlFor name} label)
(dom/div :.col-sm-10
;; THE LIBRARY SUPPLIES f/form-field. Use it to render the actual field
(f/form-field comp form name))
(when (and validation-message (f/invalid? form name))
(dom/span :.col-sm-offset-2.col-sm-10 {:className (str name)} validation-message)))))
; form/props are the same thing. The entity state *is* the form state
(defsc PhoneForm [this form]
{:initial-state (fn [params] (f/build-form PhoneForm (or params {})))
:form-fields [(f/id-field :db/id) (f/text-input :phone/number :className "form-control") (f/dropdown-input :phone/type [(f/option :home "Home") (f/option :work "Work")])]
:query (fn [] [:db/id :phone/type :phone/number f/form-key]) ; Don't forget f/form-key!
:ident [:phone/by-id :db/id]}
(dom/div :.form-horizontal
(field-with-label this form :phone/type "Phone type:") ; Use your own helpers to render out the fields
(field-with-label this form :phone/number "Number:")))
(def ui-phone-form (prim/factory PhoneForm {:keyfn :db/id}))
(defsc Root [this {:keys [phone]}]
{:query [{:phone (prim/get-query PhoneForm)}]
:initial-state (fn [params]
(let [phone-number {:db/id 1 :phone/type :home :phone/number "555-1212"}]
{:phone (prim/get-initial-state PhoneForm phone-number)}))}
(dom/div
(ui-phone-form phone)))17.6. Validation
There is a multimethod (f/form-field-valid? [symbol value args])
that dispatches on symbol (symbols are allowed in app state, lambdas are not). Form fields that support validation
will run that validation at their configured time (typically on blur).
Validation is therefore completely extensible. You need only supply a dispatch for your own validation symbol, and
declare it as the validator on a field (by symbol).
Validation is tri-state. The allowed states are :valid (checked and correct), :invalid (checked and incorrect),
and :unchecked.
You can trigger full-form validation (which you should do as part of your interaction with the form) by calling
(f/validate-entire-form! component form). This function invokes a transaction that will update the validation
markings on all declared fields (which in turn will re-render your UI).
If you want to check if a form is valid (without updating the markings in the app state…e.g. you want an inline
answer), then use (f/valid? (f/validate-fields form)) to get an immediate answer. This is more computationally
expensive, but allows you to check the validity of the form without triggering an actual validation transaction against
the application state.
For example, the definition of a validator for US phone numbers could be:
(defvalidator us-phone?
[sym value args]
(seq (re-matches #"[(][0-9][0-9][0-9][)] [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]" value)))The only change in your UI would be to add the validator to the form field declaration, along with a validation message. The result (with source) is in the example below:
(ns book.forms.forms-demo-2
(:require
[clojure.string :as str]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client :as fc]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.ui.forms :as f :refer [defvalidator]]))
(declare ValidatedPhoneForm)
(defn field-with-label
"A non-library helper function, written by you to help lay out your form."
([comp form name label] (field-with-label comp form name label nil))
([comp form name label validation-message]
(dom/div #js {:className (str "form-group" (if (f/invalid? form name) " has-error" ""))}
(dom/label :.col-sm-2 {:htmlFor name} label)
;; THE LIBRARY SUPPLIES f/form-field. Use it to render the actual field
(dom/div :.col-sm-10 (f/form-field comp form name))
(when (and validation-message (f/invalid? form name))
(dom/span :.col-sm-offset-2.col-sm-10 {:className (str name)} validation-message)))))
;; Sample validator that requires there be at least two words
(f/defvalidator name-valid? [_ value args]
(let [trimmed-value (str/trim value)]
(str/includes? trimmed-value " ")))
(defvalidator us-phone?
[sym value args]
(seq (re-matches #"[(][0-9][0-9][0-9][)] [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]" value)))
(defsc ValidatedPhoneForm [this form]
{:initial-state (fn [params] (f/build-form ValidatedPhoneForm (or params {})))
:form-fields [(f/id-field :db/id)
(f/text-input :phone/number :validator `us-phone?) ; Addition of validator
(f/dropdown-input :phone/type [(f/option :home "Home") (f/option :work "Work")])]
:query [:db/id :phone/type :phone/number f/form-key]
:ident [:phone/by-id :db/id]}
(dom/div :.form-horizontal
(field-with-label this form :phone/type "Phone type:")
;; One more parameter to give the validation error message:
(field-with-label this form :phone/number "Number:" "Please format as (###) ###-####")))
(def ui-vphone-form (prim/factory ValidatedPhoneForm))
(defsc Root [this {:keys [phone]}]
{:query [f/form-key {:phone (prim/get-query ValidatedPhoneForm)}]
:initial-state (fn [params]
(let [phone-number {:db/id 1 :phone/type :home :phone/number "555-1212"}]
{:phone (prim/get-initial-state ValidatedPhoneForm phone-number)}))}
(dom/div
(ui-vphone-form phone)))17.7. State Evolution
A form will initially record the pristine state of field values during build-form. As you interact with
the form the entity data will change (locally only). This allows the library to support:
-
The ability to compare the original entity state with the current (edited) state
-
Reset the entity state from the pristine condition
-
Commit just the actual changes to the entity to a remote
This, combined with a little server code, makes the form support full stack!
You can trigger the following operations on a form:
-
(f/commit-to-entity! comp): Commit the current edits to the entity (no-op if the form doesn’t validate) -
(f/commit-to-entity! comp true): Commit the current edits to the entity AND the server (is a no-op if the form doesn’t validate) -
(f/reset-from-entity! comp): Undo the changes on the form (back to the pristine state of the original), (triggers validation after the reset)
|
Important
|
The pristine state is the copy. Editing the fields is identical to editing your entity. A common question is "Why isn’t it the other way around?" The answer is "because of nested forms". Joining together entities requires a query join and destructuring of props. You already know how to do that with Fulcro. If you were editing some "hidden" thing, then you would not know how to write, query, or render your nested form components. |
17.7.1. State evolution within your own transactions
Any changes you make to your entity after build-form are technically considered form edits (and make the form dirty
and possibly invalid). The built-in form fields just change the state of the entity, and you can too.
Commits will copy the entity state into the form’s pristine holding area, and resets will copy from this pristine area back to your entity.
The primary concern is that any custom fields that you create should be careful to only populate the value of fields with things that are serializable via transit, since their updated values will need to be transmitted across the wire for full-stack operation.
17.8. Form Composition
Form support augments normalized entities in your app database. This makes it possible for them to be easily composed!
They are UI components, and have nothing special
about them other than the f/form-key state that is added to the entity (through your call of build-form).
You can convert any entity in your database to a form using the build-form function, meaning that you can load
entities as normal, and as you want to edit them in a form:
-
First mutate them into form-compatible entities with
build-form(which will not touch the original properties of the entity, just addf/form-keydata). -
Render them with a UI component (that has the correct entity Ident) with a render method that renders the form fields with
form-field.
17.8.1. Example: A More Complete, Nested Form
Here is a running example with source for an application that renders a Person form. The person can have any number of phone numbers,
each represented by a nested phone number entity/form. Note the use of :initial-state in Root to build out sample
data. It also includes validation of fields, and some optional rendering based on the checkbox value.
(ns book.forms.forms-demo-3
(:require
[clojure.string :as str]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.ui.forms :as f :refer [defvalidator]]))
(declare ValidatedPhoneForm)
;; Sample validator that requires there be at least two words
(defn field-with-label
"A non-library helper function, written by you to help lay out your form."
([comp form name label] (field-with-label comp form name label nil))
([comp form name label validation-message]
(dom/div :.form-group {:className (when (f/invalid? form name) "has-error")}
(dom/label :.col-sm-2 {:htmlFor name} label)
;; THE LIBRARY SUPPLIES f/form-field. Use it to render the actual field
(dom/div :.col-sm-10 (f/form-field comp form name))
(when (and validation-message (f/invalid? form name))
(dom/span :.col-sm-offset-2.col-sm-10 {:className (str name)} validation-message)))))
(defn checkbox-with-label
"A helper function to lay out checkboxes."
([comp form name label] (field-with-label comp form name label nil))
([comp form name label validation-message]
(dom/div :.checkbox
(dom/label (f/form-field comp form name) label))))
(f/defvalidator name-valid? [_ value args]
(let [trimmed-value (str/trim value)]
(str/includes? trimmed-value " ")))
(defvalidator us-phone?
[sym value args]
(seq (re-matches #"[(][0-9][0-9][0-9][)] [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]" value)))
(defmutation add-phone [{:keys [id person]}]
(action [{:keys [state]}]
(let [new-phone (f/build-form ValidatedPhoneForm {:db/id id :phone/type :home :phone/number ""})
person-ident [:people/by-id person]
phone-ident (prim/ident ValidatedPhoneForm new-phone)]
(swap! state (fn [s]
(-> s
(assoc-in phone-ident new-phone)
(m/integrate-ident* phone-ident :append (conj person-ident :person/phone-numbers))))))))
(defsc ValidatedPhoneForm [this form]
{:initial-state (fn [params] (f/build-form this (or params {})))
:query [:db/id :phone/type :phone/number f/form-key]
:ident [:phone/by-id :db/id]
:form-fields [(f/id-field :db/id)
(f/text-input :phone/number :validator `us-phone?) ; Addition of validator
(f/dropdown-input :phone/type [(f/option :home "Home") (f/option :work "Work")])]}
(dom/div :.form-horizontal
(field-with-label this form :phone/type "Phone type:")
;; One more parameter to give the validation error message:
(field-with-label this form :phone/number "Number:" "Please format as (###) ###-####")))
(def ui-vphone-form (prim/factory ValidatedPhoneForm {:keyfn :db/id}))
(defsc PersonForm [this {:keys [person/phone-numbers] :as props}]
{:initial-state (fn [params] (f/build-form this (or params {})))
:form-fields [(f/id-field :db/id)
(f/subform-element :person/phone-numbers ValidatedPhoneForm :many)
(f/text-input :person/name :validator `name-valid?)
(f/integer-input :person/age :validator `f/in-range?
:validator-args {:min 1 :max 110})
(f/checkbox-input :person/registered-to-vote?)]
; NOTE: f/form-root-key so that sub-forms will trigger render here
:query [f/form-root-key f/form-key
:db/id :person/name :person/age
:person/registered-to-vote?
{:person/phone-numbers (prim/get-query ValidatedPhoneForm)}]
:ident [:people/by-id :db/id]}
(dom/div :.form-horizontal
(field-with-label this props :person/name "Full Name:" "Please enter your first and last name.")
(field-with-label this props :person/age "Age:" "That isn't a real age!")
(checkbox-with-label this props :person/registered-to-vote? "Registered?")
(when (f/current-value props :person/registered-to-vote?)
(dom/div "Good on you!"))
(dom/div
(mapv ui-vphone-form phone-numbers))
(when (f/valid? props)
(dom/div "All fields have had been validated, and are valid"))
(dom/div :.button-group
(dom/button :.btn.btn-primary {:onClick #(prim/transact! this
`[(add-phone ~{:id (prim/tempid)
:person (:db/id props)})])}
"Add Phone")
(dom/button :.btn.btn-default {:disabled (f/valid? props) :onClick #(f/validate-entire-form! this props)}
"Validate")
(dom/button :.btn.btn-default {, :disabled (not (f/dirty? props)) :onClick #(f/reset-from-entity! this props)}
"UNDO")
(dom/button :.btn.btn-default {:disabled (not (f/dirty? props)) :onClick #(f/commit-to-entity! this)}
"Submit"))))
(def ui-person-form (prim/factory PersonForm))
(defsc Root [this {:keys [person]}]
{:initial-state (fn [params]
{:ui/person-id 1
:person (prim/get-initial-state PersonForm
{:db/id 1
:person/name "Tony Kay"
:person/age 23
:person/registered-to-vote? false
:person/phone-numbers [(prim/get-initial-state ValidatedPhoneForm
{:db/id 22
:phone/type :work
:phone/number "(123) 412-1212"})
(prim/get-initial-state ValidatedPhoneForm
{:db/id 23
:phone/type :home
:phone/number "(541) 555-1212"})]})})
:query [:ui/person-id {:person (prim/get-query PersonForm)}]}
(dom/div
(when person
(ui-person-form person))))The elements of this demo are discussed in the following sections.
17.8.2. Composition and Rendering Refresh
The one caveat is that when forms are nested the mutations on the nested fields cannot (due to the design of Fulcro) refresh
the parent automatically. To work around this, all built-in form mutations will trigger follow-on reads of
the special property f/form-root-key. So, if you add that to your parent form’s query, rendering of the top-level
form elements (e.g. buttons that control submission) will properly update when any element of a subform changes.
17.8.3. Adding Sub-form Elements
Adding a phone number (which acts as a sub-form) is done via the add-phone mutation, which looks like this:
(defmutation add-phone [{:keys [id person]}]
(action [{:keys [state]}]
(let [new-phone (f/build-form ValidatedPhoneForm {:db/id id :phone/type :home :phone/number " "})
person-ident [:people/by-id person]
phone-ident (prim/ident ValidatedPhoneForm new-phone)]
(swap! state assoc-in phone-ident new-phone)
(m/integrate-ident* state phone-ident :append (conj person-ident :person/phone-numbers)))))Notice that there is nothing really special going on here. Just add an additional item to the database (which is
augmented with f/build-form) and integrate its ident!
For example, the button to run a transaction to add a phone number to a person creates a tempid for the phone number and passes it as a parameter in the transaction:
(dom/button {:onClick #(prim/transact! this `[(add-phone ~{:id (prim/tempid) ...})])}
"Add Phone")17.8.4. Compositional Dirty-Checking, Validation, and Submission
The code also shows how you would compose the checks. The dirty? function combines the results of the nested forms
together with the top form. You could do the same for validations.
The save button in the example above does a similar thing: it submits the phone numbers, and then the top. Note that Fulcro combines mutations that happen in the same thread sequence (e.g. you have not given up the thread for rendering). So, all of those commits will be sent to the server as a single transaction (if you include the remote parameter).
17.9. Adding Form Field Types
Adding a new kind of form field is simple:
-
Create a method that returns a map of input configuration values
-
Add a multimethod that can render your field with appropriate hooks into the logic
The built-in text input field is implemented like this:
(defn text-input
"Declare a text input on a form. The allowed options are named parameters:
:className nm Additional CSS classnames to include on the input (as a string)
:validator sym A symbol to target the dispatch of validation
:validator-args Arguments that will be passed to the validator
:placeholder The input placeholder. Supports a lambda or string
:default-value A value to use in the field if the app-state value is nil
:validate-on-blur? Should the field be validated on a blur event (default = true)
"
[name & {:keys [validator validator-args className default-value placeholder validate-on-blur?]
:or {placeholder "" default-value "" className "" validate-on-blur? true}}]
(cond-> {:input/name name
:input/default-value default-value
:input/placeholder placeholder
:input/css-class className
:input/validate-on-blur? validate-on-blur?
:input/type ::text}
validator (assoc :input/validator validator)
validator-args (assoc :input/validator-args validator-args)))The keys in an input’s configuration are:
-
:input/name: Required. What you want to call the field. Must match an entity property (e.g. :person/name). -
:input/type: Required. Usually namespaced. This should be a unique key that indicates what kind of input you’re making -
:input/validator: Optional. Specifies a symbol (dispatch of the form-field-valid? multimethod). -
:input/validator-args: Optional. If there is a validator, it is called with the validator symbol, the questionable value, and these args. -
Any additional keys you want to define : The representation of an input is just a map. Put whatever else you want in this map to help with rendering (e.g. placeholder text, class names, style, etc).
and its renderer looks like this:
(defn- render-input-field [component htmlProps form field-name type
field-value->input-value
input-value->field-value]
(let [id (form-ident form)
input-value (field-value->input-value (current-value form field-name))
input-value (if (nil? input-value) "" input-value)
attrs (clj->js (merge htmlProps
{:type type
:name field-name
:value input-value
:placeholder (placeholder form field-name)
:onBlur (fn [_]
(prim/transact! component
`[(validate-field
~{:form-id id :field field-name})
~@(get-on-form-change-mutation form field-name :blur)
~form-root-key]))
:onChange (fn [event]
(let [value (input-value->field-value (.. event -target -value))
field-info {:form-id id
:field field-name
:value value}]
(prim/transact! component
`[(set-field ~field-info)
~@(get-on-form-change-mutation form field-name :edit)
~form-root-key])))}))]
(dom/input attrs)))
(def allowed-input-dom-props #{:id :className :onKeyDown :onKeyPress :onKeyUp :ref :alt :accept :align :autocomplete
:autofocus :dirname :disabled :height :max :min :maxLength :pattern
:name :size :step :width})
(defmethod form-field* ::text [component form field-name & {:keys [id className] :as params}]
(let [i->f identity
cls (or className (css-class form field-name) "form-control")
params (assoc params :className cls)
f->i identity]
(render-input-field component (select-keys params allowed-input-dom-props) form field-name "text" f->i i->f)))You can retrieve a field’s current form value with (f/current-value form field-name), and you can obtain
your field’s configuration (map of :input/??? values) with (f/field-config form field-name).
The form-field* multimethod should, in general, return as little as possible, but you are allowed to do whatever you want.
You are free to make form field renderers that render much more complex DOM, an SVG, etc.
The following built-in mutations can (and should) be used in your event handlers:
-
(fulcro.ui.form/validate-field {:form-id [:ident/by-x n] :field :field-name})- Run validation on the given form/field. Marks the form state for the field to:invalidor:valid. Fields without validators will be marked:valid. -
(fulcro.ui.form/set-field {:form-id [:ident/by-x n] :field :field-name :value raw-value})- Set the raw-value (you can use any type) onto the form’s placeholder state (not on the entity) -
Others listed elsewhere, like those that commit, validate, etc.
17.10. Other Functions of Interest
Since the form is also your entity, you may of course pull any entity data from the form map. (E.g. you can
for example directly access (:person/name person-form)). The form attributes are stored under the f/form-key key
and are intended to be opaque. Do not sneak access into the data structure, since we may choose to change the structure
in future versions. Instead, use these:
-
f/current-value: Get the most recent value of a field from a form -
f/current-validity: Get the most recent result of validation on a field -
f/valid?: Test if the form (or a field) is currently marked valid (must run validation separately) -
f/invalid?: Test if the form (or a field) is currently marked invalid (must run validation separately) -
f/field-names: Get the field names on a form -
f/form-id: returns the Ident of the form (which is also the ident of the entity) -
f/validate-fields: returns a new version of the form with the fields marked with validation. Pure function. -
f/validate-entire-form!: Transacts a mutation that runs and sets validation markers on the form (which will update UI)
17.11. Form State and Lifecycle
Form support is meant to track the state of one or more entities throughout the process of editing. It is important to remember the general model of Fulcro is one where the application moves from state to state over time, and the components themselves have (ideally) no local state.
This means that your form will not change states unless a mutation of some sort runs.
Many of the form fields do run mutations on events, which in turn change the state of the form or the fields.
A form can have any number of child forms (which themselves can dynamically change over time).
The lifecycle is as follows:
Regular Persisted Entity
|
| build-form
v
Pristine Form <------------+
| |
| edits/additions ^
v /|
Dirty Form -------------/ |
reset/commit> +------+
|
Locally Created (tempid) |
| |
| build-form |
v | (server tempid remap)
Dirty Form |
^ | _|_
| | edits/additions/reset/commit
+----+A form need not be full stack, but if it is then server interactions would typically occur when you transition from a dirty form to a pristine one due to a commit.
You are responsible for coding the transactions to ensure that your concept of a pristine vs. dirty form are consistent in a distributed sense. The default behavior for the full-stack commit is to optimistically mark the client form pristine and submit the data to the server. See pessimistic transactions for details on how to do blocking server interactions.
17.11.1. Is my Form Dirty?
A form is considered dirty? when:
-
Any field of the form or its declared subforms has a value different from the initial (or most recently committed) value.
-
Any form or subform in a set has a tempid (e.g. server remaps have not yet taken effect)
|
Note
|
If you’re writing forms on a UI that has no server interaction then you will probably want to generate your own numeric unique IDs for any new entities to prevent permanently dirty forms. |
17.12. Is my Form/Field Valid?
Form fields that support validation will typically run validation on the field when that
field is manipulated. Full-form validation can be done at any time by composing validate-fields
into your own mutation (see also on-form-change). The system is fully flexible, and for the
most part validation is composable, extensible, configurable, and happens at transaction
boundaries in whatever ways you define.
Validation is tri-state. All fields start out :unchecked. If you wish your form to start out
:valid then you can compose a call to f/valiate-fields:
;; NOTE: non-recursive validation. You'd have to use this explicitly on each declared subform state as well.
(let [initial-form (f/validate-fields (f/build-form MyForm my-entity-props))
...The functions valid? and invalid? honor the tri-state nature of forms (e.g. invalid? returns
true if and only if at least one field is :invalid, and valid? returns true if and only if all fields are
:valid). The :unchecked state thus allows you to prevent error messages from
appearing on fields until you’re actually ready to validate them:
;; only emits if the field is actually marked :invalid (not :unchecked)
(when (invalid? this-form :field) (dom/span "Invalid!"))
;; Disables submit button unless all fields are marked `:valid` (none are :unchecked or :invalid)
(dom/button {:disabled (not (valid? form)) :onClick submit} "Submit!")The tricky part is that global validation is never triggered by built-in field interaction because that would not allow you to control your form UI very well (e.g. fields might show validation errors when the user hasn’t even interacted with them yet).
Thus, you have a few ways of dealing with validation checking:
-
Trigger a
f/validate-formmutation. Such a mutation will recursively walk your form and subforms and mark all fields with:invalidor:valid. This will have the effect of showing validation messages that are defined in the examples above. -
Compose the
f/validate-formshelper function into your own mutation. This function works against an app state map and recursively updates a form/subforms. (see the source fordefmutation validate-form) -
Use the
would-be-valid?function on the forms props (e.g. in the UI). This function returns true if the supplied form (and subforms) would be valid if validation was run on it. It essentially runs validation in a pure functional way.
If using (1) or (2), then the methods valid? and invalid? can recursively test the validity. Note that
as fields are changed the state of those fields may return to unchecked (which is neither valid or invalid).
17.13. Server Integration
A form (and associated subforms) have support for saving state to the server. This support takes the best view it possibly can of the possible things a user can do to an entity via a form:
A user should be able to:
-
Change the value of one or more fields.
-
Add a completely new entity (with tempid) to the database (e.g. new form or new subform)
-
Link an existing form to an instance of a subform. The subform might have been looked up (by your code) or created (via 2).
-
Remove the linkage from a form to a subform.
17.13.1. Handling Submission of a Form
Form submission has some general helpers. In general, it is recommended that you write your own custom mutation to do a form submission, but there is a general-purpose mutation that can also do it for you.
The advantage of using the general-purpose mutation is that it is already written, but the disadvantage is that all of your form submissions become centralized into a single point of entry in the server and more significantly become difficult to distinguish from each other in the actual transaction logs.
Thus, when getting started you might choose to play with the built-in mechanism, but as you progress we highly recommend you customize form submission, which is actually quite simple to do.
Built-in Form Submisssion – commit-to-entity
A form submission can be done via the commit-to-entity function/mutation with the inclusion
of a :remote flag. The function version commit-to-entity! is a simple wrapper of a
transact! that invokes the f/commit-to-entity mutation (where f is the forms namespace).
The former is a convenience, and the latter is more useful when you want to compose commit with
other transaction actions (such as navigation away from the form).
The wrapper function must be called using the this of the component that is the top-level of the form,
and the mutation must be called with the props of the top-level form.
Both default to a local commit (where you can deal with persistence in some other way), but if you supply them with a remote argument they will send the changes to the data in the form to the server. Of course, new entities will be completely sent.
Of course to handle this mutation you must implement a server-side mutation with the fully-namespaces
fulcro.ui.forms/commit-to-entity name.
Custom Form Submission
Custom form submission allows you to do a number of custom things:
-
Choose optimistic or response-driven form submission.
-
Combine submission with other form checking logic and UI updates.
-
Name your submit mutation so that you can easily keep them separate.
The primary utility functions in fulcro.ui.forms for implementing such mutations are:
-
(f/diff-form form-root-props): This function calculates a diff of the form (and subforms). Only new and changed data will be included (see later sections). You must pass this function the tree version of a form (e.g. pass the form-props as an arg to the mutation). It is important to calculate the diff outside of the mutation, because of the multi-pass nature of mutation bodies (e.g. you’ll need the delta in remote, but action may have already done an optimistic local commit). -
(f/entity-xform state-map ident f)Recursively walks a form set starting atidentinstate-maprunningfon each (sub)form. -
(f/commit-state form-props): This is a non-recursive function that copies form data from the edited area to the pristine area locally. Typically called as(swap! state f/entity-xform form-ident commit-state). (which must be sent from the UI invocation of transact as a parameter or reconstituted as a tree withdb→tree). It copies the new state to the pristine state, making the form appear complete and clean (submitted) on the client. -
(f/reset-entity form-props): The opposite ofcommit-state, but called viaentity-xformas well. -
(f/would-be-valid form-props): Requires a tree of form props (e.g. from the UI ordb→tree). Returns true if the given form would be considered valid if a validation mutation were run on it. Useful in form submission logic where pushing validation data to the UI can be bypassed because you can tell it is OK. -
(f/dirty? form-props): Requires tree of props (from UI). Returns true if the form has changes (needs a submit) -
(f/validate-forms state-map form-ident): Used from within mutations. Causes form validation mutation on the recursive form, which will cause UI updates. Use this if you decide not to submit the form and want to show why on the UI.
Notice that a lot of these functions are meant to be usable at the UI (they work on a tree of form props). The reason there are not two versions is that because of optimistic updates and how mutations work, it is advisable to pass your form’s tree of props through to the mutation, so that your mutation closes over the form state at the time of user interaction. This allows you to properly calculate your form delta and have a consistent snapshot for the remote interaction.
It is useful to study the code of the built-in commit, and mimic parts of the behavior for your own mutations:
The commit-to-entity! function calls transact, but note how it pulls props and constructs the mutation to
include that tree. It also triggers validation, to ensure that the UI shows updated validation messages (clearing
errors or adding new ones). It also includes the f/form-root-key to ensure the entire form set will re-render:
(defn commit-to-entity!
[component & {:keys [remote rerender fallback fallback-params] :or {fallback-params {} remote false}}]
(let [form (prim/props component)
fallback-call (list `df/fallback (merge fallback-params {:action fallback}))]
(let [is-valid? (valid? (validate-fields form))
tx (cond-> []
is-valid? (conj `(commit-to-entity ~{:form form :remote remote}))
(and is-valid? (symbol? fallback)) (conj fallback-call)
(not is-valid?) (conj `(validate-form ~{:form-id (form-ident form)}))
(seq rerender) (into rerender)
:always (conj form-root-key))]
(prim/transact! component tx))))The mutation itself now has all of the data it needs to calculate a diff and such. Here is its implementation:
(defmutation commit-to-entity
[{:keys [form remote]}]
(action [{:keys [state]}] (swap! state entity-xform (form-ident form) commit-state))
(remote [{:keys [state ast target]}]
(when (and remote target)
(assoc ast :params (diff-form form)))))Note that the local optimistic update just copies the edited state over top of the pristine (this mutation isn’t run if the form doesn’t validate…see the earlier function).
The remote side modified the parameters so that instead of sending the form’s UI tree to the server, it instead sends a calculated diff. See below for how to deal with this diff.
17.13.2. What Your Server Must Do
On the server, you must provide a mutation handler for your mutation or the f/commit-to-entity symbol.
If you’re using multimethods on the server, this might look like:
(ns amazing-server.mutations
(:require
[fulcro.server :as server]))
(server/defmutation fulcro.ui.forms/commit-to-entity [params]
(action [env] ...))The complete form delta will be in the incoming params. The description of the entries in params
is below.
Processing a Form’s Diff
The incoming parameters is a map. This map will contain up to four different keys to indicate what changed on the client.
Form Field Updates
Field updates are sent under the following conditions:
-
The entity of the form has a real id (not a temp id)
-
One or more fields have values different from those at the time of
build-formor the last commit.
The parameters sent to the commit-to-entity mutation on the server will include the key
:form/updates whose value will be a map. The map’s keys will be client-side idents of
the entities that changed, and the values will be maps of k-v pairs of the data the changed.
Examples:
{:form/updates { [:thing 1] {:field-a 1 }
[:thing 2] {:field-b 55 }}}NOTES:
-
Updates will never include referential updates (e.g. A references subform element B). See New Relations and Removed Relations below.
-
Fields on the entity in the UI that are not declared as form fields will never appear in an update.
New Entities
When a form (and/or subforms) is submitted that has a primary ID whose value is a tempid then
the incoming commit parameters will include the :form/new-entities key. The value of this entry is just like
that of :form/updates, but the ID in the ident will be a tempid (which you must send remaps
back for), and the map of data will include all attributes of that entity that were declared as part
of the form.
{:form/new-entities { [:thing tempid-1] {:field-a 1 :field-b 55 }
[:thing tempid-2] {:field-a 8 :field-b 42 }}}It is important that you remember to return a map to remap the incoming tempids:
(defmethod my-mutate `f/commit-to-entity [env k params]
{:action (fn []
...
{:tempids {tempid-1 realid-1 tempid-2 realid-2}})})Some additional notes:
-
New entity properties include only the columns declared in the form support. Remember that you can declare fields without rendering them.
-
New entity entries do not include references! Any reference changes are always expressed with linkage change entries, as described below.
New Relations
If a subform is explicitly declared, then new linkage between a form and the subforms will
be expressed via the :form/add-relations entry. The value will be a map whose keys are idents of the
referring object and whose values are a single ident (in the to-one case) or vectors of the idents (in the to-many
case) of the new targets. This is a delta. This is
not meant to be interpreted as all of them, just the ones that were added since the form was considered
clean.
Examples:
Two different to-one relationship additions:
{:form/add-relations { [:thing tempid-1] {:thing/child [:thing tempid-2] }
[:thing tempid-2] {:thing/parent [:thing tempid-1] }}}A to-many parent-child relationship with two new children:
{:form/add-relations { [:people/by-id 1] {:person/number [[:phone/by-id 2] [:phone/by-id 3]] }}}Removed Relations
If a subform is explicitly declared, then removal of linkage between a form and the subforms will
be expressed via the :form/remove-relations entry. The value will be a map whose keys are idents of the
referring object and whose values are just like in the new linkage. This is also a delta.
Examples:
Removal of a to-one relation:
{:form/remove-relations { [:thing 1] {:thing/child [:thing 2] }}}Removal of a single child in a to-many relation:
{:form/remove-relations { [:people/by-id 1] {:person/number [[:phone/by-id 3]] }}}17.13.3. Updating a forms-based Entity From the Server
Since your app state is normalized, any reads of an entity will end up being merged over top of the entity you already have. This means that your active form fields on such an entity would update.
There are some caveats to doing this, since the remembered state of your form will now be out of sync with what you read (or pushed) from the server.
Typically what you’ll want to do when (re)reading an entity that is being actively used on a form is:
-
Issue a Fulcro load for that entity. The incoming state will cause the UI of the form to update (since you’re always editing/rendering active state of the entity). Unfortunately, the pristine state of the form now thinks the newly loaded entity is dirty!
-
Include a post mutation, which should:
-
dissocthe form state via(update-in app-state form-ident dissoc f/form-key) -
Run
build-formon the form -
Optionally use the
validate-fieldsorvalidate-formsfunction to update the validation markers.
-
A non-remote (local-only) commit-to-entity (still as a post-mutation) could also be used to accomplish (2).
17.14. Forms – Whole Form Logic
Many forms need logic that updates the UI in some non-local way as form interactions take place. Simple field validations can be local to a field, but some UI changes require whole-form reasoning or cross-field interactions.
Some simple examples:
-
Verification fields (two fields must contain the same data to ensure they typed it correctly)
-
Triggering a server-side check of a value (e.g. is that username in use?)
-
Making other UI elements appear/disappear according to field changes
We accomplish these things in the form support by allowing you to declare an entry in your
IForm list that names a Fulcro mutation to run as changes are detected in the form/subform
set.
The mutation given is just a normal mutation that can do anything you need done: remoting, global reasoning, etc.
Only one (the last if more than one) on-form-change can be declared on a form. Use other composition
techniques to make a single mutation if you’d like multiple operations on the form change.
(defsc Person [this props]
{:initial-state [params] (fn [params] (f/build-form this (or params {})))
:form-fields [(f/id-field :db/id)
(f/on-form-change `check-username-available)
(f/text-input :person/name)
(f/integer-input :person/age)]}
...17.14.1. The Events
The form change support can send events on change and on blur. The latter is useful for regular input fields (as opposed to checkboxes, for example). Your mutation will be passed parameters as a map that has:
:form-id-
The ident of the form that generated the event
:kind-
Either :blur or :edit
:field-
The name of the field affected
Your mutation can do anything a normal mutation can do.
17.14.2. An Example
In this example, we’ll use remoting to ask the server (on field blur) if a given username is already in use (in our code, 'sam' and 'tony' are taken). The client-side mutation looks like this:
(defmutation check-username-available
[{:keys [form-id kind field]}]
(action [{:keys [state] :as env}]
(when (and (= kind :blur) (= :person/name field)) ; only do things on blur
(let [value (get-in @state (conj form-id field))] ; get the value of the field
(swap! state assoc-in (conj form-id :ui/name-status) :checking) ; set a UI state to show progress
(df/load-action env :name-in-use nil {:target (conj form-id :ui/name-status) ; trigger a remote load
:refresh [f/form-root-key] ; ensure the forms re-render
:params {:name value}})))) ; include params on the query
(remote [env] (df/remote-load env))) ; trigger eval of network queue to see if there is anything remote to doand a server-side query function would satisfy the :name-in-use query with something like this
(users is just a set of existing usernames in our sample code):
(def users #{"tony" "sam"})
(defquery-root :name-in-use
(value [env [{:keys [name]}]]
(if (contains? users name) :duplicate :ok)))Now, the sequence of interactions is as follows:
-
The user blurs on the username field (we could also debounce edit events)
-
The mutation places a marker in the app state that allows the UI to show the 'checking' message
-
The mutation causes a remote query targeted to the marker location
-
When the server query completes, it overwrites the marker from (2) with the server response
The main catch is the :refresh argument to the load-action. This ensures that the form gets
re-rendered when the request completes. Of course, this could have just as easily been any keyword
queried by Person.
The general Person form UI looks like this:
(defsc Person [this {:keys [ui/name-status] :as props}]
{:initial-state (fn [params] (f/build-form this (or params {})))
:query [f/form-root-key f/form-key :db/id :person/name :person/age :ui/name-status]
:ident [:person/by-id :db/id]
:form-fields [(f/id-field :db/id)
(f/on-form-change `check-username-available)
(f/text-input :person/name)
(f/integer-input :person/age)]}
(dom/div :.form-horizontal
(field-with-label this props :person/name "Username:"
(case name-status
:duplicate (b/alert {:kind :warning}
"That username is in use." (i/icon :error))
:checking (b/alert {:color :neutral}
"Checking if that username is in use...")
:ok (b/alert {:color :success} "OK" (i/icon :check))
""))
(field-with-label this props :person/age "Age:")
(dom/div :.button-group
(dom/button :.btn.btn-default { :disabled (not (f/dirty? props)) :onClick #(f/commit-to-entity! this :remote true)}
"Save!"))))Note, in particular, that the query includes :ui/name-status and rendering code for the possible
values of status. The UI is completely disconnected from the fact that remoting is being used
to verify the username.
The complete running example with source is below.
(ns book.forms.whole-form-logic
(:require
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.server :refer [defquery-root]]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.ui.icons :as i]
[fulcro.ui.forms :as f]
[fulcro.client.data-fetch :as df]
[fulcro.ui.bootstrap3 :as b]))
;; SERVER
(def users #{"tony" "sam"})
(defquery-root :name-in-use
(value [env {:keys [name]}]
(if (contains? users name) :duplicate :ok)))
;; CLIENT
(defn field-with-label
"A non-library helper function, written by you to help lay out your form."
([comp form name label] (field-with-label comp form name label nil))
([comp form name label validation-message]
(dom/div :.form-group {:className (when (f/invalid? form name) "has-error")}
(dom/label :.col-sm-2 {:htmlFor name} label)
(dom/div :.col-sm-10 (f/form-field comp form name))
(when validation-message
(dom/div :.col-sm-offset-2.col-sm-10 {:className (str name)} validation-message)))))
(defmutation check-username-available
"Sample mutation that simulates legal username check"
[{:keys [form-id kind field]}]
(action [{:keys [state] :as env}]
(when (and (= kind :blur) (= :person/name field))
(let [value (get-in @state (conj form-id field))]
; Set the UI to let them know we're checking...
(swap! state assoc-in (conj form-id :ui/name-status) :checking)
; Send a query to the server to see if it is in use
(df/load-action env :name-in-use nil {:target (conj form-id :ui/name-status)
:refresh [f/form-root-key]
:marker false
:params {:name value}}))))
(remote [env] (df/remote-load env)))
(defsc Person [this {:keys [ui/name-status] :as props}]
{:initial-state (fn [params] (f/build-form this (or params {})))
:query [f/form-root-key f/form-key :db/id :person/name :person/age :ui/name-status]
:ident [:person/by-id :db/id]
:form-fields [(f/id-field :db/id)
(f/on-form-change `check-username-available)
(f/text-input :person/name)
(f/integer-input :person/age)]}
(dom/div :.form-horizontal
(field-with-label this props :person/name "Username:"
(case name-status
:duplicate (b/alert {:kind :warning}
"That username is in use." (i/icon :error))
:checking (b/alert {:color :neutral}
"Checking if that username is in use...")
:ok (b/alert {:color :success} "OK" (i/icon :check))
""))
(field-with-label this props :person/age "Age:")
(dom/div :.button-group
(dom/button :.btn.btn-default {:disabled (not (f/dirty? props)) :onClick #(f/commit-to-entity! this :remote true)}
"Save!"))))
(def ui-person (prim/factory Person {:keyfn :db/id}))
(defsc Root [this {:keys [person]}]
{:initial-state (fn [_] {:person (prim/get-initial-state Person {:db/id 1})})
:query [{:person (prim/get-query Person)}]}
(dom/div
(ui-person person)))17.15. Full Stack Form Demo
In this demo we’re still using a simulated server. We’re also using browser local storage to make sure the changes you make look like they get persisted, so you should see your edited data on page reloads.
17.15.1. Application Load
When the application loads it uses data-fetch/load to query the server for
:all-numbers.
(df/load app :all-numbers PhoneDisplayRow {:target [:screen/phone-list :tab :phone-numbers]})We have a very simple database that looks like this on the server:
(defn make-phone-number [id type num]
{:db/id id :phone/type type :phone/number num})
(defonce server-state (atom {:all-numbers [(make-phone-number 1 :home "555-1212")
(make-phone-number 2 :home "555-1213")
(make-phone-number 3 :home "555-1214")
(make-phone-number 4 :home "555-1215")]}))The server query handler is just:
(defquery-root :all-numbers
(value [env params]
{:value (get @server-state :all-numbers)} ))17.15.2. The UI
We’re using a UI router via defsc-router to create two screens: A phone list and phone editor screen.
The basic UI tree looks like this:
Root
|
TopLevelRouter
/ \\
PhoneEditor PhoneList
| / | \\
PhoneForm PhoneDisplayRow...The UI starts out showing PhoneList. Clicking on an element leads to editing.
17.15.3. The Mutations
Note: PhoneForm and PhoneDisplayRow share the same ident since they render two differing views of the same entity in our database.
Editing
Since the phone numbers were loaded from raw data on a server, they are not form capable yet.
Thus, the application must do a few things in order for editing to work:
-
It must add form state to the entity using
build-form. We create a quick helper function to do this against app state (the functionphone-identjust returns the ident of a phone number based on the simple ID):(defn- initialize-form [state-map form-class form-ident] (update-in state-map form-ident #(f/build-form form-class %))) -
The form itself needs to link up to the thing it should edit. In order words we need to write an ident into PhoneEditor to point it to the (newly initialized) PhoneForm instance. We write another helper to do this against app state (as a map). Note the path is just the ident of the PhoneEditor combined with the field name.
(defn- set-number-to-edit [state-map phone-id] (assoc-in state-map [:screen/phone-editor :tab :number-to-edit] (phone-ident phone-id))) -
Tell the top UI router to change UI routes. We can do this with the built-in
route-tomutation. -
Indicate what data changed. We can do this with a follow-on read at the call site, or just declare the refresh list in the mutation.
Our final edit-phone mutation is thus:
(defmutation edit-phone
[{:keys [id]}]
(action [{:keys [state]}]
(swap! state (fn [state-map]
(-> state-map
(initialize-form PhoneForm (phone-ident id))
(set-number-to-edit id)
(r/update-routing-links {:route-params {}
:handler :route/phone-editor})))))
(refresh [env] [:main-ui-router]))17.15.4. Commit and Reset
Commit and reset are a built-in mutations. They both have a function and mutation-composable version (the former just calls transact for you). Often you’ll want to combine other operations with a commit or reset, as is shown in the form editor.
The Save button runs a commit operation with a remote flag. This causes the changes to not only be sync’d with the form’s pristine state, it also causes a network (in this case simulated) request to have the server update its copy.
See the form diff section for the full possible items in such a request. For this example we’ll describe just the one we’re supporting: Updates.
The parameters passed to the server on update have
a :form/updates key with a map whose keys are the idents of things that changed, and whose values are maps
of the field/value updates. For example:
{:form/updates {[:phone/by-id 1] {:phone/number "444-5421"}}}would be sent to indicate that phone number with id 1 had just its :phone/number attribute changed to the
new value "444-5421".
So, a really naive implementation of this update handler looks like this:
(defn update-phone-number [id incoming-changes]
(log/info "Server asked to updated phone " id " with changes: " incoming-changes)
(swap! server-state update-in [:all-numbers (dec id)] merge incoming-changes)
;; simulate saving to "disk"
(.setItem js/localStorage "/" (pr-str @server-state)))The server commit handler is pretty simple as well:
(server/defmutation fulcro.ui.forms/commit-to-entity [p]
(action [env]
(let [updates (-> p :form/updates)]
(doseq [[[table id] changes] updates]
(case table
:phone/by-id (update-phone-number id changes)
(log/info "Server asked to update unknown entity " table)))) ) )You can see the full source and play with the demo below:
(ns book.forms.full-stack-forms-demo
(:require
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[fulcro.client.routing :as r :refer [defrouter]]
[fulcro.client.mutations :as m :refer [defmutation]]
[fulcro.logging :as log]
[fulcro.ui.forms :as f]
[fulcro.client.data-fetch :as df]
[cljs.reader :refer [read-string]]
[fulcro.ui.bootstrap3 :as b]
[fulcro.server :as server :refer [defquery-entity defquery-root]]
[fulcro.ui.elements :as ele]))
(defn render-example [width height & children]
(ele/ui-iframe {:frameBorder 0 :height height :width width}
(apply dom/div {:key "example-frame-key"}
(dom/style ".boxed {border: 1px solid black}")
(dom/link {:rel "stylesheet" :href "bootstrap-3.3.7/css/bootstrap.min.css"})
children)))
(defn make-phone-number [id type num]
{:db/id id :phone/type type :phone/number num})
(defonce server-state (atom {:all-numbers [(make-phone-number 1 :home "555-1212")
(make-phone-number 2 :home "555-1213")
(make-phone-number 3 :home "555-1214")
(make-phone-number 4 :home "555-1215")]}))
; simulate persisting the data across page reloads
(let [old-state (read-string (str (.getItem js/localStorage "/")))]
(when (map? old-state)
(reset! server-state old-state)))
(defn update-phone-number [id incoming-changes]
(log/info "Server asked to updated phone " id " with changes: " incoming-changes)
(swap! server-state update-in [:all-numbers (dec id)] merge incoming-changes)
;; simulate saving to "disk"
(.setItem js/localStorage "/" (pr-str @server-state)))
(defquery-root :all-numbers
(value [env params]
(js/console.log "query")
(get @server-state :all-numbers)))
(server/defmutation fulcro.ui.forms/commit-to-entity [p]
(action [env]
(let [updates (-> p :form/updates)]
(doseq [[[table id] changes] updates]
(case table
:phone/by-id (update-phone-number id changes)
(log/info "Server asked to update unknown entity " table))))))
(defn field-with-label
"A non-library helper function, written by you to help lay out your form."
([comp form name label] (field-with-label comp form name label nil))
([comp form name label validation-message]
(dom/div :.form-group {:className (when (f/invalid? form name) " has-error")}
(dom/label :.col-sm-2 {:htmlFor name} label)
;; THE LIBRARY SUPPLIES f/form-field. Use it to render the actual field
(dom/div :.col-sm-10 (f/form-field comp form name))
(when (and validation-message (f/invalid? form name))
(dom/span :.col-sm-offset-2.col-sm-10 {:className (str name)} validation-message)))))
(defn phone-ident [id-or-props]
(if (map? id-or-props)
[:phone/by-id (:db/id id-or-props)]
[:phone/by-id id-or-props]))
(defsc PhoneForm [this form]
{:query [:db/id :phone/type :phone/number f/form-key]
:ident (fn [] (phone-ident form))
:form-fields [(f/id-field :db/id)
(f/text-input :phone/number)
(f/dropdown-input :phone/type [(f/option :home "Home") (f/option :work "Work")])]}
(dom/div :.form-horizontal
; field-with-label is just a render-helper as covered in basic form documentation
(field-with-label this form :phone/type "Phone type:")
(field-with-label this form :phone/number "Number:")))
(def ui-phone-form (prim/factory PhoneForm))
(defn- set-number-to-edit [state-map phone-id]
(assoc-in state-map [:screen/phone-editor :tab :number-to-edit] (phone-ident phone-id)))
(defn- initialize-form [state-map form-class form-ident]
(update-in state-map form-ident #(f/build-form form-class %)))
(defmutation edit-phone
"Mutation: Set up the given phone number to be editable in the
phone form, and route the UI to the form."
[{:keys [id]}]
(action [{:keys [state]}]
(swap! state (fn [state-map]
(-> state-map
(initialize-form PhoneForm (phone-ident id))
(set-number-to-edit id)
(r/update-routing-links {:route-params {}
:handler :route/phone-editor})))))
(refresh [env] [:main-ui-router]))
(defsc PhoneDisplayRow [this {:keys [db/id phone/type phone/number]}]
{:query [:ui/fetch-state :db/id :phone/type :phone/number]
:ident (fn [] (phone-ident id))}
(b/row {:onClick #(prim/transact! this `[(edit-phone {:id ~id})])}
(b/col {:xs 2} (name type)) (b/col {:xs 2} number)))
(def ui-phone-row (prim/factory PhoneDisplayRow {:keyfn :db/id}))
(defsc PhoneEditor [this {:keys [number-to-edit]}]
{; make sure to include the :screen-type so the router can get the ident of this component
:initial-state {:screen-type :screen/phone-editor}
:ident (fn [] [:screen/phone-editor :tab])
; NOTE: the query is asking for :number-to-edit.
; The edit mutation will fill this in before routing here.
:query [f/form-root-key :screen-type {:number-to-edit (prim/get-query PhoneForm)}]}
(let [; dirty check is recursive and always up-to-date
not-dirty? (not (f/dirty? number-to-edit))
; validation is tri-state. Most fields are unchecked. Use pure functions to
; transform the form to a validated state to check validity of all fields
valid? (f/valid? (f/validate-fields number-to-edit))
not-valid? (not valid?)
save (fn [evt]
(when valid?
(prim/transact! this
`[(f/commit-to-entity {:form ~number-to-edit :remote true})
(r/route-to {:handler :route/phone-list})
; ROUTING HAPPENS ELSEWHERE, make sure the UI for that router updates
:main-ui-router])))
cancel-edit (fn [evt]
(prim/transact! this
`[(f/reset-from-entity {:form-id ~(phone-ident (:db/id number-to-edit))})
(r/route-to {:handler :route/phone-list})
; ROUTING HAPPENS ELSEWHERE, make sure the UI for that router updates
:main-ui-router]))]
(dom/div
(dom/h1 "Edit Phone Number")
(when number-to-edit
(ui-phone-form number-to-edit))
(b/row {}
(b/button {:onClick cancel-edit} "Cancel")
(b/button {:disabled (or not-valid? not-dirty?)
:onClick save} "Save")))))
(defsc PhoneList [this {:keys [phone-numbers]}]
{:query [:screen-type {:phone-numbers (prim/get-query PhoneDisplayRow)}]
:ident (fn [] [:screen/phone-list :tab])
; make sure to include the :screen-type so the router can get the ident of this component
:initial-state {:screen-type :screen/phone-list
:phone-numbers []}}
(dom/div
(dom/h1 "Phone Numbers (click a row to edit)")
(b/container nil
(b/row {} (b/col {:xs 2} "Phone Type") (b/col {:xs 2} "Phone Number"))
; Show a loading message while we're waiting for the network load
(df/lazily-loaded #(mapv ui-phone-row %) phone-numbers))))
(defrouter TopLevelRouter :top-router
; Note the ident function works against the router children,
; so they must have a :screen-type data field
(ident [this props] [(:screen-type props) :tab])
:screen/phone-list PhoneList
:screen/phone-editor PhoneEditor)
(def ui-top-router (prim/factory TopLevelRouter))
(defsc Root [this {:keys [main-ui-router]}]
{:query [{:main-ui-router (prim/get-query TopLevelRouter)}]
:initial-state (fn [params]
; merge the routing tree into the app state
(merge
{:main-ui-router (prim/get-initial-state TopLevelRouter {})}
(r/routing-tree
(r/make-route :route/phone-list
[(r/router-instruction :top-router [:screen/phone-list :tab])])
(r/make-route :route/phone-editor
[(r/router-instruction :top-router [:screen/phone-editor :tab])]))))}
(render-example "600px" "300px"
(b/container-fluid nil
(ui-top-router main-ui-router))))
(defn initialize [app]
(df/load app :all-numbers PhoneDisplayRow
{:target [:screen/phone-list :tab :phone-numbers]
:refresh [:phone-numbers]}))18. Server-side Rendering
Single-page applications have a couple of concerns when it comes to how they behave on the internet at large.
The first is size. It is not unusual for a SPA to be several megabytes in size. This means that users on slow networks may wait a while before they see anything useful. Network speeds are continually on the rise (from less than 1kbps in the 80’s to an average of about 10Mbps today). This is becoming less and less of an issue, and if this is your only concern, then it might be poor accounting to complicate your application just to shave a few ms off the initial load. After all, with proper serving you can get their browser to cache the js file for all but the first load of your site.
The second more important concern is SEO. If you have pages on your application that do not require login and you would like to have in search engines, then a blank HTML page with a javascript file isn’t going to cut it.
Fortunately, Fulcro has you covered! Server-side rendering not only works well in Fulcro, the central mechanisms of Fulcro (a client-side database with mutations) and the fact that you’re writing in one language actually make server-side rendering shockingly simple, even for pages that require data from a server-side store! After all, all of the functions and UI component queries needed to normalize the tree that you already know how to generate on your server can be in CLJC files and can be used without writing anything new!
If you’re writing your UI in CLJC files in 2.5 to support server-side rendering then you need to make sure you use a conditional reader to pull in the proper server DOM functions for Clojure:
(ns app.ui
(:require #?(:clj [fulcro.client.dom-server :as dom] :cljs [fulcro.client.dom :as dom]))18.1. Recommendations
In order to get the most out of your code base when supporting server-side rendering, here are some general recommendations about how to write your application. These are pretty much what we recommend for all applications, but they’re particularly important for server-side rendering:
18.1.1. Use Initial State on Components That Appear on Client Start
This is true for every application. We always encourage it. It helps with refactoring, initial startup, etc. When doing server-side rendering you won’t need this initial state on the client (the server will push a built-up state); however, the server does need the base minimum database on which it will build the state for the page that will be rendered.
|
Important
|
For SSR you will move initial state from just your Root node to a function. The reason for this
is that Fulcro ignores explicit application state at startup if it can find initial state on the root node, and
we want to force state into the client.
|
This will become clearer when we get to examples.
18.1.2. Write Mutations via Helper Functions on State Maps
When writing a mutation, first write a helper function. Perhaps end its name with -impl or even . The
helper function should take the application database state map (*not atom) and any arguments needed to accomplish the
task. It should then return the updated state map:
; in a CLJC file!
(defn todo-set-checked-impl [state-map todo-id checked?]
(assoc-in state-map [:todo/by-id todo-id :item/checked?] checked?))Then write your mutation using that function:
; CLJS-only, either separate file or conditionally in CLJC
(defmutation todo-set-checked [{:keys [id checked?]}]
(action [{:keys [state]}]
(swap! state todo-set-checked-impl id checked?)))This has a very positive effect on your code: composition and re-use!
; composition
(defmutation do-things [params]
(action [{:keys [state]}]
(swap! state (fn [s] (-> s
(do-thing-1-impl)
(do-thing-2-impl)
...))))Of course composition is re-use, but now that your client db mutation implementation is available in clj and cljs you can use it to initialize state for your server-side render!
|
Note
|
The new mutation ^:intern support also gives you a way to get a function that applies the mutations actions
on a state atom.
|
18.1.3. Use HTML5 Routing
You have to be able to detect the different pages via URL, and your application also needs to respond to them. As a result you will need to make all of the pages that are capable of server-side also have some distinct URI representation.
18.2. Overall Structure
Here’s how to structure your application to support SSR:
-
Follow the above recommendations for the base code
-
The server will use the client initial app state plus a sequence of mutation implementations to build a normalized database
-
The server will serve the same basic HTML page (from code) that has the following:
-
The CSS and other head-related stuff and the div on which your app will mount.
-
A div with the ID of your SPA’s target mount, which will contain the HTML of the server-rendered application state
-
A script at the top that embeds the normalized db as a transit-encoded string on
js/window. -
A script tag at the bottom that loads your client SPA code
-
-
The client will look for initial state via a var set on
js/window(transit-encoded string) and start -
The client will do an initial render, which will cause react to hook up to the existing DOM
18.2.1. Building the App State on the Server
The fulcro.server-render namespace has a function called build-initial-state that takes the root component
and an initial state tree. It normalizes this and plugs in any union branch data that was not in the tree itself
(by walking the query and looking for components that have initial state and are union branches). It returns
a normalized client application db that would be what you’d have on the client at initial startup if you’d
started the client normally.
So, now all you need to do is run any combination of operations on that map to bring it to the proper state. Here’s the super-cool thing: your renderer is pure! It will render exactly what the state says the application is in!
(let [base-state (ssr/build-initial-state (my-app/get-initial-state) my-app/Root)
user (get-current-user (:session req))
user-ident (util/get-ident my-app/User user)]
(-> base-state
(todo-check-item-impl 3 true) ; some combo of mutation impls
(assoc :current-user user-ident) ; put normalized user into root
(assoc-in user-ident user)))So now you’ve got the client-side db on the server. Now all you need to do is pre-render it, and also get this generated state to the client!
18.2.2. Rendering with Initial State
Of course, the whole point is to pre-render the page. Now that you have a complete client database this is trivial:
(let [props (prim/db->tree (prim/get-query app/Root normalized-db) state-map state-map)
root-factory (prim/factory app/Root)]
(dom/render-to-str (root-factory props)))will generate a string that contains the current HTML rendering of that database state!
18.2.3. Send The Completed Package!
Now, while you have the correct initial look, you will still need to get this database state into the client.
While you could technically try loading your UI’s initial state, it would make the UI flicker because when React
mounts it needs to see the exact DOM that is already there. So, you must pass the server-side generated-database
as initial-state to your client.
The function fulcro.server-render/initial-state→script-tag will give you a <script> tag that includes
a string-encoded EDN data structure (using transit).
We now combine what we learned about generating the application’s rendering with this to get the overall response from the server:
(defn top-html [normalized-db root-component-class]
(let [props (db->tree (get-query root-component-class) normalized-db normalized-db)
root-factory (factory root-component-class)
app-html (dom/render-to-str (root-factory props))
initial-state-script (ssr/initial-state->script-tag normalized-db)]
(str "<!DOCTYPE) html>\n"
"<html lang='en'>\n"
"<head>\n"
"<meta charset='UTF-8'>\n"
"<meta name='viewport' content='width=device-width, initial-scale=1'>\n"
initial-state-script
"<title>Home Page</title>\n"
"</head>\n"
"<body>\n"
"<div id='app'>"
app-html
"</div>\n"
"<script src='js/app.js' type='text/javascript'></script>\n"
"</body>\n"
"</html>\n")))Now let’s move on to the client.
18.2.4. Client-Side – Use Initial State
When creating your client, you will now be explicit about initial state and use a helper function (provided) to decode the server-sent state:
(defonce app (atom (fc/make-fulcro-client {:initial-state (fulcro.server-render/get-SSR-initial-state}))))Of course, you could use :client-did-mount to do various other bits (like start your HTML5 routing), but this
completes the essential pattern. No other client modifications need to be made!
18.3. A Complete Working Example
There is a complete working example of these techniques (including the HTML5 routing) in the [fulcro-template](https://github.com/fulcrologic/fulcro-template).
-
[Server-side logic](https://github.com/fulcrologic/fulcro-template/blob/master/src/main/fulcro_template/server.clj)
-
[HTML5 Routing](https://github.com/fulcrologic/fulcro-template/blob/master/src/main/fulcro_template/ui/html5_routing.cljc)
-
[Client-side Initial State Generation and Modifications](https://github.com/fulcrologic/fulcro-template/blob/master/src/main/fulcro_template/ui/root.cljc) (see
initial-app-state-tree) -
[Client Start-up](https://github.com/fulcrologic/fulcro-template/blob/master/src/main/fulcro_template/client.cljs) Note this example tolerates a failure of the server to send initial state, so it runs initial startup steps if it detects that.
18.4. Rendering via Node.js
Since node.js is powered by V8, the same javascript engine that powers chrome web browser getting isomorphic support including fulcro networking is really easy.
For fulcro networking to work in nodejs you need to provide a substitute for the browser’s XMLHttpRequest that is used by xhrio. You can install the https://www.npmjs.com/package/xmlhttprequest npm package and then set it globally.
(ns app.server
(:require
["xmlhttprequest" :as npm-xmlhttprequest]))
(set! js/global.XMLHttpRequest (.-XMLHttpRequest npm-xmlhttprequest))One approach for getting SSR on node.js with the data loaded from the network is to create a fulcro headless client and use the built-in helper fulcro.server-render/defer-until-network-idle (available as of fulcro 2.6.10) for deferring the server request until fulcro has finished loading all network data.
(ns app.server
(:require
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.data-fetch :as df]
[fulcro.client :as fc]
[fulcro.client.network :as fcn]
[fulcro.server-render :refer [defer-until-network-idle]]
["react-dom/server" :as rdom :refer (render)]
["xmlhttprequest" :as npm-xmlhttprequest]))
(defn ssr-enpdpoint [req resp]
(let [client-did-mount (fn [{:keys [reconciler]}]
(df/load reconciler ...))
fulcro-client (fc/make-fulcro-client
{:client-did-mount client-did-mount
:networking {:remote (fcn/fulcro-http-remote {:url "http://localhost:3000/api"}})})
mounted-app (fc/mount fulcro-client root/Root nil) ; nil as the last argument creates a headless client
reconciler (:reconciler mounted-app)]
(defer-until-network-idle
reconciler
(fn []
(let [app-state (-> reconciler deref)
app-state-tree (prim/db->tree (prim/get-query root/Root app-state) app-state app-state)]
(.send resp (get-html (rdom/renderToString (ui-root app-state-tree)) app-state)))))))A minimal example app with fulcro & nodejs server side rendering can be found at https://github.com/claudiu-apetrei/fulcro-nodejs-ssr-example
18.5. True Isomorphic Support with Nashorn (JVM Javascript engine)
If you use external Javascript libraries of React components then you have two choices.
-
Write wrappers in cljs that can output something reasonable for them in SSR, and them make cljc wrappers that use the JS when on the client, and your placeholder dom on the server.
-
Use Nashhorn on the server to actually run a render in a Javascript engine on the server.
Using placeholders can work very well, and is the recommended approach.
If you’re willing to work just a little bit harder then you can maintain a true isomorphic application using Java 8+ and the Nashorn ECMA scripting engine.
Some notes:
-
Server-side use of the compiled Javascript works best with advanced-optimized builds. Development builds of the javascript won’t work right, and we’ve even seen problems with builds that don’t use advanced optimizations.
-
(1) means that your SSR is going to be hard to work with if you’re in dev (hot code reload) mode. The recommendation is that you test SSR as a separate step (where you can have an auto incremental build with advanced compilation).
The basics are:
-
Start a Nashorn instance
-
Run a script that defines console and global
-
Run the compiled script of your program to define everything
-
Use a render to string call to get the initial HTML output
The js script to defined console and global is just:
var global = this;
var console = {};
console.debug = print;
console.warn = print;
console.error = print;
console.log = print;
var usingNashorn = true;Client main (which does the mount) becomes:
(when-not (exists? js/usingNashorn)
(reset! app (core/mount @app root/Root "app")))Server rendering (client-side cljs) is:
(def ui-root (prim/factory root/Root))
(defn ^:export server-render [props-str]
; incoming data will come from JVM as transit-stringified EDN
(if-let [props (some-> props-str util/transit-str->clj)]
(js/ReactDOMServer.renderToString (ui-root props))
(js/ReactDOMServer.renderToString (ui-root (prim/get-initial-state root/Root nil)))))And the server-side code holds a script engine in an atom or something (a component would be best), and accomplishes the rendering of a given tree of UI props via:
(defn ^String nashorn-render
[props]
(try
(start-nashorn)
(let [string-props (util/transit-clj->str props)
script-engine ^NashornScriptEngine @nashorn
; look up the object that holds the defs of the server-render function (using js naming)
namespc (.eval script-engine "namespace.of.server_render")
; invoke the server-render function, and pass in a transit-stringified EDN version of props
; invokeMethod is varargs, which is what the into-array is about
result (.invokeMethod script-engine namespc "server_render" (into-array [string-props]))
html (String/valueOf result)]
html)
(catch ScriptException e
(timbre/debug "Server-side render failed. This is an expected error when not running from a production build with adv optimizations.")
(timbre/trace "Rendering exception:" e))))There is a nashorn branch on the github fulcro-template project that demonstrates the setup and rendering code.
19. Client Networking with Fulcro HTTP Remote (version 2.3+)
Fulcro 2.3 and above has an implementation that uses Google’s XhrIO to implement a networking layer for Fulcro that is much easier to extend than earlier Fulcro versions.
This new version also brings a few new features:
-
It uses middleware for the request and response so you can customize the entire communication pipeline without having to deal with low-level networking. A remote can now manipulate everything from the request headers to the URL and even the raw data on the wire.
-
It allows you to give network requests an ID, and later abort them if desired.
-
It includes support for progress updates on mutations, which are commonly used for things like file uploads.
19.1. Creating a Remote
A remote with these new features requires very little code:
(fc/make-fulcro-client {:networking {:remote (net/fulcro-http-remote {:url "/api"})}})This will give you support for the abort and progress features.
You may include a :url parameter to specify what the server endpoint is (defaults to "/api").
19.2. Aborting a Request
The first thing you need to do is assign an abort ID to the request. The load API allows an :abort-id parameter.
Mutations use the AST mechanism of the mutation API:
(load this :thing Thing {:abort-id :thing})
...
(defmutation do-something [params]
...
(remote [{:keys [ast]}]
(m/with-abort-id ast :SOME-ID)))The API for aborting a request is on the FulcroApplication protocol (networking is coordinated at the
application level), which means you need access to the applcation in order to run aborts.
The recommended way to deal with aborts is:
-
Hold your mounted app in an atom, say in your
clientnamespace. -
Write a mutation in your client namespace that can access this
appatom.
(ns my-client
(:require [fulcro.client :as fc]
[fulcro.client.mutations :refer [defmutation]]
[loading.ui.root :as root]
[fulcro.client.network :as net]))
(defonce app (atom nil))
(defn abort* [id]
(when @app
(fc/abort-request! @app id)))
(defmutation abort [{:keys [id]}]
(action [env]
(abort* id)))Then you can either directly call the abort* function (if it does not create a circular require) or
just invoke the mutation from anywhere (since mutations are just symbol data):
(transact! component `[(my-client/abort {:id :ID})]`)Aborting a request that has yet to start networking results in no change to app state. It simply removes the request from the queue.
Aborting an active request stops the network transaction and acts as if the requested data resulted in an empty map from the server (so that load merge will overwrite the target with nothing). If this is a problem then target the load to a placeholder location and use a post-mutation to move it when load completes.
19.3. Progress Updates
Obtaining progress updates on mutations are requested the same way as abort IDs: through AST manipulation on the mutation:
(defmutation some-mutation [params]
(remote [{:keys [ast]}]
(m/with-progressive-updates ast `(progress-mutation {:x 1}))))Progress updates are sent to the given mutation (which will always receive the parameters you specified). The parameters will be augmented with information about the current progress:
-
:progress-phase- will be one of :sending, :receiving, :complete, or :failed. -
:progress-event- the raw XhrIO event (which has loading progress data) -
:transaction- The transaction that is running -
:body- The current low-level body. Body is NOT processed through the middleware, and could be partial. -
:status-code- The HTTP status code if receiving.
The fulcro.client.network/progress% function can be used to convert this into a number between 0 and 100.
Progress updates are currently supported on mutations. Support for progress directly on loads is possible, but not yet implemented. The workaround for the moment to get progress for a load is to use mutation joins to return a value from a mutation:
(defmutation some-mutation [params]
(remote [{:keys [ast state]}]
(-> ast
(m/with-progressive-updates `(progress {}))
(m/returning state Thing))))where Thing is some component that defines the query for the data being returned from the mutation.
In general progress updates are only really useful for larger requests, such as file uploads. Triggering downloads to the user’s machine should probably be done using tricks that force the item into the normal browser download mechanisms (external to Fulcro).
File uploads also require that you augment the new client network middleware, since there is no reliable way to encode an image of arbitrary size into a transaction.
19.4. Optional Non-Sequential Operation
When you create a networking component you can optionally implement the NetworkBehavior protocol
which has a single method (serialize-requests? [this]).
The default (without this protocol) is to serialize them, but if you implement this
protocol and return false from the method then Fulcro’s plumbing will not manage request queuing at all and will just
call send any time there is anything in the queue.
The predefined networking support already implements this protocol, so you can simply pass an option to enable parallel operation:
19.5. Request Middleware
The request will, by default, be sent through pre-written middleware fulcro.client.network/wrap-fulcro-request. This
middleware will convert the body to a json-encoded transit form and add content-type headers. If you specify request
middleware you will want to compose that middleware in or normal API requests won’t work.
Additional middleware can do any number of things:
-
Re-route requests to an alternate URI
-
Change the content type and encode the body
-
Short-circuit the result of the middleware stack
Middleware is just a function (fn [handler] (fn [req] …)). The inner function can choose to modify the request
and pass it through the remaining handler, or just return a request as the final thing to process. This is
similar to Ring middleware on the server.
Fulcro will supply the middleware with a request that contains:
-
:body- The EDN transaction to send (query or mutations). -
:headers- An empty map. -
:url- The default URL this remote talks to. -
:method- The HTTP verb as a keyword. All Fulcro requests default to:post.
Middleware should return a map with the same keys that is passed on to the next layer. It may add any keys it wishes. The final result of the middleware stack will be used as follows:
-
:body- The raw data that will be given to XhrIO send -
:headers- A clj map from string to string. It will be converted to a jsobj and given as the headers to the request. -
:url- The network target. Can be relative or a complete URL, assuming you have security set to allow you to talk to the given server. -
:method- Converted to an upper-case HTTP verb as a string.
19.5.1. File Uploads
Fulcro may soon include pre-written software to accomplish file uploads for you. In the meantime you can just copy code from the file upload demo project as a basis for your own projects.
The basic scheme is as follows (and is well-documented in that project):
-
Attach a
js/Fileobject to a mutation’s parameters (typically as metadata to avoid various tool overhead) -
Include a tempid in the parameters
-
The mutation should using an network object that has custom middleware for file upload/error handling
-
The local side of the mutation puts the file information into app state with a tempid
-
The remote’s middleware encodes the headers/body into a proper multipart form upload, and includes the tempid
-
Progress reports are handled as usual. The parameters of the progress mutation should include the tempid so that progress can be written to the file’s state.
-
The remote uses normal Fulcro response middleware (which can decode tempid remappings)
-
The server accepts the file, assigns it a real ID, and returns a transit response with tempid remapping to that real ID.
When complete, the UI has an ID for the uploaded file, and can interact with the server via that ID (e.g. for generating file serving URLs for images, send delete mutations, etc.).
The server for this would need middleware watching for file uploads at /file-uploads that
returns a transit+json encoded map for the mutation (the mutation name is irrelevant in the response):
{`upload-file {:tempids {file-temp-id newly-assigned-id}}}19.6. Client Response Middleware
The response will, by default, be sent through the pre-written middleware function fulcro.client.network/wrap-fulcro-response
which contains the logic to properly decode an API response (which is essentially just a transit decode). If you specify
response middleware you will want to compose that middleware in or normal API responses won’t work.
Raw responses from the remote will include:
-
:body- The data that will be given back to Fulcro as the response from the server -
:transaction- The transaction that body is a response to. If you modify this for queries you can manipulate the final merge. -
:status-code- The HTTP status code -
:status-text- The HTTP status text -
:error- An error code. Typically one of:network-error,:http-error,:timeout, etc. -
:error-text- A string describing the error -
:outgoing-request- The request that this is a response to.
The final response body and transaction combo will be given to Fulcro for merge. If you modify the transaction be sure to use a query from components so that normalization is done properly.
|
Important
|
Response middleware is allowed to rewrite an errant response to an OK one (by clearing the error fields and setting :status-code to 200). This would allow you, for example, to merge specific errors into state as you see fit instead of relying on Fulcro’s built-in error handling model. |
19.6.1. Merging State
As mentioned above: the final response body and transaction combo will be given to Fulcro for merge. The basic pipeline is like this:
-
You run a transact that goes remote. E.g.
(transact! this '[(f {:x 1})]).transactionis[(f {:x 1})] -
The response is received from the server. This can be anything you want to return, but typically for mutations is just
:tempids. For example{'f {:tempids {1 2}}}. This is thebody. -
Merge is a two-part affair:
-
Any mutation keys in the response are pulled off and run through migrate to get tempid migrations.
-
The remainder of the k/v pairs in the map are then run through normal merge (which requires a query, assumed to be in
transaction).
-
So, this gives you a ton of power in your response middleware to customize everything from error handling to doing post-operations on mutations.
Let’s say you want to write response middleware that does the following: If there is an error, skip Fulcro’s error
pipeline and instead put the information in :my-error key at root (which perhaps you have set up to pop a modal in your
UI code).
So, your desired merge transaction is [:my-error] (rewriting the transaction "as if" you had "asked" for the error),
and the body is {:my-error {…data for error…}}! The entire middleware component is:
(defn wrap-errors [handler]
(fn [resp]
(let [{:keys [error status-code]} resp]
(handler
(if (not= 200 status-code) ; when there are errors, rewrite them "as-if" we had asked for it
(-> resp
(assoc :body {:my-error {:error error}} :transaction [:my-error] :status-code 200)
(dissoc :error))
resp)))))installed with:
;; Resulting middleware (evaluates right to left because of nested composition)
(def middleware (-> (net/wrap-fulcro-response) (wrap-errors)))
...
(def client (fc/make-fulcro-client {:networking {:remote (net/fulcro-http-remote {:url "/api" :response-middleware middleware})}})19.6.2. Interfacing with Alternate Network Protocols
Fulcro’s pluggable remotes make it relatively easy to plug in alternate communication methods. You can interface with things like REST or GraphQL servers with relative ease, especially if you use the Pathom parser library.
A REST Example
Here’s a simple example to give you an idea of how simple it can be:
(ns app.rest-remote
(:require [com.wsscode.pathom.connect :as pc]
[com.wsscode.pathom.core :as p]
[com.wsscode.pathom.fulcro.network :as pn]
[clojure.core.async :as async]
[fulcro.client.primitives :as prim]
[fulcro.client.network :as net]))
(defmulti resolver-fn pc/resolver-dispatch)
(defonce indexes (atom {}))
(defonce defresolver (pc/resolver-factory resolver-fn indexes))
(defn rest-parser
"Create a REST parser. Make sure you've required all nses that define rest resolvers. The given app-atom will be available
to all resolvers in `env` as `:app-atom`."
[extra-env]
(p/async-parser
{::p/plugins [(p/env-plugin
(merge extra-env
{::p/reader [p/map-reader
pc/all-async-readers]
:app-atom app-atom
::pc/resolver-dispatch resolver-fn
::pc/indexes @indexes}))
p/request-cache-plugin
(p/post-process-parser-plugin p/elide-not-found)]}))
(defn rest-remote [extra-env]
(pn/pathom-remote (rest-parser extra-env)))The rest-remote function creates a remote that can resolve REST requests via Pathom resolvers. It is written to
take an atom that will hold your Fulcro app, so that resolvers for REST can interact with your database.
Simply add the remote into your networking on the client:
(fc/make-fulcro-client
{:networking {:remote (fulcro-http-remote ...)
:rest (rr/rest-remote app)}})and you can use the newly defined defresolver to define Pathom resolvers for satisfying REST API requests, like so:
(defresolver `ofac
{::pc/output [:rest/thing]}
(fn [env _]
(let [name (-> env :ast :params :name)
params {"name" name}]
(go
(let [{:keys [body]} (<!
(http/get "https://myrest.com/search" {:query-params params}))]
{:rest/thing body})))))which can then be used with:
(df/load this :rest/thing nil {:params {:name "Simon"}})and can be targeted, use load markers, etc.
Of course, you can also define resolvers that "compute" derived data with normal resolver tricks. See Pathom documentation.
GraphQL
The Pathom library also includes a pre-built GraphQL remote for Fulcro, along with tools that allow you to combine resolvers with GraphQL servers easily. Pathom’s connect feature can be combined in, which allows you to morph your perception of the server’s graph in ways that are more convenient for your application. This results in a remote for Fulcro that is far more powerful than standard GraphQL, even when GraphQL is what the server is providing!
File Upload and Low-Level Protocols
Submission of binary data as file uploads via multipart POST encodings is one area where you’re going to need to speak something other than EQL over transit. Fulcro’s built-in client remote includes support for middleware that can transform requests and responses.
See the section on file uploads for more details.
20. Websockets
|
Warning
|
As of Fulcro 2.5 you must add sente to your dependencies for websockets to work. The dependencies are dynamically resolved.
|
Fulcro includes support for using Sente to set up websockets as a remote for your applications. The support documented here is relatively new, and supercedes a prior version as of 2.2.0.
20.1. Server Side
There are two protocols in fulcro.websockets.protocols on the server side:
(defprotocol WSNet
(add-listener [this ^WSListener listener] "Add a `WSListen` listener")
(remove-listener [this ^WSListener listener] "Remove a `WSListen` listener")
(push [this cid verb edn] "Push from server"))
(defprotocol WSListener
(client-added [this ws-net cid] "Listener for dealing with client added events.")
(client-dropped [this ws-net cid] "listener for dealing with client dropped events."))WSNet is implemented by the Websockets component.
WSListener is for you to implement. It allows for listening to client added and dropped (closed) actions. An example might look like this:
(ns app
(:require
[com.stuartsierra.component :as component]
[fulcro.websockets.protocols :as wp :refer [WSListener WSNet add-listener remove-listener client-added client-dropped]]))
(defrecord ChannelListener [websockets]
WSListener
(client-dropped [this ws-net cid]
(println "Client disconnected " cid))
(client-added [this ws-net cid]
(println "Client connected " cid))
component/Lifecycle
(start [component]
(add-listener websockets component)
component)
(stop [component]
(remove-listener websockets component)
component))
(defn make-channel-listener []
(component/using
(map->ChannelListener {})
[:websockets]))These encompass the core interface that is usable from the server.
The following sections show how to set up a server.
20.1.1. Easy Server
If you’re using the easy server you need only add two components, and then inject the websockets wherever you need to do client push from:
(ns app
(:require
[fulcro.server :as server]
[fulcro.websockets :as fw]
[fulcro.easy-server :as easy])
(defn build-easy-server [path]
(easy/make-fulcro-server
:config-path path
:components {:websockets (fw/make-websockets (server/fulcro-parser))
:channel-listener (make-channel-listener)
:broadcaster (make-broadcaster) ; See below
:ws-adapter (fw/make-easy-server-adapter)}))If you need push access from the parser, simply inject the websockets component and call push on it.
|
Note
|
The parsing environment does not support parser injections of easy server. See server details below for more information on how to customize your API parsing environment with web sockets and easy server. |
20.1.2. Custom Server
A custom server is similarly simple. You’ll have some kind of component system with a web server (http-kit is the default sente adapter), middleware, etc.
The websockets component is the same, you just need to place it into your middleware like so:
(defrecord Middleware [ring-stack websockets]
component/Lifecycle
(start [this]
(assoc this :ring-stack
(-> (not-found-handler)
(fulcro.websockets/wrap-api websockets)
(wrap-keyword-params) ;required
(wrap-params) ; required
...
(wrap-not-modified)
(wrap-gzip))))
(stop [this]))
(defn make-middleware []
(component/using (map->Middleware {})
[:websockets]))where your component system map includes the websockets component:
(defrecord WebServer [config middleware stop-fn]
component/Lifecycle
(start [this]
(let [port (get-in config [:value :port] 0)
[port stop-fn] (let [stop-fn (http-kit/run-server (:ring-stack middleware) {:port port})]
[(:local-port (meta stop-fn)) (fn [] (stop-fn :timeout 100))])
uri (format "http://localhost:%s/" port)]
(println "Web server running at " uri)
(assoc this :stop-fn stop-fn)))
(stop [this]
(when stop-fn
(stop-fn))
this))
(defn make-server []
(component/using
(map->WebServer {})
[:middleware :config]))
(defn build-server
[{:keys [config] :or {config "config/dev.edn"}}]
(component/system-map
:config (server/new-config config) ; from fulcro server
:middleware (make-middleware) ; see above
:websockets (fw/make-websockets (server/fulcro-parser))
:channel-listener (make-channel-listener) ; see above
:broadcaster (make-broadcaster) ; see below
:web-server (make-server))) ; see above20.1.3. The Websockets Component [WSComponent]
The component implements the WSNet protocol, so you can call push directly on it. It wraps Sente’s operations and
internals, but quite a bit of those are easily accessible, and some of them are necessary for most features
you’d want to write.
You can pass the contruction method three arguments:
-
parser- A fulcro parser (usually(server/fulcro-parser)) -
adapter- A sente HTTP adapter (See Sente docs). Defaults to http-kit. -
sente-options- A map of options that is passed directly to the sente websocket channel construction.
|
Note
|
If you supply a packer in the sente options you’ll need to make sure tempids are supported (this is done by default, but if you override it, it is up to you.
The default user id mapping is to use the internally generated UUID of the client. Use sente’s :user-id-fn option
to override this.
|
The web sockets component has a couple of useful fields that you can also access anywhere you inject it:
parser-
The Fulcro API parser you installed.
connected-uids-
The Sente connected IDs atom. This is a read-only atom of user IDs (which defaults to the client UUID). See Sente docs for how to customize this.
The web socket component is also responsible for running your API parser, and you may want custom things to be in your parsing environment.
|
Warning
|
Easy server’s :parser-injections will not work!.
|
However, anything injected as a dependency of this component will be added to your parser environment (in addition to the parser itself). Thus, if you’d like some other component (like a database) to be there, simply add something like this to do your component entry:
...
:websockets (component/using (make-websockets (fulcro.server/fulcro-parser)) [:sql-database :sessions])
:sql-database (some-db-component)
:sessions (some-session-component)
...and when the system starts it will inject those components in and make them part of the parsing env.
|
Note
|
It is a good idea to use namespaced keywords for your component identifiers to prevent data collisions. |
Additionally, the parser environment will include:
:websockets-
The channel server component itself
:push-
A function that can send push messages to any connected client of this server. (just a shortcut to send-fn in websockets)
:parser-
The parser you supplied
:sente-message-
The raw sente event. This will include things like the client and user ID of the source message. See Sente documentation for complete details.
The most useful items in the sente message are:
:client-id-
The unique websocket client connection ID (typically a UUID)
:connected-uids-
The sente connected client ID list.
:uid-
The client’s user ID (will be same as client ID unless you override it)
:ring-req-
The ring request of the websocket.
20.1.4. Push Notifications
You can send push notifications to clients by injecting the websockets in other components and using the
push method. Here’s a sample component that broadcasts server time updates:
(defrecord Broadcaster [websockets ^Thread thread]
component/Lifecycle
(start [this]
(let [t (new Thread (fn []
(Thread/sleep 1000)
(let [cids (some-> websockets :connected-uids deref :any)]
(doseq [cid cids]
(wp/push websockets cid :time-change {:time (Date.)})))
(recur)))]
(.start t)
(assoc this :thread t)))
(stop [this] (.stop thread)))
(defn make-broadcaster []
(component/using
(map->Broadcaster {})
[:websockets]))The server push method takes a topic and an EDN message. It sends both to the client, and they’re received
as a map with keys :topic and :msg for the message.
See the Sente documentation for information on connected UIDs.
20.2. Client Side
Installing websockets on the client is equally trivial:
(fc/make-fulcro-client
{:networking {:remote (fw/make-websocket-networking
{:websockets-uri "/chsk"
:push-handler push-handler
:state-callback state-callback
:global-error-callback (fn [& args] (apply println "Network error " args))})}})The push-handler is a function that will receive server push notifications (as a map with :topic and :msg keys),
and state-callback is a function that will be told with the networking of the client is connected or not.
Usually you’ll want to transact against your application on push and state changes, so if you save your app to an atom you can easily write the callbacks to use it:
(defonce app (atom nil))
(defn push-handler [msg]
(when-let [reconciler (some-> app deref :reconciler)]
(prim/transact! reconciler `[(process-push {:message ~msg})])))
(defn state-callback
[_ {:keys [open?] :as new-state}]
(when-let [reconciler (some-> app deref :reconciler)]
(prim/transact! reconciler `[(set-network-status {:up? ~open?})])))
(defn mount []
(reset! app (fc/mount @app root/Root "app")))
(defn ^:export init []
(reset! app (fc/make-fulcro-client
; replace the default remote with websockets
{:networking {:remote (fw/make-websocket-networking "/chsk"
:push-handler push-handler
:state-callback state-callback
:global-error-callback (fn [& args]
(apply println "Network error " args)))}}))
(mount))20.2.1. Network Errors
Normally a network error results in an immediate client error (triggering fallbacks, etc.).
If the auto-retry? option of make-websocket-networking on the client is set to true then it will detect
network disconnects and go into auto-reconnect and retry mode. This
means that you must ensure that your mutations are idempotent, as there is a small chance that a mutation could have
made it to the server, run, but not responded before the network problem. The retry support could therefore consider
it "failed" and run it again. On a flaky network with a slow server this could degrade into running
the mutation any number of times.
If you choose to use auto retry it is recommended that you block your UI when the networking is down. Technically (as long as you don’t need to read) you could allow the user to continue working and the pending remote mutations will all run in sequence once the network returns. However, without more novel history management you might not be able to respond to API errors in a way that makes sense to the user.
20.3. Chat Demo
There is a full chat demo application on github.
20.4. Porting From Older Websockets
If you were using the older websockets support in Fulcro, then the following changes are necessary:
-
Modify your server to set up websockets as shown in earlier sections.
-
The
:cidparameter in the server env was misnamed in the original support (it was really a user id, but the original support defaulted the user id to the client id). The parameter is still there (but is undocumented), but it is now truly the client id, not the user id. You should port to using the rawsente-messagefor this concern. -
The
:connected-cidsof the original had the same naming problem. The name has been corrected to:connected-uids. -
The client is simpler. Push notifications are no longer received by the built-in multimethod
push-received. If you want that, then store your application in a top level atom (e.g.app) and use this as your newpush-methodparameter when creating the networking:(fn [m] (when @app (fulcro.websockets.networking/push-received @app m))).
21. Security
Full production Fulco apps, just like any other web-based software need some additional attention to ensure that there are no security holes that can be exploited. Fulcro can do nothing for you if you trust user strings in SQL string composition or make any of the other "old school" errors like those in The OWASP Top Ten List.
The most critical part of your application to secure is your network-based API. This involves low-level network security measures, authentication, and then often some additional authorization.
If you’re using unmodified Fulcro server code and client remotes then it is likely that you have not done enough to ensure your user’s safety. Here are the minimum measures (also note that I am not a security expert, and you system may have additional needs. You should do your homework.):
-
Use HTTPS for all authenticated access. Most people put something like nginx in front of thier webapp for this.
-
Use secure cookies for authenticated sessions, to ensure you don’t accidentally send an authenticated session cookie over a non-secure connection.
-
If you’re using
wrap-sessionand assign a cookie to your user on pre-login HTTP access and then "upgrade" it on login you are opening your users to man-in-the-middle attacks.
-
-
Add middleware that checks for unexpected cross-origin requests.
-
Add code to prevent websocket hijacking (if you use websockets). Sente with its built-in CSRF is not sufficient.
-
Add code to do proper cross-site scripting prevention.
-
If you can see the CSRF token go across any AJAX interaction as payload data that requires nothing more than the session cookie (or less), then your security is broken. See this Stack Overflow Discussion for more information on correct ways to use CSRF tokens, and their relative pros/cons.
-
Fulcro 2.6.8+ includes some built-in support that implement some of these. Your application auth logic and server deployment matter, so do not trust that any web application (using Fulcro or any other library) is secure. You should always go through a complete security checklist and penetration testing.
21.1. Low-Level Network Security
First, start by reviewing your server middleware. You should read through
Ring Defaults and understand
what each one of the recommended middleware bits does, and add the ones that apply for you. Pay particular attention
to any related to SSL and cross-site things (wrap-frame-options, wrap-xss-protection, wrap-content-type-options, etc.).
Fulcro is not involved in your cookie/session/auth/SSL story. You will need to design, add, and configure that middleware and logic yourself. Do not trust Fulcro templates for security. They are meant to be starting points, and not production-ready code. These, by necessity, do not force SSL for example.
The ring.middleware.ssl has a few things you should throw in once you’ve got SSL working. If you’re forcing all access
to HTTPS before wrap-session can assign a cookie, then you won’t have to re-assign a different cookie for authenticated
access, and it also allows you to add the :secure true option to wrap-session so that you can stop worrying about
that mess.
See the Ring wrap-session documentation for more details about things like how to handle cookie regeneration on privilege escalation if you started out (i.e. need) a non-secure cookie for pre-authenticated session things.
21.1.1. CSRF
The most difficult and intricate thing to secure in your application is cross-site API requests. Much of the "official"
documentation on the web about XSS is about form submission, and wrap-anti-forgery middleware is built to allow you
to secure form POST in exactly this scenario.
Fulcro does use POST for both queries and mutations, so adding this middleware will "work", in that all of your API requests will fail everywhere! This is probably stronger security than your users will find useful.
There are a number of approaches you can take to correct this. The easiest is to:
-
Configure your deployment for SSL always. Development mode can be configurable to turn off the middleware redirects and the secure marker on cookies, but you might want to have a careful deployment test to ensure non-SSL requests are always redirected in production and cookies are secure.
-
Put the CSRF token in a secure (but js-accessible) cookie or embed it in the HTML of the page of your Fulcro application. This will allow the startup code to access it. Make sure you understand the security around the generation of this token and how it works.
-
Add the CSRF to the headers of your Fulcro remote(s) as
X-CSRF-Token. This will allow your POSTs to get past thewrap-anti-forgerymiddleware. -
I also recommend that you enforce an origin header check just before the API handler. As you expand your software you might add endpoints that make you want to open up things with
Access-Control-Allow-Originon your server, but you probably don’t want those requests ever making it to your API as possible cross-site attacks. Fulcro comes with (as of 2.6.8)fulcro.server/wrap-protect-originsfor this purpose.
21.1.2. Example Securing a Normal Remote
When deploying to production you should stop using the "easy" server and roll your own. This section will cover the steps you need to do so, and you can also clone the complete source of this example.
The Server Config and Middleware
Our demo app is going to take the approach of embedding the CSRF token in the HTML page that serves our Fulcro app. This is relatively easy to understand, and is as secure as form-based CSRF embedding. Hiccup makes short work of generating such a page:
(defn generate-index [{:keys [anti-forgery-token]}]
(timbre/info "Embedding CSRF token in index page")
(-> (h.page/html5 {}
[:head {:lang "en"}
[:meta {:charset "UTF-8"}]
[:script (str "var fulcro_network_csrf_token = '" anti-forgery-token "';")]]
[:body
[:div#app]
[:script {:src "/js/main/app.js"}]
[:script "security_demo.client.init()"]])
response/response
(response/content-type "text/html")))For middleware we can adopt ring-defaults to get most of the bits we need.
You want to be able to work in development, and also safely deploy to production, and since
ring-defaults needs a number of config options we’d like to be able to tweak between the two we’ll
put a secure set of those into our Fulcro defaults.edn config file as follows:
{:http-kit/config
{:port 3000}
:legal-origins
#{"localhost" "security-demo.lvh.me"}
:ring.middleware/defaults-config
{:params {:keywordize true
:multipart true
:nested true
:urlencoded true}
:cookies true
:responses {:absolute-redirects true
:content-types true
:default-charset "utf-8"
:not-modified-responses true}
:session {:cookie-attrs {:http-only true, :same-site :strict}}
:static {:resources "public"}
:security {:anti-forgery true
:hsts true
:ssl-redirect true
:frame-options :deny
:xss-protection {:enable? true
:mode :block}}}}and then create a middleware stack like this:
(ns security-demo.components.middleware
(:require
[clojure.pprint :refer [pprint]]
[fulcro.server :as server]
[hiccup.page :as h.page]
[mount.core :refer [defstate]]
[ring.middleware.defaults :refer [wrap-defaults]]
[ring.middleware.gzip :refer [wrap-gzip]]
[ring.util.response :as response]
[ring.util.response :refer [response file-response resource-response]]
[security-demo.api.mutations] ;; ensure reads/mutations are loaded
[security-demo.api.read]
[security-demo.components.config :refer [config]]
[security-demo.components.server-parser :refer [server-parser]]
[taoensso.timbre :as timbre]
[clojure.string :as str]))
(def ^:private not-found-handler
(fn [_]
{:status 404
:headers {"Content-Type" "text/plain"}
:body "NOPE"}))
(defn wrap-api
"Fulcro's API handler"
[handler]
(fn [request]
(if (= "/api" (:uri request))
(server/handle-api-request
server-parser
{:config config}
(:transit-params request))
(handler request))))
(defn generate-index [{:keys [anti-forgery-token]}]
(timbre/info "Embedding CSRF token in index page")
(-> (h.page/html5 {}
[:head {:lang "en"}
[:meta {:charset "UTF-8"}]
[:script (str "var fulcro_network_csrf_token = '" anti-forgery-token "';")]]
[:body
[:div#app]
[:script {:src "/js/main/app.js"}]
[:script "security_demo.client.init()"]])
response/response
(response/content-type "text/html")))
(defn wrap-uris
"Wrap the given request URIs to a generator function."
[handler uri-map]
(fn [{:keys [uri] :as req}]
(if-let [generator (get uri-map uri)]
(generator req)
(handler req))))
(defstate middleware
:start
(let [defaults-config (:ring.middleware/defaults-config config)
legal-origins (get config :legal-origins #{"localhost"})]
(timbre/debug "Configuring middleware-defaults with" (with-out-str (pprint defaults-config)))
(timbre/info "Restricting origins to " legal-origins)
(when-not (get-in defaults-config [:security :ssl-redirect])
(timbre/warn "SSL IS NOT ENFORCED: YOU ARE RUNNING IN AN INSECURE MODE (only ok for development)"))
(-> not-found-handler
wrap-api
server/wrap-transit-params
server/wrap-transit-response
(server/wrap-protect-origins {:allow-when-origin-missing? true
:legal-origins legal-origins})
(wrap-uris {"/" generate-index
"/index.html" generate-index})
(wrap-defaults defaults-config)
wrap-gzip)))|
Note
|
We delete index.html from our public resources, so that the wrap-uris middleware can dynamically generate it. This
is also handy for embedding things like hashed javascript names (e.g. from a shadow-cljs manifest.edn file).
|
Really, there is no change to how you set up APIs, but by putting it behind the CSRF protection of ring-defaults all
POSTs will be rejected before they reach it. The wrap-protect-origins is really paranoia, since a cross-site script
would never know the token; however, the paranoia could be nice if the token was somehow exposed (or guessed).
|
Warning
|
When you deploy this to production behind a proxy server, you’ll want to set the :proxy option in Ring
or you’ll get infinite redirects. The production EDN config file for this example is shown below:
|
{:http-kit/config {:port 8080}
:ring.middleware/defaults-config {:proxy true}}Of course, now your client won’t be able to run queries or mutations against the server (since it isn’t sending the CSRF token)! Let’s fix that.
Securing the Client
Really all the client has to do is add CSRF headers to the request. You can do this with a very simple bit of Fulcro client middleware (supplied in 2.6.8+, but trivial to write):
;; in fulcro.client.network as of 2.6.8
(defn wrap-csrf-token
"Client remote request middleware. This middleware can be added to add an X-CSRF-Token header to the request."
([csrf-token] (wrap-csrf-token identity csrf-token))
([handler csrf-token]
(fn [request]
(handler (update request :headers assoc "X-CSRF-Token" csrf-token)))))The client should be changed to look like this:
(def secured-request-middleware
(->
(net/wrap-csrf-token (or js/fulcro_network_csrf_token "TOKEN-NOT-IN-HTML!"))
(net/wrap-fulcro-request)))
...
(fc/make-fulcro-client
{:networking {:remote (net/fulcro-http-remote {:url "/api"
:request-middleware secured-request-middleware})}})The client simply pulls the token out of the js var, and puts it in the correct header.
You could also use a js-accessible cookie for this step, which would let you go back to static HTML serving. See the earlier comments and links about CSRF.
Securing Sente Websockets (Fulcro 2.7+ with Sente 1.14+)
Older versions of Sente had a CSRF security hole, for which we had the documented workaround. New versions of Sente have a fix, so the implementation is much easier:
-
Make sure to include
wrap-anti-forgery(or enable it inwrap-defaults) in your middleware. -
Embed the CSRF token in your HTML as a js var or in the DOM itself. Serving the CSRF token in the HTML is an accepted security practice that prevents external discovery.
-
Send the CSRF token you find in cljs to the websocket constructor.
The websocket remote need only be passed the CSRF token:
(let [csrf-token js/embedded_csrf_token]
(fulcro.websockets/make-websocket-networking {:uri "/chsk"
:csrf-token csrf-token
...)See the documentation on general websockets for more information on their server-side setup other general options, but be sure to include the anti-forgery middleware so it runs before your API if you want to enforce CSRF protections.
Securing Sente Websockets (Fulcro 2.6.x and Sente Prior to 1.14)
|
Warning
|
Do not use this approach for new apps! Upgrade Fulcro and sente instead. |
Sente has an internal CSRF support, which it uses to deal with augmenting the POST requests it might make (it supports
alternate network techniques to get around missing websocket support). Unfortunately,
it exchanges the CSRF from wrap-anti-forgery within a (js-accessible) handshake. This can be ok as long as that
handshake never happens without CSRF protection *already in place. Otherwise you are open to websocket hijacking, and
also exposing the CSRF token and compromising your other remote processing as well! (This was a reported issue
on Sente, and is fixed in 1.14.0-RC1)
Fulcro’s websocket contruction function allows you to pass a parameters through sente, and you can use these to include the CSRF token, and then add a bit of additional middleware to require that in front of your websocket setup code on the server. This ensures that Sente cannot do a handshake (and expose the token) without proving that the source page already knows the token.
|
Warning
|
I know I’ve said this more than once now, but here it is a different way: Sente will stop warning about the lack of CSRF as soon as you add the anti-forgery middleware; however, that does not secure your app. You must verify that the client talking to you is valid before starting the handshake or you are open to websocket hijacking attacks. |
The code to do this all is very similar to the normal remotes, so we’ll just show the differences.
Of course, you need websocket middleware, and it needs to do CSRF checks before the Sente handshake:
...
(defn- is-wsrequest? [{:keys [uri]}] (= "/chsk" uri))
(defn enforce-csrf!
"Checks the CSRF token. If it is ok, runs the `ok-response-handler`; otherwise returns a 403 response
and logs the CSRF violation."
[{:keys [anti-forgery-token params]} ok-response-handler]
(let [{:keys [csrf-token]} params
token-matches? (and (seq csrf-token) (= csrf-token anti-forgery-token))]
(timbre/debug "Setting up websocket request. Incoming security token is: " csrf-token)
(timbre/debug "Expected CSRF token is " anti-forgery-token)
(if token-matches?
(ok-response-handler)
(do
(timbre/error "CSRF FAILURE. The token received does not match the expected value.")
(-> (response/response "Cross site requests are not supported.")
(response/status 403))))))
(defn wrap-websockets
"Add websocket middleware. This middleware does a CSRF check on the GET (normal Ring only checks POSTS)
to ensure we don't start a Sente handshake unless the client has already proven it knows the CSRF token."
[base-request-handler]
(fn [{:keys [request-method] :as req}]
(if (is-wsrequest? req)
(let [{:keys [ring-ajax-post ring-ajax-get-or-ws-handshake]} websockets]
;; The enforcement is really on GET, which ring's middleware won't block,
;; but which exposes the token in the handshake
(enforce-csrf! req (fn []
(case request-method
:get (ring-ajax-get-or-ws-handshake req)
:post (ring-ajax-post req)))))
(base-request-handler req))))
...
(defstate middleware
:start
(let [defaults-config (:ring.middleware/defaults-config config)
legal-origins (get config :legal-origins #{"localhost"})]
(timbre/debug "Configuring middleware-defaults with" (with-out-str (pprint defaults-config)))
(timbre/info "Restricting origins to " legal-origins)
(when-not (get-in defaults-config [:security :ssl-redirect])
(timbre/warn "SSL IS NOT ENFORCED: YOU ARE RUNNING IN AN INSECURE MODE (only ok for development)"))
(-> not-found-handler
wrap-websockets
server/wrap-transit-params
server/wrap-transit-response
(server/wrap-protect-origins {:allow-when-origin-missing? true
:legal-origins legal-origins})
(wrap-uris {"/" generate-index
"/index.html" generate-index})
(wrap-defaults defaults-config)
wrap-gzip)))The only thing different in the stack itself is switching from normal remoting to websockets.
The client change is also quite small: switch over to using websockets and send the page-embedded token with the websocket startup request:
(fc/make-fulcro-client
{:networking {:remote
(fws/make-websocket-networking
{:websockets-uri "/chsk"
:push-handler push-handler
;; we use params instead of Sente's ajax-options (which would be nice for setting headers)
;; because Sente doesn't use those for the initial socket request :(
;; Not ideal, since the CSRF token might end up stored in browser caches, proxy servers, etc.
;; Perhaps someone would make a PR to Sente?
:req-params {:csrf-token (or js/fulcro_network_csrf_token "TOKEN-NOT-IN-HTML!")}})}})You can play with this by cloning the complete source for this demo.
22. Internationalization
Fulcro has had internationalization support since inception. That original support worked well from the call-site; however, many lessons were learned about storing, transmitting, and structuring the actual data.
The support:
-
The ability to write UI strings in a default language/locale in the code. These are the defaults that are shown on the UI if no translation is available.
-
Supports string extraction from the compiled UI code.
-
The translator can use tools like POEdit to generate translation files
-
-
Leverages normal application state as the location to house loaded translations.
-
Allows the server to serve new locale translations via a normal query.
-
Includes server tools to directly read locales from GNU gettext PO files (no more code generation).
-
Supports a pluggable message formatting system.
22.1. The Core API
The following functions and macros make up the core of the API:
tr-
A macro that looks up the given string and returns the translation based on the current locale.
trc-
A macro that looks up the given string with a translation context (note to the translator) and returns the translation based on the current locale.
trf-
A macro that looks up the given string, and passes it and additional options through to a message formatter.
tr-unsafe-
All three of the above have an
unsafeversion. The main three require literal strings for their arguments because string extraction won’t work correctly otherwise. The unsafe versions are for situations where this is insufficient, but you still need some kind of marker to let you know where translation might be needed.
Examples:
(tr "Hello") ; might return "Hola"
(trc "Abbreviation for Male" "M") ; might return M (translator sees the other string as a note)
(trf "Hi {name}" {:name n}) ; passes a translated version of "Hi {name}" to the message formatter along with the options map.
(tr-unsafe current-selection) ; allows a non-literal to be sent through lookup. The possible values of current-selection will need to be extracted elsewhere.22.1.1. Dealing with "Unsafe" Usage
When you use an unsafe variant, it simply means that GNU gettext is not going to be able to extract a string
(because extraction is a static analysis of compiled code). One approach
is simply to make notes for your translator. That approach isn’t very scalable.
Usually, this comes up when you have something like a dropdown that needs to display translated strings. Another approach
is to simply call tr on the literal values in some unreachable code. Whitespace optimizations will not remove
these, so extraction will find them, whereas advanced optimizations will see that they are not directly called and
will remove them:
(defn do-not-call []
(tr "Yes") ; these are here for extraction only
(tr "No"))
(def options {:yes "Yes" :no "No"})
(defn render-option [o]
(tr-unsafe (get options o)))|
Warning
|
It is tempting to wrap the values of options in tr, but that is a bad idea.
|
(def options {:yes (tr "Yes") :no (tr "No")}) ; BAD IDEA!This is a problem because your program can break for unexpected reasons. If you changed the locale before
that code executed then your options map might contain the translations instead of the default locale keys
(e.g. {:yes "Oi" :no "Non"}) which are not the correct keys for the later calls to tr!
Remember that your string extraction is done against the real string you embed on the UI (your default locale), and those become the lookup keys for runtime. If you change those lookup keys based on the runtime locale, things will break.
22.2. Polyfills and Message Formatters
Fulcro’s i18n support is designed to make it easy to code and extract translatable strings in your UI. It is not, itself, interested in doing message, number, currency, or date formatting. There are plenty of libraries, including Google Closure, that can already fill that role.
The easiest pair to use for both server and client rendering are the FormatJS (client) and IBM ICU library (server). These two libraries follow the same formatting standards, and give good isomorphic rendering support.
Fulcro does one central task: it takes a string in the UI, looks up an alternate string (based on the locale) from a PO file, and pushes that alternate string through the rest of the i18n processing chain (which you define).
The macro:
(tr "Hello")will use the combination of the current locale and loaded locale data to return the correct translation for "Hello". A call to:
(trf "Hi {name}" {:name "Joe"})will look up "Hi {name}" in the translations, find something like "Hola, {name}", and will then pass that translation through to a message formatter that can substitute the supplied parameters for the placeholders.
For this to work you must load whatever polyfills and tools you need for message formatting, and then install your message formatter into Fulcro’s i18n system.
22.3. Configuring I18N
Your first step is to define a function that can format messages. If you want to use Yahoo’s FormatJS, then you’d add the FormatJS library as a script in your HTML, and then use something like this:
(ns appns
(:require [fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.i18n :as i18n :refer [tr trc trf]]))
(defn message-formatter [{:keys [::i18n/localized-format-string ::i18n/locale ::i18n/format-options]}]
(let [locale-str (name locale)
formatter (js/IntlMessageFormat. localized-format-string locale-str)]
(.format formatter (clj->js format-options))))The message formatter receives a single map with namespaced keys. The locale will be a keyword, the localized-format-string
will be the already-translated base string, and the format-options will be whatever map was passed along to trf.
Fulcro’s i18n uses shared properties to communicate the current locale, message formatter, and translations to the
UI components. This is a feature of the low-level reconciler.
When creating your client:
-
Include these options on the client:
(ns appns (:require [fulcro.client :as fc] [fulcro.i18n :as i18n])) (defn message-formatter ...) (defonce app (atom (fc/make-fulcro-client {:reconciler-options {:shared {::i18n/message-formatter message-formatter} :shared-fn ::i18n/current-locale}}}}))) -
Your
RootUI component MUST query for::i18n/current-localeand should also set the initial locale in application state. Theshared-fnextracts denormalized data from your UI root’s props. This also sets the "default" locale of your application.
22.4. Setting the "Default Locale"
Your root component should place a locale in the ::i18n/current-locale. This is normalized state, so the root
component query should join on the Locale component:
(defsc Root [this props]
{:query [{::i18n/current-locale (prim/get-query i18n/Locale)}]
:initial-state (fn [p] {::i18n/current-locale (prim/get-initial-state i18n/Locale {:locale :en :translations {}})})}22.5. Accessing the Current Locale
Shared properties are visible to all UI components via (prim/shared this). You will find the property ::i18n/current-locale
in there as well as your message formatter.
Mutations have the state database, and can simply look for the top-level key ::i18n/current-locale.
22.6. Changing the Locale
The are a few aspects to changing the locale:
-
Ensuring that the locale’s translations are loaded.
-
Changing the locale in app state.
-
Force rendering the entire UI to refresh displayed strings.
All of these tasks are handled for you by the i18n/change-locale mutation, which you can embed anywhere in your
application:
(prim/transact! this `[(i18n/change-locale {:locale :es})])There is a pre-built locale selector for your convenience.
22.7. Responding to Locale Loading Queries on Your Server
Of course, triggering a change locale that tries to load missing translations will fail if your server doesn’t respond to the query! Fortunately, configuring your server to serve these is very easy!
-
Place all of your
.pofiles on disk or in your applications classpath. The names of the PO files must beLOCALE.po, whereLOCALEmatches the locale keyword (minus the:), case sensitive. -
Add a root query like this:
(defquery-root ::i18n/translations
(value [env {:keys [locale]}]
(if-let [locale (i18n/load-locale "po-files" locale)]
locale
nil)))of course you can augment this to log errors or whatever else you want it to do. The "po-files" argument is the location
of the po files. If it is a relative path, the resources will be searched (CLASSPATH). If it is an absolute path, then
the local disk will be searched instead.
22.8. Extracting Strings
You can extract the strings from your UI for translation using GNU’s CLI utility xgettext (available via Brew, etc).
The steps are:
-
Compile your application with whitespace optimizations.
-
Run this on the resulting js file:
$ xgettext --from-code=UTF-8 --debug -k -ktr:1 -ktrc:1c,2 -ktrf:1 -o messages.pot application.js
22.9. Generating Locale Translation Files
See GNU’s gettext documentation for full details. Here are some basics:
Applications like POEdit can be used to generate a new locale from the messages.pot in the prior step.
Once you have the output (a file like es.po) you simply copy that to your server’s PO directory as described
in the section on serving locales.
When your application changes, you want to keep the existing translations. The gettext utility msgmerge is
useful for this. It takes the new messages.pot file and old PO files and generates new PO files that include
as many of the old translations as possible. This allows your translator to just deal with the changes.
Something like this will update a PO file:
$ msgmerge --force-po --no-wrap -U es.po messages.potAgain send that off to your translator, and when they return it place the updated PO file on your server.
22.10. Prebuilt Locale Selector
The i18n support comes with a convenient LocaleSelector component that you can use. You can, of course, write your
own and invoke the change-locale mutation, but the pre-written one can be used as follows:
(defsc Root [this {:keys [locale-selector]}]
{:query [{:locale-selector (prim/get-query i18n/LocaleSelector)}
{::i18n/current-locale (prim/get-query i18n/Locale)}]
:initial-state (fn [p] {::i18n/current-locale (prim/get-initial-state Locale {:locale :en :translations {}})
:locale-selector (prim/get-initial-state LocaleSelector
{:locales [(prim/get-initial-state Locale {:locale :en :name "English"})
(prim/get-initial-state Locale {:locale :es :name "Espanol"})
(prim/get-initial-state Locale {:locale :de :name "Deutsch"})]}}}
(dom/div
(i18n/ui-locale-selector locale-selector)
...))The initialization parameters are a list of the locales that are available on your server. You could, of course, load these at startup and fill out app state; however, since you have to know what locales you’re supporting in order to work with translators, it’s probably just as easy to hard-code them.
Each locale must be given a name (UTF8) to be show in the resulting select drop-down. This renders as an HTML select with the CSS class "fulcro$i18n$locale_selector".
See also src/cards/fulcro/democards/i18n_cards.cljs in the main Fulcro source.
22.11. Server-Side Rendering
Server side rendering of the default locale require no additinal code, because the strings you need are already the strings in the code. If you wish to pre-render a page using a specific locale then there is just a little bit more to do.
The steps are:
-
Load the locale from a po file.
-
Generate initial db to embed in the HTML that contains the proper normalized
::i18n/current-locale. -
Use
i18n/with-localeto wrap the server render.
(defn message-formatter ...) ; a server-side message formatter, e.g. use IBM's ICU library
(defn generate-index-html [state-db app-html]
(let [initial-state-script (ssr/initial-state->script-tag state-db)]
(str "<html><head>" initial-state-script "</head><body><div id='app'>" app-html "</div></body></html>")))
(defn index-html []
(let [initial-tree (prim/get-initial-state Root {})
es-locale (i18n/load-locale "po-directory" :es)
tree-with-locale (assoc initial-tree ::i18n/current-locale es-locale)
initial-db (ssr/build-initial-state tree-with-locale Root)
ui-root (prim/factory Root)]
(generate-index-html initial-db
(i18n/with-locale message-formatter es-locale
(dom/render-to-str (ui-root tree-with-locale))))))If you use Yahoo’s FormatJS on the client, then a good choice on the server is com.ibm.icu/icu4j since it uses the same syntax for format strings.
The message formatter could be:
(ns your-server-ns
(:import (com.ibm.icu.text MessageFormat)
(java.util Locale)))
(defn message-formatter [{:keys [::i18n/localized-format-string
::i18n/locale ::i18n/format-options]}]
(let [locale-str (name locale)]
(try
(let [formatter (new MessageFormat localized-format-string (Locale/forLanguageTag locale-str))]
(.format formatter format-options))
(catch Exception e
(log/error "Formatting failed!" e)
"???"))))23. Dev Cards and Workspaces
Devcards is an external library by Bruce Hauman that is also good for working up components, active documentation, or even complete applications piece by piece. Fulcro comes with a macro that makes embedding Fulcro Applications into a devcard trivial.
The Fulcro template now include Workspaces instead, but both are quite good. This chapter’s concepts apply equally to both.
23.1. The Project Setup
Simply include devcards in your dependencies:
[devcards "0.2.4"]and follow the basic setup instructions from that project’s documentation. Typically, a build configuration like this when using shadow-cljs:
:cards {:target :browser
:output-dir "resources/public/js/cards"
:asset-path "/js/cards"
:compiler-options {:devcards true}
:modules {:main {:entries [app.cards]}}
:devtools {:after-load app.cards/refresh
:preloads [fulcro.inspect.preload]
:http-root "resources/public"
:http-port 8023}}23.2. Developing Component UI
Developing simple components is done as described in the Devcard documentation. Fulcro encourages you to use pure rendering, so that means it is quick and easy to make cards that display UI components in all of their valid states. This is quite helpful when working out the data model and look of a component. If you use component-local CSS this can be an extremely effective way to quickly build up components for use in your application.
23.2.1. Visual Regression Testing
Developing components in cards allows you to also do a form of visual regression testing. The basic idea is to render the valid UI states for components, then have an automated script snapshot each card into an image that can be compared with later CI runs.
See AdStage’s blog for a detailed example of this with the code necessary to make it work.
23.3. Developing Active Screens
The defcard-fulcro macro can embed a Fulcro application in a card. It allows any client options
to be passed to the client, but generates the mount into the card internally. It looks like this:
(ns my-cards
(:require
[devcards.core :as dc :refer-macros [defcard defcard-doc]]
[fulcro.client.cards :refer [defcard-fulcro]]))
(defcard-fulcro symbol-for-card
AppRootUIComponent
{} ; initial state. Leave empty to use :initial-state from root component
{:inspect-data false ; normal devcard options
:fulcro { :client-did-mount (fn [app] ...)} ; fulcro client options
})23.3.1. Running Devcards Against a Real Server
Shadow-cljs and figwheel embed the hot loading websocket code into the compiled Javascript. This means that you can serve devcards from your real application server simply by making sure the HTML and Javascript for it are accessible through your server.
The Fulcro template even serves a dynamic /wslive.html to embed the CSRF token so that this works under the
security restrictions of your server.
This means that full-stack operations against your real application are trivial from within cards.
23.3.2. Splitting Your Application
Hopefully you see that the ability to embed a full-stack Fulcro client inside of a card is much more powerful than just embedding your entire application.
Remember, we have component normalization! The mutations and loads for any given part of your application work independent of how your UI is nested. This means that you can easily write your application in a way that allows you to factor it apart and embed just portions into devcards for localized development and testing!
We think this can be quite revolutionary to development, since it allows you to build up the application in completely dijoint steps and join them together once they’re ready!
(defsc ScreenOne [this props]
{:ident (fn [] [:screens/by-id :screen1])}
...)
(defmutation do-screen-1-thing [params]
(action [env]
; operations relative to ident of ScreenOne
...)
(defcard-fulcro screen-1
ScreenOne
{}
{:fulcro {:client-did-mount
(fn [app]
; code to establish the context (preloads) that the real application would have done for this screen
)}})Composition of the pieces can be as simple as dropping them into your UI router at the appropriate place!
23.4. Using External CSS via IFrames
If you need to have the content of a devcard use external CSS, then you can use the fulcro.client.elements/iframe
to do so. This cool little tool creates an iframe, but then uses React to render into from the parent page. This
gives you the isolation of an iframe with the convenience of single-page reasoning!
Here’s a quick function that can be used within a card to wrap UI that wants to use Bootstrap CSS:
(defn render-example [width height & children]
(ele/ui-iframe {:frameBorder 0 :height height :width width}
(apply dom/div {:key "example-frame-key"}
(dom/link {:rel "stylesheet" :href "/css/bootstrap.min.css"})
children)))this function can then be used to put a pre-sized iframe into a component like so:
(defsc NavRoot [this props]
{ :query [:boo]}
(render-example "100%" "150px"
(dom/div { :className "row" }
(dom/div {:className "col-md-1"}
...))))this can then be used within a devcard, keeping the external CSS from messing with the card layout or other cards.
24. Support Viewer
Fulcro automatically tracks the sequence of steps in the UI in history, including what transactions ran to move your application from state to state. This enables you to do time travel for things like debugging and error handling, but also allows you to serialize the history and send it to your servers for debugging sessions against real user interactions!
The viewer is already written for you, and is in the fulcro.support-viewer namespace. There are a few things you
have to do in order to make it work.
|
Warning
|
You must be careful to follow the rule that "only data goes in the database". Things like anonymous functions are not serializable, and therefore if you store them in app state you will break your ability to use history for things like support viewer. See the documentation on Transit for a description of the default types that are serializable and for some hints on how you can extend transit to support additional types. |
24.1. Sending a Support Request
There is a built-in mutation that can do this called fulcro.client.mutations/send-history. It can accept anything
as parameters, and will send the support request to :remote. All you have to do is run it via UI:
(transact! this `[(m/send-history {:support-id ~(prim/tempid)})])24.2. Storing the Support Request
Basically you just have to write something to handle the fulcro.client.mutations/send-history mutation, save the
data, and return a tempid remapping (optional, since the client itself won’t care):
(server/defmutation fulcro.client.mutations/send-history [params]
(action [env]
...save the history from params...
...send an email to a developer with the saved id?...))24.3. Using the Support Viewer
The support viewer is a simple UI that is pre-programmed in the fulcro.support-viewer namespace. When started, it
will issue a load in order to obtain the history you saved in the prior step. It will then run the application
(which you also have to point to) with that history in a DVR-style playback.
You can see how simple the
[client setup](https://github.com/fulcrologic/fulcro-todomvc/blob/master/src/main/fulcro_todomvc/support_viewer.cljs) is here, and
look at the defmutation for the send-history and query for :support-request in this file:
[Server API](https://github.com/fulcrologic/fulcro-todomvc/blob/master/src/main/fulcro_todomvc/api.clj)
24.4. Compressible Transactions
The compressible-transact! function support compressing transactions that would be otherwise annoying to step through. It works
as follows:
-
Use
compressible-transact!instead oftransact! -
If more than one adjacent transaction is marked compressible in history then only the last of them is kept.
The built-in mutations that set a value (e.g. m/set-value!) are meant to be used with user inputs and already mark their
transactions this way. This is quite useful when you don’t want to pollute (or overflow) history with keystrokes that
are not interesting.
24.5. Demo
See Fulcro TodoMVC for an example.
25. Code Splitting (modules)
Clojurescript 1.9.854+ has expanded support for code splitting (older versions do too, but require a bit more code). The main things you need to do to accomplish code splitting are:
-
Make sure your main app doesn’t accidentally refer to things in the module. Hard dependencies make it impossible to split the code.
-
Define a mechanism whereby your loaded code can find and install itself into the application.
Since you’re working with a data-driven application with components that have queries, this typically means that you’re going to need to have the newly loaded components somehow modify the main application’s query to tie them in. Also, since parents technically render children, you’re going to need to have an extensible mechanism for that as well.
To demonstrate one technique we’ll assume that what you load is a "section" of the application that can be routed to. The main application knows to provide the link, but it does not yet have the rendering factory, class, or query.
25.1. Dynamic Routing and Code Splitting
|
Warning
|
There was a bug in dynamic queries prior to 2.6.0, which are used by dynamic routers. Make sure you’re using a newer version of Fulcro for this support. |
The fulcro.client.routing namespace includes a second kind of UI router that can be used with the routing tree: DynamicRouter.
A DynamicRouter uses a dynamic query to change routes instead of a union, and it can derive the details of the target
component at runtime, meaning that it can be used to route to screens that were not in the loaded application code base
at start-time.
Furthermore, the routing tree has been designed to trigger the proper dynamic module loads for your dynamically loaded routes so that code splitting your application can be a fairly simple exercise. Here are the basic steps:
-
Pick a keyword for the name of a given screen. Say
:main -
Write the
defscfor that screen, and design it so that the TYPE (first element) of the ident is the keyword from (1).-
The initial state must be defined, and it must have the name (1) under the key r/dynamic-route-key
-
The bottom of the file that defines the target screen must include a
defmethodthat associates the keyword (1) with the component (2). This is how the dynamic router finds the initial state of the screen, and the query to route to. -
IMPORTANT: Your dynamically loaded screen MUST have a call to
(cljs.loader/set-loaded! KW)at the bottom of the file (where KW is from (1)).
-
-
Configure your cljs build to use modules. Place the screen from (2) into a module with the name from (1).
-
Use a DynamicRouter for the router that will route to the screen (2). This means you won’t have to explicitly refer to the class of the component.
-
The Query that composes in the router must use the special
get-dynamic-router-queryto join in the DynamicRouter’s query.
-
-
Create your routing tree as usual. Remember that a routing tree is just routing instructions (keywords).
If you are routing through a DynamicRouter as part of your initial startup, then there are a few more steps. See Pre-loaded routes below.
Trigger routing via the route-to mutation. That’s it! The module rooted at the screen will be automatically loaded
when needed.
The defsc and defmethod needed for step 2 look like this:
(prim/defsc Main [this {:keys [label]}]
{:initial-state (fn [params] {r/dynamic-route-key :main :label "MAIN"})
:ident (fn [] [:main :singleton])
:query [r/dynamic-route-key :label]}
(dom/div {:style {:backgroundColor "red"}}
label))
(defmethod r/get-dynamic-router-target :main [k] Main)
(cljs.loader/set-loaded! :main)25.1.1. Pre-loaded Routes
Screens used with DynamicRouter that are loaded at start-time are written identically to the dynamically loaded screen,
but you will have to make sure their state and multimethod are set up at load time. This can be done
via the mutation r/install-route. This mutation adds the screen’s state and multimethod component dispatch.
The demo application includes two such pre-installed routes (Login and NewUser), and one dynamically loaded one (main).
The code (called at application startup via :client-did-mount) to set up the pre-loaded routes and
is:
(defn application-loaded! [{:keys [reconciler]}]
; Let the dynamic router know that two of the routes are already loaded.
(prim/transact! reconciler `[(r/install-route {:target-kw :new-user :component ~NewUser})
(r/install-route {:target-kw :login :component ~Login})
(r/route-to {:handler :login})])
; Clojurescript requires you call this on every successfully "loaded" module:
(loader/set-loaded! :entry-point))
...
(make-fulcro-client Root {:client-did-mount application-loaded!})25.1.2. The Demo
Notice on initial load that the [:main :singleton] path in app state is not present. You could use the console to
verify that cards.dynamic_ui_main.Main is not present (via Javascript) either. Once you route to Main, both will be present.
You should see the network load of the code when you route as well. The book build configuration in project.clj has the module
definitions, and looks like this:
{:id "book"
:source-paths ["src/main" "src/book"]
:compiler {:output-dir "resources/public/js/book"
:asset-path "js/book"
:modules {:entry-point {:output-to "resources/public/js/book/book.js"
:entries #{book.main}}
; For the dynamic code splitting demo
:main {:output-to "resources/public/js/book/main-ui.js"
:entries #{book.demos.dynamic-ui-main}}}}}The HTML file to start this up must load the base CLJS module (js/book/cljs_base.js) and the entry point book.js file.
The other code will be in main-ui.js and will be loaded when you route to that screen.
The file dynamic_ui_main.cljs is the code that will be dynamically loaded. It looks like this:
(ns book.demos.dynamic-ui-main
(:require [fulcro.client.primitives :refer [defsc]]
[fulcro.client.routing :as r]
cljs.loader
[fulcro.client.dom :as dom]))
; This is a "screen" that we want to load with code-splitting modules. See the "demos" build in project.clj. The name
; of the module needs to match the first element of the ident, as that's how the dynamic router figures out what module
; to load.
(defsc Main [this {:keys [label main-prop]}]
{:query [r/dynamic-route-key :label :main-prop]
:initial-state (fn [params] {r/dynamic-route-key :main :label "MAIN" :main-prop "main page data"})
:ident (fn [] [:main :singleton])}
(dom/div {:style {:backgroundColor "red"}}
(str label " " main-prop)))
(defmethod r/get-dynamic-router-target :main [k] Main)
(cljs.loader/set-loaded! :main)The main entry point code is in the code below the demo:
(ns book.demos.dynamic-ui-routing
(:require [fulcro.client.routing :as r]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[cljs.loader :as loader]))
(defsc Login [this {:keys [label login-prop]}]
{:initial-state (fn [params] {r/dynamic-route-key :login :label "LOGIN" :login-prop "login data"})
:ident (fn [] [:login :singleton])
:query [r/dynamic-route-key :label :login-prop]}
(dom/div {:style {:backgroundColor "green"}}
(str label " " login-prop)))
(defsc NewUser [this {:keys [label new-user-prop]}]
{:initial-state (fn [params] {r/dynamic-route-key :new-user :label "New User" :new-user-prop "new user data"})
:ident (fn [] [:new-user :singleton])
:query [r/dynamic-route-key :label :new-user-prop]}
(dom/div {:style {:backgroundColor "skyblue"}}
(str label " " new-user-prop)))
(defsc Root [this {:keys [top-router :fulcro.client.routing/pending-route]}]
{:initial-state (fn [params] (merge
(r/routing-tree
(r/make-route :main [(r/router-instruction :top-router [:main :singleton])])
(r/make-route :login [(r/router-instruction :top-router [:login :singleton])])
(r/make-route :new-user [(r/router-instruction :top-router [:new-user :singleton])]))
{:top-router (prim/get-initial-state r/DynamicRouter {:id :top-router})}))
:query [:ui/react-key {:top-router (r/get-dynamic-router-query :top-router)}
:fulcro.client.routing/pending-route]}
(dom/div nil
; Sample nav mutations
(dom/a {:onClick #(prim/transact! this `[(r/route-to {:handler :main})])} "Main") " | "
(dom/a {:onClick #(prim/transact! this `[(r/route-to {:handler :new-user})])} "New User") " | "
(dom/a {:onClick #(prim/transact! this `[(r/route-to {:handler :login})])} "Login") " | "
(dom/div (if pending-route "Loading" "Done"))
(r/ui-dynamic-router top-router)))
; Use this as started-callback. These would happen as a result of module loads:
(defn application-loaded [{:keys [reconciler]}]
; Let the dynamic router know that two of the routes are already loaded.
(prim/transact! reconciler `[(r/install-route {:target-kw :new-user :component ~NewUser})
(r/install-route {:target-kw :login :component ~Login})
(r/route-to {:handler :login})])
(loader/set-loaded! :entry-point))25.2. Code Splitting and Server-Side Rendering
Version 2.5.2 of Fulcro added the support functions necessary to support server-side rendering of dynamic routes. The basics can be see in this example below:
One screen is defined in other.cljc:
(ns ssr-dynamic-routing.ui.other
(:require
#?(:cljs [cljs.loader :as loader])
#?(:cljs [fulcro.client.dom :as dom] :clj
[fulcro.client.dom-server :as dom])
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.routing :as r]))
(defsc Other [this {:keys [x]}]
{:query [r/dynamic-route-key :x]
:ident (fn [] [:other :singleton])
:initial-state (fn [_] {:x 1
r/dynamic-route-key :other})}
(dom/div nil (str "Other:" x)))
(defmethod r/get-dynamic-router-target :other [_] Other)
#?(:cljs (loader/set-loaded! :other))Another (with Root and the routing tree) is in main.cljc:
(ns ssr-dynamic-routing.ui.root
(:require
#?(:cljs [cljs.loader :as loader])
#?(:cljs [fulcro.client.dom :as dom] :clj
[fulcro.client.dom-server :as dom])
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.routing :as r]))
(def routing-tree (r/routing-tree
(r/make-route :main [(r/router-instruction :top-router [:main :singleton])])
(r/make-route :other [(r/router-instruction :top-router [:other :singleton])])))
(defsc Main [this {:keys [y]}]
{:query [r/dynamic-route-key :y]
:initial-state (fn [_] {r/dynamic-route-key :main
:y 3})
:ident (fn [] [:main :singleton])}
(dom/div (str "MAIN " y)))
(def ui-main (prim/factory Main))
(defsc Root [this {:keys [top-router]}]
{:query [{:top-router (r/get-dynamic-router-query :top-router)}]
:initial-state (fn [_] (merge
routing-tree
{r/dynamic-route-key :main
:top-router (prim/get-initial-state r/DynamicRouter {:id :top-router})}))}
(r/ui-dynamic-router top-router))
(defmethod r/get-dynamic-router-target :main [_] Main)
#?(:cljs (loader/set-loaded! :main))Notice that these look pretty much like what was described in the normal client stuff.
Next, the basic server is then:
(ns ssr-dynamic-routing.server
(:require
[ring.util.response :as resp]
[fulcro.easy-server :refer [make-fulcro-server]]
[fulcro.server-render :as ssr]
[ssr-dynamic-routing.ui.other :as other]
[ssr-dynamic-routing.ui.root :as root]
[fulcro.client.dom-server :as dom]
[fulcro.client.primitives :as prim]
[fulcro.client.routing :as r]))
(defn build-ui-tree [match]
(let [client-db (ssr/build-initial-state (prim/get-initial-state root/Root {}) root/Root)
final-db (-> client-db
;; CRITICAL: Install the routes, or their state won't be in the db
(r/install-route* :main root/Main)
(r/install-route* :other other/Other)
(r/route-to* match))]
;; CRITICAL: Pass the final database to get-query!!! Or you won't get the updated dynamic query
(prim/db->tree (prim/get-query root/Root final-db) final-db final-db)))
(defn server-side-render [env {:keys [handler] :as match}]
(let [ui-tree (build-ui-tree match)
html (dom/render-to-str ((prim/factory root/Root) ui-tree))]
(-> (resp/response (str
"<html><body><div id='app'>"
html
"</div></body></html>"))
(resp/content-type "text/html"))))
(defn build-server
[{:keys [config] :or {config "config/dev.edn"}}]
(make-fulcro-server
:parser-injections #{:config}
;; Quick way to hack a couple of pages in with different match handlers
:extra-routes {:routes ["/" {"main.html" :main
"other.html" :other}]
:handlers {:main server-side-render
:other server-side-render}}
:config-path config))We’re using the easy server extra routes system to serve the pages. These handlers conveniently return a map in
bidi match format, which can be used with route-to*. The critical pieces are marked:
-
Install the routes with
r/install-route*for each screen -
Use
route-to*to update the database to the correct desired route -
When you generate the UI tree with
db→tree, be sure to pass theget-querythe final db state after routing, otherwise the dynamic queries won’t be seen, and rendering will be incorrect.
26. Performance
Fulcro and React behave in a very performant manner for most data-driven applications. There are ways, however, in which you can negatively affect performance.
26.1. Development Compile Times
One of the most annoying performance problems when building your application is slow compile times. We all want sub-second rebuilds on our code base so that we can continue to work quickly. Here are some tips about keeping your compile times low:
-
Use shadow-cljs instead of the plain CLJS compiler. Especially if you plan on using external Javascript libraries from npm. The
lein new fulcro appcommand will get you a pre-configured template with everything set up. -
Keep your namespaces small, and
:requiresections pruned. This is about "size of code to compile", but it’s more about the dependency graph. Whenever a save happens that new file needs to be compiled along with everything that depends on it, and files that depend on those files up the dependency tree. Having large files and/or manyrequire`s means a high false-positive factor in these reloads (reloading files whose code didn’t really depend on what you changed). If a file has just a few artifacts (e.g. functions) per file then less code will depend on it and the recompile tree will be smaller for a given change. When you put large amounts of code in a single namespace then many of your other namespaces will likely depend on it (the probability of needing to `requireit goes up with the number of artifacts within it). Changing a single line of code in that large namespace not only will take a long time for that single namespace, but will trigger tons of unnecessary dependent recompiles. I’ve adopted this in my recent personal projects, and this successfully keeps my compile times quite low even as the source grows. Technically this could probably be solved at the compiler level, but it is a "hard problem" that may not be solved for some time (if ever). -
You might want to use a [linter](https://github.com/candid82/joker) to detect unused requires.
-
Keep the compiler up-to-date. I’ve seen 10-20% performance boosts in single releases.
26.2. Poor Query Performance
This is by far the most common source of performance issues in Fulcro UIs. Evaluating the UI query is relatively fast, but relative is the key word. The larger the query, the more work that has to be done to get the data for it. Remember that you compose all component queries to the root. If you do this with only joins and props, then your root query will ask for everything that your UI could ever show, on every frame! This will perform very badly as your application gets large.
The solution to this is to ensure that your query contains only the currently relevant things. There are a number of possible solutions for this, but the two most common are to use union or dynamic queries.
The fulcro.client.routing namespace includes primitives for building UI routes using unions (the unions are written
for you). It has a number of features, including the ability to nicely integrate with HTML5 history events for full HTML5
routing in your application.
In the dynamic query approach you use prim/set-query! to actually change the query of a component at runtime in
response to user events.
It is also important to note that you need not normalize things that are really just big blobs of data that you don’t intend to mutate. An example of this is large reports where the data is read-only. You could write a big nested bunch of components, normalize all of the parts, and write a query that joins it all back together; however, that incurs a lot of overhead both in loading the data, and every time you render.
Instead, realize that a property query like [:report-data] can pull any kind of (serializable, if you want
support viewer support) value from the
application state. You can put a js/Date there. You can put a map there. Anything. Furthermore, this query is super-fast
since it just pulls that big blob of data from app state and adds it to the result tree. Structural sharing makes that
fast.
26.3. Poor React Performance
In general Fulcro should be able to handle a pretty high frame-rate. In fact, the design is meant to facilitate 60FPS rendering. Remember, however, that there are a number of stages in rendering, and each of them has an overhead. Large UIs can have negative performance impacts at both the query and DOM layers.
Since React does your rendering it is best to understand how to best optimize it using their suggestions and documentation. Note
that Fulcro already ensures that shouldComponentUpdate is defined to an optimal value that should prevent even a regen/diff of VDOM
when data hasn’t changed.
Some general tips to start with in React are:
-
Make sure your components have a stable react key. If the key changes, React will ignore the diff and redo the DOM. This is very slow. So, if you’ve generated keys using something like random numbers just to get warnings to go away, then you’re asking for trouble.
-
You’re generally better off changing classes than DOM structure. For example, having a
(when render? (dom/div …))will cause entire sections to be inserted and removed from the DOM. Using a class is much more efficient:(dom/div {:className (str "" (when-not render? " hidden"))} …). -
Large DOM. React is pretty good with eliminating unnecessary changes, but that is still no reason to try to render a table with 1000’s of rows. Paginate.
27. Testing
Fulcro has a companion library called Fulcro Spec. It is a BDD DSL that wraps Clojure(script) test, and provides you with a number of helpful features:
-
A browser-based UI that can
-
Auto-refresh on code changes
-
Focus in on the tests of concern (you can define what that means)
-
Run client tests in any number of simultaneous browsers to detect browser differences
-
Run server-side tests through the same browser-based UI
-
-
A Mocking/expectation system
-
Outline-based specifications
-
All of the functions from
clojure.testwork inside of specifications (e.g.is,are, etc). -
It is easy to run specifications from CI systems. Try out the Leiningen template to get an application that is already set up to go.
27.1. Defining a Test Suite
The documentation for Fulcro Spec covers the full details. The same macro is used on both the client and server when defining a test suite, but there are a few other project details as well. The best source of a current example is the Fulcro Leiningen template, which emits a sample project that is set up with both client and server tests.
A client test suite’s configuration options include a namespace regex for finding your tests, and a map configuring the default and available test selectors (explained in a bit). Since the UI and the runner are the browser, there is really no other server component (other than your hot reload server from Figwheel or shadow-cljs):
(ns client.test-main
(:require
[fulcro-spec.selectors :as sel]
[fulcro-spec.suite :as suite]))
(def-test-suite spec-report
{:ns-regex #".*-spec"}
{:default #{::sel/none :focused}
:available #{:focused}})The spec-report symbol that gets defined represents a function that can be called to run the tests: (spec-report).
The server test suite creates its own websocket enable server to serve the test runner UI. The server tests have automatic code change detection, and the selected tests are automatically re-run and results sent to the client renderer. The setup is very simiar:
(ns user
(:require
[fulcro-spec.selectors :as sel]
[fulcro-spec.suite :as suite]))
(suite/def-test-suite server-tests
{:config {:port 8888}
:test-paths ["src/test"]
:source-paths ["src/main"]}
{:available #{:focused}
:default #{::sel/none :focused}})The macro defines a function (in this case server-tests) which when called (re)starts the websocket server
on the given port. Opening a browser on http://localhost:8888/fulcro-spec-server-tests.html will bring up the
user interface for those tests.
27.2. Specifications
A specification is just a helpful wrapper around clojure.test/deftest. It looks like this:
(specification "The thing you're testing"
...)It has several improvements to deftest:
-
The name is a string, encouraging better naming.
-
It establishes a section in the test runner view
-
It can include any number of keyword markers that indicate when the body of the test should run, allowing you to focus your test running on unit, integration, or just the current coding task:
27.2.1. Controlling Which Tests Run
Adding keywords after the string name of a specification marks that specification for targeting. You can define any number of these targeting keywords:
(specification "Some Database Operation" :integration :focused
...)An inactive specification’s body is skipped, leading to faster test suite run times when you’re focusing on a task.
When you define the test suite you define which of these selectors are defined, and which ones default to "on". For example a server test suite might be configured like this:
(ns user
(:require
[fulcro-spec.selectors :as sel]
[fulcro-spec.suite :as suite]))
(suite/def-test-suite my-tests
{ ...options... }
{:available #{:focused}
:default #{::sel/none :focused}})The special selector ::sel/none means "any specification that has no selectors". When you turn on/off selectors in the
UI (via the fold-out left panel) the rule is: Run any specification that includes at least one active selector. So,
turning off the "None" selector turns off all unmarked tests.
27.3. Behaviors, Components, and Assertions
These macros assist you in organizing your specification. The behavior and component macros just add an outline
entry and increase nesting in the report, aiding readability. The assertions macro can add descriptions for each assertion,
and gives a nice human-readable notation:
(specification "Math"
(component "Addition"
(assertions
"Works with positive integers"
(+ 1 1) => 2
"Works with negative integers"
(+ -2 -2) => -4)))27.4. Exceptions
It is common to want to test error handling code. The assertions macro supports checking for, and pattern-matching
against, exceptions. It supports several notations for the right-hand side.
The most platform-neutral syntax for exceptions is to use a map on the right-hand side which can contain the keys (all optional, but you should supply at least one):
...
(assertions
"Throws when arg is nil"
(f nil) =throws=> {:ex-type ExceptionInfo :regex #"Regex match on message" :fn (fn [e] true)}
...-
:ex-typeThe type of exception -
:regexA regular expression to compare against the exception’s message -
:fnA function that will receive the exception and can return true/false to indicate if it looks right.
27.5. Functional Assertions
Often you don’t need a data comparison as much as you need to run a predicate on the result of a function:
...
(assertions
"Returns odd numbers"
(f) =fn=> odd?)27.6. Mocking and Spies
One of the most important features of sustainable testing is the ability to test things in isolation. Any kind of coupling can result in cascading failures that make tests difficult to write/maintain/understand. Fulcro Spec has a mocking system that is concise and allows you to do a number of advanced things. The basic syntax looks like this:
(defn f [v] ...)
(defn g [] (f 1) 33)
(specification "g"
(let [real-f f] ; save f into a temporary binding
(when-mocking
(f arg) => (do ; rebinds `f` to this code
(real-f arg) ; spy! Call the real original f
(assertions
"calls f with 1"
arg => 1))
(g))))There’s a lot going on here. The when-mocking macro looks for any number of arrow-separated triples (like (f v) ⇒ 1)
and re-binds the real function to an internally scripted one that captures the arguments and makes them available to the
code on the right-hand side of the triple (see arg above).
The form to the right of the ⇒ is run instead of the original function, and it can make assertions on the args
or even invoke the original.
If you specify a mock and it isn’t called, then the specification will fail. Thus, a check that f is actually called
is also implied by this test!
27.6.1. Specifying Call Count
It may be useful (or even necessary) to specify the number of times a function is called when mocking. The default is "at least once". You can write a more complex scenario simply by adding a multiplier into the arrow!
(defn f [] 99)
(defn g [] (+ (f) (f))
(specification "g"
(assertions
"produces the sum of two calls to f (coupled to the real definition of f)"
(g) => 198))
(when-mocking
(f arg) => 2
(assertions
"produces the sum of two calls to f (mocking returns same thing over and over)"
(g) => 4))
(when-mocking
(f arg) =1x=> 2
(f arg) =1x=> 4
(assertions
"produces the sum of two calls to f (called exactly twice is enforced, and different values returned)"
(g) => 6)))27.6.2. Checking Order
When call counts are specified they imply order, and that order is checked as well by the internals of mocking. For
example a 1x mock of f, g, f will fail if f is called twice before g.
27.6.3. Limitations
Fulcro spec has some limitations that are inherent to the underlying programming language/VM.
-
It cannot mock inline, protocols, or macros.
-
You’re always creating "partial mocks". Expanding a function will often invalidate the mocking around it.
27.7. Visual Regression Testing
When you have immutable data, pure rendering, and devcards it isn’t too hard to create an automated testing suite that verifies your UI, without having to have ugly and hard-to-maintain browser drivers. The scheme is as follows:
-
Treat your UI components as animations that have a specific list of valid "key frames"
-
Each possible combination of input values results in a specific look
-
-
Create a devcard that statically renders the component with that state
-
Write a script that can drive a browser to jump from card to card, and screen shot the output
-
Have a human look at them and approve their look
-
Add the script to CI, and have it compare the "approved" images to the newly generated ones. If the image comparison fails, your UI changed. Have a human check that specific item and approve the change.
See the section on Dev Cards for more information.
28. Logging
Fulcro’s internal logging on the client and server are handled by a small set of logging functions. The logging itself can be modified to use any logging system that you wish to integrate, or you could choose to use the internal facility.
The internal facility is meant to be used for Fulcro and related libraries so that no external logging \ dependency is necessary.
You can plug in your own output function (which can format and send log messages however you wish).
The basic API is (assume cljc file):
(ns app
(:require [fulcro.logging :as log]))
(log/set-level! :error) ; prevent any logging messages except :error and :fatal
(log/set-logger! (fn [source-location log-level & args] (apply println args))) ; change the function that outputs the messages
(log/fatal "PROBLEM!") ; log a fatal error.
(log/debug "Doing something." [1 2 3] #{1 2} 22 "Hello" (ex-info "error" {})) ; log a debug message with a bunch of data|
Warning
|
Fulcro includes a legacy namespace (fulcro.client.logging) that should not be used.
|
28.1. Making Fulcro Log Through External Libraries
You can make this logging facility delegate to another via set-logger!. It’s as simple as something like:
(ns startup
(:require [taoensso.timbre :as timbre
fulcro.logging :as log]))
(log/set-logger!
(fn [{:keys [file line] :as location} level & args]
(timbre/log! level :p [args] {:?ns-str file :?line line})))Be sure you’re using your loggers low-level logging function, and not the macros. The macros will typically try
to extract the location using compile-time info, and the compile-time info of your call to set-logger! is of
little use in your actual logs. The macros in Fulcro’s internal logging will have already extracted the relevant
information into the location argument.
28.2. Eliding Logging Code
The set-level! function changes runtime behavior of logging statements in the code base; however, you may wish
to completely remove logging statements from your production code below certain levels like debug.
The logging library will remove logging statements from code if you specify the JVM argument -Dfulcro.logging=<level>,
where <level> is a level like debug or error. Logging statements below that level will not generate code
in the resulting compiled program.
Of course, if you’ve removed logging statements this way then set-level! cannot magically re-add them. Therefore
using -Dfulcro.logging=error and doing (set-level! :debug) at runtime is not going to suddenly re-add the debug
logging statements.
29. Deploying to Heroku
As an example of sending a complete Fulcro application to the cloud we’ll walk you through the steps to put an application up on Heroku.
Here are the things you need to do:
-
Set up server to pull the web port from the PORT environment variable (using EDN)
-
Make sure
:min-lein-versionis in your project file -
Include a Procfile
-
Use the clojure build pack (should be auto-detected)
29.1. Setting PORT
Fulcro server’s PORT can be configured from the environment as follows:
{ :port :env.edn/PORT }place that in a file on your classpath, such as src/config/prod.edn (if src is your base source code directory). You
could also use resources (which is technically more correct).
29.2. Minimum lein version
Heroku (at the time of this writing) defaults to lein version 1.7.x. This is almost certainly not what you want.
29.3. Include a Profile
If you’re building an uberjar from one of our template projects, using Fulcro Server, and you’ve set up a config file as described above, then the following Procfile should work for you:
web: java $JVM_OPTS -Dconfig=config/prod.edn -jar target/uberjar-name.jar\n29.4. Use a Clojure Build Pack
Just follow the directions when adding a project. We’ve only used the git deployment method. Make sure you don’t have
a generated pom.xml as well as a project.clj file, or your project might get built using Maven instead of Lein.
29.5. Sample Project
The fulcro-template is pre-configured for easy deployment to Heroku.
30. Converting HTML to Fulcro
This chapter has a simple little live application that can convert valid HTML into the Clojure(script) you’d use
within a Fulcro component. Note that stray whitespace will be converted to (harmless) things like " \n" that can be easily
removed, and the output indentation isn’t ideal; Still, it turns the task into one of simple formatting:
(ns book.html-converter
(:require
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.mutations :as m :refer [defmutation]]
[hickory.core :as hc]
[clojure.set :as set]
[clojure.pprint :refer [pprint]]
[clojure.string :as str]))
(def attr-renames {
:class :className
:for :htmlFor
:tabindex :tabIndex
:viewbox :viewBox
:spellcheck :spellcheck
:autocorrect :autoCorrect
:autocomplete :autoComplete})
(defn elem-to-cljs [elem]
(cond
(and (string? elem)
(let [elem (str/trim elem)]
(or
(= "" elem)
(and
(str/starts-with? elem "<!--")
(str/ends-with? elem "-->"))
(re-matches #"^[ \n]*$" elem)))) nil
(string? elem) (str/trim elem)
(vector? elem) (let [tag (name (first elem))
attrs (set/rename-keys (second elem) attr-renames)
children (keep elem-to-cljs (drop 2 elem))]
(concat (list (symbol "dom" tag) attrs) children))
:otherwise "UNKNOWN"))
(defn to-cljs
"Convert an HTML fragment (containing just one tag) into a corresponding Dom cljs"
[html-fragment]
(let [hiccup-list (map hc/as-hiccup (hc/parse-fragment html-fragment))]
(first (map elem-to-cljs hiccup-list))))
(defmutation convert [p]
(action [{:keys [state]}]
(let [html (get-in @state [:top :conv :html])
cljs (to-cljs html)]
(swap! state assoc-in [:top :conv :cljs] {:code cljs}))))
(defsc HTMLConverter [this {:keys [html cljs]}]
{:initial-state (fn [params] {:html "<div id=\"3\" class=\"b\"><p>Paragraph</p></div>" :cljs {:code (list)}})
:query [:cljs :html]
:ident (fn [] [:top :conv])}
(dom/div {:className ""}
(dom/textarea {:cols 80 :rows 10
:onChange (fn [evt] (m/set-string! this :html :event evt))
:value html})
(dom/pre {} (with-out-str (pprint (:code cljs))))
(dom/button :.c-button {:onClick (fn [evt]
(prim/transact! this `[(convert {})]))} "Convert")))
(def ui-html-convert (prim/factory HTMLConverter))
(defsc Root [this {:keys [converter]}]
{:initial-state {:converter {}}
:query [{:converter (prim/get-query HTMLConverter)}]}
(ui-html-convert converter))31. Demos
This chapter includes some additional running demos with source that will give you insight on how to approach various problems. Remember that the server latency can be set using the controls in the upper-right corner in the live HTML version, so you can more easily watch state changes during server interactions.
31.1. Autocomplete
A fairly common desire in user interfaces is to try to help the user complete an input by querying the server or possible completions. Like many of the demos, the UI for this example is intentionally very bare-bones so that we can primarily concentrate on the data-flow that you’ll want to use to achieve the effect.
Typically you will want to trigger autocomplete on a time interval (e.g. using goog.functions/debounce)
or after some number of characters have been entered into the field. We’re going to implement it in the
following way:
-
The autocomplete query will trigger when the input has at least 2 characters of input.
-
The server will be asked for 10 suggestions, and will update on a debounced interval.
-
The autocomplete suggestion list will clear if length goes below 2
-
The user must use the mouse to select the desired completion (we’re not handling keyboard events)
31.1.1. Basic Operation
The basic idea is as follows:
-
Make a component that has isolated state, so you can have more than one
-
Decide when to trigger the server query
-
Use load, but target it for a place that is not on the UI
-
Allows the UI to continue displaying old list while new load is in progress
-
Use a post-mutation to move the finished load into place
-
31.1.2. The Server Query
For our server we have a simple list of all of the airports in the world that have 3-letter codes. Our server just grabs 10 that match your search string:
(defn airport-search [s]
(->> airports
(filter (fn [i] (str/includes? (str/lower-case i) (str/lower-case s))))
(take 10)
vec))
(defquery-root :autocomplete/airports
(value [env {:keys [search]}] (airport-search search)))31.1.3. The UI and Post Mutation
We create a helper function so we don’t have to manually generate the ident for autocomplete wherever we need it:
(defn autocomplete-ident
"Returns the ident for an autocomplete control. Can be passed a map of props, or a raw ID."
[id-or-props]
(if (map? id-or-props)
[:autocomplete/by-id (:db/id id-or-props)]
[:autocomplete/by-id id-or-props]))We use Google Closure’s debounce to generate a function that will not bash the server too hard. Load’s will run at most
once every 500ms. Notice that the server query itself is for airport suggestions, and we use the :target option
to place the results in our autocomplete’s field:
(def get-suggestions
"A debounced function that will trigger a load of the server suggestions into a temporary locations and fire
a post mutation when that is complete to move them into the main UI view."
(letfn [(load-suggestions [component new-value id]
(df/load component :autocomplete/airports nil
{:params {:search new-value}
:post-mutation `populate-loaded-suggestions
:post-mutation-params {:id id}
:target (conj (autocomplete-ident id) :autocomplete/loaded-suggestions)}))]
(gf/debounce load-suggestions 500)))Notice when we trigger the load it goes into the auto-complete widget’s :autocomplete/loaded-suggestions field.
The UI renders the :autocomplete/suggestions. We do this so we can continue filtering the list as they type
independently of the load, but at the end of the load we need to update the suggestions. We do this by running a post
mutation (see the demo source).
The running demo (with source) is below:
(ns book.demos.autocomplete
(:require
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[fulcro.client :as fc]
[fulcro.client.mutations :as m]
[fulcro.server :as s]
[fulcro.client.data-fetch :as df]
[book.demos.airports :refer [airports]]
[clojure.string :as str]
[devcards.core :as dc :include-macros true]
[goog.functions :as gf]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn airport-search [s]
(->> airports
(filter (fn [i] (str/includes? (str/lower-case i) (str/lower-case s))))
(take 10)
vec))
(s/defquery-root :autocomplete/airports
(value [env {:keys [search]}]
(airport-search search)))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn autocomplete-ident
"Returns the ident for an autocomplete control. Can be passed a map of props, or a raw ID."
[id-or-props]
(if (map? id-or-props)
[:autocomplete/by-id (:db/id id-or-props)]
[:autocomplete/by-id id-or-props]))
(defsc CompletionList [this {:keys [values onValueSelect]}]
(dom/ul nil
(map (fn [v]
(dom/li {:key v}
(dom/a {:href "javascript:void(0)" :onClick #(onValueSelect v)} v))) values)))
(def ui-completion-list (prim/factory CompletionList))
(m/defmutation populate-loaded-suggestions
"Mutation: Autocomplete suggestions are loaded in a non-visible property to prevent flicker. This is
used as a post mutation to move them to the active UI field so they appear."
[{:keys [id]}]
(action [{:keys [state]}]
(let [autocomplete-path (autocomplete-ident id)
source-path (conj autocomplete-path :autocomplete/loaded-suggestions)
target-path (conj autocomplete-path :autocomplete/suggestions)]
(swap! state assoc-in target-path (get-in @state source-path)))))
(def get-suggestions
"A debounced function that will trigger a load of the server suggestions into a temporary locations and fire
a post mutation when that is complete to move them into the main UI view."
(letfn [(load-suggestions [comp new-value id]
(df/load comp :autocomplete/airports nil
{:params {:search new-value}
:marker false
:post-mutation `populate-loaded-suggestions
:post-mutation-params {:id id}
:target (conj (autocomplete-ident id) :autocomplete/loaded-suggestions)}))]
(gf/debounce load-suggestions 500)))
(defsc Autocomplete [this {:keys [db/id autocomplete/suggestions autocomplete/value] :as props}]
{:query [:db/id ; the component's ID
:autocomplete/loaded-suggestions ; A place to do the loading, so we can prevent flicker in the UI
:autocomplete/suggestions ; the current completion suggestions
:autocomplete/value] ; the current user-entered value
:ident (fn [] (autocomplete-ident props))
:initial-state (fn [{:keys [id]}] {:db/id id :autocomplete/suggestions [] :autocomplete/value ""})}
(let [field-id (str "autocomplete-" id) ; for html label/input association
;; server gives us a few, and as the user types we need to filter it further.
filtered-suggestions (when (vector? suggestions)
(filter #(str/includes? (str/lower-case %) (str/lower-case value)) suggestions))
; We want to not show the list if they've chosen something valid
exact-match? (and (= 1 (count filtered-suggestions)) (= value (first filtered-suggestions)))
; When they select an item, we place it's value in the input
onSelect (fn [v] (m/set-string! this :autocomplete/value :value v))]
(dom/div {:style {:height "600px"}}
(dom/label {:htmlFor field-id} "Airport: ")
(dom/input {:id field-id
:value value
:onChange (fn [evt]
(let [new-value (.. evt -target -value)]
; we avoid even looking for help until they've typed a couple of letters
(if (>= (.-length new-value) 2)
(get-suggestions this new-value id)
; if they shrink the value too much, clear suggestions
(m/set-value! this :autocomplete/suggestions []))
; always update the input itself (controlled)
(m/set-string! this :autocomplete/value :value new-value)))})
; show the completion list when it exists and isn't just exactly what they've chosen
(when (and (vector? suggestions) (seq suggestions) (not exact-match?))
(ui-completion-list {:values filtered-suggestions :onValueSelect onSelect})))))
(def ui-autocomplete (prim/factory Autocomplete))
(defsc AutocompleteRoot [this {:keys [airport-input]}]
{:initial-state (fn [p] {:airport-input (prim/get-initial-state Autocomplete {:id :airports})})
:query [{:airport-input (prim/get-query Autocomplete)}]}
(dom/div
(dom/h4 "Airport Autocomplete")
(ui-autocomplete airport-input)))31.2. Using Unions to Switch out UI Elements
This demo is similar to the example in the section on unions. In fact, the two could be combined to make this one polymorphic as well, but the primary interest in this demo is to show swapping between an editor and a list (or table).
This example uses forms support with a custom submit and cancel mutation. It is instructive to see how entities could be loaded (simulated in the client-did-mount) as pristine entities and augmented with form support through mutations that have a nice clear meaning (to both front and back-end).
See the comments on the source for more details.
(ns book.queries.union-example-2
(:require [fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.cards :refer [defcard-fulcro]]
[fulcro.client :as fc]
[fulcro.client.routing :as r :refer [defrouter]]
[fulcro.client.mutations :refer [defmutation]]
[book.macros :refer [defexample]]
[fulcro.ui.bootstrap3 :as b]
[fulcro.ui.elements :as ele]
[fulcro.ui.forms :as f]))
(defn person-ident
"Generate an ident from a person."
[id-or-props]
(if (map? id-or-props)
[:person/by-id (:db/id id-or-props)]
[:person/by-id id-or-props]))
(declare PersonForm)
(defmutation edit-person
"Fulcro mutation: Edit the person with the given ID."
[{:keys [id]}]
(action [{:keys [state] :as env}]
(swap! state (fn [s]
(-> s
; change the route. This just points the routers via ident changes
(r/update-routing-links {:handler :editor :route-params {:id id}})
; make sure the form has form support installed
(f/init-form PersonForm (person-ident id)))))))
(defmutation cancel-edit
"Fulcro mutation: Cancel an edit."
[no-args-needed]
(action [{:keys [state] :as env}]
(let [ident-of-person-being-edited (r/current-route @state :listform-router)]
(swap! state (fn [s]
(-> s
; change the route
(r/update-routing-links {:handler :people})
; clear any edits on the person (this is non-recursive)
(update-in ident-of-person-being-edited f/reset-entity)))))))
(defmutation submit-person
"Fulcro mutation: An example of a custom form submit, composing other operations into the submit."
[{:keys [form]}] ; form is passed in from UI to close over it. See dev guide for why.
(action [{:keys [state]}]
(let [ident-of-person-being-edited (r/current-route @state :listform-router)]
(swap! state (fn [s]
(-> s
; non-recursive. if using subforms see dev guide
(update-in ident-of-person-being-edited f/commit-state)
(r/update-routing-links {:handler :people})))))))
(defn make-person [id n] {:db/id id :person/name n})
(defsc PersonForm [this {:keys [db/id person/name] :as form-props}]
{:ident (fn [] (person-ident form-props))
:query [:db/id :person/name f/form-key f/form-root-key]
:protocols [static f/IForm
(form-spec [this] [(f/id-field :db/id)
(f/text-input :person/name)])]}
(b/form-horizontal nil
(b/labeled-input {:split 4
:input-generator (fn [_] (f/form-field this form-props :person/name))} "Name:")
(b/labeled-input {:split 4
:input-generator (fn [_]
(dom/div
; the follow-on read of :root/router ensures re-render from the router level
(b/button {:onClick #(prim/transact! this `[(cancel-edit {}) :root/router])} "Cancel")
(b/button {:onClick #(prim/transact! this `[(submit-person {:form form-props}) :root/router])} "Save")))} "")))
(defsc PersonListItem [this {:keys [db/id person/name] :as props}]
{:ident (fn [] (person-ident props))
:query [:db/id :person/name]}
; the follow-on read of :root/router ensures re-render from the router level
(dom/li {:onClick #(prim/transact! this `[(edit-person {:id ~id}) :root/router])}
(dom/a {:href "javascript:void(0)"} name)))
(def ui-person (prim/factory PersonListItem {:keyfn :db/id}))
(def person-list-ident [:person-list/table :singleton])
(defsc PersonList [this {:keys [people]}]
{:initial-state (fn [p] {:people []})
:query [{:people (prim/get-query PersonListItem)}]
:ident (fn [] person-list-ident)}
(dom/div
(dom/h4 "People")
(dom/ul
(map (fn [i] (ui-person i)) people))))
(defrouter PersonListOrForm :listform-router
(fn [this props]
(if (contains? props :people)
person-list-ident
(person-ident props)))
; if the router points to a person list entity, render with a PersonList. This is the default route.
:person-list/table PersonList
; if the router points to a person entity, render with PersonForm
:person/by-id PersonForm)
(def ui-person-list-or-form (prim/factory PersonListOrForm))
(defsc Root [this {:keys [ui/react-key root/router] :as props}]
{:query [:ui/react-key {:root/router (prim/get-query PersonListOrForm)}]
:initial-state (fn [p] (merge
; This data is used by the `update-routing-links` functions to switch routes (union idents on the router's current route)
(r/routing-tree
; switch to the person list
(r/make-route :people [(r/router-instruction :listform-router person-list-ident)])
; switch to the given person (id is passed to update-routing-links and become :param/id)
(r/make-route :editor [(r/router-instruction :listform-router (person-ident :param/id))]))
{:root/router (prim/get-initial-state PersonListOrForm nil)}))}
; embed in iframe so we can use bootstrap css easily
(ele/ui-iframe {:frameBorder 0 :height "300px" :width "100%"}
(dom/div {:key react-key}
(dom/style ".boxed {border: 1px solid black}")
(dom/link {:rel "stylesheet" :href "bootstrap-3.3.7/css/bootstrap.min.css"})
(b/container-fluid {}
(ui-person-list-or-form router)))))
(defexample "Unions as View/Edit Routers" Root "union-example-2"
:started-callback (fn [{:keys [reconciler]}]
; simulate a load of people via a simple integration of some tree data
(prim/merge-component! reconciler PersonList {:people [(make-person 1 "Tony")
(make-person 2 "Sally")
(make-person 3 "Allen")
(make-person 4 "Luna")]})))31.3. Cascading Dropdowns
A common UI desire is to have dropdowns that cascade. I.e. a dropdown populates in response to a selection in an earlier dropdown, like Make/Model for cars. This can be done quite easily.
The basic implementation is as follows:
-
Define dropdowns that can display the items
-
Don’t initialize the extra ones with items
-
When the first one is given a selection, load the next one
A couple of simple implementation details are needed:
-
We’re using bootstrap dropdowns, and we need to know where they normalize their data. Looking at the data inspector for the card makes this easy to see. For example, we can see that items are stored in the
:bootstrap.dropdown/by-idtable, in the:fulcro.ui.bootstrap3/itemscolumn. -
The IDs of the dropdowns (which we generate)
On the server, we define the query handler as follows (remember you can affect the server latency with the server controls to watch things happen):
(defquery-root :models
(value [env {:keys [make]}]
(case make
:ford [(bs/dropdown-item :escort "Escort")
(bs/dropdown-item :F-150 "F-150")]
:honda [(bs/dropdown-item :civic "Civic")
(bs/dropdown-item :accort "Accord")])))and we define a mutation for showing a "Loading…" item in the dropdown that is loading as:
(defmutation show-list-loading
"Change the items of the dropdown with the given ID to a single item that indicates Loading..."
[{:keys [id]}]
(action [{:keys [state]}]
(swap! state assoc-in
[:bootstrap.dropdown/by-id id :fulcro.ui.bootstrap3/items]
[(assoc (bs/dropdown-item :loading "Loading...") :fulcro.ui.bootstrap3/disabled? true)])))The main action is in the onSelect of the first dropdown, which just issues the transact to set the loading
visualization, followed by the remote load.
(ns book.demos.cascading-dropdowns
(:require
[fulcro.ui.bootstrap3 :as bs]
[fulcro.logging :as log]
[fulcro.client.data-fetch :as df]
[fulcro.ui.bootstrap3 :as bs]
[fulcro.client.mutations :refer [defmutation]]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.server :as server]
[fulcro.ui.elements :as ele]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Server
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(server/defquery-root :models
(value [env {:keys [make]}]
(case make
:ford [(bs/dropdown-item :escort "Escort")
(bs/dropdown-item :F-150 "F-150")]
:honda [(bs/dropdown-item :civic "Civic")
(bs/dropdown-item :accort "Accord")])))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; Client
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn render-example
"Wrap an example in an iframe so we can load external CSS without affecting the containing page."
[width height & children]
(ele/ui-iframe {:frameBorder 0 :height height :width width}
(apply dom/div {:key "example-frame-key"}
(dom/style ".boxed {border: 1px solid black}")
(dom/link {:rel "stylesheet" :href "bootstrap-3.3.7/css/bootstrap.min.css"})
children)))
(defmutation show-list-loading
"Change the items of the dropdown with the given ID to a single item that indicates Loading..."
[{:keys [id]}]
(action [{:keys [state]}]
(swap! state assoc-in
[:bootstrap.dropdown/by-id id :fulcro.ui.bootstrap3/items]
[(assoc (bs/dropdown-item :loading "Loading...") :fulcro.ui.bootstrap3/disabled? true)])))
(defsc Root [this {:keys [make-dropdown model-dropdown]}]
{:initial-state (fn [params]
{:make-dropdown (bs/dropdown :make "Make" [(bs/dropdown-item :ford "Ford")
(bs/dropdown-item :honda "Honda")])
; leave the model items empty
:model-dropdown (bs/dropdown :model "Model" [])})
:query [; initial state for two Bootstrap dropdowns
{:make-dropdown (prim/get-query bs/Dropdown)}
{:model-dropdown (prim/get-query bs/Dropdown)}]}
(let [{:keys [:fulcro.ui.bootstrap3/items]} model-dropdown]
(render-example "200px" "200px"
(dom/div
(bs/ui-dropdown make-dropdown
:onSelect (fn [item]
; Update the state of the model dropdown to show a loading indicator
(prim/transact! this `[(show-list-loading {:id :model})])
; Issue the remote load. Note the use of DropdownItem as the query, so we get proper normalization
; The targeting is used to make sure we hit the correct dropdown's items
(df/load this :models bs/DropdownItem {:target [:bootstrap.dropdown/by-id :model :fulcro.ui.bootstrap3/items]
; don't overwrite state with loading markers...we're doing that manually to structure it specially
:marker false
; A server parameter on the query
:params {:make item}}))
:stateful? true)
(bs/ui-dropdown model-dropdown
:onSelect (fn [item] (log/info item))
:stateful? true)))))31.4. Loading due to a UI Event
Tabbed interfaces typically use a UI Router (which can be further integrated into HTML5 routing as a routing tree). See this YouTube video for more details.
This example not only shows the basic construction of an interface that allows content (and query) to be switched, it also demonstrates how one goes about triggering loads of data that some screen might need.
If you look at the source for the root component you’ll see two buttons with transactions on their click handlers.
(defsc Root [this {:keys [current-tab] :as props}]
; Construction MUST compose to root, just like the query. The resulting tree will automatically be normalized into the
; app state graph database.
{:initial-state (fn [params] {:ui/react-key "initial" :current-tab (prim/get-initial-state UITabs nil)})
:query [{:current-tab (prim/get-query UITabs)}]}
(dom/div
; The selection of tabs can be rendered in a child, but the transact! must be done from the parent (to
; ensure proper re-render of the tab body). See prim/computed for passing callbacks.
(dom/button {:onClick #(prim/transact! this `[(choose-tab {:tab :main})])} "Main")
(dom/button {:onClick #(prim/transact! this `[(choose-tab {:tab :settings})
; extra mutation: sample of what you would do to lazy load the tab content
(lazy-load-tab {:tab :settings})])} "Settings")
(ui-tabs current-tab)))The first is simple enough: run a mutation that chooses which tab to show. The routing library includes a helper function for building that, so the mutation just looks like this:
(m/defmutation choose-tab [{:keys [tab]}]
(action [{:keys [state]}] (swap! state r/set-route* :ui-router [tab :tab])))The transaction to go to the settings tab is more interesting. It switches tabs but also runs another mutation to load data needed for that screen. The intention is to just load it if it is missing. That mutation looks like this:
(defn missing-tab? [state tab] (empty? (-> @state :settings :tab :settings)))
(m/defmutation lazy-load-tab [{:keys [tab]}]
(action [{:keys [state] :as env}]
(when (missing-tab? state tab)
(df/load-action state :all-settings SomeSetting
{:target [:settings :tab :settings]
:refresh [:settings]})))
(remote [{:keys [state] :as env}]
(when (missing-tab? state tab) (df/remote-load env))))Fairly standard fare at this point: Look at the database to see if it has what you want, and if not trigger a load
with df/load-action (on the action side) and df/remote-load on the remote.
(ns book.demos.loading-in-response-to-UI-routing
(:require
[fulcro.client.routing :as r]
[fulcro.client.mutations :as m]
[fulcro.client.dom :as dom]
[fulcro.client.primitives :as prim :refer [defsc InitialAppState initial-state]]
[fulcro.client.data-fetch :as df]
[fulcro.server :as server]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(server/defquery-root :all-settings
"This is the only thing we wrote for the server...just return some value so we can see it really talked to the server for this query."
(value [env params]
[{:id 1 :value "Gorgon"}
{:id 2 :value "Thraser"}
{:id 3 :value "Under"}]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defsc SomeSetting [this {:keys [id value]}]
{:query [:ui/fetch-state :id :value]
:ident [:setting/by-id :id]}
(dom/p nil "Setting " id " from server has value: " value))
(def ui-setting (prim/factory SomeSetting {:keyfn :id}))
(defsc SettingsTab [this {:keys [settings-content settings]}]
{:initial-state {:kind :settings
:settings-content "Settings Tab"
:settings []}
; This query uses a "link"...a special ident with '_ as the ID. This indicates the item is at the database
; root, not inside of the "settings" database object. This is not needed as a matter of course...it is only used
; for convenience (since it is trivial to load something into the root of the database)
:query [:kind :settings-content {:settings (prim/get-query SomeSetting)}]}
(dom/div nil
settings-content
(df/lazily-loaded (fn [] (map ui-setting settings)) settings)))
(defsc MainTab [this {:keys [main-content]}]
{:initial-state {:kind :main :main-content "Main Tab"}
:query [:kind :main-content]}
(dom/div nil main-content))
(r/defrouter UITabs :ui-router
(ident [this {:keys [kind]}] [kind :tab])
:main MainTab
:settings SettingsTab)
(def ui-tabs (prim/factory UITabs))
(m/defmutation choose-tab [{:keys [tab]}]
(action [{:keys [state]}] (swap! state r/set-route :ui-router [tab :tab])))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; LAZY LOADING TAB CONTENT
;; This is the shape of what to do. We define a method that can examine the
;; state to decide if we want to trigger a load. Then we define a mutation
;; that the UI can call during transact (see the transact! call for Settings on Root in ui.cljs).
;; The mutation itself (app/lazy-load-tab) below uses a data-fetch helper function to
;; set :remote to the right thing, and can then give one or more load-data-action's to
;; indicate what should actually be retrieved. The server implementation is trivial in
;; this case. See api.clj.
;; When to consider the data missing? Check the state and find out.
(defn missing-tab? [state tab]
(let [settings (-> @state :settings :tab :settings)]
(or (not (vector? settings))
(and (vector? settings) (empty? settings)))))
(m/defmutation lazy-load-tab [{:keys [tab]}]
(action [{:keys [state] :as env}]
; Specify what you want to load as one or more calls to load-action (each call adds an item to load):
(when (missing-tab? state tab)
(df/load-action env :all-settings SomeSetting
{:target [:settings :tab :settings]
:refresh [:settings]})))
(remote [{:keys [state] :as env}]
(df/remote-load env)))
(defsc Root [this {:keys [current-tab] :as props}]
; Construction MUST compose to root, just like the query. The resulting tree will automatically be normalized into the
; app state graph database.
{:initial-state (fn [params] {:current-tab (prim/get-initial-state UITabs nil)})
:query [{:current-tab (prim/get-query UITabs)}]}
(dom/div
; The selection of tabs can be rendered in a child, but the transact! must be done from the parent (to
; ensure proper re-render of the tab body). See prim/computed for passing callbacks.
(dom/button {:onClick #(prim/transact! this `[(choose-tab {:tab :main})])} "Main")
(dom/button {:onClick #(prim/transact! this `[(choose-tab {:tab :settings})
; extra mutation: sample of what you would do to lazy load the tab content
(lazy-load-tab {:tab :settings})])} "Settings")
(ui-tabs current-tab)))31.5. Paginating Large Lists
This demo is showing a (dynamically generated) list of items. The server can generate any number of them, so you can page ahead as many times as you like. Each page is dynamically loaded if and only if the browser does not already have it. The demo also ensures you cannot run out of browser memory by removing items and pages that are more than 4 steps away from your current position. You can demostrate this by moving ahead by more than 4 pages, then page back 5. You should see a reload of that early page when you go back to it.
The UI of this example is a great example of how a complex application behavior remains very very simple at the UI layer with Fulcro.
We represent the list items as you might expect:
(defsc ListItem [this {:keys [item/id]}]
{:query [:item/id :ui/fetch-state]
:ident [:items/by-id :item/id]}
(dom/li (str "Item " id)))We then generate a component to represent a page of them. This allows us to associate the items on a page with a particular component, which makes tracking the page number and items on that page much simpler:
(defsc ListPage [this {:keys [page/number page/items]}]
{:initial-state {:page/number 1 :page/items []}
:query [:page/number {:page/items (prim/get-query ListItem)}]
:ident [:page/by-number :page/number]}
(dom/div
(dom/p "Page number " number)
(df/lazily-loaded #(dom/ul (mapv ui-list-item %)) items)))Next we build a component named LargeList to control which page we’re on. This component does nothing more than
show the current page, and transact mutations that ask for the specific page. Not that we could easily add a control
to jump to any page, since the mutation itself is goto-page.
(defsc LargeList [this {:keys [list/current-page]}]
{:initial-state (fn [params] {:list/current-page (prim/get-initial-state ListPage {})})
:query [{:list/current-page (prim/get-query ListPage)}]
:ident (fn [] [:list/by-id 1])}
(let [{:keys [page/number]} current-page]
(dom/div
(dom/button {:disabled (= 1 number)
:onClick #(prim/transact! this `[(goto-page {:page-number ~(dec number)})])} "Prior Page")
(dom/button {:onClick #(prim/transact! this `[(goto-page {:page-number ~(inc number)})])}
"Next Page")
(ui-list-page current-page))))31.5.1. The goto-page Mutation
So you can infer that all of the complexity of this application is hidden behind a single mutation: goto-page. This
mutation is a complete abstraction to the UI, and the UI designer would need to very little about it.
We’ve decided that this mutation will:
-
Ensure the given page exists in app state (with its page number)
-
Check to see if the page has items
-
If not: it will trigger a server-side query for those items
-
-
Update the `LargeList’s current page to point to the correct page
-
Garbage collect pages/items in the app database that are 5 or more pages away from the current position.
The mutation itself looks like this:
(m/defmutation goto-page [{:keys [page-number]}]
(action [{:keys [state] :as env}]
(load-if-missing env page-number)
(swap! state (fn [s]
(-> s
(init-page page-number)
(set-current-page page-number)
(gc-distant-pages page-number)))))
(remote [{:keys [state] :as env}]
(when (not (page-exists? @state page-number))
(df/remote-load env)))) ; trigger load queue processingLet’s break this down.
The Action
The load-if-missing function is composed of the following bits:
(defn page-exists? [state-map page-number]
(let [page-items (get-in state-map [:page/by-number page-number :page/items])]
(boolean (seq page-items))))
(defn load-if-missing [{:keys [reconciler state] :as env} page-number]
(when-not (page-exists? @state page-number)
(let [start (inc (* 10 (dec page-number)))
end (+ start 9)]
(df/load reconciler :paginate/items ListItem {:params {:start start :end end}
:target [:page/by-number page-number :page/items]}))))and you can see that it just detects if the page is missing its items. If the items are missing, it loads them.
31.5.2. The Server-Side Code
The server in this example is trivial. It is just a query that generates items on the fly:
(defmethod api/server-read :paginate/items [env k {:keys [start end]}]
(when (> 1000 (- end start)) ; ensure the server doesn't die if the client does something like use NaN for end
{:value (vec (for [id (range start end)]
{:item/id id}))}))(ns book.demos.paginating-large-lists-from-server
(:require
[fulcro.client.mutations :as m]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.dom :as dom]
[fulcro.server :as server]
[fulcro.client.data-fetch :as df]
[fulcro.client :as fc]
[fulcro.client.primitives :as prim]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(server/defquery-root :paginate/items
"A simple implementation that can generate any number of items whose ids just match their index"
(value [env {:keys [start end]}]
(when (> 1000 (- end start))
(vec (for [id (range start end)]
{:item/id id})))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn page-exists? [state-map page-number]
(let [page-items (get-in state-map [:page/by-number page-number :page/items])]
(boolean (seq page-items))))
(defn init-page
"An idempotent init function that just ensures enough of a page exists to make the UI work.
Doesn't affect the items."
[state-map page-number]
(assoc-in state-map [:page/by-number page-number :page/number] page-number))
(defn set-current-page
"Point the current list's current page to the correct page entity in the db (via ident)."
[state-map page-number]
(assoc-in state-map [:list/by-id 1 :list/current-page] [:page/by-number page-number]))
(defn clear-item
"Removes the given item from the item table."
[state-map item-id] (update state-map :items/by-id dissoc item-id))
(defn clear-page
"Clear the given page (and associated items) from the app database."
[state-map page-number]
(let [page (get-in state-map [:page/by-number page-number])
item-idents (:page/items page)
item-ids (map second item-idents)]
(as-> state-map s
(update s :page/by-number dissoc page-number)
(reduce (fn [acc id] (update acc :items/by-id dissoc id)) s item-ids))))
(defn gc-distant-pages
"Clears loaded items from pages 5 or more steps away from the given page number."
[state-map page-number]
(reduce (fn [s n]
(if (< 4 (Math/abs (- page-number n)))
(clear-page s n)
s)) state-map (keys (:page/by-number state-map))))
(declare ListItem)
(defn load-if-missing [{:keys [reconciler state] :as env} page-number]
(when-not (page-exists? @state page-number)
(let [start (inc (* 10 (dec page-number)))
end (+ start 9)]
(df/load reconciler :paginate/items ListItem {:params {:start start :end end}
:target [:page/by-number page-number :page/items]}))))
(m/defmutation goto-page [{:keys [page-number]}]
(action [{:keys [state] :as env}]
(load-if-missing env page-number)
(swap! state (fn [s]
(-> s
(init-page page-number)
(set-current-page page-number)
(gc-distant-pages page-number)))))
(remote [{:keys [state] :as env}]
(when (not (page-exists? @state page-number))
(df/remote-load env))))
(defsc ListItem [this {:keys [item/id]}]
{:query [:item/id :ui/fetch-state]
:ident [:items/by-id :item/id]}
(dom/li (str "Item " id)))
(def ui-list-item (prim/factory ListItem {:keyfn :item/id}))
(defsc ListPage [this {:keys [page/number page/items]}]
{:initial-state {:page/number 1 :page/items []}
:query [:page/number {:page/items (prim/get-query ListItem)}]
:ident [:page/by-number :page/number]}
(dom/div
(dom/p "Page number " number)
(df/lazily-loaded #(dom/ul nil (mapv ui-list-item %)) items)))
(def ui-list-page (prim/factory ListPage {:keyfn :page/number}))
(defsc LargeList [this {:keys [list/current-page]}]
{:initial-state (fn [params] {:list/current-page (prim/get-initial-state ListPage {})})
:query [{:list/current-page (prim/get-query ListPage)}]
:ident (fn [] [:list/by-id 1])}
(let [{:keys [page/number]} current-page]
(dom/div
(dom/button {:disabled (= 1 number) :onClick #(prim/transact! this `[(goto-page {:page-number ~(dec number)})])} "Prior Page")
(dom/button {:onClick #(prim/transact! this `[(goto-page {:page-number ~(inc number)})])} "Next Page")
(ui-list-page current-page))))
(def ui-list (prim/factory LargeList))
(defsc Root [this {:keys [pagination/list]}]
{:initial-state (fn [params] {:pagination/list (prim/get-initial-state LargeList {})})
:query [{:pagination/list (prim/get-query LargeList)}]}
(dom/div (ui-list list)))
(defn initialize
"To be used as started-callback. Load the first page."
[{:keys [reconciler]}]
(prim/transact! reconciler `[(goto-page {:page-number 1})]))31.6. UI Query Security
If you examine any UI query it will have a tree form. That is the nature of EQL. It is also the nature of UI’s. For any such query, you can imagine it as a graph walk:
Take this query:
[:a {:join1 [:b {:join2 [:c :d]}]}]If you think about how this looks in the server: each join walks from one table (or entity) to another through some kind of (forward or reverse) reference.
QUERY PART IMPLIED DATABASE graph
[:a {:join1 { :a 6 :join1 [:tableX id1] }
\
\
\
[:b {:join2 :tableX { id1 { :id id1 :join2 [:tableY id2]
/
/
/
[:c :d]}]}] :tableY { id2 { :id id2 :c 4 :d 5 }}One idea that works pretty well for us is based on this realization: There is a starting point of this walk (e.g. I want to load a person), and the top-level detail must be specified (or implied at least) by the incoming query (load person 5, load all persons in my account, etc.).
A tradition logic check always needs to be run on this object to see if it is OK for the user to start reading the database there.
The problem that remains is that there is a graph query that could conceivably walk to things in the database that should not be readable. So, to ensure security we need to verify that the user:
-
is allowed to read the specific data at the node of the graph (e.g. :a, :c, and :d)
-
is allowed to walk across a given reference at that node of the graph.
However, since both of those cases are essentially the same in practice (can the user read the given property), one possible algorithm simplifies to:
-
Create a whitelist of keywords that are allowed to be read by the query in question. This can be a one-time declarative configuration, or something dynamic based on user rights.
-
Verify the user is allowed to read the "top" object. If not, disallow the query.
-
Recursively gather up all keywords from the query as a set
-
Find the set difference of the whitelist and the query keywords.
-
If the difference is not empty, refuse to run the query
31.6.1. The Server Hooks
This is one of the few examples that would add extra code to the server itself (we’re still simulating it for this book). This example’s auth mechanisms would be set up as components and a parser injection there. The relevant code is:
(defrecord Authentication [handler]
c/Lifecycle
(start [this]
(log/info "Hooking into pre-processing to add user info")
(let [old-pre-hook (h/get-pre-hook handler)
new-hook (fn [ring-handler] (fn [req] ((old-pre-hook ring-handler) (assoc req :user {:username "Tony"}))))]
(h/set-pre-hook! handler new-hook))
this)
(stop [this] this))
(defn make-authentication []
(c/using (map->Authentication {}) [:handler]))
(defprotocol Auth
(can-access-entity? [this user key entityid] "Check if the given user is allowed to access the entity designated by the given key and entity id")
(authorized-query? [this user top-key query] "Check if the given user is allowed to access all of the data in the query that starts at the given join key"))
(defrecord Authorizer []
c/Lifecycle
(start [this] this)
(stop [this] this)
Auth
(can-access-entity? [this user key entityid] (authorized-root-entity? user key entityid))
(authorized-query? [this user top-key query] (is-authorized-query? query top-key)))
(defn make-authorizer [] (map->Authorizer {}))
(defn make-system []
(core/make-fulcro-server
:config-path "config/demos.edn"
:parser (prim/parser {:read logging-query :mutate logging-mutate})
:parser-injections #{:authentication}
:components {
; Server security demo: This puts itself into the Ring pipeline to add user info to the request
:auth-hook (server-security/make-authentication)
; This is here as a component so it can be injected into the parser env for processing security
:authentication (server-security/make-authorizer)}))This logic is basically hacked in to the live example to give you an idea of how it looks.
(ns book.demos.server-query-security
(:require
[fulcro.client.data-fetch :as df]
[fulcro.client.primitives :as prim :refer [defsc]]
[fulcro.client.mutations :refer [defmutation]]
[clojure.set :as set]
[clojure.walk :as walk]
[fulcro.client.dom :as dom]
[fulcro.server :as server]
[com.stuartsierra.component :as c]
[fulcro.client.data-fetch :as df]
[fulcro.logging :as log]
[fulcro.client :as fc]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
; A map from "entry-level" concept/entity to a set of the allowed graph read/navigation keywords
(def whitelist {:person #{:name :address :mate}})
(defn keywords-in-query
"Returns all of the keywords in the given (arbitrarily nested) query."
[query]
(let [result (atom #{})
_ (walk/prewalk
(fn [k] (if (keyword? k) (swap! result conj k)))
query)]
@result))
; TODO: determine if the user is allowed to start at the given keyword for entity with given ID
(defn authorized-root-entity?
"Returns true if the given user is allowed to run a query rooted at the entity indicated by the combination of
query keyword and entity ID.
TODO: Implement some logic here."
[user keyword id] true)
(defn is-authorized-query?
"Returns true if the given query is ok with respect to the top-level key of the API query (which should have already
been authorized by `authorized-root-entity?`."
[query top-key]
(let [keywords-allowed (get whitelist top-key #{})
insecure-keywords (set/difference (keywords-in-query query) keywords-allowed)]
(empty? insecure-keywords)))
(defprotocol Auth
(can-access-entity? [this user key entityid] "Check if the given user is allowed to access the entity designated by the given key and entity id")
(authorized-query? [this user top-key query] "Check if the given user is allowed to access all of the data in the query that starts at the given join key"))
(defrecord Authorizer []
c/Lifecycle
(start [this] this)
(stop [this] this)
Auth
(can-access-entity? [this user key entityid] (authorized-root-entity? user key entityid))
(authorized-query? [this user top-key query] (is-authorized-query? query top-key)))
(defn make-authorizer [] (map->Authorizer {}))
(def pretend-database {:person {:id 42 :name "Joe" :address "111 Nowhere" :cc-number "1234-4444-5555-2222"}})
(server/defquery-root :person
(value [{:keys [request query] :as env} params]
(let [authorization (make-authorizer)
user (:user request)]
(log/info (str authorization "w/user" user))
(or
(and
;; of course, the params would be derived from the request/headers/etc.
(can-access-entity? authorization user :person 42)
(authorized-query? authorization user :person query))
(throw (ex-info "Unauthorized query!" {:status 401 :body {:query query}})))
;; Emulate a datomic pull kind of operation...
(select-keys (get pretend-database :person) query))))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(def initial-state {:ui/react-key "abc"})
(defonce app (atom (fc/make-fulcro-client
{:initial-state initial-state
:started-callback (fn [{:keys [reconciler]}]
; TODO
)})))
(defsc Person [this {:keys [name address cc-number]}]
{:query [:ui/fetch-state :name :address :cc-number]}
(dom/div
(dom/ul
(dom/li (str "name: " name))
(dom/li (str "address: " address))
(dom/li (str "cc-number: " cc-number)))))
(def ui-person (prim/factory Person))
(defmutation clear-error [params] (action [{:keys [state]}] (swap! state dissoc :fulcro/server-error)))
(defsc Root [this {:keys [person fulcro/server-error] :as props}]
{:query [{:person (prim/get-query Person)} :fulcro/server-error]}
(dom/div
(when server-error
(dom/p (pr-str "SERVER ERROR: " server-error)))
(dom/button {:onClick (fn []
(prim/transact! this `[(clear-error {})])
(df/load this :person Person {:refresh [:person]}))} "Query for person with credit card")
(dom/button {:onClick (fn []
(prim/transact! this `[(clear-error {})])
(df/load this :person Person {:refresh [:person] :without #{:cc-number}}))} "Query for person WITHOUT credit card")
(df/lazily-loaded ui-person person)))31.7. Fulcro with SQL
The Fulcro SQL library is capable of running many Fulcro graph queries directly against an SQL database. It also comes with testing utilities and a component for setting up connection pooling (via HikariCP) and migrations (via Flyway).
Since our demos run in the browser only for this document, we cannot show you a live demo, but here are some basics to whet your appetite.
Assume you have a PostgreSQL database. We could create a project with
migrations in src/main/config/migrations/V1__account_schema.sql. See
Flyway documentation for naming conventions. For our example here,
let’s say our initial schema is:
CREATE TABLE settings (
id SERIAL PRIMARY KEY,
auto_open BOOLEAN NOT NULL DEFAULT FALSE,
keyboard_shortcuts BOOLEAN NOT NULL DEFAULT TRUE
);
CREATE TABLE account (
id SERIAL PRIMARY KEY,
name TEXT,
last_edited_by INTEGER,
settings_id INTEGER REFERENCES settings (id),
created_on TIMESTAMP NOT NULL DEFAULT now()
);
CREATE TABLE member (
id SERIAL PRIMARY KEY,
name TEXT,
account_id INTEGER NOT NULL REFERENCES account (id)
);
ALTER TABLE account
ADD CONSTRAINT account_last_edit_by_fkey FOREIGN KEY (last_edited_by) REFERENCES member (id);
-- Some seed data for the demo
INSERT INTO settings (id, auto_open, keyboard_shortcuts) VALUES (1, true, false);
INSERT INTO settings (id, auto_open, keyboard_shortcuts) VALUES (2, false, false);
INSERT INTO account (id, name, settings_id) values (1, 'Sally', 1);
INSERT INTO account (id, name, settings_id) values (2, 'Bob', 2);
INSERT INTO member (id, name, account_id) values (1, 'Billy', 1);
INSERT INTO member (id, name, account_id) values (2, 'Tom', 1);
INSERT INTO member (id, name, account_id) values (3, 'Tori', 1);
INSERT INTO member (id, name, account_id) values (4, 'Cory', 2);
INSERT INTO member (id, name, account_id) values (5, 'Kady', 2);The connection pooling needs to be configured as well, and Fulcro SQL allows this to
also be on the classpath. Assume we have src/main/config/accountpool.props with
(see HikariCP documentation):
dataSourceClassName=org.postgresql.ds.PGSimpleDataSource
dataSource.user=test
dataSource.password=
dataSource.databaseName=accounts
dataSource.portNumber=5432
dataSource.serverName=localhostThen with some simple UI components like
(defsc Settings [this {:keys [db/id settings/auto-open? settings/keyboard-shortcuts?]}]
{:query [:db/id :settings/auto-open? :settings/keyboard-shortcuts?]
...
(defsc Member [this {:keys [db/id member/name]}]
{:query [:db/id :member/name]
...
(defsc Account [this {:keys [db/id account/name account/members account/settings]}]
{:query [:db/id :account/name {:account/members (prim/get-query Member)} {:account/settings (prim/get-query Settings)}]we might want to issue a load like this:
(df/load app :graph-demo/accounts Account {:target [:accounts]})In this example, we’ve been careful to align the UI with the schema of the database. All Fulcro SQL needs is a bit of configuration to tell it how to map the UI graph to the schema:
(def schema
{:fulcro-sql.core/graph->sql {:settings/auto-open? :settings/auto_open
:settings/keyboard-shortcuts? :settings/keyboard_shortcuts}
:fulcro-sql.core/joins {:account/members (sql/to-many [:account/id :member/account_id])
:account/settings (sql/to-one [:account/settings_id :settings/id])
:member/account (sql/to-one [:member/account_id :account/id])}
:fulcro-sql.core/pks {}})The relations (defined with to-one and to-many) assume you’ve chosen keyword namespaces that match your table names,
and keyword names that match column names (e.g. keyword :account/id → SQL ACCOUNT.ID). The joins are
then simply defined in the direction desired (you can see :account/members and :member/account
trafersing the same SQL "edge"). If that isn’t try, then you can remap them in the graph→sql section.
The database configuration (in our config EDN file) is:
{:port 8081
:sqldbm {:accounts {:hikaricp-config "config/accountpool.props"
:auto-migrate? true
:create-drop? true
:migrations ["classpath:config/migrations"]}}}and we inject the Fulcro SQL component into our parsing environment via:
(core/make-fulcro-server
...
:parser-injections #{:sqldb}
:components {:sqldb (component/using (sql/build-db-manager {}) [:config])})The server code to handle the query is then quite small:
(server/defquery-root :graph-demo/accounts
(value [{:keys [sqldb query]} params] ; get the injected database manager
(let [db (sql/get-dbspec sqldb :accounts) ; get the database from the db manager
; Find the IDs of the account(s) of interest (all accounts)
all-account-ids (jdbc/query db ["select id from account"] {:row-fn :id :result-set-fn set})]
(if (seq all-account-ids)
(sql/run-query db schema :account/id query all-account-ids) ; run the graph query
[]))))The complete source for this demo is:
(ns book.demos.server-SQL-graph-queries
(:require
#?@(:clj [[fulcro-sql.core :as sql]
[clojure.java.jdbc :as jdbc]
[taoensso.timbre :as timbre]])
[com.stuartsierra.component :as component]
[fulcro.client.dom :as dom]
[fulcro.easy_server :refer [make-fulcro-server]]
[fulcro.server :as server :refer [defquery-root server-read server-mutate]]
[fulcro.client.data-fetch :as df]
[fulcro.logging :as log]
[fulcro.client :as fc]
[fulcro.ui.bootstrap3 :as b]
[fulcro.client.primitives :as prim :refer [defsc]]))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; SERVER:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
#?(:clj
(def schema
{:fulcro-sql.core/graph->sql {:settings/auto-open? :settings/auto_open
:settings/keyboard-shortcuts? :settings/keyboard_shortcuts}
:fulcro-sql.core/joins {:account/members (sql/to-many [:account/id :member/account_id])
:account/settings (sql/to-one [:account/settings_id :settings/id])
:member/account (sql/to-one [:member/account_id :account/id])}
:fulcro-sql.core/pks {}}))
; This is the only thing we wrote for the server...just return some value so we can
; see it really talked to the server for this query.
#?(:clj
(server/defquery-root :graph-demo/accounts
(value [{:keys [sqldb query]} params]
(let [db (sql/get-dbspec sqldb :accounts)
all-account-ids (jdbc/query db ["select id from account"] {:row-fn :id :result-set-fn set})]
(timbre/info all-account-ids)
(if (seq all-account-ids)
(sql/run-query db schema :account/id query all-account-ids)
[])))))
(defn make-system []
(let [include-postgres? (boolean (System/getProperty "postgres"))]
(make-fulcro-server
:config-path "config/demos.edn"
:parser-injections (cond-> #{:authorization}
include-postgres? (conj :sqldb))
:components {:sqldb (component/using
(sql/build-db-manager {})
[:config])})))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; CLIENT:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defsc Settings [this {:keys [db/id settings/auto-open? settings/keyboard-shortcuts?]}]
{:query [:db/id :settings/auto-open? :settings/keyboard-shortcuts?]
:ident [:settings/by-id :db/id]}
(dom/ul
(dom/li (str "Auto open? " auto-open?))
(dom/li (str "Enable Keyboard Shortcuts? " keyboard-shortcuts?))))
(def ui-settings (prim/factory Settings {:keyfn :db/id}))
(defsc Member [this {:keys [db/id member/name]}]
{:query [:db/id :member/name]
:ident [:member/by-id :db/id]}
(dom/div
"Member: " name))
(def ui-member (prim/factory Member {:keyfn :db/id}))
(defsc Account [this {:keys [db/id account/name account/members account/settings]}]
{:query [:db/id :account/name {:account/members (prim/get-query Member)} {:account/settings (prim/get-query Settings)}]
:ident [:account/by-id :db/id]}
(dom/div
(dom/h3 (str "Account for " name))
(dom/ul
(when (seq settings)
(dom/li
(dom/h3 "Settings")
(ui-settings settings)))
(dom/li
(dom/h3 "Members in the account")
(map ui-member members)))))
(def ui-account (prim/factory Account {:keyfn :db/id}))
(defsc Root [this {:keys [ui/react-key accounts]}]
{:query [:ui/react-key {:accounts (prim/get-query Account)}]}
(dom/div {:key react-key}
(dom/h3 "Accounts with settings and users")
(map ui-account accounts)))
#?(:cljs (defonce app (atom (fc/make-fulcro-client
{:client-did-mount
(fn [app]
(df/load app :graph-demo/accounts Account {:target [:accounts]}))})))) `#?(:cljs (swap! app fc/mount Root "app"))